AI
推荐
模板社区
专题
登录
免费注册
首页
思维导图
详情
机器学习
2024-09-10 10:53:00
31
举报
分享方式
免费使用
AI智能生成
对周志华老师的《机器学习》主要内容进行梳理
大学
机器学习
学习
计算机科学与技术
人工智能
模板推荐
作者其他创作
大纲/内容
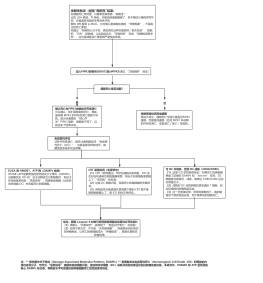
绪论
1.1机器学习
1.2 学习,训练;分类,回归,聚类;泛化;独立同分布
1.3 假设空间
1.4 归纳偏好,学习算法好坏需结合实际问题谈
1.5NP难题
模型评估与选择
2.1 欠拟合/过拟合,经验误差/泛化误差
2.2评估方法 给定数据集,适当处理产生训练集和测试集
常见方法
留出法
“分层采样”
若干次随机划分,重复实验取评估均值作为结果
训练集/测试集→2:1~4:1
p次k折交叉验证
稳定性保真性取决于k
自助法
“包外估计”
调参与最终模型
算法的参数
人工
模型的参数
学习
2.3性能度量
回归任务
均方误差(2.2)
分类任务
错误率与精度
查准率与查全率
PR图
ROC
TPR
FPR
AUC
代价敏感错误率与代价曲线
非均等代价
期望总体代价
2.4比较检验(错误率e为度量)
性能比较中的问题
算法随机性
测试集性能限制性
泛化性能难直接评估
假设检验 前提:测试e为泛化e的独立采样
二项检验
测试错误率→泛化错误率分布
一数据集两算法
交叉验证t检验
5x2交叉验证
McNemar检验
卡方检验
一数据集多算法
Friedman检验与Nemenyi后续检验
F计算平均序值,N计算临界值域,AB交叠,AB无显著差别,AC无交叠,A显著优于C
2.5偏差-方差分解
偏差刻画学习算法拟合能力
方差刻画数据扰动造成的影响
噪声刻画学习问题本身的难度
欠拟合→过拟合
线性回归
基本形式:
线性回归
最小二乘“参数估计”
多元线性回归
正则化6.4 11.4
对数线性回归:
广义线性模型:g为单调可微
分类
二分类
对数几率回归
近似单位跃阶函数
Sigmoid函数
y视为样本x为正例的可能性,y/1-y为几率
优点:P58
y视为类后验概率估计
极大似然法7.2
线性判别分析LDA:
目标:最大化Sb(类间散度矩阵)Sw(类内~)的广义瑞利商
同类样例投影点尽可能近
异类样例投影点尽可能远
多分类
拆解出二分类任务训练分类器,对分类器预测结果集成获得最终多分类结果
拆解
OvO
OvR
考虑置信度
MvM
ECOC
编码
解码:比较预测编码和类别编码返回距离最小值
集成 8.4
类别不平衡
再缩放
欠采样
过采样
阈值移动
特征选择与稀疏学习
特征选择
基础环节
子集搜索
前向搜索
后向搜索
子集评价
信息增益
分类
过滤式选择
Relief
相关统计量的确定:对比猜中近邻和猜错近邻的大小,控制属性对应统计量分量
包裹式选择
LVW
子集搜索
拉斯维加斯方法
特征子集评价准则
分类器误差
嵌入式选择
融合特征选择和学习器训练过程
正则化降低过拟合
稀疏表示与字典学习
稀疏稠密数据简化任务
压缩感知
Nyquist采样定理→信号恢复
感知测量
如何对原始信号处理以获得稀疏样本表示
傅里叶变换
小波变换
字典学习
重构恢复
基于稀疏性从少量观测恢复原信号
k限定等距性:
计算学习理论
确定性学习问题
研究经验误差和泛化误差之间的逼近程度
PAC学习
概念;概念类;学习算法;假设空间;假设;可分的
PAC辨识
PAC可学习
PAC学习算法
样本复杂度
有限假设空间
可分
不可分
假设空间复杂度
VC维
Rademacher复杂度
考虑数据分布
算法稳定性
ERM
监督模型
单一
线性模型
K邻近
影响因素:k和距离计算方式
懒惰学习
决策树
划分选择
提高节点纯度
信息增益
信息增益率
gini index
剪枝
预剪枝
后剪枝
连续/确失值处理
多变量决策树
线性分类器
神经网络
M-P神经元模型:
感知机:
神经网络
BP:
过拟合
早停
正则化
局部极小
多组参数值初始化
模拟退火
随机梯度下降
其他网络
深度学习
SVM支持向量机
线性可分
最大化间隔
Lagrange乘子法
SMO
难分开?过拟合?
