
Java大纲包含后端用到的所有知识
2025-03-04 16:11:09 0 举报Java后端核心知识大纲概览: - **Java基础**:理解Java语言基础,如变量、数据类型、运算符、控制流(if, for, while, switch)、数组和字符串处理等。 - **面向对象编程**(OOP):掌握类与对象、继承、多态、封装等OOP核心概念,以及接口和抽象类的使用。 - **Java集合框架**:熟悉List, Set, Map等集合接口及其实现,包括ArrayList, LinkedList, HashSet, TreeSet, HashMap等,并理解集合的迭代、排序与比较器(Comparator)。 - **异常处理**:学会使用try-catch-finally进行异常捕获和处理,理解Checked与Unchecked异常的差异。 - **Java I/O**:掌握字节流(InputStream, OutputStream)和字符流(Reader, Writer)的操作,包括文件读写和序列化。 - **多线程和并发**:理解Java线程的创建与使用,如继承Thread类或实现Runnable接口,同步(synchronized)机制,线程池(ExecutorService)的使用,以及并发工具类(如CountDownLatch, CyclicBarrier)的应用。 - **网络编程**:掌握Socket编程,以及HTTP协议和相关类(如URL, HttpURLConnection)的使用。 - **Java数据库连接(JDBC)**:熟悉使用JDBC API进行数据库操作,包括连接数据库、执行SQL语句、处理结果集以及事务管理。 - **框架与技术栈**:深入了解Spring框架(包括核心容器、MVC、Data JPA)、MyBatis、Hibernate等ORM框架。 - **Java虚拟机(JVM)**:理解JVM的工作原理,包括内存管理、垃圾回收机制等。 - **构建工具与版本控制**:掌握Maven或Gradle的构建过程,以及Git的基本使用。 - **单元测试与集成测试**:应用JUnit进行单元测试,了解Mock框架(如Mockito)的使用。 - **设计模式与最佳实践**:理解和应用常见设计模式,掌握软件设计的最佳实践。 - **持续集成/持续部署(CI/CD)**:理解CI/CD的流程,可能会用到的工具有Jenkins, GitLab CI等。 文件类型:PDF或.docx。 修饰语:详尽的、实用的、最新版的、完整的、指南式的、适合自己学习节奏的。
后端开发
综合知识
大纲解析
java
面试宝典
模板推荐
作者其他创作
大纲/内容
框架
spring
描述
Spring 是 Java 生态中最流行的企业级开发框架,主要用于构建高效、可扩展、易维护的 Java 应用程序。Spring 提供了一整套解决方案,包括依赖注入(DI)、面向切面编程(AOP)、事务管理、MVC 架构、数据访问、消息队列集成等。
Spring 框架核心组成
Spring 框架的核心主要由以下几个模块组成:<br><br><ul><li>Spring Core 容器(Core、Beans、Context、Expression Language)</li><li>AOP(面向切面编程)</li><li>数据访问(JDBC、ORM)</li><li>事务管理</li><li>Web(Spring MVC)</li><li>Spring Security(安全)</li><li>Spring Boot(简化 Spring 配置)</li><li>Spring Cloud(微服务架构)</li></ul>
Spring 框架核心模块
Spring Core 容器
Spring Core 负责管理应用程序中的 Bean,提供依赖注入(DI)功能。<br>
依赖注入(DI - Dependency Injection):依赖注入是 Spring 的核心特性,它可以自动管理对象之间的依赖关系。<br>
基于 XML 配置<br><bean id="userService" class="com.example.UserService"><br> <property name="userDao" ref="userDao"/><br></bean><br><br><bean id="userDao" class="com.example.UserDao"/><br><br>基于 Java 配置<br>@Configuration<br>public class AppConfig {<br> @Bean<br> public UserDao userDao() {<br> return new UserDao();<br> }<br><br> @Bean<br> public UserService userService() {<br> UserService userService = new UserService();<br> userService.setUserDao(userDao());<br> return userService;<br> }<br>}<br><br>基于注解配置<br>@Component<br>public class UserDao {}<br><br>@Service<br>public class UserService {<br> @Autowired<br> private UserDao userDao;<br>}
AOP(面向切面编程)
AOP 允许我们在不修改业务逻辑的情况下增强功能(如日志、事务、权限控制等)。<br><br>(1)AOP 术语<br>JoinPoint:目标方法(连接点)<br>Pointcut:方法匹配规则(切点)<br>Advice:额外增强逻辑(通知)<br>Aspect:一组 Advice(切面)<br>Weaving:将 Aspect 织入目标对象的过程<br><br>(2)AOP 示例<br>@Aspect<br>@Component<br>public class LoggingAspect {<br> @Before("execution(* com.example.service.*.*(..))")<br> public void beforeMethod(JoinPoint joinPoint) {<br> System.out.println("Before method: " + joinPoint.getSignature().getName());<br> }<br>}<br>
数据访问(JDBC、ORM)
Spring 提供了一系列用于简化数据库操作的模块。<br><br>(1)JDBC 操作<br>@Repository<br>public class UserDao {<br> @Autowired<br> private JdbcTemplate jdbcTemplate;<br><br> public User getUserById(int id) {<br> return jdbcTemplate.queryForObject("SELECT * FROM users WHERE id=?", new Object[]{id}, new BeanPropertyRowMapper<>(User.class));<br> }<br>}<br><br>(2)Spring + MyBatis<br>@Mapper<br>public interface UserMapper {<br> @Select("SELECT * FROM users WHERE id = #{id}")<br> User getUserById(int id);<br>}<br>
事务管理
Spring 提供了声明式事务管理,常用于数据库操作。<br><br>(1)XML 配置<br><tx:annotation-driven transaction-manager="transactionManager"/><br><bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><br> <property name="dataSource" ref="dataSource"/><br></bean><br><br>(2)注解方式<br>@Service<br>public class UserService {<br> @Transactional<br> public void updateUser(User user) {<br> userDao.update(user);<br> // 其他数据库操作<br> }<br>}<br>
Spring MVC(Web 层)
Spring MVC 是 Spring 提供的 Web 框架,基于 Servlet 架构。<br><br>(1)Spring MVC 组件<br>DispatcherServlet(前端控制器)<br>HandlerMapping(处理器映射)<br>Controller(控制器)<br>ViewResolver(视图解析器)<br><br>(2)Spring MVC 示例<br>@Controller<br>@RequestMapping("/user")<br>public class UserController {<br> @Autowired<br> private UserService userService;<br><br> @GetMapping("/{id}")<br> public ResponseEntity<User> getUser(@PathVariable int id) {<br> return ResponseEntity.ok(userService.getUserById(id));<br> }<br>}<br>
Spring Security(安全管理)
Spring Security 提供了身份认证和权限控制功能。<br><br>(1)Spring Security 配置<br>@Configuration<br>@EnableWebSecurity<br>public class SecurityConfig extends WebSecurityConfigurerAdapter {<br> <br> @Override<br> protected void configure(HttpSecurity http) throws Exception {<br> http.authorizeRequests()<br> .antMatchers("/admin/**").hasRole("ADMIN")<br> .antMatchers("/user/**").authenticated()<br> .and().formLogin();<br> }<br>}<br>
Spring IOC(控制反转)
什么是 IOC?
IOC(Inversion of Control,控制反转) 是一种设计原则,它将对象的创建和管理交给 Spring 容器,而不是手动在代码中实例化对象。<br><br>IOC 解决了什么问题?<br>在传统 Java 代码中,对象是主动创建的:<br><br>public class UserService {<br> private UserDao userDao = new UserDao(); // 直接创建对象<br>}<br><br>这种方式的问题:<br><ul><li>紧耦合(难以替换实现)</li><li>难以维护(无法轻松管理对象)</li><li>不易扩展(更换 UserDao 需要修改 UserService 代码)</li></ul><br>IOC 让对象变成被动获取:<br>@Service<br>public class UserService {<br> @Autowired<br> private UserDao userDao; // 由 Spring 容器管理<br>}<br><br><ul><li>由 Spring 自动注入 UserDao,不需要手动创建对象</li><li>解耦 了 UserService 和 UserDao</li><li>提高了 灵活性 和 可维护性</li></ul>
依赖注入(DI)
依赖注入(DI, Dependency Injection)是 IOC 的核心机制,Spring 通过 DI 负责注入对象。
DI 的三种方式<br>(1)基于 XML 配置<br><bean id="userDao" class="com.example.UserDao"/><br><br><bean id="userService" class="com.example.UserService"><br> <property name="userDao" ref="userDao"/><br></bean><br><br>(2)基于 Java 配置<br>@Configuration<br>public class AppConfig {<br> @Bean<br> public UserDao userDao() {<br> return new UserDao();<br> }<br><br> @Bean<br> public UserService userService() {<br> return new UserService(userDao());<br> }<br>}<br><br>(3)基于注解<br>@Component<br>public class UserDao {}<br><br>@Service<br>public class UserService {<br> @Autowired<br> private UserDao userDao;<br>}<br>
Spring IOC 容器
(1)BeanFactory 和 ApplicationContext<br><ul><li>BeanFactory(底层 IOC 容器):懒加载(性能高,但功能少)</li><li>ApplicationContext(高级 IOC 容器):支持 AOP、事件发布等功能,推荐使用。</li></ul><br>(2)IOC 容器的创建<br>ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);<br>UserService userService = context.getBean(UserService.class);<br>
IOC 的底层实现
Spring IOC 容器
<br>
IOC 容器的初始化过程
Spring IOC 容器的核心实现类是 DefaultListableBeanFactory,IOC 容器的初始化过程如下:<br><br>IOC 容器初始化流程<br><span style="font-size: inherit;">1、加载 BeanDefinition(Bean 定义)</span><br><ul><li>解析 @ComponentScan 或 XML 配置,扫描出所有 @Component、@Service 等标注的类。</li></ul><span style="font-size: inherit;">2</span>、<span style="font-size: inherit;">注册 BeanDefinition 到 BeanFactory</span><br><ul><li>解析 BeanDefinition(Bean 的元信息,包括 class、scope、initMethod 等)。</li></ul>3、实例化 Bean(创建对象)<br><ul><li>如果是 singleton,则创建单例 Bean 并缓存。</li><li>如果是 prototype,则每次获取时重新创建。</li></ul>4、依赖注入(DI)<br><ul><li>解析 @Autowired、@Qualifier,进行依赖注入。</li><li>依赖注入有 构造函数注入 和 setter 方法注入。</li></ul>5、初始化 Bean<br><ul><li>执行 @PostConstruct 方法</li><li>执行 InitializingBean 接口的 afterPropertiesSet 方法</li><li>执行 init-method 指定的方法</li></ul>6、完成 Bean 的创建并存入容器<br>
Spring IOC 的核心类
<br>
依赖注入(DI)的实现
Spring 通过 AutowiredAnnotationBeanPostProcessor 处理 @Autowired 注解,实现依赖注入。<br><br>依赖注入的底层过程<br><ol><li>扫描 BeanDefinition</li><li>实例化 Bean</li><li>执行 AutowiredAnnotationBeanPostProcessor</li><li>反射调用 setUserDao() 或构造方法注入</li></ol>
AOP(面向切面编程)
什么是 AOP?
AOP(Aspect-Oriented Programming,面向切面编程)用于在不改变业务代码的情况下,增强某些功能(如日志、事务、安全等)。
AOP 解决的问题<br>
假设我们需要在 UserService 的方法执行前后记录日志:<br><br>public void saveUser() {<br> System.out.println("开始执行 saveUser 方法...");<br> // 业务逻辑<br> System.out.println("saveUser 方法执行完毕...");<br>}<br><ul><li>代码重复(每个方法都需要加日志)</li><li>侵入式(破坏业务代码的整洁性)</li></ul><br>AOP 让日志逻辑与业务逻辑分离:<br>@Aspect<br>@Component<br>public class LoggingAspect {<br> @Before("execution(* com.example.service.*.*(..))")<br> public void beforeMethod() {<br> System.out.println("开始执行方法...");<br> }<br>}<br>
AOP 术语
<br>
AOP 注解
@Aspect(定义切面)
@Aspect
@Component
public class LoggingAspect {}
@Pointcut(定义切点)
@Pointcut("execution(* com.example.service.*.*(..))")
public void serviceMethods() {}
通知(Advice)
<br>@Aspect<br>@Component<br>public class LoggingAspect {<br><br> @Pointcut("execution(* com.example.service.*.*(..))")<br> public void serviceMethods() {}<br><br> @Before("serviceMethods()")<br> public void beforeMethod(JoinPoint joinPoint) {<br> System.out.println("执行前:" + joinPoint.getSignature().getName());<br> }<br><br> @After("serviceMethods()")<br> public void afterMethod(JoinPoint joinPoint) {<br> System.out.println("执行后:" + joinPoint.getSignature().getName());<br> }<br>}<br>
@Around 注解(高级用法)
@Around 能够在方法前后执行逻辑,还能修改返回值。<br><br>@Aspect<br>@Component<br>public class ExecutionTimeAspect {<br><br> @Around("execution(* com.example.service.*.*(..))")<br> public Object measureExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {<br> long start = System.currentTimeMillis();<br> Object result = joinPoint.proceed(); // 继续执行目标方法<br> long end = System.currentTimeMillis();<br> System.out.println(joinPoint.getSignature().getName() + " 执行时间:" + (end - start) + "ms");<br> return result;<br> }<br>}<br>
Spring AOP 实现原理
AOP(Aspect-Oriented Programming,面向切面编程) 允许在不修改源代码的情况下增强方法的行为。<br><br>Spring AOP 基于代理模式实现,包括:<br><ul><li>JDK 动态代理(基于接口)</li><li>CGLIB 动态代理(基于子类继承)</li></ul>
Spring AOP 的底层实现
JDK 动态代理
JDK 动态代理基于 Java 反射 Proxy 类,它只适用于实现了接口的类。<br><br>JDK 动态代理实现:<br><br>import java.lang.reflect.InvocationHandler;<br>import java.lang.reflect.Method;<br>import java.lang.reflect.Proxy;<br><br>// 目标接口<br>interface UserService {<br> void save();<br>}<br><br>// 目标类<br>class UserServiceImpl implements UserService {<br> public void save() {<br> System.out.println("保存用户信息...");<br> }<br>}<br><br>// 代理工厂<br>class ProxyFactory {<br> public static Object getProxy(Object target) {<br> return Proxy.newProxyInstance(<br> target.getClass().getClassLoader(),<br> target.getClass().getInterfaces(),<br> new InvocationHandler() {<br> public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {<br> System.out.println("执行前增强...");<br> Object result = method.invoke(target, args);<br> System.out.println("执行后增强...");<br> return result;<br> }<br> }<br> );<br> }<br>}<br><br>// 测试代理<br>public class AOPDemo {<br> public static void main(String[] args) {<br> UserService proxy = (UserService) ProxyFactory.getProxy(new UserServiceImpl());<br> proxy.save();<br> }<br>}<br>执行结果:<br><ul><li>执行前增强...</li><li>保存用户信息...</li><li>执行后增强...</li></ul><br>
CGLIB 动态代理
CGLIB 代理基于 子类继承机制,适用于没有接口的类。<br><br>CGLIB 代理实现:<br><br>import net.sf.cglib.proxy.Enhancer;<br>import net.sf.cglib.proxy.MethodInterceptor;<br>import net.sf.cglib.proxy.MethodProxy;<br>import java.lang.reflect.Method;<br><br>// 目标类(无接口)<br>class UserService {<br> public void save() {<br> System.out.println("保存用户信息...");<br> }<br>}<br><br>// 代理工厂<br>class CglibProxyFactory implements MethodInterceptor {<br> private Object target;<br><br> public CglibProxyFactory(Object target) {<br> this.target = target;<br> }<br><br> public Object getProxy() {<br> Enhancer enhancer = new Enhancer();<br> enhancer.setSuperclass(target.getClass());<br> enhancer.setCallback(this);<br> return enhancer.create();<br> }<br><br> public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {<br> System.out.println("执行前增强...");<br> Object result = proxy.invokeSuper(obj, args);<br> System.out.println("执行后增强...");<br> return result;<br> }<br>}<br><br>// 测试代理<br>public class CglibAOPDemo {<br> public static void main(String[] args) {<br> UserService proxy = (UserService) new CglibProxyFactory(new UserService()).getProxy();<br> proxy.save();<br> }<br>}<br>
CGLIB 代理 vs JDK 代理
<br>
总结
<br>
springmvc
描述
Spring MVC(Model-View-Controller)是 Spring 框架中的 Web 层框架,用于构建基于 Servlet 的 Web 应用。它遵循 MVC 设计模式,提供了请求处理、数据绑定、视图解析、表单验证、REST 支持等功能。
Spring MVC 架构概述
Spring MVC 采用 前端控制器(DispatcherServlet)模式,整个请求处理流程如下:<br><br>浏览器请求 -> DispatcherServlet -> 处理器映射 -> 控制器(Controller)-> 业务逻辑层 -> 视图解析器 -> 响应<br>
Spring MVC 主要组件:
<ul><li>DispatcherServlet 前端控制器,拦截所有请求并分发</li><li>HandlerMapping 处理器映射,找到对应的 Controller</li><li>Controller 业务逻辑控制器,处理请求并返回数据</li><li>ViewResolver 视图解析器,解析 View(如 JSP、Thymeleaf)</li><li>ModelAndView 传递数据给 View 层</li><li>Interceptor 拦截器,处理权限、日志等</li></ul>
Spring MVC 请求处理流程
<ol><li>用户请求 -> DispatcherServlet</li><li>HandlerMapping 查找 Controller</li><li>Controller 处理请求,返回 ModelAndView</li><li>ViewResolver 解析视图</li><li>渲染视图并返回响应</li></ol>
组件详细解析
DispatcherServlet(前端控制器)
Spring MVC 的 核心,继承自 HttpServlet,在 web.xml 中配置:
HandlerMapping(处理器映射)
用于 查找请求对应的 Controller,Spring 提供以下实现:<br><br>RequestMappingHandlerMapping解析 @RequestMapping 注解<br>SimpleUrlHandlerMapping解析 XML 配置的 URL 映射
HandlerAdapter(处理器适配器)
作用:调用 Controller 方法。<br>默认适配器:<br><br>RequestMappingHandlerAdapter 处理 @RequestMapping 方法
ViewResolver(视图解析器)
Spring MVC 解析 ModelAndView 的视图名称并返回相应页面。常见视图解析器:<br><br>InternalResourceViewResolver 解析 JSP<br>ThymeleafViewResolver 解析 Thymeleaf<br>FreeMarkerViewResolver 解析 FreeMarker
Spring MVC 拦截器
HandlerInterceptor(拦截器)
用于 权限校验、日志记录:
springboot
什么是 Spring Boot?
Spring Boot 是 Spring 框架的一个子项目,它用来简化 Spring 应用的开发。它提供了一套 约定优于配置(Convention Over Configuration) 的方案,自动配置(Auto Configuration),以及一个 内嵌 Web 服务器,大幅减少了 XML 配置,让开发更加简单高效。<br>
Spring Boot 主要特性
<br>
Spring Boot 启动流程
Spring Boot 采用 SpringApplication 作为启动入口,核心流程如下:<br><br><ul><li>创建 SpringApplication 对象</li><li>加载 ApplicationContext</li><li>启动 Embedded Web Server(Tomcat)</li><li>运行 ApplicationRunner 或 CommandLineRunner</li><li>应用启动完成,等待请求</li></ul>
Spring Boot 核心原理
SpringApplication 启动流程
底层流程分析<br><br><ul><li>调用 SpringApplication.run()</li><li>初始化 SpringApplication</li><li>调用 prepareEnvironment() 加载环境变量</li><li>创建 ApplicationContext</li><li>刷新 ApplicationContext</li><li>启动 Web 服务器</li><li>调用 ApplicationRunner 和 CommandLineRunner</li><li>应用启动完成</li></ul>
Spring Boot 自动配置(核心机制)
@SpringBootApplication
@SpringBootApplication = @Configuration + @EnableAutoConfiguration + @ComponentScan
<ul><li>@Configuration:允许 Java 配置 Bean</li><li>@EnableAutoConfiguration:开启 Spring Boot 自动配置</li><li>@ComponentScan:自动扫描 @Component、@Service、@Repository</li></ul>
@EnableAutoConfiguration
该注解的核心逻辑:<br><br><ol><li>读取 META-INF/spring.factories</li><li>加载 EnableAutoConfiguration 配置的所有类</li><li>通过 @ConditionalOnClass 或 @ConditionalOnMissingBean 进行自动装配</li></ol>spring-boot-autoconfigure.jar 中的 spring.factories:<br><ul><li>org.springframework.boot.autoconfigure.EnableAutoConfiguration=\</li><li>org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration,\</li><li>org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration<br></li></ul>原理解析<br><ul><li>@ConditionalOnClass(DataSource.class):只有 DataSource 存在时才生效</li><li>@ConditionalOnMissingBean(DataSource.class):如果 DataSource 已被用户手动定义,则不启用</li></ul>
自动装配的底层原理
@EnableAutoConfiguration 的加载机制
Spring Boot 自动装配的实现流程如下:<br><br><ol><li>读取 spring.factories 配置文件,找到 EnableAutoConfiguration 相关的自动配置类。</li><li>使用 AutoConfigurationImportSelector 选择合适的自动配置类。</li><li>根据 @Conditional 注解 判断是否满足加载条件(如 @ConditionalOnClass、@ConditionalOnMissingBean)。</li><li>向 Spring 容器中注册自动配置的 Bean。</li></ol>
spring.factories
它列出了所有可用的自动配置类,例如:<br><ul><li>DataSourceAutoConfiguration(数据库配置)</li><li>WebMvcAutoConfiguration(Spring MVC 配置)</li><li>HibernateJpaAutoConfiguration(JPA 配置)</li></ul>Spring Boot 在应用启动时自动加载这些类,并判断是否需要激活。
AutoConfigurationImportSelector
@EnableAutoConfiguration 的核心逻辑在 AutoConfigurationImportSelector 里:<br><ul><li>SpringFactoriesLoader.loadFactoryNames() 方法会读取 spring.factories 配置文件,并加载所有 EnableAutoConfiguration 配置的类。</li></ul>
@Conditional 条件注解
<br>
springcloud
描述
Spring Cloud 是基于 Spring Boot 构建的一整套微服务架构解决方案,提供了 服务治理、配置管理、负载均衡、熔断机制、消息驱动、分布式任务调度 等功能,使微服务架构的开发更加简洁高效。
Spring Cloud 核心组件
<br>
Spring Cloud 组件详解
服务注册与发现
Eureka(Netflix 提供)
Eureka 是 Spring Cloud 早期默认的服务注册与发现组件。<br><br><ul><li>Eureka Server:服务注册中心</li><li>Eureka Client:服务提供者和消费者</li></ul>特点:<br><ul><li>支持自我保护机制,避免短暂故障时误剔除服务</li><li>支持客户端缓存,提高性能</li><li>适用于小型微服务架构</li></ul>
Nacos(阿里巴巴提供)
Nacos 是阿里云开源的服务注册与配置管理组件,支持动态服务发现。<br><br>优点:<br><ul><li>支持 DNS 级别的服务发现</li><li>支持 AP 和 CP 模式切换</li><li>支持配置管理(替代 Spring Cloud Config)</li><li>适用于大规模微服务架构</li></ul>
