
JAVA学习之路
2024-03-03 20:24:45 0 举报AI智能生成
这是一份关于JAVA学习之路的详细指南,旨在帮助读者从零基础开始,逐步掌握JAVA编程的核心技能。文件内容包括JAVA环境搭建、变量与数据类型、运算符、控制结构、数组与字符串、类和对象、继承与多态、抽象类与接口、异常处理、集合框架、IO流、多线程、网络编程、反射机制、注解以及JDBC数据库编程等知识点。通过理论和实践相结合的方式,引导读者深入理解JAVA编程的精髓,提升实际开发能力。这份指南不仅有助于初学者快速入门,同时也适合有经验的开发者查漏补缺,深化理解。
后端开发
大数据
架构师
技术栈
个人
模板推荐
作者其他创作
大纲/内容
计算机基础
计算机操作系统
数据结构与算法
计算机组成原理
计算机网络
大数据
流处理
Spark
批处理
Flink
运维与测试
k8s
常用命令
查看POD
kebuctl get pod
kebuctl get pod -o -wide<br>
kebuctl describe pod <pod name><br>
删除POD
kebuctl detele pod --all/<pod name><br>
概念
POD
Label<br>
Replication Controller<br>
Horizontal Pod Autoscaler
Volume
Namespace
Service
Docker
虚拟化
虚拟化(英语:Virtualization)是一种资源管理技术,是将计算机的各种<br>实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结<br>构间的不可切割的障碍,使用户可以比原本的组态更好的方式来应用这些资源。这些资<br>源的新虚拟部份是不受现有资源的架设方式,地域或物理组态所限制。一般所指的虚拟<br>化资源包括计算能力和资料存储。
介绍
Docker是一个开发,运输和运行应用程序的开放平台。 Docker使您可以将应用程序与基<br>础架构分离,以便快速交付软件。 使用Docker,您可以像管理应用程序一样管理基础架<br>构(OS)。 通过利用Docker的方法快速发送,测试和部署代码,您可以显着减少编写代<br>码和在生产中运行代码之间的延迟。(代码改了)
优缺点
优点
加速本地开发和构建流程,使其更加高效、更加轻量化。
能够让独立的服务或应用程序在不同的环境中,得到相同的运行结果。这一点在面向<br>服务的架构和重度依赖微型服务的部署由其实用。
用Docker创建隔离的环境来进行测试。
Docker可以让开发者先在本机上构建一个复杂的程序或架构来进行测试,而不是一<br>开始就在生产环境部署、测试。
构建一个多用户的平台即服务(PaaS)基础设施
为开发、测试提供一个轻量级的独立的沙盒环境
容器和虚拟机的区别
容器<br>
容器是一个应用层抽象,用于将代码和依赖资源打包在一起。 多个容器可以在同一<br>台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行 。与<br>虚拟机相比, 容器占用的空间较少(容器镜像大小通常只有几十兆),瞬间就能完<br>成启动 。<br>
虚拟机
容器是一个应用层抽象,用于将代码和依赖资源打包在一起。 多个容器可以在同一<br>台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行 。与<br>虚拟机相比, 容器占用的空间较少(容器镜像大小通常只有几十兆),瞬间就能完<br>成启动 。
版本
企业版
社区版
安装
docker对Ubuntu的支持是最好的
如果是 CentOS:安装docker 建议7.x及以上版本
Docker支持在多种平台上使用,包括Mac、Windows、Cloud以及Linux系统上等
常用命令
启动
systemctl status docker<br>
查看docker详细信息
docker info
查看docker版本
docker --version
镜像
介绍
Docker 镜像是容器的基础。镜像是一个有序集合,其中包含根文件系统更改和在容器运<br>行时中使用的相应执行参数。镜像通常 包含堆叠在彼此之上的联合分层文件系统。镜像<br>没有状态并且始终不会发生更改。 当运行容器时,使用的镜像如果在本地中不存在,<br>docker 就会自动从 docker 镜像仓库中下载,默认是从 Docker Hub 公共镜像源下载<br>
文件
这些镜像都是存储在Docker宿主机的/var/lib/docker目录下。<br>
配置镜像加速器
阿里云(先加入阿里云开发者平台:https://dev.aliyun.com)
docker中国加速器(https://www.docker‐cn.com<br>
USTC加速器(https://lug.ustc.edu.cn/wiki/ ) 真正的公共服务(无需任何操<br>作)
操作
sudo vim /etc/docker/daemon.json
{<br>"registry‐mirrors": ["https://cs913o6k.mirror.aliyuncs.com"]<br>}<br>sudo systemctl daemon‐reload<br>sudo systemctl restart docker
命令
列出镜像
docker images
查找镜像
docker search 镜像名称
拉取镜像
docker pull 镜像名称[:version]<br>
删除镜像<br>
一个镜像
docker rmi 镜像名称/id
多个
docker rmi 镜像名称1/id1 镜像名称2/id2 ...
所有
docker rmi `docker images ‐q`<br>
镜像的制作
两种方式<br>
使用docker commit命令<br>
使用docker build和Dockerfile文件<br>
Dockerfile使用基本的基于DSL语法的指令来构建一个Docker镜像,之后使用docker<br>builder命令基于该Dockerfile中的指令构建一个新的镜像。<br>
容器
介绍
容器是 docker 镜像的运行时实例
常用命令
创建容器<br>
dcoker run -
‐i:交互式容器<br>‐t:tty,终端<br>‐d:后台运行,并且打印容器id
进入容器
docker exec ‐it 容器名称/id /bin/bash (ps:exit,容器不会停止)
查询容器
docker ps:查看正在运行的容器<br>docker ps ‐a:查看运行过的容器(历史)<br>docker ps ‐l:最后一次运行的容器
停止和启动容器
docker start 容器名称/id<br>docker stop 容器名称/id
查询容器的元数据
docker inspect 容器/镜像<br>
删除容器
一个容器
docker rm 容器名称/id<br>
多个容器
docker rm 容器名称1/id1 容器名称2/id2 ...
删除所有容器
docker rm `docker ps ‐a ‐q`
PS 无法查看正在运行的容器
查看容器日志
docker logs 容器名称/id
文件拷贝
docker cp 需要拷贝的文件或目录 容器名称:容器目录<br>例如:docker cp 1.txt c2:/root<br>
目录挂载
我们可以在创建容器的时候,将宿主机的目录与容器内的目录进行映射,这样我们就可<br>以通过修改宿主机某个目录的文件从而去影响容器。<br>
创建容器 添加-v参数 后边为 宿主机目录:容器目录
docker run ‐id ‐‐name=c4 ‐v /opt/:/usr/local/myhtml centos<br>
如果你共享的是多级的目录,可能会出现权限不足的提示<br>
这是因为CentOS7中的安全模块selinux把权限禁掉了,我们需要添加参数 --<br>privileged=true 来解决挂载的目录没有权限的问题<br>
docker run ‐id ‐‐privileged=true ‐‐name=c4 ‐v /opt/:/usr/local/myhtml centos
仓库
介绍<br>
Docker仓库(Repository)类似与代码仓库,是Docker集中存放镜像文件的地方
dockerHub
1、打开https://hub.docker.com/<br>2、注册账号:略<br>3、创建仓库(Create Repository):略<br>4、设置镜像标签<br>docker tag local‐image:tagname new‐repo:tagname(设置tag)<br>eg:docker tag hello‐world:latest 108001509033/test‐hello‐world:v1<br>5、登录docker hub<br>docker login(回车,输入账号以及密码)<br>6、推送镜像<br>docker push new‐repo:tagname<br>eg:docker push 108001509033/test‐hello‐world:v1
阿里云
1、创建阿里云账号<br>2、创建命名空间<br>3、创建镜像仓库<br>4、操作指南<br>$ sudo docker login ‐‐username=[账号名称] registry.cn‐<br>hangzhou.aliyuncs.com<br>$ sudo docker tag [ImageId] registry.cn‐<br>hangzhou.aliyuncs.com/360buy/portal:[镜像版本号]<br>$ sudo docker push registry.cn‐hangzhou.aliyuncs.com/360buy/portal:[镜像版<br>本号<br>
私有仓库的搭建
启动Docker Registry,使用Docker官方提供的Registry镜像就可以搭建本地私有镜像<br>仓库,具体指令如下。<br>$ docker run ‐d \<br>‐p 5000:5000 \<br>‐‐restart=always \<br>‐‐name registry \<br>‐v /mnt/registry:/var/lib/registry \<br>registry:2<br>
2、重命名镜像,之前推送镜像时,都是默认推送到远程镜像仓库,而本次是将指定镜像推送<br>到本地私有镜像仓库。由于推送到本地私有镜像仓库的镜像名必须符合“仓库IP:端口<br>号/repository”的形式,因此需要按照要求修改镜像名称,具体操作指令如下。<br>$ docker tag hello‐world:latest localhost:5000/myhellodocker
3、推送镜像,本地私有镜像仓库搭建并启动完成,同时要推送的镜像也已经准备就绪后,就<br>可以将指定镜像推送到本地私有镜像仓库了,具体操作指令如下<br>$ docker push localhost:5000/myhellodocker
4、查看本地仓库镜像<br>http://localhost:5000/v2/myhellodocker/tags/list (注意:使用该地址时注意镜<br>像名称)<br>由于做了目录挂载,因此可以在本地的该目录下查看:<br>/mnt/registry/docker/registry/v2/repositories
docker compose编排工具
docker可视化工具
数据结构与算法
前端
基础
JS
CSS
HTML
框架
Vue.js
React.JS
Angular.js
分布式专题
CAP理论
数据一致性
可用性
分区容错性
BASE理论
基本可用
软状态
最终一致性
负载均衡策略<br>
轮询法<br>
加权轮询法<br>
随机法<br>
加权随机法
源地址哈希法<br>
最小连接数法
事务
解决方案
基于XA协议的:两阶段提交和三阶段提交,需要数据库层面支持<br>
基于事务补偿机制的:TCC,基于业务层面实现<br>
本地消息表:基于本地数据库+mq,维护本地状态(进行中),通过mq调用服务,完成后响应一条消<br>息回调,将状态改成完成。需要配合定时任务扫表、重新发送消息调用服务,需要保证幂等<br>
基于事务消息:mq<br>
两阶段和三阶段对比
两阶段
第一阶段( prepare )<br>
每个参与者执行本地事务但不提交,进入 ready 状态,并通知协调者已经准备就绪。
第二阶段(commit)
当协调者确认每个参与者都 ready 后,通知参与者进行 commit 操作;如果有<br>参与者 fail ,则发送 rollback 命令,各参与者做回滚。<br>
问题
单点故障:一旦事务管理器出现故障,整个系统不可用(参与者都会阻塞住)<br>
数据不一致:在阶段二,如果事务管理器只发送了部分 commit 消息,此时网络发生异常,那么只有部分参与者接收到 commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。<br>
响应时间较长:参与者和协调者资源都被锁住,提交或者回滚之后才能释放<br>
不确定性:当协事务管理器发送 commit 之后,并且此时只有一个参与者收到了 commit,那么当<br>该参与者与事务管理器同时宕机之后,重新选举的事务管理器无法确定该条消息是否提交成功。<br>
三阶段
第一阶段
CanCommit阶段,协调者询问事务参与者,是否有能力完成此次事务。<br>
第二阶段<br>
PreCommit阶段,此时协调者会向所有的参与者发送PreCommit请求,参与者收到后开始执行事务操作。参与者执行完事务操作后(此时属于未提交事务的状态),就会向协调者反馈“Ack”表示我已经准备好提交了,并等待协调者的下一步指令
第三阶段<br>
DoCommit阶段, 在阶段二中如果所有的参与者节点都返回了Ack,那么协调者就会从“预提交状态”转变为“提交状态”。然后向所有的参与者节点发送"doCommit"请求,参与者节点在收到提交请求后就会各自执行事务提交操作,并向协调者节点反馈“Ack”消息,协调者收到所有参与者的Ack消息后完成事务。 相反,如果有一个参与者节点未完成PreCommit的反馈或者反馈超时,那么协调者都会向所有的参与者节点发送abort请求,从而中断事务。
TCC事务模型
介绍
TCC;补偿事务,Try、Confirm、Cancel<br>
针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作
Try操作做业务检查及资源预留,Confirm做业务确认操作,Cancel实现一个与Try相反的操作既回滚操<br>作。TM首先发起所有的分支事务的try操作,任何一个分支事务的try操作执行失败,TM将会发起所有<br>分支事务的Cancel操作,若try操作全部成功,TM将会发起所有分支事务的Confirm操作,其中<br>Confirm/Cancel操作若执行失败,TM会进行重试
TCC模型对业务的侵入性较强,改造的难度较大,每个操作都需要有 try 、 confirm 、 cancel 三个接口实现<br>
TCC 中会添加事务日志,如果 Confirm 或者 Cancel 阶段出错,则会进行重试,所以这两个阶段需要支<br>持幂等;如果重试失败,则需要人工介入进行恢复和处理等。
分布式服务
RPC
远程过程调用<br>
RPC要求在调用方中放置被调用的方法的接口。调用方只要调用了这些接口,就相当于调用了被调用方的实际方法,十分易用。于是,调用方可以像调用内部接口一样调用远程的方法,而不用封装参数名和参数值等操作
内容
1. 动态代理,封装调用细节<br>2. 序列化与反序列化,数据传输与接收<br>3. 通信,可以选择七层的http,四层的tcp/udp<br>4. 异常处理等<br>
Zookeeper
初始化选举<br>
zxId:事务id,sId:节点id<br>先对比zxId,再对比sId,先投自己,选票内容(zxId,sId),遇强改投<br>投票箱:每个节点在本地维护自己和其他节点的投票信息,改投时需要更新信息,并广播
节点状态:
LOOKING,竞选状态。<br>FOLLOWING,随从状态,同步leader状态,参与投票。<br>OBSERVING,观察状态,同步leader状态,不参与投票。<br>LEADING,领导者状态<br>
初始化:没有历史数据,5个节点为例
节点1启动,此时只有一台服务器启动,它发出去的请求没有任何响应,所以它的选举状态一直是LOOKING状态<br>节点2启动,它与节点1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以serverId值较大的服务器2胜出,但是由于没有达到半数以上,所以服务器1,2还是继续保持LOOKING状态<br>节点3启动,与1、2节点通信交互数据,服务器3成为服务器1,2,3中的leader,此时有三台服务器选举了3,所以3成为leader<br>节点4启动,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能切换为follower<br>节点5启动,同4一样<br>
数据模型<br>
树形结构,具有一个固定的根节点(/),可以在根节点下创建子节点,并在子节点下继续创建下一级节点
类型
持久节点<br>
临时节点<br>
有序节点
watch机制实现原理
分布式锁<br>
步骤
上来直接创建一个锁节点下的一个接一个的临时顺序节点<br>如果自己不是第一个节点,就对自己上一个节点加监听器<br>只要上一个节点释放锁,自己就排到前面去了,相当于是一个排队机制。<br>
而且用临时顺序节点,如果某个客户端创建临时顺序节点之后,自己宕机了,zk感知到那个客户端宕机,会自动删除对应的临时顺序节点,相当于自动释放锁,或者是自动取消自己的排队。解决了惊群效应
应用场景
(1)数据发布/订阅:配置中心<br>(2)负载均衡:提供服务者列表<br>(3)命名服务:提供服务名到服务地址的映射<br>(4)分布式协调/通知:watch机制和临时节点,获取各节点的任务进度,通过修改节点发出通知<br>(5)集群管理:是否有机器退出和加入、选举 master<br>(7)分布式锁<br>(8)分布式队列<br>
数据同步原理
Dubbo
介绍<br>
Dubbo是阿里巴巴开源的基于 Java 的高性能 RPC 分布式服务框架,现已成为 Apache 基金会孵化项<br>目。致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。<br>
分层
Service,业务层,就是咱们开发的业务逻辑层。<br>Config,配置层,主要围绕 ServiceConfig 和 ReferenceConfig,初始化配置信息。<br>Proxy,代理层,服务提供者还是消费者都会生成一个代理类,使得服务接口透明化,代理层做远程调用和返回结果。<br>Register,注册层,封装了服务注册和发现。<br>Cluster,路由和集群容错层,负责选取具体调用的节点,处理特殊的调用要求和负责远程调用失败的容错措施。<br>Monitor,监控层,负责监控统计调用时间和次数。<br>Portocol,远程调用层,主要是封装 RPC 调用,主要负责管理 Invoker。<br>Exchange,信息交换层,用来封装请求响应模型,同步转异步。<br>Transport,网络传输层,抽象了网络传输的统一接口,Netty 、Mina 等。<br>Serialize,序列化层,将数据序列化成二进制流,以及反序列化。<br>
工作流程
1. Start: 启动Spring容器时,自动启动Dubbo的Provider<br>2. Register: Dubbo的Provider在启动后会去注册中心注册内容.注册的内容包括:IP、端口、接口列表(接口类、方法)、版本、Provider的协议.<br>3. Subscribe: 订阅.当Consumer启动时,自动去Registry获取到所已注册的服务的信息.<br>4. Notify: 通知.当Provider的信息发生变化时, 自动由Registry向Consumer推送通知.<br>5. Invoke: Consumer 调用Provider中方法,同步请求.消耗一定性能.但是必须是同步请求,因为需要接收调用方法后的结果<br>6. Count:次数,每隔2分钟,Provoider和Consumer自动向Monitor发送访问次数.Monitor进行统计.<br>
存储
分库分表<br>
介绍
将原本存储于单个数据库上的数据拆分到多个数据库,把原来存储在单张数据表的数据拆分到多张数据表中,实现数据切分,从而提升数据库操作性能。分库分表的实现可以分为两种方式:垂直切分和水平切分。
方式
水平:将数据分散到多张表,涉及分区键<br>
分库:每个库结构一样,数据不一样,没有交集。库多了可以缓解io和cpu压力<br>分表:每个表结构一样,数据不一样,没有交集。表数量减少可以提高sql执行效率、减轻cpu压力
垂直:将字段拆分为多张表,需要一定的重构
分库:每个库结构、数据都不一样,所有库的并集为全量数据<br>分表:每个表结构、数据不一样,至少有一列交集,用于关联数据,所有表的并集为全量数据<br>
主键<br>
UUID:简单、性能好,没有顺序,没有业务含义,存在泄漏mac地址的风险
数据库主键:实现简单,单调递增,具有一定的业务可读性,强依赖db、存在性能瓶颈,存在暴露业务信息的风险
redis,mongodb,zk等中间件:增加了系统的复杂度和稳定性
雪花算法
第一位符号位固定为0,41位时间戳,10位workId,12位序列号,位数可以有不同实现
优点
每个毫秒值包含的ID值很多,不够可以变动位数来增加,性能佳(依赖workId的实现)。<br>时间戳值在高位,中间是固定的机器码,自增的序列在低位,整个ID是趋势递增的。<br>能够根据业务场景数据库节点布置灵活调整bit位划分,灵活度高。<br>
缺点
强依赖于机器时钟,如果时钟回拨,会导致重复的ID生成,所以一般基于此的算法发现时钟回<br>拨,都会抛异常处理,阻止ID生成,这可能导致服务不可用。<br>
session的分布式方案<br>
采用无状态服务,抛弃session
存入cookie(有安全风险)<br>
服务器之间进行 Session 同步,这样可以保证每个服务器上都有全部的 Session 信息,不过当服务<br>器数量比较多的时候,同步是会有延迟甚至同步失败;<br>
IP 绑定策略<br>
使用 Nginx (或其他复杂均衡软硬件)中的 IP 绑定策略,同一个 IP 只能在指定的同一个机器访问,但<br>是这样做失去了负载均衡的意义,当挂掉一台服务器的时候,会影响一批用户的使用,风险很大;
使用 Redis 存储<br>
把 Session 放到 Redis 中存储,虽然架构上变得复杂,并且需要多访问一次 Redis ,但是这种方案带来<br>的好处也是很大的:
实现了 Session 共享;<br>可以水平扩展(增加 Redis 服务器);<br>服务器重启 Session 不丢失(不过也要注意 Session 在 Redis 中的刷新/失效机制);<br>不仅可以跨服务器 Session 共享,甚至可以跨平台(例如网页端和 APP 端)。
缓存
问题<br>
缓存雪崩<br>
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内<br>承受大量请求而崩掉。
解决方式
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。<br>给每一个缓存数据增加相应的缓存标记,记录缓存是否失效,如果缓存标记失效,则更新数据缓存。<br>缓存预热<br>互斥锁<br>
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同<br>时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪<br>崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查<br>数据库。
解决方式
设置热点数据永远不过期。<br>加互斥锁
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承<br>受大量请求而崩掉。
解决方式
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;<br>从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有<br>效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户<br>反复用同一个id暴力攻击<br>采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据<br>会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力<br>
解决方案
客户端缓存:页面和浏览器缓存,APP缓存,H5缓存,localStorage 和 sessionStorage<br>CDN缓存:内容存储:数据的缓存,内容分发:负载均衡<br>nginx缓存:静态资源<br>服务端缓存:本地缓存,外部缓存<br>数据库缓存:持久层缓存(mybatis,hibernate多级缓存),mysql查询缓存<br>操作系统缓存:Page Cache、Buffer Cache
数据库与缓存的一致性
介绍
由于缓存和数据库是分开的,无法做到原子性的同时进行数据修改,可能出现缓存更新失败,或者数据<br>库更新失败的情况,这时候会出现数据不一致,影响前端业务
解决方式
先更新数据库,再更新缓存。缓存可能更新失败,读到老数据<br>先删缓存,再更新数据库。并发时,读操作可能还是会将旧数据读回缓存<br>先更新数据库,再删缓存。也存在缓存删除失败的可能
最经典的缓存+数据库读写的模式,Cache Aside Pattern。<br>读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。<br>更新的时候,先更新数据库,然后再删除缓存。
延时双删:先删除缓存,再更新数据库,休眠1s、再次删除缓存。写数据的休眠时间则在读数据业务逻<br>辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成<br>的缓存脏数据,并发还是可能读到旧值覆盖缓存
终极方案
将访问操作串行化<br>
1. 先删缓存,将更新数据库的操作放进有序队列中<br>2. 从缓存查不到的查询操作,都进入有序队列
会面临的问题:<br>
1. 读请求积压,大量超时,导致数据库的压力:限流、熔断<br>2. 如何避免大量请求积压:将队列水平拆分,提高并行度。<br>3. 保证相同请求路由正确。
删除策略
定时过期<br>
惰性过期
定期过期<br>
分桶策略<br>
淘汰策略
FIFO(First In First Out,先进先出),根据缓存被存储的时间,离当前最远的数据优先被淘汰;<br>
LRU(Least Recently Used,最近最少使用),根据最近被使用的时间,离当前最远的数据优先被淘汰;
LFU(Least Frequently Used,最不经常使用),在一段时间内,缓存数据被使用次数最少的会被淘汰。
布隆过滤器原理<br>
位图:int[10],每个int类型的整数是4*8=32个bit,则int[10]一共有320 bit,每个bit非0即1,初始化<br>时都是0<br>
添加数据时,将数据进行hash得到hash值,对应到bit位,将该bit改为1,hash函数可以定义多个,则<br>一个数据添加会将多个(hash函数个数)bit改为1,多个hash函数的目的是减少hash碰撞的概率<br>查询数据:hash函数计算得到hash值,对应到bit中,如果有一个为0,则说明数据不在bit中,如果都<br>为1,则该数据可能在bit中
优点:
占用内存小<br>增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关<br>哈希函数相互之间没有关系,方便硬件并行运算<br>布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势<br>数据量很大时,布隆过滤器可以表示全集<br>使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点
误判率,即存在假阳性(False Position),不能准确判断元素是否在集合中<br>不能获取元素本身<br>一般情况下不能从布隆过滤器中删除元素
redis
持久化
RDB:Redis DataBase 将某一个时刻的内存快照(Snapshot),以二进制的方式写入磁盘。<br>
手动触发:<br>save命令,使 Redis 处于阻塞状态,直到 RDB 持久化完成,才会响应其他客户端发来的命令,所<br>以在生产环境一定要慎用<br>bgsave命令,fork出一个子进程执行持久化,主进程只在fork过程中有短暂的阻塞,子进程创建<br>之后,主进程就可以响应客户端请求了
自动触发:<br>save m n :在 m 秒内,如果有 n 个键发生改变,则自动触发持久化,通过bgsave执行,如果设<br>置多个、只要满足其一就会触发,配置文件有默认配置(可以注释掉)<br>flushall:用于清空redis所有的数据库,flushdb清空当前redis所在库数据(默认是0号数据库),会<br>清空RDB文件,同时也会生成dump.rdb、内容为空<br>主从同步:全量同步时会自动触发bgsave命令,生成rdb发送给从节点
优点:<br>
1、整个Redis数据库将只包含一个文件 dump.rdb,方便持久化。<br>2、容灾性好,方便备份。<br>3、性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单独子进<br>程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能<br>4.相对于数据集大时,比 AOF 的启动效率更高。
缺点<br>
1、数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢<br>失。所以这种方式更适合数据要求不严谨的时候)<br>2、由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导<br>致整个服务器停止服务几百毫秒,甚至是1秒钟。会占用cpu
AOF:Append Only File 以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记<br>录,以文本的方式记录,可以打开文件看到详细的操作记录,调操作系统命令进程刷盘<br>
1、所有的写命令会追加到 AOF 缓冲中。<br>2、AOF 缓冲区根据对应的策略向硬盘进行同步操作。<br>3、随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。<br>4、当 Redis 重启时,可以加载 AOF 文件进行数据恢复。<br>
同步策略:<br>每秒同步:异步完成,效率非常高,一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢<br>失<br>每修改同步:同步持久化,每次发生的数据变化都会被立即记录到磁盘中,最多丢一条<br>不同步:由操作系统控制,可能丢失较多数据
优点<br>
1、数据安全<br>图灵学院<br>2、通过 append 模式写文件,即使中途服务器宕机也不会破坏已经存在的内容,可以通过 redischeck-aof 工具解决数据一致性问题。<br>3、AOF 机制的 rewrite 模式。定期对AOF文件进行重写,以达到压缩的目的
缺点<br>
1、AOF 文件比 RDB 文件大,且恢复速度慢。<br>2、数据集大的时候,比 rdb 启动效率低。<br>3、运行效率没有RDB高
AOF文件比RDB更新频率高,优先使用AOF还原数据。<br>AOF比RDB更安全也更大<br>RDB性能比AOF好<br>如果两个都配了优先加载AOF<br>
单线程为什么这么快
Redis基于Reactor模式开发了网络事件处理器、文件事件处理器 file event handler。它是单线程的,<br>所以 Redis 才叫做单线程的模型,它采用IO多路复用机制来同时监听多个Socket,根据Socket上的事件<br>类型来选择对应的事件处理器来处理这个事件。可以实现高性能的网络通信模型,又可以跟内部其他单<br>线程的模块进行对接,保证了 Redis 内部的线程模型的简单性。<br>
文件事件处理器的结构包含4个部分:多个Socket、IO多路复用程序、文件事件分派器以及事件处理器<br>(命令请求处理器、命令回复处理器、连接应答处理器等)。
多个 Socket 可能并发的产生不同的事件,IO多路复用程序会监听多个 Socket,会将 Socket 放入一个<br>队列中排队,每次从队列中有序、同步取出一个 Socket 给事件分派器,事件分派器把 Socket 给对应的<br>事件处理器。<br>然后一个 Socket 的事件处理完之后,IO多路复用程序才会将队列中的下一个 Socket 给事件分派器。文<br>件事件分派器会根据每个 Socket 当前产生的事件,来选择对应的事件处理器来处理。<br>
1、Redis启动初始化时,将连接应答处理器跟AE_READABLE事件关联。<br>2、若一个客户端发起连接,会产生一个AE_READABLE事件,然后由连接应答处理器负责和客户端建立<br>连接,创建客户端对应的socket,同时将这个socket的AE_READABLE事件和命令请求处理器关联,使<br>得客户端可以向主服务器发送命令请求。<br>3、当客户端向Redis发请求时(不管读还是写请求),客户端socket都会产生一个AE_READABLE事<br>件,触发命令请求处理器。处理器读取客户端的命令内容, 然后传给相关程序执行。<br>图灵学院<br>4、当Redis服务器准备好给客户端的响应数据后,会将socket的AE_WRITABLE事件和命令回复处理器<br>关联,当客户端准备好读取响应数据时,会在socket产生一个AE_WRITABLE事件,由对应命令回复处<br>理器处理,即将准备好的响应数据写入socket,供客户端读取。<br>5、命令回复处理器全部写完到 socket 后,就会删除该socket的AE_WRITABLE事件和命令回复处理器<br>的映射。
