命令
DEL
删除的是列表、集合、有序集合或哈希表类型的 key,如果集合元素过多,是会阻塞Redis的
删除的是字符串类型的 key,但是key对应value比较大,比如有几百M
RANDOMKEY
随机取出一个 key,这个命令可能导致Redis死循环阻塞
数据一致(MySQL)
旁路缓存
查询
先读缓存
如果命中,直接返回
如果缺失,查 DB 并将结果放入缓存,再返回
增、删、改
新增数据,直接存 DB,
修改、删除数据,先更新DB,再删缓存
1. 先更新Mysql,再更新Redis,如果更新Redis失败,可能仍然不⼀致
2. 先删除Redis缓存数据,再更新Mysql,再次查询的时候在将数据添加到缓存中
3. 延时双删,步骤是:先删除Redis缓存数据,再更新Mysql,延迟⼏百毫秒再删除Redis缓存数据,
分布式锁
1. ⾸先利⽤setnx来保证:如果key不存在才能获取到锁,如果key存在,则获取不到锁
2. 然后还要利⽤lua脚本来保证多个redis操作的原⼦性
3. 同时还要考虑到锁过期,所以需要额外的⼀个看⻔狗定时任务来监听锁是否需要续约
4. 同时还要考虑到redis节点挂掉后的情况,所以需要采⽤红锁的⽅式来同时向N/2+1个节点申请锁,都申请到了才证明获取锁成功,这样就算其中某个redis节点挂掉了,锁也不能被其他客户端获取到
Redisson框架
给获得锁的线程,开启一个定时守护线程,每隔时检查锁是否存在,延长锁key的生存时间,这就解决了锁过期释放,业务还没执行完的情况。
集群部署分布式锁Redlock+Redisson
数据结构
1.字符串(strings)
⽤来做最简单的数据,可以缓存某个简单的字符串,也可以缓存某个json格式的字符串,Redis分布式锁的实现就利⽤了这种数据结构,还包括可以实现计数器、Session共享、分布式ID
2.字符串列表(lists)
Redis的列表通过命令的组合,既可以当做栈,也可以当做队列来使⽤,可以⽤来缓存类似微信公众号、微博等消息流数据
3.字符串集合(sets)
和列表类似,也可以存储多个元素,但是不能重复,集合可以进⾏交集、并集、差集操作,从⽽可以实现类似,我和某⼈共同关注的⼈、朋友圈点赞等功能
4.有序字符串集合(sorted sets)
集合是⽆序的,有序集合可以设置顺序,可以⽤来实现排⾏榜功能
5.哈希(hashes)
可以⽤来存储⼀些key-value对,更适合⽤来存储对象
缓存失效
缓存雪崩
某一时刻大批量热点数据同时过期
1、在过期时间上增加⼀点随机值
2、服务降级:暂停非核心数据查询缓存,返回预定义信息(错误页面,空值等)
3、跑定时任务,在缓存失效前刷进新的缓存
搭建⼀个⾼可⽤的Redis集群
redis宕机
1、事前预防:搭建高可用集群事前预防:
2、多级缓存:缺点是实现复杂度高
3、熔断:通过监控一旦雪崩出现,暂停缓存访问,待实例恢复,返回预定义信息(有损方案
4、限流:通过监控一旦发现数据库访问量超过阈值,限制访问数据库的请求数(有损方案)
缓存击穿
某⼀个热点key突然失效
这个热点key不设置过期时间(永不过期)
加上互斥锁
缓存穿透
⼤量key都在redis中不存在
很可能被恶意请求利用
解决
将此不存在的key 关联 null值放入缓存,缺点是这样的key 没有任何业务作用,白占空间
解决:布隆过滤器
① 过滤器可以用来判定 key 不存在,发现这些不存在的 key,把它们过滤掉就好
② 需要将所有的key 都预先加载至布隆过滤器
③ 布隆过滤器不能删除,因此查询删除的数据一定会发生穿透
区别
缓存雪崩与缓存击穿都是数据库中有,但缓存暂时缺失
缓存雪崩与缓存击穿都能自然恢复,但缓存穿透则不能
集群
主从模式
主从复制、读写分离
全量复制
部分复制
主从第一次同步是全量同步,但如果slave重启后同步,则执行增量同步
读写分离
读操作:主库、从库都可以执行处理;
写操作:先在主库执行,再由主库将写操作同步给从库。
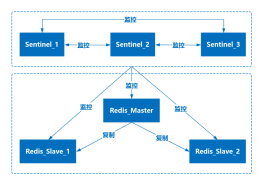
哨兵模式
监控:哨兵进程会周期性地给所有的主从库发送 PING 命令,检测它们是否仍然在线运行。
主观下线:哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状态, 如果单哨兵发现主库或从库对 PING 命令的响应超时了,那么,哨兵就会先把它标记为“主观下线”
客观下线:在哨兵集群中,基于少数服从多数,多数实例都判定主库已“主观下线”,则认为主库“客观下线”。
选主(选择主库):主库挂了以后,哨兵基于一定规则评分选选举出一个从库实例新的主库 。
通知 :哨兵会将新主库的信息发送给其他从库,让它们和新主库建立连接,并进行数据复制(让从库执行replacaof,与新主库同步)。同时,哨兵会把新主库的信息广播通知给客户端,让它们把请求操作发到新主库上。