
机器学习-学习笔记
2024-07-04 18:24:43 0 举报AI智能生成
机器学习是一种使计算机系统在没有明确编程的情况下自动学习和改进的方法。核心内容包括监督学习、无监督学习以及强化学习等。监督学习通过标记训练数据预测新实例,而无监督学习则通过发现数据中的结构或模式来进行学习。强化学习则是机器学习的一种,通过试错来提高其在特定任务中的性能。文件类型主要涉及数据文件和模型文件等,包括.csv、.xlsx、.txt、.json等。修饰语包括自学、自适应、智能化等,这些都体现了机器学习的能力和特性。
机器学习
学习笔记
数据分析
模板推荐
作者其他创作
大纲/内容
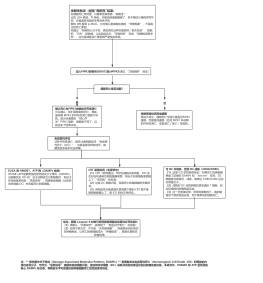
机器学习关键代码(Scikit - learn)<br>
标准化/归一化<br>
标准化
公式
<font color="#0000ff">( x - np.mean ) / (np.std)</font><br>
导入库<br>
<font color="#388e3c">from sklearn.preprocessing import StandardScaler</font><br>
代码
<font color="#ff0000">std_scaler = StandardScaler() # 创建对象<br>results = std_scaler.fit_transform(df_work['列名']) <br>print(results) </font> <font color="#ff00ff"># 其结果是一个numpy array</font><br>
归一化
公式
<font color="#0000ff">(x - min) / (max - min)</font><br>
导入库
<font color="#388e3c">from sklearn.preprocessing import MinMaxScaler</font><br>
代码
<font color="#ff0000">mmx_scaler = MinMaxScaler()<br>df_work['列名'] = mmx_scaler.fit_transform(df_work['列名'])<br>df_work.head()</font><br>
基础填充
<font color="#ff0000">data[x].fillna(data[x].mode().iloc[0], inplace = True)</font><font color="#000000">(以众数填充)</font><br>
数值化
OrdinalEncoder
导入库
<font color="#388e3c">from sklearn.preprocessing import OrdinalEncoder</font>
代码
<font color="#ff0000">encoder = OrdinalEncoder()<br>encoder.fit(df.loc[:, ['学历要求','工作经验']]) # 即使只有1个列,也必须将列名写在[]中<br>data_encoded = encoder.transform(df.loc[:, ['学历要求','工作经验']]) <br>df['学历要求_ordinal'] = data_encoded[:, 0]<br>df['工作经验_ordinal'] = data_encoded[:, 1]</font><br>
OneHotEncoder<br>
导入库
<font color="#388e3c">from sklearn.preprocessing import OneHotEncoder</font>
代码
<font color="#ff0000">encoder = OneHotEncoder()<br>encoder.fit(df.loc[:, ['学历要求']]) # 即使只有1个列,也必须将列名写在[]中<br>data_onehot = encoder.transform(df.loc[:, ['学历要求']]).toarray() # 使用toarray获得转换以后的OneHot编码数组</font><br>
调优
导入库
<font color="#388e3c">from sklearn.model_selection import GridSearchCV</font><br>
代码
<font color="#ff0000">param_grid = {'learning_rate': [0.1 0.01],<br> 'max_depth': [2, 4],<br> 'min_samples_leaf': [5, 9],<br> 'max_features': [1.0, 0.8]<br> }<br># 实例化gbm分类模型gbm_2<br>gbm_2 = GradientBoostingClassifier(n_estimators=3000)<br><br># 实例化GridSearchCV并执行训练<br>gbm_gs = GridSearchCV(gbm_2, param_grid, cv=10).fit(train_X, train_y)</font><br>
划分数据集和验证集<br>
导入库<br>
<font color="#388e3c">from sklearn.model_selection import train_test_split</font><br>
代码
data_X, val_X, data_y, val_y = train_test_split(dataX, dataY, test_size=<font color="#ff0000">(划分比例)</font>,random_state = <font color="#ff0000">(随机状态)</font>)<br>
<b style=""><font color="#0097a7">算法</font></b>
<font color="#0097a7">决策树</font><br>
导入库<br>
<font color="#388e3c">from sklearn import tree</font><br>
代码
<font color="#ff0000">clf = tree.DecisionTreeClassifier(random_state = 1)<br>clf = clf.fit(data_X, data_y)<br>clf.score(val_X, val_y)</font>
<font color="#0097a7">随机森林</font><br>
导入库
<font color="#388e3c">from sklearn.ensemble import RandomForestClassifier</font>
代码
<font color="#ff0000">rf = RandomForestClassifier(random_state=1)<br>rf = rf.fit(train_X, train_y)<br>a = rf.predict(val_X) </font><font color="#000000">#预测</font><br><font color="#ff0000">accuracy1 = accuracy_score(val_y, a) </font><font color="#000000">#正确率</font><br><font color="#ff0000">accuracy1</font>
<font color="#0097a7">GBM</font>
导入库
<font color="#388e3c">from sklearn.ensemble import GradientBoostingClassifier</font><br>
代码
<font color="#ff0000">gbm = GradientBoostingClassifier(random_state=1, n_estimators = 1000, learning_rate = 0.1, max_depth = 3, min_samples_leaf = 6)<br>gbm = gbm.fit(train_X, train_y)<br>b = gbm.predict(val_X)<br>score = accuracy_score(val_y, b)<br>print(score)</font><br>
<font color="#0097a7">XGboost</font><br>
导入库
<font color="#388e3c">from xgboost import XGBClassifier</font><br>
代码
<font color="#ff0000">xgb = XGBClassifier(learning_rate=0.1, n_netimators = 1000, max_depth=7, min_child_weight = 1, scale_pos_weight=1, random_state=2, min_samples_leaf = 6)<br>xgb.fit(train_X, train_y)<br>xgb.score(val_X, val_y)</font><br>
<font color="#0097a7">LightGBM</font><br>
导入库
<font color="#388e3c">from lightgbm import LGBMClassifier</font><br>
代码
<font color="#ff0000">lgm = LGBMClassifier(learning_rate = 0.1, n_estimators = 1000, max_depth = 6, min_samples_leaf = 7, num_leaves = 20)<br>lgm.fit(train_X, train_y)<br>lgm.score(val_X, val_y)</font><br>
<font color="#0097a7">K-means(聚类算法)</font><br>
导入库<br>
<font color="#388e3c">from sklearn.cluster import KMeans</font><br>
代码
<font color="#ff0000">kmeans_model = KMeans(n_clusters=3</font><font color="#000000">(K)</font><font color="#ff0000">, random_state=9)<br>kmeans_model.fit(iris_X_train)<br>kmeans_model.predict(iris_X_test)</font><br>
寻找最优k值
<font color="#ff0000"># KMeans算法实例化,将其设置为</font>K=range(2,6),random_state=123<br>d = {}<br>fig_reduced_data = plt.figure(figsize= (12,12))<br>for k in range(2,6):<br> <br> <font color="#ff0000"># KMeans算法实例化</font><br> kmeans_model = KMeans(n_clusters=k, random_state=123)<br> <br> <font color="#ff0000"> # 训练集聚类</font><br> kmeans_model.fit(iris_X_train)<br> <br> <font color="#ff0000"># 训练集的预测标签</font><br> label = kmeans_model.predict(iris_X_train)<br> <br> <font color="#ff0000"># 估不同k值聚类算法效果</font><br> score = metrics.calinski_harabasz_score(iris_X_train,label)<br> d.update({k:score})<br> print('calinski_harabaz_score with k={0} is {1}'.format(k,score))<br>
<font color="#0097a7">逻辑回归(本质是分类问题)</font>
<font color="#0097a7">线性回归(LinearRegression)</font><br>
<font color="#000000">导入库</font><br>
<font color="#388e3c">from sklearn.linear_model import LinearRegression</font>
代码
<font color="#ff0000">tr = LinearRegression()<br>tr = tr.fit(data_X, data_y)<br>val_pred = tr.predict(val_X)<br>val_pred</font>
关于<b><font color="#0097a7">词</font></b>的
<font color="#0097a7">分词方法preprocess</font>
导入库
<font color="#388e3c">from nltk.tokenize import TweetTokenizer</font><br>
代码
<font color="#ff0000"># 实例化TweetTokenizer方法<br>tokenizer = TweetTokenizer()<br><br># 使用TweetTokenizer方法中tokenize函数进行文本分词处理,处理前使用lower()函数首先将文本转换为小写。<br>preprocess = lambda text: ' '.join(tokenizer.tokenize(text.lower()))</font><br>
<font color="#0097a7">词袋模型</font>
导入库
<font color="#388e3c">from sklearn.feature_extraction.text import CountVectorizer</font><br>
代码
<font color="#ff0000"># 实例化CountVectorizer方法,min_df参数设置为1<br>vectorizer = CountVectorizer(min_df=1)<br><br># 基于text_train数据训练词袋模型<br>vectorizer.fit(texts_train)<br><br># 使用已训练的词袋模型完成对texts_train,texts_test的特征抽取<br>X_train_bow = vectorizer.transform(texts_train)<br>X_test_bow= vectorizer.transform(texts_test)</font><br>
<font color="#0097a7">词云(画图查看哪个词频高)</font>
导入库
<font color="#388e3c">from wordcloud import WordCloud<br>from matplotlib import pyplot as plt<br>%matplotlib inline</font><br>
代码
<font color="#ff0000">def cloud(text, title, size = (10,7)):<br> """<br> 输入是文本list,图片标题<br> """<br> wordcloud = WordCloud(width=800, height=400, collocations=False).generate(" ".join(text))<br> fig = plt.figure(figsize=size, dpi=80, facecolor='k',edgecolor='k')<br> plt.imshow(wordcloud,interpolation='bilinear')<br> plt.axis('off')<br> plt.title(title, fontsize=25,color='w')<br> plt.tight_layout(pad=0)<br> plt.show()<br><br># 使用cloud函数绘制词云图 <br>cloud(texts, "word cloud of comments")</font><br>
评估模型(计算预测)<br>
预测结果<br>
<font color="#ff0000">predict(val_X)</font>
预测概率
<font color="#ff0000">predict_proba(val_X)</font><br>
评估模型(计算准确率、召回率)<br>
导入库
<font color="#388e3c">from sklearn.metrics import roc_auc_score, accuracy_score, r2_score</font>
代码
accuracy = accuracy_score(val_y, val_pred)<font color="#ff0000"> (分类问题的正确率) </font>/ accuracy = roc_auc_score(val_y, val_pred)<font color="#ff0000">(分类问题的召回率)</font><font color="#000000">/</font><font color="#ff0000"> </font>r2_score =<font color="#ff0000"> </font>r2_score(test_y, test_predict) <font color="#ff0000">(回归问题的正确率)</font><br>
评测指标
导入库<br>
<font color="#388e3c">import numpy as np<br>from sklearn import metrics<br>from sklearn.metrics import mean_squared_error</font><br>
各类误差代码
均方误差(MSE)<br>
<font color="#ff0000">mean_squared_error(val_y, val_pred)</font><br>
均方根误差(RMSE)
<font color="#ff0000">np.sqrt(mean_squared_error(val_y, val_pred))</font><br>
平均绝对误差(MAE)<br>
<font color="#ff0000">metrics.mean_absolute_error(val_y, val_pred)</font><br>
平均绝对百分误差(MAPE)
<font color="#ff0000">np.mean(np.abs((y_pred - y_true) / y_true))</font><br>
中值绝对误差(MAD)
<font color="#ff0000">metrics.median_absolute_error(val_y, val_pred)</font><br>
回归决定系数<br>
<font color="#ff0000">metrics.r2_score(val_y, val_pred)</font>
数据分析与应用
pandas 统计分析
文件读取与存储
csv文件
读取
pandas.read_csv( filepath , sep = ',' (<font color="#ff0000">分隔符为逗号</font> ), header = 'infer' (<font color="#ff0000">将某行数据最为列名)</font><font color="#000000">,names = None</font><font color="#ff0000"> (自定义列名)</font><font color="#000000">, index_col = None(</font><font color="#ff0000">表示索引列的位置)</font><font color="#000000">, nrows = None (</font><font color="#ff0000">读取前几行)</font><font color="#000000">, chunksize = 数值</font><font color="#ff0000">(对于大数据的读取)</font>)等<br>