总结
1)纯内存操作<br>2)核心是基于非阻塞的IO多路复用机制<br>3)单线程反而避免了多线程的频繁上下文切换带来的性能问题
高可用方案
主从<br>
哨兵模式:<br>
sentinel,哨兵是 redis 集群中非常重要的一个组件,主要有以下功能:<br>集群监控:负责监控 redis master 和 slave 进程是否正常工作。<br>消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。<br>故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。<br>配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。<br>故障转移时,判断一个 master node 是否宕机了,需要大部分的哨兵都同意才行,涉及到了分布<br>式选举<br>即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的<br>哨兵通常需要 3 个实例,来保证自己的健壮性。<br>哨兵 + redis 主从的部署架构,是不保证数据零丢失的,只能保证 redis 集群的高可用性。<br>对于哨兵 + redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演<br>练。
Cluster<br>
Redis Cluster是一种服务端Sharding技术,3.0版本开始正式提供。采用slot(槽)的概念,一共分成<br>16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行
通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了<br>16384 个槽位<br>每份数据分片会存储在多个互为主从的多节点上<br>图灵学院<br>数据写入先写主节点,再同步到从节点(支持配置为阻塞同步)<br>同一分片多个节点间的数据不保持强一致性<br>读取数据时,当客户端操作的key没有分配在该节点上时,<br>
在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加1w 的端<br>口号,比如 16379。<br>16379 端口号是用来进行节点间通信的,也就是 cluster bus 的通信,用来进行故障检测、配置更新、<br>故障转移授权。cluster bus 用了另外一种二进制的协议,gossip 协议,用于节点间进行高效的数据交<br>换,占用更少的网络带宽和处理时间。
优点
无中心架构,支持动态扩容,对业务透明<br>具备Sentinel的监控和自动Failover(故障转移)能力<br>客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可<br>高性能,客户端直连redis服务,免去了proxy代理的损耗<br>
缺点<br>
运维也很复杂,数据迁移需要人工干预<br>只能使用0号数据库<br>不支持批量操作(pipeline管道操作)<br>分布式逻辑和存储模块耦合等
Redis Sharding
Redis Sharding是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用<br>哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。Java<br>redis客户端驱动jedis,支持Redis Sharding功能,即ShardedJedis以及结合缓存池的<br>ShardedJedisPool
优点
优势在于非常简单,服务端的Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,<br>非常容易线性扩展,系统的灵活性很强
缺点
由于sharding处理放到客户端,规模进一步扩大时给运维带来挑战。<br>客户端sharding不支持动态增删节点。服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新<br>调整。连接不能共享,当应用规模增大时,资源浪费制约优化<br>
主从同步机制<br>
1、从节点执行slaveof masterIp port,保存主节点信息<br>图灵学院<br>2、从节点中的定时任务发现主节点信息,建立和主节点的socket连接<br>3、从节点发送信号,主节点返回,两边能互相通信<br>4、连接建立后,主节点将所有数据发送给从节点(数据同步)<br>5、主节点把当前的数据同步给从节点后,便完成了复制过程。接下来,主节点就会持续的把写命令发<br>送给从节点,保证主从数据一致性。
runId:每个redis节点启动都会生成唯一的uuid,每次redis重启后,runId都会发生变化。<br>offset:主从节点各自维护自己的复制偏移量offset,当主节点有写入命令时,offset=offset+命令的字<br>节长度。从节点在收到主节点发送的命令后,也会增加自己的offset,并把自己的offset发送给主节<br>点。主节点同时保存自己的offset和从节点的offset,通过对比offset来判断主从节点数据是否一致。<br>repl_backlog_size:保存在主节点上的一个固定长度的先进先出队列,默认大小是1MB。
全量复制:<br>
从节点发送psync命令,psync runid offset(由于是第一次,runid为?,offset为-1)<br>主节点返回FULLRESYNC runId offset,runId是主节点的runId,offset是主节点目前的offset。<br>从节点保存信息<br>主节点启动bgsave命令fork子进程进行RDB持久化<br>主节点将RDB文件发送给从节点,到从节点加载数据完成之前,写命令写入缓冲区<br>从节点清理本地数据并加载RDB,如果开启了AOF会重写AOF
部分复制<br>
1. 复制偏移量:psync runid offset<br>2. 复制积压缓冲区:当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执<br>行全量复制。<br>如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继<br>续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况);<br>如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并<br>不是当前的主节点,只能进行全量复制。
事务实现<br>
事务开始
MULTI命令的执行,标识着一个事务的开始。MULTI命令会将客户端状态的 flags 属性中打开<br>REDIS_MULTI 标识来完成的
命令入队
当一个客户端切换到事务状态之后,服务器会根据这个客户端发送来的命令来执行不同的操作。如果客<br>户端发送的命令为MULTI、EXEC、WATCH、DISCARD中的一个,立即执行这个命令,否则将命令放入一<br>个事务队列里面,然后向客户端返回 QUEUED 回复<br>
如果客户端发送的命令为 EXEC、DISCARD、WATCH、MULTI 四个命令的其中一个,那么服务器<br>立即执行这个命令。<br>如果客户端发送的是四个命令以外的其他命令,那么服务器并不立即执行这个命令。<br>首先检查此命令的格式是否正确,如果不正确,服务器会在客户端状态(redisClient)的 flags 属<br>性关闭 REDIS_MULTI 标识,并且返回错误信息给客户端。<br>如果正确,将这个命令放入一个事务队列里面,然后向客户端返回 QUEUED 回复
事务队列是按照FIFO的方式保存入队的命令<br>
事务执行<br>
客户端发送 EXEC 命令,服务器执行 EXEC 命令逻辑。
如果客户端状态的 flags 属性不包含 REDIS_MULTI 标识,或者包含 REDIS_DIRTY_CAS 或者<br>REDIS_DIRTY_EXEC 标识,那么就直接取消事务的执行。<br>否则客户端处于事务状态(flags 有 REDIS_MULTI 标识),服务器会遍历客户端的事务队列,然<br>后执行事务队列中的所有命令,最后将返回结果全部返回给客户端;<br>
redis 不支持事务回滚机制,但是它会检查每一个事务中的命令是否错误。<br>Redis 事务不支持检查那些程序员自己逻辑错误。例如对 String 类型的数据库键执行对 HashMap 类型<br>的操作!<br>
WATCH 命令是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。可以监控一个<br>或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC<br>命令。<br>MULTI命令用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送<br>任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有<br>队列中的命令才会被执行。<br>EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排<br>列。当操作被打断时,返回空值 nil 。<br>通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务, 并且客户端会从事务状态中退<br>出。<br>UNWATCH命令可以取消watch对所有key的监控。
数据结构
String:字符串<br>List:列表<br>Hash:哈希表<br>Set:无序集合<br>Sorted Set:有序集合<br>bitmap:布隆过滤器<br>GeoHash:坐标,借助Sorted Set实现,通过zset的score进行排序就可以得到坐标附近的其它元素,<br>通过将score还原成坐标值就可以得到元素的原始坐标<br>HyperLogLog:统计不重复数据,用于大数据基数统计<br>Streams:内存版的kafka<br>
数据库实现分布式锁的问题及解决方案
利用唯一约束键存储key,insert成功则代表获取锁成功,失败则获取失败,操作完成需要删除锁
问题:<br>
非阻塞,锁获取失败后没有排队机制,需要自己编码实现阻塞,可以使用自旋,直到获取锁<br>不可重入,如果加锁的方法需要递归,则第二次插入会失败,可以使用记录线程标识解决重入问题<br>死锁,删除锁失败、则其他线程没办法获取锁,可以设置超时时间、使用定时任务检查<br>数据库单点故障,数据库高可用
redis分布式锁实现<br>
setnx+setex:存在设置超时时间失败的情况,导致死锁<br>set(key,value,nx,px):将setnx+setex变成原子操作<br>
问题
任务超时,锁自动释放,导致并发问题。使用redisson解决(看门狗监听,自动续期)<br>以及加锁和释放锁不是同一个线程的问题。在value中存入uuid(线程唯一标识),删除锁时判断该<br>标识(使用lua保证原子操作)<br>不可重入,使用redisson解决(实现机制类似AQS,计数)<br>异步复制可能造成锁丢失,使用redLock解决<br>
解决
1. 顺序向五个节点请求加锁<br>2. 根据一定的超时时间来推断是不是跳过该节点<br>3. 三个节点加锁成功并且花费时间小于锁的有效期<br>4. 认定加锁成功
高可用
服务降级
降级是解决系统资源不足和海量业务请求之间的矛盾
服务熔断
熔断模式保护的是业务系统不被外部大流量或者下游系统的异常而拖垮。<br>
如何设计限流<br>
限流一般需要结合容量规划和压测来进行。当外部请求接近或者达到系统的最大阈值时,触发限流,采<br>取其他的手段进行降级,保护系统不被压垮。常见的降级策略包括延迟处理、拒绝服务、随机拒绝等。
方案
计数器法:<br>
1、将时间划分为固定的窗口大小,例如1s<br>2、在窗口时间段内,每来一个请求,对计数器加1。<br>3、当计数器达到设定限制后,该窗口时间内的之后的请求都被丢弃处理。<br>4、该窗口时间结束后,计数器清零,从新开始计数。
滑动窗口计数法:<br>
1. 将时间划分为细粒度的区间,每个区间维持一个计数器,每进入一个请求则将计数器加一。<br>2. 多个区间组成一个时间窗口,每流逝一个区间时间后,则抛弃最老的一个区间,纳入新区间。<br>3. 若当前窗口的区间计数器总和超过设定的限制数量,则本窗口内的后续请求都被丢弃。
漏桶算法:<br>
如果外部请求超出当前阈值,则会在容易里积蓄,一直到溢出,系统并不关心溢出的流量。<br>从出口处限制请求速率,并不存在计数器法的临界问题,请求曲线始终是平滑的。无法应对突发流量,<br>相当于一个空桶+固定处理线程
令牌桶算法<br>
假设一个大小恒定的桶,这个桶的容量和设定的阈值有关,桶里放着很多令牌,通过一个固定的速率,往里边放入令牌,如果桶满了,就把令牌丢掉,最后桶中可以保存的最大令牌数永远不会超过桶的大小。当有请求进入时,就尝试从桶里取走一个令牌,如果桶里是空的,那么这个请求就会被拒绝。
消息中间件
优缺点<br>
优点<br>
1、解耦,降低系统之间的依赖<br>2、异步处理,不需要同步等待<br>3、削峰填谷,将流量从高峰期引到低谷期进行处理
缺点<br>
1、增加了系统的复杂度,幂等、重复消费、消息丢失等问题的带入<br>2、系统可用性降低,mq的故障会影响系统可用<br>3、一致性,消费端可能失败
应用场景
日志采集、发布订阅等<br>
问题
如何保证消息不被重复消费<br>
幂等:一个数据或者一个请求,重复来多次,确保对应的数据是不会改变的,不能出错
思路
如果是写 redis,就没问题,反正每次都是 set ,天然幂等性<br>
生产者发送消息的时候带上一个全局唯一的id,消费者拿到消息后,先根据这个id去 redis里查一<br>下,之前有没消费过,没有消费过就处理,并且写入这个 id 到 redis,如果消费过了,则不处理。
基于数据库的唯一键
Kafka、ActiveMQ、RabbitMQ、RocketMQ 对比<br>
kafka:高性能,高可用,生产环境有大规模使用场景,单机容量有限(超过64个分区响应明显变<br>长)、社区更新慢、吞吐量单机百万<br>
rocketmq:java实现,方便二次开发、设计参考了kafka,高可用、高可靠,社区活跃度一般、支持语<br>言较少、吞吐量单机十万<br>
ActiveMQ:JMS规范,支持事务、支持XA协议,没有生产大规模支撑场景、官方维护越来越少
RabbitMQ:erlang语言开发、性能好、高并发,支持多种语言,社区、文档方面有优势,erlang语言<br>不利于java程序员二次开发,依赖开源社区的维护和升级,需要学习AMQP协议、学习成本相对较高<br>以上吞吐量单机都在万级
基础
面向对象
封装
继承
多态
集合
Map
线程安全
ConcurrentHashMap
初始容量默认为16段(Segment),使⽤分段锁设计
不对整个Map加锁,⽽是为每个Segment加锁
当多个对象存⼊同⼀个Segment时,才需要互斥
最理想状态为16个对象分别存⼊16个Segment,并⾏数量16
HashMap
TreeMap
List
线程安全的集合
CopyOnWriteArrayList<br>
写有锁,读⽆锁,读写之间不阻塞,优于读写锁
线程安全的ArrayList,加强版读写分离<br>
写⼊时,先copy⼀个容器副本、再添加新元素,最后替换引⽤
使用方式与ArrayList一样
写时复制
先从原有的数组中拷⻉⼀份出来,然后在新的数组做写操作,写完之后,<br>再将原来的数组引⽤指向到新数组<br>
LinkedArrayList
有序
ArrayList
查询快
底层
Set
线程安全
CopyOnWriteArraySet
HashSet
TreeSet
异常
Exception
Error
运算
位运算
逻辑运算
正常计算
IO基础
网络编程
注解
线程
概念
是操作系统能够进行运算调度的最小单位
线程调度
分时调度
所有线程轮流使⽤ CPU 的使⽤权,平均分配每个线程占⽤ CPU 的时间<br>
抢占式调度(JAVA使用)
优先让优先级⾼的线程使⽤ CPU,如果线程的优先级相同,那么会随机选择⼀个(线程随机性)
进程
概念
系统进行资源分配和调度的基本单位
区别
⼀个程序运⾏后⾄少有⼀个进程,⼀个进程中可以包含多个线程
分类
守护线程(后台线程)
setDaemon(true)
如果程序中所有前台线程都执⾏完毕了,后台线程会⾃动结束
垃圾回收器线程属于守护线程
用户线程(前台线程)<br>
并行和并发
并发
指两个或多个事件在同⼀个时间段内发⽣<br>
并行
指两个或多个事件在同⼀时刻发⽣(同时发⽣)
创建线程的方式
继承Thread
直接实例化使用
实现Runnab
直接使用,需借助Thread
实现Callable
有返回值
生命周期
新建状态(New)
实例化线程类,进入该状态
就绪状态(Runnable)<br>
通过线程的start()方法进入就绪状态
执行状态(Running)<br>
线程正在执行一些run()方法中的任务
阻塞状态(Blocked)
等待阻塞<br>
运行过程中调用了Wait()方法<br>
同步阻塞<br>
线程在获取synchronized同步锁失败
其他阻塞<br>
通过调⽤线程的sleep()或join()或发出了I/O请求
死亡状态(Dead)
线程常用的方法
join()
合并线程,当主线程需要用到子线程的结果,可以调用该方法,等子线程执行结束之后,继续主线程<br>
sleep()
执行该方法是指定多长时间之后继续执行后面的程序
yield()
该方法只是让线程从运行状态(Running)回到就绪状态(Runnable),<br>但线程可能会立马重新抢占资源执行<br>
优先级
设置setPriority()<br>
优先级⾼的线程会获得较多的运⾏机会。优先级 : 只能反<br>映 线程 的 中或者是 紧急程度 , 不能决定 是否⼀定先执⾏
线程优先级为1-10,默认为5,优先级越⾼
线程的安全问题
原因
多线程访问统一资源(共享资源、临界资源),产生数据不一致
解决方法<br>
同步代码块<br>
synchronized(对象){原子操作}
同步锁
锁可以是任意对象
多线程需要同一把锁
在任何时候,最多允许⼀个线程拥有同步锁,谁拿到锁就进⼊代码块,<br>其他的线程只能在外等着(BLOCKED)<br>
同步⽅法<br>
使⽤synchronized修饰的⽅法,就叫做同步⽅法,保证A线程执⾏该⽅法的时候,<br>其他线程只能在⽅法外等着<br>
锁机制<br>
Lock
JDK5加⼊
方法
lock()
获取锁<br>
tryLock()<br>
尝试获取锁,获取锁成功为True,否则False,不阻塞
unLock()
释放锁
线程的通信
多个线程并发执⾏时, 在默认情况下CPU是随机切换线程的,当我们需要多个线程来共同完成⼀件任<br>务,并且我们希望他们有规律的执⾏, 那么多线程之间需要⼀些协调通信,以此来帮我们达到多线程共<br>同操作⼀份数据<br>
等待唤醒机制<br>
这是多个线程间的⼀种协作机制
方法
wait()<br>
释放锁,进入等待状态
wait(Long time)
指定时间内进入等待,超过时间自动醒来<br>
notify()<br>
唤醒一个线程
notifyAll()<br>
唤醒所有线程
死锁
多个线程同时被阻塞,它们中的⼀个或者全部都在等待某个资源被释放
线程池
概念
其实就是⼀个容纳多个线程的容器
优点
降低资源消耗<br>
提⾼响应速度<br>
提⾼线程的可管理性<br>
使用
顶层接口
java.util.concurrent.Executor
java.util.concurrent.ExecutorService
java.util.concurrent.Executors
newFixedThreadPool 创建⼀个固定⻓度的线程池
newCachedThreadPool 创建⼀个可缓存的线程池
newScheduledThreadPool 定时线程池
newSingleThreadPoolExecutor 创建⼀个单线程的Executor,确保任务对了,串⾏执⾏
使用步骤
创建线程池对象
创建Runnable接⼝⼦类对象。(task)
提交Runnable接⼝⼦类对象。(take task)
关闭线程池(⼀般不做)
JDK新特性
8
Lambda表达式<br>
匿名内部类
()->{}
特性
函数式接口<br>
@FunctionalInterface注解
java.util.function
只有一个抽象方法
方法引用和构造器引用
Stream Api
常用方法
filter<br>
判断是真的返回为一个新的流
map
将一个集合转换为另外一个集合
distinct
去重<br>
limit<br>
截取保留指定的位置之内的数据,从1开始<br>
skip<br>
跳过指定的条数,从1开始
collect
收集对象
接口中的默认方法和静态方法<br>
新时间API
LocalDate
LocalDateTime
9&10
基本类型
<br>
并发编程
JMM模型<br>
Java内存模型(Java Memory Model简称JMM)是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JVM比较
不同之处
概念<br>
JMM描述的是一组规则,通过这组规则控制程序中各个变量在共享数据区域和私有数据区域的访问方式
JMM是围绕原子性,有序性、可见性展开
相同之处
共享数据区域和私有数据区域
联系
在JMM中主内存属于共享数据区域,从某个程度上讲应该包括了堆和方法区,而工作内存数据线程私有数据区域,<br>从某个程度上讲则应该包括程序计数器、虚拟机栈以及本地方法栈<br>
内存
主内存
主要存储的是Java实例对象,所有线程创建的实例对象都存放在主内存中,不管该实例<br>对象是成员变量还是方法中的本地变量(也称局部变量),当然也包括了共享的类信息、常<br>量、静态变量<br>
由于是共享数据区域,多条线程对同一个变量进行访问可能会发生线程安全问题
工作内存
主要存储当前方法的所有本地变量信息(工作内存中存储着主内存中的变量副本拷贝)
每个线程只能访问自己的工作内存
即线程中的本地变量对其它线程是不可见的,就算是两个线程执行的是同一段代码,<br>它们也会各自在自己的工作内存中创建属于当前线程的本地变量,<br>当然也包括了字节码行号指示器、相关Native方法的信息<br>
由于工作内存是每个线程的私有数据,线程间无法相互访问工作内存,<br>因此存储在工作内存的数据不存在线程安全问题<br>
数据同步八大原子操作
lock(锁定)
作用于主内存的变量,把一个变量标记为一条线程独占状态
unlock(解锁)
作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后<br>的变量才可以被其他线程锁定
read(读取)
作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存<br>中,以便随后的load动作使用
load(载入)
作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工<br>作内存的变量副本中
use(使用)
作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎
assign(赋值)
作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内<br>存的变量
store(存储)
作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存<br>中,以便随后的write的操作
write(写入)
作用于工作内存的变量,它把store操作从工作内存中的一个变量的值<br>传送到主内存的变量中
特性
原子性<br>
原子性指的是一个操作是不可中断的,即使是在多线程环境下,一个操作一旦开始就不会被其他线程影响<br>
基本数据类型都是安全的,long和double在32位虚拟机中存在不安全
可以通过 synchronized和Lock实现原子性。<br>因为synchronized和Lock能够保证任一时刻只有一个线程访问该代码块<br>
可见性
可见性指的是当一个线程修改了某个共享变量<br>的值,其他线程是否能够马上得知这个修改的值
volatile关键字保证可见性
有序性
有序性是指对于单线程的执行代码,我们总是认为代码的执行是按顺序依次执行的,这<br>样的理解并没有毛病,毕竟对于单线程而言确实如此,但对于多线程环境,则可能出现乱序<br>现象,因为程序编译成机器码指令后可能会出现指令重排现象,重排后的指令与原指令的顺<br>序未必一致
可以通过volatile关键字来保证一定的“有序性”
另外可以通过synchronized和Lock来保证有序性,很显然,<br>synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行<br>同步代码,自然就保证了有序性
指令重排序
java语言规范规定JVM线程内部维持顺序化语义。即只要程序的最终结果与它顺序化情况的结果相等,<br>那么指令的执行顺序可以与代码顺序不一致,此过程叫指令的重排序<br>
意义
JVM能根据处理器特性(CPU多级缓存系统、多核处理器等)适当的对机器指令进行重排序,<br>使机器指令能更符合CPU的执行特性,最大限度的发挥机器性能<br>
as-if-serial语义
不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。<br>编译器、runtime和处理器都必须遵守as-if-serial语义<br>
编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。<br>但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序<br>
happens-before 原则
关键字
volatile
volatile是Java虚拟机提供的轻量级的同步机制
作用
<div>保证被volatile修饰的共享变量对所有线程总数可见的,也就是当一个线程修改</div><div>了一个被volatile修饰共享变量的值,新值总是可以被其他线程立即得知</div>
禁止指令重排序优化
volatile无法保证原子性
内存屏障
内存屏障,又称内存栅栏,是一个CPU指令
作用
保证特定操作的执行顺序
保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)
Memory Barrier
如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,<br>也就是说通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化<br>
强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本
安全问题
所有的并发模式在解决线程安全问题时,采用的方案都是序列化访问临界资源。即在同一时刻,只能有一个线程访问临<br>界资源,也称作同步互斥访问<br>
synchronized<br>
内置锁是一种对象锁(锁的是对象而非引用),作用粒度是对象,可以用来实现对临界资源的同步互斥访问,是可重入的
加锁的方式<br>
同步实例方法,锁是当前实例对象
同步类方法,锁是当前类对象
同步代码块,锁是括号里面的对象
原理
基于JVM内置锁实现,通过内部对象Monitor(监视器锁)实现,基于进入与退出Monitor对象实现方法与代码<br>块同步,监视器锁的实现依赖底层操作系统的Mutex lock(互斥锁)实现,它是一个重量级锁性能较低
JVM内置锁在1.5之后版本做了重大的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)、适应性自旋(Adaptive Spinning)等技术来减少锁操作的开销
synchronized关键字被编译成字节码后会被翻译成monitorenter 和 monitorexit 两条指令<br>分别在同步块逻辑代码的起始位置与结束位置<br>
锁
可重入锁
可重入锁的字面意思是“可以重新进入的锁”,即允许同一个线程多次获取同一把锁
synchronized和ReentrantLock
悲观锁
乐观锁
线程池
工作流程<br>
判断核心线程池的线程是否都在执行任务
创建新的工作线程执行
判断阻塞队列是否已满
将新提交的任务存储在阻塞队列中
判断线程池的线程是否处于工作状态
创建新的工作线程执行任务
饱和策略(拒绝策略)处理
ThreadPoolExecutor
原理流程
判断当前的线程少于corePoolSize
创建新的工作线程来执行任务
执行此步需要获取全局锁
判断当前运行的线程大于或等于corePoolSize,而且BlockingQueue未满
添加到BlockingQueue中
如果BlockingQueue已满,而且当前运行的线程小于maximumPoolSize
创建新的工作线程来执行任务
执行这一步骤需要获取全局锁
果当前运行的线程大于或等于maximumPoolSize,任务将被拒绝
调用RejectExecutionHandler.rejectExecution()方法。即调用饱和策略对任务进行处理
工作线程(Worker)
线程池在创建线程时,会将线程封装成工作线程Woker
Woker在执行完任务后,不是立即销毁而是循环获取阻塞队列里的任务来执行
构造参数
new ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, <br>TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler)
7个核心参数
corePoolSize(线程池的基本大小)
提交一个任务到线程池时,线程池会创建一个新的线程来执行任务
即使有空闲的基本线程能执行该任务,也会创建新的线程
如果线程池中的线程数已经大于或等于corePoolSize,则不会创建新的线程
如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程
maximumPoolSize(线程池的最大数量)
阻塞队列已满,线程数小于maximumPoolSize便可以创建新的线程执行任务
如果使用无界的阻塞队列,该参数没有什么效果
workQueue(工作队列)
ArrayBlockingQueue
基于数组结构的有界阻塞队列,按FIFO(先进先出)原则对任务进行排序。使用该队列,线程池中能创建的最大线程数为maximumPoolSize
LinkedBlockingQueue
基于链表结构的无界阻塞队列,按FIFO(先进先出)原则对任务进行排序,吞吐量高于ArrayBlockingQueue。使用该队列,线程池中能创建的最大线程数为corePoolSize。静态工厂方法 Executor.newFixedThreadPool()使用了这个队列
SynchronousQueue
一个不存储元素的阻塞队列。添加任务的操作必须等到另一个线程的移除操作,否则添加操作一直处于阻塞状态。<br>静态工厂方法 Executor.newCachedThreadPool()使用了这个队列<br>
PriorityBlokingQueue
一个支持优先级的无界阻塞队列。使用该队列,线程池中能创建的最大线程数为corePoolSize
keepAliveTime(线程活动保持时间)
线程池的工作线程空闲后,保持存活的时间。如果任务多而且任务的执行时间比较短,可以调大keepAliveTime,提高线程的利用率
unit(线程活动保持时间的单位)
可选单位有DAYS、HOURS、MINUTES、毫秒、微秒、纳秒
handler(饱和策略,或者又称拒绝策略)
AbortPolicy
无法处理新任务时,直接抛出异常,这是默认策略
CallerRunsPolicy
用调用者所在的线程来执行任务
DiscardOldestPolicy
丢弃阻塞队列中最靠前的一个任务,并执行当前任务
DiscardPolicy
直接丢弃任务
threadFactory
构建线程的工厂类
常见线程池的创建参数
CachedThreadPool核心池为0,最大池为Integer.MAX_VALUE,相当于只使用了最大池;其他线程池,核心池与最大池一样大,因此相当于只用了核心池
FixedThredPool: new ThreadExcutor(n, n, 0L, ms, new LinkedBlockingQueue<Runable>() <br>SingleThreadExecutor: new ThreadExcutor(1, 1, 0L, ms, new LinkedBlockingQueue<Runable>()) <br>CachedTheadPool: new ThreadExcutor(0, max_valuem, 60L, s, new SynchronousQueue<Runnable>()); <br>ScheduledThreadPoolExcutor: ScheduledThreadPool, SingleThreadScheduledExecutor.
