注册中心选型和落地
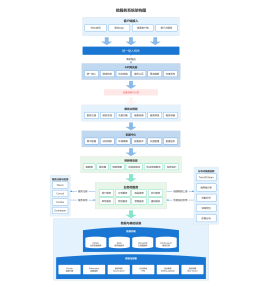
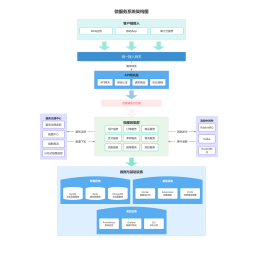
注册中心工作流程
1. 查看是否在白名单中
2. 查看注册的Cluster(服务的接口名)是否存在
3. 检查service 是否存在
4. 将节点信息添加到对应的service 和 cluster 中
反注册工作流
1. 查看 Service(服务的分组)是否存在
2. 查看 Cluster(服务的接口名)是否存在
3. 删除存储中 Service 和 Cluster 下对应的节点信息
4. 更新 Cluster 的 sign 值
查询节点信息
1. 首先从 localcache(本机内存)中查找
2. 接着从 snapshot(本地快照)中查找,
订阅服务变更
1. 服务消费者从注册中心获取了服务的信息后,就订阅了服务的变化,会在本地保留 Cluster 的 sign 值
2. 服务消费者每隔一段时间,调用 getSign() 函数,从注册中心获取服务端该 Cluster 的 sign 值,并与本地保留的 sign 值做对比,如果不一致,就从服务端拉取新的节点信息,并更新 localcache 和 snapshot。
选型
1. 应用内注册与发布
2. 应用外注册与发布
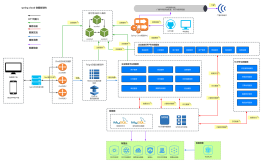
服务监控系统的搭建
集中式日志解决方案: ELK
ELK,Elasticsearch, Logstash,Kibana 三个开源软件的首字母缩写
Logstash 负责数据的收集和传输
Elasticsearch 服务数据的处理
Kibana 负责数据展示
时序数据库解决方案: Graphite, TICK, Prometheus
Graphite :Carbon, Whisper, Graphite-Web
Carbon:接收被监控节点的连接,收集各个指标的数据,将这些数据写入 carbon-cache 并最终持久化到 Whisper 存储文件中去。
Whisper
Graphite-Web
TICK: Telegraf、InfluxDB、Chronograf、Kapacitor 四个软件首字母的缩写
Prometheus
选型对比
数据收集
ELK 是通过在每台服务器上部署 Beats 代理来采集数据;
Graphite 本身没有收据采集组件,需要配合使用开源收据采集组件,比如 StatsD;
TICK 使用了 Telegraf 作为数据采集组件;
Prometheus 通过 jobs/exporters 组件来获取 StatsD 等采集过来的 metrics 信息。
数据传输
【推】ELK 是 Beats 采集的数据传输给 Logstash,经过 Logstash 清洗后再传输给 Elasticsearch;
【推】Graphite 是通过第三方采集组件采集的数据,传输给 Carbon
【推】TICK 是 Telegraf 采集的数据,传输给 InfluxDB
【拉】Prometheus 是 Prometheus Server 隔一段时间定期去从 jobs/exporters 拉取数据。
数据处理
数据展示
服务追踪系统的搭建
PinPoint - 深度支持java,
OpenZipKin
Collector:负责收集探针 Reporter 埋点采集的数据,经过验证处理并建立索引。
Storage:存储服务调用的链路数据,默认使用的是 Cassandra,是因为 Twitter 内部大量使用了 Cassandra,你也可以替换成 Elasticsearch 或者 MySQL。
API:将格式化和建立索引的链路数据以 API 的方式对外提供服务,比如被 UI 调用。
UI:以图形化的方式展示服务调用的链路数据。
工作原理: