
大数据
2023-05-09 15:02:42 2 举报AI智能生成
大数据组件脑图
大数据
模板推荐
作者其他创作
大纲/内容
CDC
debezium
缺点
依赖 kafka connect
消息体内容太多,对消息队列压力较大
每张表对应一个topic,管理起来不够方便(canal,maxwell则可以使用正则来处理)
优势
支持快照模式(snapshot.mode)全量同步
Canal
mysql-binlog-connector-java (mbcj)
原理
1.mbcj 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
2.MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 mbcj)
3.mbcj 解析 binary log 对象(原始为 byte 流)
Maxwell
不支持truncate命令同步
OLAP
MOLAP(Multidimensional OLAP)
MOLAP以Cube为表现形式,但计算与管理成本较高
ROLAP(Relational OLAP)
ROLAP需要强大的关系型DB引擎支撑
随着分布式、并行化技术成熟应用,MPP引擎逐渐表现出强大的高吞吐、低时延计算能力,号称“亿级秒开”的引擎不在少数,ROLAP模式可以得到更好的延伸。
HOLAP(Hybrid OLAP)
关系型数据库
ROLLUP(上卷)
数据可视化
cboard
davinci
DVAAS(Data Visualization as a Service)平台解决方案
flume数据收集工具
Event 数据传输的基本单元
Source 数据源
Channel 临时存储数据的管道
Sink 数据处理单元
Agent
sqoop数据迁移工具
分布式任务调度框架
Azkaban
架构
Webserver
ExecutorServer
核心概念
job
Flow
Flow1.0
Flow2.0
dolphinscheduler
Beam
提供统一批处理和流处理的编程范式
Hudi
Hadoop Upserts anD Incrementals
在hadoop兼容的存储之上存储大量数据
两种原语
Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
变更流:Hudi对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已updated/inserted/deleted的所有记录的增量流,并解锁新的查询姿势(类别)
Storm
核心概念
Topology
spout
bolt
stream
集群架构
Nimbus
Supervisors
hadooop
环境搭建
HA集群
源码
hadoop-mapreduce-project
hadoop-mapreduce-client
hadoop-mapreduce-client-core
Mapper.java
Maps input key/value pairs to a set of intermediate key/value pairs. 将输入键/值对映射到一组中间键/值对。
The Hadoop Map-Reduce framework spawns one map task for each {@link InputSplit} generated by the {@link InputFormat} for the job. Hadoop Map-Reduce框架为作业的InputFormat生成的每个InputSplit生成一个map作业
All intermediate values associated with a given output key are subsequently grouped by the framework, and passed to a {@link Reducer} to determine the final output. Users can control the grouping by specifying a <code>Comparator</code> via {@link JobConf#setOutputKeyComparatorClass(Class)}.
与给定输出键关联的所有中间值随后由框架进行分组,并传递给Reduce以确定最终输出。用户可以通过{@link jobconf# setOutputKeyComparatorClass(Class)}指定Comparator来控制分组。
Comparator
Users can optionally specify a <code>combiner</code>, via {@link JobConf#setCombinerClass(Class)}, to perform local aggregation of the intermediate outputs, which helps to cut down the amount of data transferred from the <code>Mapper</code> to the <code>Reducer</code>.
