
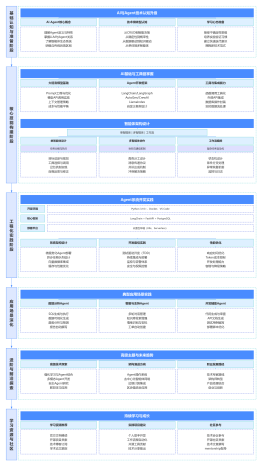
大数据学习路线
2021-11-09 23:15:56 84 举报AI智能生成
年轻人做一件事情的时候记得先考虑清楚!从入门到放弃
大数据
模板推荐
作者其他创作
大纲/内容
大数据开发基础
编程语言
<span style="font-size: inherit;"><b><font color="#f44336">Java</font></b></span><br>
<b>语言基础</b>
基础语法
面向对象
接口
容器
异常
泛型
反射
注解
I/O
JVM虚拟机
类加载机制
字节码执行机制
JVM内存模型
GC垃圾回收
JVM性能监控与故障定位
JVM调优
并发/多线程编程
并发编程基础
线程池
锁
原子类
并发容器
JUC并发工具类
Scala
基础语法
类型系统
类和对象
函数和闭包
字符集/数组/集合
迭代器
Trait
模式匹配和正则
隐式转换
函数式编程范式
Actor编程
数据结构和算法
数据结构
字符串
数组
链表
堆
栈
队列
树
哈希
图
算法
基本算法
查找
排序
算法思想
枚举
递归
贪心
分治
动态规划
回溯
计算机网络
体系结构和分层模型
ARP/RARP协议
IP/ICMP协议
TCP/UDP协议
DNS/HTTP/HTTPS协议
Session/Cookie/Token等概念
操作系统
进程与线程
内存管理和调度
I/O原理
文件管理
数据库基础
SQL语句书写
SQL语句优化
数据库规范化设计
事务/隔离级别/并发/索引等重要机制
设计模式
单例
工厂
代理
策略
模板方法
观察者
适配器
责任链
Linux系统
系统部署与安装
基本命令和配置
常用系统和网络管理
基本的shell编程
服务/软件部署
基本开发工具
Linux操作系统
Centos
Ubuntu
.......
SSH终端
SecureCRT
Mobaxterm
Xshell
...
FTP/SFTP工具
WinSCP
FileZilla
Transmit
...
IDE
IDEA
Eclipse
...
源码控制工具
Git
SVN
构建工具
Maven
Gradle
数据采集
数据采集
Flume
概念
分布式数据采集和聚合框架
基本组件和架构
组件
Event:数据基本单元
Soure:数据的收集端
Channel:临时存储数据的管道
Sink:从Channel中取数据
Agent
架构模式
单Agent
串联Agent
并联Agent
安装部署
数据采集流程
Source
HTTP Source
Avro Source
Kafka Source
Channel
Menory Channel
JDBC Channel
File Channel
Sink
HDFS Sink
Avro Sink
Sink Processor
Default Sink Processor
Load Balancing Sink Processor
Failover Sink Processor
Selector
复制模式
多路复用模式
Interceptor
Timestamp Interceptor
Static Interceptor
Regex Interceptor
Logstash
概念
开源数据收集引擎
安装部署
数据采集流程
input
filter
output
强大的插件功能
数据迁移
Sqoop
概念
下载和配置安装
基本命令和使用
数据传输实战
DataX
数据存储
数据库
关系型数据库
MySQL
SQL Server
Oracle
非关系型数据库
Redis
MongDB
Neo4J
InfluxDB
...
搜索引擎
Elasticsearch
作用<br>
分布式、Rest风格的全文搜索引擎
基础概念
节点
集群
分片
副本
类型
文档
索引
路由
映射
安装部署
单节点方式
多借点集群方式
数据类型
基础类型
复杂类型
基本操作(含API使用)
索引操作
增/删/改/查
文档操作
增/删/改/查
分词
同义词
高亮
推荐
基本检索
结构化检索
全文检索
复合检索
特殊检索
基本聚合
Metric聚合
Buckting聚合
Pipeline聚合
Matrix聚合
集群运维
集群状态
集群扩展
集群安全
集群监控
集群备份
调优
写入优化
检索/聚合优化
索引优化
磁盘读写优化
数据模型优化
集群部署优化
分布式文件系统
HDFS
基本概念和架构
概念
Hadoop分布式文件系统
基本架构
Blocks
NameNode
DataNode
平台主要特点
高容错
高吞吐量
大数据量支持
基本使用
命令行接口
创建目录/文件
删除文件/目录
查看文件内容
导入/导出文件
拷贝/修改文件
....
对应的API编程接口
核心机制理解
数据读写原理
数据复制和原理
副本策略
路由策略
心跳机制
快照机制
缓存机制
认证机制
...
GlusterFS
KFS
Ceph
Tachyon
...
