Redis原理Redis性能优化面试题集群
2022-09-25 18:48:22 4 举报AI智能生成
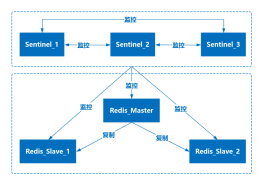
jk时间redis原理学习笔记脑图整理redis集群redis同步原理
模板推荐
作者其他创作
大纲/内容




0 条评论
下一页

