MySQl 知识点
2022-02-27 12:59:00 37 举报AI智能生成
MySQL是一种关系型数据库管理系统,它使用结构化查询语言(SQL)进行数据操作。MySQL具有高性能、稳定性强、易于使用等特点,广泛应用于各种规模的应用程序开发中。MySQL支持多种操作系统,如Windows、Linux等,同时也提供了多种客户端工具,方便用户进行管理和操作。在MySQL中,数据以表格的形式存储,每个表格由行和列组成,可以通过SQL语句对表格进行增删改查等操作。此外,MySQL还支持事务处理、存储过程、触发器等功能,能够满足复杂业务需求。总之,MySQL是一款功能强大、应用广泛的数据库管理系统,是开发人员必备的技能之一。
模板推荐
作者其他创作
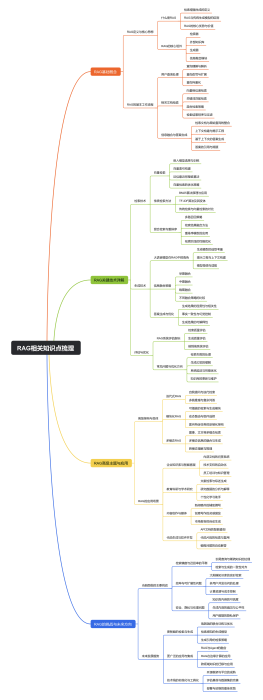
大纲/内容






0 条评论
下一页