分布式数据库
HBase
基本概念和架构
概念
面向列的分布式数据库
基本数据模型
NameSpace
Table
Row
Column
TimeStamp
Cell
基本架构
Client
ZooKeeper
Master
Region Server
安装部署和环境搭建
Standalone/伪集群模式
集群模式
常用操作
基本Shell命令
状态/版本/Help命令
表操作
增删改查
对应的API编程接口
重要机制和原理
存储原理
读写流程
复制原理
负载均衡原理
容灾与备份机制
宕机恢复和故障处理
...
数据仓库
Hive
概念
一款构建在Hadoop之上的数据仓库
Hive架构
用户接口
CLI
Web GUI
JDBC/ODBC
MetaStore
元数据服务
Driver
SQL的解析器、编译器、执行器、优化器
HiveServer2
beline
安装部署
内嵌模式
Local模式
远程模式
数据类型
基本数据类型
整型
浮点型
字符串
日期
布尔
复杂数据类型
array
map
struct
常用操作
Hive基本命令
基本shell命令
Hive service
库表定义
数据库操作
创建数据库
修改数据库
删除数据库
查看数据库
数据表操作
创建表
创建表
复制表
克隆表
临时表
内部表
分区表
分桶表
修改表
修改表名
修改表字段
修改表的属性
...
查看表
删除表
清空表
数据操作
插入数据
导入数据
导出数据
查询数据
设置支持事务操作
删除数据
修改数据
分区操作
创建分区
添加分区
删除分区
查看分区
修复分区
重命名分区
动态分区
分桶操作
创建
加载
使用
索引
创建
查看
更新
删除
视图
创建
查看
删除
修改
函数
数值修改
字符串函数
时间函数
日期函数
条件函数
聚合函数
自定义函数
排序
order by全局排序
sort by局部排序
distribute by分区排序
cluster by
窗口函数
Windows子句
序列函数
调优
fetch抓取策略
join优化
group by优化
count优化
表数据压缩
数据倾斜问题
并行执行机制
严格模式
JVM重用机制
推测执行机制
...
ClickHouse
Pig
Lylin
Presto
数据处理
通用计算
MapReduce
基本概念
分布式计算编程框架,用于便写针对于大数据的批处理程序
主要工作流理解
输入
拆分
映射
输出
编程实践
作业配置
作业提交/监控
作业输入/输出
任务运行
Mapper/Reducer/Driver编写实现
Combiner/Partitioner编写实现
重要机制理解掌握
作业通信协议
作业提交与初始化
任务分配和执行
JobTracke内部实现
TaskTracke内部实现
Task运行过程
Spark
概念
分布式计算框架
Spark部署模式
Locall模式
Standalone模式/HA
Spark on Yam模式
核心组件
Spark-Code
RDD核心
RDD概念
RDD创建
操作RDD
RDD缓存
宽窄依赖
DAG
常用转换/行动算子
键值对操作
连接/聚合操作
数据分区
函数传递
分布式共享变量
广播变量
累加器
Spark-SQL
概念
Spark子模块,主要用于操作结构化数据
编程抽象
DataFrame
DataSet
DataFrame/DataSet创建和转换
基本的结构化操作
各种数据类型的处理
聚合操作
连接操作
自定义函数
Spark-Streaming
概念
Spark流式计算子模块
DStream核心
创建
输入/输出
转换
实战练手
聚合Kafka等
Spark-MLlib
概念
Spark机器学习子模块,包含各种高级分析工具包和算法
基础编程接口
算法应用实践
特征工程
特征提取
特征转换
特征降维
特征选择
分类/回归
逻辑回归
朴素贝叶斯
KNN
SVN
决策树
随机森林
梯度增强树
广义线性回归
子主题
..
无监督学习
GMM高斯混合
LDA
...
推荐系统
交替最小二乘法(ALS)
...
深度学习
Storm
基本概念和框架
简介
分布式实时计算框架
<div><span style="font-size: inherit;">核心概念</span><br></div>
Topologies拓扑
Spouts数据源
Bolts数据流处理组件
Streams数据流
Tuple元组
Reliability
Tasks
Workers
核心框架
Nimbus进程
Supervisor进程
Worker进程
Executo线程
Zookeeper
开发环境搭建
单机环境
集群环境
重要机制掌握
数据分组策略
Shuffle Grouping随机分组
Field Grouping按字段分组
Global Grouping全局分组
Direct Grouping指向型分组
并发机制
并行度配置
Worker数量
Executor数量
Task数量
Acker设置
修改运行中的拓扑的并行度
Rebalance再平衡
通信机制
Worker进程间的数据通信
Worker内部的数据通信
Worker内部的消息传递机制
容错机制
集群节点故障
进程挂掉
当Worker进程挂掉
当Nimbus进程挂掉
当Supervisor进程挂掉
消息的可靠性
消息的完整性处理
消息的生命周期
相关的可靠性API
Storm编程模型
本质:编写各个类的实现,以及数据源输入的编写
设计Topolog结构
编写数据流
Spout数据源
实现Spout接口
继承BaseRichSpout抽象类
...
