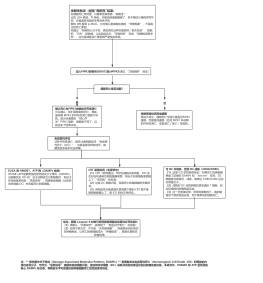
线性回归
<span style="font-size:inherit;">代价函数J(θ,b)=1/2m*Σ(i=1→m)(y^i-yi)²</span><br>
梯度下降(θi'=θi-α*d(J)/dθi=θi-α/m*Σ(i=1→m)(y^i-yi)²*xi<br>b=b-α*d(J)/db)<br>θ' = =θ - α/m*XT(y^-y)<br>注意:θ和b参数应同步更新
正则化后代价函数J(θ,b)=1/2m*Σ(i=1→m)(y^i-yi)²+λ/2m*(Σ(i=1→m)θi)<br>梯度下降为θi'=θi-α*(d(J)/dθi+λ/2m*θi)=(1-α*λ/m)θi-α/m*Σ(i=1→m)(y^i-yi)²*xi)
多项式回归
多特征向量化(NumPy:array、matrix、mat)
特征缩放:使用归一化加快梯度下降过程
逻辑回归
模型:g(zi)=g(θix+b)=1/(1+e-(θix+b))
决策边界:zi=θix+b=0,分类的阈值
损失函数Li= {-log(g(zi)) if y=1<br> {-log(1-g(zi)) if y=0<br>或y(-log(g(zi)))+(1-y)(-log(1-g(zi)))
代价函数J = 1/mΣ(i=1→m)Li
梯度下降:与线性回归类似,对θ和b求导(即为对决策边界的参数)
正则化后代价函数J(θ)=1/m(Σ(i=1→m)Li+λ/2Σ(i=1→m)θi)<br>梯度下降与线性回归类似
多类softmax:a=e^z/Σe^z
常见概念
标签(table):即输出、因变量
训练集(training examples):即训练样本
样本数(number of training examples)
假设(hypothesis):也称模型,即拟合出来的函数
代价函数(cost function):又称成本函数,整体样本的损失值的平均数<br>
学习率(learning rate):一个介于0-1的数
特征缩放(feature scaling):即归一化,用于加速梯度下降
学习曲线(learning curve):可视化训练进度,梯度下降收敛结果
特征工程(feature engineering):通过定义新的合适的特征以获得更好的模型
过拟合(overfitting):过于拟合训练数据导致测试数据差距很大或不能很好的预测实际数据<br>解决过拟合:1、使用更多的训练样本。2、选择合适的重要的特征,而非所有特征。3、正则化,减小参数
正则化(regularized):代价函数J中加入λ/2mΣ(i=1→m)θi,对所有特征进行惩罚以减小过拟合,λ为正则化参数
激活函数:sigmoid函数、REKU函数、Linear