5.提交job
3.定义Mapper和Reducer
解析器:将SQL字符串转换成抽象的语法书AST,这一步一般都用第三方工具库完成,比如:antlr、对AST进行语法分析,比如表是否存在,字段时候存在,SQL语义是否正确
1.获取MR临时工作目录
ExecDriver
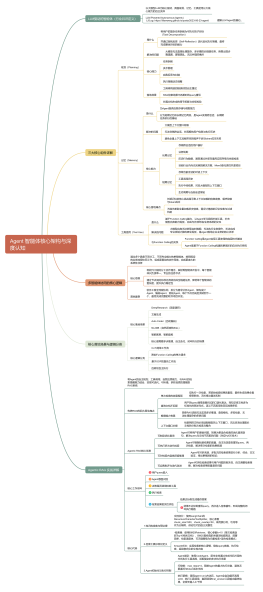
1.进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);2.遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元;3.遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;4.使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;5.遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;6.使用物理优化器对TaskTree进行物理优化;7.生成最终的执行计划,提交任务到Hadoop集群运行。
HDFS
执行器:把逻辑计划转换成可以运行的物理计划。对于hive来说,MR/Spark
CLI (command-line-interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
Query Optimizer执行器
Drive
JDBC
Meta strore
CliDriver
2.对Token进行解析,生成AST
Execution执行器
$HIVE_HOME/bin/hiveselect ....
CLI
3.提交任务执行
2.定义Partitioner
SQL Parder解析器
2.将AST转换为TaskTree
5.TaskTre执行物理优化
4.生成TaskTree
1.解析客服端“-e -f”等参数
client
优化器:对逻辑执行计划进行优化
1.将HQL语句转换为Token
HQL 转换为MR的核心流程
用户接口:Client
4.实例化job
Driver
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表数据所在的目录等
1.将AST转换为QueryBlock
SemanticAnalyzer
使用HDFS做储存,MapReduce进行计算
HQL编译为MR任务流程介绍
2.定义标准输入输出流
1.将HQL语句转换成AST
说明
2.将QueryBlock转换为OperatorTree
四个器:
3.OperatorTree进行逻辑优化
编译器:将AST语法书编译生成逻辑执行计划
Physical Plan编译器
MapReduce
元数据:Metstore
PaserDriver
3.然后按照“;”切分HQL语句
Hive架构
Hadoop: