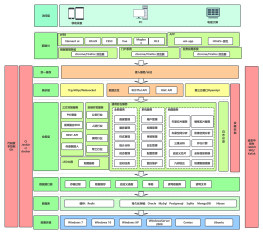
概述
它或者是一棵空树,或者是具有下列性质的二叉树:<br>它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。<br>(注:平衡二叉树应该是一棵二叉排序树)<br>
n个结点的AVL树最大深度约1.44log2n
查找、插入和删除在平均和最坏情况下都是O(logn)
增加和删除可能需要通过<b><u>一次或多次树旋转</u></b>来重新平衡这个树;<br><b>这个方案很好的解决了二叉查找树退化成链表的问题,<br>把插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)。<br>但是频繁旋转会使插入和删除牺牲掉O(logN)左右的时间,不过相对二叉查找树来说,时间上稳定了很多</b><br>