负载均衡
Ribbon
Ribbon 是 Spring Cloud 内置的客户端负载均衡组件,可自动从注册中心拉取可用服务实例并进行负载均衡。<br><br>支持的策略:<br><ul><li>轮询(默认)</li><li>随机</li><li>最少并发策略</li></ul>注意:Spring Cloud 2020 版本之后,Ribbon 被 Spring Cloud LoadBalancer 替代。
声明式服务调用
Feign
Feign 是基于 Ribbon 的声明式 HTTP 客户端,用于简化微服务之间的调用。<br>特点:<br><ul><li>基于接口调用,类似 SpringMVC</li><li>内置 Ribbon 进行负载均衡</li><li>支持熔断(Hystrix / Sentinel)</li></ul>
服务网关
Spring Cloud Gateway
Spring Cloud Gateway 是 Spring 官方推出的API 网关,用于路由转发和过滤请求。<br>优势:<br><ul><li>动态路由,支持 Predicate 进行请求匹配</li><li>支持 WebFlux,提高吞吐量</li><li>集成 JWT 认证、限流、熔断等功能</li></ul>
熔断与降级
Hystrix
Hystrix 是 Netflix 提供的熔断降级组件,已被 Sentinel 取代。
@HystrixCommand(fallbackMethod = "fallbackMethod")<br>public String getUser() {<br> return restTemplate.getForObject("http://user-service/user", String.class);<br>}<br><br>public String fallbackMethod() {<br> return "服务暂不可用";<br>}<br>
Sentinel(推荐)
Sentinel 是阿里巴巴开源的流量控制和熔断降级组件。
@SentinelResource(value = "getUser", fallback = "fallbackMethod")<br>public String getUser() {<br> return restTemplate.getForObject("http://user-service/user", String.class);<br>}<br>
分布式配置
Spring Cloud Config 允许微服务从集中配置中心获取配置信息。
链路追踪
Spring Cloud Sleuth + Zipkin
Sleuth + Zipkin 结合使用,用于微服务请求链路追踪。<br><ul><li>Sleuth:提供日志跟踪 ID</li><li>Zipkin:可视化链路追踪数据</li></ul>
消息驱动
Spring Cloud Stream
Spring Cloud Stream 提供事件驱动架构,可使用 Kafka/RabbitMQ 作为消息中间件。
@EnableBinding(Source.class)<br>public class MessageProducer {<br> @Autowired<br> private MessageChannel output;<br><br> public void sendMessage(String msg) {<br> output.send(MessageBuilder.withPayload(msg).build());<br> }<br>}<br>
Spring Cloud 版本迭代
Hoxton(2020 前) 采用 Netflix 组件,如 Hystrix、Ribbon、Zuul
2020 及以后 移除 Netflix 组件,推荐 Sentinel、Gateway、Spring Cloud LoadBalancer
Spring Cloud Alibaba(阿里云版)
Spring Cloud Alibaba 适用于大规模微服务架构,提供了:<br><br><ul><li>Nacos(服务注册与配置)</li><li>Sentinel(熔断限流)</li><li>RocketMQ(消息队列)</li><li>Seata(分布式事务)</li></ul>
mybatis
MyBatis 概述
MyBatis 是一个轻量级 ORM(对象关系映射)框架,主要用于 SQL 映射、动态 SQL 处理、数据库操作封装。相较于 Hibernate,MyBatis 允许开发者手写 SQL,并提供了自动映射和简化 JDBC 代码的能力,特别适用于复杂 SQL 需求的项目。
MyBatis 主要特性
<ul><li>SQL 语句可控:手写 SQL,避免 Hibernate 复杂 SQL 生成问题。</li><li>动态 SQL 支持:支持 if、choose、foreach 等标签。</li><li>映射灵活:支持 对象-表字段 映射,可自动或手动配置。</li><li>支持缓存:提供 一级缓存(Session 级别) 和 二级缓存(Mapper 级别)。</li><li>插件扩展:支持自定义插件,如拦截 SQL 语句执行。</li></ul>
MyBatis 体系结构
MyBatis 主要包括以下核心组件:<br><ul><li>SqlSessionFactory:生产 SqlSession 的工厂,维护数据库连接信息</li><li>SqlSession:执行 SQL 语句、获取 Mapper</li><li>Mapper :映射接口提供数据库访问方法,MyBatis 自动实现</li><li>配置文件(mybatis-config.xml):全局配置,如数据库连接、缓存、日志等</li><li>映射文件(XXXMapper.xml):定义 SQL 语句和对象映射关系</li></ul><br>
MyBatis 缓存机制
MyBatis 提供一级缓存和二级缓存。
一级缓存(SqlSession 级别,默认开启):
SqlSession session1 = sqlSessionFactory.openSession();
User user1 = session1.selectOne("getUserById", 1);
User user2 = session1.selectOne("getUserById", 1); // 走缓存
二级缓存(Mapper 级别,需要手动开启):
<cache />
MyBatis 三级缓存的实现
三级缓存实现原理
通常来说,MyBatis 的三级缓存可以理解为:<br><br><ul><li>一级缓存:每个 SqlSession 内部使用的缓存,存储在当前 SqlSession 内,作用于本地 JVM。</li><li>二级缓存:在 SqlSessionFactory 中共享,存储在 Mapper 级别的缓存,作用于同一 SqlSessionFactory 内。</li><li>三级缓存:使用外部缓存系统(如 Redis、Memcached),跨 SqlSessionFactory 和多个服务实例共享缓存。</li></ul>
hibernate
描述
Hibernate 是一个广泛使用的 Java ORM(对象关系映射)框架,用于简化 Java 应用程序中与数据库的交互。Hibernate 能够将 Java 对象与数据库表相映射,实现持久化操作,从而避免了直接编写 SQL 查询代码。它提供了自动化的方式来执行增删改查操作(CRUD),并提供了丰富的功能来处理关系数据库中的复杂数据。
Hibernate 的核心概念
ORM (对象关系映射)
ORM 是一种用于将面向对象编程(OOP)中的类和对象与关系型数据库中的表和记录进行映射的技术。Hibernate 实现了 ORM,通过这种映射,开发者可以用 Java 对象操作数据库中的数据,而无需直接编写 SQL。<br><br><ul><li>对象:Java 类</li><li>关系:数据库表</li><li>属性:Java 类的字段与数据库表的列一一对应</li></ul>
Hibernate 的工作原理
Hibernate 通过映射文件或者注解,管理 Java 类与数据库表之间的关系。通过 Hibernate 的核心接口(如 SessionFactory、Session),它能够执行数据库操作,并将 Java 对象映射到数据库表中的行。
会话(Session)
Session 是 Hibernate 的一个核心概念,它代表了与数据库的一次连接或对数据库的一个会话。通过 Session,我们可以执行增、删、改、查等数据库操作,并且 Hibernate 会管理对象的持久化。
Hibernate 的优势
<ul><li>简化数据库操作:通过 ORM,Hibernate 可以自动管理对象与数据库表之间的映射,大大减少了编写 SQL 的工作量。</li><li>跨数据库支持:Hibernate 可以运行在多种数据库之上,只需要调整配置即可支持不同的数据库。</li><li>缓存支持:Hibernate 支持一级缓存(Session 缓存)和二级缓存(多个 SessionFactory 共享缓存),能够有效提高性能。</li><li>事务管理:Hibernate 提供了对事务的良好支持,简化了事务处理。</li><li>延迟加载:Hibernate 支持懒加载,能够按需加载数据,减少不必要的性能开销。</li></ul>
Hibernate 的缺点
<ul><li>学习曲线较陡:对于初学者,Hibernate 的学习曲线可能较为陡峭,尤其是理解和使用高级特性时。</li><li>性能开销:虽然 Hibernate 提供了缓存等优化机制,但在某些复杂查询场景下,性能可能不如手写 SQL。</li><li>调试难度:由于 Hibernate 对数据库操作进行了封装,调试时可能较难查看实际执行的 SQL 语句。</li></ul>
Hibernate 与 JPA(Java Persistence API)
Hibernate 实现了 JPA 规范,JPA 是 Java EE 中的一个标准,用于定义 Java 应用程序与关系数据库之间的持久化层。Hibernate 作为 JPA 的实现之一,提供了更强大的功能,如更丰富的查询能力、缓存机制等。
Hibernate 不仅支持 JPA,还提供了自己的扩展功能,因此可以同时使用 JPA 和 Hibernate 特性。
缓存
Redis<br>
描述
Redis(Remote Dictionary Server)是一个开源的高性能键值存储数据库,广泛用于缓存、消息队列、会话存储等场景。Redis 支持多种数据结构,如字符串、哈希、列表、集合、有序集合、位图、HyperLogLog 等,并且具备丰富的功能,如持久化、事务、发布/订阅等。<br><br>Redis 是一个基于内存的数据库,它通过持久化机制将数据保存在磁盘中,从而避免数据丢失。由于其极高的性能,Redis 被广泛应用于高并发、高可用的分布式系统中。
Redis 的基本特性
<ul><li>内存存储:Redis 将所有数据存储在内存中,确保了极高的读写速度。</li><li>持久化:Redis 提供了持久化机制,可以将内存中的数据保存到磁盘,以防止服务器重启后数据丢失。</li><li>丰富的数据类型:Redis 提供了丰富的数据结构,如字符串、哈希表、列表、集合、有序集合等。</li><li>高性能:Redis 的单线程模型和高效的数据结构使得它能够在每秒处理数百万次操作。</li><li>分布式:Redis 支持主从复制、分片等分布式特性,能够在多个节点间分布式存储数据,提供高可用性和扩展性。</li><li>支持事务:Redis 提供了简单的事务机制,能够确保操作的原子性。</li><li>发布/订阅:Redis 支持发布/订阅(Pub/Sub)模式,适用于消息队列、事件通知等场景。</li></ul>
Redis 数据类型
字符串(String)
字符串是 Redis 中最基本的数据类型。它可以包含任何类型的二进制数据,如 JPEG 图片或序列化的对象。
Redis 中的字符串是二进制安全的,意味着它可以包含任何形式的值(不仅仅是文本)。
哈希(Hash)
哈希是键值对集合,适合存储对象。例如,可以使用哈希存储一个用户的基本信息(如用户名、年龄、地址)。
使用哈希存储小规模的对象信息比使用字符串更高效。
列表(List)
列表是一个简单的字符串列表,按插入顺序排序。你可以在列表的两端进行推入、弹出操作。非常适合实现消息队列等场景。
列表是一个双端队列,支持从两端进行推入和弹出。
集合(Set)
集合是一个无序的字符串集合。集合中的元素是唯一的,不允许重复。集合非常适合用来存储一些不重复的数据。
集合支持高效的成员添加、删除和查找操作。
有序集合(Sorted Set)
有序集合与集合类似,但每个元素都会关联一个分数(score),Redis 会根据分数对元素进行排序。适合用于排行榜等场景。
有序集合支持按分数排序、范围查询等操作。
位图(Bitmap)
位图是一个比特数组,可以用来表示某些状态信息,如用户是否活跃,某个特定日期是否完成任务等。
位图非常适合用来实现计数、状态标记等功能。
HyperLogLog
HyperLogLog 是一个用于估算基数的概率性数据结构。它可以用来统计唯一元素的数量,例如统计访问量,但误差在可接受范围内。
HyperLogLog 能够以较少的内存估算大型数据集的基数。
Redis 持久化机制
虽然 Redis 是一个内存数据库,但它提供了两种持久化机制来确保数据的持久性:
RDB(快照)
RDB 持久化会在指定的时间间隔内生成数据的快照并保存到磁盘。它适用于对性能要求较高,但容忍短时间内数据丢失的场景。<br><br><ul><li>可以通过配置 SAVE 或 BGSAVE 指令来生成 RDB 快照。</li><li>快照文件通常保存在 dump.rdb 文件中。</li></ul>
AOF(追加文件)
AOF 持久化会将每个写命令追加到文件末尾,以记录每一次的变更。通过重放 AOF 文件,可以恢复数据库状态。<br><br><ul><li>AOF 适用于需要较高数据可靠性的场景,但会对性能产生一些影响。</li><li>AOF 文件通常保存在 appendonly.aof 中。</li></ul>
Redis 可以同时启用 RDB 和 AOF,提供两者的优势(性能和数据持久性)。
Redis 高可用性与分布式
主从复制
Redis 支持主从复制架构,一个主节点可以有多个从节点,所有从节点会自动复制主节点的数据。这为 Redis 提供了高可用性和数据备份功能。<br><br><ul><li>主从复制使得 Redis 可以读取分流、负载均衡。</li><li>从节点可以在主节点故障时提供数据。</li></ul>
Sentinel(哨兵)
Redis Sentinel 是 Redis 的高可用解决方案,它提供了故障自动检测、自动故障转移和通知机制。当主节点宕机时,Sentinel 会自动将某个从节点升级为新的主节点。
Redis 分片(Sharding)
Redis 支持数据分片,即将数据分布到多个 Redis 节点上。这可以通过 Redis 集群(Cluster)实现,提供横向扩展的能力。<br><br><ul><li>Redis 集群支持自动分片,将键分布到不同的节点上,保证数据的负载均衡。</li></ul>
Redis 性能优化
Redis 由于其基于内存的特性,性能非常高。但为了进一步提高 Redis 的性能,可以采取一些优化措施:
合理使用数据结构
选择适合业务场景的数据结构,以提高操作效率。例如:<br><br><ul><li>用列表实现队列。</li><li>用集合实现唯一性要求的数据集合。</li><li>用有序集合实现排行榜等。</li></ul>
持久化优化
<ul><li>使用 RDB 时,可以调整快照的保存频率,以平衡性能和数据可靠性。</li><li>使用 AOF 时,可以调整 AOF 重写的策略(如每次修改后追加、定期重写)。</li></ul>
内存管理
<ul><li>设置合理的内存使用策略,使用 maxmemory 指令限制 Redis 占用的最大内存。</li><li>配置内存淘汰策略,如 volatile-lru(仅对设置了过期时间的键进行 LRU 淘汰)等。</li></ul>
Redis 在实际应用中的常见场景
6.1 缓存系统<br>Redis 常作为缓存层,用于加速数据访问,减少数据库负载。常见的做法是将查询频繁的数据缓存到 Redis 中。<br><br>6.2 会话存储<br>Redis 是存储会话信息的理想选择,尤其是在分布式应用中,它提供了高性能的读写能力。<br><br>6.3 消息队列<br>Redis 支持发布/订阅模型,可以用于构建轻量级的消息队列系统。<br><br>6.4 排行榜/计数器<br>Redis 的有序集合非常适合构建排行榜,也可以用于实现统计计数器等功能。<br><br>6.5 分布式锁<br>Redis 的 SETNX 命令可以实现分布式锁,用于分布式系统中的资源控制。
总结
Redis 是一个高性能的键值存储数据库,具备丰富的数据结构和强大的持久化能力,广泛应用于缓存、消息队列、会话存储等多个场景。其内存数据库特性和分布式能力,使得 Redis 在高并发、海量数据的处理场景中具有极大的优势。通过合理配置 Redis,能够有效提高系统性能和可扩展性。
面试题
基础面试题
Redis 为什么快?
<ul><li>基于内存操作,避免磁盘 IO 。</li><li>单线程架构,避免多线程切换开销。</li><li>采用 I/O 多路复用,支持高并发。</li><li>高效的数据结构(跳表、字典、整数数组等)。</li></ul>
Redis 是单线程的吗?
<ul><li>数据操作是单线程的(避免锁竞争)。</li><li>持久化(RDB/AOF)、集群复制、异步删除 是多线程的。</li></ul>
Redis 如何实现持久化?
<ul><li>RDB(快照):定期将数据写入二进制文件,适用于冷备份。</li><li>AOF(日志):记录每个写操作,适用于高可靠性数据存储。</li></ul>
Redis 支持事务吗?
支持但不具备回滚:<br><ul><li>MULTI:开启事务。</li><li>EXEC:提交事务。</li><li>DISCARD:取消事务。</li></ul>
高级面试题
Redis 如何实现分布式锁?
<ul><li>SETNX + EXPIRE</li><li>RedLock(官方推荐,支持多节点)</li></ul>
Redis 如何做缓存雪崩、缓存击穿、缓存穿透?
缓存雪崩(大量 Key 失效):<br><ul><li>设置 不同的过期时间,避免同时失效。</li><li>使用 主从架构+持久化,防止宕机。</li></ul>缓存击穿(高并发访问某个 Key 失效):<br><ul><li>使用 互斥锁(SETNX)。</li></ul>缓存穿透(访问不存在 Key):<br><ul><li>存空值,防止穿透。</li><li>使用 BloomFilter 过滤非法请求。</li></ul>
Redis 过期策略?
<ol><li>定期删除(随机抽样,减少内存占用)。</li><li>惰性删除(访问 Key 时检查是否过期)。</li><li>内存淘汰策略:</li></ol><ul><li>volatile-lru(LRU 淘汰最近最少使用的 Key)。</li><li>allkeys-lru(所有 Key 都可淘汰)。</li><li>volatile-ttl(优先删除快过期的 Key)。</li><li>noeviction(拒绝写入新数据)。</li></ul>
分布式 & 高可用
Redis 如何实现主从复制?
<ul><li>SLAVEOF <Master_IP> <PORT>:手动设置从库。</li><li>Redis 2.8+ 采用 PSYNC(部分同步)。</li><li>Redis 5.0+ 引入 主从自动切换(Redis Sentinel)。</li></ul>
Redis Sentinel(哨兵模式)工作原理?
<ul><li>监控(监视 Master 是否存活)。</li><li>自动选举(Master 宕机后选举新 Master)。</li><li>通知客户端(更新 Master 地址)。</li><li>心跳检测(info 和 PING)。</li></ul>
Redis Cluster(集群模式)原理?
<ul><li>无中心架构,每个节点存储数据的一部分。</li><li>槽位分配(0-16383),采用 HashSlot 机制。</li><li>Gossip 协议,用于节点间通信。</li><li>主从模式(自动故障转移)。</li></ul>
高级优化
如何提高 Redis 并发量?
<ul><li>使用 pipeline 进行批量操作,减少 RTT。</li><li>减少大 Key,避免阻塞操作。</li><li>使用 Lua 脚本(EVAL),减少网络开销。</li></ul>
Redis 如何防止内存爆炸?
<ul><li>设置最大内存(maxmemory)。</li><li>使用淘汰策略(LRU/LFU)。</li><li>定期删除不常用的 Key。</li></ul>
Redis 面试技巧
<ul><li>理解 Redis 核心概念,如缓存机制、持久化、集群等。</li><li>结合项目经验,讲述Redis 在实际场景中的应用(如分布式锁、热点数据缓存)。</li><li>对比 Redis 和其他存储方案(如 MySQL、MongoDB),表现出架构思维。</li></ul>
Memcached
描述
Memcached 是一个高性能的分布式内存对象缓存系统,主要用于加速动态 web 应用程序,减少数据库负载。它通过将数据存储在内存中,从而大大提高数据读取速度。Memcached 主要是为了减少数据库访问的延迟,提高 Web 应用的响应速度。它是一个键值对存储系统,能够缓存任何类型的数据(如字符串、对象、数组等),非常适合于需要快速访问的场景。<br><br>Memcached 是一个开源项目,通常作为缓存层部署,通常与关系型数据库(如 MySQL)或 NoSQL 数据库(如 Redis)结合使用。
Memcached 的基本特性
<ul><li>内存存储:Memcached 将数据完全存储在内存中,这使得它非常快速,能够为大量并发请求提供快速的数据访问。</li><li>分布式:Memcached 支持水平扩展,可以通过增加节点来扩展缓存容量和处理能力,适应大规模的数据缓存需求。</li><li>简单的键值存储:Memcached 基于简单的键值对存储,不像 Redis 提供复杂的数据结构(如列表、哈希等),而是专注于高效的键值数据存储和访问。</li><li>多客户端支持:Memcached 支持多种编程语言的客户端,如 Java、Python、PHP、Ruby 等,方便开发者在不同的应用程序中使用。</li><li>过期时间:Memcached 支持为每个缓存项设置过期时间,缓存项可以在超过指定时间后自动删除。</li><li>高并发性能:Memcached 被设计为处理大量并发请求的高性能缓存系统。它通过将数据存储在内存中,避免了磁盘 I/O 的瓶颈。</li></ul>
Memcached 的工作原理
键值对存储
Memcached 将数据存储在内存中,按照键值对的形式进行管理。应用程序将数据存入 Memcached 时,指定一个唯一的键(key)和相应的值(value)。随后,应用程序通过该键来检索数据。
set <key> <flags> <expiration> <bytes> <data><br>
<ul><li>键(key):唯一标识缓存数据的字符串,客户端通过这个键来检索缓存。</li><li>值(value):缓存的数据内容,可以是字符串、序列化后的对象或其他数据类型。</li><li>标志(flags):用于存储附加信息,通常用于应用层的标识,如缓存数据的类型。</li><li>过期时间(expiration):缓存数据的过期时间,单位为秒。</li><li>字节数(bytes):缓存值的大小。</li></ul>
数据存储与获取
Memcached 是一个基于内存的缓存系统,因此它会将数据直接存储在内存中,避免了磁盘 I/O 操作,从而提高了性能。当应用程序需要访问缓存数据时,它首先会向 Memcached 查询键是否存在,如果存在则直接返回对应的值;如果不存在,则可能需要从数据库中加载数据并将其存入 Memcached。
分布式架构
Memcached 是一个分布式系统,支持多个 Memcached 节点共同工作。当数据量超过单台服务器的内存容量时,可以将数据分布到多个 Memcached 服务器上。Memcached 会根据客户端的请求自动将数据分配到适当的节点。<br><br><ul><li>一致性哈希:Memcached 使用一致性哈希来确定数据存储在哪个节点上。客户端根据键值的哈希值来计算其存储的位置,从而实现数据分布。</li><li>节点扩展:通过添加新的 Memcached 节点,系统的缓存容量和处理能力可以水平扩展。</li></ul>
Memcached 的常用命令
Memcached 提供了一些简单的命令来存储、获取和管理缓存数据:
存储数据
SET:存储一个键值对,如果键已存在,则覆盖现有值。
ADD:如果键不存在,则存储该键值对。如果键已存在,则不做任何操作。
REPLACE:如果键已存在,则替换其值。如果键不存在,则不做任何操作。
APPEND:将新的数据附加到已存在键的值后面。如果键不存在,则不做任何操作。
PREPEND:将新的数据插入到已存在键的值前面。
获取数据
GET:获取一个键的值。
GETS:与 GET 类似,但是 GETS 返回的结果还包含了标志信息。
删除数据
DEL:删除一个键。
缓存统计与管理
STAT:获取 Memcached 服务器的统计信息。
FLUSHALL:清空所有缓存。
FLUSH:清空当前实例中的缓存。
Memcached 的优缺点
优点
<ul><li>高性能:Memcached 在内存中直接存储数据,避免了磁盘 I/O 操作,因此能够提供非常高的读写性能。</li><li>简单易用:Memcached 的使用非常简单,通过客户端提供的 API 就可以进行基本的存储、获取、删除操作。</li><li>分布式:Memcached 原生支持分布式架构,能够根据需要水平扩展缓存容量。</li><li>开源和广泛支持:Memcached 是一个开源项目,支持多种编程语言,社区活跃,文档丰富。</li></ul>
缺点
<ul><li>只支持键值对存储:Memcached 只支持简单的键值对存储,缺乏更复杂的数据结构,如 Redis 提供的列表、集合等。</li><li>不支持持久化:Memcached 默认不支持持久化,即一旦服务重启,缓存的数据将丢失。虽然可以通过一些方法来模拟持久化,但这并不是 Memcached 的设计重点。</li><li>内存受限:由于 Memcached 是内存存储,缓存数据量受到物理内存大小的限制。在大规模缓存需求下,可能需要更高效的内存管理机制。</li></ul>
Memcached 的使用场景
Memcached 作为一个高性能缓存系统,广泛应用于以下几种场景:
5.1 缓存加速
Memcached 通常作为数据库的缓存层,减少数据库的负载,加速数据读取。例如,存储热门页面的查询结果、动态生成的数据等。
5.2 会话存储
Memcached 可以用于存储用户会话数据,避免每次请求都从数据库中读取会话信息。
5.3 高并发的 Web 应用
在高并发的 Web 应用中,Memcached 可以帮助缓存常见请求的数据,减少数据库的查询次数,提升响应速度。
5.4 分布式缓存
Memcached 支持分布式架构,能够在多个节点之间分配缓存数据,适合大规模 Web 应用的缓存需求。
总结
Memcached 是一个高性能、简单的分布式内存对象缓存系统,适用于需要快速读取数据的场景。通过将数据存储在内存中,Memcached 能够显著减少数据库访问的延迟,提升 Web 应用的响应速度。尽管它功能较为简单,只支持键值对存储,并且不提供持久化机制,但它在大规模缓存需求和高并发系统中的表现十分出色。
搜索引擎
Lucene
描述
Apache Lucene 是一个高性能、开源的全文搜索库,它提供了全文检索和索引功能,广泛应用于构建搜索引擎和信息检索系统。Lucene 被设计为一个高效的文本搜索库,可以处理大量文本数据的索引和搜索,并且其设计可以嵌入到各种 Java 应用中。Lucene 本身并不提供 Web 界面或 Web 应用集成功能,但它是许多搜索引擎框架(如 Solr 和 Elasticsearch)的核心库。<br><br>Lucene 的核心特性包括高效的文本索引、分词、查询解析和排序等功能。本文将详细介绍 Lucene 的架构、核心概念、实现原理以及如何使用 Lucene 来构建高效的搜索引擎。
Lucene 的核心概念
<span style="font-size: inherit;">在深入了解 Lucene 的工作原理之前,首先了解一些 Lucene 的核心概念是很重要的:</span><br><ul><li><span style="font-size: inherit;">文档(Document):Lucene 索引的基本单位,每个文档是由多个字段组成的。例如,一个包含标题和内容的文本条目。</span></li><li><span style="font-size: inherit;">字段(Field):文档包含的单个数据项,通常表示文档的属性(例如:标题、正文等)。字段有名称和内容,Lucene 中的字段类型通常有 TextField 和 KeywordField,前者表示可分词的字段,后者表示不可分词的字段。</span></li><li><span style="font-size: inherit;">分析器(Analyzer):用于处理文档文本的组件,分析器负责将文档的文本分解成词项(token),并且可以进行停用词过滤、词干提取等操作。</span></li><li><span style="font-size: inherit;">索引(Index):Lucene 通过索引机制存储和查找数据。每个文档都会通过分析器生成一系列的词项,并将这些词项存储到倒排索引(Inverted Index)中,供查询时使用。</span></li><li><span style="font-size: inherit;">查询(Query):Lucene 查询是对索引中的词项进行搜索的请求。Lucene 提供了多种查询类型,如常规查询、范围查询、布尔查询等。</span></li><li><span style="font-size: inherit;">倒排索引(Inverted Index):倒排索引是 Lucene 的核心数据结构,它将每个词项(单词)映射到包含该词项的文档 ID。这种结构使得搜索变得非常高效。</span></li><li><span style="font-size: inherit;">评分(Score):Lucene 使用一个评分机制来评估文档与查询的相关性。Lucene 采用一种基于词频-逆文档频率(TF-IDF)模型和 BM25 算法来进行评分。</span></li></ul>
Lucene 的工作原理
Lucene 的索引与查询过程
<ul><li>索引过程:当文档被添加到 Lucene 中时,文档会通过指定的分析器进行分词。分词后,Lucene 将每个词项存储到倒排索引中,并将词项与文档 ID 相关联。</li><li><br></li><li>查询过程:当用户提交查询请求时,Lucene 会将查询字符串解析为词项,并通过倒排索引查找相关的文档。查询结果返回的是匹配的文档 ID 和相应的评分(基于 BM25 或其他算法)。</li></ul>
索引过程
<ol><li>文档创建:首先,创建一个 Document 对象,表示一个完整的搜索条目。每个文档包含多个 Field,每个字段保存了文档的一个属性或内容。</li><li>文本分析:使用 Analyzer 来将字段的文本进行分析,分词并去除停用词。例如,使用标准分析器(StandardAnalyzer)来处理文本。</li><li>建立倒排索引:Lucene 使用倒排索引来存储词项与文档之间的关系。倒排索引将每个词项(例如 "Lucene")映射到所有包含该词项的文档 ID。</li><li>写入索引:将所有文档及其字段信息通过 IndexWriter 写入索引存储(可以是内存中的 RAMDirectory 或磁盘中的 FSDirectory)。</li></ol>
查询过程
<ol><li>查询解析:Lucene 通过 QueryParser 将用户的查询字符串转换为 Lucene 查询对象。例如,用户可能输入 "search engine" 这样的查询词,Lucene 会将其转换为查询对象。</li><li>匹配查询:Lucene 通过倒排索引查找包含查询词的文档。它会遍历倒排索引,找到匹配的文档并计算每个文档的相关性得分。</li><li>排序与评分:Lucene 使用 BM25 或类似的算法对每个匹配文档进行评分,并根据得分对结果进行排序。高分的文档会被认为与查询更相关。</li><li>返回查询结果:查询结果返回时,通常是按照得分排序的文档 ID 列表。开发者可以选择返回更多信息,如字段内容等。</li></ol>
Lucene 的核心组件
Lucene 提供了许多核心组件,用于实现全文索引和检索功能。
Analyzer(分析器)
Analyzer 用于将文本字段分解为词项,并将其存储到倒排索引中。Lucene 提供了许多内置的分析器(如 StandardAnalyzer、WhitespaceAnalyzer、KeywordAnalyzer 等),也支持自定义分析器。<br><br><ul><li>Tokenizer:负责将文本分割成词项(token)。</li><li>Filter:处理分词后的词项,如去除停用词、转换小写、词干提取等。</li></ul>
IndexWriter(索引写入器)
IndexWriter 是用于写入文档到索引的主要组件。它将分析后的文本存储到索引文件中。IndexWriter 支持文档的增加、更新和删除。
IndexSearcher(索引查询器)
IndexSearcher 是用于从索引中查询文档的主要组件。它提供了高效的查询接口,可以基于各种查询类型(如布尔查询、范围查询等)来查找匹配的文档。
Query(查询)
Lucene 提供了多种查询类型,如:<br><br><ul><li>TermQuery:匹配一个特定的词项。</li><li>PhraseQuery:匹配一系列词项的短语。</li><li>BooleanQuery:支持布尔逻辑运算(AND、OR、NOT)。</li><li>RangeQuery:根据范围条件匹配文档。</li><li>WildcardQuery:支持通配符查询。</li></ul>
ScoreDoc 和 TopDocs
ScoreDoc 表示查询结果中的单个文档,并包含文档 ID 和评分。TopDocs 用于存储查询的前 N 个最相关文档。
Lucene 的索引和查询优化
为了确保高效的索引和查询性能,Lucene 提供了一些优化技术:
索引优化
<ul><li>Merge:当有大量文档被添加到索引中时,Lucene 会合并多个小索引文件,以减小磁盘的读取开销。</li><li>字段存储方式:通过选择适当的字段存储策略(如 Field.Store.YES 或 Field.Store.NO),可以控制是否将字段内容存储在索引中,从而优化存储和查询性能。</li></ul>
查询优化
<ul><li>Query Caching:Lucene 可以缓存查询结果,提高重复查询的性能。</li><li>索引分片:在数据量非常大的情况下,Lucene 支持将索引分成多个分片(或分段),并通过合并优化性能。</li><li>BM25 算法:Lucene 使用 BM25 算法来对查询结果进行评分,这使得文档与查询之间的相关性更加精确。</li></ul>
Lucene 的使用场景
<ul><li><span style="font-size: inherit;">全文搜索引擎:Lucene 是许多自定义搜索引擎的核心组件,能够支持高效的全文检索。</span></li><li><span style="font-size: inherit;">日志分析:Lucene 可以快速索引和查询大量的日志数据,适用于日志管理系统。</span></li><li><span style="font-size: inherit;">电子商务:在电商平台中,Lucene 可以用来实现产品搜索、排序和过滤等功能。</span></li><li><span style="font-size: inherit;">数据挖掘和内容推荐:Lucene 可以用于构建推荐系统,通过搜索和相关性评分来推荐相关内容。</span></li></ul>