例如:<font color="#ff0000">pd.read_csv(r"C:\Users\Lenovo\Desktop\文件\data.csv") </font><font color="#000000">(最基础)</font>
储存
pandas.to_csv(path = None, sep = ',' , columns = None<font color="#ff0000"> (表示写出的列名) </font>, header = True (<font color="#ff0000">是否写出列名)</font>,<font color="#ff0000"> </font>index = True (<font color="#ff0000">是否将行名写出)</font>, index_label = None (<font color="#ff0000">索引名)</font> , mode = 'w ' (<font color="#ff0000">数据写入模式(默认值为w))</font>)等
例如:<font color="#ff0000">pd.to_csv(r"C:\Users\Lenovo\Desktop\文件\data.csv") </font><font color="#000000">(最基础)</font>
Excel文件
读取
pandas.read_excel(<font color="#ff0000">扩展名有 .xls 和 .xlsx 两种</font>, sheetname = 0 (<font color="#ff0000">代表Excel表内数据的分表位置)</font>, header = 0 )等
例如:<font color="#ff0000">pd.read_excel(r"C:\Users\Lenovo\Desktop\文件\data.xls或.xlsx") </font><font color="#000000">(最基础)</font>
储存
pandas.to_excel(excel_writer = None, sheetname= 0, header = True, index = True, index_label = None, mode = 'w')
例如:<font color="#ff0000">pd.to_excel(r"C:\Users\Lenovo\Desktop\文件\data.xlsx") </font><font color="#000000">(最基础)</font>
读取位置
head() (<font color="#ff0000">读取前几行(默认值参数为5行))</font>
tail() <font color="#ff0000">读取后几行</font>
encoding(编码类型)
utf-8 <font color="#ff0000">全球通用编码类型 (内存大)</font>
gbk <font color="#ff0000">汉语编码类型(内存小)</font><br>
基础操作
基础函数
columns<font color="#ff0000"> 查找列名</font>
index <font color="#ff0000"> 查找index</font><br>
values <font color="#ff0000">查找值</font>
dtypes <font color="#ff0000">查询类型</font><br>
size <font color="#ff0000">查询元素个数</font>
ndim<font color="#ff0000"> 获取数据维度</font><br>
shape <font color="#ff0000">获取数据形状</font><br>
loc <font color="#ff0000">[行索引名称或条件, 列索引名称] 在行索引前加 ~ 符可以筛选相反数据</font>
iloc<font color="#ff0000"> [行索引位置, 列索引位置]</font>
info() <font color="#ff0000"> 用于获取 DataFrame 的简要信息</font><br>
describe(include = 'all') <font color="#ff0000">用于获取 DataFrame 较多值的计算 参数include = 'all' 可获取更多数据</font><br>
描述性统计<br>
corr <font color="#ff0000">相关系数函数</font><br>
基于相关性结果做变量选择
选择与y相关性高的因子,同时互相关性低的因子
代码 :<font color="#0000ff">sns.heatmap(corr_df)</font><br>
value_counts() <font color="#ff0000">对频数进行统计 (该数据有几种数据和每种数据的数量)</font>
var()<font color="#ff0000"> 方差</font>
median() <font color="#ff0000">中位数</font><br>
mean() <font color="#ff0000">平均值</font><br>
max() <font color="#ff0000">最大值</font>
min() <font color="#ff0000">最小值</font><br>
std() <font color="#ff0000">标准差</font><br>
mode() <font color="#ff0000">众数</font>
count() <font color="#ff0000"> 非空值数目</font><br>
quantile() <font color="#ff0000"> 四分位数</font>
遍历dataframe
apply + 自定义函数
缺失值检查
iterrows<br>
元组<br>
index
row(serise)<br>
for index, row in a1.iterrows(): <font color="#ff0000">#返回的是元组</font><br> print(index, row['Gender'])<br>
分组统计/数据透视表
pivot_table<br>
values<br>
<font color="#ff0000">列表,元素是列名</font><br>
index<br>
<font color="#ff0000">列表,元素是列名</font><br>