Bolt处理单元
实现Bolt接口
继承BaseRichBolt抽象类
...
TopologBuilder
Storm其他编程实战
集成HDFS
集成Hbase
集成Kafka
集成Redis
...
Flink
基本概念和架构
基本概念
开源流处理架构
分层架构
APIs & Libraries层
提供编程API和类库
Runtime Core层
计算框架的核心实现
Deploy层
不同平台上部署
运行组件
JobManager
Client
TasManager
分层API编程
SQL/Table API
DataStream API
DataSet API
ProcessFunction
开发环境安装部署
Local模式
Standalone Cluster/Standalone Cluster HA
Flink on Yam
Flink on K8s
数据处理(流操作)
数据源Source
内置数据源
文件数据源
聚合数据源
Socker数据源
Connectors连接器
Kafka Connector
HDFS Connector
Redis Connector
...
自定义数据源
SourceFunction
ParallelSourceFunction
...
数据转换Transfirmation
DataStreamTransformations
Map
Filter
Reduce
Fold
...
Physical partitioning
Random partitioning
Reblaancing
Rescaling
Broadcasting
Custom partitioning
Task chaining and resource groups
数据输出Sink
Collection-based-sink
File-based-sink
Streaming Connectors
....
窗口机制
窗口类型
时间窗口
滚动窗口
滑动窗口
会话窗口
计数窗口
滚动窗口
滑动窗口
分配器Assigner
滑动窗口
滚动窗口
会话窗口
全局窗口
窗口函数Function
ReduceFunction
AggregateFunction
FoldFunction
ProcessWindowFunction
...
触发器Trigger
EventTimeTrigger
ProcessingTimeTrigger
CountTrigger
PurgingTrigger
其他自定义触发器
驱逐器Evictor
收集器Collector
其他特征
数据延迟
测流输出
Watermark
其他主要机制
Checkpoint
Savepoint
State
数据价值和应用
数据加工输出
DB
文件
FTP服务器
...
统计报表
数据推荐/预测
关键指标度量
智能图表
数据大屏
数据地图
数据仪表
...
模型决策
流程优化
风险控制
智能预警
增值服务
...
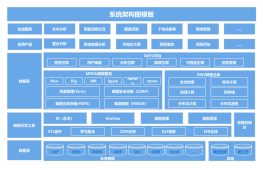
大数据集群周边技术
集群部署/管理/监控
Ambari
概念
基于Web方式的大数据集群配置、管理和管理工具
体系架构
Ambari Server
Ambari Agent
实战
安装配置
部署/管理Hadoop集群
Cloudera Manager
概念
Cloudera开发的一款大数据集群安装/管理/监听利器
主要成分
Agent
Server
Management Service
Database
Cloudera Repository
Client
实战
安装配置
部署/管理Hadoop集群
资源管理/任务调度
YARN
概念
资源管理框架
安装配置
基本架构
执行流程理解
Oozie
概念
一个开源的工作流调度引擎
安装配置
主要组件
workflow
coordinator
bundle
常用命令
提交任务
启动任务
开始任务
停止任务
查看任务执行
...
Azkaban
概念
工作流调度系统
核心概念
Job
Flow
Flow 1.0
Flow 2.0
架构
WebServer
Executor Server
集群高可用
Zookeeper
简介
开源分布式协调服务、分布式服务管理框架
安装搭建
单机环境
集群环境
核心概念
设计目标
简单的数据模型
构建集群
顺序访问
高可用
集群角色
Leader
Follower
Observer
节点
数据节点
持久节点
临时节点
顺序节点
节点信息
znode结构
会话(Session)
ACL策略
Watcher
ZAB协议
广播模式
恢复模式
常用CLI命令
help
ls/ ls2
set / get
stat
create / delete
...
客户端
Curator
使用最广泛
zkClient
应用场景
数据分布/订阅
Master选举
分布式锁/分布式队列
分布式协调/通知
集群管理
其他中间件技术
kafka
基本概念/架构
概念
高吞吐量的分布式分布订阅消息系统、分布式的流处理平台
组件
Message
Topic
Partition
Consumer
Broker
Zookeeper
集群安装搭建
Zookeeper集群搭建
kafka集群搭建
核心机制
系统页缓存
批处理
零拷贝技术
数据压缩
负载均衡
分区机制partition
副本机制
leader选举算法
消息持久化
工作流程理解
生产过程
创建生产者
属性设置
发送消息
同步
异步
分区
序列化
副本
写入流程
Broker保存消息
存储方式
存储策略
存储结构
消费过程
创建消费者
属性设置
订阅主题
轮询
提交
再均衡
消费者组
使用
命令行
创建topic
查看topic
创建provider
创建comsumer
API使用
Producer API
Consumer API
Streams API
Connect API
Admin API
应用场景
常规的消息系统
系统间解耦
峰值压力缓冲
异步通信
流处理
...
自由主题


Collect
Get Started
Collect
Get Started

Collect
Get Started
Collect
Get Started
评论
0 条评论
下一页