Solr
描述
Apache Solr 是一个开源的企业级搜索平台,它是建立在 Apache Lucene 上的,提供了丰富的搜索功能、可扩展性和高可用性。Solr 是一个非常强大的搜索引擎,可以用来实现全文检索、数据索引、实时搜索、分布式搜索等功能,广泛应用于电子商务、内容管理系统、日志分析等多个领域。<br><br>Solr 提供了很多 Lucene 没有的特性,主要是为了简化搜索引擎的配置、管理和集群的扩展。它支持 RESTful API、分布式搜索、自动分词、支持多种查询语言、分析器、拼写纠错、排序、聚合等。
Solr 的架构
<ul><li><span style="font-size: inherit;">Solr 的架构基于 Lucene,具有以下几个关键组件:</span></li><li><span style="font-size: inherit;">Solr Server:Solr Server 是 Solr 的核心组件,提供了 HTTP 接口和管理界面,负责接受客户端的请求并返回结果。Solr Server 是通过容器(如 Jetty 或 Tomcat)运行的 Web 应用。</span></li><li><span style="font-size: inherit;">Core:Solr 中的核心是一个包含所有配置、数据和索引的单位。每个核心都可以有自己的独立配置和索引结构。Solr 可以支持多个核心,类似于多个数据库实例。每个核心可以看作是一个独立的索引实例。</span></li><li><span style="font-size: inherit;">Schema:每个 Solr 核心都需要一个 Schema 文件,它定义了文档的字段(如 text, id, timestamp 等)以及这些字段的类型、分析器和存储方式等。Solr 提供了 schema.xml 和 solrconfig.xml 文件来配置索引和查询。</span></li><li><span style="font-size: inherit;">Solr Admin UI:Solr 提供了一个非常直观的 Web 管理界面,通过这个界面可以管理索引、查询、查看统计信息、监控集群等。</span></li><li><span style="font-size: inherit;">Indexing and Searching:Solr 提供了高效的索引和搜索能力,它利用 Lucene 实现倒排索引,并支持各种查询方式(如布尔查询、范围查询、短语查询等)。</span></li></ul>
Solr 的核心功能
分布式搜索和索引
Solr 提供了强大的分布式搜索和索引功能,它通过 SolrCloud 来管理分布式系统的集群。SolrCloud 是基于 Apache ZooKeeper 的,提供了以下几个特性:<br><br><ul><li>分片:SolrCloud 支持将索引数据分片,每个分片存储在不同的服务器上,从而实现数据的水平扩展。</li><li>复制:SolrCloud 还支持副本机制,多个副本可以保证系统的高可用性和容错性。</li><li>自动负载均衡:SolrCloud 可以自动平衡负载和副本,确保各节点的负载均衡。</li></ul>
高级查询支持
Solr 提供了丰富的查询语言和查询功能,支持:<br><br><ul><li>标准查询:支持布尔查询、范围查询、短语查询等。</li><li>全文搜索:可以对文本字段进行全文搜索,支持模糊搜索、拼写纠错等。</li><li>聚合:Solr 支持通过聚合查询对数据进行汇总统计(如计算最大值、最小值、平均值、计数等)。</li><li>排序与评分:支持基于字段、相关性和自定义排序规则进行排序。</li><li>过滤器查询:Solr 提供了过滤查询功能,可以提高查询性能,避免多次扫描索引。</li></ul>
数据导入和导出
Solr 提供了多种数据导入和导出方式,可以从不同数据源(如数据库、XML 文件、CSV 文件等)导入数据。常见的数据导入方式有:<br><br><ul><li>DataImportHandler (DIH):通过 DIH 可以从数据库(如 MySQL、PostgreSQL 等)导入数据到 Solr。</li><li>CSV、JSON 和 XML:Solr 支持通过 CSV、JSON 或 XML 格式上传数据。</li></ul>
自动分词和索引优化
Solr 继承了 Lucene 的分词能力,并且可以配置不同的分词器来处理文本字段。常见的分词器有:<br><br><ul><li>StandardTokenizer:标准分词器,基于空格和标点符号分割文本。</li><li>EdgeNGramTokenizer:根据词首生成 n-gram,用于前缀匹配。</li><li>KeywordTokenizer:将整个字段作为一个词项,适用于存储 URL、ID 等。</li></ul>
结果高亮
Solr 提供了高亮功能,可以高亮查询结果中匹配的词项,便于用户快速定位搜索结果。例如,当用户搜索“Solr”时,查询结果中的“Solr”词项可以高亮显示。
Solr 的核心组件
Schema 和 FieldType
<ul><li>Schema:Solr 的 schema 定义了文档中字段的类型、索引和存储方式。每个字段可以配置不同的类型,如文本类型、数字类型、日期类型等。</li><li><br></li><li>FieldType:Solr 中的 FieldType 定义了如何解析和存储字段数据。例如,TextField 用于存储可分词的文本,StringField 用于存储不可分词的字符串,DateField 用于存储日期。</li></ul>
SolrConfig
solrconfig.xml 是 Solr 的配置文件,定义了 Solr 核心的行为。通过该文件,开发者可以配置缓存策略、查询请求的处理方式、索引处理等。
查询和过滤器
Solr 支持通过查询字符串(query string)来查询索引,常见的查询类型包括:<br><br><ul><li>普通查询:直接查找某个字段的词项。</li><li>布尔查询:通过 AND、OR、NOT 进行复合查询。</li><li>范围查询:查找某个字段在特定范围内的文档。</li><li>拼写纠错:Solr 支持拼写纠错和相似词搜索功能。</li></ul>
聚合查询
Solr 支持聚合查询,可以对查询结果进行统计和分组。例如,可以使用 Solr 聚合查询来统计商品的平均价格、按类别统计商品数量等。
如何使用 Solr
启动 Solr 服务
Solr 可以通过启动命令行来启动服务:
bin/solr start
Solr 服务会在默认端口 8983 上启动,访问 Solr 管理界面:
http://localhost:8983/solr
创建核心(Core)
Solr 中的数据存储和搜索是基于核心的,每个核心可以对应一个独立的索引。可以使用以下命令创建核心:
bin/solr create -c mycore
其中 -c 参数指定了核心的名称。
添加数据
Solr 提供了 RESTful API 来添加数据。通过 HTTP 请求可以将数据添加到 Solr 中:
查询数据
Solr 提供了强大的查询功能,可以通过 URL 发起查询请求:
配置 Schema 和 SolrConfig
Solr 使用 schema.xml 和 solrconfig.xml 配置文件来管理索引字段、分析器和请求处理等。通过修改这些配置文件,用户可以定制 Solr 的行为和性能。
Solr 的应用场景
Solr 广泛应用于以下场景:<br><br><ul><li>全文搜索引擎:Solr 是构建全文搜索引擎的理想选择,适用于博客、新闻、产品目录等各种需要快速搜索的场景。</li><li>电子商务:Solr 可用于商品搜索、排序、过滤等。</li><li>日志分析:通过实时索引和查询,Solr 可用于日志数据的分析与检索。</li><li>数据挖掘与推荐:Solr 可以对数据进行聚合和分析,用于推荐系统。</li></ul>
Elasticsearch
描述
Elasticsearch 是一个开源的、基于分布式的搜索引擎,它基于 Apache Lucene 构建,提供了强大的全文搜索、分布式处理能力,并且非常适合用于大规模的日志分析、数据分析以及信息检索等场景。Elasticsearch 是一个高效、可扩展的搜索和分析引擎,广泛用于日志管理、实时数据分析、全文搜索等多个领域。<br><br>Elasticsearch 采用 RESTful API,支持多种编程语言的客户端,可以通过 HTTP 请求进行查询、数据插入、索引管理等操作。它也通常是 ELK Stack(Elasticsearch, Logstash, Kibana)的核心组件,用于实现日志收集、存储和分析。
Elasticsearch 核心概念
节点(Node)
Elasticsearch 是一个分布式系统,节点是构成 Elasticsearch 集群的基本单位。每个节点可以处理搜索请求、存储数据并参与集群的操作。常见的节点类型包括:<br><br><ul><li>主节点(Master Node):负责集群的管理工作,例如创建和删除索引、管理节点等。</li><li>数据节点(Data Node):存储数据并处理与数据相关的操作,如索引、搜索和聚合查询。</li><li>协调节点(Coordinating Node):处理客户端请求,并将请求转发给其他节点进行处理。任何节点都可以充当协调节点。</li></ul>
集群(Cluster)
一个 Elasticsearch 集群是由一个或多个节点组成的,它们共同工作来存储数据和处理查询。集群中的每个节点都有一个唯一的名称,而集群也有一个名字,用来标识该集群。集群的所有数据和状态都存储在集群的节点之间。
索引(Index)
Elasticsearch 中的索引类似于数据库中的表,它是存储文档的地方。每个索引包含多个文档,并且索引会分为多个分片(shards)。索引有一个名称,用于在集群中唯一标识。
文档(Document)
文档是 Elasticsearch 中的基本数据单位,类似于关系型数据库中的一行。每个文档都属于某个索引,并且是由一组字段组成的 JSON 对象。每个文档都有一个唯一的 ID,用于区分不同的文档。
分片(Shard)
分片是索引的数据分布单元,Elasticsearch 会将索引的数据分散存储在多个分片中。每个分片本身是一个完整的 Lucene 索引,可以独立存储和查询。分片可以提高存储容量,并允许并行处理查询。每个索引可以由多个分片组成。
副本(Replica)
副本是分片的副本副本,目的是提高数据的可靠性和搜索性能。副本分片与主分片内容相同,但存储在不同的节点上。副本分片可以用于负载均衡,在集群中分布式查询时提高搜索性能。
文档类型(Document Type)
在早期版本的 Elasticsearch 中,文档类型用于表示索引中的不同数据结构。自 Elasticsearch 7.x 起,已经移除了类型的概念,每个索引只能包含一种类型的文档。
Elasticsearch 的工作原理
数据存储与索引
Elasticsearch 的存储和索引机制基于 Lucene,它通过倒排索引实现高效的查询。具体过程如下:<br><br><ul><li>文档存储:当用户将文档插入到索引时,Elasticsearch 会将文档进行解析,使用指定的分析器(Analyzer)将文本内容分解为词项(tokens)。</li><li>倒排索引:这些词项被存储在倒排索引中,倒排索引将每个词项映射到包含该词项的文档 ID,从而实现高效的检索。</li><li>分片与副本:Elasticsearch 会将索引数据分成多个分片,并为每个分片创建副本,这样既可以提高查询的并发性能,也可以确保数据的高可用性。</li></ul>
查询与检索
Elasticsearch 通过 RESTful API 提供查询接口,查询时用户会发送 HTTP 请求,Elasticsearch 会将查询请求解析为内部的查询表达式,并在倒排索引中查找匹配的文档。查询结果会按相关性排序,相关性由 Elasticsearch 的评分机制(默认使用 TF-IDF 和 BM25 算法)计算得出。
分布式处理
Elasticsearch 是一个分布式系统,所有节点都参与处理查询、存储数据和维护集群状态。查询会被路由到合适的分片,分片会将查询请求发送到实际存储数据的节点上。为了保证高可用性和容错性,Elasticsearch 会维护多个副本,并根据负载平衡进行查询和数据分布。
集群管理与协调
Elasticsearch 集群通过协调节点来管理查询请求。当一个查询请求到达集群时,协调节点会负责将请求分发到适当的节点(分片)。集群的状态(如节点的加入与离开)由主节点管理。主节点定期检查集群状态,并负责新节点的加入和故障节点的移除。
Elasticsearch 的核心功能
强大的查询能力
Elasticsearch 提供了多种查询类型,包括:<br><br><ul><li>全文检索:基于倒排索引,支持模糊查询、短语查询等。</li><li>结构化查询:可以对字段进行精确查询、范围查询等。</li><li>布尔查询:支持 AND、OR、NOT 等布尔逻辑查询。</li><li>聚合查询:用于进行数据分析和统计,如按时间范围统计事件数。</li><li>排序与分页:支持对查询结果进行排序,并可以返回分页数据。</li></ul>
数据导入和管理
Elasticsearch 提供了多种数据导入方式:<br><br><ul><li>批量导入:通过 bulk API 可以一次性批量插入数据。</li><li>Logstash:通过 Logstash 可以从不同数据源(如数据库、日志文件等)导入数据到 Elasticsearch。</li><li>Kibana:Kibana 是 Elasticsearch 的可视化界面,提供了简单的导入和查看数据功能。</li></ul>
实时搜索
Elasticsearch 支持实时搜索,能够非常快速地处理最新插入的数据。每当数据插入时,Elasticsearch 会将其快速地添加到索引,并立即使其可搜索。
聚合与分析
Elasticsearch 的聚合功能非常强大,支持分组、统计、排序等操作。常见的聚合类型包括:<br><br><ul><li>术语聚合(Terms Aggregation):按字段的值进行分组。</li><li>日期直方图聚合(Date Histogram Aggregation):根据日期字段进行时间分桶。</li><li>范围聚合(Range Aggregation):按指定的范围对数据进行聚合。</li><li>统计聚合(Stats Aggregation):计算数据的最小值、最大值、平均值、总和等。</li></ul>
高可用与容错
Elasticsearch 通过分片和副本机制确保数据的高可用性和容错性。即使某些节点发生故障,副本分片依然能够提供服务,避免系统宕机。
使用 Elasticsearch
启动 Elasticsearch
Elasticsearch 运行在 JVM 上,可以通过以下命令启动:
bin/elasticsearch
Elasticsearch 默认监听在 localhost:9200 端口。
索引和数据管理
创建索引:
PUT /my-index
添加文档:
POST /my-index/_doc/1
{
"title": "Elasticsearch Tutorial",
"content": "Elasticsearch is a powerful search engine"
}
查询数据:
GET /my-index/_search?q=Elasticsearch
集群和节点管理
可以通过 /_cat/ API 查看集群状态、节点信息等:
查看集群健康状态:
GET /_cat/health
查看节点信息:
GET /_cat/nodes
聚合查询
Elasticsearch 支持丰富的聚合查询:
POST /my-index/_search
{
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
Elasticsearch 高级功能
聚合与分析
Elasticsearch 提供强大的聚合功能,可以用于分析大规模数据集。聚合允许对数据进行分组、计算统计信息、计算数据的分布等。常见的聚合类型包括:
术语聚合(Terms Aggregation):按字段的不同值进行分组。适用于对类别、标签、状态等进行分析。
示例:按标签对文章进行统计。
{
"aggs": {
"tags": {
"terms": {
"field": "tags"
}
}
}
}
日期直方图聚合(Date Histogram Aggregation):按时间对数据进行分组,适用于时间序列数据分析。
示例:按月统计销售额。
{
"aggs": {
"monthly_sales": {
"date_histogram": {
"field": "sale_date",
"interval": "month"
}
}
}
}
范围聚合(Range Aggregation):按指定的数值范围对数据进行分组,适用于定量分析。
统计价格在不同范围内的商品数量。
{
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 50 },
{ "from": 50, "to": 100 },
{ "from": 100 }
]
}
}
}
}
统计聚合(Stats Aggregation):对字段进行统计,计算最小值、最大值、平均值、总和等。
统计商品价格的最小值、最大值、平均值。
{
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
跨字段和多字段查询
Elasticsearch 支持对多个字段进行搜索和聚合,可以通过布尔查询(bool query)实现对多个条件的组合查询。此外,Elasticsearch 也支持在多个字段上执行全文搜索或精确搜索。
多字段查询(Multi-Match Query):
用于同时对多个字段进行匹配查询。它适合处理需要对多个字段进行搜索的情况,如标题和正文。
搜索标题和内容中包含 "Elasticsearch" 的文章。
{
"query": {
"multi_match": {
"query": "Elasticsearch",
"fields": ["title", "content"]
}
}
}
布尔查询(Boolean Query):
可以组合多个查询条件,支持 must、should、must_not 等关键字来实现复杂的查询。
查询包含 "Elasticsearch" 且作者为 "John Doe" 的文章。
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Elasticsearch" } },
{ "match": { "author": "John Doe" } }
]
}
}
}
模糊查询与拼写纠错
Elasticsearch 支持模糊查询,可以进行类似于拼写纠错的操作。通过 fuzzy 查询,Elasticsearch 可以容忍一定的拼写错误或字符差异。
模糊查询(Fuzzy Query):在搜索时允许一定的错误匹配。
查找与 "Elasicsearch" 相似的文章标题。
{
"query": {
"fuzzy": {
"title": {
"value": "Elasicsearch",
"fuzziness": "AUTO"
}
}
}
}
拼写建议(Suggest Query):通过 suggest API 提供拼写纠错建议。
给出 "Elesticsearch" 拼写错误的纠正建议。
{
"suggest": {
"text": "Elesticsearch",
"simple_phrase": {
"phrase": {
"field": "title",
"size": 1,
"gram_size": 2,
"direct_generator": [
{
"field": "title",
"suggest_mode": "always"
}
]
}
}
}
}
文档相关性评分
Elasticsearch 基于 BM25 算法进行文档相关性评分。BM25 是一种基于词频(TF)和文档频率(DF)的算法,可以根据查询中的关键词与文档内容的匹配度来评分,返回最相关的文档。
Elasticsearch 默认使用 BM25 算法,但也可以自定义评分方法,如通过 custom_score 或 function_score 查询来改变评分的逻辑。
查询相关性评分:
Elasticsearch 会根据关键词在文档中的出现频率、文档的长度以及其他因素来评分。
查询文档中包含 "Elasticsearch" 和 "tutorial" 的文章,Elasticsearch 会根据词频计算相关性评分。
{
"query": {
"match": {
"content": "Elasticsearch tutorial"
}
}
}
安全性与访问控制
Elasticsearch 提供了多种安全控制功能,确保集群和数据的安全性。常见的安全功能包括:<br><br><ul><li>用户认证与授权:通过 X-Pack 插件,Elasticsearch 提供用户和角色管理功能,可以对用户的操作权限进行细粒度控制。</li><li>SSL/TLS 加密:Elasticsearch 支持通过 SSL/TLS 加密通信,以确保数据的安全性。</li><li>审计日志:记录用户的访问行为,进行安全审计和监控。</li></ul>
Elasticsearch 性能优化
索引优化
<ul><li>合理分片:选择合适的分片数量可以有效提高查询性能。在 Elasticsearch 中,索引分片的数量决定了数据的分布,分片过多会导致性能下降,而分片过少会影响查询的并发性能。通常,建议根据数据量和查询需求来设定分片数量。</li><li>映射优化:合理设计索引的映射(Mapping),特别是字段的类型和索引方式。避免对不需要被搜索的字段进行索引,可以减小索引的大小,提高查询速度。</li><li>字段数据类型优化:为数值字段选择合适的数据类型,并避免使用多字段(Multi-fields)来增加不必要的索引字段。</li></ul>
查询优化
<ul><li>使用 filter 而不是 query:在布尔查询中,如果某个条件不需要计算相关性评分,可以使用 filter 子句。filter 是免费的,不计算相关性分数,因此比 query 更高效。</li><li>避免 wildcard 和 regex 查询:通配符查询和正则表达式查询可能会导致性能问题,尽量避免在高频查询中使用。</li><li>缓存机制:Elasticsearch 内部实现了查询缓存。通过合理的查询设计,利用缓存可以大幅提升查询性能。</li></ul>
集群优化
<ul><li>集群资源管理:合理配置 Elasticsearch 集群的硬件资源,包括内存、CPU 和磁盘空间。特别是对节点内存的管理,应该为每个节点分配合适的 JVM 堆内存大小,避免过大的堆内存导致垃圾回收延迟。</li><li><br></li><li>使用快照与备份:定期对数据进行快照,以防止数据丢失。Elasticsearch 提供了快照 API,可以将数据备份到远程存储中(如 S3、HDFS 等)。</li></ul>
Elasticsearch 应用场景
<ul><li>全文搜索:用于网站、博客、电商平台等的搜索引擎,提供高效的文本检索。</li><li>日志管理与分析:ELK Stack(Elasticsearch, Logstash, Kibana)广泛用于日志收集、存储和分析。</li><li>实时数据分析:Elasticsearch 支持对实时数据的快速查询和分析,适用于监控系统和实时数据流处理。</li><li>数据仓库和 BI:Elasticsearch 的聚合功能可以用于数据</li></ul>
消息队列
RabbitMQ
描述
RabbitMQ 是一个开源的消息代理软件,遵循 AMQP(Advanced Message Queuing Protocol)协议,支持多种消息传输协议,广泛用于分布式系统中的异步消息通信。它通过将消息传递到队列并保证消息传递的可靠性,帮助系统实现解耦、异步处理等特性。
RabbitMQ 核心概念
消息队列(Queue)
消息队列是 RabbitMQ 中存储消息的地方,消费者从队列中获取消息并进行处理。消息会按照先进先出的顺序(FIFO)在队列中进行存储。
交换机(Exchange)
交换机是 RabbitMQ 中的一个重要组件,负责接收生产者发送的消息,并根据路由规则将消息转发到一个或多个队列。交换机类型的不同,决定了它如何路由消息。<br><br>交换机有以下几种常见类型:<br><ul><li>Direct Exchange:根据消息的路由键(routing key)将消息发送到匹配的队列。</li><li>Fanout Exchange:将消息广播到所有绑定的队列,不考虑路由键。</li><li>Topic Exchange:根据路由键中的模式(wildcard)将消息发送到匹配的队列,灵活性高。</li><li>Headers Exchange:通过消息的 header 来路由消息,不使用路由键。</li></ul>
队列绑定(Binding)
队列和交换机之间的关系通过绑定实现。交换机将消息路由到队列中,通常通过路由键来确定消息应路由到哪个队列。绑定是一种动态过程,可以随时修改。
消息(Message)
消息是 RabbitMQ 中传输的数据单元,生产者通过交换机将消息发送到队列,消费者从队列中读取消息进行处理。消息可以包含任何类型的数据,比如 JSON、XML 或者二进制数据。
路由键(Routing Key)
路由键是用于交换机与队列之间消息路由规则的一个字符串。交换机通过该路由键决定将消息路由到哪个队列。例如,direct 类型的交换机会直接根据消息的路由键将消息发送到队列。
消费者(Consumer)
消费者是从队列中接收消息并进行处理的应用程序。消费者从队列中获取消息并进行相关业务处理,一旦处理完成,消费者会确认消息的消费。
生产者(Producer)
生产者是发送消息到 RabbitMQ 交换机的应用程序。生产者并不直接和队列进行交互,而是通过交换机将消息发送到队列。
RabbitMQ 工作原理
消息发送流程
<ol><li>生产者 将消息发送到 交换机。</li><li>交换机根据消息的路由键将消息路由到 绑定的队列。</li><li>消费者 从队列中获取消息并进行处理。</li></ol>
消息确认机制
消息的可靠性传输是 RabbitMQ 的重要特点之一。消息传递可以分为两种确认方式:<br><br><ul><li>自动确认:消费者从队列获取消息后自动确认消息已被成功消费。</li><li>手动确认:消费者处理完消息后手动确认消息已经消费,这样可以保证消息在处理成功后才从队列中删除。</li></ul>
消息持久化
为了保证消息不会在 RabbitMQ 停止或重启后丢失,RabbitMQ 提供了消息持久化机制。可以通过设置队列和消息为持久化,确保消息在服务器重启时不会丢失。
死信队列(Dead Letter Queue)
如果消息无法被消费者成功消费,或者消息过期,RabbitMQ 会将这些消息转发到一个指定的死信队列中。这使得开发者可以对这些无法消费的消息进行进一步的处理。
交换机与队列绑定
交换机与队列的绑定是通过路由键完成的。具体的路由规则根据交换机类型有所不同。比如:<br><br><ul><li>Direct Exchange:精确匹配路由键。</li><li>Fanout Exchange:消息会广播到所有绑定的队列,不关心路由键。</li><li>Topic Exchange:支持通配符,可以实现复杂的消息路由。</li><li>Headers Exchange:根据消息的 header 来进行路由。</li></ul>
RabbitMQ 的高级特性
消息优先级
RabbitMQ 支持为队列中的消息设置优先级,消费者会根据消息的优先级来决定先处理哪个消息。通过设置队列的优先级属性,可以影响消息消费的顺序。
限流
RabbitMQ 提供了限流机制来防止系统过载。可以对生产者、消费者或者队列设置流量控制,确保系统能够平稳运行。例如,可以限制队列的最大长度,当队列满时,生产者发送消息会被拒绝。
集群与高可用性
RabbitMQ 支持通过集群机制来提升可用性。集群模式下,RabbitMQ 会将多个节点连接在一起,组成一个集群。消息可以在集群中进行分布式存储,并实现高可用性。如果某个节点发生故障,其他节点可以继续工作。
插件支持
RabbitMQ 支持通过插件扩展功能。RabbitMQ 插件可以添加多种功能,如监控、管理、协议支持等。比如,RabbitMQ 提供了 Management Plugin,可以通过 HTTP API 或者 Web UI 来管理 RabbitMQ 集群。
消息过期与 TTL
RabbitMQ 支持消息的生命周期管理,可以为消息设置过期时间(TTL)。消息在队列中超过指定时间未被消费时,会被丢弃,或者转移到死信队列中。这有助于避免长时间未处理的垃圾消息堆积。
消费者预取(Prefetch)
消费者预取是指消费者从队列中预取消息的数量。通过设置消费者的预取计数,消费者可以控制每次从队列中获取多少消息。这有助于防止消费者过载。
RabbitMQ 常见使用场景
5.1 异步任务处理
RabbitMQ 非常适合用于异步任务处理。生产者将任务消息发送到队列,消费者从队列中获取任务并进行处理,消费者之间可以并发执行,从而提高系统的吞吐量。
5.2 消息解耦
通过将消息放入 RabbitMQ 队列中,生产者和消费者之间实现了解耦。生产者不需要关心消息是否被消费,消费者也可以独立运行并处理消息。
5.3 事件驱动架构
RabbitMQ 支持事件驱动架构,可以通过发布订阅模式(Fanout Exchange)将事件广播到多个消费者,适合实时系统和日志分析系统。
5.4 系统集成
RabbitMQ 可作为异构系统之间的消息传递中介,实现不同系统之间的集成。例如,可以在微服务架构中使用 RabbitMQ 实现服务间通信。
总结
RabbitMQ 是一款功能强大的消息队列系统,提供了丰富的功能来支持高效可靠的消息传递。通过合理配置与优化,RabbitMQ 可以应用于许多不同的场景,如异步处理、消息解耦、事件驱动等。通过支持 AMQP 协议以及插件扩展,RabbitMQ 具有良好的可扩展性和灵活性,适用于分布式系统、微服务架构等多种应用场景。
ActiveMQ
描述
ActiveMQ 是一个开源的消息中间件,由 Apache 提供支持。它基于 JMS(Java Message Service)规范,支持多种消息协议,如 AMQP、MQTT 和 STOMP,用于在不同的系统或应用程序之间传递消息。ActiveMQ 能够处理高并发、大规模的消息传递,并且具有高可靠性和高可用性。它广泛应用于企业级分布式系统、微服务架构等场景,支持异步消息处理、解耦、可靠消息传递等功能。
ActiveMQ 核心概念
消息(Message)
消息是 ActiveMQ 中传递的数据单元。消息包含消息的有效载荷(通常是文本、二进制数据或对象),以及一些元数据,如消息的目的地(Destination)、消息类型、优先级等。
目的地(Destination)
消息的目标地点,即接收消息的对象。ActiveMQ 中的目的地有两种类型:<br><br><ul><li>Queue:点对点模式(P2P),每条消息只能被一个消费者消费。</li><li>Topic:发布/订阅模式(Pub/Sub),每条消息会被所有订阅者消费。</li></ul>
生产者(Producer)
生产者是负责将消息发送到 ActiveMQ 目的地(队列或主题)的应用程序。它不需要关心消息的消费端,只需将消息发送到指定的目的地。
消费者(Consumer)
消费者是从目的地(队列或主题)中消费消息的应用程序。消费者从消息队列或主题中获取消息并进行处理。
连接工厂(ConnectionFactory)
连接工厂是 ActiveMQ 中用于创建连接的对象。通过连接工厂,生产者和消费者可以连接到 ActiveMQ 代理(Broker)。
消息代理(Broker)
消息代理是负责存储、转发消息并管理消息传递的组件。ActiveMQ 的 Broker 支持多个协议,并且能够处理大量并发的消息传递。
会话(Session)
会话是消费者和生产者与消息代理进行交互的上下文。会话负责创建生产者、消费者和消息的生成。它也负责事务管理和消息确认。
ActiveMQ 工作原理
消息发送流程
<ol><li>生产者通过 连接工厂 创建连接。</li><li>连接工厂创建 连接,然后通过连接创建 会话。</li><li>会话创建消息生产者,生产者将消息发送到 目的地(Queue 或 Topic)。</li><li>ActiveMQ 消息代理将消息存储在对应的目的地。</li><li>消费者连接到 ActiveMQ 代理,获取消息并进行处理。</li></ol>
消息确认
消息确认是 ActiveMQ 中确保消息可靠性的机制。消费者在处理完消息后,需要确认消息已经成功消费,以便 ActiveMQ 删除该消息。消息确认有两种方式:<br><br><ul><li>自动确认:消费者从队列中获取消息后自动确认消息。</li><li>手动确认:消费者手动确认消息,只有在处理完消息后才进行确认。</li></ul>
消息持久化
消息持久化是确保消息在服务器宕机或重启后不会丢失的机制。ActiveMQ 可以将消息持久化到磁盘中,即使发生故障,消息也能被恢复。可以配置队列或主题以启用消息持久化。
消息过期
消息可以设置过期时间。当消息在队列中存在超过指定时间时,消息会被自动删除,避免积压的过期消息影响系统性能。
消息的优先级
ActiveMQ 允许为消息设置优先级。通过设置消息的优先级,系统可以确保高优先级的消息会被优先处理。默认情况下,ActiveMQ 支持 10 个级别的优先级,从 0 到 9。
ActiveMQ 高级特性
事务管理
ActiveMQ 支持事务机制,可以在生产者和消费者中进行事务控制。在事务内发送的消息,如果事务提交,则消息被成功传递;如果事务回滚,则所有消息将被撤回。
消息路由
ActiveMQ 支持多种消息路由机制:<br><br><ul><li>Point-to-Point(P2P):通过队列模型进行点对点消息传递,每条消息只有一个消费者。</li><li>Publish/Subscribe(Pub/Sub):通过主题模型进行发布订阅模式的消息传递,每条消息可以被多个订阅者消费。</li></ul>
集群和高可用性
ActiveMQ 支持高可用性和负载均衡。通过配置 Master-Slave 集群模式,消息代理的主节点会向备份节点同步消息数据,确保在主节点宕机时系统能自动切换到备份节点,保证系统的高可用性。
分布式消息传递
ActiveMQ 可以跨多个数据中心进行消息传递,支持高效的消息复制和负载均衡。通过配置 KahaDB 和 JDBC 连接池,ActiveMQ 可以进行跨数据中心的消息同步。
消息过滤
在订阅者和主题之间,ActiveMQ 提供了强大的消息过滤功能。消费者可以通过定义 消息选择器 来过滤消息,只有符合特定条件的消息才会被消费者接收。
消息重试与死信队列
ActiveMQ 支持消息重试机制。如果消费者处理消息失败,可以设置重试次数。超过最大重试次数后,消息将被送入 死信队列(Dead Letter Queue),便于后续处理。
ActiveMQ 常见应用场景
5.1 异步消息传递
ActiveMQ 可以用于构建异步任务处理系统,将任务消息发送到队列,消费者从队列中读取并处理任务。它适合用于处理高并发和低延迟的业务场景。
5.2 微服务架构
在微服务架构中,服务之间的通信可以通过 ActiveMQ 实现解耦。微服务之间不直接调用,而是通过消息传递机制进行异步通信,提高系统的可扩展性。
5.3 事件驱动架构
ActiveMQ 可以用于事件驱动架构中,各个系统通过发布/订阅机制实现事件通知,保证系统间的实时数据同步。
5.4 数据同步与集成
ActiveMQ 可用于多个系统之间的消息传递,帮助不同系统进行数据同步。例如,异构系统之间的消息传递、金融交易平台的异步处理等。
总结
ActiveMQ 是一款功能强大的开源消息中间件,基于 JMS 规范,支持多种消息协议和高可用性特性。它的可靠性、灵活性和可扩展性使其在分布式系统、微服务架构等场景中得到广泛应用。通过合理的配置,ActiveMQ 能够满足各种复杂的消息传递需求,并能够处理高并发、分布式环境下的消息传递问题。
RocketMQ
什么是 RocketMQ?