aggfunc<br>
<font color="#ff0000">字典,元素“列名”:[函数1, 函数2]</font><br>
样例代码<br>
代码
<font color="#ff0000">import numpy as np<br>g = a1.pivot_table(values = ['LoanAmount', 'ApplicantIncome'],<br> index = ['Gender', 'Married', 'Self_Employed'], <br> aggfunc ={'LoanAmount':np.mean, 'ApplicantIncome':[np.sum,np.mean]})<br>pd.DataFrame(g)</font><br>
groupby() <br>
groupby('列名')<br>
返回的是一个group的类型<br>
groupby().agg({'列1': 'mean', 'age': 'max'})
<font color="#000000">代码:</font><font color="#ff0000">data.groupby('company').agg({'salary': 'median', 'age': 'mean'})</font><br>
返回的是dataframe<br>
groupby(). apply()
传递给自定义函数的是dataframe<br>
代码
<font color="#ff0000">def func1(x):<br> print(type(x))<br> print(x)<br>data.apply(func1)</font>
注意事项:<b><font color="#e65100"> groupby创建完之后返回的是一个对象</font></b>
crosstab
列Series, 可以用列表保存多列
列Series, 可以用列表保存多列<br>
margins<br>
<font color="#ff0000">是否统计总数</font><br>
normalize<br>
<font color="#ff0000">是否求比例</font>
样例<br>
<font color="#ff0000">pd.crosstab(a1['Credit_History'],[a1['Gender'],a1['Loan_Status']],margins=True, normalize = True)</font><br>
合并数据集<br>
merge<br>
right =<br>
join<br>
left_on/right——on
<font color="#ff0000">列名是否要一致? 否</font>
列的内容是可以mou定
left_index/right_index<br>
True/False
concat<br>
默认index列进行合并
[表1, 表2, 表3 .......]
axis = 1或0<br>
1: 列合并<br>
0:行合并<br>
join
排序<br>
sort_values<br>
ascending = True/False (升序/降序)<br>
变量离散化<br>
pd.cut<br>
列, series
bins = [...](划分区间)
labels<br>
right<br>
(9, 90) 不包括90值<br>
(9, 90]包括90值<br>
样例
pd.cut(x <font color="#ff0000">(一维数组)</font> , bins<font color="#ff0000"> (整数--将x划分为多少个等距的区间.若不在该序列中,则是Nan) </font>, right=True <font color="#ff0000">(是否包含右端点)</font>,labels=None <font color="#ff0000">(是否用标记来代替返回的bins)</font>, precision=3 <font color="#ff0000">(精度)</font> ,include_lowest=False <font color="#ff0000">(是否包含左端点)</font>)
独热编码<br>
get_dummies<br>
列, series
prefix = ' ' (建议是与原列名一致)<br>
堆叠合并数据
concat 方法堆叠数据
pandas.concat(objs <font color="#ff0000">(参与连接pandas对象列表的组合)</font>, axis = 0<font color="#ff0000"> (连接的轴向)</font>, join = ' outer '<font color="#ff0000"> (按交际(inner)或并集(outer)进行合并)</font>, <br>ignore_index = False <font color="#ff0000">(表示是否不保留连接轴上的索引)</font>, keys = None<font color="#ff0000"> (层次化索引)</font>, levels = None <font color="#ff0000">(在确定keys后用于层次化各级别上的索引)</font>, <br>names = None <font color="#ff0000">(在确定keys和leves后,用于创建分层级别名称)</font>, verify_integrity = False <font color="#ff0000">(是否检查连接轴上的重复项)</font>)<br>
append 方法堆叠数据<br>
pandas.DataFrame.append(self, other<font color="#ff0000"> (要添加的新数据)</font>, ignore_index = Fasle<font color="#ff0000"> (表示是否不保留连接轴上的索引)</font>,verify_integrity = False<font color="#ff0000"> (是否检查连接轴上的重复项)</font><font color="#000000">)</font><br>
变量映射
replace
replace(['a','b','c'],['A','B','C'])
Matplotlib 数据可视化/seaborn
工具包及基本参数设置<br>
导入库<br>
<font color="#0000ff">import matplotlib.pyplot as plt / import seaborn as sns</font><br>
画布与子图<br>
创建画布大小、像素<br>
plt.figure( figsize = (<font color="#ff0000">长</font>, <font color="#ff0000">宽</font>) , dpi = <font color="#ff0000">(像素)</font>)
