常见命令
Keys
setnx
exprie: 设置过期时间<br>persist: 设置永不过期
常见问题
缓存雪崩
同一时间大量的key失效,大量请求打入数据库
如何预知雪崩
检测redis 所在的机器喝数据库所在机器的负载指标(数据库机器负载激增)
解决
1. 过期时间加随机值(随机增加1~3分钟)
2. 服务降级
当业务应用访问的是非核心数据(例如电商商品属性)时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
允许核心数据请求数据库
3. 在业务系统中实现服务熔断或请求限流机制。
服务熔断: 业务应用调用缓存接口时,缓存客户端并不把请求发给 Redis 缓存实例,而是直接返回,<br>等到 Redis 缓存实例重新恢复服务后,再允许应用请求发送到缓存系统
限流机制
4.集群部署
缓存击穿
热点数据,数据被频繁且大量的访问,该keys失效的瞬间,全部请求打入数据库
缓存穿透
出现问题
业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
恶意攻击:专门访问数据库中没有的数据
解决<br>
缓存空值或缺省值。
针对查询的数据,在 Redis 中缓存一个空值或是和业务层协商确定的缺省值(例如,库存的缺省值可以设为 0)。紧接着,应用发送的后续请求再进行查询时,就可以直接从 Redis 中读取空值或缺省值,返回给业务应用了,避免了把大量请求发送给数据库处理,保持了数据库的正常运行。
布隆过滤器
布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
把数据写入数据库时,使用布隆过滤器做个标记
当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在
布隆过滤器可以使用 Redis 实现
Redis实现的布隆过滤器bigkey问题:Redis布隆过滤器是使用String类型实现的,存储的方式是一个bigkey,<br>建议使用时单独部署一个实例,专门存放布隆过滤器的数据,不要和业务数据混用,否则在集群环境下,数据迁移时会导致Redis阻塞问题。
请求入口前端堆请求合法性进行检查
双写一致性
删改数据
先删缓存后更新DB
DB更新失败,导致缓存缺失,再读DB值为旧值
解决
重试机制(最终一致性, 数据还是会出现短暂的不一致)()
例如: 把命令先写入到Kafka消息队列, Kafka有事务消息机制算是最终一致; 此时如果原子操作没有成功,<br>就从消息队列中重新拿取该值; 原子操作才会算作消息消费成功, 成功则把这些值从消息队列中去除
延迟双删
延时双删(先删除缓存,再更新数据库)
先删缓存,在更新DB后,sleep一段时间,再进行一次缓存删除操作
在线程 A 更新完数据库值以后,我们可以让它先 sleep 一小段时间,再进行一次缓存删除操作。
加上 sleep 的这段时间,就是为了让线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存
线程 A sleep 的时间,就需要大于线程 B 读取数据再写入缓存的时间
示例
<br>redis.delKey(X)<br>db.update(X)<br>Thread.sleep(N)<br>redis.delKey(X)
(先更新数据库值,再删除缓存值)
删除缓存值或更新数据库失败而导致数据不一致,你可以使用<font color="#ff0000">重试机</font>制确保删除或更新操作成功。
应对方案还是是延迟双删
关于重试机制
最好 <font color="#ff0000">异步重试</font>
<b>消息队列保证可靠性:</b>写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)
<b>消息队列保证消息成功投递</b>:下游从队列拉取消息,成功消费后才会删除消息,<br>否则还会继续投递消息给消费者(符合我们重试的场景)
写队列失败 概率很低
<b>维护成本</b>:我们项目中一般都会用到消息队列,维护成本并没有新增很多
如果你确实不想在应用中去写消息队列,是否有更简单的方案,同时又可以保证一致性呢?
