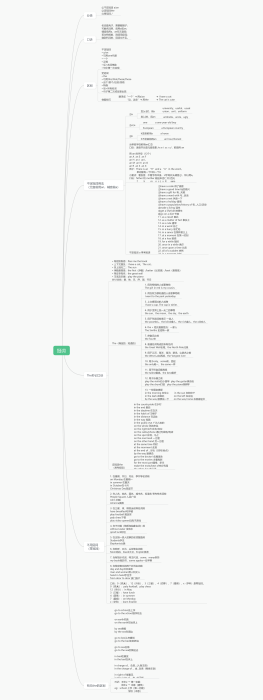
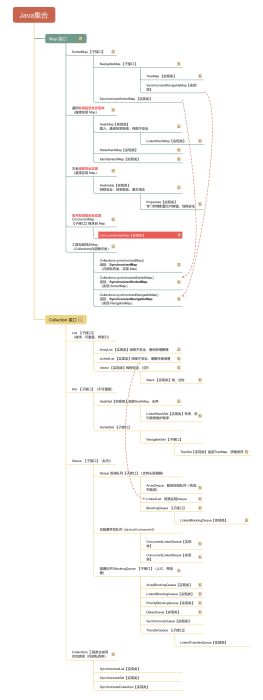
Map基础知识
存储的结构是key-value键值对,不像Collection是单列集合
阅读Map前最好知道什么是散列表和红黑树
Map常用子类
HashMap
底层是散列表+红黑树。初始容量为16,装载因子为0.75,每次扩容2倍
允许为null,存储无序
非同步
散列表容量大于64且链表大于8时,转成红黑树
Key的哈希值会与该值的高16位做异或操作,进一步增加随机性
JDK1.8对hash算法和寻址算法的优化<br>
hash算法的优化:对每个hash值,在他的低16位中,让高低16位进行了异或,让他的低16位同时保持了高低16位的特征,尽量避免一些hash值后续出现冲突,大家可能会进入数组的同一个位置
寻址算法的优化:用与运算替代取模,提升性能
当散列表的元素 > 容量 * 装载因子 时,会再散列,每次扩容2倍
如果hashCode相同,key不同则替换元素,否则就是散列冲突
LinkedHashMap
底层是散列表+红黑树+双向链表,父类是HashMap
允许为null,插入有序
非同步
提供插入顺序和访问顺序两种,访问顺序是符合LRU算法的,一般用于扩展(默认是插入顺序)
迭代与初始容量无关(迭代的是维护的双向链表)
大多使用HashMap的API,只不过在内部重写了某些方法,维护了双向链表
TreeMap
底层是红黑树,保证了时间复杂度为log(n)
可以对其进行排序,使用Comparator或者Comparable
只要compare或者CompareTo认定该元素相等,那就相等
非同步
自然排序(手动排序),元素不能为null
ConcurrentHashMap
底层是散列表+红黑树,支持高并发操作
key和value都不能为null
线程是安全的,利用CAS算法和部分操作上锁实现
get方法是非阻塞,无锁的。重写Node类,通过volatile修饰next来实现每次获取都是最新设置的值
在高并发环境下,统计数据(计算size…等等)其实是无意义的,因为在下一时刻size值就变化了。