用户可以选择指定一个combiner,通过 jobconf#setCombinerClass以执行本地聚合中间输出,有助于减少从mapper到reduce的数据传输
combiner
优化
配置优化
core-site.xml
fs.trash.interval 垃圾箱清理文件间隔
dfs.namenode.handle.count hadoop启动任务线程数
mapreduce.tasktraker.http.threads map和reduce之间通过http传输数据 传输的并行线程数
系统优化
代码优化
combiner的个数尽量同reduce相同,数据类型保持一直,可以减少拆包和封包进度
HDFS
核心模块
namenode节点
namenode挂了。先分析宕机后的损失,宕机后直接导致client无法访问,内存中的元数据丢失,但是硬盘中的元数据应该还存在,如果只是节点挂了,
重启即可,如果是机器挂了,重启机器后看节点是否能重启,不能重启就要找到原因修复了。
但是最终的解决方案应该是在设计集群的初期就考虑到这个问题,做namenode的HA。
datanode节点
Datanode宕机了后,如果是短暂的宕机,可以实现写好脚本监控,将它启动起来。如果是长时间宕机了,那么datanode上的数据应该已经被备份到其他机器了,
secondarynamenode
sn的主要职责是执行checkpoint操作
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地
客户端
HDFS协议(RPC协议、流式接口协议:HTTP和TCP)
mapreduce
Mapper任务过程
第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片,会有三个Mapper进程处理。
第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
第三阶段是调用Mapper类中的map方法。第二阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出零个或者多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。分区是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux文件中。
第六阶段Reducer任务过程
决定Mapper的数量
HDFS中数据的存储是以块的形式存储的,数据块的切分是物理切分,而split是在Block的基础上进行的逻辑切分。每一个split对应着一个Mapper进程。每个Split中的每条记录调用一次map方法。
一个文件被切分成多少个split就有多少个Mapper进程。
Reducer任务过程
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对,Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据,再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
决定Reducer的数量
如: 10个key可以有1个reducer,但是这个reducer只能一次处理一个key,也就是说处理10次
10个key可以有大于10个reducer ,只不过有的reduce不进行key的处理。
10个key有10个reducer,这是最合理的分配,达到并行计算。
相同的key如何识别到指定的reducer进行计算呢?
对输出的key、value进行分区。
总结:Mapper阶段是并行读取处理的它的数量是由切片的数量决定的;Reducer阶段可以不并行,他的数量的是通过key进行规划,由人来决定。
shuffle
将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
map的主要输入是一对<key , value>值,经过map计算后输出一对<key , value>值;然后将相同key合并,形成<key , value集合>;再将这个<key , value集合>输入reduce,经过计算输出零个或多个<key , value>对。
yarn
资源调度
ResourceManager
ApplicationMaster
NodeManager
container
问题处理
datanode首次加入cluster时候 版本号不一致
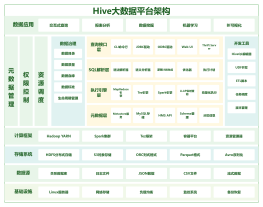
hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
架构
用户接口/界面
元存储
HiveQL处理引擎
执行引擎
HDFS 或 HBASE
内部表
外部表
分区表
分桶表
视图
索引
hbase
核心概念
Row Key(行键)
Column Family(列族)
Column Qualifier(列限定符)
Column(列)
Cell
集群架构
HMaster
Region Servers
Row Key 设计原则
唯一原则
Key-Value存储 会覆盖
排序原则
HBase的Rowkey是按照ASCII有序设计的
散列原则
Region热点问题