如果使用的阻塞队列为无界队列,则永远不会调用拒绝策略,因为再多的任务都可以放在队列中
SynchronousQueue是不存储任务的,新的任务要么立即被已有线程执行,要么创建新的线程执行
五种运行状态
running
该状态的线程池既能接受新提交的任务,又能处理阻塞队列中任务
shutdown
该状态的线程池不能接收新提交的任务,但是能处理阻塞队列中的任务
(政府服务大厅不在允许群众拿号了,处理完手头的和排队的政务就下班。)
处于running状态时,调用 shutdown()方法会使线程池进入到该状态
finalize() 方法在执行过程中也会隐式调用shutdown()方法
stop
该状态的线程池不接受新提交的任务,也不处理在阻塞队列中的任务,还会中断正在执行的任务
政府服务大厅不再进行服务了,拿号、排队、以及手头工作都停止了
在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态
tidying
如果所有的任务都已终止,workerCount (有效线程数)=0
<span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">线程池进入该状态后会调用 </span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">terminated() 钩子方法</code><span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">进入</span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">TERMINATED 状态</code>
terminated
在terminated()钩子方法执行完后进入该状态,默认terminated()钩子方法中什么也没有做
shutdown或者shutdownNow方法
可以通过调用线程池的shutdown或者shutdownNow方法来关闭线程池:遍历线程池中工作线程,逐个调用interrupt方法来中断线程
特点
shutdown方法将线程池的状态设置为SHUTDOWN状态,只会中断空闲的工作线程
<code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">shutdownNow方法</code><span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">将线程池的状态设置为</span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">STOP状态</code><span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">,</span><strong style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; font-family: PingFangSC-Light; font-size: 15px; color: black; box-sizing: border-box !important; overflow-wrap: break-word !important;">会中断所有工作线程</strong><span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">,不管工作线程是否空闲</span><br>
调用两者中任何一种方法,都会使isShutdown方法的返回值为true;线程池中所有的任务都关闭后,isTerminated方法的返回值为true
通常使用shutdown方法关闭线程池,如果不要求任务一定要执行完,则可以调用shutdownNow方法
调优(线程池的合理配置)
几个角度分析任务的特性
任务的性质
CPU 密集型任务、IO 密集型任务和混合型任务
可以通过 Runtime.getRuntime().availableProcessors() 方法获得当前设备的 CPU 个数
<strong style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; font-family: PingFangSC-Light; font-size: 15px; color: black; box-sizing: border-box !important; overflow-wrap: break-word !important;">CPU 密集型任务</strong><span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">配置</span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">尽可能小的线程</code><span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">,如配置 N c p u + 1 N_{cpu}+1_N</span><strong style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; font-family: PingFangSC-Light; font-size: 15px; color: black; box-sizing: border-box !important; overflow-wrap: break-word !important;">c</strong><span style="color: rgb(1, 1, 1); font-family: PingFangSC-Light; font-size: 15px;">p**u_+1 个线程的线程池</span>
IO 密集型任务则由于线程并不是一直在执行任务,则配置尽可能多的线程,如2 ∗ N c p u 2_N_{cpu}2∗_Ncp**u*
混合型任务,如果可以拆分,则将其拆分成一个 CPU 密集型任务和一个 IO 密集型任务。只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率;如果这两个任务执行时间相差太大,则没必要进行分解
任务的优先级
高、中、低
可以使用优先级队列 PriorityBlockingQueue 来处理,它可以让优先级高的任务先得到执行。但是,如果一直有高优先级的任务加入到阻塞队列中,那么低优先级的任务可能永远不能执行
任务的执行时间
长、中、短
可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行
任务的依赖性
是否依赖其他系统资源,如数据库连接。
依赖数据库连接池的任务,因为线程提交 SQL 后需要等待数据库返回结果,线程数应该设置得较大,这样才能更好的利用 CPU
<strong style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; color: rgb(0, 0, 0); font-family: PingFangSC-Light; font-size: 15px; letter-spacing: 3px; word-spacing: 1.5px; box-sizing: border-box !important; overflow-wrap: break-word !important;">建议使用有界队列</strong><span style="color: rgb(0, 0, 0); font-family: PingFangSC-Light; font-size: 15px; letter-spacing: 3px; word-spacing: 1.5px;">,有界队列能</span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; letter-spacing: 3px; word-spacing: 1.5px; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">增加系统的稳定性和预警能力</code><span style="color: rgb(0, 0, 0); font-family: PingFangSC-Light; font-size: 15px; letter-spacing: 3px; word-spacing: 1.5px;">。可以根据需要设大一点,比如几千。</span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; letter-spacing: 3px; word-spacing: 1.5px; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">使用无界队列</code><span style="color: rgb(0, 0, 0); font-family: PingFangSC-Light; font-size: 15px; letter-spacing: 3px; word-spacing: 1.5px;">,线程池的队列就会越来越大,</span><strong style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; color: rgb(0, 0, 0); font-family: PingFangSC-Light; font-size: 15px; letter-spacing: 3px; word-spacing: 1.5px; box-sizing: border-box !important; overflow-wrap: break-word !important;">有可能会撑满内存,导致整个系统不可用</strong>
解决方案
任务性质不同的任务可以用不同规模的线程池分开处理
监控
taskCount
线程池需要执行的任务数量,包括已经执行完的、未执行的和正在执行的
<span style="color: rgb(30, 107, 184); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; font-size: 14px; letter-spacing: 3px; word-spacing: 1.5px; background-color: rgba(27, 31, 35, 0.05);">completedTaskCount</span>
线程池在运行过程中已完成的任务数量,completedTaskCount <= taskCount
largestPoolSize
线程池曾经创建过的最大线程数量,通过这个数据可以知道线程池是否满过。如等于线程池的最大大小,则表示线程池曾经满了
getPoolSize
线程池的线程数量。如果线程池不销毁的话,池里的线程不会自动销毁,所以线程池的线程数量只增不减
getActiveCount
获取活动的线程数
通过继承线程池并重写线程池的 beforeExecute,afterExecute 和 terminated 方法,我们可以在任务执行前,执行后和线程池关闭前干一些事情
如监控任务的平均执行时间,最大执行时间和最小执行时间等。这几个方法在线程池里是空方法
protected void beforeExecute(Thread t, Runnable r) { }
常见问题
基础
以ThreadPoolExecutor为切入点,讲解excute()方法中所体现的Java线程池运行流程
工作线程Worker,它的循环工作特点
如何新建线程池:7个参数(重点在阻塞队列和饱和策略)
<strong style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; font-family: PingFangSC-Light; font-size: 15px; color: black; box-sizing: border-box !important; overflow-wrap: break-word !important;">进阶</strong>
线程池五个状态的特点以及如何进行状态之间的切换:running、shutdown、stop、tidying、terminated
如何关闭线程:shutdown方法和shutdownNow方法的特点
线程池的调优(针对任务的不同特性 + 建议使用有界队列)
<span style="color: rgb(0, 0, 0); font-family: PingFangSC-Light; font-size: 15px; letter-spacing: 3px; word-spacing: 1.5px;">线程池的</span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; letter-spacing: 3px; word-spacing: 1.5px; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">监控参数</code><span style="color: rgb(0, 0, 0); font-family: PingFangSC-Light; font-size: 15px; letter-spacing: 3px; word-spacing: 1.5px;">以及</span><code style="margin: 0px 2px; padding: 2px 4px; outline: 0px; max-width: 100%; letter-spacing: 3px; word-spacing: 1.5px; font-size: 14px; border-radius: 4px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all; box-sizing: border-box !important; overflow-wrap: break-word !important;">可以重写的方法</code>
扩展
两种主要的线程池类型:普通的线程池ThreadPoolExecutor,支持延迟或周期性执行的任务的线程池ScheduledThreadPoolExcutor
讲解ThreadPoolExcutor中5个常用参数+2个不常用参数,包含的三种线程池:创建时的参数、运行的流程、各自适合的场景
讲解ScheduledThreadPoolExecutor的阻塞队列的原理、如何更改任务的time
提供了五种定义好的线程池,都可以通过Executors工具类去调用,比如Executors.newFixedThreadPool(12)
具体的场景,如果corePoolSize为x,maximumPoolSize为y,阻塞队列为z,第w个任务进来如何分配?
线程池中的核心参数,超过核心size怎么处理,队列满怎么处理,拒绝策略有哪些?(比较具体)
线程池如何进行调优?
线程池的调优(针对任务的不同特性 + 建议使用有界队列)
JVM
介绍
内存划分
JDK7之前
JDK8之后
方法区
用于存储已被虚拟机加载的类信息、常量、静态变<br>量、即时编译后的代码等数据
本地方法栈
与虚拟机栈的作用是一样的,只不过虚<br>拟机栈是服务 Java 方法的,而本地方法栈是为虚拟机调用 Native 方法服务的
堆
Java 虚拟机中内存最大的一块,是被所有线程共享<br>的,几乎所有的对象实例都在这里分配内存
虚拟机栈
用于存储局部变量表、操作数栈、动态链接、方法出口等信息<br>
程序计数器
当前线程所执行的字节码的行号<br>指示器,字节码解析器的工作是通过改变这个计数器的值,来选取下一条需要执行的<br>字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能,都需要依赖这个<br>计数器来完成
底层
常见问题
逃逸分析
原理
分析对象动态作用域,当一个对象在方法中定义后,它可能被外部方法所引用<br>
分析
如果是逃逸分析出来的对象可以在栈上分配的话,那么该对象的生命周期就跟随线程了,就不需要垃圾回收,<br>如果是频繁的调用此方法则可以得到很大的性能提高。<br>采用了逃逸分析后,满足逃逸的对象在栈上分配<br>没有开启逃逸分析,对象都在堆上分配,会频繁触发垃圾回收(垃圾回收会影响系统性能),导致代码运行慢
命令
-XX:+DoEscapeAnalysis开启逃逸分析(jdk1.8默认开启)<br>-XX:-DoEscapeAnalysis 关闭逃逸分析
-XX:+EliminateAllocations开启标量替换(jdk1.8默认开启)<br>-XX:-EliminateAllocations 关闭标量替换
解决
标量替换
逃逸分析证明一个对象不会被外部访问,如果这个对象可以被拆分的话,当程序真正执行的时<br>候可能不创建这个对象,而直接创建它的成员变量来代替。将对象拆分后,可以分配对象的成<br>员变量在栈或寄存器上,原本的对象就无需分配内存空间了。这种编译优化就叫做标量替换<br>(前提是需要开启逃逸分析)<br>
垃圾回收机制
垃圾回收算法
标记-清除<br>
标记无用对象,然后进行清除回收。缺点:效率不高,无法清<br>除垃圾碎片
复制算法<br>
按照容量划分二个大小相等的内存区域,当一块用完的时候将活着的<br>对象复制到另一块上,然后再把已使用的内存空间一次清理掉。缺点:内存使用率不<br>高,只有原来的一半
标记-整理算法<br>
标记无用对象,让所有存活的对象都向一端移动,然后直接清<br>除掉端边界以外的内存。
分代算法<br>
根据对象存活周期的不同将内存划分为几块,一般是新生代和老年<br>代,新生代基本采用复制算法,老年代采用标记整理算法
如何认定是垃圾
可达性分析算法
作为GC Roots的对象主要包括下面4种<br>虚拟机栈(栈帧中的本地变量表):各个线程调用方法堆栈中使用到的参数、局部变量、临时变量等。<br>方法区中类静态变量:java类的引用类型静态变量。<br>方法区中常量:比如:字符串常量池里的引用。<br>本地方法栈中JNI指针:(即一般说的Native方法)。
引用计数法
给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加1;当引用失效,计数器就减1;任何时候计数器为0<br>的对象就是不可能再被使用的。<br>
垃圾回收器
新生代
Serial收集器(-XX:+UseSerialGC -XX:+UseSerialOldGC)
Parallel Scavenge收集器(-XX:+UseParallelGC(年轻代),-XX:+UseParallelOldGC(老年代))
ParNew收集器(-XX:+UseParNewGC)
老年代
Serial Old收集器是Serial收集器的老年代版本<br>
Parallel Old收集器是Parallel Scavenge收集器的老年代版本
使用多线程和“标记-整理”算法。在注重吞吐量以及<br>CPU资源的场合,都可以优先考虑 Parallel Scavenge收集器和Parallel Old收集器(JDK8默认的新生代和老年代收集<br>器)
CMS收集器(-XX:+UseConcMarkSweepGC(old))<br>
底层实现
三色标记<br>
黑色:表示对象已经被垃圾收集器访问过, 且这个对象的所有引用都已经扫描过。 黑色的对象代表已经扫描<br>过, 它是安全存活的, 如果有其他对象引用指向了黑色对象, 无须重新扫描一遍。 黑色对象不可能直接(不经过<br>灰色对象) 指向某个白色对象。
灰色:表示对象已经被垃圾收集器访问过, 但这个对象上至少存在一个引用还没有被扫描过<br>
白色:表示对象尚未被垃圾收集器访问过。 显然在可达性分析刚刚开始的阶段, 所有的对象都是白色的, 若<br>在分析结束的阶段, 仍然是白色的对象, 即代表不可达。<br>
种类
Serial收集器(复制算法)
新生代单线程收集器,标记和清理都是单线程,优点<br>是简单高效;
ParNew收集器 (复制算法)<br>
新生代收并行集器,实际上是Serial收集器的多线程<br>版本,在多核CPU环境下有着比Serial更好的表现;
Parallel Scavenge收集器 (复制算法)<br>
新生代并行收集器,追求高吞吐量,高效<br>利用 CPU。吞吐量 = 用户线程时间/(用户线程时间+GC线程时间),高吞吐量可以高<br>效率的利用CPU时间,尽快完成程序的运算任务,适合后台应用等对交互相应要求不<br>高的场景;
Serial Old收集器 (标记-整理算法)<br>
老年代单线程收集器,Serial收集器的老年<br>代版本;
Parallel Old收集器 (标记-整理算法)<br>
老年代并行收集器,吞吐量优先,<br>Parallel Scavenge收集器的老年代版本;
CMS(Concurrent Mark Sweep)收集器(标记-清除算法)<br>
老年代并行收集<br>器,以获取最短回收停顿时间为目标的收集器,具有高并发、低停顿的特点,追求最<br>短GC回收停顿时间
G1(Garbage First)收集器 (标记-整理算法)<br>
Java堆并行收集器,G1收集器是<br>JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会<br>产生内存碎片。此外,G1收集器不同于之前的收集器的一个重要特点是:G1回收的<br>范围是整个Java堆(包括新生代,老年代),而前六种收集器回收的范围仅限于新生代<br>或老年代。
ZGC
是JDK 11中推出的一款追求极致低延迟的垃圾收集器,
特点
停顿时间不超过10ms(JDK16已经达到不超过1ms);<br>停顿时间不会随着堆的大小,或者活跃对象的大小而增加;<br>支持8MB~4TB级别的堆,JDK15后已经可以支持16TB。
ZGC中没有分代的概念(新生代、老年代)<br>ZGC支持3种页面,分别为小页面、中页面和大页面。<br>其中小页面指的是2MB的页面空间,中页面指32MB的页面空间,大页面指受操作系统控制的大页。
概念
指针着色技术(Color Pointers)
流程
标记阶段(标识垃圾)<br>
转移阶段(对象复制或移动)
常用命令
Jmap<br>
此命令可以用来查看内存信息,实例个数以及占用内存大小
jmap -histo pid
jmap -haed pid<br>
jmap -dump:format=b,file=files.hprof pid<br>
jstack<br>
找死锁
jstack top -p
jinfo
jstat
垃圾回收统计
jstat -gc pid
Arthas
Arthas 是 Alibaba 在 2018 年 9 月开源的 Java 诊断工具。支持 JDK6+, 采用命令行交互模式,可以方便的定位和诊断<br>线上程序运行问题<br>
结合gceasy使用
日志体系
起源
logUtil
起初简单的日志工具类
功能
日志按时间打包处理<br>
日志等级<br>
根据等级高效查看筛选日志<br>
异步追踪<br>
开日志线程,不影响主业务执行时间
日志追踪
出现错误信息可以给指定用户告知错误
常见的日志框架
log4j
Apache的一个开源项目
jul
官方看不惯第三方的日志框架,自己开发了一套日志体系
java.util.logging<br>
log4j2
apache开发升级了log4j<br>
logback
与log4j,Slf4j是同一个作者
门面日志框架
Jcl
jakarta Commons Logging<br>
如果能找到Log4j 则默认使用log4j 实现,如果没有则使用jul(jdk自带的) 实现,再没有则使用jcl内部提供的<br>SimpleLog 实现。
动态加载日志框架的顺序
子主题<br>
commonslogging.properties> 系 统 环 境 变 量 >log4j>jul>simplelog>nooplog
Slf4j
发现jcl不好用,独自开发该门面日志框架
不实现具体的日志功能,适配市面上日志框架
适配器
桥接器<br>
整合主流框架
主流开源框架
SSM
Spring
AOP
解释
应用场景
IOC
DI
解释
事务
特性
事务传播机制7种
源码分析
内容
Bean的生命周期
依赖注入
注入方式
手动
XML
Set方法输入
构造方法注入
自动
XML的autowire自动注入
@Autowired注解的自动注入
注入点
确定Bean
循环依赖
三级缓存
推断构造方法
Spring的启动流程理解
配置类理解
整合Mybatis
AOP
事务
概念
BeanDefinition
BeanDefinitionReader
AnnotatedBeanDefinitionReader
@Conditional,@Scope、@Lazy、@Primary、@DependsOn、<br>@Role、@Description
XmlBeanDefinitionReader
解析<bean/>标签
ClassPathBeanDefinitionScanner
ClassPathBeanDefinitionScanner是扫描器,但是它的作用和BeanDefinitionReader类似,它可以<br>进行扫描,扫描某个包路径,对扫描到的类进行解析,比如,扫描到的类上如果存在@Component<br>注解,那么就会把这个类解析为一个BeanDefinition
BeanFactory
BeanFactory表示Bean工厂,所以很明显,BeanFactory会负责创建Bean,并且提供获取Bean的API。
DefaultListableBeanFactory
ApplicationContext
AnnotationConfigApplicationContext
ClassPathXmlApplicationContext
BeanPostProcessor
BeanPostProcess表示Bena的后置处理器,我们可以定义一个或多个BeanPostProcessor
BeanFactoryPostProcessor
FactoryBean
国际化
资源加载
获取运行时环境
事件发布
类型转化
ConversionService
PropertyEditor
JDK
TypeConverter
OrderComparator
OrderComparator是Spring所提供的一种比较器,可以用来根据@Order注解或实现Ordered接口<br>来执行值进行笔记,从而可以进行排序
AnnotationAwareOrderComparator
ExcludeFilter和IncludeFilter
MetadataReader、ClassMetadata、AnnotationMetadata
工作流程
SpringMVC
介绍
官网
配置
注解
xml
文件上传
国际化
请求流程
拦截器和过滤器
servlet
源码分析
请求流程源码
父子容器启动原理
Mybatis
缓存
别名
xml
plus
分页
源码分析
体系介绍
配置文件解析
SQL执操作执行流程
Springboot
官网
自动配置原理
整合SSM
基本配置介绍
微服务
SpringCloud
服务注册与发现
Eurka
zookeeper<br>
配置中心
config
服务调用
feign
介绍
Feign是Netflix开发的声明式、模板化的HTTP客户端,Feign可帮助我们更加便捷、优雅地<br>调用HTTP API<br>
优势
它像 Dubbo 一样,consumer 直接调用接口方法调用 provider,而不需要通过常规的 Http Client 构造请求再解析返回数据。它<br>解决了让开发者调用远程接口就跟调用本地方法一样,无需关注与远程的交互细节,更无需关注分布式环境开发
Spring Cloud openfeign对Feign进行了增强,使其支持Spring MVC注解,另外还整合<br>了Ribbon和Eureka,从而使得Feign的使用更加方便
扩展
日志配置
四种
NONE【性能最佳,适用于生产】:不记录任何日志(默认值)<br>
BASIC【适用于生产环境追踪问题】:仅记录请求方法、URL、响应状态代码以及执行时间。
HEADERS:记录BASIC级别的基础上,记录请求和响应的header。
FULL【比较适用于开发及测试环境定位问题】:记录请求和响应的header、body和元数据。
通过拦截器实现参数传递
feign.RequestInterceptor
应用场景
1. 统一添加 header 信息;<br>2. 对 body 中的信息做修改或替换;
超时时间配置
客户端组件配置
GZIP 压缩配置
dubbo
链路
skywaking
网关
gateway
zuul
服务治理限流熔断
hyst
springcloud Alibaba
服务注册与发现(Nacos)
网关(gateway)
配置中心(Nacos)
服务调用
负载均衡(Ribbon)
feign
dubbo
分布式事务
seata
熔断限流
sentienl
关系型数据库
mysql
介绍
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于<br>Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应<br>用方面,MySQL是最好的 RDBMS (Relational Database Management<br>System,关系数据库管理系统) 应用软件之一。在Java企业级开发中非常常<br>用,因为 MySQL 是开源免费的,并且方便扩展。
三大范式
第一范式:每个列都不可以再拆分。<br>第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主<br>键的一部分。<br>第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。<br>
权限表
user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。<br>db权限表:记录各个帐号在各个数据库上的操作权限。<br>table_priv权限表:记录数据表级的操作权限。<br>columns_priv权限表:记录数据列级的操作权限。<br>host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。<br>这个权限表不受GRANT和REVOKE语句的影响。<br>
搜索引擎
MylSAM<br>
MyIASM引擎(原本Mysql的默认引擎):不提供事务的支持,也不支持行级锁<br>和外键。
InnoDB<br>
nnodb引擎提供了对数据库ACID事务的支持。并且还提供了<br>行级锁和外键的约束。它的设计的目标就是处理大数据容量的数据库系统。
4大特性
插入缓冲(insert buffer)<br>二次写(double write)<br>自适应哈希索引(ahi)<br>预读(read ahead)<br>
MEMORY
所有的数据都在内存中,数据的处理速度快,但是安全性不高<br>
MylSAM与InnoDB区别
InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。<br>InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。<br>MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。<br>InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询<br>时做到覆盖索引会非常高效。<br>