创建子图<br>
figure<font color="#ff0000">(画布)</font>.add_subplot(2, 1 , 1) <font color="#ff0000">(创建一个2行1列的子图 这是绘制第一个)</font>
标签与图例<br>
添加标题
<font color="#ff0000">plt.title()</font><br>
添加x/y轴名称
<font color="#ff0000">plt.xlabel() / plt.ylabel()</font><br>
指定当前x/y轴数据范围
<font color="#ff0000">plt.xlim()/plt.ylim()</font><br>
指定x/y轴刻度与取值
<font color="#ff0000">plt.xticks()/plt.yticks()</font><br>
图例
<font color="#ff0000">plt.legend()</font><br>
保存与显示图形<br>
保存<br>
<font color="#ff0000">plt.savafig()</font><br>
显示图形<br>
<font color="#ff0000">plt.show()</font><br>
基础构图<br>
柱状图<br>
plt.bar(left <font color="#ff0000">(x轴数据)</font>, height<font color="#ff0000"> (x轴所代表的的数据数量0</font>, color = None <font color="#ff0000">(柱状图颜色),</font>width = 0.8 <font color="#ff0000">(柱状图宽度 默认值 0.8)</font>)
直方图
基础代码:<font color="#ff0000">data['列名'].plot.hist()</font>
折线图
plt.plot(x , y , linestyle = '-' <font color="#ff0000"> (线条类型 默认值 ' - '</font><b style=""><font color="#ff0000"> )</font></b>,marker = None <font color="#ff0000">(点类型)</font>, alpha = None <font color="#ff0000">(透明度 0~1的小数)</font>, color = None <font color="#ff0000">(折线图颜色)</font>)<br>
散点图
plt.scatter(x , y , s = None <font color="#ff0000">(点的大小)</font>, c = None <font color="#ff0000">(点的颜色)</font>, marker = None <font color="#ff0000">(点的形状)</font>, alpha = None <font color="#ff0000">(点的透明度 0~1的小数)</font>)
饼图<br>
plt.pie(x, explode = None <font color="#ff0000">(表示指定项距圆心的半径)</font><font color="#000000">,</font><font color="#ff0000"> </font> labels = None <font color="#ff0000">(每一项的名称) </font>, colors = None <font color="#ff0000">(饼图颜色)</font>, autopct = None <font color="#ff0000">(数值的显示方式)</font> , pctdistance = 0.6 <font color="#ff0000">(每一项的比例autopct和距离圆心的半径)</font> , labeldistance = 1.1<font color="#ff0000"> (指定每一列的名称labels和距离圆心的半径)</font> , radius = 1<font color="#ff0000"> (饼图的半径) </font>)<br>
横柱图<br>
plt.barh(y <font color="#ff0000">(条形的y轴坐标)</font> , width <font color="#ff0000">(条形的宽度)</font>, height=0.8<font color="#ff0000"> (条形的高度,默认值0.8)</font>)<br>
箱线图<br>
sns.boxplot(data<font color="#ff0000"> </font>, y , x , widths <font color="#ff0000">(箱线图宽度)</font>, showmeans <font color="#ff0000">(是否显示均值)</font> , showbox <font color="#ff0000">(是否显示箱体)</font>, sym <font color="#ff0000">(异常点形状)</font>, positions <font color="#ff0000">(放在x轴位置) </font>, vert<font color="#ff0000"> (是否垂直放置箱体)</font>)<br>
热力图<br>
sns.heatmap(data <font color="#ff0000">(数据corr()结果)</font>, vmin <font color="#ff0000">(颜色最小值),</font> vmax<font color="#ff0000"> (颜色最大值)</font>, center <font color="#ff0000">(色彩中心对称)</font>, square = False <font color="#ff0000">(矩阵小块的形状) </font><font color="#000000">, annot = True </font><font color="#ff0000">(是否标注)</font>)
小提琴图<br>
代码
<font color="#ff0000">fig, ax = plt.subplots(1, 3, figsize = (16, 6))<br>sns.violinplot(x="feature_1", y="target", data=train, ax=ax[0], title='feature_1')</font>







评论
0 条评论
下一页