Reverse反转
Salt加盐
Mod
长度原则
Rowkey是一个二进制,Rowkey的长度被很多开发者建议说设计在10~100个字节,建议是越短越好
zookeeper
分布式的,开放源码的分布式应用程序协调服务文件系统+监听通知机制
安装部署
zoo.cfg配置
tickTime
这个属性表示心跳时间间隔,Leader用来监听Follower的心跳,一旦挂掉一半以上Follower,会通过Zab(消息原子广播)协议使集群所有个体状态转变为Looking(等待选举新任Leader)。此属性除了用来监听之外,还对后面的同步时间和初始化时间有影响,系统默认为2000毫秒。
initLimit
集群中的follower服务器与Leader服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),系统默认为10。
syncLimit
集群中Follower服务器跟Leader服务器之间的请求和答应最多能容忍的心跳数(tickTime的数量),系统默认为5。
dataDir
此属性表示一个路径,用来存放数据快照(即zookeeper目录)、myid文件和日志文件夹,系统默认为/tmp/data,根据自己zk安装路径进行修改并创建data目录。
clientPort
zk客户端端口号,默认2181。
dataLogDir
用来存放zk写日志。
server.index=IP:A:B
此处是关于zk集群的配置,index代表自定义的各服务器序号(对应写在各自机器的myid中),IP即各服务器IP,A表示集群服务器之间通讯组件的端口,B表示选举组件的端口。如果配成集群,则zk状态(mode)为leader或follower;如果只配一个单机,mode为standalone。
各节点角色
leader
follower
observer
ZNODE
永久节点
临时节点
有序节点
ACL权限
Permissions
id
Schemes
curator
会话
Watcher
核心原理
ZAB协议
崩溃恢复
消息广播
paxos算法
发布订阅
分布式锁
master选举
kafka
概念
Topics And Partition(主题与分区)
topic通过文件存储,partition是目录
消息是顺序append log方式存储
分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
消息冗余多台beoker存储,多台机器就叫一个replica集合
replica集合中,需要选出1个leader,剩下的是follower。也就是master/slave。
offset回退机制
消息会存放一个星期,才会被删除。并且在一个partion里面,消息是按序号递增的顺序存放的,因此消费者可以回退到某一个历史的offset,进行重新消费。
offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序性而不是主题有序性。
之所以要分成多个partition,是为了提高并发度,多个partition并行的进行发送/消费,但这却没有办法保证消息的顺序问题
一个topic只用一个partition,但这样很显然限制了灵活性。
所有发送的消息,用同一个key,这样同样的key会落在一个partition里面。
轮询分区策略
随机分区策略
消息刷盘
操作系统本身是有page cache的。即使我们用无缓冲的io,消息也不会立即落到磁盘上,而是在操作系统的page cache里面。操作系统会控制page cache里面的内容,什么时候写回到磁盘。在应用层,对应的就是fsync函数。
我们可以指定每条消息都调用一次fsync存盘,但这会较低性能,也增大了磁盘IO。也可以让操作系统去控制存盘。
Producers And Consumers(生产者与消费者)
消费者去broker pull消息
同步发送 异步发送
RecordAccimator
Metadata
生产者压缩算法
Producer 端压缩
Broker 端保持
Consumer 端解压缩
Producer 发送消息的过程如下图所示,需要经过拦截器,序列化器和分区器,最终由累加器批量发送至 Broker。
Kafka 有消费组的概念,每个消费者只能消费所分配到的分区的消息,每一个分区只能被一个消费组中的一个消费者所消费,所以同一个消费组中消费者的数量如果超过了分区的数量,将会出现有些消费者分配不到消费的分区
配置客户端,创建消费者
订阅主题
拉去消息并消费
提交消费位移
关闭消费者实例
Kafka Consumer 线程不安全,单线程消费,多线程处理
rebalance
rebalance 本质上是一种协议,规定了一个 consumer group 下的所有 consumer 如何达成一致来分配订阅 topic 的每个分区。比如某个 group 下有 20 个 consumer,它订阅了一个具有 100 个分区的 topic。正常情况下,Kafka 平均会为每个 consumer 分配 5 个分区。这个分配的过程就叫 rebalance。
组成员发生变更(新 consumer 加入组、已有 consumer 主动离开组或已有 consumer 崩溃了——这两者的区别后面会谈到)
订阅主题数发生变更
订阅主题的分区数发生变更