软间隔
SVR
核方法
核函数,核聚类,核感知机,核PCA
样本映射到高维空间内线性可分
KLDA
集成
构建并结合多个学习器
学习器生成方式
个体学习器间无强依赖关系:并行化
Bagging
自助采样法
随机森林RF
决策树为基学习器,训练过程加入随机属性选择,Bagging集成
效率优,泛化误差低
个体学习器间强依赖关系:序列化
Boosting 通过重赋权法/重采样法,使学习器对特定数据分布学习
AdaBoost:基于加性模型推导结果
关注降低偏差,对泛化性能弱的学习器构建强集成
结合策略
方法
平均
加权平均
投票
学习
多样性
误差-分歧分解
多样性度量
半监督模型
学习器不依赖外界交互、自动利用未标记样板提升学习性能
生成式方法
假设模型必须与真实数据分吻合
半监督SVM
设计高效优化求解策略
图半监督学习
存储开销
新样本处理
半监督聚类
必连
勿连
基于分歧的方法
利用不同学习器标记分歧
协同训练
多视图补充
无监督模型
聚类
性能度量
与某模型比较
原型聚类
原型向量
学习向量量化LVQ
k均值算法
概率模型
高斯混合聚类:初始化+EM算法
考察结果
密度聚类
从样本密度考虑样本可连接性
DBSCAN
层次聚类
树状
AGNES
降维
多维缩放MDS
PCA
KPCA
对应核函数,似KLDA→LDA
流形学习
Isomap
计算距离:流形在局部与欧式空间同胚
局部线性嵌入LLE
保持邻域内样本间线性关系
度量学习
学习出合适的距离度量
概率模型
EM算法
隐变量
贝叶斯
判别式模型
决策树、BP神经网络、支持向量机等
生成式模型
朴素贝叶斯
属性条件独立性假设
半朴素贝叶斯
独依赖估计ODE
SPODE
TAN
AODE
贝叶斯网
DAG刻画依赖关系,CPT描述属性联合概率分布
结构
边际独立性
有向分离
学习
评分函数
最小描述长度准则MDL
求解最优贝叶斯网结构
贪心法
约束以削减
推断
近似推断:吉布斯采样
概率图
有向无环
贝叶斯网
HMM
系统下一时刻的状态仅由当前状态决定
结构组成
参数
状态转移概率
输出观测概率
初始状态概率
状态空间y,观测空间x
话题模型
隐狄利克雷分配模型LDA
无向
马尔可夫网
团上势函数来定义概率
MRF
全局马尔可夫性
给定观测值
CRF
学习和推断
计算边际/条件概率
精确推断
变量消去
多个边际分布重复计算
信念传播
近似推断
采样
基于期望决策,则求解期望
MCMC
马尔科夫链满足平稳条件:
马尔科夫链构造重要,取得符合后验分布的样本
MH
“拒绝采样”
变分推断
简单分布逼近复杂分布
盘式标记法
MLE
估计类条件概率:假定其有某种确定的概率分布形式,估计参数
规则学习
可解释性
规则
关系型规则
特例:命题规则
从训练数据学习出一组能用于对未见示例判别的规则
序贯覆盖
分治
命题规则学习
产生规则?
一般到特殊
特殊到一般
后期调整
预剪枝
CN2
后剪枝
减错剪枝REP
IREP
生成规则后立刻剪枝
结合其他手段减枝
RIPPER:从全局考虑缓解贪心算法局部性
命题规则难以处理对象关系时使用
一阶规则学习
FOIL
使用FOIL来选择候选文字
归纳逻辑程序设计ILP
一阶规则学习中引入逻辑表达式和函数嵌套
最小一般泛化:常量替换
逆归结:发展新关系与概念
发明心谓词
强化学习
马尔可夫决策过程MDP描述:环境E,状态(x)空间为X,能采取的行动a构成动作空间,潜在转移函数P,转移时奖赏函数R反馈给机器
目标:长期累积奖赏最大化 T步/y折扣
有“延迟标记信息”的监督学习问题
最大化单步奖赏
K摇臂赌博机
分配
e-贪心法
e的概率探索
1-e的概率利用
Softmax
探索
为获知摇臂期望奖赏
利用
为执行奖赏最大动作
有模型学习
评估策略值函数
策略改进
最优Bellman等式
将策略选择动作改编为当前最优动作
策略迭代与值迭代
评估改进交替
模型未知情形
策略估计困难
蒙特卡罗强化学习
考虑采样轨迹,“批处理式”
时序差分学习TD
结合MDP结构,及时更新
Sarsa
Q-learning:异策略
值函数近似
离散→连续
线性值函数
模仿学习
直接模仿学习
模仿人类专家“状态-动作对”
逆强化学习
从人类专家范例数据反推出奖励函数
Nevele
收藏
立即使用
机器学习
Nevele_
职业:无
去主页
Collect
Get Started
学习
Collect
Get Started
机器学习
Collect
Get Started
机器学习
Collect
Get Started
机器学习
评论
0
条评论
下一页
图形选择
思维导图
主题
补充说明
AI生成
修改AI描述
去编辑
重新生成
提示
关闭后当前内容将不会保存,是否继续?
取消
确定
Document