近几年比较流行的解决方案:订阅数据库变更日志,再操作缓存。
拿 MySQL 举例,当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),<br>我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。
订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal,使用这种方案的优点在于<br><b>无需考虑写消息队列失败情况</b>:只要写 MySQL 成功,Binlog 肯定会有<br><b>自动投递到下游队列</b>:canal 自动把数据库变更日志「投递」给下游的消息队列<br>
建议
「延迟双删」,这个延迟时间很难评估,所以推荐用「先更新数据库,再删除缓存」的方案,<br>并配合「消息队列」或「订阅变更日志」的方式来做(本质是通过 [重试] 机制保证一致性)。<br>
并发竞争
分布式锁
使用分布锁的注意点:
1. 使用 SET $lock_key $unique_val EX $second NX 命令保证加锁原子性,并为锁设置过期时间
2. 锁的过期时间要提前评估好,要大于操作共享资源的时间
3. 每个线程加锁时设置随机值(unique_val),释放锁时判断是否和加锁设置的值一致,防止自己的锁被别人释放(解铃还须系铃人)
4. 释放锁时使用 Lua 脚本,保证操作的原子性
/**<br> * 解锁的lua脚本<br> */<br> public static final String UNLOCK_LUA;<br><br> static {<br> StringBuilder sb = new StringBuilder();<br> sb.append("if redis.call(\"get\",KEYS[1]) == ARGV[1] ");<br> sb.append("then ");<br> sb.append(" return redis.call(\"del\",KEYS[1]) ");<br> sb.append("else ");<br> sb.append(" return 0 ");<br> sb.append("end ");<br> UNLOCK_LUA = sb.toString();<br> }
result = (Long) ((Jedis) nativeConnection).eval(UNLOCK_LUA, keys, values);
Redlock(l了解)
5. 基于多个节点的 Redlock,加锁时超过半数节点操作成功,并且获取锁的耗时没有超过锁的有效时间才算加锁成功
6、Redlock 释放锁时,要对所有节点释放(即使某个节点加锁失败了),因为加锁时可能发生服务端加锁成功,由于网络问题,<br>给客户端回复网络包失败的情况,所以需要把所有节点可能存的锁都释放掉
7、使用 Redlock 时要避免机器时钟发生跳跃,需要运维来保证,对运维有一定要求,否则可能会导致 Redlock 失效。例如共 3 个节点,线程 A 操作 2 个节点加锁成功,但其中 1 个节点机器时钟发生跳跃,锁提前过期,线程 B 正好在另外 2 个节点也加锁成功,此时 Redlock 相当于失效了(Redis 作者和分布式系统专家争论的重要点就在这)
8、如果为了效率,使用基于单个 Redis 节点的分布式锁即可,此方案缺点是允许锁偶尔失效,优点是简单效率高
9、如果是为了正确性,业务对于结果要求非常严格,建议使用 Redlock,但缺点是使用比较重,部署成本高
问题
锁过期释放,业务没执行完
解决: 利用 Redisson框架 的watch dog (看门狗)来解决
只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,<br>如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了「锁过期释放,业务没执行完」问题。
集群问题
多机实现的分布式锁Redlock+Redisson
部署成本高
大Key
bingkey命令 找到干掉
Redis 4.0引入了memory usage命令和lazyfree机制
热点key
缓存时间不失效
多级缓存
布隆过滤器
读写分离
预防
针对缓存击穿,在缓存访问非常频繁的热点数据时,不要设置过期时间;
针对缓存雪崩,合理地设置数据过期时间,以及搭建高可靠缓存集群
针对缓存穿透,提前在入口前端实现恶意请求检测,或者规范数据库的数据删除操作,避免误删除。
多路IO复用
read得读到很多才会返回 为会卡在那 知道新数据来或者链接关闭
写不会阻塞,除非缓冲区满了
非阻塞的IO提供了一个选项no_blocking 读写都不会阻塞,读多少写多少<br>取决于内核的套接字字节分配
非阻塞的IO也有问题,线程要读数据,读了一点久返回了 线程什么时候知道哟啊继续读,写一样
一版都是select解决, 现在都是epoll