Kafka 默认提供了两种分配策略:Range 和 Round-Robin。当然 Kafka 采用了可插拔式的分配策略,你可以创建自己的分配器以实现不同的分配策略。
Brokers And Clusters
broke依赖zk,生产消费者并不依赖
Messages And Batches(消息与批次)
Exactly Once
消息不会重复存储
消息不会重复消费
不会丢失存储
不会丢失消费
高水位值 (High watermark)。这是控制消费者可读取消息范围的重要字段。一 个普通消费者只能“看到”Leader 副本上介于 Log Start Offset 和 HW(不含)之间的 所有消息。水位以上的消息是对消费者不可见的。
消息丢失
broker
异步刷盘
页缓存到file时系统挂掉
设置 unclean.leader.election.enable = false。这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
设置 replication.factor >= 3。这也是 Broker 端的参数。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
设置 min.insync.replicas > 1。这依然是 Broker 端参数,控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas +1
Producer
异步发送消息-丢失消息
不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。记住,一定要使用带有回调通知的 send 方法。
设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义。
Consumer
自动提交
确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把它设置成 false,并采用手动提交位移的方式。就像前面说的,这对于单 Consumer 多线程处理的场景而言是至关重要的。
Consumer Group:一个消费者组可以包含一个或多个消费者。使用多分区 + 多消费者方式可以极大提高数据下游的处理速度,同一消费组中的消费者不会重复消费消息,同样的,不同消费组中的消费者消息消息时互不影响。Kafka 就是通过消费组的方式来实现消息 P2P 模式和广播模式。
数据的一致性
Kafka 事务机制
Kafka 生产者在同一个事务内提交到多个分区的消息,要么同时成功,要么同时失败。
TransactionalID
epoch 机制
步骤
initTransactions 方法初始化事务上下文
找到 Kafka 集群负责管理当前事务的事务协调者( TransactionCoordinator ),向其申请 ProducerID 资源
幂等
Producer ID(即PID)
PID:每个新的 Producer 在初始化的时候会被分配一个唯一的 PID,这个PID 对用户完全是透明的。
Sequence Number
配置
enable.idempotence
ISR数据同步
AR:Assigned Replicas。AR 是主题被创建后,分区创建时被分配的副本集合,副本个 数由副本因子决定。
ISR:In-Sync Replicas。Kafka 中特别重要的概念,指代的是 AR 中那些与 Leader 保 持同步的副本集合。
在 AR 中的副本可能不在 ISR 中,但 Leader 副本天然就包含在 ISR 中。关于 ISR,还有一个常见的面试题目是如何判断副本是否应该属于 ISR。目前的判断 依据是:Follower 副本的 LEO 落后 Leader LEO 的时间,是否超过了 Broker 端参数 replica.lag.time.max.ms 值。如果超过了,副本就会被从 ISR 中移除。
Kafka 在所有分配的副本 (AR) 中维护一个可用的副本列表 (ISR),Producer 向 Broker 发送消息时会根据ack配置来确定需要等待几个副本已经同步了消息才相应成功,Broker 内部会ReplicaManager服务来管理 flower 与 leader 之间的数据同步。
性能
Partition 并发
一方面,由于不同 Partition 可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。另一方面,由于 Partition 在物理上对应一个文件夹,即使多个 Partition 位于同一个节点,也可通过配置让同一节点上的不同 Partition 置于不同的 disk drive 上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
顺序读写
400M/s
Kafka 每一个 partition 目录下的文件被平均切割成大小相等(默认一个文件是 500 兆,可以手动去设置)的数据文件, 每一个数据文件都被称为一个段(segment file), 每个 segment 都采用 append 的方式追加数据。
使用 Filesystem Cache PageCache 缓存来减少与磁盘的交互
使用 Zero-copy 和 MMAP 来减少内存交换
使用批量,以流的方式进行交互,直顶网卡上限
