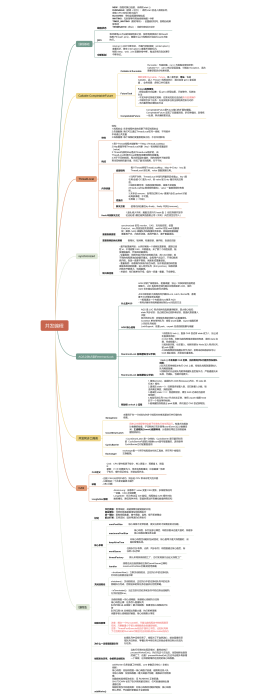
手动创建:new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, milliseconds,runnableTaskQueue, handler);
各参数解析
corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线
程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任 务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,
线程池会提前创建并启动所有基本线程。
maximumPoolSize(线程池最大数量):线程池允许创建的最大线程数。如果队列满了,并
且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如
果使用了无界的任务队列这个参数就没什么效果
keepAliveTime(线程空闲的时间)。线程的创建和销毁是需要代价的。线程执行完任务后不会立即销毁,而是继续存活一段时间:keepAliveTime。默认情况下,该参数只有在线程数大于corePoolSize时才会生效。
keepAliveTime的单位。TimeUnit
runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通 常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用 移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,静态工 厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原
则对元素进行排序。
ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设 置更有意义的名字。使用开源框架guava提供的ThreadFactoryBuilder可以快速给线程池里的线
程设置有意义的名字,代码如下:
new ThreadFactoryBuilder().setNameFormat("XX-task-%d").build();
RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状 态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法 处理新任务时抛出异常。在JDK 1.5中Java线程池框架提供了以下4种策略。
CallerRunsPolicy:只用调用者所在线程来运行任务。
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉。
AbortPolicy:直接抛出异常。