数据中台知识体系(上):原理篇
2021-07-14 13:11:51 3 举报AI智能生成
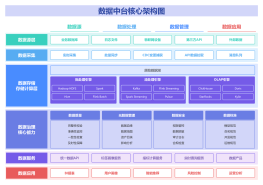
数据中台是一套可持续“让企业的数据用起来”的机制,一种战略选择和组织形式,是依据企业特有的业务模式和组织架构,通过有形的产品和实施方法论支撑,构建一套持续不断把数据变成资产并服务于业务的机制。数据中台建设是一个系统工程,需要从上到下进行推动,涉及组织架构、人员配备、流程优化、技术支持等多个方面。在实施过程中,需要明确目标、制定计划、分阶段推进,并注重与业务部门的沟通协作,以确保数据中台能够真正为企业创造价值。总之,数据中台是一个复杂而又重要的课题,值得我们深入研究和探讨。