使用拉模式进行消息的获取消费,与消费端处理能力相符
Doris
单分区
复合分区
时间分区
维度分筒
部署
FE
FrontEnd DorisDB的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。
BE
BackEnd DorisDB的后端节点,负责数据存储,计算执行,以及compaction,副本管理等工作。
Broker
DorisDB中和外部HDFS/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。
Tablet
数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
DorisManager
DorisDB 管理工具,提供DorisDB集群管理、在线查询、故障查询、监控报警的可视化工具。
Partition
多个 Tablet 在逻辑上归属于不同的分区(Partition)。一个 Tablet 只属于一个 Partition。而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立。Tablet 是数据移动、复制等操作的最小物理存储单元。
OLAP_SCAN_NODE
OlapScanner
SegmentIterator
OlapScanner
对一个tablet数据读取操作整体的封装
RowsetReader
负责了对一个Rowset的读取
RowwiseIterator
提供了一个Rowset中所有Segment的统一访问的Iterator功能
SegmentIterator
对应了一个Segment的数据读取,Segment的读取会根据查询条件与索引进行计算找到读取的对应行号信息
物化视图
数据流和控制流
查询
MySQL客户端执行DQL SQL命令。
FE解析, 分析, 改写, 优化和规划, 生成分布式执行计划。
分布式执行计划由 若干个可在单台be上执行的plan fragment构成, FE执行exec_plan_fragment, 将plan fragment分发给BE,并指定其中一台BE为coordinator。
BE执行本地计算, 比如扫描数据。
其他BE调用transimit_data将中间结果发送给BE coordinator节点汇总为最终结果。
FE调用fetch_data获取最终结果。
FE将最终结果发送给MySQL client。
稀疏索引
Bloom Filter(布隆过滤器)
Bloom Filter(布隆过滤器)是用于判断某个元素是否在一个集合中的数据结构,优点是空间效率和时间效率都比较高,缺点是有一定的误判率。
布隆过滤器是由一个Bit数组和n个哈希函数构成。Bit数组初始全部为0,当插入一个元素时,n个Hash函数对元素进行计算, 得到n个slot,然后将Bit数组中n个slot的Bit置1。
当我们要判断一个元素是否在集合中时,还是通过相同的n个Hash函数计算Hash值,如果所有Hash值在布隆过滤器里对应的Bit不全为1,则该元素不存在。当对应Bit全1时, 则元素的存在与否, 无法确定. 这是因为布隆过滤器的位数有限, 由该元素计算出的slot, 恰好全部和其他元素的slot冲突. 所以全1情形, 需要回源查找才能判断元素的存在性。
Bloom Filter 索引
DorisDB的建表时, 可通过PROPERTIES{"bloom_filter_columns"="c1,c2,c3"}指定需要建BloomFilter索引的列,查询时, BloomFilter可快速判断某个列中是否存在某个值。如果Bloom Filter判定该列中不存在指定的值,就不需要读取数据文件;如果是全1情形,此时需要读取数据块确认目标值是否存在。另外,Bloom Filter索引无法确定具体是哪一行数据具有该指定的值。
Bitmap索引
Bitmap是元素为1个bit的, 取值为0,1两种情形的, 可对某一位bit进行置位(set)和清零(clear)操作的数组
建立在枚举值列
向量化执行
简单理解为就是消除程序循环的优化。
列式存储
每列的数据存储在一起,可以认为这些数据是以数组的方式存储的,基于这样的特征,当该列数据需要进行某一同样操作,可以使用SIMD进一步提升计算效率,即便运算的机器上不支持SIMD, 也可以通过一个循环来高效完成对这个数据块各个值的计算。
优势
向量化执行引擎可以减少节点间的调度,提高CPU的利用率
因为列存数据,同一列的数据放在一起,导致向量化执行引擎在执行的时候拥有了更多的机会能够利用的当前硬件与编译的新优化特征
因为列存数据存储将同类型的类似数据放在一起使得压缩比能够达到更高,这样可以拉近一些磁盘IO能力与计算能力的差距
join
shuffle join
broadcast join
broadcast join
参与join的两张表的数据行, 若满足join条件, 则需要将它们汇合在一台节点上, 完成join; 这两种join方式, 都无法避免节点间数据网络传输带来额外的延迟和其他开销
kylin
以Hive或者Kafka作为数据源,里面保存着真实表,而Kylin做的就是将数据进行抽象,通过引擎实现Cube的构建。将Hbase作为数据的仓库,存放Cube。因为Hbase的直接读取比较复杂,所以Kylin提供了近似SQL和HQL的形式,满足了数据读取的基本需求。对外提供了RestApi和JDBC/ODBC方便操作。
