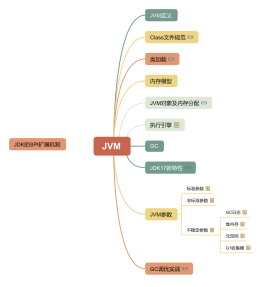
垃圾收集算法
标记-清除
标记
找出内存中需要回收的对象,并且把它们标记出来
堆中所有的对象都会被扫描一遍,从而才能确定需要回收的对象,比较耗时
清除
清除掉被标记需要回收的对象,释放出对应的内存空间
缺点
标记和清除俩个过程都比较耗时,效率不高
会产生大量内存碎片,导致创建大对象时连续内存不够而提前触发另一次垃圾收集
标记-复制
将内存分为俩块相等的区域,每次只是用其中一块
当其中一块内存使用完了,就将存活的对象复制到另一块,然后把使用过的空间一次清除掉
缺点
空间利用率低
在对象存活率较高时就要进行较多的复制操作,效率会变低
如果不想浪费50%的空间没,就需要额外的空间进行分配担保,应对所有对象都有100%存活的情况,所以老年代一般不能直接选用这种算法
标记-整理
标记
找出内存中需要回收的对象,并且把它们标记出来
堆中所有的对象都会被扫描一遍,从而才能确定需要回收的对象,比较耗时
让所有存活的对象都向一端移动,清理掉边界以外的内存
垃圾收集器
Serial
JDK1.3.1之前是虚拟机新生代收集的唯一选择
单线程收集齐,进行垃圾收集的时候需要暂停其它线程
Serial Old
Serial Old收集器是Serial的老年代版本
也是一个单线程收集器,不同的是采用了标记-整理算法
ParNew
可以把这个收集器理解为Serial的多线程版本
缺点
收集过程暂停所有应用程序线程,单CPU时比Serial效率差
应用
运行在Server模式下的虚拟机中首选的新生代收集器
Parallel Scavenge
Parallel Scavenge收集器是一个新生代收集器
它也是使用复制算法的收集器,又是并行的多线程收集器
看上去和ParNew一样,但是Parallel Scavenge更关注系统的吞吐量
吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)
吞吐量越大,垃圾收集的时间越短,则用户代码可以充分利用CPU资源,尽快完成程序的运算任务
Parallel Old
Parallel Old是Parallel Scavenge收集器的老年代版本
使用多线程和标记-整理算法进行垃圾回收
也是更关注系统的吞吐量
CMS
CMS收集器是一种以获取最短回收停顿时间为目标的收集器
采用的是标记-清除算法,整个过程分为4步
1.初始标记
标记GC Roots直接关联对象,不用Tracing,速度很快
2.并发标记
进行GC Roots Tracing
4.并发清除
清除不可达对象回收空间,同时有新垃圾产生,留着下次清理称为浮动垃圾
整个过程中,并发标记和并发清除,收集器线程可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的
缺点
产生大量空间碎片、并发阶段会降低吞吐量,还会并发失败
background模式为正常模式执行上述的CMS GC流程
forefroud模式为Full GC模式
G1(Garbage-First)
G1收集器的堆内存布局与其它收集器有很大差别,G1将整个java堆划分为多个大小相等的独立区域(Region)
虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分Region(不需要连续)的集合
每个Region大小都是一样的,可以是1M到32M之间的数值,但是必须保证是2的n次幂
如果对象太大,一个Region放不下[超过Region大小的50%],那么就会直接放到H中
所谓Garbage-Frist,其实就是优先回收垃圾最多的Region区域
1.分代收集(仍然保留了分代的概念)
2.空间整合(整体上属于“标记-整理”算法,不会导致空间碎片)
3.可预测的停顿(比CMS更先进的地方在于能让使用者明确指定一个长度为M毫秒的时间片段内,消 耗在垃圾收集上的时间不得超过N毫秒)
工作过程
初始标记(Initial Marking)
标记以下GC Roots能够关联的对象,并且修改TAMS的值,需要暂 停用户线程
并发标记(Concurrent Marking)
从GC Roots进行可达性分析,找出存活的对象,与用户线程并发 执行
最终标记(Final Marking)
修正在并发标记阶段因为用户程序的并发执行导致变动的数据,需 暂停用户线程
筛选回收(Live Data Counting and Evacuation)
对各个Region的回收价值和成本进行排序,根据 用户所期望的GC停顿时间制定回收计划