查询语句执行过程
优化
索引
介绍
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它<br>们包含着对数据表里所有记录的引用指针。<br>索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,<br>以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种<br>B+树。
优缺点
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。<br>通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。<br>索引的缺点<br>时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增<br>加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;<br>空间方面:索引需要占物理空间。
类型
主键索引
唯一索引
普通索引
全文索引
数据结构
B+树
BTree是最常用的mysql数据库索引算法,也是mysql默认的算法。因为它不仅<br>可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操<br>作符,只要它的查询条件是一个不以通配符开头的常量<br>
Hash<br>
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一<br>次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这<br>样多次IO访问,所以检索效率远高于BTree索引
设计原则
1. 适合索引的列是出现在where子句中的列,或者连接子句中指定的列<br>2. 基数较小的类,索引效果较差,没有必要在此列建立索引<br>3. 使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这<br>样能够节省大量索引空间<br>4. 不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修<br>改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会<br>越长。所以只保持需要的索引有利于查询即可。<br>
创建索引原则
1) 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到<br>遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and<br>c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立<br>(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。<br>2)较频繁作为查询条件的字段才去创建索引<br>3)更新频繁字段不适合创建索引<br>4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三<br>种,区分度实在太低)<br>5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)<br>的索引,那么只需要修改原来的索引即可。<br>6)定义有外键的数据列一定要建立索引。<br>7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。<br>8)对于定义为text、image和bit的数据类型的列不要建立索引。<br>
注意
非空字段:应该指定列为NOT NULL,除非你想存储NULL。在mysql中,含有<br>空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加<br>复杂。你应该用0、一个特殊的值或者一个空串代替空值;<br>取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前<br>面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字<br>段的离散程度高;<br>索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操<br>作获取的数据越大效率越高。<br>
日志
binlog
有几种格式录入
有三种格式,statement,row和mixed
statement模式下,每一条会修改数据的sql都会记录在binlog中。不需要记录<br>每一行的变化,减少了binlog日志量,节约了IO,提高性能。由于sql的执行是有上<br>下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语<br>句无法被记录复制。<br>
row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。记录单<br>元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动<br>(比如alter table),因此这种模式的文件保存的信息太多,日志量太大。<br>
mixed,一种折中的方案,普通操作使用statement记录,当无法使用<br>statement的时候使用row。<br>
事务
ACID
隔离级别
锁
锁粒度<br>
表级锁
行级锁
InnoDB是根据ID索引来完成的
页级锁
分类
共享锁
读锁
排他锁
写锁<br>
常见问题
百万级别或以上的数据如何删除
由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所<br>以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需<br>要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级<br>别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是<br>成正比的。<br>
1. 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分<br>多钟)<br>2. 然后删除其中无用数据(此过程需要不到两分钟)<br>3. 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分<br>钟左右。<br>4. 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会<br>回滚。那更是坑了。<br>
oracle
用户/权限
版本介绍
结构了解
常用查询函数
SQL server
Nginx
介绍
作者
俄罗斯
伊戈尔·赛索耶夫
第一个公开版本0.1.0发布于2004年10月4日
开发语言
c语言
特点
轻量级,占有内存少,并发能力强
官网
中文
https://www.nginx.cn/doc/
英文
http://nginx.org/
应用场景
http 服务器<br>
虚拟主机。可以实现在一台服务器虚拟出多个网站<br>
反向代理,负载均衡,限流
安装
linux
yum install -y pcre-devel openssl-devel gcc curl<br>
wget https://openresty.org/download/openresty-1.17.8.2.tar.gz<br>
tar -zxvf openresty-1.17.8.2.tar.gz
目录在:/usr/local/nginx<br>
./configure
make && make install
window
官网下载ZIP解压皆可使用
配置介绍
#设置用户的权限 root nobody 指定 用户名虚拟机内用户 或者 Ip访问 <br>user nobody;<br>
#设置工作进程数 一般为 Cpu 核心*2 4*2 <br>worker_processes 8;
# 日志输出参数 <br>error_log logs/error.log;<br>
# 进程ID <br>pid logs/nginx.pid;
events {<br>#指定运行模型 <br> use epoll;<br># 工作连接数 默认512 根据自己的情况调整 <br> worker_connections 1024;<br>}
http{}
功能使用
代理
正向代理
正向代理代理客户端
反向代理
反向代理代理服务器
动静分离
负载均衡
限流熔断
高级进阶
用户认证管理
主备切换
调优
Netty
介绍
网络编程
BIO
NIO
AIO
优势
1、API 使用简单,开发门槛低;<br>2、功能强大,预置了多种编解码功能,支持多种主流协议;<br>3、定制能力强,可以通过 ChannelHandler 对通信框架进行灵活地扩展;<br>4、性能高,通过与其他业界主流的 NIO 框架对比,Netty 的综合性能最优;<br>5、成熟、稳定,Netty 修复了已经发现的所有 JDK NIO BUG,业务开发人员不需要再为<br>NIO 的 BUG 而烦恼;<br>6、社区活跃,版本迭代周期短,发现的 BUG 可以被及时修复,同时,更多的新功能会加入;<br>7、经历了大规模的商业应用考验,质量得到验证。<br>
Netty 使用 NIO 而不是 AIO
Netty 不看重 Windows 上的使用,在 Linux 系统上,AIO 的底层实现仍使用 EPOLL,没有<br>很好实现 AIO,因此在性能上没有明显的优势,而且被 JDK 封装了一层不容易深度优化。
AIO 还有个缺点是接收数据需要预先分配缓存, 而不是 NIO 那种需要接收时才需要分配<br>缓存, 所以对连接数量非常大但流量小的情况, 内存浪费很多。
而且 Linux 上 AIO 不够成熟,处理回调结果速度跟不上处理需求<br>
为什么不用 Mina
Mina不在更新,Netty 本来就是因为 Mina 不够好所以开发出来的<br>
入门
基本概念<br>
Bootstrap、EventLoop(Group) 、Channel<br>
Bootstrap 是 Netty 框架的启动类和主入口类,分为客户端类 Bootstrap 和服务器类<br>ServerBootstrap 两种。
Channel 是 Java NIO 的一个基本构造<br>
它代表一个到实体(如一个硬件设备、一个文件、一个网络套接字或者一个能够执行一<br>个或者多个不同的 I/O 操作的程序组件)的开放连接,如读操作和写操作<br>
目前,可以把 Channel 看作是传入(入站)或者传出(出站)数据的载体。因此,它<br>可以被打开或者被关闭,连接或者断开连接。<br>
EventLoop 暂时可以看成一个线程、EventLoopGroup 自然就可以看成线程组
事件和 ChannelHandler、ChannelPipeline<br>
<div><font color="#efeceb"><span style="font-size: 10.56pt; font-family: Calibri;">Netty </span><span style="font-size: 10.56pt; font-family: 宋体;">使用不同的事件来通知我们状态的改变或者是操作的状态。这使得我们能够基于<br></span></font></div><div><span style="font-size: 10.56pt; font-family: 宋体;"><font color="#efeceb">已经发生的事件来触发适当的动作。</font></span></div>
Netty 事件是按照它们与入站或出站数据流的相关性进行分类的。
ChannelFuture
Netty 中所有的 I/O 操作都是异步的,我们知道“异步的意思就是不需要主动等待结果的返回,而是通过其他手段比如,状态通知,回调函数等”,那就是说至少我们需要一种获得异步执行结果的手段。
进阶
Netty高并发高性能架构设计精髓
主从Reactor线程模型<br>NIO多路复用非阻塞<br>无锁串行化设计思想<br>支持高性能序列化协议<br>零拷贝(直接内存的使用)<br>ByteBuf内存池设计<br>灵活的TCP参数配置能力<br>并发优化
实战
设计精髓
主从Reactor线程模型<br>NIO多路复用非阻塞<br>支持高性能序列化协议<br>并发优化<br>
无锁串行化设计思想
对于锁竞争带来的资源浪费的问题,通过串行化设计,尽可能在一个线程里面完成,串行化设计似乎CPU利用率不高,并发程度不够。<br>但是,通过调整NIO线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优<br>
直接内存<br>
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,某些情况下这部分内存也<br>会被频繁地使用,而且也可能导致OutOfMemoryError异常出现。Java里用DirectByteBuffer可以分配一块直接内存(堆外内存),元空间<br>对应的内存也叫作直接内存,它们对应的都是机器的物理内存。
优缺点
不占用堆内存空间,减少了发生GC的可能<br>
java虚拟机实现上,本地IO会直接操作直接内存(直接内存=>系统调用=>硬盘/网卡),而非直接内存则需要二次拷贝(堆内<br>存=>直接内存=>系统调用=>硬盘/网卡)
初始分配较慢<br>
没有JVM直接帮助管理内存,容易发生内存溢出。为了避免一直没有FULL GC,最终导致直接内存把物理内存耗完。我们可以<br>指定直接内存的最大值,通过-XX:MaxDirectMemorySize来指定,当达到阈值的时候,调用system.gc来进行一次FULL GC,间<br>接把那些没有被使用的直接内存回收掉。<br>
零拷贝(直接内存的使用)<br>
Netty的接收和发送ByteBuf采用DIRECT BUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。<br>如果使用传统的JVM堆内存(HEAP BUFFERS)进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才能写入Socket<br>中。JVM堆内存的数据是不能直接写入Socket中的。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。<br>可以看下netty的读写源码,比如read源码NioByteUnsafe.read()
ByteBuf内存池设计<br>
随着JVM虚拟机和JIT即时编译技术的发展,对象的分配和回收是个非常轻量级的工作。但是对于缓冲区Buffer(相当于一个内存块),情况<br>却稍有不同,特别是对于堆外直接内存的分配和回收,是一件耗时的操作。为了尽量重用缓冲区,Netty提供了基于ByteBuf内存池的缓冲<br>区重用机制。需要的时候直接从池子里获取ByteBuf使用即可,使用完毕之后就重新放回到池子里去。下面我们一起看下Netty ByteBuf的<br>实现
灵活的TCP参数配置能力
合理设置TCP参数在某些场景下对于性能的提升可以起到显著的效果,例如接收缓冲区SO_RCVBUF和发送缓冲区SO_SNDBUF。如果设置<br>不当,对性能的影响是非常大的。通常建议值为128K或者256K。<br>Netty在启动辅助类ChannelOption中可以灵活的配置TCP参数,满足不同的用户场景。<br>
并发优化<br>
volatile的大量、正确使用;<br>CAS和原子类的广泛使用;<br>线程安全容器的使用;<br>通过读写锁提升并发性能。
Linux
环境介绍
Vmware
Centos
环境搭建
常用命令
cd
touch
mv
tail -f 文件
用户
权限
消息中间件(MQ)
介绍
Message Queue(消息队列),是在消息的传输过程中保存消息的容器。多用于分布式系统之间进行通信
优势
应用解耦
系统的耦合性越高,容错性越低,可维护性就越低<br>
解决系统之间的耦合问题,提高容错性和维护性
异步提速<br>
提高用户的响应时间和系统的吞吐量<br>
削峰填谷
提高系统的运行稳定性
缺点
系统的可用性降低
一旦MQ宕机,便造成了整个系统的瘫痪<br>
系统的复杂度提高
解决消息队列中的重复消费,消息丢失等一系列问题
消息一致性问题
常见MQ对比
常见的MQ
kafka
leader和follower选举规则<br>
ISR中存在的副本,且AR副本排在前面,就可以成为leader
一、入门
1、概述
定义
Kafka是一个开源的分布式事件流平台(Event StreamingPlatform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。<br>
2、队列模式
点对点模式<br>
消费者主动拉去数据后,确认消息把队列中的数据删除
发布与订阅模式
可以有多个Topic主题<br>
消费数据后,不删除数据
每个消费者独立消费,都可以消费到数据<br>
3、架构
Producer
生产者,向Kafka集群中发消息的客户端<br>
Brocker<br>
一个服务器就是一个Brocker,一个集群由多个Brocker组成,一个Brocker上面可以有多个Topic
Consumer
消费者,从kafka集群中取消息的客户端
Consumer Group
由多个消费者组成,组内每个消费者负责不同分区的消费,一个分区只能由一个组内的消费者消费,消费者组内互不影响<br>每个消费者都属于一个消费组,一个消费组逻辑上是一个订阅者<br>
Topic
可以理解为一个队列,生产者和消费者都面对是topic
Partition<br>
实现扩展性,一个topic分布到多个brocker节点上,一个topic可以分为多个partition,每个partition是个有序的队列<br>
Replica<br>
副本,一个topic分为多个副本,副本分为一个leader和多个follower<br>
Leader
每个分区副本中“主”要的领头者,生产者和消费者收发消息都是通过该副本进行
Follower
每个分区副本中的“从”,会实时从leader中同步数据,如果leader故障,该副本会成为新的leader<br>
图
4、入门
集群搭建
zookeeper
kafka
基本命令使用
5、生产者
原理
main线程和sender线程,main 线程中创建了一个双端队列 RecordAccumulator,main 线程将消息发送给 RecordAccumulator,<br>Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。<br>
重要参数
buffer.memory<br>
RecordAccumulator 缓冲区总大小,默认 32m。<br>
batch.size
缓冲区一批数据最大值,默认 16k。适当增加该值,可<br>以提高吞吐量,但是如果该值设置太大,会导致数据<br>传输延迟增加。<br>
linger.ms
如果数据迟迟未达到 batch.size,sender 等待 linger.time<br>之后就会发送数据。<br>单位 ms,默认值是 0ms,表示没有延迟。<br>生产环境建议该值大小为 5-100ms 之间。<br>
acks
0:生产者发送过来的数据,不需要等数据落盘应答。<br>1:生产者发送过来的数据,Leader 收到数据后应答。<br>-1(all):生产者发送过来的数据,Leader+和 isr 队列<br>里面的所有节点收齐数据后应答。默认值是-1,-1 和<br>all 是等价的。<br>
retries
当消息发送出现错误的时候,系统会重发消息。<br>retries表示重试次数。默认是 int 最大值,2147483647。<br>
enable.idempotence<br>
是否开启幂等性,默认 true,开启幂等性。
compression.type
生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。<br>支持压缩类型:none、gzip、snappy、lz4 和 zstd。
发送方式
异步
同步
在异步的方式基础上加上get()方法
分区
优点
便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一<br>块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。<br>
提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
分区策略
默认的分区器 DefaultPartitioner<br>
指明分区,则按照指定分区来进行发送
若没有指明分区,则按照发送key对分区hash取模进行发送
既没有指明分区,又没有key,则采用粘性分区策略
自定义分区器
实现Partitioner,重写partition()
生产经验
提高吞吐量调优
• batch.size:批次大小,默认16k
• linger.ms:等待时间,修改为5-100ms
• compression.type:压缩snappy
• RecordAccumulator:缓冲区大小,修改为64m
数据可靠性<br>
ack应答
Leader维护了一个动态的in-sync replica set(ISR),意为和<br>Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)。<br>如果Follower长时间未向Leader发送通信请求或同步数据,则<br>该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参<br>数设定,默认30s。例如2超时,(leader:0, isr:0,1)。<br>这样就不用等长期联系不上或者已经故障的节点。
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
数据去重
幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。<br>精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。
重复数据的判断标准:具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其<br>中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。<br>所以幂等性只能保证的是在单分区单会话内不重复
默认是开启
数据有序
单分区内,是有序<br>多分区,无序
数据乱序
1.x之前版本
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。<br>
1.x之后版本
未开启幂等性<br>
max.in.flight.requests.per.connection需要设置为1。<br>
开启幂等性
max.in.flight.requests.per.connection需要设置为5<br>原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,<br>故无论如何,都可以保证最近5个request的数据都是有序的。<br>
事务
开启事务,必须开启幂等性。
Producer 在使用事务功能前,必须先<br>自定义一个唯一的 transactional.id。有<br>了 transactional.id,即使客户端挂掉了,<br>它重启后也能继续处理未完成的事务
6、Broker<br>
Zookeeper 存储的 Kafka 信息<br>
工作流程
重要参数
replica.lag.time.max.ms
ISR 中,如果 Follower 长时间未向 Leader 发送通<br>信请求或同步数据,则该 Follower 将被踢出 ISR。<br>该时间阈值,默认 30s。
auto.leader.rebalance.enable
默认是 true。 自动 Leader Partition 平衡。
log.retention.hours
Kafka 中数据保存的时间,默认 7 天。
生产调优
节点服役和退役<br>
平衡topic
创建一个要均衡的主题。<br>
生成一个负载均衡的计划。<br>
创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
执行副本存储计划。
)验证副本存储计划。
副本
副本基本信息<br>
Leader选举规则
Leader和follower故障细节<br>
基本概念
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。<br>
HW(High Watermark):所有副本中最小的LEO 。<br>
follower故障
等该Follower的LEO大于等于该Partition的HW,即<br>Follower追上Leader之后,就可以重新加入ISR了<br>
leader故障
为保证多个副本之间的数据一致性,其余的Follower会先<br>将各自的log文件高于HW的部分截掉,然后从新的Leader同步<br>数据。<br>
生产调优
手动调整分区副本存储
创建执行计划,执行,验证<br>
Leader Partition 负载平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某<br>些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的<br>broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。
增加副本因子
创建副本执行计划,执行副本计划,验证
文件存储<br>
log、segment<br>
.log、.index、.timeindex<br>
log日志默认是1G<br>
清理策略
Kafka 中默认的日志保存时间为 7 天,
delete 日志删除:将过期数据删除
log.cleanup.policy = delete 所有数据启用删除策略
基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。<br>log.retention.bytes,默认等于-1,表示无穷大。<br>
ompact 日志压缩
compact日志压缩:对于相同key的不同value值,只保留最后一个版本。
log.cleanup.policy = compact 所有数据启用压缩策略
高效读写数据
Kafka 本身是分布式集群,可以采用分区技术,并行度高
读数据采用稀疏索引,可以快速定位要消费的数据<br>
顺序写磁盘<br>
官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。
页缓存 + 零拷贝技术
零拷贝
Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用<br>走应用层,传输效率高。
7、消费者
消费方式
pull模式
push模式<br>
工作流程<br>
子主题<br>
消费者组
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。<br>• 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。<br>• 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
重要参数
生产经验
分区的分配以及再平衡
1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个<br>partition的数据。<br>2、Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。<br>可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用<br>多个分区分配策略。
漏消费和重复消费
消费者事务
数据积压(消费者如何提高吞吐量)
8、Kafka-Eagle 监控
9、Kafka-Kraft 模式
二、外部系统接入
Flume
生产者
消费者
Flink
消费者
生产者
SpringBoot
生产者
消费者
Spark
生产者
消费者
三、生产环境调优
Kafka 硬件配置选择
100 万日活,每人每天 100 条日志,每天总共的日志条数是 100 万 * 100 条 = 1 亿条。<br>1 亿/24 小时/60 分/60 秒 = 1150 条/每秒钟。<br>每条日志大小:0.5k - 2k(取 1k)。<br>1150 条/每秒钟 * 1k ≈ 1m/s 。<br>高峰期每秒钟:1150 条 * 20 倍 = 23000 条。<br>每秒多少数据量:20MB/s。
服务器台数选择
服务器台数= 2 * (生产者峰值生产速率 * 副本 / 100) + 1<br> = 2 * (20m/s * 2 / 100) + 1<br>= 3 台<br>建议 3 台服务器。
磁盘选择
kafka 底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多。<br>建议选择普通的机械硬盘。<br>每天总数据量:1 亿条 * 1k ≈ 100g<br>100g * 副本 2 * 保存时间 3 天 / 0.7 ≈ 1T<br>建议三台服务器硬盘总大小,大于等于 1T。
内存选择
Kafka 内存组成:堆内存 + 页缓存<br>
Kafka 堆内存建议每个节点:10g ~ 15g
页缓存:页缓存是 Linux 系统服务器的内存。我们只需要保证 1 个 segment(1g)中<br>25%的数据在内存中就好。<br>每个节点页缓存大小 =(分区数 * 1g * 25%)/ 节点数。例如 10 个分区,页缓存大小<br>=(10 * 1g * 25%)/ 3 ≈ 1g<br>建议服务器内存大于等于 11G。
CPU 选择
num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的 50%。<br>num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的 50%的 1/3<br>num.network.threads = 3 数据传输线程数,这个参数占总核数的 50%的 2/3。<br>
网络选择
网络带宽 = 峰值吞吐量 ≈ 20MB/s 选择千兆网卡即可。<br>100Mbps 单位是 bit;10M/s 单位是 byte ; 1byte = 8bit,100Mbps/8 = 12.5M/s。<br>一般百兆的网卡(100Mbps )、千兆的网卡(1000Mbps)、万兆的网卡(10000Mbps)。
四、源码分析
源码下载地址
http://kafka.apache.org/downloads
安装 JDK&Scala<br>
加载源码
安装 gradle
五、常见问题解决
消息丢失情况<br>
消息发送端