预加载
Cube
核心算法
kylin.cube.algorithm.auto.threshold 默认7作为阈值
逐层构建算法
从最大维开始,基于上一层,只需要读取一次数据
充分利用MR
缺点,MR多,磁盘消耗大
快速构建算法
一个reduce 写三维度
架构
REST Server服务层
查询引擎
路由层
元数据
cube构建引擎
flink
可扩展并行度的 ETL、数据分析以及事件驱动
Batch(DataSet API)
Streaming(DataStream API)
Tables API & SQL
概念
在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。
窗口
从 Streaming 到 Batch 的一个桥梁,将无界数据划分成有界数据。我们通过定义一个窗口,收集一批数据,并对这个窗口内的数据进行聚合类的计算。
时间
事件时间与处理时间
如果关心事件实际发生时间,则必须基于事件的事件时间,而不是处理时间
窗口组件
Window Assigner
用来决定某个元素被分配到哪个/哪些窗口中去。
Trigger
触发器。决定了一个窗口何时能够被计算或清除,每个窗口都会拥有一个自己的Trigger。
Evictor
“驱逐者”。在Trigger触发之后,在窗口被处理之前,Evictor(如果有Evictor的话)会用来剔除窗口中不需要的元素,相当于一个filter,如countTime 中evictor(size) ,其中size 为 保留的元素个数
watermark
处理数据从source、transform、sink中的背压和消息乱序问题---延迟触发window计算
引入watermark机制则会等待晚到的数据一段时间,等待时间到则触发计算,如果数据延迟很大,通常也会被丢弃或者另外处理。
checkpoint 与 state
Flink 基于 Chandy-Lamport 算法实现了自己的分布式快照算法,利用 state 和 checkpoint 机制实现了 streaming system 的 exactly-once 语义
checkpoint 机制
一个Checkpoint记录着数据流中某个时刻所有operators对应的状态
Checkpoint Barrier
Flink Checkpoint的核心元素就是数据流Barrier,Barrier会被注入到数据流中,作为数据流的一部分向前流动。Barrier将数据流中的数据切分为进入当前Checkpoint的部分和进入下一次Checkpoint的部分,每个Barrier都携带对应Checkpoint的ID。Barrier是非常轻量级的,不会中断数据流的处理。
执行过程
Job Manager中的Checkpoint Coordinator向所有source端发送触发Checkpoint的通知,并在source端注入barrier事件。
Source端向下游传递barrier,并将自己的状态异步地写入到持久化存储中。
Operator接收到source端传递的barrier之后,会对operator的输入流进行对齐barrier,然后向输出流传递barrier,并将自己的状态异步的写入到持久化存储中。
当sink端接收到所有输入流传递过来的barrier之后,就会向Checkpoint Coordinator通知,此次Checkpoint执行完成。
Chandy-Lamport 算法
在缺乏类似全局时钟或者全局时钟不可靠的分布式系统中来确定一种全局状态
分布式快照算法应用到流式系统中就是确定一个 Global 的 Snapshot
将分布式系统简化成有限个进程和进程之间的 channel 组成,也就是一个有向图:节点是进程,边是 channel。因为是分布式系统,也就是说,这些进程是运行在不同的物理机器上的。那么一个分布式系统的全局状态就是有进程的状态和 channel 中的 message 组成
Flink 在 2015 发布了一篇论文 Lightweight asynchronous snapshots for distributed dataflows
扩展库
Event Processing(CEP)
Graphs:Gelly
Machine Learning
JobManager
处理 Job 提交、 Job 监控以及资源管理
Flink TaskManager
运行 worker 进程, 负责实际任务 Tasks 的执行,而这些任务共同组成了一个 Flink Job
Back Pressure背压
分区
BroadcastPartitioner:广播分区器,将数据发往下游的所有节点
CustomPartitionerWrapper:自定义分区器,可以自定义分区的规则
ForwardPartitioner:转发分区器,将数据转发给在本地运行下游的operater
ShufflePartitioner: 洗牌分区器,将数据在所有output chancel随机选择一个输出
GlobalPartitioner:全局分区器:默认会选择索引为0的channel进行输出
KeyGroupStreamPartitioner:键组分区器,通过记录数据的值获取到分区key:keyGroupId * parallelism / maxParallelism;
