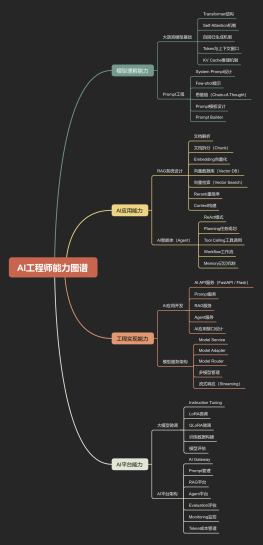
<font color="#ff0d00">AI<br>数据<br>建模<br>流程</font><br>
<font color="#ff0d00">模型设计</font>
根据问题目标和数据集,<br>选择合适的模型架构和参数,<br>如选择神经网络结构<br>
<font color="#ff0d00">特征工程</font>
为训练数据选取合适的特征,<br>如数据预处理、特征提取<br>和降维等方法优化模型<br>
<font color="#ff0d00">模型训练</font>
用训练数据对模型进行学习和参数调整,<br>如反向传播算法训练神经网络模型<br>
<font color="#ff0d00">模型验证</font>
使用验证数据评估模型性能,<br>如交叉验证、ROC曲线<br>评估模型准确率和偏差<br>
<font color="#ff0d00">模型融合</font>
将多个模型结果通过加权、<br>投票等方式融合,<br>提高模型泛化能力和预测精度。<br>
模型相关<br>技术名词<br>列举
<font color="#ff0d00">特征清洗</font>
对数据进行清洗去掉重复值、干扰数据,以及填充缺失值<br>
<font color="#ff0d00">数据变换</font>
对原始数据进行清洗、过滤、处理等一系列转换操作,以提高模型的准确性。<br>
<font color="#ff0d00">训练集<br>验证集<br>测试集</font><br>
<font color="#ff0d00">训练集</font>是让机器学习的样本集合用来拟合模型。<br><font color="#ff0d00">验证集</font>是模型训练过程中,用来对模型性能做初步的评估,用于模型参数调优。<br><font color="#ff0d00">测试集</font>是最终用来评估模型效果的。<br>
<font color="#ff0d00">测试</font>
<font color="#ff0d00">跨时间测试<br>OOT测试</font><br>
跨时间测试是指使用测试集中<br>与训练集时间不同的数据对模型进行测试,<br>目的是检验模型在未来数据上的预测性能。<br>
<font color="#ff0d00">回溯测试</font>
使用历史数据对模型进行测试,<br>模拟模型在过去预测效果,<br>主要用于验证模型的稳定性和可靠性。<br>
<font color="#ff0d00">KS检验</font>
对模型分类效果进行评估的一种方法,<br>通过比较好坏样本累积分布曲线<br>差异大小来判断模型效果<br>
KS值
一种<font color="#ff0d00">模型分类效果的评估指标</font>,<br>通过比较好坏样本累积分布曲线的差异大小,<br>反映模型对正负样本的区分能力。<br><font color="#ff0d00">KS值越大模型分类效果越好</font>。<br>
<font color="#ff0d00">过拟合</font>
在训练数据上表现良好<br>而在未知数据上表现不佳的现象,<br>常见原因包括特征维度<br>过高或模型复杂度过大。 <br>
<font color="#ff0d00">偏差:</font><br>指的是模型的预测结果<br>和实际的结果的偏离程度。<br>如果偏差比较大,<br>就说明模型的拟合程度比较差,<br>也就是欠拟合<br>
<font color="#ff0d00">方差:</font><br>各个样本值与均值偏差的平方和的平均值,<br>描述数据的离散程度<br>
<font color="#ff0d00">欠拟合</font>
指模型在训练数据上表现不佳,<br>无法拟合数据的真实分布。<br>它通常发生在模型过于简单、<br>特征选择不足、训练数据过少等情况下,<br>
<font color="#ff0d00">ROC曲线</font>
描述模型在二分类问题中的<br>准确率和召回率之间的关系,<br>横坐标为误判率,纵坐标为命中率。<br>
<font color="#ff0d00">AUC</font><br>
ROC曲线下的面积,用于评估二分类模型的性能,取值范围为0~1,值越大模型性能越好。<br>
<font color="#ff0d00">混淆矩阵</font>
用于表示模型的分类情况,<br>在二分类中由真正率、假正率、<br>真负率、假负率四部分组成。<br>
联合建模
就是使用三方公司(如银联、运营商、电商)的数据,在对方的环境下部署一个模型,然后我们通过接口调用这个模型的结果,再把结果融合到我们自己的模型上。通过这种方式,可以弥补我们自有业务中数据不足的问题。<br>
联合建模是指将多个模型的输出结果进行集成,以提高预测的准确性,<br><br>
<font color="#ff0d00">联邦学习</font>
<font color="#ff0d00">联邦学习是一种分布式机器学习技术,将多个本地设备或终端的数据进行聚合处理,使得算法可在不同设备间共享学习结果,<br>保护隐私同时具有良好的扩展性和适用性。</font><br>
<font color="#ff0d00">业务要使用三方数据,就可以考虑做联合建模。<br>如果想要避免个人信息外传的风险,<br>就可以考虑使用联邦学习技术</font><br>