(1)acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消<br>息。大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。<br>(2)acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消<br>息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。<br>(3)acks=-1或all: 这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,这种策略会保证只要有一<br>个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。当然如果<br>min.insync.replicas配置的是1则也可能丢消息,跟acks=1情况类似。
消息消费端<br>
如果消费这边配置的是自动提交,万一消费到数据还没处理完,就自动提交offset了,但是此时你consumer直接宕机了,未处理完的数据<br>丢失了,下次也消费不到了。
消息重复消费<br>
消息发送端
发送消息如果配置了重试机制,比如网络抖动时间过长导致发送端发送超时,实际broker可能已经接收到消息,但发送方会重新发送消息<br>
消息消费端
如果消费这边配置的是自动提交,刚拉取了一批数据处理了一部分,但还没来得及提交,服务挂了,下次重启又会拉取相同的一批数据重<br>复处理一般消费端都是要做消费幂等处理的。
消息乱序<br>
如果发送端配置了重试机制,kafka不会等之前那条消息完全发送成功才去发送下一条消息,这样可能会出现,发送了1,2,3条消息,第<br>一条超时了,后面两条发送成功,再重试发送第1条消息,这时消息在broker端的顺序就是2,3,1了<br>所以,是否一定要配置重试要根据业务情况而定。也可以用同步发送的模式去发消息,当然acks不能设置为0,这样也能保证消息从发送<br>端到消费端全链路有序。<br>kafka保证全链路消息顺序消费,需要从发送端开始,将所有有序消息发送到同一个分区,然后用一个消费者去消费,但是这种性能比较<br>低,可以在消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个),一个内存队列开启一个线程顺序处理消<br>息。<br>
消息积压<br>
1)线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。<br>此种情况如果积压了上百万未消费消息需要紧急处理,可以修改消费端程序,让其将收到的消息快速转发到其他topic(可以设置很多分<br>区),然后再启动多个消费者同时消费新主题的不同分区。
2)由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。<br>此种情况可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。<br>
延时队列<br>
延时队列存储的对象是延时消息。所谓的“延时消息”是指消息被发送以后,并不想让消费者立刻获取,而是等待特定的时间后,消费者<br>才能获取这个消息进行消费,延时队列的使用场景有很多, 比如 :<br>1)在订单系统中, 一个用户下单之后通常有 30 分钟的时间进行支付,如果 30 分钟之内没有支付成功,那么这个订单将进行异常处理,<br>这时就可以使用延时队列来处理这些订单了。<br>2)订单完成1小时后通知用户进行评价。
实现思路
发送延时消息时先把消息按照不同的延迟时间段发送到指定的队列中(topic_1s,topic_5s,topic_10s,...topic_2h,这个一<br>般不能支持任意时间段的延时),然后通过定时器进行轮训消费这些topic,查看消息是否到期,如果到期就把这个消息发送到具体业务处<br>理的topic中,队列中消息越靠前的到期时间越早,具体来说就是定时器在一次消费过程中,对消息的发送时间做判断,看下是否延迟到对<br>应时间了,如果到了就转发,如果还没到这一次定时任务就可以提前结束了。<br>
消息回溯<br>
如果某段时间对已消费消息计算的结果觉得有问题,可能是由于程序bug导致的计算错误,当程序bug修复后,这时可能需要对之前已消<br>费的消息重新消费,可以指定从多久之前的消息回溯消费,这种可以用consumer的offsetsForTimes、seek等方法指定从某个offset偏移<br>的消息开始消费。
分区数越多吞吐量越高吗<br>
分区数到达某个值吞吐量反而开始下降,实际上很多事情都会有一个<br>临界值,当超过这个临界值之后,很多原本符合既定逻辑的走向又会变得不同。一般情况分区数跟集群机器数量相当就差不多了。
当然吞吐量的数值和走势还会和磁盘、文件系统、 I/O调度策略等因素相关。<br>注意:如果分区数设置过大,比如设置10000,可能会设置不成功,后台会报错"java.io.IOException : Too many open files"。<br>异常中最关键的信息是“ Too many open flies”,这是一种常见的 Linux 系统错误,通常意味着文件描述符不足,它一般发生在创建线<br>程、创建 Socket、打开文件这些场景下 。 在 Linux系统的默认设置下,这个文件描述符的个数不是很多 ,通过 ulimit -n 命令可以查<br>看:一般默认是1024,可以将该值增大,比如:ulimit -n 65535
消息传递保障
at most once(消费者最多收到一次消息,0-1次):acks = 0 可以实现。<br>at least once(消费者至少收到一次消息,1-多次):ack = all 可以实现。<br>exactly once(消费者刚好收到一次消息):at least once 加上消费者幂等性可以实现,还可以用kafka生产者的幂等性来实现。
kafka生产者的幂等性
因为发送端重试导致的消息重复发送问题,kafka的幂等性可以保证重复发送的消息只接收一次,只需在生产者加<br>上参数 props.put(“enable.idempotence”, true) 即可,默认是false不开启。<br>具体实现原理是,kafka每次发送消息会生成PID和Sequence Number,并将这两个属性一起发送给broker,broker会将PID和<br>Sequence Number跟消息绑定一起存起来,下次如果生产者重发相同消息,broker会检查PID和Sequence Number,如果相同不会再接收。<br>
1 PID:每个新的 Producer 在初始化的时候会被分配一个唯一的 PID,这个PID 对用户完全是透明的。生产者如果重启则会生成新的PID。<br>2 Sequence Number:对于每个 PID,该 Producer 发送到每个 Partition 的数据都有对应的序列号,这些序列号是从0开始单调递增的。
kafka的事务<br>
Kafka的事务不同于Rocketmq,Rocketmq是保障本地事务(比如数据库)与mq消息发送的事务一致性,Kafka的事务主要是保障一次发送<br>多条消息的事务一致性(要么同时成功要么同时失败),一般在kafka的流式计算场景用得多一点,比如,kafka需要对一个topic里的消息做<br>不同的流式计算处理,处理完分别发到不同的topic里,这些topic分别被不同的下游系统消费(比如hbase,redis,es等),这种我们肯定<br>希望系统发送到多个topic的数据保持事务一致性。Kafka要实现类似Rocketmq的分布式事务需要额外开发功能。
kafka高性能的原因<br>
(1)磁盘顺序读写:kafka消息不能修改以及不会从文件中间删除保证了磁盘顺序读,kafka的消息写入文件都是追加在文件末尾,<br>不会写入文件中的某个位置(随机写)保证了磁盘顺序写。<br>(2)数据传输的零拷贝<br>(3)读写数据的批量batch处理以及压缩传输<br>
RabbitMQ
主要协议
<span style="font-size: 10.5pt; font-variant-numeric: normal; font-variant-east-asian: normal; color: red; letter-spacing: 0pt; vertical-align: baseline;">AMQP</span><br>
Advanced Message Queuing Protocol(高级消息队列协议)
一个网络协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。2006年,AMQP 规范发布。类比HTTP
简介
2007年,Rabbit 技术公司基于 AMQP 标准开发的 RabbitMQ 1.0 发布。RabbitMQ 采用 Erlang 语言开发。Erlang 语言由 Ericson 设计,专门为开发高并发和分布式系统的一种语言,在电信领域使用广泛
主要架构
相关概念
Broker<br>
接收和分发消息的应用<br>
Virtual host
出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念
Connection
publisher/consumer 和 broker 之间的 TCP 连接
Channel
如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection的开销将是巨大的,效率也较低。Channel 是在 connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的 channel 进行通讯,AMQP method 包含了channel id 帮助客户端和message broker 识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的 Connection 极大减少了操作系统建立 TCP connection 的开销
Exchange<br>
message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到queue 中去。常用的类型有:direct (point-to-point), topic (publish-subscribe) and fanout (multicast)<br>
3种类型
Fanout<br>
广播,将消息交给所有绑定到交换机的队列
Direct
定向,把消息交给符合指定routing key 的队列
Topic
通配符,将消息交给符合routing pattern(路由模式) 的队列<br>
只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与 Exchange 绑定,或者没有符合路由规则的队列,那么消息会丢失!
Queue
消息最终被送到这里等待 consumer 取走
Binding
exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key。Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据
工作模式
简单模式<br>
一对一,有默认的交换机
work queues<br>
对于任务过重或任务较多情况使用工作队列可以提高任务处理的速度
一对多,一个生产对应多个消费者
Publish/Subscribe 发布与订阅模式
绑定交换机(Exchange)
需要设置类型为 fanout 的交换机,并且交换机和队列进行绑定,当发送消息到交换机后,交换机会将消息发送到绑定的队列。
Routing 路由模式
交换机和routingKey
需要设置类型为 direct 的交换机,交换机和队列进行绑定,并且指定 routing key,当发送消息到交换机后,交换机会根据 routing key 将消息发送到对应的队列<br>
Topics 主题模式
在路由模式上支持更灵活的方式
需要设置类型为 topic 的交换机,交换机和队列进行绑定,并且指定通配符方式的 routing key,当发送消息到交换机后,交换机会根据 routing key 将消息发送到对应的队列
RPC 远程调用模式
消息确认机制
如何确保消息投入到borker,监听器<br>
Confirm
表示生产者将消息投入到Borker时产生的状态<br>
ack表示borker已经接收消息<br>
nack表示拒收消息,原因,队列满,限流,异常等<br>
Return
表示被Borker接受(ack)以后,但是Borker没有对应的队列进行投递产生的状态,消息退回生产者<br>
以上两种只代表生产者与Borker之间的消息投递状态,与消费者的是否确认和接收无关<br>
安装
下载网址<br>
https://www.rabbitmq.com/download.html
集群搭建
整合
spring
使用 Spring 整合 RabbitMQ 将组件全部使用配置方式实现
提供了RabbitTemplate 简化发送消息 API<br>
使用监听机制简化消费者编码<br>
springboot
基本信息再yml中配置,队列交互机以及绑定关系在配置类中使用Bean的方式配置<br>
生产端直接注入RabbitTemplate完成消息发送<br>
消费端直接使用@RabbitListener完成消息接收<br>
高级特性
消息的可靠投递<br>
confirm 确认模式<br>
return 退回模式<br>
整个消息投递过程
producer--->rabbitmq broker--->exchange--->queue--->consumer<br>
消息从 producer 到 exchange 则会返回一个 confirmCallback
消息从 exchange-->queue 投递失败则会返回一个 returnCallback
Consumer Ack
含义
ack指Acknowledge,确认。 表示消费端收到消息后的确认方式
三种方式
自动确认:acknowledge="none"<br>
当消息一旦被Consumer接收到,则自动确认收到,并将相应 message 从 RabbitMQ 的消息缓存中移除
手动确认:acknowledge="manual"<br>
设置了手动确认方式,则需要在业务处理成功后,调用channel.basicAck(),手动签收,<br>如果出现异常,则调用channel.basicNack()方法,让其自动重新发送消息<br>
根据异常情况确认:acknowledge="auto"
可靠性投递总结<br>
持久化<br>
exchenge持久化<br>
queue要持久化<br>
message要持久化<br>
生产方确认Confirm<br>
消费方确认Ack<br>
Broker高可用<br>
消费端限流
配置 prefetch属性设置消费端一次拉取多少消息
消费端的确认模式一定为手动确认。acknowledge="manual"<br>
TTL
解释
Time To Live(存活时间/过期时间)
当消息到达存活时间后,还没有被消费,会被自动清除
RabbitMQ可以对消息设置过期时间,也可以对整个队列(Queue)设置过期时间
参数<br>
x-message-ttl,单位:ms(毫秒),会对整个队列消息统一过期
expiration。单位:ms(毫秒),当该消息在队列头部时(消费时),会单独判断这一消息是否过期
两者都设置,以时间短的为准<br>
死信队列<br>
DLX
Dead Letter Exchange(死信交换机)
当消息成为Dead message后,可以被重新发送到另一个交换机,这个交换机就是DLX
成为死信的三种情况
队列消息长度到达限制<br>
消费者拒接消费消息,basicNack/basicReject,并且不把消息重新放入原目标队列,requeue=false<br>
原队列存在消息过期设置,消息到达超时时间未被消费
给队列设置参数: x-dead-letter-exchange 和 x-dead-letter-routing-key<br>
延迟队列<br>
即消息进入队列后不会立即被消费,只有到达指定时间后,才会被消费
RabbitMQ中没有提供该队列支持,只能通过TTL+死信队列实现<br>
消息幂等性保障
幂等性指一次和多次请求某一个资源,对于资源本身应该具有同样的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同<br>
在MQ中指,消费多条相同的消息,得到与消费该消息一次相同的结果<br>
实现
乐观锁机制
消息挤压
问题
消费者宕机挤压
消费者消费能力不足挤压
发送者发流量太大<br>
解决<br>
创建多个Work(工作队列)进行消费
把消息队列中的消息存放到数据库中,后面写程序进行消费
ActiveMQ
RocketMQ
简介
RocketMQ是阿里巴巴开源的一个消息中间件,在阿里内部历经了双十一等很多高并发场景的考验,能够处理亿万级别的消息。<br>2016年开源后捐赠给Apache,现在是Apache的一个顶级项目。
版本
商业版
社区版
java开发
架构
官网
https://rocketmq.apache.org/
组件介绍
NameServer
提供轻量级的Broker路由服务
邮局的管理机构
Broker
实际处理消息存储、转发等服务的核心组件
暂存和传输消息
邮局
Producer
消息生产者集群。通常是业务系统中的一个功能模块
发信者
Consumer
消息消费者集群。通常也是业务系统中的一个功能模块
收信者
Topic
区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息
Message Queue<br>
相当于是Topic的分区;用于并行发送和接收消息
环境部署
环境部署准备
jdk
maven
centos7
单机测试
# 编辑runbroker.sh和runserver.sh修改默认JVM大小<br>vi runbroker.sh<br>vi runserver.sh
先启动NameServer<br>
nohup sh bin/mqnamesrv &<br># 2.查看启动日志<br>tail -f ~/logs/rocketmqlogs/namesrv.log
启动Broker<br>
nohup sh bin/mqbroker -n localhost:9876 &<br># 2.查看启动日志<br>tail -f ~/logs/rocketmqlogs/broker.log
测试
发送消息<br>
# 1.设置环境变量<br>export NAMESRV_ADDR=localhost:9876<br># 2.使用安装包的Demo发送消息<br>sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
接受消息
# 1.设置环境变量<br>export NAMESRV_ADDR=localhost:9876<br># 2.接收消息<br>sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
关闭
# 1.关闭NameServer<br>sh bin/mqshutdown namesrv<br># 2.关闭Broker<br>sh bin/mqshutdown broker<br>
集群搭建
机器
192.168.217.99;192.168.217.88
修改Host文件,配置映射
vim /etc/hosts<br>
# nameserver<br>192.168.217.99 rocketmq-nameserver1<br>192.168.217.88 rocketmq-nameserver2<br># broker<br>192.168.217.99 rocketmq-master1<br>192.168.217.99 rocketmq-slave2<br>192.168.217.88 rocketmq-master2<br>192.168.217.88 rocketmq-slave1<br>
systemctl restart network
防火墙
# 关闭防火墙<br>systemctl stop firewalld.service <br># 查看防火墙的状态<br>firewall-cmd --state <br># 禁止firewall开机启动<br>systemctl disable firewalld.service
`nameserver` 默认使用 9876 端口<br>
`master` 默认使用 10911 端口<br>
`slave` 默认使用11011 端口
# 开放name server默认端口<br>firewall-cmd --remove-port=9876/tcp --permanent<br># 开放master默认端口<br>firewall-cmd --remove-port=10911/tcp --permanent<br># 开放slave默认端口 (当前集群模式可不开启)<br>firewall-cmd --remove-port=11011/tcp --permanent <br># 重启防火墙<br>firewall-cmd --reload
环境变量
vim /etc/profile
#set rocketmq<br>ROCKETMQ_HOME=/usr/local/rocketmq/rocketmq-all-4.4.0-bin-release<br>PATH=$PATH:$ROCKETMQ_HOME/bin<br>export ROCKETMQ_HOME PATH
source /etc/profile
创建消息存储路径<br>
mkdir /usr/local/rocketmq/store<br>mkdir /usr/local/rocketmq/store/commitlog<br>mkdir /usr/local/rocketmq/store/consumequeue<br>mkdir /usr/local/rocketmq/store/index<br>
配置文件
master1
192.168.217.99<br>
vi conf/2m-2s-sync/broker-a.properties<br>
内容
nohup sh mqbroker -c /usr/local/rocketmq/conf/2m-2s-syncbroker-a.properties &
slave2
192.168.217.99<br>
vi conf/2m-2s-sync/broker-b-s.properties<br>
内容
nohup sh mqbroker -c /usr/local/rocketmq/conf/2m-2s-sync/broker-b-s.properties &
master2
192.168.217.88
vi conf/2m-2s-sync/broker-b.properties
内容<br>
nohup sh mqbroker -c /usr/local/rocketmq/conf/2m-2s-sync/broker-b.properties &<br>
slave1
192.168.217.88
vi conf/2m-2s-sync/broker-a-s.properties
内容
nohup sh mqbroker -c /usr/local/rocketmq/conf/2m-2s-sync/broker-a-s.properties &
修改启动脚本中的内存
bin/runbroker.sh<br>
bin/runserver.sh<br>
先启动nameserver<br>
nohup sh mqnamesrv &
在启动broker
查看启动进程
jps
# 查看nameServer日志<br>tail -500f ~/logs/rocketmqlogs/namesrv.log<br># 查看broker日志<br>tail -500f ~/logs/rocketmqlogs/broker.log
mqadmin管理工具<br>
可视化页面管理
git clone https://github.com/apache/rocketmq-externals<br>cd rocketmq-console<br>mvn clean package -Dmaven.test.skip=true
rocketmq.config.namesrvAddr=192.168.217.99:9876;192.168.217.88:9876
java -jar rocketmq-console-ng-1.0.0.jar
端口是8080
消息分类
基本
消息发送
同步消息
异步消息
单向发送
消息消费
负载均衡模式
广播模式
顺序消息
延迟消息
过滤消息
事务消息
ELK
ElasticSearch<br>
介绍
Elasticsearch是用Java开发并且是当前最流行的开源的企业级搜索引擎<br>
官网
https://www.elastic.co/
下载网址
https://www.elastic.co/cn/start
创始人
Shay Banon(谢巴农)
Lucene
关系
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库(框架)
Es基于Lucene开发
缺点
只能在Java项目中使用,并且要以jar包的方式直接集成项目中
使用非常复杂-创建索引和搜索索引代码繁杂
不支持集群环境-索引数据不同步(不支持大型项目)
索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬盘.共用空间少
Solr
速度
<ol><li>当单纯的对已有数据进行搜索时,Solr更快。</li><li>当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势</li></ol>
区别
<ul><li>Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能</li></ul>
关系型数据库
Database(数据库)<br>
index(索引)<br>
table(表)
Type(类型)<br>
Row(行)
Document(文档)<br>
Column(列)<br>
Field(字段)<br>
Schema(结构)<br>
Mapping(映射)<br>
SQL(语法)
DSL(语法)
倒排索引
索引就类似于目录,平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引呢,刚好相反,数据对应到主键
核心概念
Index(索引)
一个索引就是一个拥有几分相似特征的文档的集合<br>
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
Mapping(映射)
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的<br>
Field(字段)
相当于是数据表的字段|列<br>
Type(类型)
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等<br>
Document(文档)
一个文档是一个可被索引的基础信息单元,类似一条记录。文档以JSON(Javascript Object Notation)格式来表示
Cluster(集群)
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
Node(节点)
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能<br>
一个节点可以通过配置集群名称的方式来加入一个指定的集群<br>
shards&replicas(分片和副本)
分片<br>
一个索引可以存储超出单个结点硬件限制的大量数据
一个索引可以存储超出单个结点硬件限制的大量数据
每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
至于分片怎么分布,是由ElasticSearch来控制
重要性
允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
允许水平分割/扩展你的内容容量
副本
概念
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
重要性
在分片/节点失败的情况下,提供了高可用性<br>
扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
每个索引可以被分成多个分片。一个索引有0个或者多个副本<br>
一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定<br>
在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
安装
linux
ES不能使用root用户来启动,必须使用普通用户来安装启动
创建一个es专门的用户(必须)
分词器
内置分词器
中文分词
IK分词器<br>
下载网址
https://github.com/medcl/elasticsearch-analysis-ik/releases
两种
ik_smart<br>
ik_max_word<br>
config目录
IKAnalyzer.cfg.xml:用来配置自定义词库
可以配置指定的热词
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
quantifier.dic:放了一些单位相关的词
suffix.dic:放了一些后缀
surname.dic:中国的姓氏
stopword.dic:英文停用词
热更新
一种方式,修改IKAnalyzer.cfg.xml
IKAnalyzer.cfg.xml里面配置指定的服务器来更新词语
修改IK源码,通过数据库存储的热词,让IK从数据库读取并实施更新
pinyin分词器
下载网址
https://github.com/medcl/elasticsearch-analysis-pinyin/releases
HanLP
工作流程
预先处理无用的一些信息,比如<Html>
然后根据内容进行分词
分词过根据配置过滤敏感词或者一些其他设置<br>
定制分词器
中英分词
监控和可视化
Head插件
https://github.com/mobz/elasticsearch-head/releases
需要依赖NodeJs
<span style="color: rgb(51, 51, 51); font-family: "Open Sans", "Clear Sans", "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 16px; orphans: 4; white-space: pre-wrap;">cerebro</span>
https://github.com/lmenezes/cerebro/releases<br>
直接启动
集群搭建
config/elasticsearch.yml<br>
状态
green:每个索引的primary shard和replica shard都是active状态的<br>
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
在同一台服务器上部署集群会出现该状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
节点介绍
主节点:node.master:true<br>数据节点: node.data: true<br>
默认的配置
在一个生产集群中我们可以对这些节点的职责进行划分,建议集群中设置3台以上的节点作为master节点
避免出现脑裂问题