RebalancePartitioner:轮询分区器,适用于数据倾斜
RescalePartitioner:可扩展的分区器,通过轮询的方式将数据向下游输出
org.apache.flink
streaming
runtime
tasks
OperatorChain
StreamTask
invoke
Create basic utils (config, etc) and load the chain of operators
operators.setup()
task specific init()
initialize-operator-states()
open-operators()
run()
finish-operators()
close-operators()
common cleanup
task specific cleanup()
jobgraph
JobGraph
优化的逻辑执行计划(Web UI中看到的就是这个)
executiongraph
ExecutionGraph
物理执行计划
api
graph
StreamGraph
原始逻辑执行计划
Spark
模式
spark基于local
spark基于standalone
spark基于yarn
spark基于metsos
spark core
spark sql
DataSet
DataFrame
Spark Streaming 流处理框架
MLlib机器学习库
Graphx图形处理库
集群架构
master
Work Node
集群中可以运行Application代码的节点,在Spark on Yarn模式中指的就是NodeManager节点
Executer
运行在worker节点上的一个进程,负责运行某些task,并将数据存在内存或者磁盘上。
task
在executor进程中执行任务的工作单元
stage
每个job被划分为多个stage,一个stage中包含一个taskset
Cache
Cluster manager
Driver
main()函数,创建SparkContext,由SparkContext进行资源申请,任务的分配和监控等。程序执行完毕后关闭SparkContext。
算子
distinct
groupByKey
弹性式数据集RDDs
一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数;
RDD 拥有一个用于计算分区的函数 compute
RDD 会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算;
Key-Value 型的 RDD 还拥有 Partitioner(分区器),用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区);
操作RDD
transformations(转换,从现有数据集创建新数据集)
actions(在数据集上运行计算后将值返回到驱动程序)
宽依赖和窄依赖
窄依赖 (narrow dependency):父 RDDs 的一个分区最多被子 RDDs 一个分区所依赖;
宽依赖 (wide dependency):父 RDDs 的一个分区可以被子 RDDs 的多个子分区所依赖。
首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)对父分区数据进行计算,例如先执行 map 操作,然后执行 filter 操作。而宽依赖则需要计算好所有父分区的数据,然后再在节点之间进行 Shuffle,这与 MapReduce 类似。
窄依赖能够更有效地进行数据恢复,因为只需重新对丢失分区的父分区进行计算,且不同节点之间可以并行计算;而对于宽依赖而言,如果数据丢失,则需要对所有父分区数据进行计算并再次 Shuffle。
性能
基于内存计算,减少低效的磁盘交互
高效的调度算法,基于DAG
容错机制Linage,精华部分就是DAG和Lingae
优化
防止不必要的jar包分发,提高数据的本地性,选择高效的存储格式如parquet
过滤操作符的优化降低过多小任务
降低单条记录的资源开销
处理数据倾斜
复用RDD进行缓存
作业并行化执行
JVM
启用高效的序列化方法如kyro
增大off head
shuffle
将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition
不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)
Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)
Hadoop MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先 sort
在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蕴含在 transformation() 中。

收藏
立即使用

收藏
立即使用

收藏
立即使用

收藏
立即使用

Collect
Get Started
Collect
Get Started

Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