RocketMQ 是阿里巴巴开源的一款高性能、低延迟、分布式的消息中间件,基于 Java 开发,主要用于 高吞吐、低延迟、高可靠性的消息传输。RocketMQ 适用于 异步消息处理、分布式事务、事件驱动架构、流式计算等 场景。
RocketMQ 目前已进入 Apache 基金会,成为顶级开源项目,广泛应用于 金融、电商、物流、大数据、物联网等 领域。
RocketMQ 的核心架构
RocketMQ 的整体架构包括以下几个核心组件:
<ul><li>Producer(生产者):负责发送消息到 Broker。</li><li>Broker(消息代理):负责接收、存储和转发消息。</li><li>Consumer(消费者):负责从 Broker 拉取消息并处理。</li><li>NameServer(注册中心):提供 Broker 的路由信息,并管理 Broker 的动态变更。</li></ul>
RocketMQ 的消息传递流程
<ul><li>生产者(Producer) 通过 NameServer 获取 Broker 的地址信息,并向 Broker 发送消息。</li><li>Broker 收到消息后,将消息存储到本地磁盘(CommitLog)中,同时更新消息的索引(ConsumeQueue)。</li><li>消费者(Consumer) 从 Broker 订阅并消费消息,消费模式可以是推模式(Push) 或 拉模式(Pull)。</li><li>NameServer 作为轻量级的注册中心,管理 Broker 和 Consumer 之间的映射关系。</li></ul>
RocketMQ 的核心概念
消息(Message)
RocketMQ 中的消息是数据传递的基本单位,包含:<br><br><ul><li>Topic(主题):消息的分类,每条消息必须属于一个 Topic。</li><li>Tag(标签):用于对 Topic 进行进一步细分。</li><li>Key(消息键):用于唯一标识消息,方便查询和追踪。</li><li>Body(消息体):具体的消息内容,可以是 JSON、XML 或二进制数据。</li></ul>
主题(Topic)
<ul><li>每条消息必须有一个 Topic,不同 Consumer Group 可以订阅相同的 Topic。</li><li>Topic 在 RocketMQ 中相当于 逻辑队列,多个 Consumer Group 可以订阅同一个 Topic,但每个 Consumer 只能消费自己的队列(Queue)。</li></ul>
生产者(Producer)
生产者用于发送消息,它支持同步(Sync)、异步(Async)、单向(OneWay) 三种发送模式:<br><ul><li>同步发送:发送消息后,等待 Broker 确认。</li><li>异步发送:发送消息后,不等待 Broker 确认,适用于高吞吐业务。</li><li>单向发送:发送消息后不关心是否发送成功,适用于日志等场景。</li></ul>
消费者(Consumer)
消费者用于接收并处理消息,支持两种消费模式:<br><ul><li>Push 模式:Broker 主动推送消息到 Consumer。</li><li>Pull 模式:Consumer 主动从 Broker 拉取消息。</li></ul>
消费者组(Consumer Group):多个 Consumer 组成一个 Group,用于并行消费 Topic。
RocketMQ 提供两种消费模式:
RocketMQ 提供两种消费模式:<br><br>集群消费(Clustering Mode):<br><ul><li>多个消费者组成一个 Consumer Group,消息被 多个消费者分摊 处理。</li><li>每条消息只会被其中一个消费者消费(负载均衡)。</li></ul>广播消费(Broadcasting Mode):<br><ul><li>所有 Consumer Group 内的消费者都能收到同样的消息(适用于多实例处理相同数据)。</li></ul>
消息存储
<ul><li>消息存储在 CommitLog 中,同时建立 ConsumeQueue(索引文件),加速消息查询。</li><li>消息存储采用 MappedFile 机制,基于 零拷贝(Zero Copy) 提高 IO 性能。</li></ul>
RocketMQ 的高级特性
顺序消息
RocketMQ 支持 全局顺序消息 和 分区顺序消息:<br><ul><li>全局顺序消息:消息按照严格的顺序存入同一个 Queue,消费时必须按顺序读取。</li><li>分区顺序消息:同一 Key 的消息会进入相同的队列,保证局部有序。</li></ul>
消息重试
RocketMQ 支持自动重试机制,如果消费者处理失败,可以自动重试。<br>重试规则:<br><ul><li>顺序消息:失败后进入 重试队列,直至消费成功。</li><li>普通消息:默认重试 16 次,失败后进入 死信队列(DLQ)。</li></ul>
死信队列(DLQ)
<ul><li>超过最大重试次数的消息,会进入 死信队列,以防止消息丢失。</li><li>开发者可以手动处理死信消息,以保证消息最终处理。</li></ul>
延迟消息
<ul><li>RocketMQ 支持 定时/延迟消息,消息可在固定时间后投递。</li><li>最多支持 18 级延迟(从 1s 到 2h)。</li></ul>
事务消息
RocketMQ 独有的分布式事务消息机制,解决分布式事务问题。<br>事务消息流程:<br><ul><li>生产者发送半消息,RocketMQ 先存储但不会投递。</li><li>生产者执行本地事务(如数据库更新)。</li><li>本地事务成功,发送确认消息,RocketMQ 投递消息。</li><li>本地事务失败,RocketMQ 丢弃该消息。</li></ul>
高可用架构
<ul><li>多 NameServer 结构,支持动态路由和高可用性。</li><li>主从 Broker 结构,支持 SYNC 和 ASYNC 双写,提高容灾能力。</li></ul>
RocketMQ 适用场景
<br>
总结
RocketMQ 作为一款高性能的消息中间件,具有 高吞吐、低延迟、事务消息、顺序消息、分布式事务 等优点,广泛应用于 金融、电商、游戏、物联网等领域。如果你的业务需要高性能的消息处理,RocketMQ 是一个非常好的选择!
Kafka
什么是 Kafka?
Apache Kafka 是一个 分布式流式处理平台,用于构建 高吞吐、可扩展、可持久化 的消息系统。它最初由 LinkedIn 开发,并于 2011 年开源,后来成为 Apache 的顶级项目。Kafka 主要用于 日志收集、实时流处理、消息队列、大数据分析 等场景。
Kafka 主要特点:<br><br><ul><li>高吞吐量:每秒可处理百万级消息。</li><li>分布式架构:高可用,可水平扩展。</li><li>持久化存储:消息存储到磁盘,可长时间保留。</li><li>发布订阅模式:支持实时和批量消费。</li></ul>
Kafka 的核心架构
Kafka 由多个组件构成:<br><br><ul><li>Producer(生产者):向 Kafka 发送消息。</li><li>Broker(消息代理):存储和管理消息,Kafka 集群中的服务器。</li><li>Consumer(消费者):从 Kafka 订阅并消费消息。</li><li>Topic(主题):消息的分类,Kafka 通过 Topic 组织消息。</li><li>Partition(分区):Topic 内部的物理存储单位,每个 Topic 由多个 Partition 组成。</li><li>Zookeeper:Kafka 依赖 Zookeeper 进行元数据管理、选举 Leader 等操作。</li></ul>
Kafka 消息流动过程::<br><br><ul><li>Producer 发送消息到 指定的 Topic,Kafka 根据分区策略 写入 Partition。</li><li>Broker 存储消息,每个 Partition 的 Leader 负责接收和复制数据到 Follower。</li><li>Consumer 订阅 Topic 并消费消息,消息在多个 Partition 之间并行处理。</li><li>Zookeeper 负责管理元数据,例如 Broker 状态、Partition Leader 选举等。</li></ul>
Kafka 核心概念
Topic(主题)
Kafka 通过 Topic 进行消息分类,一个 Topic 可以有多个 Partition,每个 Partition 都存储一部分 Topic 的数据。
Partition(分区)
<ul><li>Topic 被拆分成多个 Partition,可以并行存储,提高吞吐量。</li><li>每个 Partition 由一个 Leader 和多个 Follower 组成,Leader 负责读写,Follower 负责备份数据。</li></ul>
Producer(生产者)
生产者将消息写入 Kafka,支持 同步(Sync) 和 异步(Async) 发送:<br><ul><li>同步发送:等待 Broker 确认,保证数据可靠性。</li><li>异步发送:不等待 Broker 响应,适用于高吞吐场景。</li></ul>
Consumer(消费者)
消费者从 Broker 读取消息,支持两种消费模式:<br><ul><li>拉取模式(Pull):消费者主动拉取消息(Kafka 默认)。</li><li>推送模式(Push):Kafka 主动推送消息(Kafka 默认不采用)。</li></ul>
Consumer Group(消费者组)
<ul><li>多个 Consumer 可以组成 Consumer Group,共同消费 Topic 的数据。</li><li>同一个 Partition 只能被一个 Consumer 消费,避免重复消费。</li></ul>
Offset(偏移量)
Kafka 通过 Offset 记录 Consumer 消费的位置,防止消息丢失。<br>Offset 存储方式:<br><ul><li>默认存储在 Kafka,高效可靠(推荐)。</li><li>存储在 Zookeeper,适用于早期版本 Kafka。</li></ul>
Broker(消息代理)
<ul><li>Kafka 集群中的 每台服务器就是一个 Broker。</li><li>多个 Broker 组成 Kafka 集群,提供高可用和负载均衡。</li><li>Leader-Follower 机制:每个 Partition 有一个 Leader,多个 Follower 进行数据备份。</li></ul>
Kafka 的核心特性
高吞吐量
<ul><li>Kafka 使用磁盘顺序写入,并结合零拷贝(Zero Copy) 提高吞吐量。</li><li>支持批量发送和压缩,减少网络开销。</li></ul>
可靠性
<ul><li>Kafka 通过 ISR(同步副本集) 确保数据一致性。</li><li>支持多副本(Replication)机制,保证数据高可用。</li></ul>
分布式存储
<ul><li>Kafka 采用 Partition 进行数据分片,支持水平扩展。</li><li>多 Broker 结构,避免单点故障。</li></ul>
事务支持
Kafka 支持事务,确保消息的精确一次(Exactly Once)投递。
乱序与有序
Kafka 只能保证 Partition 内部有序,但不能保证全局有序。<br>解决方案:<br><ul><li>使用单 Partition,保证全局有序(影响吞吐)。</li><li>基于 Key 进行 Hash 分区,保证同一 Key 进入相同 Partition。</li></ul>
Kafka 消息存储
存储机制
<ul><li>Kafka 消息存储在 Segment 文件 中,每个 Partition 由多个 Segment 组成。</li><li>Kafka 使用 PageCache 进行缓存,减少磁盘 IO 访问,提高性能。</li></ul>
数据删除策略
Kafka 提供两种消息删除策略:<br><ul><li>基于时间删除(log.retention.hours):默认保留 168 小时(7 天)。</li><li>基于大小删除(log.retention.bytes):当 Partition 超过阈值时,删除旧数据。</li></ul>
Kafka 典型应用场景
<br>
Kafka 与 RabbitMQ 对比
<br>
总结
Kafka 是目前最流行的分布式消息系统,广泛应用于实时数据处理、大数据分析、流式计算等场景。它以 高吞吐、可扩展、高可靠性 的特点,在日志收集、事件流处理、消息队列等领域具有无可替代的优势。
消息队列对比总结
<br>
面试题
通用
为什么需要消息队列(MQ),有什么优点和缺点?
优点:<br><ul><li>解耦:系统间通信解耦,提高扩展性。</li><li>削峰填谷:缓解高并发请求压力,防止数据库崩溃。</li><li>异步处理:提高系统吞吐量,优化响应时间。</li></ul>缺点:<br><ul><li>增加复杂度:涉及消息可靠性、重复消费、幂等性等问题。</li><li>系统可用性降低:MQ 本身是依赖组件,宕机会影响业务。</li><li>一致性问题:需要保证分布式事务或最终一致性。</li></ul>
如何保证 MQ 消息的可靠性?
生产者端:<br><ul><li>开启 事务机制 或 ACK 确认机制,确保消息成功发送到 MQ。</li></ul>MQ 端:<br><ul><li>持久化存储(磁盘/数据库),防止数据丢失。</li><li>主从备份,Kafka 的 ISR 机制保证副本同步。</li></ul>消费者端:<br><ul><li>手动 ACK 确认消费,防止消息丢失。</li></ul>
如何解决 MQ 的重复消费问题?
消费者端处理:<br><ul><li>幂等性设计(如数据库去重、基于 Redis 记录已消费消息)。</li><li>使用全局唯一 ID(如业务 ID 或 UUID)。</li></ul>MQ 端:<br><ul><li>RabbitMQ 使用 ACK 机制,确保消息被正确处理后再删除。</li></ul>
如何保证 MQ 消息的有序性?
<ul><li>Kafka:通过单 Partition 顺序写入,保证 Partition 内部消息有序。</li><li>RocketMQ:支持全局有序队列,基于单一队列模式实现顺序消费。</li><li>RabbitMQ:默认不保证消息顺序,但可以通过 FIFO 队列和 Message Group 解决。</li></ul>
如何保证 MQ 的高可用性?
<ul><li>Kafka:采用 ISR(同步副本)机制,分区 Leader 宕机时,Follower 自动提升为 Leader。</li><li>RabbitMQ:主从模式(镜像队列),主节点挂掉时,从节点接管。</li><li>RocketMQ:多主多从模式,主从间同步数据,支持自动 Failover。</li></ul>
Kafka 面试题
Kafka 是如何保证高吞吐量的?
<ul><li>顺序写入磁盘(减少随机 IO)。</li><li>使用 PageCache 进行文件缓存,减少磁盘访问。</li><li>支持批量发送和压缩,减少网络开销。</li></ul>
Kafka 消息存储在哪里?
<ul><li>数据存储在 Segment 文件中,每个 Partition 由多个 Segment 组成。</li><li>Kafka 采用 PageCache 提高读写效率。</li></ul>
Kafka 如何保证数据不丢失?
<ul><li>生产端:acks=all 确保消息写入所有副本。</li><li>Broker 端:ISR 机制(同步副本),防止数据丢失。</li><li>消费者端:手动提交 Offset,防止消息丢失。</li></ul>
RabbitMQ 面试题
RabbitMQ 的消息模型?
<ul><li>直连(Direct)交换机:点对点投递消息。</li><li>广播(Fanout)交换机:将消息广播到所有绑定队列。</li><li>主题(Topic)交换机:支持模糊匹配路由(#、*)。</li></ul>
RabbitMQ 如何处理死信队列(DLX)?
<ul><li>设置 TTL(Time-To-Live)超时机制,自动转移到死信队列。</li><li>消息被 多次拒绝(rejected),也会进入死信队列。</li></ul>
ActiveMQ 面试题
ActiveMQ 的持久化机制有哪些?
<ul><li>JDBC 存储(数据库)。</li><li>KahaDB 存储(默认,性能较好)。</li><li>内存存储(适用于短期任务)。</li></ul>
ActiveMQ 如何支持分布式事务?
使用 XA 事务,支持 2PC(两阶段提交) 确保数据一致性。
RocketMQ 面试题
RocketMQ 事务消息原理?
支持 Try-Confirm-Cancel 事务机制,生产者提交消息后,RocketMQ 先存储 半消息,消费者确认消费后,才正式提交。
RocketMQ 如何支持延迟消息?
通过 定时队列 + 时间轮,实现延迟级别消费。
MQ 面试技巧
<ol><li>掌握 MQ 基本概念,如 生产者-消费者模型、ACK 确认机制。</li><li>对比不同 MQ 的优缺点,Kafka 适用于高吞吐日志分析,RabbitMQ 适用于事务队列。</li><li><span style="font-size: inherit;">熟练解决 MQ 常见问题:</span></li></ol><ul><li><span style="font-size: inherit;">丢消息 → 持久化+ACK 机制。</span></li><li><span style="font-size: inherit;">重复消费 → 幂等设计。</span></li><li><span style="font-size: inherit;">高可用 → 主从+分区机制。</span></li></ul>
数据库
mysql
sql流程
sql查询<br>
查询解析器
在这一阶段,MySQL 会对 SQL 查询进行语法检查,以确认 SQL 语法是否正确。MySQL 会使用 语法分析器(Parser) 来进行此步骤。解析过程包括以下几个步骤:<br><br>词法分析(Lexical Analysis):将查询字符串拆分成一系列的标记(Token),例如关键词、标识符、常量等。<br>语法分析(Syntax Analysis):将这些标记组成一个语法树(Parse Tree),并检查 SQL 语句的语法是否符合 MySQL 的 SQL 语法规则。<br>如果 SQL 语法无误,解析器会将其转换为 内部表示,通常是 抽象语法树(AST) 或 查询树。
查询优化器
接下来,MySQL 会将查询交给 查询优化器(Optimizer)。在这个阶段,优化器的目标是选择一种执行计划,使得 SQL 查询能够高效执行。优化器会考虑以下几个因素:<br><br>查询重写(Query Rewrite):通过重写查询来提升执行效率,例如将子查询转换为连接等。<br>成本估算:计算不同执行计划的成本,选择一个最优的执行计划。成本估算会根据表的索引、表的大小、数据分布等因素来做出选择。<br>执行计划生成:生成一个执行计划,通常是 访问路径 的选择,例如全表扫描、索引扫描、联合索引等。<br>优化器最终会选择一个执行计划,并将其传递给执行引擎。
执行器+调用存储引擎接口<br>
根据优化器选择的执行计划,MySQL 会调用相应的执行引擎(如 InnoDB、MyISAM)来实际执行查询。这一阶段包括:<br><br>获取数据:MySQL 会从磁盘或缓存中获取所需数据。<br>索引查找:如果查询使用了索引,MySQL 会通过索引查找数据,避免全表扫描。<br>数据处理:执行查询中所涉及的任何计算、连接、排序、聚合等操作。
<br>
bufferpool<br>
描述信息
MySQL 的 Buffer Pool 是 InnoDB 存储引擎的一个重要组成部分,用于缓存数据页、索引页以及其他内存中的数据结构。其主要目的是减少磁盘 I/O,提高数据库的性能。<br><br>在 InnoDB 存储引擎 中,Buffer Pool 是一个内存区域,用来存储和缓存从磁盘读取的数据。当一个查询请求数据时,InnoDB 会先在 Buffer Pool 中查找所需的数据页,如果没有找到(即发生了 缓存未命中),则会从磁盘加载数据到 Buffer Pool 中并进行访问。
Buffer Pool 内存结构
Buffer Pool 是通过多个 数据页(data pages) 组织起来的。每个数据页通常为 16KB,MySQL 会根据内存的大小将 Buffer Pool 划分为多个页,每个页可以缓存数据库表中的一部分数据。内存管理的基本单位就是这些数据页。
Buffer Pool 的主要作用:
1、减少磁盘 I/O:通过将频繁访问的数据缓存到内存中,避免每次都从磁盘读取数据,从而提高性能。<br>2、加速查询响应时间:提高数据读取速度,尤其是当查询涉及到大量数据访问时,能够显著降低查询的延迟。<br>3、缓存数据页:除了普通的表数据外,Buffer Pool 还缓存索引页、redo log 和其他元数据结构,进一步提高了系统的整体性能。<br>
Buffer Pool 主要包含以下几类数据
1、数据页(Data Pages):存储实际的表数据。<br>2、索引页(Index Pages):存储表的索引信息。包括 B+ 树索引、聚集索引等。<br>3、Insert Buffer:用于加速对索引的写入操作,主要用于二级索引的插入。<br>4、Adaptive Hash Index:为了加速某些查询,InnoDB 会基于查询的访问模式自动创建哈希索引,并存储在 Buffer Pool 中。<br>5、双写缓冲(Doublewrite Buffer):写入数据前,先写入 Buffer Pool,再写入磁盘。这可以避免因崩溃导致的数据损坏。<br>
Buffer Pool 的工作流程
1、查询缓存:当有查询请求时,InnoDB 会首先检查该查询所需的数据页是否已经存在于 Buffer Pool 中。如果存在(缓存命中),则直接从内存中读取数据。<br>2、缓存未命中:如果数据页不在 Buffer Pool 中,InnoDB 会从磁盘中读取相应的数据,并将其存入 Buffer Pool。之后,查询将从内存中获取数据。<br>3、脏页(Dirty Pages):如果对数据进行了修改,Buffer Pool 中相应的数据页会被标记为脏页,表示该页的数据与磁盘上的数据不一致。脏页会定期刷新(写回)到磁盘中。<br>4、刷新脏页(Flush):InnoDB 会定期将脏页写回磁盘,这个过程称为 刷脏(Flush Dirty Pages)。在写回过程中,InnoDB 会遵循一定的策略来保证数据的一致性和高效性。<br>
free链表
flush链表
缓存页是否有被缓存的数据结构,hash表
表空间号+数据页号作为key,缓存页地址作为value<br>
缓存页淘汰算法
内存管理
Buffer Pool 会通过 LRU(Least Recently Used) 算法来管理内存中的数据页。当 Buffer Pool 满时,最久未被访问的数据页会被淘汰出缓存,以腾出空间给新的数据页。
Buffer Pool Dumping
当 MySQL 进程停止时,Buffer Pool 中的数据会被 "dump"(转储)到磁盘,以便下次启动时恢复,避免从磁盘重新加载数据。
lru链表
简单lru链表带来的问题
mysql预读机制
全表扫描
冷热数据分离lru链表
innodb_old_blocks_pct<br>
冷热数据比例
默认冷数据占比37%<br>
第一次加载到冷数据头部
innodb_old_blocks_time<br>
默认1s
1s以后访问这个缓存页放到热数据头部
访问热数据前1/4不会移到热数据头部<br>
日志
undolog日志
回滚日志
redolog日志
事务没有提交前,mysql宕机不会丢失数据,因为事务还没有提交
innodb_flush_log_at_trx_commit<br>
0
不会立即存盘
1
立即存磁盘才返回成功
2
存os缓存
innodb特有日志
表空间号+数据页号+偏移量+修改几个字节的值+具体的值<br>
日志类型(就是类似MLOG_1BYTE之类的),表空间ID,数据页号,数据页中的偏移量,具体修改的数据<br>
binglog日志
归档日志
sync_binglog<br>
刷盘策略
0
刷入os缓存
1
强制刷回磁盘
基于binglog和redolog完成事务的提交
日志类型
<br>
一行数据在磁盘如何存储
compact格式
变长字段的长度列表、null值列表、数据头、column01的值、column02的值、column0N的值、
索引
页分裂
B+ 树索引基础
B+ 树 是一种自平衡的树状数据结构,常用于数据库索引。B+ 树中的每个节点都包含一个键值和指向子节点的指针。叶子节点存储实际的数据指针,内部节点存储键值和指向下一个层级节点的指针。<br><br>在 InnoDB 存储引擎中,所有的索引都是基于 B+ 树 的,默认使用聚簇索引(Primary Key)来存储数据,非聚簇索引(Secondary Index)则存储对数据行的引用(即数据行的主键值)。
索引页分裂的触发
<br>
页分裂的过程
1、页已满:当索引页被填满,且有新数据插入时,MySQL 会进行页分裂操作。<br>2、选择分裂点:MySQL 会选择中间的键值作为分裂点。假设我们有一个包含多个键值的索引页,分裂点通常是该页索引项的中间位置。这个分裂点会成为新页的最小键值。<br>3、创建新页:MySQL 会为分裂出来的部分创建一个新的索引页。新页中会包含一些原本属于老页的数据项。<br>4、更新父节点:在分裂过程中,分裂出的新页会被插入到父节点中(即上层的索引页)。如果父节点也已经满了,那么父节点也会发生分裂。这可能会导致逐层向上分裂,直到根节点。根节点分裂后,B+ 树的层级将增加。<br>5、数据迁移:分裂的过程中,部分数据项会从旧页移动到新页中,这样新页和旧页中的数据都会满足 B+ 树的结构要求,保持排序。
索引页分裂的影响
1. 性能影响<br>频繁分裂:频繁的索引页分裂会导致 磁盘 I/O 增加,因为每次分裂都会涉及到数据的写入、页的复制以及父节点的更新。频繁的分裂也可能会导致 B+ 树的高度增加,从而增加查询时的页访问次数。<br>碎片化:随着页分裂的进行,可能会导致索引中存在一些 不连续的空间(即碎片),尽管 B+ 树通常会尽量保持平衡,但碎片化可能导致某些页的空闲空间不能被高效利用。<br>缓存失效:每次索引页分裂都会导致数据页被重新写入磁盘,并更新父节点的索引。若数据库的缓存较小,可能会导致缓存命中率下降。<br><br>2. 索引效率下降<br>如果索引页分裂频繁,B+ 树的深度可能会增大。虽然 B+ 树的查找效率是 O(log n),但随着深度的增加,查询性能可能会逐渐下降。特别是在极端情况下,如果没有优化索引策略,查询可能需要多次磁盘访问,导致延迟增加。<br><br>3. 空间浪费<br>频繁的索引页分裂可能导致空间的浪费。每个页面都有固定的大小,可能存在部分空闲空间没有得到有效利用。<br>
如何优化和减少页分裂
1、合理设置页大小:通过调整 innodb_page_size(虽然 InnoDB 默认页大小为 16KB,但在某些场景下可以修改)可以提高磁盘空间的利用率,减少分裂的频率。<br>2、预分配空间:在设计索引时,确保索引的选择字段能有效避免频繁的页分裂。例如,选择具有较小值域或稀疏数据的列作为索引字段,减少插入的频率。<br>3、批量插入数据:如果你知道会有大量数据插入,可以将其分批处理,避免在一次性插入大量数据时频繁发生页分裂。<br>4、避免过多索引:避免为每个查询创建单独的索引,过多的索引会增加分裂的次数。合理选择和优化索引策略。<br>5、使用合适的填充因子(Fill Factor):在某些数据库系统中,可以调整填充因子,使得每个索引页不会在插入时很快被填满。虽然 InnoDB 本身没有直接的填充因子控制参数,但通过合理设计表的结构和选择合适的列类型,可以间接控制索引页的分裂频率。