由于个节点之间通信问题导致
脑裂问题
就是同一个集群中的不同节点,对于集群的状态有了不一样的理解,比如集群中存在两个master<br>
解决
集群中master节点的数量至少3台,三台主节点通过在elasticsearch.yml中配置discovery.zen.minimum_master_nodes: 2,就可以避免脑裂问题的产生
集群节点/2+1
3个节点,该值的配置
3/2+1=2
架构原理
结构
Master
<ul><li>管理索引(创建索引、删除索引)、分配分片</li><li> 维护元数据</li><li> 管理集群节点状态</li><li> 不负责数据写入和查询,比较轻量级</li></ul>
一个集群中只有一个
内存可以相对小一点,但机器要稳定
DataNode
一个集群中有N多个节点
数据写入、数据检索
内存最好配置大
7.x以后默认一个索引有一个分片和一个副本
写入
一个请求会任意选一个DataNode节点,作为coordinating node(协调节点)<br>
计算得到文档要写入的分片,shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id
协调节点会把该请求转发到其他的节点上<br>
然后写入到对应的主节点中,然后同步至副本节点
主副节点都保存完毕数据之后,返回结果<br>
检索<br>
请求任意一个DataNode作为协调节点
该节点负责广播到每个DataNode,找到对应查询的Index以后处理<br>
每个分片返回document的分片,节点,文档id到协调节点进行汇总<br>
协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端<br>
<div id="x8po-1631438308959" yne-bulb-block="heading" yne-bulb-level="3" style="white-space: pre-wrap; line-height: 1.75; font-size: 14px;">准实时检索</div>
分片收到ES的数据,首先会写入到内存
然后通过内存的buffer生成一个segment
并刷到文件系统缓存中,数据可以被检索
每秒一次
在写入到内存中的同时,也会记录translog日志,在refresh期间出现异常,会根据translog来进行数据恢复<br>等到文件系统缓存中的segment数据都刷到磁盘中,清空translog文件<br>
ES默认每隔30分钟会将文件系统缓存的数据刷入到磁盘
Segment太多时,ES定期会将多个segment合并成为大的segment,减少索引查询时IO开销,此阶段ES会真正的物理删除(之前执行过的delete的数据)
_score 计算原理
根据用户的query条件,先过滤出包含指定term的doc<br>
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度<br>
TF/IDF算法<br>
term frequency/inverse document frequency<br>
TF
搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关<br>
IDF
搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关<br>
Kibana
概念
Kibana是世界上最受欢迎的开源日志分析平台ELK Stack中的“K” ,它为用户提供了一个工具,<br>用于在存储于Elasticsearch集群中的日志数据进行检索,可视化和构建仪表板<br>
下载
https://www.elastic.co/cn/downloads/kibana
安装
bin目录中,首先修改config目录下的kibana.yml文件
elasticsearch.hosts: ["http://ip1:9200", "http://ip2:9200"]<br>
基本操作
DevTools<br>
查询所有的索引<br>
GET _cat/indices<br>
创建索引
<div yne-bulb-block="code" data-theme="default" style="white-space:pre-wrap;" data-language="javascript">PUT /es_db</div>
查询索引
GET /es_db
删除索引
DELETE /es_db<br>
文档操作
添加
PUT /索引名称/类型/ID<br>
PUT /es_db/_doc/1<br>
POST和PUT都能起到创建/更新的作用<br>1、需要注意的是==PUT==需要对一个具体的资源进行操作也就是要确定id才能进行==更新/创建,而==POST==是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行==创建==新文档,如果填了id那就针对这个id的文档进行创建/更新<br>2、PUT只会将json数据都进行替换, POST只会更新相同字段的值<br>3、PUT与DELETE都是幂等性操作, 即不论操作多少次, 结果都一样<br>
查询
GET /索引名称/类型/id<br>
GET /es_db/_doc/1
删除
DELETE /索引名称/类型/id
DELETE /es_db/_doc/1<br>
查询
简单查询
查询当前类型中的所有文档 _search<br>
GET /索引名称/类型/_search<br>
GET /es_db/_doc/6
条件查询
GET /索引名称/类型/_search?q=*:***<br>
GET /es_db/_doc/_search?q=age:18
范围查询
GET /索引名称/类型/_search?q=***[25 TO 26]
GET /es_db/_doc/_search?q=age[26 TO 26]
批量查询
根据多个ID进行批量查询 _mget
GET /索引名称/类型/_mget
GET /es_db/_doc/_mget<br>{<br> "ids":["1","2"]<br>}<br>
分页查询
GET /索引名称/类型/_search?q=age[25 TO 26]&from=0&size=1
GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1<br>
过滤查询结果字段
GET /索引名称/类型/_search?_source=字段,字段
GET /es_db/_doc/_search?_source=name,age<br>
排序
<div yne-bulb-block="code" data-theme="default" style="white-space:pre-wrap;" data-language="javascript">GET /索引名称/类型/_search?sort=字段 desc<br></div>
GET /es_db/_doc/_search?sort=age:desc
批量查询
在URL中不指定index和type<br>请求方式:GET<br>请求地址:_mget<br>功能说明 : 可以通过ID批量获取不同index和type的数据<br>请求参数:<br>docs : 文档数组参数<br>_index : 指定index<br>_type : 指定type<br>_id : 指定id<br>_source : 指定要查询的字段<br>
GET _mget<br>{<br>"docs": [<br> {<br> "_index": "es_db",<br> "_type": "_doc",<br> "_id": 1<br> },<br> {<br> "_index": "es_db",<br> "_type": "_doc",<br> "_id": 2<br> }<br> ]<br>}<br>
批量操作(增删改)
增加
批量创建文档create<br>
POST _bulk<br>{"create":{"_index":"article", "_type":"_doc", "_id":3}}<br>{"id":3,"title":"好家伙","content":"好家伙666","tags":["java", "面向对象"],"create_time":1554015482530}<br>{"create":{"_index":"article", "_type":"_doc", "_id":4}}<br>{"id":4,"title":"好家伙1","content":"好家伙3","tags":["java", "面向对象"],"create_time":1554015482530}
如果原文档不存在,则是创建<br>
如果原文档存在,则是替换(全量修改原文档)<br>
修改
POST _bulk<br>{"update":{"_index":"article", "_type":"_doc", "_id":3}}<br>{"doc":{"title":"ES大法必修内功"}}<br>{"update":{"_index":"article", "_type":"_doc", "_id":4}}<br>{"doc":{"create_time":1554018421008}}<br>
删除
POST _bulk<br>{"delete":{"_index":"article", "_type":"_doc", "_id":3}}<br>{"delete":{"_index":"article", "_type":"_doc", "_id":4}}<br>
DSL语言高级查询
Domain Specific Language
DSL由叶子查询子句和复合查询子句两种子句组成
查询<br>
记录查询(query)<br>
无条件
match<br>
有条件<br>
叶子查询(单条件)<br>
模糊匹配<br>
match<br>
profix<br>
regexp
精确匹配
term<br>
terms<br>
range
exists<br>
ids
组合查询(多条件)
bool<br>
must
filter<br>
must_not<br>
should
constant_score<br>
dis_max<br>
mult_match
type
most_fields:在多字段中匹配的越多排名越靠前
best_fields: 能完全匹配的文档,排名越靠前
cross_fields: 查询越分散,排名越靠前
连接查询<br>
父子文档查询
has_child<br>
type
指定子文档名称
query<br>
子文档的查询条件<br>
inner_hits<br>
内层过滤<br>
has_parent
parent_type<br>
指定父文档名称
query<br>
父文档查询条件
inner_hits<br>
内层过滤
嵌套文档查询
nested<br>
path<br>
嵌套字段路径
query<br>
嵌套文档查询条件
聚合查询(aggs)
bucket
metric
对一个bucket数据执行的统计分析
求和,最大值,最小值,平均值
示例
无条件查询所有
GET /es_db/_doc/_search<br>{<br> "query":{<br> "match_all":{}<br> }<br>}<br>
推荐搜索
suggest_mode
<span md-inline="code" spellcheck="false" class="md-pair-s md-expand" style="box-sizing: border-box; color: rgb(51, 51, 51); font-family: "Open Sans", "Clear Sans", "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 16px; orphans: 4; white-space: pre-wrap;"><code style="box-sizing: border-box; font-family: var(--monospace); vertical-align: initial; border: 1px solid rgb(231, 234, 237); background-color: rgb(243, 244, 244); border-radius: 3px; padding: 0px 2px; font-size: 0.9em;">missing</code></span><span md-inline="plain" class="md-plain md-expand" style="box-sizing: border-box; color: rgb(51, 51, 51); font-family: "Open Sans", "Clear Sans", "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 16px; orphans: 4; white-space: pre-wrap;"> </span><br>
当词典中没有找到对应的索引信息,才去推荐<br>
<code style="box-sizing: border-box; font-family: var(--monospace); vertical-align: initial; border: 1px solid rgb(231, 234, 237); background-color: rgb(243, 244, 244); border-radius: 3px; padding: 0px 2px; font-size: 0.9em; color: rgb(51, 51, 51); orphans: 4; white-space: pre-wrap;">popular</code>
即使我们去搜索一个被索引了的单词,但是还是会去给我们推荐类似的但是出现频率很高的词
<code style="box-sizing: border-box; font-family: var(--monospace); vertical-align: initial; border: 1px solid rgb(231, 234, 237); background-color: rgb(243, 244, 244); border-radius: 3px; padding: 0px 2px; font-size: 0.9em; color: rgb(51, 51, 51); orphans: 4; white-space: pre-wrap;">always</code>
无论在任何情况下,都给出推荐
高亮显示
highlight中的field,必须跟query中的field一一对齐<br>
常用的highlight介绍
plain
lucene
posting<br>
index_options=offsets
性能比plain highlight要高,因为不需要重新对高亮文本进行分词
对磁盘的消耗少
fast vector
对大field而言(大于1mb),性能更高
<div yne-bulb-block="code" data-theme="default" style="white-space:pre-wrap;" data-language="javascript">强制使用某种highlighter</div>
设置高亮html标签,默认是<em>标签<br>
高亮片段fragment的设置
fragment_size: 你一个Field的值,比如有长度是1万,不可能在页面上显示这么长,设置要显示出来的fragment文本判断的长度,默认是100
number_of_fragments:你可能你的高亮的fragment文本片段有多个片段,你可以指定就显示几个片段
Logstash
介绍
Logstash是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储”。创建于2009年,于2013年被elasticsearch收购
下载
https://www.elastic.co/cn/downloads/logstash
资源
http://files.grouplens.org/datasets/movielens/
开发工具
git
官方网站
安装和部署
gitlab搭建
常用命令
设置用户和邮箱<br>
git config --global user.name "chenjingbo"<br> git config --global user.email "chenjb1024@aliyun.com"<br>
在c盘下面用户名文件夹下面有一个.gitconfig,里面可以查看配置的文件
git的分支管理
创建分支:git branch 分支名;<br> 切换分支:git chectout 分支名<br>
8.1.切换到主分支<br> 8.2.git pull<br> 8.3.git checkout -b 分支名字<br> 8.4.git push --set-upstream origin 分支名字<br> 8.4.git push
删除分支
git branch -d 分支名字<br> git push origin --delete 分支名字<br>
合并分支<br>
git checkout 需要合并分支<br> git merge 合并的分支<br> 取消合并 git merge --abort
从一个分支的某个提交合并到主分支
git checkout 主分支上<br> git cherry-pick commitId<br> git cherry-pick A、B<br> git cherry-pick A^..B
更新某个版本下的一个文件
git checkout -m 68e95237 pom.xml
本地没有远程的分支,切换远程的分支至本地
git checkout -b <分支名> origin/<分支名>
配置gitLab公私玥生成
ssh-keygen -t rsa -C '你注册的邮箱'<br> 位置保存在:C:\Users\本人用户\.ssh<br>
回滚上个版本并更新到远程
git reset --hard HEAD^;<br> git push -f origin 分支名称;
常用分支
master
dev
bugFix
future
test
maven
生命周期
Jenkins
svn
gland
UML类图
基本介绍
UML——Unified modeling language UML (统一建模语言),是一种用于软件系统分析和设计的语言工具,它用<br>于帮助软件开发人员进行思考和记录思路的结果<br>
UML 本身是一套符号的规定,就像数学符号和化学符号一样,这些符号用于描述软件模型中的各个元素和他<br>们之间的关系,比如类、接口、实现、泛化、依赖、组合、聚合等
分类
用例图(use case)<br>
静态结构图:类图、对象图、包图、组件图、部署图<br>
动态行为图:交互图(时序图与协作图)、状态图、活动图
UML 类图
说明
用于描述系统中的类(对象)本身的组成和类(对象)之间的各种静态关系。
类之间的关系:依赖、泛化(继承)、实现、关联、聚合与组合。
依赖关系(Dependence)
只要是在类中用到了对方,那么他们之间就存在依赖关系。如果没有对方,连编绎都通过不了。<br>
泛化关系(generalization)
泛化关系实际上就是继承关系,他是依赖关系的特例
实现关系(Implementation)
实现关系实际上就是 A 类实现 B 接口,他是依赖关系的特例
关联关系(Association)
类与类之间的联系,他也是依赖关系的特例
聚合关系(Aggregation)
表示的是整体和部分的关系,整体与部分可以分开。聚合关系是关联关系的特例,所<br>以他具有关联的导航性与多重性。
组合关系(Composition)
组合关系:也是整体与部分的关系,但是整体与部分不可以分开。<br>
设计模式
设计模式七大原则
目的<br>
编写软件过程中,程序员面临着来自 耦合性,内聚性以及可维护性,可扩展性,重用性,灵活性 等多方面的<br>挑战,设计模式是为了让程序(软件),具有更好<br>
1)代码重用性 (即:相同功能的代码,不用多次编写)<br>2)可读性 (即:编程规范性, 便于其他程序员的阅读和理解)<br>3)可扩展性 (即:当需要增加新的功能时,非常的方便,称为可维护)<br>4)可靠性 (即:当我们增加新的功能后,对原来的功能没有影响)<br>5)使程序呈现高内聚,低耦合的特性
意义
设计模式原则,其实就是程序员在编程时,应当遵守的原则,也是各种设计模式的基础(即:设计模式为什么<br>这样设计的依据)
原则
1)单一职责原则<br>
对类来说的,即一个类应该只负责一项职责。如类 A 负责两个不同职责:职责 1,职责 2。当职责 1 需求变更<br>而改变 A 时,可能造成职责 2 执行错误,所以需要将类 A 的粒度分解为 A1,A2<br>
2)接口隔离原则
1)客户端不应该依赖它不需要的接口,即一个类对另一个类的依赖应该建立在最小的接口上
3)依赖倒转(倒置)原则
高层模块不应该依赖低层模块,二者都应该依赖其抽象
抽象不应该依赖细节,细节应该依赖抽象
依赖倒转(倒置)的中心思想是面向接口编程
依赖倒转原则是基于这样的设计理念:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建的架<br>构比以细节为基础的架构要稳定的多。在 java 中,抽象指的是接口或抽象类,细节就是具体的实现类
使用接口或抽象类的目的是制定好规范,而不涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成
依赖关系传递的三种方式
接口传递<br>
构造方法传递
setter方法传递
4)里氏替换原则
基本介绍
里氏替换原则(Liskov Substitution Principle)在 1988 年,由麻省理工学院的以为姓里的女士提出的。<br>
所有引用基类的地方必须能透明地使用其子类的对象。
在使用继承时,遵循里氏替换原则,在子类中尽量不要重写父类的方法
里氏替换原则告诉我们,继承实际上让两个类耦合性增强了,在适当的情况下,可以通过聚合,组合,依赖 来解决问题。
5)开闭原则
开闭原则(Open Closed Principle)是编程中最基础、最重要的设计原则
一个软件实体如类,模块和函数应该对扩展开放(对提供方),对修改关闭(对使用方)。用抽象构建框架,用实现扩展细节
当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
编程中遵循其它原则,以及使用设计模式的目的就是遵循开闭原则。
6)迪米特法则
一个对象应该对其他对象保持最少的了解
类与类关系越密切,耦合度越大<br>
迪米特法则(Demeter Principle)又叫最少知道原则,即一个类对自己依赖的类知道的越少越好。也就是说,对于<br>被依赖的类不管多么复杂,都尽量将逻辑封装在类的内部。对外除了提供的 public 方法,不对外泄露任何信息<br>
迪米特法则还有个更简单的定义:只与直接的朋友通信
直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间<br>是朋友关系。耦合的方式很多,依赖,关联,组合,聚合等。其中,我们称出现成员变量,方法参数,方法返<br>回值中的类为直接的朋友,而出现在局部变量中的类不是直接的朋友。也就是说,陌生的类最好不要以局部变<br>量的形式出现在类的内部。
7)合成复用原则
原则是尽量使用合成/聚合的方式,而不是使用继承
核心思想<br>
找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起。<br>
针对接口编程,而不是针对实现编程。<br>
为了交互对象之间的松耦合设计而努力<br>
概述
层次
第 1 层:刚开始学编程不久,听说过什么是设计模式
第 2 层:有很长时间的编程经验,自己写了很多代码,其中用到了设计模式,但是自己却不知道
第 3 层:学习过了设计模式,发现自己已经在使用了,并且发现了一些新的模式挺好用的
第 4 层:阅读了很多别人写的源码和框架,在其中看到别人设计模式,并且能够领会设计模式的精妙和带来的好处。
第 5 层:代码写着写着,自己都没有意识到使用了设计模式,并且熟练的写了出来。
介绍
设计模式是程序员在面对同类软件工程设计问题所总结出来的有用的经验,模式不是代码,而是某类问题的通<br>用解决方案,设计模式(Design pattern)代表了最佳的实践。这些解决方案是众多软件开发人员经过相当长的<br>一段时间的试验和错误总结出来的。
设计模式的本质提高 软件的维护性,通用性和扩展性,并降低软件的复杂度。
类型
设计模式分为三种类型,共 23 种
创建型模式:单例模式、抽象工厂模式、原型模式、建造者模式、工厂模式。
结构型模式:适配器模式、桥接模式、装饰模式、组合模式、外观模式、享元模式、代理模式。
行为型模式:模版方法模式、命令模式、访问者模式、迭代器模式、观察者模式、中介者模式、备忘录模式、<br>解释器模式(Interpreter 模式)、状态模式、策略模式、职责链模式(责任链模式)。
23种模式
创建型模式(5)
单例模式
介绍
所谓类的单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例, 并且该类只提供一个取得其对象实例的方法(静态方法)。<br>
比如 Hibernate 的 SessionFactory,它充当数据存储源的代理,并负责创建 Session 对象。SessionFactory 并不是轻量级的,一般情况下,一个项目通常只需要一个 SessionFactory 就够,这是就会使用到单例模式。
单例设计模式八种方式
饿汉式(静态常量)
1)优点:这种写法比较简单,就是在类装载的时候就完成实例化。避免了线程同步问题。<br>2)缺点:在类装载的时候就完成实例化,没有达到 Lazy Loading 的效果。如果从始至终从未使用过这个实例,则会造成内存的浪费<br><br>3)这种方式基于 classloder 机制避免了多线程的同步问题,不过,instance 在类装载时就实例化,在单例模式中大多数都是调用 getInstance 方法, 但是导致类装载的原因有很多种,因此不能确定有其他的方式(或者其他的静态方法)导致类装载,这时候初始化 instance 就没有达到 lazy loading 的效果<br><br>4)结论:这种单例模式可用,可能造成内存浪费
饿汉式(静态代码块)
1)这种方式和上面的方式其实类似,只不过将类实例化的过程放在了静态代码块中,也是在类装载的时候,就执行静态代码块中的代码,初始化类的实例。优缺点和上面是一样的。<br>2)结论:这种单例模式可用,但是可能造成内存浪费
懒汉式(线程不安全)
1)起到了 Lazy Loading 的效果,但是只能在单线程下使用。<br>2)如果在多线程下,一个线程进入了 if (singleton == null)判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。所以在多线程环境下不可使用这种方式<br>3)结论:在实际开发中,不要使用这种方式.
懒汉式(线程安全,同步方法)
1)解决了线程安全问题<br>2)效率太低了,每个线程在想获得类的实例时候,执行 getInstance()方法都要进行同步。而其实这个方法只执行一次实例化代码就够了,后面的想获得该类实例,直接 return 就行了。方法进行同步效率太低<br>3)结论:在实际开发中,不推荐使用这种方式
懒汉式(线程安全,同步代码块)
不推荐使用<br>
双重检查
1)Double-Check 概念是多线程开发中常使用到的,如代码中所示,我们进行了两次 if (singleton == null)检查,这样就可以保证线程安全了。<br>2)这样,实例化代码只用执行一次,后面再次访问时,判断 if (singleton == null),直接 return 实例化对象,也避免的反复进行方法同步.<br>3)线程安全;延迟加载;效率较高<br>4)结论:在实际开发中,推荐使用这种单例设计模式<br>
静态内部类<br>
1)这种方式采用了类装载的机制来保证初始化实例时只有一个线程。<br><br>2)静态内部类方式在 Singleton 类被装载时并不会立即实例化,而是在需要实例化时,调用 getInstance 方法,才会装载 SingletonInstance 类,从而完成 Singleton 的实例化。<br>3)类的静态属性只会在第一次加载类的时候初始化,所以在这里,JVM 帮助我们保证了线程的安全性,在类进行初始化时,别的线程是无法进入的。<br>4)优点:避免了线程不安全,利用静态内部类特点实现延迟加载,效率高<br>5)结论:推荐使用.
枚举<br>
1) 这借助 JDK1.5 中添加的枚举来实现单例模式。不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象。<br>2) 这种方式是 Effective Java 作者 Josh Bloch 提倡的方式3) 结论:推荐使用<br>
说明
1)单例模式保证了 系统内存中该类只存在一个对象,节省了系统资源,对于一些需要频繁创建销毁的对象,使用单例模式可以提高系统性能<br>2)当想实例化一个单例类的时候,必须要记住使用相应的获取对象的方法,而不是使用 new<br><br>3)单例模式使用的场景:需要频繁的进行创建和销毁的对象、创建对象时耗时过多或耗费资源过多(即:重量级对象),但又经常用到的对象、工具类对象、频繁访问数据库或文件的对象(比如数据源、session 工厂等)
工厂模式
简单工厂模式<br>
介绍
1)简单工厂模式是属于创建型模式,是工厂模式的一种。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。<br>简单工厂模式是工厂模式家族中最简单实用的模式<br>
2)简单工厂模式:定义了一个创建对象的类,由这个类来封装实例化对象的行为(代码)
3)在软件开发中,当我们会用到大量的创建某种、某类或者某批对象时,就会使用到工厂模式.
工厂方案模式
意义
1)工厂模式的意义<br>将实例化对象的代码提取出来,放到一个类中统一管理和维护,达到和主项目的依赖关系的解耦。从而提高项目的扩展和维护性。<br>2)三种工厂模式 (简单工厂模式、工厂方法模式、抽象工厂模式)
原则
创建对象实例时,不要直接 new 类, 而是把这个 new 类的动作放在一个工厂的方法中,并返回。有的书上说, 变量不要直接持有具体类的引用。<br>不要让类继承具体类,而是继承抽象类或者是实现 interface(接口)<br>不要覆盖基类中已经实现的方法。<br>
原型模式
介绍
1)原型模式(Prototype 模式)是指:用原型实例指定创建对象的种类,并且通过拷贝这些原型,创建新的对象<br>2)原型模式是一种创建型设计模式,允许一个对象再创建另外一个可定制的对象,无需知道如何创建的细节<br>3)工作原理是:通过将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象拷贝它们自己来实施创建,即 对象.clone()<br>4)形象的理解:孙大圣拔出猴毛, 变出其它孙大圣
注意细节
1)创建新的对象比较复杂时,可以利用原型模式简化对象的创建过程,同时也能够提高效率<br>2)不用重新初始化对象,而是动态地获得对象运行时的状态<br>3)如果原始对象发生变化(增加或者减少属性),其它克隆对象的也会发生相应的变化,无需修改代码<br>4)在实现深克隆的时候可能需要比较复杂的代码<br>5)缺点:需要为每一个类配备一个克隆方法,这对全新的类来说不是很难,但对已有的类进行改造时,需要修改其源代码,违背了 ocp 原则,这点请同学们注意.
