springcloud
2022-10-13 21:34:18 49 举报AI智能生成
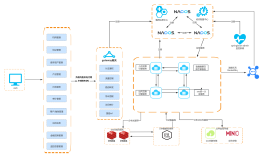
Spring Cloud是一个基于Spring Boot实现的云应用开发工具,它为基于JVM的云应用开发中涉及的配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、决策竞选、分布式会话和集群状态管理等操作提供了一种简单的开发方式。Spring Cloud包含了多个子项目,如Spring Cloud Config、Spring Cloud Netflix、Spring Cloud OpenFeign等,它们分别用于配置管理、服务注册与发现、声明式服务调用等功能。通过使用Spring Cloud,开发者可以快速构建分布式系统的基础设施,提高开发效率和系统稳定性。
模板推荐
作者其他创作
大纲/内容




Collect

Collect

Collect
Collect
0 条评论
下一页