B+树<br>
描述
B+树 是一种常用的自平衡树结构,广泛用于数据库索引和文件系统中。它是 B树(Balanced Tree)的变种,并具有优化的查询性能。MySQL 中的 InnoDB 存储引擎 使用 B+ 树作为其默认索引结构,包括 聚簇索引 和 非聚簇索引。
B+树的基本概念
B+树 是一种 自平衡的多路搜索树,它能够保证查询操作的高效性。B+树是一种 索引树,适用于范围查询和排序操作,能在 对数时间复杂度 内完成查找、插入和删除操作。
B+树的基本特点:
1、所有叶子节点存储数据:与普通的 B 树不同,在 B+ 树中,所有的实际数据(或者指向数据的指针)存储在 叶子节点。非叶子节点仅存储键值(不存储实际数据),用于指引搜索路径。<br>2、内节点只存储键值:内节点只存储索引键值,并作为导航指针,指向下层节点。<br>3、有序:B+树的节点按大小顺序排列,确保从根节点到叶节点的路径始终有序。<br>4、链式结构:B+树的叶子节点通过指针形成一个链表,这使得范围查询变得高效,能够顺序遍历叶子节点。
B+树的结构
1、根节点(Root Node)<br>根节点是树的起点,包含指向子节点的指针。根节点可能是叶节点,也可能是内部节点。<br>2、内节点(Internal Nodes)<br>内节点不存储实际数据,它们存储键值,并且有指针指向子节点。内节点用于帮助查找数据。<br>3、叶子节点(Leaf Nodes)<br>叶子节点存储实际的数据或数据的指针(例如,指向数据行的主键值)。所有叶子节点通过链表连接,允许快速的范围查询。<br>4、键值(Key Values)<br>存储在内节点和叶节点中,用于定位数据。键值按照升序排列,确保树的有序性。<br>
B+树的工作原理
1. 插入操作<br>在 B+ 树中插入一个新的键值时,插入操作通常会遵循以下步骤:<br><br>查找插入位置:从根节点开始,依次向下查找插入位置,直到叶子节点。这个过程类似于二分查找,每次都选择一个合适的子树(根据键值判断)。<br>插入键值:在叶子节点中找到插入位置,将新的键值插入。如果叶子节点未满,则直接插入;如果满了,则触发 分裂操作(会把一部分数据移到新节点,并将中间的键值提升到父节点)。<br>分裂和递归:如果叶子节点分裂,新的键值会被传递到父节点。父节点同样可能触发分裂,直到根节点。如果根节点分裂,树的高度增加。<br><br>2. 查找操作<br>B+ 树的查找操作遵循 二分查找 的方式:<br><br>从根节点开始查找:从根节点开始,按照键值选择子节点。<br>查找子树:在每个内节点中,通过键值选择指向下一层节点的指针。<br>到达叶子节点:最终到达叶子节点,找到目标数据。如果数据存在,则返回;如果数据不存在,则返回失败。<br>由于每一层都进行的是二分查找,因此 B+ 树的查找效率是 O(log n),即使数据量非常大,查询速度仍然非常快。<br><br>3. 删除操作<br>删除操作也是从根节点开始,类似于查找操作。删除一个键值时:<br><br>找到键值:从根节点开始查找要删除的键值,直到叶子节点。<br>删除键值:在叶子节点删除目标键值。如果删除操作导致某个节点的键值数量少于最小值(即违反了 B+ 树的平衡条件),则需要触发 节点合并 或 借值操作,将键值从兄弟节点借过来,或者将当前节点与兄弟节点合并。<br>回溯调整:如果某一层的节点发生了合并或借值,可能会递归地影响上层节点,直到根节点。<br>
B+树与B树的区别
数据存储位置:<br>B树:数据可以存储在内节点和叶子节点中。<br>B+树:所有的数据(或指向数据的指针)都存储在叶子节点中,内节点只存储键值。<br><br>范围查询:<br>B树:范围查询较为复杂,需要遍历树的不同部分。<br>B+树:由于叶子节点通过指针形成链表,范围查询非常高效,能够顺序遍历叶子节点。<br><br>树的高度:<br>B树:由于数据和指针的存储位置不同,可能会导致树的高度稍微增加。<br>B+树:因为所有数据都存储在叶子节点,并且叶子节点相连,结构更加简单,通常在查找和范围查询上更高效。<br>
B+树的优势
高效的范围查询:<br>由于叶子节点通过链表连接,B+树非常适合进行范围查询,能够顺序遍历叶子节点,避免重复访问。<br><br>高效的磁盘读取:<br>B+树通常用于磁盘存储,因为它是平衡的,每次查找的深度较浅,从根到叶的路径较短。每个节点可以存储多个子节点,降低了磁盘 I/O 的次数。<br><br>优化的空间利用:<br>叶子节点和内节点都可以高效地利用存储空间,避免了频繁的页面分裂。B+树结构紧凑,节点内的数据项多。<br><br>支持多种类型的查询:<br>B+树不仅支持精确匹配查询,还支持范围查询(例如 BETWEEN)、前缀匹配查询等。<br>
B+树在 MySQL 中的应用
在 MySQL 中,InnoDB 存储引擎 默认使用 B+ 树作为索引结构来组织数据,主要体现在以下两种类型的索引:<br><br>聚簇索引(Clustered Index):<br>聚簇索引是表的 主键索引,数据的存储顺序与索引的顺序一致。InnoDB 的主键索引本质上就是 B+ 树索引,数据存储在叶子节点中,叶子节点直接包含数据行。<br><br>非聚簇索引(Non-clustered Index):<br>非聚簇索引是指除主键之外的索引,它们的叶子节点存储的是 指向数据行的指针(通常是主键的值)。每个非聚簇索引都有自己的 B+ 树结构,但其叶子节点并不存储实际数据,而是存储对主键数据的引用。<br>
总结
B+树 是一种高效的自平衡树结构,广泛应用于数据库索引。它的叶子节点通过链表连接,使得范围查询非常高效。与 B 树相比,B+树有更优的查询性能,尤其是在磁盘 I/O 操作频繁的情况下。MySQL 的 InnoDB 存储引擎 使用 B+树来实现索引,提供了高效的查询、插入、删除和范围查找能力。
回表
回表的基本概念
聚簇索引:在 InnoDB 存储引擎中,表的主键索引(Primary Key)是聚簇索引。数据表的所有数据行都会按照主键索引的顺序存储在磁盘上。换句话说,主键值是数据表记录的 物理存储位置。<br><br>非聚簇索引:非主键索引(Secondary Index)是指在表中除了主键之外的索引。与聚簇索引不同,非聚簇索引的叶子节点不存储实际的数据行,而是存储数据行的 主键值。<br><br>在查询时,如果涉及到非聚簇索引,MySQL 需要首先通过非聚簇索引找到相关的 主键值,然后再去 主键索引(聚簇索引)中查找对应的 数据行。这时,执行的就是回表操作。<br>
回表操作的流程
通过非聚簇索引查找:<br>1、MySQL 会根据查询条件,使用 非聚簇索引 查找符合条件的 索引项。例如,如果查询中使用了非主键列(即索引列)作为条件,MySQL 会先在非聚簇索引中查找符合条件的键值。<br>获取主键值:<br>2、非聚簇索引的叶子节点存储的是数据的 主键值,因此 MySQL 会从非聚簇索引中获取到相应的主键值。<br>回到主键索引中查找数据:<br>3、使用获取到的 主键值,MySQL 会再次通过 聚簇索引 查找数据行。聚簇索引的叶子节点存储的是数据行,因此通过主键值可以找到数据行的实际内容。<br>返回查询结果:<br>4、MySQL 通过回表的方式获取到实际的行数据,并将查询结果返回。
回表的步骤
1、查找非聚簇索引:查询条件 name = 'Alice' 会通过 name 索引查找匹配项,假设找到了主键值 1 和 3。<br>2、回表查询:MySQL 根据主键值 1 和 3 回到聚簇索引中查找对应的完整数据行(如 id=1 的数据行)。<br>3、返回结果:MySQL 最终返回查询结果:符合条件的 name = 'Alice' 的所有记录。
为什么回表会影响性能
回表操作会增加查询的 时间和 I/O,从而影响性能。原因如下:
两次查找:对于使用非聚簇索引的查询,MySQL 需要两次查找:一次在非聚簇索引中查找主键值,另一次通过主键值回到聚簇索引中查找实际数据。如果查询涉及大量数据,回表的性能开销会变得非常大。
增加磁盘 I/O:如果数据表很大,回表操作可能会导致更多的磁盘读取操作。特别是在磁盘存储上,磁盘 I/O 速度通常远低于内存操作,这会导致查询的响应时间变慢。
更多的缓存失效:非聚簇索引和聚簇索引分别有独立的缓存。查询时,可能会导致多个缓存失效,需要多次磁盘读取数据,从而影响性能。
避免回表的优化策略
为了避免回表,MySQL 提供了一些优化方法,使得查询更加高效:<br><br>1. 覆盖索引(Covering Index)<br>覆盖索引是指索引包含了查询所需的所有列,这样就不需要回表。通过覆盖索引,MySQL 可以直接从索引中返回结果,而不需要回到主键索引中查找数据。<br>覆盖索引的例子:<br>假设我们改为查询 id 和 name 列,如果 id 已经是主键,而查询只依赖 name 列,那么索引应该覆盖 id 和 name:<br><br>SELECT id, name FROM employees WHERE name = 'Alice';<br>在这个查询中,索引 name 只需要存储 name 和 id,因此当查询时,MySQL 可以直接在索引中找到 id 和 name,而无需回表。<br><br>2. 合理选择索引<br>对于经常进行的查询,合理地创建 覆盖索引 可以避免回表。如果查询只涉及某些特定列,考虑为这些列创建复合索引,并确保索引能覆盖所有需要查询的字段。<br>例如,如果查询经常基于 name 和 department 查找员工,创建一个包含 name 和 department 的复合索引就可以避免回表:<br><br>CREATE INDEX idx_name_department ON employees(name, department);<br>这样,当查询涉及到 name 和 department 时,MySQL 可以直接从索引中读取到所有需要的字段,而无需回表。<br><br>3. 避免查询不必要的字段<br>尽量避免在查询中涉及非索引列或不必要的字段。如果查询需要的数据都可以通过索引字段获取,回表的需求就能减少或消除。<br>
总结
回表 是当 MySQL 使用 非聚簇索引 进行查询时,索引只存储了 主键值,因此需要根据主键值再去 主键索引 查找实际数据的过程。
回表会增加查询的性能开销,尤其是当查询的数据量较大时,回表操作可能导致较大的 磁盘 I/O 和 时间延迟。
为了避免回表,可以使用 覆盖索引,使得查询的所有数据都包含在索引中,从而直接从索引中返回数据。
通过合理设计索引和优化查询,可以减少回表操作,从而提高查询性能。
覆盖索引
描述
覆盖索引(Covering Index)是指索引包含了查询所需要的所有列,这样查询就可以直接通过索引获得结果,而无需回到表中查找实际数据行,从而提高查询效率。在 MySQL 中,覆盖索引 可以有效避免 回表 操作,减少磁盘 I/O 和提升查询性能
什么是覆盖索引?
覆盖索引是一个 包含查询所需字段的索引,即索引中的所有列都能满足查询的需求。这样,查询就不需要回到主键索引(聚簇索引)中去读取实际数据,而可以直接从索引中获取所需的值。<br><br>覆盖索引的关键特点:<br>索引包含了查询中所有的 SELECT 字段。<br>索引包含了 WHERE 子句中涉及的字段。<br>索引包含了 ORDER BY 和 GROUP BY 子句中涉及的字段(如果有的话)。<br>通过覆盖索引,MySQL 可以只访问索引,而不需要访问表数据,因此可以大幅提高查询性能,减少回表操作。
覆盖索引的工作原理
通常,查询操作会按照以下步骤进行:<br><br>通过索引查找数据:MySQL 根据查询条件,在索引中查找匹配的记录。如果索引包含了所有查询所需的字段,则可以直接从索引中获得查询结果。<br>避免回表操作:如果索引包含了所有需要的数据列,就不再需要去表中查找实际的数据行,从而避免了回表的操作。<br>例如,假设有一个 employees 表,包含 id, name, age 和 department 四个字段,且 id 是主键:<br><br>CREATE TABLE employees (<br> id INT PRIMARY KEY,<br> name VARCHAR(100),<br> age INT,<br> department VARCHAR(100),<br> INDEX(idx_name) -- 为 name 列创建非聚簇索引<br>);<br>如果查询如下:<br><br>SELECT id, name FROM employees WHERE name = 'Alice';<br><br>没有覆盖索引:MySQL 需要先通过 idx_name 索引查找符合条件的 name,然后通过 回表 去主键索引(id)查找实际的 id 数据。<br>有覆盖索引:如果在 idx_name 索引中包含 name 和 id,MySQL 可以直接从索引中得到 id 和 name,无需回表。<br>
什么时候可以使用覆盖索引
覆盖索引的适用场景通常有:<br>1、查询列完全包含在索引中:<br>如果查询中 SELECT 的字段、WHERE 子句的条件、ORDER BY 和 GROUP BY 子句的字段都在索引中,则可以使用覆盖索引。<br>2、查询性能要求高:<br>查询涉及的列较多时,覆盖索引可以显著减少回表的次数,减少磁盘 I/O,提高查询性能。<br>3、简化查询路径:<br>在一些场景下,使用覆盖索引能够将查询路径简化,避免多次索引查找和回表操作,尤其是在大数据量表中,使用覆盖索引可以显著提高查询响应速度。<br>
覆盖索引的例子
假设我们有一个 employees 表,包含如下数据和索引:<br><br>CREATE TABLE employees (<br> id INT PRIMARY KEY, <br> name VARCHAR(100), <br> age INT, <br> department VARCHAR(100),<br> INDEX idx_name_age (name, age)<br>);<br>查询 1:完全使用覆盖索引<br>SELECT name, age FROM employees WHERE name = 'Alice';<br>没有覆盖索引:查询首先会使用 idx_name_age 索引查找 name = 'Alice',然后通过回表去主键索引中查找 name 和 age 对应的数据。<br>有覆盖索引:查询会直接从 idx_name_age 索引中获取到 name 和 age,无需回表。<br><br>查询 2:部分使用覆盖索引<br>SELECT name, department FROM employees WHERE name = 'Alice';<br>没有覆盖索引:查询需要通过 idx_name_age 索引查找 name = 'Alice',然后回表查找 department 字段。<br>有覆盖索引:如果索引 idx_name_age 被修改为 idx_name_department(包含 name 和 department),查询可以直接从索引中获取所需的字段。<br>
覆盖索引的优势
1、避免回表操作:覆盖索引的最大优势是避免回表操作。通常,回表会增加查询的延迟,因为它需要进行两次查找:一次通过索引查找,另一次通过主键索引查找实际数据。通过覆盖索引,查询可以仅通过索引完成,节省了磁盘 I/O。<br>2、减少磁盘 I/O:由于 MySQL 只需要访问索引而非数据表,减少了磁盘读取的次数,特别是在查询大数据量时,覆盖索引能显著提升性能。<br>3、提高查询速度:由于覆盖索引能够提供全部查询所需的数据,无需回到主键索引中查找,能显著提高查询速度,尤其在 大数据表 或 高频查询 中,性能优势更加明显。<br>4、适用于范围查询:覆盖索引不仅适用于精确匹配查询,也适用于范围查询。例如,查询 age 在某个范围内的数据时,覆盖索引可以避免回表,直接从索引中获取数据。
如何创建覆盖索引
为了使查询能够利用覆盖索引,索引中必须包含查询的所有相关字段。可以通过以下几种方式来创建覆盖索引:<br><br>1. 创建单列索引<br>当查询中只涉及到一个字段时,可以创建一个包含该字段的索引。<br><br>CREATE INDEX idx_name ON employees(name);<br>这个索引会覆盖所有仅基于 name 查询的数据。<br><br>2. 创建复合索引<br>如果查询中涉及多个字段,可以创建一个 复合索引,将所有涉及的字段包含在一个索引中。这样索引就可以覆盖查询的所有字段。<br><br>CREATE INDEX idx_name_age_department ON employees(name, age, department);<br>这个索引将能覆盖以下查询:<br><br>SELECT name, age FROM employees WHERE name = 'Alice'; -- 使用 idx_name_age<br>SELECT name, age, department FROM employees WHERE name = 'Alice'; -- 使用 idx_name_age_department<br><br>3. 选择合适的字段顺序<br>在创建复合索引时,需要注意字段的顺序。对于复合索引,索引的效率取决于字段的顺序。例如,查询中 WHERE 子句的条件字段应尽量排在索引的前面。索引是从左到右进行匹配的,前面的字段更能提高索引的使用效率。<br><br>CREATE INDEX idx_name_age_department ON employees(name, age, department);<br>此索引会更加适合以下查询:<br><br>SELECT name, age FROM employees WHERE name = 'Alice' AND age > 30;<br>
覆盖索引的注意事项
1、存储空间:虽然覆盖索引可以提高查询性能,但它需要额外的存储空间,因为它存储了更多的数据列。对于包含很多列的表,覆盖索引可能会增加索引的大小。<br>2、更新成本:当表的列数据发生更新时,覆盖索引的维护成本可能会增加,尤其是当索引覆盖的列较多时。每次更新索引时,MySQL 需要更新索引中的所有字段。<br>3、创建过多索引的风险:虽然覆盖索引能提高查询效率,但过多的索引会导致 写入性能下降(插入、更新和删除操作变慢)。因此,需要根据具体的查询需求来选择合适的索引。
总结
覆盖索引是一个非常有效的优化手段,它能够让查询仅通过索引完成,从而避免回表操作,减少磁盘 I/O,提高查询性能。为了实现覆盖索引,可以通过创建合适的索引,确保索引中包含查询所需的所有字段。虽然覆盖索引有许多优点,但也需要在性能和存储开销之间做好平衡。
建立索引考虑的因素
描述
在 MySQL 中,建立索引是优化查询性能的关键步骤之一。然而,索引的创建需要谨慎考虑,因为它不仅能提高查询速度,还会带来一些额外的存储空间和维护成本。以下是建立索引时需要考虑的几个重要因素:
查询的类型和模式
建立索引时,首先需要分析查询的类型和模式,了解查询的频繁程度和查询的条件。不同的查询模式可能需要不同类型的索引。<br><br>1、SELECT 查询:如果某些列频繁出现在查询的 WHERE 子句、JOIN 子句、ORDER BY 子句、GROUP BY 子句中,这些列通常应该创建索引。<br>2、INSERT/UPDATE/DELETE 操作:尽管索引能够加速查询操作,但每次插入、更新或删除数据时,MySQL 需要维护相关的索引。这会增加写操作的成本。因此,在频繁的写操作场景中,应谨慎创建索引。
选择索引列
索引应该包含查询中 经常用作过滤条件 的列。这些列可以是:<br><br><ul><li>WHERE 子句中的条件列:经常用于过滤数据的列。</li><li>JOIN 条件列:用于连接多个表的列。</li><li>ORDER BY 或 GROUP BY 中的列:用于排序和分组操作的列。</li><li>UNIQUE 列:主键或唯一约束列。</li></ul><br>选择索引列的原则:<br>优先选择 查询频繁使用的列 作为索引列。<br>如果某个列很少用于查询或经常被修改(如频繁更新),不建议为其创建索引。<br>
索引的选择性(Cardinality)
对于高选择性的列,创建索引能显著提高查询效率。
对于低选择性的列(如性别、状态),索引可能不会带来很大性能提升,甚至可能会增加查询成本,因此应谨慎考虑。
复合索引与单列索引
1、复合索引的列顺序非常重要。MySQL 会根据索引的左前缀原则使用复合索引,也就是说,查询条件中的第一个列应该是复合索引中的第一个列,第二个列应该是复合索引中的第二个列,以此类推。<br>2、复合索引适用于 多条件查询,尤其是多个列在查询中同时出现的情况。<br>3、如果查询中的某些列经常单独作为查询条件,也可以为它们创建单列索引。
索引的类型
MySQL 支持不同类型的索引。选择合适的索引类型对于性能至关重要。<br><br>1、B+树索引(默认索引类型):用于大多数场景,适用于等值查找、范围查找、前缀查找等。<br><ul><li>聚簇索引(Clustered Index):主键索引就是聚簇索引,数据行按照主键值的顺序存储在磁盘上。每个表只能有一个聚簇索引。</li><li>非聚簇索引(Non-clustered Index):非主键索引,索引中的叶子节点存储的是指向数据行的指针,而不是数据行本身。</li></ul>2、全文索引(Fulltext Index):用于支持文本数据的高效检索,适用于查找文本字段中包含某些关键词的情况。<br><ol><li>用于 TEXT 或 VARCHAR 类型的字段。</li><li>支持 MATCH ... AGAINST 查询。</li></ol>3、哈希索引(Hash Index):只用于 MEMORY 存储引擎,适用于快速的等值查询,但不支持范围查询。<br>4、空间索引(Spatial Index):用于处理空间数据类型(如 GEOMETRY)的索引。<br><br>建议:<br>默认情况下,使用 B+树索引进行大部分的查询优化。<br>对于全文搜索,考虑使用 全文索引。<br>如果使用的是内存表,并且只做等值查询,可以考虑使用 哈希索引。<br>
索引的维护和更新成本
索引不仅提高了查询性能,也会增加表的维护成本。每次插入、更新或删除数据时,MySQL 都需要更新索引。特别是在大量更新数据的情况下,索引维护的开销可能非常大。<br><ul><li>INSERT 操作:每次插入数据时,索引需要被更新或重新排序。</li><li>UPDATE 操作:如果更新的列包含索引,则索引也需要重新更新。</li></ul><span style="font-size: inherit;">DELETE 操作:删除数据时,相关索引项需要被删除或调整。</span><br style="font-size: inherit;"><span style="font-size: inherit;">建议:</span><br><ul><li>对于更新频繁的表,索引的创建应适当减少,尤其是对于那些需要经常更新的列,避免为这些列创建过多的索引。</li><li>对于经常进行批量更新或删除的表,可以定期对索引进行优化,删除无用索引,或考虑使用更合适的索引类型。</li></ul>
查询优化和执行计划
MySQL 会根据查询语句的结构自动选择最优的索引,但有时需要手动优化查询以确保正确使用索引。使用 EXPLAIN 语句来查看查询执行计划,分析是否使用了索引,或者查询是否因为没有索引而导致全表扫描。<br><ul><li>EXPLAIN:用于查看查询的执行计划,帮助分析索引的使用情况。<br>EXPLAIN SELECT * FROM employees WHERE name = 'Alice';</li></ul><br>
多列索引与单列索引的权衡
在设计索引时,应该权衡单列索引和复合索引的使用。单列索引适用于单独查询某个列的情况,而复合索引适用于多条件查询。通常,复合索引 需要考虑列的顺序,应该把查询中经常出现在 WHERE 子句中的列放在前面。
结论
创建索引时需要综合考虑以下因素:<br><ul><li>查询类型:分析查询的频率、条件列、排序需求等,决定哪些列需要索引。</li><li>选择性:优先为选择性高的列创建索引,低选择性列可能没有太大帮助。</li><li>索引类型:根据数据类型和查询类型选择合适的索引类型(如 B+ 树索引、全文索引等)。</li><li>存储与维护成本:为高频查询创建索引,但要避免为每个列都创建索引,避免过多的索引占用大量存储空间和增加更新成本。</li><li>查询优化:使用 EXPLAIN 查看执行计划,优化查询语句和索引的使用。</li></ul>通过合理的索引设计,可以显著提升 MySQL 查询性能,减少不必要的回表操作,优化系统整体性能。
为什么主键建议使用自增主键
自动生成唯一标识符<br>
自增主键 能够自动为每一条记录生成一个唯一的标识符,避免手动生成主键值带来的复杂性。每插入一条新记录时,MySQL 会自动为该记录分配一个递增的整数值,这确保了主键的唯一性和顺序性。<br><ul><li>简化开发工作:开发人员不需要编写额外的逻辑来生成主键值。</li><li>避免重复值:由于自增是由数据库自动管理的,因此几乎没有可能出现主键重复的问题。</li></ul>
提高查询性能
主键是表的唯一标识符,因此在设计数据库时,主键通常会创建一个索引。使用 自增主键 的好处之一是其值通常是 递增的整数,这种索引的设计有利于数据存储和查询优化。<br><ul><li>B+树索引的性能:MySQL 默认使用 B+ 树作为索引结构,而递增的整数值会导致数据的物理存储按顺序排列。这使得查询时可以快速定位数据,尤其是基于主键的查询(例如,范围查询)会变得非常高效。</li><li>顺序插入:自增主键是顺序递增的,因此新记录总是插入到索引的末尾,避免了频繁的索引重排和页面分裂,提高了性能。</li></ul>
避免人为错误
手动生成主键值容易出现错误,比如重复主键或不规则的主键值。自增主键由数据库管理,能够确保主键的唯一性和按顺序排列,避免了人为干预和错误。
简化数据迁移和备份
在跨表或跨数据库进行数据迁移时,使用自增主键可以避免生成复杂的主键值,确保数据的完整性。例如,迁移过程中,无需担心主键值的冲突,因为自增的主键值在源表和目标表中都不会重复。
避免“全局唯一”生成的复杂性
如果需要使用自定义的、全局唯一的主键(如 UUID),会增加一定的存储开销(UUID 比整数占用更多的存储空间),而且 UUID 不递增,导致索引性能下降。自增主键采用递增的整数,通常比 UUID 更节省空间并且索引更高效。<br><ul><li>存储空间:UUID 是 128 位(16 字节),而整数(INT 类型)仅占 4 字节。</li><li>索引效率:整数型主键(自增主键)相对于 UUID 更加顺序,避免了频繁的索引重排和分裂,因此在查询性能上更有优势。</li></ul>
数据一致性和顺序性
自增主键为每条记录分配的值是按照顺序递增的,这样便于查询时理解数据的插入顺序,或者在某些场景下(如分页查询、记录分析)能有效帮助追踪数据的变化。例如,可以使用主键来表示记录的插入时间顺序,虽然这并不是其本意,但在一些应用场景下非常有用。
与外键的兼容性
在关系型数据库设计中,外键约束是维护数据一致性的重要手段。自增主键可以作为外键引用的目标,简化了表与表之间的关联。由于自增主键值在不同表之间唯一且顺序,外键关系通常能够更好地实现数据完整性和参照完整性。
适合大多数应用场景
对于大多数应用来说,使用自增主键作为唯一标识符是足够且合适的。无论是简单的CRUD应用,还是更复杂的业务逻辑,使用自增主键都能提供足够的性能和一致性。
避免锁竞争和性能瓶颈
在高并发的场景下,如果主键是自增的整数,MySQL 会自动确保主键的递增过程是顺序进行的,而不是随机分配。因此,对于并发插入操作,自增主键能够避免大量的锁竞争。
避免随机性带来的锁竞争:如果主键值是随机的(例如 UUID),则可能导致存储引擎在处理插入操作时频繁发生锁竞争,进而影响性能。
便于与其他系统集成
自增主键广泛被数据库和应用程序使用,几乎所有主流的数据库系统都支持自增主键,因此使用自增主键能使得数据库设计更加标准化、通用化,易于与其他系统进行集成。
总结:自增主键的优势
