Vision-Transformer
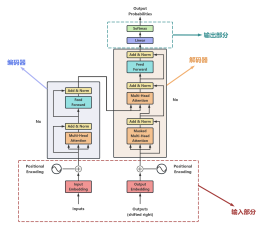
2021-10-24 16:25:55 98 举报Vision-Transformer是一种基于自注意力机制的深度学习模型,用于计算机视觉任务。它由多个编码器层和解码器层组成,每个层都包含多头自注意力机制、位置编码和前馈神经网络。与传统的卷积神经网络不同,Vision-Transformer不需要局部感受野或卷积操作,而是直接对整个图像进行处理。这使得它可以更好地捕捉全局信息和长距离依赖关系,从而提高了图像分类、目标检测等任务的性能。此外,Vision-Transformer还具有较低的计算复杂度和内存占用量,可以在大规模数据集上进行高效的训练和推理。
模板推荐
作者其他创作
大纲/内容


Collect

Collect
Collect

Collect
0 条评论
下一页