建造者模式
介绍<br>
1)建造者模式(Builder Pattern) 又叫生成器模式,是一种对象构建模式。它可以将复杂对象的建造过程抽象出来(抽象类别),使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。<br>2)建造者模式 是一步一步创建一个复杂的对象,它允许用户只通过指定复杂对象的类型和内容就可以构建它们, 用户不需要知道内部的具体构建细节。
四个角色
1)Product(产品角色): 一个具体的产品对象。<br>2)Builder(抽象建造者): 创建一个 Product 对象的各个部件指定的 接口/抽象类。<br><br>3)ConcreteBuilder(具体建造者): 实现接口,构建和装配各个部件。<br>4)Director(指挥者): 构建一个使用 Builder 接口的对象。它主要是用于创建一个复杂的对象。它主要有两个作用,一是:隔离了客户与对象的生产过程,二是:负责控制产品对象的生产过程。<br>
细节
1)客户端(使用程序)不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象<br>2)每一个具体建造者都相对独立,而与其他的具体建造者无关,因此可以很方便地替换具体建造者或增加新的具体建造者, 用户使用不同的具体建造者即可得到不同的产品对象<br><br>3)可以更加精细地控制产品的创建过程 。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰, 也更方便使用程序来控制创建过程<br>4)增加新的具体建造者无须修改原有类库的代码,指挥者类针对抽象建造者类编程,系统扩展方便,符合“开闭原则”<br>5)建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。<br>6)如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大,因此在这种情况下,要考虑是否选择建造者模式.<br><br>7)抽象工厂模式 VS 建造者模式<br>抽象工厂模式实现对产品家族的创建,一个产品家族是这样的一系列产品:具有不同分类维度的产品组合,采用抽象工厂模式不需要关心构建过程,只关心什么产品由什么工厂生产即可。而建造者模式则是要求按照指定的蓝图建造产品,它的主要目的是通过组装零配件而产生一个新产品<br>
抽象工厂模式
1)抽象工厂模式:定义了一个 interface 用于创建相关或有依赖关系的对象簇,而无需指明具体的类<br>2)抽象工厂模式可以将简单工厂模式和工厂方法模式进行整合。<br>3)从设计层面看,抽象工厂模式就是对简单工厂模式的改进(或者称为进一步的抽象)。<br>4)将工厂抽象成两层,AbsFactory(抽象工厂) 和 具体实现的工厂子类。程序员可以根据创建对象类型使用对应的工厂子类。这样将单个的简单工厂类变成了工厂簇,更利于代码的维护和扩展。<br>5)类图<br>
结构型模式(7)
适配器模式
介绍<br>
1)适配器模式(Adapter Pattern)将某个类的接口转换成客户端期望的另一个接口表示,主的目的是兼容性,让原本因接口不匹配不能一起工作的两个类可以协同工作。其别名为包装器(Wrapper)<br>2)适配器模式属于结构型模式<br>3)主要分为三类:类适配器模式、对象适配器模式、接口适配器模式
工作原理
1)适配器模式:将一个类的接口转换成另一种接口.让原本接口不兼容的类可以兼容<br>2)从用户的角度看不到被适配者,是解耦的<br>3)用户调用适配器转化出来的目标接口方法,适配器再调用被适配者的相关接口方法<br>用户收到反馈结果,感觉只是和目标接口交互<br>
类型
类适配器模式
介绍
基本介绍:Adapter 类,通过继承 src 类,实现 dst 类接口,完成 src->dst 的适配。
1)Java 是单继承机制,所以类适配器需要继承 src 类这一点算是一个缺点, 因为这要求 dst 必须是接口,有一定局限性;<br>2)src 类的方法在 Adapter 中都会暴露出来,也增加了使用的成本。<br>3)由于其继承了 src 类,所以它可以根据需求重写 src 类的方法,使得 Adapter 的灵活性增强了。
对象适配器模式
介绍<br>
1)基本思路和类的适配器模式相同,只是将 Adapter 类作修改,不是继承 src 类,而是持有 src 类的实例,以解决兼容性的问题。 即:持有 src 类,实现 dst 类接口,完成 src->dst 的适配<br><br>2)根据“合成复用原则”,在系统中尽量使用关联关系(聚合)来替代继承关系。<br>3)对象适配器模式是适配器模式常用的一种<br>
细节
1)对象适配器和类适配器其实算是同一种思想,只不过实现方式不同。<br>根据合成复用原则,使用组合替代继承, 所以它解决了类适配器必须继承 src 的局限性问题,也不再要求 dst<br>必须是接口。<br><br>2)使用成本更低,更灵活。<br>
接口适配器
介绍
1)一些书籍称为:适配器模式(Default Adapter Pattern)或缺省适配器模式。<br>2)核心思路:当不需要全部实现接口提供的方法时,可先设计一个抽象类实现接口,并为该接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可有选择地覆盖父类的某些方法来实现需求<br>3)适用于一个接口不想使用其所有的方法的情况。<br>
细节
1)三种命名方式,是根据 src 是以怎样的形式给到 Adapter(在 Adapter 里的形式)来命名的。<br>2)类适配器:以类给到,在 Adapter 里,就是将 src 当做类,继承<br>对象适配器:以对象给到,在 Adapter 里,将 src 作为一个对象,持有接口适配器:以接口给到,在 Adapter 里,将 src 作为一个接口,实现<br>3)Adapter 模式最大的作用还是将原本不兼容的接口融合在一起工作。<br>4)实际开发中,实现起来不拘泥于我们讲解的三种经典形式
桥接模式<br>
介绍<br>
1)桥接模式(Bridge 模式)是指:将实现与抽象放在两个不同的类层次中,使两个层次可以独立改变。<br>2)是一种结构型设计模式<br>3)Bridge 模式基于类的最小设计原则,通过使用封装、聚合及继承等行为让不同的类承担不同的职责。它的主要特点是把抽象(Abstraction)与行为实现(Implementation)分离开来,从而可以保持各部分的独立性以及应对他们的功能扩展
细节
1)实现了抽象和实现部分的分离,从而极大的提供了系统的灵活性,让抽象部分和实现部分独立开来,这有助于系统进行分层设计,从而产生更好的结构化系统。<br>2)对于系统的高层部分,只需要知道抽象部分和实现部分的接口就可以了,其它的部分由具体业务来完成。<br>3)桥接模式替代多层继承方案,可以减少子类的个数,降低系统的管理和维护成本。<br><br>4)桥接模式的引入增加了系统的理解和设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进行设计和编程<br>5)桥接模式要求正确识别出系统中两个独立变化的维度(抽象、和实现),因此其使用范围有一定的局限性,即需要有这样的应用场景。
常用场景
1)-JDBC 驱动程序<br>2)-银行转账系统<br>转账分类: 网上转账,柜台转账,AMT 转账<br>转账用户类型:普通用户,银卡用户,金卡用户..<br>3)-消息管理<br>消息类型:即时消息,延时消息<br>消息分类:手机短信,邮件消息,QQ 消息...<br>
装饰者模式
介绍<br>
1)装饰者模式:动态的将新功能附加到对象上。在对象功能扩展方面,它比继承更有弹性,装饰者模式也体现了开闭原则(ocp)<br>2)这里提到的动态的将新功能附加到对象和 ocp 原则,在后面的应用实例上会以代码的形式体现,请同学们注意体会。
组合模式
介绍<br>
1)组合模式(Composite Pattern),又叫部分整体模式,它创建了对象组的树形结构,将对象组合成树状结构以表示“整体-部分”的层次关系。<br><br>2)组合模式依据树形结构来组合对象,用来表示部分以及整体层次。<br>3)这种类型的设计模式属于结构型模式。<br>4)组合模式使得用户对单个对象和组合对象的访问具有一致性,即:组合能让客户以一致的方式处理个别对象以及组合对象
细节
1)简化客户端操作。客户端只需要面对一致的对象而不用考虑整体部分或者节点叶子的问题。<br>2)具有较强的扩展性。当我们要更改组合对象时,我们只需要调整内部的层次关系,客户端不用做出任何改动.<br>3)方便创建出复杂的层次结构。客户端不用理会组合里面的组成细节,容易添加节点或者叶子从而创建出复杂的树形结构<br>4)需要遍历组织机构,或者处理的对象具有树形结构时, 非常适合使用组合模式.<br>5)要求较高的抽象性,如果节点和叶子有很多差异性的话,比如很多方法和属性都不一样,不适合使用组合模式
外观模式
介绍
1)外观模式(Facade),也叫“过程模式:外观模式为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用<br>2)外观模式通过定义一个一致的接口,用以屏蔽内部子系统的细节,使得调用端只需跟这个接口发生调用,而无需关心这个子系统的内部细节<br>
细节
1)外观模式对外屏蔽了子系统的细节,因此外观模式降低了客户端对子系统使用的复杂性<br>2)外观模式对客户端与子系统的耦合关系 - 解耦,让子系统内部的模块更易维护和扩展<br>3)通过合理的使用外观模式,可以帮我们更好的划分访问的层次<br>4)当系统需要进行分层设计时,可以考虑使用 Facade 模式<br>5)在维护一个遗留的大型系统时,可能这个系统已经变得非常难以维护和扩展,此时可以考虑为新系统开发一个<br>Facade 类,来提供遗留系统的比较清晰简单的接口,让新系统与 Facade 类交互,提高复用性<br>6)不能过多的或者不合理的使用外观模式,使用外观模式好,还是直接调用模块好。要以让系统有层次,利于维护为目的。
享元模式
介绍<br>
1)享元模式(Flyweight Pattern) 也叫 蝇量模式: 运用共享技术有效地支持大量细粒度的对象<br>2)常用于系统底层开发,解决系统的性能问题。像数据库连接池,里面都是创建好的连接对象,在这些连接对象中有我们需要的则直接拿来用,避免重新创建,如果没有我们需要的,则创建一个<br>3)享元模式能够解决重复对象的内存浪费的问题,当系统中有大量相似对象,需要缓冲池时。不需总是创建新对象,可以从缓冲池里拿。这样可以降低系统内存,同时提高效率<br>4)享元模式经典的应用场景就是池技术了,String 常量池、数据库连接池、缓冲池等等都是享元模式的应用,享元模式是池技术的重要实现方式
细节
1)在享元模式这样理解,“享”就表示共享,“元”表示对象<br>2)系统中有大量对象,这些对象消耗大量内存,并且对象的状态大部分可以外部化时,我们就可以考虑选用享元模式<br>3)用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象,用 HashMap/HashTable 存储<br>4)享元模式大大减少了对象的创建,降低了程序内存的占用,提高效率<br>5)享元模式提高了系统的复杂度。需要分离出内部状态和外部状态,而外部状态具有固化特性,不应该随着内部状态的改变而改变,这是我们使用享元模式需要注意的地方.<br>6)使用享元模式时,注意划分内部状态和外部状态,并且需要有一个工厂类加以控制。<br>7)享元模式经典的应用场景是需要缓冲池的场景,比如 String 常量池、数据库连接池
代理模式
介绍
1)代理模式:为一个对象提供一个替身,以控制对这个对象的访问。即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。<br>2)被代理的对象可以是远程对象、创建开销大的对象或需要安全控制的对象<br>3)代理模式有不同的形式, 主要有三种 静态代理、动态代理 (JDK 代理、接口代理)和 Cglib 代理 (可以在内存动态的创建对象,而不需要实现接口, 他是属于动态代理的范畴) 。<br>
类型
静态代理
介绍<br>
静态代理在使用时,需要定义接口或者父类,被代理对象(即目标对象)与代理对象一起实现相同的接口或者是继承相同父类
优缺点
1)优点:在不修改目标对象的功能前提下, 能通过代理对象对目标功能扩展<br>2)缺点:因为代理对象需要与目标对象实现一样的接口,所以会有很多代理类<br>3)一旦接口增加方法,目标对象与代理对象都要维护<br>
动态代理
介绍
1)代理对象,不需要实现接口,但是目标对象要实现接口,否则不能用动态代理<br>2)代理对象的生成,是利用 JDK 的 API,动态的在内存中构建代理对象<br>3)动态代理也叫做:JDK 代理、接口代理<br>
类型
CGlib
介绍
1)代理对象,不需要实现接口,但是目标对象要实现接口,否则不能用动态代理<br>2)代理对象的生成,是利用 JDK 的 API,动态的在内存中构建代理对象<br>3)动态代理也叫做:JDK 代理、接口代理<br>
常见代理模式
1)防火墙代理<br>内网通过代理穿透防火墙,实现对公网的访问。<br>2)缓存代理<br>比如:当请求图片文件等资源时,先到缓存代理取,如果取到资源则 ok,如果取不到资源,再到公网或者数据库取,然后缓存。<br>3)远程代理<br>远程对象的本地代表,通过它可以把远程对象当本地对象来调用。远程代理通过网络和真正的远程对象沟通信息。<br>4)同步代理:主要使用在多线程编程中,完成多线程间同步工作同步代理:主要使用在多线程编程中,完成多线程间同步工作<br>
行为型模式(11)
模板方法模式
介绍
1)模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern),z 在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。<br>2)简单说,模板方法模式 定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构,就可以重定义该算法的某些特定步骤<br>3)这种类型的设计模式属于行为型模式。
细节
1)基本思想是:算法只存在于一个地方,也就是在父类中,容易修改。需要修改算法时,只要修改父类的模板方法或者已经实现的某些步骤,子类就会继承这些修改<br>2)实现了最大化代码复用。父类的模板方法和已实现的某些步骤会被子类继承而直接使用。<br>3)既统一了算法,也提供了很大的灵活性。父类的模板方法确保了算法的结构保持不变,同时由子类提供部分步骤的实现。<br>4)该模式的不足之处:每一个不同的实现都需要一个子类实现,导致类的个数增加,使得系统更加庞大<br>5)一般模板方法都加上 final 关键字, 防止子类重写模板方法.<br>6)模板方法模式使用场景:当要完成在某个过程,该过程要执行一系列步骤 ,这一系列的步骤基本相同,但其个别步骤在实现时 可能不同,通常考虑用模板方法模式来处理
命令模式
介绍
1)命令模式(Command Pattern):在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个,<br>我们只需在程序运行时指定具体的请求接收者即可,此时,可以使用命令模式来进行设计<br>2)命名模式使得请求发送者与请求接收者消除彼此之间的耦合,让对象之间的调用关系更加灵活,实现解耦。<br>3)在命名模式中,会将一个请求封装为一个对象,以便使用不同参数来表示不同的请求(即命名),同时命令模式也支持可撤销的操作。<br>4)通俗易懂的理解:将军发布命令,士兵去执行。其中有几个角色:将军(命令发布者)、士兵(命令的具体执行者)、命令(连接将军和士兵)。<br>Invoker 是调用者(将军),Receiver 是被调用者(士兵),MyCommand 是命令,实现了 Command 接口,持有接收对象<br>
示例
Spring 框架 JdbcTemplate 应用<br>
细节
1)将发起请求的对象与执行请求的对象解耦。发起请求的对象是调用者,调用者只要调用命令对象的 execute()方法就可以让接收者工作,而不必知道具体的接收者对象是谁、是如何实现的,命令对象会负责让接收者执行请求的动作,也就是说:”请求发起者”和“请求执行者”之间的解耦是通过命令对象实现的,命令对象起到了 纽带桥梁的作用。<br>2)容易设计一个命令队列。只要把命令对象放到列队,就可以多线程的执行命令<br>3)容易实现对请求的撤销和重做<br>4)命令模式不足:可能导致某些系统有过多的具体命令类,增加了系统的复杂度,这点在在使用的时候要注意<br>5)空命令也是一种设计模式,它为我们省去了判空的操作。在上面的实例中,如果没有用空命令,我们每按下一个按键都要判空,这给我们编码带来一定的麻烦。<br>6)命令模式经典的应用场景:界面的一个按钮都是一条命令、模拟 CMD(DOS 命令)订单的撤销/恢复、触发- 反馈机制
访问者模式
介绍<br>
1)访问者模式(Visitor Pattern),封装一些作用于某种数据结构的各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。<br>2)主要将数据结构与数据操作分离,解决 数据结构和操作耦合性问题<br>3)访问者模式的基本工作原理是:在被访问的类里面加一个对外提供接待访问者的接口<br>4)访问者模式主要应用场景是:需要对一个对象结构中的对象进行很多不同操作(这些操作彼此没有关联),同时需要避免让这些操作"污染"这些对象的类,可以选用访问者模式解决
细节
优点<br>1)访问者模式符合单一职责原则、让程序具有优秀的扩展性、灵活性非常高<br>2)访问者模式可以对功能进行统一,可以做报表、UI、拦截器与过滤器,适用于数据结构相对稳定的系统<br>缺点<br>1)具体元素对访问者公布细节,也就是说访问者关注了其他类的内部细节,这是迪米特法则所不建议的, 这样造成了具体元素变更比较困难<br>2)违背了依赖倒转原则。访问者依赖的是具体元素,而不是抽象元素<br>3)因此,如果一个系统有比较稳定的数据结构,又有经常变化的功能需求,那么访问者模式就是比较合适的.<br>
迭代器模式
介绍<br>
1)迭代器模式(Iterator Pattern)是常用的设计模式,属于行为型模式<br>2)如果我们的集合元素是用不同的方式实现的,有数组,还有 java 的集合类,或者还有其他方式,当客户端要遍历这些集合元素的时候就要使用多种遍历方式,而且还会暴露元素的内部结构,可以考虑使用迭代器模式解决。<br>3)迭代器模式,提供一种遍历集合元素的统一接口,用一致的方法遍历集合元素,不需要知道集合对象的底层表示,即:不暴露其内部的结构。
示例
JDK-ArrayList 集合应用<br>
细节
优点<br>1)提供一个统一的方法遍历对象,客户不用再考虑聚合的类型,使用一种方法就可以遍历对象了。<br>2)隐藏了聚合的内部结构,客户端要遍历聚合的时候只能取到迭代器,而不会知道聚合的具体组成。<br>3)提供了一种设计思想,就是一个类应该只有一个引起变化的原因(叫做单一责任原则)。在聚合类中,我们把迭代器分开,就是要把管理对象集合和遍历对象集合的责任分开,这样一来集合改变的话,只影响到聚合对象。而如果遍历方式改变的话,只影响到了迭代器。<br>4)当要展示一组相似对象,或者遍历一组相同对象时使用, 适合使用迭代器模式<br><br>缺点<br>每个聚合对象都要一个迭代器,会生成多个迭代器不好管理类
观察者模式
介绍<br>
对象之间多对一依赖的一种设计方案,被依赖的对象为 Subject,依赖的对象为 Observer,Subject<br>通知 Observer 变化,比如这里的奶站是 Subject,是 1 的一方。用户时 Observer,是多的一方。<br>
好处
1)观察者模式设计后,会以集合的方式来管理用户(Observer),包括注册,移除和通知。<br>2)这样,我们增加观察者(这里可以理解成一个新的公告板),就不需要去修改核心类 WeatherData 不会修改代码, 遵守了 ocp 原则。
示例
Jdk 的 Observable 类就使用了观察者模式
中介者模式
介绍
1)中介者模式(Mediator Pattern),用一个中介对象来封装一系列的对象交互。中介者使各个对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互<br>2)中介者模式属于行为型模式,使代码易于维护<br>3)比如 MVC 模式,C(Controller 控制器)是 M(Model 模型)和 V(View 视图)的中介者,在前后端交互时起到了中间人的作用<br>
细节
1)多个类相互耦合,会形成网状结构, 使用中介者模式将网状结构分离为星型结构,进行解耦<br>2)减少类间依赖,降低了耦合,符合迪米特原则<br>3)中介者承担了较多的责任,一旦中介者出现了问题,整个系统就会受到影响<br>4)如果设计不当,中介者对象本身变得过于复杂,这点在实际使用时,要特别注意<br>
备忘录模式
介绍
1)备忘录模式(Memento Pattern)在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态<br>2)可以这里理解备忘录模式:现实生活中的备忘录是用来记录某些要去做的事情,或者是记录已经达成的共同意见的事情,以防忘记了。而在软件层面,备忘录模式有着相同的含义,备忘录对象主要用来记录一个对象的某种状态,或者某些数据,当要做回退时,可以从备忘录对象里获取原来的数据进行恢复操作<br>3)备忘录模式属于行为型模式<br>
细节
1)给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态<br>2)实现了信息的封装,使得用户不需要关心状态的保存细节<br>3)如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存, 这个需要注意<br>4)适用的应用场景:1、后悔药。 2、打游戏时的存档。 3、Windows 里的 ctri + z。 4、IE 中的后退。 4、数据库的事务管理<br>5)为了节约内存,备忘录模式可以和原型模式配合使用
解释器模式
介绍
1)在编译原理中,一个算术表达式通过词法分析器形成词法单元,而后这些词法单元再通过语法分析器构建语法分析树,最终形成一颗抽象的语法分析树。这里的词法分析器和语法分析器都可以看做是解释器<br>2)解释器模式(Interpreter Pattern):是指给定一个语言(表达式),定义它的文法的一种表示,并定义一个解释器, 使用该解释器来解释语言中的句子(表达式)<br>
示例
Spring 框架中 SpelExpressionParser 就使用到解释器模式
细节
1)当有一个语言需要解释执行,可将该语言中的句子表示为一个抽象语法树,就可以考虑使用解释器模式,让程序具有良好的扩展性<br>2)应用场景:编译器、运算表达式计算、正则表达式、机器人等<br>3)使用解释器可能带来的问题:解释器模式会引起类膨胀、解释器模式采用递归调用方法,将会导致调试非常复杂、效率可能降低.<br>
状态模式<br>
介绍
1)状态模式(State Pattern):它主要用来解决对象在多种状态转换时,需要对外输出不同的行为的问题。状态和行为是一一对应的,状态之间可以相互转换<br>2)当一个对象的内在状态改变时,允许改变其行为,这个对象看起来像是改变了其类
细节
1)代码有很强的可读性。状态模式将每个状态的行为封装到对应的一个类中<br>2)方便维护。将容易产生问题的 if-else 语句删除了,如果把每个状态的行为都放到一个类中,每次调用方法时都要判断当前是什么状态,不但会产出很多 if-else 语句,而且容易出错<br>3)符合“开闭原则”。容易增删状态<br>4)会产生很多类。每个状态都要一个对应的类,当状态过多时会产生很多类,加大维护难度<br>5)应用场景:当一个事件或者对象有很多种状态,状态之间会相互转换,对不同的状态要求有不同的行为的时候, 可以考虑使用状态模式<br>
策略模式
介绍
1)策略模式(Strategy Pattern)中,定义算法族(策略组),分别封装起来,让他们之间可以互相替换,此模式让算法的变化独立于使用算法的客户<br>2)这算法体现了几个设计原则,第一、把变化的代码从不变的代码中分离出来;第二、针对接口编程而不是具体类(定义了策略接口);第三、多用组合/聚合,少用继承(客户通过组合方式使用策略)。<br>
示例
JDK 的 Arrays 的 Comparator 就使用了策略模式
细节
1)策略模式的关键是:分析项目中变化部分与不变部分<br>2)策略模式的核心思想是:多用组合/聚合 少用继承;用行为类组合,而不是行为的继承。更有弹性<br>3)体现了“对修改关闭,对扩展开放”原则,客户端增加行为不用修改原有代码,只要添加一种策略(或者行为) 即可,避免了使用多重转移语句(if..else if..else)<br>4)提供了可以替换继承关系的办法: 策略模式将算法封装在独立的Strategy 类中使得你可以独立于其Context 改变它,使它易于切换、易于理解、易于扩展<br>5)需要注意的是:每添加一个策略就要增加一个类,当策略过多是会导致类数目庞<br>
职责链模式
介绍<br>
1)职责链模式(Chain of Responsibility Pattern), 又叫 责任链模式,为请求创建了一个接收者对象的链(简单示意图)。这种模式对请求的发送者和接收者进行解耦。<br>2)职责链模式通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。<br>3)这种类型的设计模式属于行为型模式
示例
SpringMVC-HandlerExecutionChain 类就使用到职责链模式
细节
1)将请求和处理分开,实现解耦,提高系统的灵活性<br>2)简化了对象,使对象不需要知道链的结构<br>3)性能会受到影响,特别是在链比较长的时候,因此需控制链中最大节点数量,一般通过在 Handler 中设置一个最大节点数量,在 setNext()方法中判断是否已经超过阀值,超过则不允许该链建立,避免出现超长链无意识地破坏系统性能<br>4)调试不方便。采用了类似递归的方式,调试时逻辑可能比较复杂<br>5)最佳应用场景:有多个对象可以处理同一个请求时,比如:多级请求、请假/加薪等审批流程、Java Web 中 Tomcat<br>对 Encoding 的处理、拦截器<br>
Redis
常用数据结构
String
Hash
Set
Zset
List
持久化方式
RDB
AOF
区别
集群搭建
并发产生的问题以及对应的解决方案
哈希槽
底层实现模型
MongoDB<br>
介绍
MongoDB是一个文档数据库(以 JSON 为数据模型),由C++语言编写,旨在为WEB应用提供可扩展的<br>高性能数据存储解决方案。
概念
数据库(database)
最外层的,逻辑上命名<br>
集合(collection)<br>
相当于SQL中的表,一个集合可以存放多个不同的文档<br>
文档(document)
一个文档相当于数据表中的一行,由多个不同的字段组成
字段(field)
文档中的一个属性,等同于列(column)<br>
索引(index)<br>
独立的检索式数据结构,与SQL概念一致<br>
id
每个文档中都拥有一个唯一的id字段,相当于SQL中的主键(primary key)
视图(view)
可以看作一种虚拟的(非真实存在的)集合,与SQL中的视图类似。从MongoDB<br>3.4版本开始提供了视图功能,其通过聚合管道技术实现。
聚合操作($lookup)
MongoDB用于实现“类似”表连接(tablejoin)的聚合操作符
与传统数据库的对比
半结构化,在一个集合中,文档所拥有的字段并不需要是相同的,而且也不需要对所用的字段进行<br>声明。因此,MongoDB具有很明显的半结构化特点<br>
弱关系,MongoDB没有外键的约束,也没有非常强大的表连接能力。类似的功能需要使用聚合管<br>道技术来弥补。
优势
MongoDB基于灵活的JSON文档模型,非常适合敏捷式的快速开发
其与生俱来的高可用、高水平扩展能力使得它在处理海量、高并发的数据应用时颇具优势
复制集提供99.999%高可用<br>
多中心容灾的能力<br>
分片架构支持海量数据和无缝扩容
横向扩展能力强,支持TB、PB级别数据<br>
JSON 结构和对象模型接近,开发代码量低<br>
JSON的动态模型意味着更容易响应新的业务需求
应用场景
游戏场景
用户信息,游戏的积分,用户的装备<br>
物流场景
海量订单信息,实时更新,内嵌存储,一次性可以查询出所有信息<br>
社交场景
存储朋友圈信息,方便地理位置,附近的人功能的实现
物联网场景
智能设备,并且汇总日志信息,可对这些内容进行多维度的分析<br>
视频直播
用 MongoDB 存储用户信息、礼物信息等
大数据应用
使用云数据库MongoDB作为大数据的云存储系统,随时进行数据提取分析,掌握行<br>业动态。|
应用
官网
https://www.mongodb.com/
下载地址
https://www.mongodb.com/try/download/community<br>
学习文档地址
https://www.mongodb.com/docs/v4.4/introduction/<br>
安装
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.9.tgz<br>tar -zxvf mongodb-linux-x86_64-rhel70-4.4.9.tgz
启动与关闭
#创建dbpath和logpath<br>mkdir -p /mongodb/data /mongodb/log /mongodb/conf<br>#进入mongodb目录,启动mongodb服务<br>bin/mongod --port=27017 --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --bind_ip=0.0.0.0 --fork
添加环境变量
修改/etc/profile,添加环境变量,方便执行MongoDB命令
export MONGODB_HOME=/usr/local/soft/mongodb<br>PATH=$PATH:$MONGODB_HOME/bin
然后执行source /etc/profile 重新加载环境变量
增加配置文件并启动
systemLog:<br>destination: file<br>path: /mongodb/log/mongod.log # log path<br>logAppend: true<br>storage:<br>dbPath: /mongodb/data # data directory<br>engine: wiredTiger #存储引擎<br>journal: #是否启用journal日志<br>enabled: true<br>net:<br>bindIp: 0.0.0.0<br>port: 27017 # port<br>processManagement:<br>fork: true<br>
mongod -f /mongodb/conf/mongo.conf
关闭
mongod --port=27017 --dbpath=/mongodb/data --shutdown
mongo shell
use admin<br>db.shutdownServer()<br>
mongo shell的使用
mongo --port=27017
常用的命令
show dbs | show databases<br>
展示数据库
use 数据库名
切换数据库,如果不存在创建数据库
db.dropDatabase()
删除数据库
show collections | show tables
显示当前数据库的集合列表
db.集合名.stats()
查询集合的详情
db.集合名.drop()
删除集合
show users