<ol><li>自动生成唯一标识符,简化开发。</li><li>提高查询性能,尤其是在基于主键的查询中。</li><li>避免人为错误,确保数据一致性。</li><li>简化数据迁移和备份,避免主键冲突。</li><li>节省存储空间和提高索引效率,相比 UUID 等全局唯一标识符更高效。</li><li>便于与外键引用和其他系统集成。</li></ol>
何时避免使用自增主键
虽然自增主键有很多优点,但在某些特殊的场景下,它可能并不是最优选择:<br><ul><li>分布式系统:在分布式系统中,如果需要生成全局唯一的主键(且不依赖于单个数据库实例),使用自增主键可能会遇到瓶颈。可以考虑使用 UUID、Snowflake ID(Twitter 的分布式 ID 生成算法)等方法。</li><li>多主机环境:如果有多个数据库实例,使用自增主键可能会导致主键冲突,特别是在没有合适的主键分配机制时。</li></ul>
总体来说,自增主键 是一种高效、简洁且广泛适用的主键设计方式,适用于大多数场景,尤其是在单机环境或传统关系型数据库设计中。
索引失效的情况
描述
在 MySQL 中,索引的使用能显著提升查询性能,但有时由于某些原因,索引可能无法生效,导致查询回表或全表扫描,进而降低性能。了解索引失效的情况对于优化查询至关重要。以下是一些常见的索引失效的情况:
使用了 OR 条件
当查询条件中涉及 OR 时,索引的使用可能会失效。尤其是当 OR 的两个条件中至少有一个不能使用索引时,MySQL 会放弃索引,改为全表扫描。<br>解决方法:<br><ul><li>在 OR 的每一项条件上都建立合适的索引。</li><li>使用 UNION 替代 OR,这样可以为每个查询单独使用索引。</li></ul>
函数或表达式中的列
当在查询条件中使用函数、计算或表达式时,索引通常会失效,因为这些操作会改变列的值,使得 MySQL 无法直接利用索引。<br>解决方法:<br><ul><li>避免在查询中使用函数或计算表达式。如果可能,可以将计算移到查询外部,或使用 生成列(generated column)来存储计算结果,并对该列建立索引。</li></ul>
模糊查询(LIKE)开头有通配符
LIKE 查询在匹配模式时,特别是当通配符 % 出现在查询模式的开头时,通常会导致索引失效,因为这种模式匹配无法通过索引优化。<br>解决方法:<br><ul><li>如果可能,避免使用前缀通配符,或者使用全文索引(FULLTEXT)来优化搜索。</li><li>对于特定的场景,可以考虑反转字符串的存储和查询,或者利用外部工具如 Elasticsearch 来支持高效的模糊查询。</li></ul>
IS NULL 或 IS NOT NULL
使用 IS NULL 或 IS NOT NULL 时,如果查询列没有 NULL 值的索引,索引可能会失效。即使列有索引,也可能无法利用该索引来优化查询。<br>解决方法:<br><ul><li>在需要频繁查找 NULL 值的列上创建 IS NULL 索引。</li></ul>
多列索引列的顺序不匹配
多列索引(复合索引)只会对索引的 前缀列 起作用,查询中使用的列必须从索引的最左边开始匹配。如果查询中的条件列的顺序与复合索引的列顺序不一致,MySQL 可能不会使用索引。<br><br>例子:<br>CREATE INDEX idx_name_age ON employees(name, age);<br>查询:SELECT * FROM employees WHERE age = 30 AND name = 'Alice';<br>在这个查询中,虽然 age 和 name 都出现在索引中,但由于复合索引的顺序是 (name, age),MySQL 可能无法使用该索引来优化查询。<br><br>解决方法:<br><ul><li>复合索引的列顺序要与查询中的 WHERE 子句一致,尽量让查询中的条件从索引的左边开始匹配。</li><li>如果查询经常使用不同的列顺序,考虑创建多个复合索引。</li></ul>
索引列的类型不匹配
如果查询中的条件列与索引列的类型不匹配,索引可能会失效。例如,查询条件使用了不同的字符集或数据类型不兼容,MySQL 可能会强制转换数据类型,导致索引无法使用。<br><br>例子:<br>SELECT * FROM employees WHERE age = '30';<br>如果 age 列是整数类型,查询条件中的 '30' 被当作字符串处理,这可能导致索引失效。<br>解决方法:<br><ul><li>确保查询中的条件类型与列的实际数据类型一致,避免隐式类型转换。</li></ul>
使用 DISTINCT 或 ORDER BY 与索引不匹配
在某些情况下,使用 DISTINCT 或 ORDER BY 时,MySQL 可能无法完全利用索引,特别是当 DISTINCT 或 ORDER BY 中的列与索引列不完全匹配时。<br><br>例子:<br>SELECT DISTINCT name FROM employees ORDER BY age;<br>在这个例子中,索引是根据 name 列创建的,但是 ORDER BY age 列并不与索引匹配,MySQL 可能会放弃使用 name 上的索引,而导致全表扫描。<br><br>解决方法:<br><ul><li>确保 ORDER BY 和 DISTINCT 中的列能与索引匹配,或者考虑创建复合索引。</li></ul>
使用了 LIMIT 和不合适的索引
在使用 LIMIT 限制结果的数量时,如果查询中没有适当的索引,MySQL 可能仍会执行全表扫描,无法利用索引优化查询。<br><br>例子:<br>SELECT * FROM employees ORDER BY name LIMIT 10;<br>如果查询的 name 列没有索引,ORDER BY 会导致全表扫描。<br><br>解决方法:<br><ul><li>确保 ORDER BY 使用的列有索引,特别是对于排序条件的列,索引的存在可以加速排序和限制结果的操作。</li></ul>
表的 LOCK 或 TRANSACTION 锁定
在高并发的环境中,如果对表进行锁定(如 LOCK IN SHARE MODE 或 FOR UPDATE),查询可能会因为锁的原因而导致索引失效。<br><br>例子:<br>SELECT * FROM employees WHERE name = 'Alice' FOR UPDATE;<br>如果表在事务中被锁定,可能会影响索引的使用,导致性能问题。<br><br>解决方法:<br><ul><li>在事务中要合理控制锁的粒度,尽量避免长时间锁住整个表。</li></ul>
表的统计信息过期或不准确
MySQL 在执行查询时依赖表的统计信息来决定是否使用索引。如果表的统计信息过期或不准确,查询优化器可能会做出错误的决策,导致索引失效。<br><br>解决方法:<br><ul><li>定期更新表的统计信息,特别是在大量数据插入、更新或删除之后,可以使用 ANALYZE TABLE 来更新统计信息。</li><li>ANALYZE TABLE employees;</li></ul>
总结
索引失效的常见原因包括:<br><ol><li>使用 OR 条件。</li><li>查询中使用了函数或表达式。</li><li>LIKE 查询的模式以 % 开头。</li><li>使用 IS NULL 或 IS NOT NULL。</li><li>多列索引的列顺序不匹配。</li><li>查询条件与索引列类型不匹配。</li><li>使用 DISTINCT 或 ORDER BY 与索引不匹配。</li><li>LIMIT 查询中没有合适的索引。</li><li>表的锁或事务影响索引使用。</li><li>表的统计信息不准确。</li></ol>
in和or会使用索引吗
描述
在 MySQL 中,IN 和 OR 都是常见的逻辑操作符,它们在查询条件中使用时,索引的使用情况有一些差异。具体是否会使用索引,取决于查询的结构、索引的设计、数据的分布等因素。我们来分别讨论 IN 和 OR 在不同场景下是否会使用索引。
IN 操作符与索引
IN 用于多个值的匹配,它的行为类似于多个 OR 条件的组合。在某些情况下,MySQL 会使用索引来优化 IN 操作,但前提是列上有适当的索引。<br><br>1.1 基本使用<br>如果在查询中使用 IN 操作符,且相关列上有索引,MySQL 可以利用该索引来加速查询。<br><br>例子:<br>SELECT * FROM employees WHERE department_id IN (1, 2, 3);<br><ul><li>在上述查询中,如果 department_id 列上有索引,MySQL 会使用该索引来快速查找值为 1, 2, 或 3 的记录。这是因为 IN 操作符可以被转换为一系列的 OR 操作,MySQL 会尝试为每个条件值使用索引,从而避免全表扫描。</li></ul><br>1.2 多个 IN 列<br>如果查询中有多个列使用 IN 操作符,MySQL 会尝试使用复合索引来优化查询。如果没有合适的复合索引,MySQL 可能会选择使用单列索引或者放弃索引。<br><br>例子:<br>SELECT * FROM employees WHERE department_id IN (1, 2) AND status IN ('active', 'inactive');<br><ul><li>如果 department_id 和 status 列都有索引,并且查询条件的列顺序与索引一致,MySQL 可能会选择一个复合索引来加速查询。</li></ul><br>1.3 使用 IN 时的注意事项<br><ul><li>IN 可以包含多达数百个值,但过多的值可能会导致性能问题,特别是在查询时 MySQL 需要在大量的值中查找匹配项。</li><li>对于大量值的 IN 查询,最好使用临时表来存储这些值,并通过联接(JOIN)来查询。</li></ul>
OR 操作符与索引
OR 用于多个条件的选择。在 MySQL 中,OR 的索引使用通常较为复杂,它的行为依赖于以下几点:<br><br>2.1 多个条件涉及索引列<br>当 OR 中的多个条件涉及索引列时,MySQL 可以使用这些索引,但它的优化方式和 IN 不完全一样。<br><br>例子:<br>SELECT * FROM employees WHERE department_id = 1 OR department_id = 2;<br>如果 department_id 列上有索引,MySQL 会尝试使用该索引。实际上,MySQL 会为 OR 的每个条件独立使用索引,然后将结果合并(通常是通过排序合并)。这种方法通常会比全表扫描更有效,但比简单的单一索引查询要差一些。<br><br>2.2 OR 与非索引列<br>如果 OR 中包含一个或多个没有索引的列,MySQL 可能会放弃索引,转而进行全表扫描。<br><br>例子:<br>SELECT * FROM employees WHERE department_id = 1 OR name = 'Alice';<br>如果 department_id 列有索引,但 name 列没有索引,MySQL 可能会决定对 department_id = 1 使用索引,但对 name = 'Alice' 进行全表扫描。这会导致查询性能降低,因为索引的作用并不显著。<br><br>2.3 OR 中包含 NULL 或 IS NULL<br>在某些情况下,OR 中的 NULL 或 IS NULL 会导致索引失效,特别是如果该列没有为 NULL 值建立专门的索引。<br><br>例子:<br>SELECT * FROM employees WHERE department_id = 1 OR department_id IS NULL;<br>如果 department_id 列没有为 NULL 值创建索引,MySQL 可能会放弃使用索引,转而进行全表扫描。<br><br>2.4 多个 OR 条件的性能问题<br>使用 OR 时,MySQL 会在每个条件上使用索引,并将结果合并。虽然这种方法能利用索引,但在某些复杂查询中,这可能会导致性能问题。特别是当 OR 中的条件较多,或者其中一个条件的选择性很低时,索引可能不会带来显著的性能提升。<br>
IN 和 OR 对比
<ul><li>IN 操作符:通常情况下,IN 比多个 OR 更高效,因为它在处理多个值时,本质上是一次性比较所有条件。IN 对于索引的使用更为直接和高效。</li><li>OR 操作符:在多个条件中,OR 可以利用索引,但在涉及多个条件时,MySQL 可能会依次使用每个条件的索引,然后合并结果。性能比 IN 稍差,尤其是在存在多个索引时。</li></ul>
索引优化建议
<ul><li>避免 OR 中的多个条件:尽可能避免使用多个 OR 条件,尤其是当条件中涉及不同的列或索引时。可以考虑使用 UNION 来代替 OR,这样每个查询都可以单独使用索引。<br>例子:<br>SELECT * FROM employees WHERE department_id = 1<br>UNION<br>SELECT * FROM employees WHERE department_id = 2;</li><li>为 IN 中的列建立索引:如果 IN 用于查找多个值,确保 IN 中涉及的列有索引,这样查询能有效利用索引进行优化。</li><li>避免使用 OR 与没有索引的列:尽量避免在 OR 中使用没有索引的列,特别是在数据量较大的情况下,可能会导致性能大幅下降。</li><li>优化 OR 查询的顺序:如果 OR 中的条件中有索引列和非索引列,尽量把索引列放在前面,以减少不必要的全表扫描。</li></ul>
总结
<ul><li>IN 操作符:通常会利用索引,尤其是当查询条件中的列上有索引时。IN 比多个 OR 更高效,特别是在涉及多个值时。</li><li>OR 操作符:如果 OR 中涉及索引列,MySQL 会尝试使用索引,但在某些情况下,索引的使用效果较差,尤其是当多个条件不匹配索引时,可能会导致全表扫描。</li></ul>
为了确保索引的有效利用,设计查询时应该尽量避免复杂的 OR 条件和过多的函数或表达式,合理选择合适的索引来优化查询性能。
事务
四大特性
隔离级别
多个事务同时执行可能出现的问题
脏写
脏读
不可重复度
幻读
读已提交
读未提交
可重复读
串行化
spring事务设置mysql隔离级别
mvcc
undolog版本链
每条数据其实都有两个隐藏字段,一个是trxid,一个是roll_pointer,这个trxid就是这条数据最近一个更新的事务id,,这个roll_pointer就是指向更新这个事务之前生成的undo_log<br>
<br>
readview
执行一个事务的时候,就会生成一个readview
内容
m_ids<br>
此时有哪些事务在mysql里面执行还没有提交
min_trxid<br>
mids里面最小的值
max_trxid<br>
mysql下一个事务要生成的事务id,当前最大事务id
creator_trxid<br>
这个事务的id<br>
rc隔离级别每次查询都会生成一个readview
rr隔离级别只会在第一次查询的时候生成一个readview
锁
描述
MySQL 锁是保证数据库事务一致性、并发性和隔离性的关键机制。锁的使用可以防止多个事务对同一数据进行并发访问时发生冲突或导致数据不一致。
MySQL 锁的基本概念
锁可以分为 表级锁 和 行级锁,以及 共享锁 和 排他锁 等类型。锁的主要作用是限制并发访问数据的方式,以保证数据一致性、完整性,并且避免出现脏读、不可重复读和幻读等问题。
表级锁(Table Locks)
表级锁是 MySQL 中最简单的一种锁类型,它锁住整个表,避免其他事务对该表的操作。表级锁有以下几种:<br><br>共享锁(S 锁,Shared Lock):<br><ul><li>用途:允许事务读取数据,但不允许其他事务修改数据。</li><li>操作:当一个事务持有共享锁时,其他事务也可以对该数据加共享锁,但不能加排他锁,保证了数据的安全读取。</li></ul>例子:<br>SELECT * FROM employees WHERE department_id = 1 LOCK IN SHARE MODE;<br><br>排他锁(X 锁,Exclusive Lock):<br><ul><li>用途:排他锁会锁住数据,阻止其他事务对该数据进行任何操作(包括读取和修改)。</li><li>操作:当事务持有排他锁时,其他事务不能对该行数据加任何类型的锁,直到当前事务释放该锁。</li></ul>例子:<br>SELECT * FROM employees WHERE department_id = 1 FOR UPDATE;<br>排他锁常用于 UPDATE、DELETE 或 SELECT ... FOR UPDATE 中,它确保在事务执行时,数据不会被其他事务修改。<br>
行级锁(Row Locks)
行级锁是 MySQL 在 InnoDB 存储引擎中使用的锁类型,它只会锁住特定的行,而不是整张表。这种锁的粒度较细,能够实现更高的并发访问。<br><br>行级锁优点:<br><ul><li>提高并发性:行级锁允许多个事务同时对同一表的不同记录进行操作,减少锁竞争,提高并发性能。</li></ul><span style="font-size: inherit;">行级锁的实现:</span><br><ul><li>范围锁:行级锁不仅锁定当前行,还会锁定满足条件的其它行,通常是通过条件范围来锁定。例如,使用 WHERE 子句时,会锁定匹配的行。</li><li>间隙锁(Gap Lock):为了避免出现幻读,InnoDB 会在某些情况下锁定记录之间的间隙。</li></ul>例子:<br>SELECT * FROM employees WHERE department_id = 1 FOR UPDATE;
意向锁(Intention Locks)
意向锁是 InnoDB 存储引擎的一种特殊锁,它并不直接锁定数据,而是表示当前事务对某些数据的锁定意图。意向锁主要用来解决表级锁和行级锁之间的冲突问题。<br><ul><li>意向共享锁(IS 锁):事务打算对某些行加共享锁时,会先加意向共享锁。</li><li>意向排他锁(IX 锁):事务打算对某些行加排他锁时,会先加意向排他锁。</li></ul>意向锁可以有效地判断事务是否需要对表进行更高级的锁操作,从而避免了表级锁与行级锁之间的冲突。
死锁(Deadlock)
死锁发生在两个或多个事务相互持有对方需要的资源锁,并且都在等待对方释放锁。死锁是并发系统中的常见问题,MySQL 通过死锁检测机制自动处理死锁,它会回滚某个事务来打破死锁。
InnoDB 存储引擎中的锁
InnoDB 存储引擎支持行级锁、表级锁、意向锁,并且使用多版本并发控制(MVCC)来实现高并发的事务隔离。<br><ul><li>MVCC(多版本并发控制):每次事务都会创建数据的一个版本,这样读取操作不会被写入操作阻塞,避免了读写冲突。每个事务只会看到它自己的数据版本,直到提交或回滚为止。</li></ul>
InnoDB 锁的类型
InnoDB 中的锁分为以下几种:<br><ul><li>共享锁(S 锁):允许事务读取数据,但不允许修改数据。</li><li>排他锁(X 锁):允许事务读取和修改数据,其他事务不能再读取或修改被锁定的数据。</li><li>意向锁(IS、IX):表示对行的锁定意图,确保能够有效使用表级锁与行级锁。</li></ul>
InnoDB 锁的兼容性
<ul><li>共享锁与共享锁:兼容,多个事务可以同时对相同的数据加共享锁。</li><li>共享锁与排他锁:不兼容,一个事务加了共享锁,另一个事务不能加排他锁,反之亦然。</li><li>排他锁与排他锁:不兼容,多个事务不能同时加排他锁。</li><li>意向锁与共享锁或排他锁:兼容,可以同时存在。</li></ul>
MySQL 锁的隔离级别
MySQL 支持四种事务隔离级别,不同的隔离级别会对锁的使用方式产生影响。
读未提交(READ UNCOMMITTED):
<ul><li>事务可以读取其他事务未提交的数据(脏读)。</li><li>锁的使用较少,性能较高,但数据一致性较差。</li></ul>
读已提交(READ COMMITTED):
<ul><li>事务只能读取其他事务已提交的数据。</li><li>锁的使用仍然有限,但避免了脏读。</li></ul>
可重复读(REPEATABLE READ):
<ul><li>事务在执行过程中,读取的数据在整个事务中始终保持一致。</li><li>锁的使用较为严格,可以避免脏读和不可重复读。</li></ul>
串行化(SERIALIZABLE):
<ul><li>事务之间完全隔离,强制执行顺序,避免所有并发问题(包括幻读)。</li><li>性能最低,但保证数据一致性。</li></ul>
锁的冲突和优化
描述
锁冲突是指当多个事务尝试访问相同的数据时,发生的竞争情况,导致性能下降。锁冲突的原因主要有:<br><ul><li>锁粒度过大:表级锁比行级锁的粒度大,容易导致锁竞争。</li><li>长时间持有锁:事务持锁时间过长,可能会导致其他事务等待,增加锁冲突的概率。</li></ul>
避免锁冲突的策略
<ul><li>使用合适的隔离级别:根据实际需求选择合适的事务隔离级别,避免过高的隔离级别带来不必要的性能开销。</li><li>分批操作:对于大量数据的插入、更新或删除,尽量分批处理,以减少每个事务的持续时间。</li><li>避免长时间持有锁:减少事务的执行时间,及时释放锁。</li><li>使用索引:合理使用索引,提高查询效率,减少锁的持有时间。</li></ul>
避免死锁
<ul><li>保持一致的锁定顺序:确保所有事务按照相同的顺序获取锁,避免死锁。</li><li>较短的事务:尽量缩短事务执行时间,减少锁冲突的机会。</li><li>死锁检测与回滚:MySQL 的 InnoDB 引擎会自动检测死锁,并回滚其中一个事务以打破死锁。</li></ul>
MySQL 锁的管理
MySQL 提供了一些工具和命令,用于查看当前的锁信息以及调试锁相关问题。<br><br><ul><li>查看当前的锁:<br>SHOW ENGINE INNODB STATUS;<br>这个命令返回 InnoDB 存储引擎的状态信息,包括当前锁的情况、死锁信息等。</li></ul><br><ul><li>查看当前事务的锁:<br>SHOW OPEN TABLES WHERE In_use > 0;<br>这个命令返回当前被锁定的表和索引。</li></ul>
总结
MySQL 中的锁机制非常复杂,它支持多种类型的锁,包括表级锁、行级锁、意向锁等,并且通过不同的隔离级别和 MVCC 来保证事务
调优
硬件资源优化
1.1 CPU<br><ul><li>多核 CPU:MySQL 可以在多核 CPU 上并行执行查询任务,因此,增加 CPU 核心数有助于提高并发查询的处理能力。高主频的 CPU 对于单线程性能要求高的查询也有帮助,尤其是在处理复杂查询时。</li><li>CPU 限制:可以通过 max_connections 限制最大连接数,避免过多的并发连接占用 CPU 资源。</li></ul><br>1.2 内存<br><ul><li>内存大小:增加内存可以有效地提高数据库性能,尤其是对缓存(如 InnoDB Buffer Pool)和查询处理的优化有很大帮助。</li></ul><span style="font-size: inherit;">配置建议:</span><br style="font-size: inherit;"><ul><li><span style="font-size: inherit;">InnoDB Buffer Pool:InnoDB 是 MySQL 的默认存储引擎,innodb_buffer_pool_size 配置项控制 InnoDB 缓存池的大小。通常,建议将其设置为系统总内存的 60%-80%,这样可以确保大多数数据和索引都能放入内存中,从而减少磁盘 I/O。</span></li><li><span style="font-size: inherit;">Query Cache:对于频繁执行的相同查询,MySQL 提供查询缓存功能,配置 query_cache_size 来增加查询缓存。</span></li></ul><br>1.3 磁盘 I/O<br><ul><li>磁盘性能:磁盘的读写速度直接影响到 MySQL 的性能,尤其是涉及大量数据的操作时,磁盘性能至关重要。使用固态硬盘(SSD)比机械硬盘(HDD)能显著提高磁盘 I/O 性能。</li></ul>配置建议:<br><ul><li>InnoDB 日志文件大小:innodb_log_file_size 配置项设置每个日志文件的大小,较大的日志文件可以减少磁盘 I/O 操作,但会占用更多的内存和磁盘空间。</li><li>RAID 阵列:使用 RAID 10 而不是 RAID 5,可以提高磁盘 I/O 的吞吐量和可靠性。</li></ul>
MySQL 配置调优
2.1 InnoDB 配置<br><ul><li>innodb_buffer_pool_size:</li></ul>说明:这个参数决定了 InnoDB 存储引擎缓存数据和索引的内存大小。对于高负载的数据库,建议将其设置为系统总内存的 60%-80%。<br>配置示例:<br>innodb_buffer_pool_size = 16G<br><br><ul><li>innodb_log_file_size:</li></ul>说明:决定了每个 InnoDB 日志文件的大小。较大的日志文件能减少日志刷新频率,提升写入性能。<br>配置示例:<br>innodb_log_file_size = 512M<br><br><ul><li>innodb_flush_log_at_trx_commit:</li></ul>说明:控制事务提交时日志刷新到磁盘的策略。设置为 1 最安全,保证每次事务提交都会将日志写入磁盘。设置为 2 或 0 可以提高性能,但在断电时可能会丢失事务数据。<br>配置示例:<br>innodb_flush_log_at_trx_commit = 2<br><br><ul><li>innodb_flush_method:</li></ul>说明:设置 InnoDB 刷新数据的方式。通常可以设置为 O_DIRECT,以避免操作系统缓存带来的性能问题。<br>配置示例:<br>innodb_flush_method = O_DIRECT<br><br><ul><li>innodb_file_per_table:</li></ul>说明:启用该配置后,每个 InnoDB 表会有一个独立的表空间文件,这样有助于提高 I/O 性能并减少表碎片。<br>配置示例:<br>innodb_file_per_table = 1<br><br>2.2 查询缓存配置<br><ul><li>query_cache_size:</li></ul>说明:查询缓存可以缓存 SELECT 查询的结果,对于频繁执行相同查询的场景,查询缓存能显著提高性能。<br>配置示例:<br>query_cache_size = 128M<br><br><ul><li><span style="font-size: inherit;">query_cache_type:</span></li></ul>说明:控制查询缓存的启用状态。可以设置为 ON、OFF 或 DEMAND(仅对显式 SQL_CACHE 查询生效)。<br>配置示例:<br>query_cache_type = ON<br><br>2.3 连接和线程配置<br><ul><li>max_connections:</li></ul>说明:设置 MySQL 数据库最大连接数。如果系统有大量并发连接需求,可以适当调大此值。<br>配置示例:<br>max_connections = 500<br><br><ul><li>thread_cache_size:</li></ul>说明:控制线程缓存的大小,增大该值可以减少频繁创建和销毁线程的开销。<br>配置示例:<br>thread_cache_size = 50<br><br><ul><li>wait_timeout 和 interactive_timeout:</li></ul>说明:控制连接空闲时的等待时间。可以根据实际情况设置适当的超时时间。<br>配置示例:<br>wait_timeout = 300<br>interactive_timeout = 300<br>
