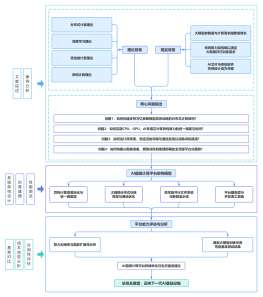
AI产品养成(2) 如何转AI产品? AI模型设计、 训练、部署
2023-04-26 19:03:53 2 举报AI智能生成
AI产品养成(2) 如何转AI产品? AI模型设计、 训练、部署
模板推荐
作者其他创作
大纲/内容







![[AI知识-1]AI产品基础背景知识](https://www.processon.com/chart_image/template/thumb/5dcb673ae4b022abb631ef4c.png?tid=5dcb673ae4b022abb631ef4a)
0 条评论
下一页