显示当前数据库的用户列表
show roles
显示当前数据库下的用户角色
show profile<br>
显示最近发生的操作
load("xxx.js")
加载对应的js脚本
exit | quit()
退出当前shell
db.help()
查看当前数据库支持的方法
db.集合名.help()
db.集合名.help()<br>
db.version()
查看数据库的版本
#创建集合<br>db.createCollection("emp")
安全认证
创建管理员账号
# 设置管理员用户名密码需要切换到admin库<br>use admin<br>#创建管理员<br>db.createUser({user:"root",pwd:"root",roles:["root"]})<br># 查看所有用户信息<br>show users<br>#删除用户<br>db.dropUser("root")<br>
创建应用数据库的账号
use test<br>db.createUser({user:"test",pwd:"test",roles:["dbOwner"]})
默认情况下,MongoDB不会启用鉴权,以鉴权模式启动MongoDB
mongod -f /mongodb/conf/mongo.conf --auth
mongo localhost:27017 -u test -p test --authenticationDatabase=test
文档常用操作
插入<br>
3.2 版本之后新增了 db.collection.insertOne() 和 db.collection.insertMany()<br>
insert: 若插入的数据主键已经存在,则会抛 DuplicateKeyException 异常,提示主键重复,不保<br>存当前数据。
save: 如果 _id 主键存在则更新数据,如果不存在就插入数据。
insertMany:向指定集合中插入多条文档数据
查询
查询一条
db.collection.findOne(query, projection)
条件查询
db.collection.find({字段:条件})
正则表达式匹配查询
//使用正则表达式查找type包含 so 字符串的book<br>db.books.find({type:{$regex:"so"}})<br>//或者<br>db.books.find({type:/so/})
分页&排序
#指定按收藏数(favCount)降序返回<br>db.books.find({type:"travel"}).sort({favCount:-1})
skip用于指定跳过记录数,limit则用于限定返回结果数量。可以在执行find命令的同时指定skip、limit<br>参数,以此实现分页的功能。比如,假定每页大小为8条,查询第3页的book文档:
db.books.find().skip(8).limit(4)<br>
更新<br>
db.collection.update(query,update,options)
query<br>
描述更新的查询条件
update<br>
描述更新的动作及新的内容
options
描述更新的选项<br>
upsert<br>
可选,如果不存在update的记录,是否插入新的记录。默认false,不插入
multi
可选,是否按条件查询出的多条记录全部更新。 默认false,只更新找到的第一条记录
writeConcern
决定一个写操作落到多少个节点上才算成功
更新多条
db.books.update({type:"novel"},{$set:{publishedDate:new Date()}},{"multi":true})
updateMany<br>
更新单个
updateOne
替换单个文档
replaceOne
upsert是一种特殊的更新,其表现为如果目标文档不存在,则执行插入命令。
db.books.update(<br>{title:"my book"},<br>{$set:{tags:["nosql","mongodb"],type:"none",author:"fox"}},<br>{upsert:true}<br>)
nMatched、nModified都为0,表示没有文档被匹配及更新,nUpserted=1提示执行了upsert动作
findAndModify命令<br>
findAndModify兼容了查询和修改指定文档的功能,findAndModify只能更新单个文档<br>
findAndModify会返回修改前的“旧”数据。如果希望返回修改后的数据,则可以指定new选<br>项
findOneAndUpdate
更新单个文档并返回更新前(或更新后)的文档
findOneAndReplace
替换单个文档并返回替换前(或替换后)的文档
删除
remove
db.user.remove({age:28})// 删除age 等于28的记录<br>db.user.remove({age:{$lt:25}}) // 删除age 小于25的记录<br>db.user.remove( { } ) // 删除所有记录<br>db.user.remove() //报错
只删除一条文档
remove命令会删除匹配条件的全部文档,如果希望明确限定只删除一个文档,则需要指定justOne参<br>数,命令格式如下:
db.books.remove({type:"novel"},true)
删除满足条件的首条记录
delete<br>
db.books.deleteMany ({}) //删除集合下全部文档<br>db.books.deleteMany ({ type:"novel" }) //删除 type等于 novel 的全部文档<br>db.books.deleteOne ({ type:"novel" }) //删除 type等于novel 的一个文档
remove、deleteOne等命令在删除文档后只会返回确认性的信息,如果希望获得被删除的文档,则可以<br>使用findOneAndDelete命令
db.books.findOneAndDelete({type:"novel"})
除了在结果中返回删除文档,findOneAndDelete命令还允许定义“删除的顺序”,即按照指定顺序删除找<br>到的第一个文档
db.books.findOneAndDelete({type:"novel"},{sort:{favCount:1}})
remove、deleteOne等命令只能按默认顺序删除,利用这个特性,findOneAndDelete可以实现队列的先进先出。
聚合操作
单一聚合
db.collection.estimatedDocumentCount()<br>
忽略查询条件,返回集合或视图中所有文档的计数<br>
db.collection.count()
返回与find()集合或视图的查询匹配的文档计数 。<br>等同于 db.collection.find(query).count()构造
db.collection.distinct()
在单个集合或视图中查找指定字段的不同值,并在<br>数组中返回结果。
聚合管道
管道(Pipeline)<br>
整个聚合运算过程
阶段(Stage)<br>
常用管道操作
$project<br>
投影
db.books.aggregate([{$project:{name:"$title"}}])<br>
db.books.aggregate([{$project:{name:"$title",_id:0,type:1,author:1}}])
$match<br>
筛选条件<br>
db.books.aggregate([{$match:{type:"technology"}}])
$count
统计
db.books.aggregate([ {$match:{type:"technology"}}, {$count: "type_count"}])
$lookup
连接
db.customer.aggregate([<br>{$lookup: {<br>from: "order",<br>localField: "customerCode",<br>foreignField: "customerCode",<br>as: "customerOrder"<br>}<br>}<br>])
$group
分组
$sort
排序
$skip/$limit
分页
$unwind
展开数组
视图
介绍
MongoDB视图是一个可查询的对象,它的内容由其他集合或视图上的聚合管道定义
作用
数据抽象
保护敏感数据的一种方法<br>
将敏感数据投射到视图之外<br>
只读
基于角色,给与访问权限
应用
创建
删除
db.orderInfo.drop();
修改
索引
介绍
索引是一种用来快速查询数据的数据结构。B+Tree就是一种常用的数据库索引数据结构,MongoDB<br>采用B+Tree 做索引,索引创建在colletions上。MongoDB不使用索引的查询,先扫描所有的文档,再<br>匹配符合条件的文档。 使用索引的查询,通过索引找到文档,使用索引能够极大的提升查询效率。
分类
按照索引包含的字段数量,可以分为单键索引和组合索引(或复合索引)
按照索引字段的类型,可以分为主键索引和非主键索引。
按照索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引,其中聚簇索引是指索<br>引节点上直接包含了数据记录,而后者则仅仅包含一个指向数据记录的指针
按照索引的特性不同,又可以分为唯一索引、稀疏索引、文本索引、地理空间索引等
应用
创建索引
db.collection.createIndex(keys, options)<br>
查询索引
#查看索引信息<br>db.books.getIndexes()<br>#查看索引键<br>db.books.getIndexKeys()<br>
查询索引占用大小
db.collection.totalIndexSize([is_detail])<br>
is_detail:可选参数,传入除0或false外的任意数据,都会显示该集合中每个索引的大小及总大<br>小。如果传入0或false则只显示该集合中所有索引的总大小。默认值为false。
删除索引
#删除集合指定索引<br>db.col.dropIndex("索引名称")<br>#删除集合所有索引<br>db.col.dropIndexes()
操作
单键索引(Single Field Indexes)<br>
在某一个特定的字段上建立索引 mongoDB在ID上建立了唯一的单键索引,所以经常会使用id来进行查<br>询; 在索引字段上进行精确匹配、排序以及范围查找都会使用此索引
复合索引(Compound Index)
复合索引是多个字段组合而成的索引,其性质和单字段索引类似。但不同的是,复合索引中字段的顺<br>序、字段的升降序对查询性能有直接的影响,因此在设计复合索引时则需要考虑不同的查询场景。<br>
多键索引(Multikey Index)
在数组的属性上建立索引。针对这个数组的任意值的查询都会定位到这个文档,既多个索引入口或者键值<br>引用同一个文档
<div>多键索引很容易与复合索引产生混淆,复合索引是多个字段的组合,而多键索引则仅仅是在一个字段上</div><div>出现了多键(multi key)。而实质上,多键索引也可以出现在复合字段上</div>
MongoDB并不支持一个复合索引中同时出现多个数组字段
地理空间索引(Geospatial Index)
在移动互联网时代,基于地理位置的检索(LBS)功能几乎是所有应用系统的标配。MongoDB为地理空<br>间检索提供了非常方便的功能。地理空间索引(2dsphereindex)就是专门用于实现位置检索的一种特<br>殊索引。
db.restaurant.createIndex({location : "2dsphere"})
全文索引(Text Indexes)
MongoDB支持全文检索功能,可通过建立文本索引来实现简易的分词检索。
db.reviews.createIndex( { comments: "text" } )
Hash索引(Hashed Indexes)
不同于传统的B-Tree索引,哈希索引使用hash函数来创建索引。在索引字段上进行精确匹配,但不支持范<br>围查询,不支持多键hash; Hash索引上的入口是均匀分布的,在分片集合中非常有用;
db.users. createIndex({username : 'hashed'})<br>
通配符索引(Wildcard Indexes)
MongoDB的文档模式是动态变化的,而通配符索引可以建立在一些不可预知的字段上,以此实现查询<br>的加速。MongoDB 4.2 引入了通配符索引来支持对未知或任意字段的查询。
db.products.createIndex( { "product_attributes.$**" : 1 } )
属性
唯一索引(Unique Indexes)<br>
部分索引(Partial Indexes)
稀疏索引(Sparse Indexes)
TTL索引(TTL Indexes)
隐藏索引(Hidden Indexes)
建议
为每一个查询建立合适的索引
创建合适的复合索引,不要依赖于交叉索引<br>
复合索引字段顺序:匹配条件在前,范围条件在后(Equality First, Range After)
尽可能使用覆盖索引(Covered Index)
建索引要在后台运行
在对一个集合创建索引时,该集合所在的数据库将不接受其他读写操作。对大数据量的集合建索引,建<br>议使用后台运行选项 {background: true}
explain执行计划详解
db.collection.find().explain(<verbose>)
verbose 可选参数,表示执行计划的输出模式,默认queryPlanner
<div># 未创建title的索引</div><div>db.books.find({title:"book-1"}).explain("queryPlanner")</div>
executionStats
#创建索引<br>db.books.createIndex({title:1})<br>db.books.find({title:"book-1"}).explain("executionStats")
allPlansExecution
allPlansExecution返回的信息包含 executionStats 模式的内容,且包含allPlansExecution:[]块
Zookeeper
介绍
分布式协调框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同<br>步服务、集群管理、分布式应用配置项的管理等。
核心概念
文件系统数据结构<br>
每个子目录项都被称作为 znode(目录节点)
PERSISTENT持久化目录节点<br>
客户端与zookeeper断开连接后,该节点依旧存在,只要不手动删除该节点,他将永远存在
PERSISTENT_SEQUENTIAL持久化顺序编号目录节点<br>
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
EPHEMERAL临时目录节点
客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
Container 节点
3.5.3 版本新增,如果Container节点下面没有子节点,则Container节点<br>在未来会被Zookeeper自动清除,定时任务默认60s 检查一次<br>
TTL 节点
默认禁用,只能通过系统配置 zookeeper.extendedTypesEnabled=true 开启,不稳定
监听通知机制<br>
客户端注册监听它关心的任意节点,<br>或者目录节点及递归子目录节点
如果注册的是对某个节点的监听,则当这个节点被删除,或者被修改时,对应的客户端将被通知
如果注册的是对某个目录的监听,则当这个目录有子节点被创建,或者有子节点被删除,对应<br>的客户端将被通知
如果注册的是对某个目录的递归子节点进行监听,则当这个目录下面的任意子节点有目录结构<br>的变化(有子节点被创建,或被删除)或者根节点有数据变化时,对应的客户端将被通知。
注意:所有的通知都是一次性的,及无论是对节点还是对目录进行的监听,一旦触发,对应的监<br>听即被移除。递归子节点,监听是对所有子节点的,所以,每个子节点下面的事件同样只会被触<br>发一次。
应用场景
分布式配置中心
分布式注册中心
分布式锁<br>
分布式队列
集群选举<br>
分布式屏障<br>
发布/订阅
应用
安装<br>
配置JAVA环境<br>
java ‐version
下载
wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper‐3.5.8/apache‐zookeeper‐3.5.8‐bin.tar.gz
tar ‐zxvf apache‐zookeeper‐3.5.8‐bin.tar.gz
cd apache‐zookeeper‐3.5.8‐bin
重命名配置文件
cp zoo_sample.cfg zoo.cfg
启动zookeeper
# 可以通过 bin/zkServer.sh 来查看都支持哪些参数 <br>bin/zkServer.sh start conf/zoo.cfg
监测是否启动成功
echo stat | nc 192.168.109.200 // 前提是配置文件中中讲 stat 四字命令设置了了白名单 <br>如:<br>4lw.commands.whitelist=stat
连接服务器
bin/zkCli.sh -server ip:port
命令操作
help<br>
查询所有命令
创建zookeeper 节点命令
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
中括号为可选项,没有则默认创建持久化节点
-s: 顺序节点<br>-e: 临时节点<br>-c: 容器节点<br>-t: 可以给节点添加过期时间,默认禁用,需要通过系统参数启用<br>(-Dzookeeper.extendedTypesEnabled=true, znode.container.checkIntervalMs : (Java system property only) New in 3.5.1: The time interval in milliseconds for each check of candidate container and ttl nodes. Default is "60000".)<br>
创建
create /test niubi<br>
查看节点
get /test<br>
修改节点
set /test niubi1
查看节点状态
stat /test<br>
Stat<br>cZxid:创建znode的事务ID(Zxid的值)。<br>mZxid:最后修改znode的事务ID。<br>pZxid:最后添加或删除子节点的事务ID(子节点列表发生变化才会发生改变)。<br>ctime:znode创建时间。<br>mtime:znode最近修改时间。<br>dataVersion:znode的当前数据版本。<br>cversion:znode的子节点结果集版本(一个节点的子节点增加、删除都会影响这个版本)。<br>aclVersion:表示对此znode的acl版本。<br>ephemeralOwner:znode是临时znode时,表示znode所有者的 session ID。 如果znode不是临时znode,则该字段设置为零。<br>dataLength:znode数据字段的长度。<br>numChildren:znode的子znode的数量。
创建子节点
create /test/test1
查看子节点信息,比如根节点下面的所有子节点, 加一个大写 R 可以查看递归子节点列表<br>
ls -R /test
监听
针对节点的监听:一定事件触发,对应的注册立刻被移除,所以事件监听是一次性的<br>
get -w /path // 注册监听的同时获取数据<br>stat -w /path // 对节点进行监听,且获取元数据信息
针对目录的监听
ls -w /path
针对递归子目录的监听
ls -R -w /path : -R 区分大小写,一定用大写
Zookeeper事件类型
None: 连接建立事件<br>NodeCreated: 节点创建<br>NodeDeleted: 节点删除<br>NodeDataChanged:节点数据变化<br>NodeChildrenChanged:子节点列表变化<br>DataWatchRemoved:节点监听被移除<br>ChildWatchRemoved:子节点监听被移除
ACL 权限控制( Access Control List )
可以控制节点的读写操作,保证数据的安全性,Zookeeper ACL 权限设置分为 3 部分组成,分别是:权限模式(Scheme)、授权对象(ID)、权限信息(Permission)。最终组成一条例如“scheme:id:permission”格式的 ACL 请求信息
Scheme(权限模式)
用来设置 ZooKeeper 服务器进行权限验证的方式
种是范围验证。所谓的范围验证就是说 ZooKeeper 可以针对一个 IP 或者一段 IP 地址授予某种权限。比如我们可以让一个 IP 地址为“ip:192.168.0.110”的机器对服务器上的某个数据节点具有写入的权限。或者也可以通过“ip:192.168.0.1/24”给一段 IP 地址的机器赋权。
另一种权限模式就是口令验证,也可以理解为用户名密码的方式。在 ZooKeeper 中这种验证方式是 Digest 认证,而 Digest 这种认证方式首先在客户端传送“username:password”这种形式的权限表示符后,ZooKeeper 服务端会对密码 部分使用 SHA-1 和 BASE64 算法进行加密,以保证安全性。
还有一种Super权限模式, Super可以认为是一种特殊的 Digest 认证。具有 Super 权限的客户端可以对 ZooKeeper 上的任意数据节点进行任意操作。
授权对象(ID)
授权对象就是说我们要把权限赋予谁,而对应于 4 种不同的权限模式来说,如果我们选择采用 IP 方式,使用的授权对象可以是一个 IP 地址或 IP 地址段;而如果使用 Digest 或 Super 方式,则对应于一个用户名。如果是 World 模式,是授权系统中所有的用户。
生成授权ID的两种方式
@Test<br>public void generateSuperDigest() throws NoSuchAlgorithmException {<br> String sId = DigestAuthenticationProvider.generateDigest("gj:test");<br> System.out.println(sId);// gj:X/NSthOB0fD/OT6iilJ55WJVado=<br>}
在xshell 中生成
echo -n <user>:<password> | openssl dgst -binary -sha1 | openssl base64
权限信息(Permission)
权限就是指我们可以在数据节点上执行的操作种类
数据节点(c: create)创建权限,授予权限的对象可以在数据节点下创建子节点;<br>数据节点(w: wirte)更新权限,授予权限的对象可以更新该数据节点;<br>数据节点(r: read)读取权限,授予权限的对象可以读取该节点的内容以及子节点的列表信息;<br>数据节点(d: delete)删除权限,授予权限的对象可以删除该数据节点的子节点;<br>数据节点(a: admin)管理者权限,授予权限的对象可以对该数据节点体进行 ACL 权限设置。<br>
设置ACL有两种方式
节点创建的同时设置ACL<br>create [-s] [-e] [-c] path [data] [acl]
create /zk-node datatest digest:gj:X/NSthOB0fD/OT6iilJ55WJVado=:cdrwa
setAcl /zk-node digest:gj:X/NSthOB0fD/OT6iilJ55WJVado=:cdrwa
访问前需要添加授权信息<br>
addauth digest gj:test<br>get /zk-node<br>datatest
auth 明文授权
使用之前需要先<br>addauth digest username:password 注册用户信息,后续可以直接用明文授权
addauth digest u100:p100<br>create /node-1 node1data auth:u100:p100:cdwra<br>这是u100用户授权信息会被zk保存,可以认为当前的授权用户为u100<br>get /node-1<br>node1data
<div yne-bulb-block="paragraph" style="white-space: pre-wrap; line-height: 1.75; font-size: 14px;">IP授权模式</div><br>
setAcl /node-ip ip:192.168.109.128:cdwra<br>create /node-ip data ip:192.168.109.128:cdwra
多个指定IP可以通过逗号分隔, 如 setAcl /node-ip ip:IP1:rw,ip:IP2:a
Super 超级管理员模式
这是一种特殊的Digest模式, 在Super模式下超级管理员用户可以对Zookeeper上的节点进行任何的操作。
需要在启动了上通过JVM 系统参数开启<br>
<div yne-bulb-block="code" data-theme="default" style="white-space:pre-wrap;" data-language="java">DigestAuthenticationProvider中定义<br>-Dzookeeper.DigestAuthenticationProvider.superDigest=super:<base64encoded(SHA1(password))<br></div>
getAcl:获取某个节点的acl权限信息<br>setAcl:设置某个节点的acl权限信息<br>addauth: 输入认证授权信息,相当于注册用户信息,注册时输入明文密码,zk将以密文的形式存储
可以通过系统参数zookeeper.skipACL=yes进行配置,默认是no,可以配置为true, 则配置过的ACL将不再进行权限检测
内存数据和持久化<br>
内存数据
public class DataTree {<br> private final ConcurrentHashMap<String, DataNode> nodes =<br> new ConcurrentHashMap<String, DataNode>();<br> <br> <br> private final WatchManager dataWatches = new WatchManager();<br> private final WatchManager childWatches = new WatchManager();
DataNode 是Zookeeper存储节点数据的最小单位
public class DataNode implements Record {<br> byte data[];<br> Long acl;<br> public StatPersisted stat;<br> private Set<String> children = null;<br>
<div yne-bulb-block="paragraph" style="white-space: pre-wrap; line-height: 1.75; font-size: 14px;"><span style="font-weight: bold;">事务日志</span></div>
针对每一次客户端的事务操作,Zookeeper都会将他们记录到事务日志中,当然,Zookeeper也会将数据变更应用到内存数据库中。我们可以在zookeeper的主配置文件zoo.cfg 中配置内存中的数据持久化目录,也就是事务日志的存储路径 dataLogDir. 如果没有配置dataLogDir(非必填), 事务日志将存储到dataDir (必填项)目录,<br>zookeeper提供了格式化工具可以进行数据查看事务日志数据 <br>org.apache.zookeeper.server.LogFormatter
java -classpath .:slf4j-api-1.7.25.jar:zookeeper-3.5.8.jar:zookeeper-jute-3.5.8.jar org.apache.zookeeper.server.LogFormatter /usr/local/zookeeper/apache-zookeeper-3.5.8-bin/data/version-2/log.1
Zookeeper进行事务日志文件操作的时候会频繁进行磁盘IO操作,事务日志的不断追加写操作会触发底层磁盘IO为文件开辟新的磁盘块,即磁盘Seek。因此,为了提升磁盘IO的效率,Zookeeper在创建事务日志文件的时候就进行文件空间的预分配- 即在创建文件的时候,就向操作系统申请一块大一点的磁盘块。这个预分配的磁盘大小可以通过系统参数 zookeeper.preAllocSize 进行配置。<br>
数据快照
数据快照用于记录Zookeeper服务器上某一时刻的全量数据,并将其写入到指定的磁盘文件中
可以通过配置snapCount配置每间隔事务请求个数,生成快照,数据存储在dataDir 指定的目录中,<br>可以通过如下方式进行查看快照数据( 为了避免集群中所有机器在同一时间进行快照,实际的快照生成时机为事务数达到 [snapCount/2 + 随机数(随机数范围为1 ~ snapCount/2 )] 个数时开始快照)
java -classpath .:slf4j-api-1.7.25.jar:zookeeper-3.5.8.jar:zookeeper-jute-3.5.8.jar org.apache.zookeeper.server.SnapshotFormatter /usr/local/zookeeper/apache-zookeeper-3.5.8-bin/data-dir/version-2/snapshot.0<br>
快照事务日志文件名为: snapshot.<当时最大事务ID>,日志满了即进行下一次事务日志文件的创建
有了事务日志,为啥还要快照数据。<br>快照数据主要时为了快速恢复,事务日志文件是每次事务请求都会进行追加的操作,而快照是达到某种设定条件下的内存全量数据。所以通常快照数据是反应当时内存数据的状态。事务日志是更全面的数据,所以恢复数据的时候,可以先恢复快照数据,再通过增量恢复事务日志中的数据即可
集群搭建
应用实战
分布式锁
优点:ZooKeeper分布式锁(如InterProcessMutex),具备高可用、可重入、阻塞锁特<br>性,可解决失效死锁问题,使用起来也较为简单。<br>缺点:因为需要频繁的创建和删除节点,性能上不如Redis。<br>在高性能、高并发的应用场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper<br>的高可用性,因此在并发量不是太高的应用场景中,还是推荐使用ZooKeeper的分布式锁。
第三方的Java客户端API,比如Curator。<br>
注册中心<br>
保证CP
Zookeeper写入是强一致性,读取是顺序一致性。

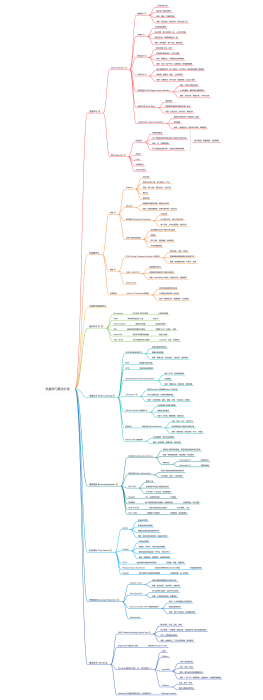
Collect
Get Started

Collect
Get Started
Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