查询优化
索引优化
创建适当的索引:<br><ul><li>MySQL 查询的性能大多依赖于索引的使用。合理的索引设计能够显著提高查询性能。</li><li>B+ 树索引:适用于范围查询、排序等操作。</li><li>全文索引:适用于文本搜索操作。</li><li>复合索引:多个列的索引,可以提高涉及多个条件的查询效率。</li><li>避免过度索引:过多的索引会影响写操作的性能,因此只为常用的查询添加索引。</li></ul>
查询语句优化
<ul><li>**避免使用 SELECT ***:只查询所需的列,减少不必要的数据传输。</li><li>优化 WHERE 子句中的条件顺序:将最具选择性的条件放在前面,减少查询扫描的行数。</li><li>避免在 WHERE 子句中使用函数:函数会导致索引失效。</li><li>避免大范围的 JOIN 操作:在查询时,尽量避免多表连接时的笛卡尔积,保证连接条件有索引支持。</li></ul><br>例子:=<br>SELECT id, name FROM employees WHERE department_id = 1;
EXPLAIN 分析查询
使用 EXPLAIN 关键字来分析查询计划,查看查询是否利用了索引。<br><br>例子:<br>EXPLAIN SELECT id, name FROM employees WHERE department_id = 1;<br>通过 EXPLAIN 可以查看查询执行计划,帮助我们理解查询是如何执行的,并决定是否需要增加索引或修改查询。
避免锁争用
<ul><li>使用合适的隔离级别,避免不必要的锁竞争。</li><li>尽量缩短事务的执行时间,减少事务持锁时间。</li></ul>
监控和性能分析
启用慢查询日志可以帮助识别执行时间过长的查询,进而进行优化。<br><br>配置示例:<br>slow_query_log = 1<br>slow_query_log_file = /var/log/mysql/mysql-slow.log<br>long_query_time = 2<br>这样可以记录执行时间超过 2 秒的查询。
性能模式
MySQL 提供了 performance_schema,可以用来跟踪系统的运行情况,提供详细的性能数据。<br><br>SELECT * FROM performance_schema.events_statements_summary_by_digest;
查看当前状态
可以使用 SHOW STATUS 查看数据库的状态信息,判断是否存在瓶颈。<br><br>例子:<br>SHOW STATUS LIKE 'Innodb_buffer_pool%';
总结
MySQL 调优是一个系统化的过程,需要结合硬件资源、MySQL 配置、查询优化和索引设计等多个方面。要保证数据库的高性能,需要根据具体应用的需求和负载特征来进行细致的配置和优化,同时定期监控数据库状态,发现潜在的瓶颈和问题。<br><br>调优的核心目标是:<br><ul><li>提升查询性能:优化查询执行</li></ul>
引擎
InnoDB
1.1 概述<br>InnoDB 是 MySQL 的默认存储引擎,具有事务支持、行级锁、外键支持等高级功能,适用于大多数需要事务处理的应用场景,尤其是OLTP(在线事务处理)系统。<br><br>1.2 特点<br><ul><li>事务支持(ACID):InnoDB 支持事务,符合 ACID 原则(原子性、一致性、隔离性、持久性)。</li><li>行级锁:InnoDB 使用行级锁而非表级锁,能够提高高并发情况下的性能。</li><li>外键支持:InnoDB 支持外键约束,保证数据的一致性和完整性。</li><li>支持崩溃恢复:InnoDB 使用了写前日志(WAL,Write-Ahead Log)机制,可以在数据库崩溃后通过日志文件恢复数据。</li><li>MVCC(多版本并发控制):InnoDB 通过使用多版本并发控制(MVCC)来支持高并发读操作,而不阻塞写操作。</li><li>支持全文索引:InnoDB 支持全文索引,可以加速文本搜索。</li></ul>1.3 适用场景<br><ul><li>高并发写操作</li><li>需要事务支持的应用</li><li>数据完整性和一致性要求高的场景</li><li>需要支持外键约束的场景</li></ul>1.4 性能和配置<br><ul><li>缓冲池(InnoDB Buffer Pool):innodb_buffer_pool_size 是 InnoDB 的关键配置,它决定了内存中能缓存多少数据。通常,建议将其设置为系统内存的 60%-80%,以减少磁盘 I/O。</li><li>日志配置:innodb_log_file_size 和 innodb_log_buffer_size 控制 InnoDB 的日志文件大小和日志缓冲区大小,合理配置这些参数可以提高写入性能。</li></ul>
MyISAM
2.1 概述<br>MyISAM 是 MySQL 早期的默认存储引擎,适用于读取密集型应用,提供快速的查询响应,但不支持事务和外键。它对简单查询的性能较好,但不适合高并发写入的应用。<br><br>2.2 特点<br><ul><li>不支持事务:MyISAM 不支持事务处理,不符合 ACID 原则,数据一旦写入无法回滚。</li><li>表级锁:MyISAM 使用表级锁,这在高并发写操作时可能导致性能瓶颈。</li><li>较高的查询性能:对于读取密集型的应用,MyISAM 提供了比 InnoDB 更好的查询性能,尤其是在简单的 SELECT 查询上。</li><li>不支持外键:MyISAM 不支持外键约束,数据完整性和一致性不如 InnoDB。</li><li>压缩表:MyISAM 支持表压缩,可以节省存储空间,适用于存储大量数据且读取频繁的应用。</li></ul>2.3 适用场景<br><ul><li>主要以查询为主,写入较少的应用(如日志分析系统、报表系统)</li><li>存储大量只读数据的场景</li><li>需要压缩表以节省存储空间的场景</li></ul>2.4 性能和配置<br><ul><li>索引缓存(Key Cache):key_buffer_size 配置项决定了 MyISAM 使用的内存大小来缓存索引数据。设置合适的 key_buffer_size 能提高查询性能。</li><li>表压缩:MyISAM 提供表压缩功能,可以显著减少磁盘空间的占用,适用于大数据量但查询为主的场景。</li></ul>
MEMORY 存储引擎
3.1 概述<br>MEMORY 存储引擎(也叫 HEAP 引擎)是一个将数据存储在内存中的引擎,适用于需要快速访问的临时表或者会话级别的数据存储。它的性能极高,但数据在服务器重启后会丢失。<br><br>3.2 特点<br><ul><li>数据存储在内存中:所有数据存储在内存中,极大地提高了访问速度。</li><li>无持久化存储:数据不会保存在磁盘上,因此 MySQL 重启后数据会丢失。</li><li>适用于临时数据:适用于快速存取、临时存储的场景,比如缓存、临时计算结果等。</li><li>表级锁:类似 MyISAM,MEMORY 使用表级锁,不支持行级锁。</li></ul>3.3 适用场景<br><ul><li>临时表存储</li><li>缓存数据存储</li><li>需要高速访问的会话数据存储</li></ul>3.4 性能和配置<br><ul><li>数据类型限制:MEMORY 引擎只能使用定长数据类型(如 CHAR、INT 等),不支持变长数据类型(如 TEXT、BLOB)。</li><li>大小限制:max_heap_table_size 控制最大内存表的大小,tmp_table_size 控制临时表的大小。</li></ul>
CSV 存储引擎
4.1 概述<br>CSV 存储引擎将每个表的数据存储为一个 CSV 格式的文件,适用于将数据导出或导入到其他系统的场景。它是一个只支持简单查询的存储引擎,不支持索引。<br><br>4.2 特点<br><ul><li>数据以 CSV 格式存储:表数据以纯文本格式存储,可以轻松导入导出。</li><li>不支持索引:查询性能较低,不适合大数据量的查询操作。</li><li>适合数据交换:用于与其他系统之间进行数据交换,导入导出操作方便。</li></ul>4.3 适用场景<br><ul><li>数据导入导出</li><li>简单的文件存储系统</li><li>小规模数据的读取和写入</li></ul>4.4 性能和配置<br><ul><li>CSV 文件的处理:查询不支持索引,因此性能通常比其他存储引擎差,适用于小规模数据的存储。</li></ul>
NDB 存储引擎(Cluster 存储引擎)
5.1 概述<br>NDB 存储引擎是 MySQL Cluster 的一部分,专为高可用性、高并发和分布式架构设计。它提供了一个分布式的、高可用的数据库集群架构,适用于需要高可用性和高并发的大型在线应用。<br><br>5.2 特点<br><ul><li>分布式架构:NDB 以分布式方式存储数据,可以跨多台机器进行数据存储。</li><li>高可用性:提供自动故障转移和数据复制,保证系统的高可用性。</li><li>事务支持:支持事务和 ACID 原则。</li><li>内存存储:NDB 将数据存储在内存中,提供非常高的访问速度。</li></ul>5.3 适用场景<br><ul><li>分布式数据库系统</li><li>高可用性、高并发、大规模的数据存储</li><li>实时应用,如电信行业、在线游戏、在线金融等</li></ul>5.4 性能和配置<br><ul><li>分布式数据:配置 ndb_cluster,可以让多个节点协同工作以处理大规模数据。</li><li>内存优化:大量使用内存以确保快速的数据存取和查询。</li></ul>
其他存储引擎
<ul><li>TokuDB:适用于大规模数据写入的场景,特别是在需要高性能插入和更新操作时,TokuDB 使用 Fractal Tree 索引结构提供更好的性能。</li><li>Aria:MySQL 5.5 引入的存储引擎,旨在替代 MyISAM,提供更高的可靠性和性能,支持事务、行级锁等。</li></ul>
选择存储引擎的考虑因素
在选择存储引擎时,需要考虑以下因素:<br><ul><li>事务支持:是否需要事务支持,是否需要 ACID 特性。</li><li>性能需求:是否需要高并发读写,是否需要支持行级锁。</li><li>数据一致性:是否需要外键支持,是否需要高可用性</li></ul>
oracle
PostgreSQL
hive
HBASE
core Java
类与对象的关系
类(Class)
类是 Java 中的一个蓝图或模板,用于定义对象的属性(字段)和行为(方法)。类不占用内存,它只是一个概念或框架,表示对象的共性特征和行为。类的定义通常包含:<br><br><ul><li>字段:定义类的状态(数据成员),通常是变量。</li><li>方法:定义类的行为(功能),即类能够执行的操作。</li><li>构造方法:用于创建类的实例,并初始化对象的字段。</li><li>静态成员:包括静态字段和静态方法,它们属于类本身,而不是某个具体的对象。</li></ul><br>类的定义:类的定义是通过 class 关键字来实现的。类的名称应遵循 Java 的命名规则,通常首字母大写,采用驼峰命名法。<br><br>public class Person {<br> // 字段(属性)<br> String name;<br> int age;<br><br> // 构造方法<br> public Person(String name, int age) {<br> this.name = name;<br> this.age = age;<br> }<br><br> // 方法(行为)<br> public void greet() {<br> System.out.println("Hello, my name is " + name);<br> }<br>}<br>在上面的代码中,Person 类有两个字段:name 和 age,一个构造方法用于初始化这些字段,一个方法 greet 用来表示类的行为。<br>
对象(Object)
对象是类的实例(或实例化)结果。每当通过类的构造方法创建一个新的对象时,就生成了该类的一个对象。对象具有类所定义的属性(字段)和行为(方法)。<br><br>对象是实际存在的实体,真正占用内存,并能在程序运行时执行类中的方法。一个类可以创建多个对象,每个对象都有自己独立的状态,但它们共享类定义的行为。<br><br>对象的创建:通过 new 关键字调用类的构造方法来创建一个对象。例如:<br><br>public class Main {<br> public static void main(String[] args) {<br> // 创建 Person 类的对象<br> Person person1 = new Person("John", 30);<br> Person person2 = new Person("Alice", 25);<br><br> // 调用对象的方法<br> person1.greet(); // Output: Hello, my name is John<br> person2.greet(); // Output: Hello, my name is Alice<br> }<br>}<br>在上面的代码中,person1 和 person2 是 Person 类的两个对象,它们具有自己的 name 和 age 属性。通过 new Person() 构造方法创建这些对象,调用 greet() 方法输出个性化的问候语。<br>
类与对象的关系
3.1 类是对象的模板<br>类相当于一个模板或蓝图,定义了对象的结构(字段)和行为(方法)。类本身不占用内存,只有在创建对象时,类的定义才会被实例化,生成一个实际的对象。<br><ul><li>类是一个概念,表示一组对象的共性特征。</li><li>对象是类的实例,表示类的具体实现,它具有具体的状态和行为。</li></ul><br>3.2 对象是类的实例化<br><ul><li>对象是类的实例化结果,每个对象都是类的一个独立实例。通过类定义的构造方法,创建了类的一个新对象,该对象有自己的状态(通过字段存储)和行为(通过方法定义)。</li></ul><br>3.3 类定义字段和方法,对象占用内存<br><ul><li>字段(属性):字段表示类的状态。每个对象都会有自己独立的字段副本。比如每个 Person 对象都有自己的 name 和 age。</li><li>方法(行为):方法表示类的行为。所有对象共享相同的方法(方法的代码),但每个对象可以通过自己的数据(字段)来执行不同的操作。</li></ul>
类与对象的生命周期
<ul><li>类的生命周期:类本身是程序中的一个静态结构,它在程序开始时加载,一直到程序结束时才会卸载。</li><li><span style="font-size: inherit;">对象的生命周期:对象是动态的,它是在通过构造方法实例化时创建的,并且在不再使用时由垃圾回收器销毁。</span></li></ul><span style="font-size: inherit;"><br>例如,下面是对象的生命周期:</span><br style="font-size: inherit;"><ol><li><span style="font-size: inherit;">创建:通过类的构造方法创建对象。</span></li><li><span style="font-size: inherit;">使用:调用对象的方法和访问对象的属性。</span></li><li><span style="font-size: inherit;">销毁:当对象不再被引用时,垃圾回收器会自动销毁对象。</span></li></ol>
类与对象的关系示意
可以将类和对象的关系比作是**“工厂和产品”**:<br><ul><li>类就像是工厂的生产线,定义了生产产品的规格、样式和功能。</li><li>对象就像是工厂生产出来的产品,每个产品都是按类(工厂)的设计标准生产的,但每个产品有自己的状态(比如颜色、尺寸等)。</li></ul>
类与对象的对比
<br>
其他对象
1、Runtime对象:
该类并没有提供构造函数,说明不可以new对象,那么会想到该类中的方法都是非静态的。发现该类中还有非静态方法,说明该类肯定会提供一个方法获取本类对象,而且该方法是静态的,并返回值类型是本类类型。由这个特点可以看出该类使用了单例设计模式完成。
2、Math
ceil:返回大于指定数据的最小整数。
floor:返回小于指定数据的最小整数。
round:四舍五入。
pow:a,b a底数 b指数。
总结
<ul><li>类是对象的模板或蓝图,定义了对象的属性和行为,但不占用内存。</li><li>对象是类的实例,占用内存并在程序运行时创建、使用和销毁。</li><li>类与对象的关系可以看作工厂与产品的关系,类是对象的抽象设计,对象是类的实际化存在。</li></ul>
整理
映射到java中,描述就是class定义的类。<br>具体对象就是对应java在堆内存中用new建立的实体<br>凡事用于存储数据的都放在堆内存中。<br><br>堆内存的变量会有默认初始化值:null<br><br>类就是:对现实生活中事物的描述。<br>对象:就是这类事物,实实在在的个体。<br><br>属性对应是类中变量,行为对应的是类中的函数(方法)<br>其实定义类,就是在描述事物,就是在定义属性和行为,属性和行为共同成为类中的成员(成员变量和方法)<br><br>引用类型变量(三种):数组类型、类类型变量、接口<br>类类型变量指向对象<br><br><br>成员变量和局部变量:<br>成员变量作用于整个类中。<br>局部变量作用于函数中,或者语句中。<br><br>在内存中的位置:<br>成员变量:在堆内存中,因为对象的存在,才在内存中存在。<br>局部变量:存在于栈内存中。<br><br><br>匿名对象:<br>Car car = new Car();<br>car.num = 4;<br>等<br>于<br>new Car().num=4;<br><br><br>匿名对象使用方式一:<br>当对对象的方法只调用一次时,可以用匿名对象来完成,这样写比较简化。<br>如果对一个对象进行多个成员对象调用,必须给这个对象起一个名字。<br><br>匿名对象使用方式二:<br>可以将匿名对象作为实际参数进行传递。<br>public static void show(Car car){<br>c.num = 4;<br>c.color = "read";<br>}<br><br><br>封装概述:<br>封装:是指隐藏对象的属性和实现细节,仅对外提供公共访问方式。<br>好处:<br>将变化隔离。<br>便于使用。<br>提高重用性。<br>提高安全性。<br><br>封装原则:<br>将不需要对外提供的内容都隐藏起来。<br>把属性都隐藏,提供公共方法对其访问。<br><br>函数是代码最小的封装体。<br><br>权限修饰符:<br>private:私有只在本类中有效。<br>public:公共的。<br><br>之所以对外提供访问方式,就因为可以在访问方式中加入逻辑判断等语句。<br>对访问的数据进行操作。提高代码健壮性。<br><br><br>构造函数:<br>特点:<br>1、函数名与类名相同。<br>2、不用定义返回值类型。<br>3、不可以写return语句。<br><br>对象一建立就会调用与之对应的一个构造函数。<br>构造函数的作用:可以给对象进行初始化。<br><br>构造函数的小细节:<br>当一个类中没有定义构造函数是,那么系统会默认给该类加入一个空参数的构造函数。<br>挡在类中定义了构造函数后,默认的构造函数就没有了。<br><br>构造函数和一般函数在写法上有不同。<br>在运行上也有不用:<br>构造函数是在对象一建立就运行,给对象初始化。<br>而一般函数是对象调用才执行,是给对象添加对象具备的功能。<br><br>一个对象建立,构造函数只运行一次。<br>而一般函数可以被该对象调用多次。<br><br>什么时候定义构造函数呢?<br>当分析事物时,该事物存在具备一些特性或者行为,那么将这些内容定义在构造函数中。<br><br><br>构造代码块<br>作用:给对象进行初始化。<br>对象一建立就运行,而且优先于构造函数执行。<br><br>和构造函数的区别:<br>1、构造代码块是给所有对象进行统一初始化。<br>2、而构造函数是给对应的对象初始化。<br><br>构造代码块中定义的是不同对象共性的初始化内容。<br><br><br>this关键字<br>this:看上去,是用于区分局部变量和成员变量(全局变量)同名的情况。<br>this特点:<br>this就是代表本类对象,this代表它所在函数所属对象的引用。<br>简单说:哪个对象在调用this所在的函数,this就代表哪个对象。<br><br>this的应用:<br>当定义类中函数时,该函数内部要用到调用该函数的对象时,这时用this来表示这个对象。但凡本类功能内部使用了本类对象,都用this表示。<br><br>this关键字在构造函数间调用:<br>this语句:用于构造函数间互相调用。<br>this只能放在构造函数第一行。因为初始化动作要先执行。<br>
继承、接口<br>
继承
1.1 概念<br>继承是面向对象编程中的一个基本概念,它允许一个类(子类)从另一个类(父类)继承属性和方法。通过继承,子类可以复用父类的代码,并且可以对父类的方法进行扩展或修改。<br><br>1.2 继承的语法<br>在 Java 中,继承通过 extends 关键字来实现。子类可以继承父类的所有公共(public)和保护(protected)成员,但不能直接访问父类的私有(private)成员。<br><br>1.3 继承的特性<br><ul><li>单继承:Java 只支持单继承,即一个类只能继承一个父类。Java 通过接口提供了多继承的能力。</li><li>方法重写(Override):子类可以重写父类的方法,即使用相同的方法签名重新定义父类的方法实现。重写的目的是改变父类方法的行为。</li><li>构造方法继承:子类不能继承父类的构造方法,但可以调用父类的构造方法(使用 super())。</li><li>super 关键字:super 用于调用父类的构造方法、字段和方法。</li></ul><br>1.4 继承的优势<br><ul><li>代码复用:继承可以让子类继承父类的方法和属性,避免了重复编写相同的代码。</li><li>实现“is-a”关系:子类是父类的一种特殊类型,例如 Dog 是 Animal 的一种特殊类型。这样可以实现多态性。</li></ul><br>1.5 继承的局限性<br><ul><li>单继承的限制:Java 不支持多重继承(即一个类继承多个类),这是为了避免因继承关系复杂化而引起的问题,如菱形继承问题。</li><li>紧耦合:继承导致子类与父类的耦合性很高,父类的改动可能会影响到子类,这使得继承关系不够灵活。</li></ul>
接口
2.1 概念<br>接口是 Java 中的一种抽象类型,定义了一组方法的签名,但不提供实现。类可以实现接口,从而承诺提供接口中声明的方法的具体实现。接口用于定义类与类之间的行为规范,具有解耦性和灵活性。<br><br>2.2 接口的语法<br>接口使用 interface 关键字定义,并且类通过 implements 关键字实现接口。一个类可以实现多个接口,解决了 Java 中不能多继承的问题。<br><br>2.3 接口的特性<br><ul><li>不能实例化:接口不能直接实例化,只能通过实现它的类来创建对象。</li><li>多重实现:一个类可以实现多个接口,这是 Java 解决多继承的一种方式。</li><li>抽象方法:接口中的方法默认都是 abstract 的,即没有方法体(直到 Java 8)。</li><li>默认方法(Java 8 引入):接口可以有默认方法(使用 default 关键字定义),这样接口可以提供方法的默认实现,从而避免影响实现类的代码。</li><li>静态方法:接口可以包含静态方法,这些方法只能通过接口本身调用,不能通过实例调用。</li></ul><br>2.4 接口与继承的比较<br><ul><li>接口提供行为的抽象:接口只定义行为,不涉及状态(数据成员)。它更关注于“做什么”,而不是“怎么做”。</li><li>继承提供代码的复用:继承提供了一个父类和子类的层次结构,子类可以继承父类的代码并可以对其进行扩展或修改。</li></ul><br>2.5 接口的优势<br><ul><li>解耦:接口通过解耦具体实现和抽象,使得代码更加灵活,易于扩展和维护。</li><li>多重继承:Java 中通过接口提供了多重继承的能力,一个类可以实现多个接口,从而在类之间共享行为。</li><li>代码规范:接口可以作为类之间的一种规范,确保实现类遵循某种行为契约。</li></ul><br>2.6 接口的局限性<br>无法包含状态:接口不能定义实例变量(只能定义 public static final 常量),不能持有状态。它只能定义行为。<br>多重实现的复杂性:虽然接口提供了多重继承的能力,但多个接口的实现可能会增加类的复杂性,尤其是当接口中有很多默认方法时。<br><br>3. 继承与接口的使用场景<br>继承:<br><ul><li>当类之间有明显的层次结构,且子类需要复用父类的代码时使用继承。</li><li>适用于类与类之间的“是一个”(is-a)关系。</li><li>适用于具有共性行为的对象(例如:Dog 是 Animal 的一种)。</li></ul>接口:<br><ul><li>当需要为多个类定义相同的行为,但又不关心它们的实现时使用接口。</li><li>适用于定义某种功能或行为的契约,通常是“能做某事”的关系。</li><li><span style="font-size: inherit;">适用于解耦和实现多重继承的场景(例如:Runnable 接口定义了 run 方法,可以由任何类实现)。<br><br></span></li></ul><span style="font-size: inherit;">4. 继承与接口的对比</span><br>
整理
一、继承
1、提高了代码的复用性。
2、让类与类之间产生了关系,有了这个关系,才有了多态的特性。
注意:千万不要为了获取其他类的功能,简化代码而继承。必须是类与类之间有所属关系才可以继承。
java语言中:java只支持单继承,不支持多继承。
因为多继承容易带来安全隐患:当多个父类中定义了相容的功能,当功能内容不同时,子类对象不确定要运行哪一个。
但是java保留这种机制,并用另一种体现形式来完成表示,多实现。
java支持多层继承。
二、子父类中变量的特点
1、子父类出现后,类成员的特点:
类中成员:
a、变量:
如果子类中出现非私有的同名成员变量时:
子类要访问本类中的变量,使用this。
子类要访问父类中的同名变量,使用super。
super的使用和this使用几乎一致。
this代表的是本类对象的引用。
super代表的是父类对象的引用。
b、函数
当子类出现和父类一模一样的函数时,当子类对象调用该函数,会运行子类函数的内容。如同父类的函数被覆盖一样。
这种情况时函数的另一个特性:重写(覆盖)。
当子类继承父类,沿袭了父类的功能到子类中,但是子类虽具备该功能,但是功能的内容却和父类不一致,这时,没有必要定义新功能,而是使用覆盖特性,保留父类的功能定义,并重写功能内容。
注意:
(1)、子类覆盖父类,必须保证子类权限大于等于父类权限,才可以覆盖,否则编译失败。
(2)、静态只能覆盖静态。
重载:只看同名函数的参数列表。
重写:子父类方法要一模一样。
c、构造函数
在对子类对象进行初始化时,父类的构造函数也会运行,那是因为子类的构造函数默认第一行有一条隐式的语句 super();
super():会访问父类中空参数的构造函数。而且子类中所有的构造函数默认第一行都是super();
为什么子类一定要访问父类中的构造函数?