select
epoll
高可用
持久化
RDB
默认配置
save 900 1<br>save 300 10<br>save 60 10000
在下面的例子中,行为将是保存:<br>1. 在900秒(15分钟)后有1次更新,就进行持久化操作<br>2. 在300秒(5分钟)后有10次更新,就进行持久化操作<br>3. 在60秒后有10000次更新,就进行持久化操作<br>
冷备
快照文件生成时间久,消耗CPU
手动调用SAVE或者BGSAVE命令或者配置条件触发,将数据库某一时刻的数据快照,生成RDB文件实现持久化
AOF
配置
appendonly yes //是否开启AOF, 默认No
AOF持久化配置文件的名称: appendfilename “appendonly.aof”
AOF持久化策略(默认每秒):
appendfsync always (同步持久化,每次发生数据变更会被立即记录到磁盘,性能差但数据完整性比较好)<br>appendfsync everysec (异步操作,每秒记录,如果一秒钟内宕机,有数据丢失)<br>appendfsync no (将缓存回写的策略交给系统,linux 默认是30秒将缓冲区的数据回写硬盘的)<br>AOF的Rewrite(重写) :<br>
优点: 数据齐全
缺点: 恢复速度慢,慢文件大
实现
后日志(先执行命令,后写如日志)
优点
避免出现记录错误命令的情况
<span style="color: rgb(51, 51, 51); font-family: "PingFang SC", Avenir, Tahoma, Arial, "Lantinghei SC", "Microsoft Yahei", "Hiragino Sans GB", "Microsoft Sans Serif", "WenQuanYi Micro Hei", Helvetica, sans-serif; font-size: 16px;">不会阻塞当前的写操作。</span>
缺点
AOF 日志也是在主线程中执行,可能阻塞后续命令
写日志时宕机,这个命令和相应的数据就有丢失的风险
三种写回策略
Always
同步写回,可靠性高,数据基本不丢失
每个写命令都要落盘,性能影响较大
重写(fork 子进程,不堵塞)
随着AOF文件越来越大,里面会有大部分是重复命令或者可以合并的命令(例如: 100次incr = set key 100)
重写的好处:减少AOF日志尺寸,减少内存占用,加快数据库恢复时间。
重写方法
手动执行命令: bgrewriteaof
自动重写
auto-aof-rewrite-min-size 64 <br>auto-aof-rewrite-percentage 100
原理: 1 fork子进程执行 2. 重写aof文件 3. 返回消息
数据初始化
从节点发送命令主节点做bgsave同时开启buffer
AOF 和 RDB: 如果Redis服务器同时开启了RDB和AOF持久化,服务器会优先使用AOF文件来还原数据(因为AOF更新频率比RDB更新频率要高,还原的数据更完善)
数据同步机制
主从同步
主从库如何实现数据一致
1: 建立连接,协商同步
psync ? - 1
2: 主库同步数据给从库: 发送RDB 文件<br>
二进制,体积小,传输高效(网络带宽占用少),低成本, 从库加载快
3: 主库发送新写命令给从库
发送repl buffer
主从库间网络断了怎么办
从库恢复连接时根据,master 根据 <font color="#ff0000"> repl_backlog_buffer </font>来执行全量复制或者增量复制
repl_backlog_buffer(从库恢复连接用)
一个环形缓冲区,**主库会记录自己写到的位置,从库则会记录自己已经读到的位置。**
主库中的,所有从库的共享的缓冲区。
所有从库都断开了,那么acklog buffer会释放
全量同步
第一次建立连接
主库根据从库传来的offset,在repl_backlog中寻找,如果没有被覆盖,就可以只同步差异数据,否则给从库全量数据
主数据库写入速度过快,从库来不及消费,导致环形命令被覆盖
配置
repl_backlog_buffer配置尽量大一些,可以降低主从断开后全量同步的概率
repl_backlog_size 来配置 repl_backlog_buffer 大小, 默认是1M
缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小
考虑突发的压力,设置为业务的2倍
replication buffer
和repl_backlog_buffer 配合使用
<span style="color: rgb(51, 51, 51); font-family: "Open Sans", "Clear Sans", "Helvetica Neue", Helvetica, Arial, "Segoe UI Emoji", sans-serif; font-size: 16px; orphans: 4; white-space: pre-wrap;">用于主节点与各个从节点间 数据的批量交互</span>
