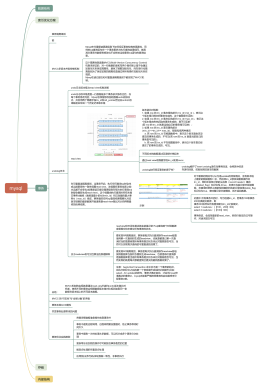
外键约束
1、外键的定义语法:<br>[<b><font color="#a23735">constraint</font></b> symbol] <b><font color="#a23735">foreign key</font></b>(外键字段)<b><font color="#a23735">references</font></b> tbl_name (主表主键)<br>[<b><font color="#a23735">on delete</font></b> {RESTRICT | CASCADE | SET NULL}] [<b><font color="#a23735">on update</font></b> {RESTRICT | CASCADE | SET NULL}]<br>
2、创建表时直接创建外键:<br>CREATE TABLE person (<br>id int PRIMARY KEY AUTO_INCREMENT,<br>name varchar(32) NOT NULL,<br>age tinyint unsigned,<br>salary decimal(10,2),<br>dept_id int ,<br><b><font color="#a23735">constraint dept_fk foreign key(dept_id) references dept(id)<br>);</font></b><br>
3、建表后增加外键:<br>alter table person add<br><b><font color="#a23735">constraint dept_fk<br>foreign key(dept_id)<br>references dept(id)</font></b>;<br>
4、通过外键名称解除外键约束:<br>alter table person drop <b><font color="#a23735">foreign key dept_fk</font></b>;
表关联查询
1、简单多表查询
select 字段1,字段2... from 表1,表2... [where 条件]
2、内连接
SELECT 字段列表 FROM 表1 <b><font color="#a23735"> inner join</font></b> 表2 on 表1.字段 = 表2.字段;
3、左连接
SELECT 字段列表 FROM 表1 <b><font color="#a23735">left join</font></b> 表2 on 表1.字段 = 表2.字段;
4、右连接
SELECT 字段列表 FROM 表1 <b><font color="#a23735">right join</font></b> 表2 on 表1.字段 = 表2.字段;