主节点为各个从节点分别创建一个缓冲区,由于各个从节点的处理能力差异,各个缓冲区数据可能不同。(==Kaito== 大神回答) buffer是主从通信的数据通道,所有主从同步的数据都是要经过这个buffer的,无论全量同步还是增量同步。
主从同步中 master 需要给每个salve fork 子进程进行全量同步,主库压力大如何解决
分担主库压力
主 - 从 - 从”模式”, 让多个从库关联到其中一个从库,让该从库分担大部分压力
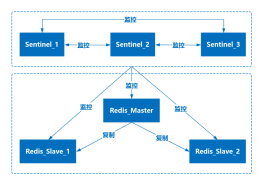
哨兵
集群监控
消息通知
故障转以
配置中心
脑裂
备用方案
主从 + 哨兵 + cluster
ecache + Hystrix + 降级 + 熔断 + 隔离
持久化
淘汰机制
概念
redis的maxmemory参数用于控制redis可使用的最大内存容量。如果超过maxmemory的值,就会动用淘汰策略来处理expaire字典中的键。
获取当前的内存淘汰策略
config get maxmemory-policy
redis4.0为我们提供了八个不同的内存置换策略, 之前6种,多了 lfu (使用频率最低的)
8种机制
volatile-lru
从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
volatile-random: 从已设置过期时间的数据集中任意选择数据淘汰
volatile-ttl: 从已设置过期时间的数据集中挑选将要过期的数据
allkeys-lru: 从数据集中挑选最近最少使用的数据淘汰
allkeys-lfu:从所有键中驱逐使用频率最少的键
allkeys-random: 从数据集中任意选择数据淘汰
no-eviction:<font color="#ff0000"><b> (默认策略)</b></font>:对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外) 不驱逐
择淘汰策略
<span style="color: rgba(0, 0, 0, 0.75); font-family: -apple-system, "SF UI Text", Arial, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", sans-serif; font-size: 16px; font-variant-ligatures: no-common-ligatures;">如果分为热数据与冷数据, 推荐使用 allkeys-lru 策略。 也就是, 其中一部分key经常被读写. 如果不确定具体的业务特征, 那么 allkeys-lru 是一个很好的选择</span>
各个key的访问频率差不多, 可以使用 allkeys-random 策略
子主题
过期策略
定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
缺点:
定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),<br>消耗内存, 性能影响严重
惰性删除
含义
key过期的时不删,每次访问key时去检查是否过期,若过期则删除,返回null。
可能存在大量key,消耗内存,但是不会占cpu资源
定期删除
每隔一段时间执行一次删除(在redis.conf配置文件设置hz,1s刷新的频率)过期key操作,<br>轮询(默认16个)数据库, 随机删除数据库的(20)过期key, 若没有过期的检查下一个数据库
RDB对过期key的处理
过期key对RDB没有任何影响
从内存数据库持久化数据到RDB文件之前,会检查是否过期,过期的key不进入RDB文件
从RDB文件恢复数据到内存数据库之前,会对key先进行过期检查,过期则不导入数据库(主库情况)
AOF对过期key的处理
<div yne-bulb-block="paragraph" style="white-space: pre-wrap; line-height: 1.75; font-size: 14px;"><span style="font-family: Verdana;color: rgb(57, 57, 57);background-color: rgb(250, 247, 239);">过期key对AOF没有任何影响</span></div>
从内存数据库持久化数据到AOF文件:
当key过期后,还没有被删除,此时进行执行持久化操作
当key过期后,在发生删除操作时,程序会向aof文件追加一条del命令(在将来的以aof文件恢复数据的时候该过期的键就会被删掉)
AOF重写时,会先判断key是否过期,已过期则不重写到aof文件