因为父类中的数据子类可以直接获取,所以子类对象在建立时,需要先查看父类是如何对这些数据进行初始化的,所以子类在对象初始化时,要先访问一下父类中的构造函数。如果要访问父类中指定的构造函数,可以通过手动定义super()的方式来指定。
注意:
super()语句一定要放在子类构造函数的第一行。
子类的实例化过程:
结论:
子类的所有构造函数,默认都会访问父类中空参数的构造函数。因为子类每一个构造函数内的第一行都有一句隐式super();
当父类中没有空参数的构造函数时,子类必须手动通过super语句形式来指定要访问父类中的构造函数。
当然子类的构造函数第一行也可以手动指定this语句来访问本类中的构造函数,子类中至少会有一个构造函数会访问父类中的构造函数。
三、final关键字
1、final:最终。作为一个修饰符
a、可以修饰类,函数,变量。
b、被final修饰的类不可以被继承。为了避免被子类复写功能。
c、被final修饰的方法不可以被复写。
d、被final修饰的变量是一个常量只能赋值一次,既可以修饰成员变量,又可以修饰局部变量。
当在描述事物时,一些数据的出现值是固定的,那么这时为了增强阅读性,都给这些值起个名字,方便阅读。而这个值不需要改变,所以加上final修饰。作为常量:常量的书写规范所有字母都大写,如果由多个单词组成。单词间通过_连接。
e、内部类定义在类中的局部位置上时,只能访问该局部被final修饰的局部变量。
四、抽象类
1、定义:当多个类中出现相同的功能,但是功能主体不同,这时可以进行向上抽取。这时只抽取功能定义,而不抽取功能主体。
2、特点
a、抽象方法一定在抽象类中。
b、抽象方法和抽象类都必须被abstract关键字修饰。
c、抽象类不可以用new创建对象。因为调用抽象方法没有意义。
d、抽象类中的方法要被使用,必须由子类复写其所有的抽象方法后,建立子类对象调用。如果子类只覆盖了部分抽象方法,那么该子类还是一个抽象类。
3、抽象类和一般类没有太大的不同。
a、该如何描述事物,就如何描述事物,只不过,该事物出现了一些看不懂的东西。这些不确定的部分,也是该事物的功能,需要明确出现。但是无法定义主体。
b、抽象类比一般类多了个抽象函数。
c、抽象类不可以实例化。
4、特殊:抽象类中不定义抽象方法,这样做仅仅是不让该类建立对象。
五、模板方法设计模式
1、定义:在定义功能时,功能的一部分是确定的,但是有一部分是不确定,而确定的部分在使用不确定的部分,那么这时就将不确定的部分暴露出去,由该类的子类去完成。
六、接口
1、定义:初期理解,可以认为是一个特殊的抽象类。当抽象类中的方法都是抽象的,那么该类可以通过接口的形式来表示。
class:用于定义类。
interface:用于定义接口。
2、接口定义时,格式特点
a、接口中常见定义:常量,抽象方法。
b、接口中的成员都有固定的修饰符。
常量:public static final
方法:public abstract
3、记住:
a、接口中的成员都是public的。
b、接口是不可以创建对象的,因为有抽象方法。需要被子类实现,子类对接口中的抽象方法全都覆盖后,子类才可以实例化,否则子类是一个抽象类。
4、接口可以被类多实现,也是对多继承不支持的转换形式。java支持多实现。
5、特点:
a、接口是对外暴露的规则。
b、接口是程序的功能扩展。
c、接口是可以用来多实现。
d、类与接口之间是实现关系,而且类可以继承一个类的同时实现多个接口。
e、接口与接口之间可以有继承关系。
多态、object
多态
多态的定义
多态(Polymorphism)是面向对象编程(OOP)的三大特性之一(封装、继承、多态)。它允许相同的接口以不同的方式执行,主要用于提高代码的可扩展性和维护性。
多态的核心思想是**“一个接口,多种实现”**,即同一方法在不同对象上表现出不同的行为。
Java 实现多态的方式
Java 中的多态主要分为**编译时多态(静态绑定)和运行时多态(动态绑定)**两种。<br><br>1、编译时多态(方法重载 - Overloading)<br>编译时多态是通过方法重载(Method Overloading)实现的,即相同的方法名,但参数列表不同(参数个数、类型或顺序不同)。<br><br>示例:<br>class MathUtils {<br> // 两个参数的加法<br> int add(int a, int b) {<br> return a + b;<br> }<br><br> // 三个参数的加法<br> int add(int a, int b, int c) {<br> return a + b + c;<br> }<br><br> // 浮点数加法<br> double add(double a, double b) {<br> return a + b;<br> }<br>}<br><br>public class TestOverloading {<br> public static void main(String[] args) {<br> MathUtils mu = new MathUtils();<br> System.out.println(mu.add(2, 3)); // 调用 int add(int, int)<br> System.out.println(mu.add(2, 3, 4)); // 调用 int add(int, int, int)<br> System.out.println(mu.add(2.5, 3.2)); // 调用 double add(double, double)<br> }<br>}<br>特点:<br><ul><li>方法名相同,参数列表不同(参数个数、类型或顺序不同)。</li><li>返回类型可以不同,但不能单独以返回类型区分方法重载。</li><li>方法调用时,编译器会根据参数匹配合适的方法,所以它在编译时就能确定调用哪个方法(静态绑定)。</li></ul><br>2、运行时多态(方法重写 - Overriding)<br>运行时多态是通过**方法重写(Method Overriding)**实现的,子类重写父类的方法,并且使用父类的引用指向子类对象时,会执行子类的重写方法。<br><br><ul><li>方法重写的规则</li><li>方法名、参数列表必须相同。</li><li>返回类型:可以是父类方法返回类型的子类型(协变返回类型,JDK 5 之后支持)。</li><li><span style="font-size: inherit;">访问权限:<br></span>子类方法的访问权限不能比父类更严格(如:父类方法是 public,子类不能降级为 protected 或 private)。<br>只能重写非 static 方法(static 方法属于类,不属于实例,不能被重写)。</li></ul><ul><li>@Override 注解(可选但推荐),可以让编译器检查是否正确重写了方法。</li></ul><br>示例:<br>class Animal {<br> void makeSound() {<br> System.out.println("动物发出声音");<br> }<br>}<br><br>class Dog extends Animal {<br> @Override<br> void makeSound() {<br> System.out.println("狗叫:汪汪!");<br> }<br>}<br><br>class Cat extends Animal {<br> @Override<br> void makeSound() {<br> System.out.println("猫叫:喵喵!");<br> }<br>}<br><br>public class TestOverriding {<br> public static void main(String[] args) {<br> Animal myAnimal1 = new Dog(); // 向上转型(父类引用指向子类对象)<br> Animal myAnimal2 = new Cat(); <br><br> myAnimal1.makeSound(); // 输出:狗叫:汪汪!<br> myAnimal2.makeSound(); // 输出:猫叫:喵喵!<br> }<br>}<br>特点:<br><ul><li>方法调用在运行时决定,属于动态绑定(Dynamic Binding)。</li><li>通过父类的引用指向子类对象,调用的方法是子类重写后的方法,而不是父类的方法。</li></ul><br>
向上转型与向下转型
在运行时多态中,我们通常会涉及向上转型(Upcasting)和向下转型(Downcasting)。<br><br>(1)向上转型(Upcasting)<br>向上转型是子类对象赋值给父类引用,这样可以屏蔽子类的特有方法,增强代码的通用性。<br><br>Animal a = new Dog(); // 向上转型<br>a.makeSound(); // 调用的是 Dog 的 makeSound() 方法<br>特点:<br><br>只能调用父类中被子类重写的方法,无法调用子类特有的方法。<br>编译时检查类型安全,确保父类引用可以指向子类。<br>(2)向下转型(Downcasting)<br>向下转型是父类引用重新转换为子类引用,通常需要强制类型转换。<br><br>Animal a = new Dog(); // 向上转型<br>Dog d = (Dog) a; // 向下转型<br>d.makeSound(); // 调用 Dog 的 makeSound()<br><br>注意:<br>必须确保父类引用指向的是实际的子类对象,否则会抛出 ClassCastException。<br>使用 instanceof 关键字确保安全转换:<br><br>if (a instanceof Dog) {<br> Dog d = (Dog) a;<br> d.makeSound();<br>}<br>
抽象类与接口中的多态
多态的核心在于面向接口编程,在 Java 中,抽象类和接口也可以实现多态。<br><br>(1)抽象类实现多态<br>abstract class Animal {<br> abstract void makeSound(); // 抽象方法<br>}<br><br>class Dog extends Animal {<br> @Override<br> void makeSound() {<br> System.out.println("狗叫:汪汪!");<br> }<br>}<br><br>class Cat extends Animal {<br> @Override<br> void makeSound() {<br> System.out.println("猫叫:喵喵!");<br> }<br>}<br><br>public class TestAbstract {<br> public static void main(String[] args) {<br> Animal a = new Dog(); // 向上转型<br> a.makeSound(); // 狗叫:汪汪!<br> }<br>}<br>(2)接口实现多态<br>interface Animal {<br> void makeSound();<br>}<br><br>class Dog implements Animal {<br> public void makeSound() {<br> System.out.println("狗叫:汪汪!");<br> }<br>}<br><br>class Cat implements Animal {<br> public void makeSound() {<br> System.out.println("猫叫:喵喵!");<br> }<br>}<br><br>public class TestInterface {<br> public static void main(String[] args) {<br> Animal a = new Dog(); // 接口引用指向子类对象<br> a.makeSound(); // 狗叫:汪汪!<br> }<br>}
总结
<ul><li>编译时多态(方法重载):方法名相同,参数不同,编译时绑定。</li><li>运行时多态(方法重写):子类重写父类方法,通过父类引用调用子类方法,运行时绑定。</li><li>向上转型:子类对象赋值给父类引用,可调用父类的方法。</li><li>向下转型:将父类引用强制转换回子类,需要 instanceof 进行类型检查。</li><li>抽象类和接口提供了一种更灵活的多态实现方式。</li></ul>多态的最大优势是提高代码的可扩展性和可维护性,在实际开发中应充分利用。
整理
一、多态
1、定义:可以理解为事物存在的多重体现形态。
2、多态的体现
父类的引用指向了直接的子类对象。
父类的引用可以接收自己的子类对象。
3、多态的好处
多态的出现提高了程序的扩展性。
4、多态的前提
必须是类与类之间必须有关系,要么继承,要么实现。
通常还有一个前提:存在覆盖。
5、多态中成员的特点:
a:在多态中成员函数的特点:
1)、在编译时期:参阅引用型变量所属的类中是否有调用的方法,如果有编译通过,没有失败;
2)、在运行时期:参阅对象所属的类中是否有调用的方法。
简单总结:成员函数在多态调用时,编译看左边,运行看右边。
b:在多态中,成员变量的特点:
无论编译和运行,都参考左边(引用型变量所属的类)。
c:在多态中,静态成员函数的特点:
无论编译和运行,都参考左边。
object
Object 类的概述
Object 是 Java 中所有类的父类,位于 java.lang 包中。Java 中的所有类默认继承 Object 类(如果没有显式继承其他类)。因此,每个 Java 对象都可以使用 Object 类提供的方法。
Object 类的方法<br>
<br>
equals() 方法<br>
(1)默认实现<br>Object 类中的 equals() 方法比较的是对象的引用地址,即是否指向同一个对象。<br><br>class A {}<br><br>public class TestEquals {<br> public static void main(String[] args) {<br> A obj1 = new A();<br> A obj2 = new A();<br> A obj3 = obj1;<br><br> System.out.println(obj1.equals(obj2)); // false,不是同一对象<br> System.out.println(obj1.equals(obj3)); // true,引用相同<br> }<br>}<br>(2)重写 equals()(基于内容比较)<br>在实际开发中,我们通常需要比较对象的内容,因此需要重写 equals() 方法。<br><br>示例:<br>class Person {<br> String name;<br> int age;<br><br> Person(String name, int age) {<br> this.name = name;<br> this.age = age;<br> }<br><br> @Override<br> public boolean equals(Object obj) {<br> if (this == obj) return true; // 同一个对象<br> if (obj == null || getClass() != obj.getClass()) return false;<br> Person person = (Person) obj;<br> return age == person.age && name.equals(person.name);<br> }<br>}<br><br>public class TestEqualsOverride {<br> public static void main(String[] args) {<br> Person p1 = new Person("Alice", 25);<br> Person p2 = new Person("Alice", 25);<br> Person p3 = new Person("Bob", 30);<br><br> System.out.println(p1.equals(p2)); // true,内容相同<br> System.out.println(p1.equals(p3)); // false,内容不同<br> }<br>}<br>重写 equals() 方法的要点:<br><ul><li>自反性:x.equals(x) 必须返回 true。</li><li>对称性:x.equals(y) 返回 true,则 y.equals(x) 也必须返回 true。</li><li>传递性:x.equals(y) 且 y.equals(z),则 x.equals(z) 也必须返回 true。</li><li>一致性:多次调用 equals() 方法,结果应保持一致(除非对象属性改变)。</li><li>与 null 比较:x.equals(null) 必须返回 false。</li></ul>
hashCode() 方法
hashCode() 方法返回对象的哈希码,通常用于哈希表(HashMap、HashSet 等)。<br><br>(1)默认实现<br>Object 的 hashCode() 方法基于对象的内存地址计算哈希值。<br><br>class A {}<br><br>public class TestHashCode {<br> public static void main(String[] args) {<br> A obj1 = new A();<br> A obj2 = new A();<br><br> System.out.println(obj1.hashCode()); // 可能是 12345678<br> System.out.println(obj2.hashCode()); // 可能是 87654321<br> }<br>}<br><br>(2)重写 hashCode()<br>如果重写 equals() 方法,也必须重写 hashCode() 方法,否则会影响 HashMap、HashSet 等数据结构的正确性。<br><br>示例(与 equals() 结合):<br>import java.util.Objects;<br><br>class Person {<br> String name;<br> int age;<br><br> Person(String name, int age) {<br> this.name = name;<br> this.age = age;<br> }<br><br> @Override<br> public boolean equals(Object obj) {<br> if (this == obj) return true;<br> if (obj == null || getClass() != obj.getClass()) return false;<br> Person person = (Person) obj;<br> return age == person.age && name.equals(person.name);<br> }<br><br> @Override<br> public int hashCode() {<br> return Objects.hash(name, age);<br> }<br>}<br><br>public class TestHashCodeOverride {<br> public static void main(String[] args) {<br> Person p1 = new Person("Alice", 25);<br> Person p2 = new Person("Alice", 25);<br><br> System.out.println(p1.hashCode()); // 相同哈希值<br> System.out.println(p2.hashCode()); // 相同哈希值<br> }<br>}<br>hashCode() 方法的要求:<ul><li>相等的对象 equals() 返回 true,它们的 hashCode() 必须相同。</li><li>不同的对象 hashCode() 可以相同,但尽量减少哈希冲突。</li><li>使用 Objects.hash() 方法简化哈希计算。</li></ul>
toString() 方法
(1)默认实现<br>默认 toString() 方法返回 "类名@十六进制内存地址"。<br><br>class A {}<br><br>public class TestToString {<br> public static void main(String[] args) {<br> A obj = new A();<br> System.out.println(obj.toString()); // A@1a2b3c4d<br> }<br>}<br>(2)重写 toString()<br>toString() 通常用于打印对象信息,应在自定义类中重写。<br><br>class Person {<br> String name;<br> int age;<br><br> Person(String name, int age) {<br> this.name = name;<br> this.age = age;<br> }<br><br> @Override<br> public String toString() {<br> return "Person{name='" + name + "', age=" + age + "}";<br> }<br>}<br><br>public class TestToStringOverride {<br> public static void main(String[] args) {<br> Person p = new Person("Alice", 25);<br> System.out.println(p); // 自动调用 toString() 方法<br> }<br>}
getClass() 方法
getClass() 返回对象的运行时 Class 对象。<br><br>class A {}<br><br>public class TestGetClass {<br> public static void main(String[] args) {<br> A obj = new A();<br> System.out.println(obj.getClass()); // class A<br> }<br>}
clone() 方法<br>
clone() 用于对象克隆,但类必须实现 Cloneable 接口,否则会抛 CloneNotSupportedException。<br><br>class Person implements Cloneable {<br> String name;<br><br> Person(String name) {<br> this.name = name;<br> }<br><br> @Override<br> protected Object clone() throws CloneNotSupportedException {<br> return super.clone();<br> }<br>}<br><br>public class TestClone {<br> public static void main(String[] args) throws CloneNotSupportedException {<br> Person p1 = new Person("Alice");<br> Person p2 = (Person) p1.clone();<br> System.out.println(p2.name); // Alice<br> }<br>}
总结<br>
<ul><li>equals() 和 hashCode() 需同时重写。</li><li>toString() 用于输出对象信息,建议重写。</li><li>getClass() 获取对象的运行时类型。</li><li>clone() 需要实现 Cloneable 接口。</li><li>wait() 和 notify() 用于线程同步。</li></ul>Object 类是 Java 最基础的类,掌握它可以提升 Java 开发能力。
static
描述
static 是一个非常重要的关键字,它用于修饰类中的成员(变量、方法、代码块和内部类),使得这些成员不再与对象的实例关联,而是与类本身关联。通过 static,我们可以在没有实例化类的情况下访问和操作这些成员。
static 关键字的用途
static 关键字的主要作用是将类的成员与对象实例分离,使得该成员属于类本身,而不是类的实例。使用 static 修饰的成员,无论创建了多少个类的实例,都会共享同一个值。
static变量
static 修饰的变量属于类而不是实例。所有实例共享这个静态变量,而不是每个实例都有自己的一份。<br><br>特点:<br><ul><li>static 变量在内存中只有一份,所有对象共享这份数据。</li><li>它们在类加载时就已经分配内存,并且在整个程序运行期间都存在,直到程序结束。</li></ul>
static 方法
static 方法是属于类的,而不是属于类的某个实例。static 方法不能直接访问实例变量和实例方法,只能访问静态变量和静态方法。<br><br>特点:<br><ul><li>静态方法可以在没有创建类的实例时调用。</li><li>静态方法不能访问非静态(实例)成员(变量和方法)。</li><li>静态方法可以通过类名直接访问。</li></ul>
static 块(静态初始化块)
static 块是一种特殊的代码块,它用于初始化静态变量。静态块只会在类第一次加载时执行一次,通常用于静态变量的初始化。<br><br>特点:<br><ul><li>静态块在类加载时执行一次,用于执行一些初始化操作。</li><li>只会执行一次,不会随着对象的创建多次执行。</li></ul>
static 类(静态内部类)
在 Java 中,我们可以将类声明为静态内部类。静态内部类是属于外部类的一部分,但不依赖于外部类的实例。静态内部类可以直接访问外部类的静态成员。<br><br>特点:<br><ul><li>静态内部类可以访问外部类的静态成员,但不能访问外部类的实例成员。</li><li>静态内部类可以独立于外部类的实例化而存在。</li><li>静态内部类的实例可以通过外部类直接创建,无需创建外部类的实例。</li></ul>
static 的优缺点
2.1 优点<br><ul><li>内存共享:静态成员(变量和方法)在所有类的实例中共享,节省内存空间。</li><li>无需创建对象:通过类名直接访问静态方法和静态变量,无需实例化对象。</li><li>简化代码:静态方法有助于封装不依赖于对象状态的功能,例如工具类中的方法。</li></ul>2.2 缺点<br><ul><li>难以测试和扩展:静态方法和静态变量在程序中很难进行替换和扩展,过多使用静态成员会导致程序设计变得不灵活。</li><li>全局状态:静态变量属于类本身,共享状态,这可能导致全局变量问题,尤其是在多线程环境中。</li><li>隐藏依赖性:静态方法无法访问实例成员,这限制了其灵活性和扩展性。</li></ul>
static 与线程安全
当多个线程访问相同的静态变量时,可能会出现线程安全问题。静态变量在所有对象中共享,如果多个线程同时修改静态变量的值,可能会导致数据不一致。为了确保线程安全,可以使用 synchronized 关键字来保护静态方法,或使用 java.util.concurrent 包中的工具类来保证线程安全。<br><br>public class Counter {<br> static int count = 0;<br><br> public synchronized static void increment() {<br> count++;<br> }<br>}<br>通过 synchronized 关键字,我们可以确保多个线程在执行 increment 方法时不会同时修改静态变量 count,从而避免竞态条件。
小结
<ul><li>static 关键字使得变量、方法、代码块或内部类属于类本身,而不是某个特定对象。</li><li>使用 static 时可以节省内存并简化代码,但要注意它带来的限制,尤其是对灵活性和扩展性的影响。</li><li>static 变量和方法在整个程序生命周期内共享,适用于无需依赖实例状态的功能。</li></ul>
自己整理<br>
一、static(静态)关键字
1、用法:
是一个修饰符,用于修饰成员(成员变量,局部变量)
当成员被静态修饰后,就多了一个调用方式,除了可以被对象调用外,还可以直接被类名调用,类名.静态成员。
2、特点
a、随着类的加载而加载。
也就是说:静态会随着类的消失而消失。说明它的生命周期最长。
b、优先于对象存在。
明确一点:静态是先存在的,对象是后存在的。
c、被所有对象所共享。
d、可以直接被类名所调用。
3、实例变量(成员变量)和类变量(静态变量)的区别
a、存放位置:
类变量随着类的加载而存在于方法区中。
实例变量随着对象的建立而存在于堆内存中。
b、生命周期:
类变量生命周期最长,随着类的消失而消失。
实例变量生命周期随着对象的消失而消失。
4、静态使用注意事项
a、静态方法只能访问静态成员。
非静态方法既可以访问静态也可以访问非静态。
b、静态方法中不可以定义this, super关键字。
因为静态优先于对象存在,所以静态方法中不可以出现this。
c、主函数是静态的。
5、静态有利有弊
利处:
对对象的共享数据进行单独空间的存储,节省空间,没有必要每一个对象中都存储一份。
可以直接被类名调用。
弊端:
生命周期过长。
访问出现局限性。(静态虽好,只能访问静态)
二、main函数
public static void main(String[] args)
主函数:是一个特殊的函数,作为程序的入口,可以被jvm调用。
定义:
public:代表着该函数访问权限最大的。
static:代表着主函数随着类的加载就已经存在了。
void:主函数没有具体的返回值。
main:不是关键字,但是是一个特殊的单词,可以被jvm识别。
(String[] args):主函数的参数,参数类型是一个数组,该数组中的元素是字符串。字符串类型元素的数组。
主函数是固定格式的:jvm识别。
jvm在调用主函数时,传入的是new String[0];
三、什么时候使用静态
要从两方面下手:因为静态修饰的内容有成员变量和函数。
1、什么时候定义静态变量(类变量)呢?
当对象中出现共享数据时,该数据被静态所修饰。
对象中的特有数据要定义成非静态存在于堆内存中。
2、什么时候定义静态函数呢?
当功能内部没有访问到非静态数据(对象的特有数据),那么该功能可以定义成静态的。
四、静态的应用
每一个应用程序中都有共性的功能,可以将这些功能进行抽取,独立封装。以便复用。
五、java帮助文档
javadoc -d 目录 -author(作者) -version(版本) 文件名
六、静态代码块
1、格式:
static{
静态代码块中的执行语句
}
2、特点:
随着类的加载而执行,只执行一次,并优先于主函数。
用于给类进行初始化的。
3、
static{
静态代码块给类进行初始化
}
{
构造代码块给对象进行初始化
}
类名(int x){
构造函数给对象进行初始化
}
4、初始化顺序
静态代码块 > 构造代码块 >构造函数
七、对象的初始化过程
1、Person p = new Person("zhangsan",20);
a、因为new 用到了person.class,所以会先找到Person.class文件加载到内存中。
b、执行该类中的static代码块,如果有的话,给Person.class类进行初始化。
c、在堆内存中开辟空间,分配内存地址。
d、在堆内存中建立对象的特有属性,并进行默认初始化。
e、对属性进行显示初始化。
f、对对象进行构造代码块初始化。
g、对对象进行对应的构造函数初始化。
h、将内存地址赋给栈内村中的p变量。
八、设计模式
1、定义:解决某一类问题最行之有效的方法。
2、单例设计模式:解决一个类在内存中只存在一个对象。
想要保证对象唯一:
a、为了避免其他程序过多建立该类对象。先禁止其他程序建立该类对象。
b、为了让其他程序可以访问到该类对象,只好在本类中,自定义一个对象。
c、为了方便其他程序对自定义对象对的访问,可以对外提供一些访问方式。
这三步代码体现:
a、将构造函数私有化。
b、在类中创建一个本类对象。
c、提供一个方法可以获取到该对象。
对于事物该怎么描述,还怎么描述。当需要将该事物的对象保证在内存中唯一时,就将这三步加上即可。
这个是先初始化对象。称为:饿汉式。
Single类一进内存,就已经创建好了对象。
class Singel{
privae static Single s = new Single();
private Singe(){};
public static Single getInstance(){
return s;
}
}
这个是方法被调用时,才初始化,也叫作对象的延时加载。称为:懒汉式。
Single类进内存,对象还没有存在,只有调用了getInstance方法时,才建立对象。
懒汉式和饿汉式有什么不同?
懒汉式的特点是延迟加载,多线程访问延迟加载会出现安全问题,可以用同步函数和同步代码块,缺点是有点低效。可以用双重判断解决效率问题。加同步的时候使用的锁是该类所属的文件字节码对象。
class Single{
private static Single s = null;
private Single(){};
public static Single getInstance(){
if(s == null){
synchronized(Single.class){
if(s == null){
s = new Single();
}
}
}
return s;
}
}
定义单例,建议使用饿汉式。
内部类、异常
内部类
描述
在 Java 中,**内部类(Inner Class)**是定义在另一个类内部的类。它与外部类紧密关联,通常用于表示一个依赖于外部类或封装外部类功能的类。内部类可以访问外部类的成员(包括私有成员),从而提高了封装性和可维护性。<br><br>Java 中的内部类有多种类型,每种类型的内部类在语法和使用场景上有所不同。下面将详细介绍不同类型的内部类及其特点。
成员内部类(Member Inner Class)
成员内部类是定义在外部类内部,作为外部类的一个成员存在。它与外部类的实例关联,可以访问外部类的所有成员(包括私有成员)。<br><br>1.1 成员内部类的特点<br><ul><li>成员内部类可以访问外部类的实例成员(字段和方法)。</li><li>成员内部类需要通过外部类的实例来创建,不能直接通过外部类的类名来创建。</li><li>成员内部类不能定义静态成员(字段、方法等),因为它依赖于外部类的实例。</li></ul><br>1.2 示例<br>public class OuterClass {<br> private String outerField = "Outer Field";<br><br> // 成员内部类<br> class InnerClass {<br> void display() {<br> System.out.println("Accessing outer field: " + outerField);<br> }<br> }<br><br> public static void main(String[] args) {<br> // 创建外部类对象<br> OuterClass outer = new OuterClass();<br> <br> // 创建成员内部类对象<br> OuterClass.InnerClass inner = outer.new InnerClass();<br> <br> inner.display(); // Output: Accessing outer field: Outer Field<br> }<br>}<br>在上面的代码中,InnerClass 是一个成员内部类。它可以访问外部类 OuterClass 的私有成员 outerField。<br>
静态内部类(Static Inner Class)
静态内部类是定义为静态的内部类,它与外部类的实例无关,属于外部类的类本身。静态内部类只能访问外部类的静态成员。<br><br>2.1 静态内部类的特点<br><ul><li>静态内部类不需要外部类的实例即可创建。</li><li>静态内部类只能访问外部类的静态成员(静态字段和静态方法)。</li><li>静态内部类可以定义静态成员(字段、方法等),这是成员内部类不能做到的。</li></ul><br>2.2 示例<br>public class OuterClass {<br> private static String staticOuterField = "Static Outer Field";<br><br> // 静态内部类<br> static class StaticInnerClass {<br> void display() {<br> System.out.println("Accessing static outer field: " + staticOuterField);<br> }<br> }<br><br> public static void main(String[] args) {<br> // 直接通过外部类类名创建静态内部类的实例<br> OuterClass.StaticInnerClass inner = new OuterClass.StaticInnerClass();<br> <br> inner.display(); // Output: Accessing static outer field: Static Outer Field<br> }<br>}<br>在这个例子中,StaticInnerClass 是一个静态内部类,它不需要外部类的实例就可以创建,并且它只能访问外部类的静态成员。<br>
局部内部类(Local Inner Class)
局部内部类是在方法或代码块内部定义的类。它的作用域仅限于方法或代码块中,类似于局部变量。局部内部类不能被外部访问,只能在定义它的方法或代码块内部使用。<br><br>3.1 局部内部类的特点<br>不能在方法外部创建局部内部类的实例。<br>局部内部类可以访问方法中的局部变量和参数,但局部变量必须是 final 或等效于 final,即值不可改变。<br>局部内部类的生命周期与方法或代码块的执行周期一致。<br><br>3.2 示例<br>public class OuterClass {<br> void method() {<br> // 局部内部类<br> class LocalInnerClass {<br> void display() {<br> System.out.println("This is a local inner class");<br> }<br> }<br><br> // 创建局部内部类的对象<br> LocalInnerClass inner = new LocalInnerClass();<br> inner.display(); // Output: This is a local inner class<br> }<br><br> public static void main(String[] args) {<br> OuterClass outer = new OuterClass();<br> outer.method(); // 调用方法,创建局部内部类的对象<br> }<br>}<br>在这个例子中,LocalInnerClass 是一个局部内部类,它只在 method() 方法中有效,并且不能在外部直接创建。<br>
匿名内部类(Anonymous Inner Class)
匿名内部类是没有名字的内部类,通常用于实现接口或继承类。匿名内部类通常在需要临时创建一个类并且不打算重用时使用。<br><br>4.1 匿名内部类的特点<br>匿名内部类没有类名,通常用于快速实现一个接口或继承一个类。<br>它是直接在创建时实例化的,通常用来实现接口或继承抽象类。<br>匿名内部类只能有一个实例,且不能定义构造方法。<br><br>4.2 示例<br>public class OuterClass {<br> void method() {<br> // 匿名内部类实现接口<br> Runnable r = new Runnable() {<br> public void run() {<br> System.out.println("This is an anonymous inner class");<br> }<br> };<br><br> r.run(); // Output: This is an anonymous inner class<br> }<br><br> public static void main(String[] args) {<br> OuterClass outer = new OuterClass();<br> outer.method(); // 调用方法,执行匿名内部类<br> }<br>}<br>在这个例子中,匿名内部类实现了 Runnable 接口,直接在方法中创建并使用。它没有名字,通常用于临时实现接口或抽象类。<br>
内部类的访问权限
<ul><li>成员内部类:可以访问外部类的所有成员(包括私有成员),但外部类不能直接访问内部类的成员。</li><li>静态内部类:可以访问外部类的静态成员,但不能访问外部类的实例成员。</li><li>局部内部类和匿名内部类:可以访问方法中的局部变量,但这些局部变量必须是 final 或等效于 final。</li></ul>
内部类的用途
<ul><li>封装性:内部类有助于提高类的封装性。通过将类作为内部类,可以确保它只在外部类的上下文中使用,不被外部类以外的代码访问。</li><li>逻辑组织:内部类适用于一些与外部类紧密关联的功能。通过内部类,外部类可以将它的实现细节隐藏起来,只暴露必要的接口。</li><li>事件监听:匿名内部类在事件处理(例如 GUI 编程)中非常常见。它允许我们在一个地方同时实现事件监听器并进行事件处理。</li></ul>
总结
<ul><li>成员内部类:类定义在外部类内部,可以访问外部类的成员。必须通过外部类的实例来创建。</li><li>静态内部类:与外部类实例无关,可以独立创建。只能访问外部类的静态成员。</li><li>局部内部类:定义在方法或代码块内部,生命周期限定在该方法或代码块内。</li><li><span style="font-size: inherit;">匿名内部类:没有名字的内部类,通常用来快速实现接口或继承类。</span></li></ul><span style="font-size: inherit;">内部类提高了代码的封装性和可维护性,适用于很多场景,尤其是需要将某些功能限定在某个类内部时。</span><br>
异常
描述
在 Core Java 中,异常(Exception)是程序在运行过程中出现的错误。异常处理机制允许开发者在程序发生错误时采取适当的行动,而不是直接终止程序。异常处理主要通过 try, catch, finally, throw, 和 throws 关键字来实现。
异常的分类
Java 中的异常分为两大类:<br><ol><li>检查型异常(Checked Exception)</li><li>非检查型异常(Unchecked Exception)</li></ol>
检查型异常(Checked Exception)
检查型异常是指在编译时能够被检查到的异常,通常是程序外部因素引起的错误,比如文件操作、数据库连接等。开发者必须显式地处理这些异常,要么通过 try-catch 块捕获并处理,要么通过 throws 关键字声明抛出。<br><br>常见检查型异常:<br><ul><li>IOException:输入输出异常</li><li>SQLException:SQL 异常</li><li>ClassNotFoundException:类没有找到异常</li></ul><br>import java.io.*;<br><br>public class CheckedExceptionExample {<br> public static void main(String[] args) {<br> try {<br> FileInputStream file = new FileInputStream("file.txt"); // 可能会抛出 FileNotFoundException<br> } catch (FileNotFoundException e) {<br> e.printStackTrace();<br> }<br> }<br>}<br>在上面的代码中,FileInputStream 的构造方法会抛出 FileNotFoundException,这是一个检查型异常,我们必须处理它。
非检查型异常(Unchecked Exception)
非检查型异常是指在编译时无法检查到的异常,它通常是由程序的错误逻辑导致的,比如数组越界、空指针引用等。非检查型异常继承自 RuntimeException,开发者可以选择不显式处理它们。<br><br>常见非检查型异常:<br><ul><li>NullPointerException:空指针异常</li><li>ArrayIndexOutOfBoundsException:数组索引越界异常</li><li>ArithmeticException:算术异常(如除以零)</li></ul><br>public class UncheckedExceptionExample {<br> public static void main(String[] args) {<br> int[] arr = {1, 2, 3};<br> System.out.println(arr[5]); // 会抛出 ArrayIndexOutOfBoundsException<br> }<br>}<br>在上面的代码中,访问数组越界会抛出 ArrayIndexOutOfBoundsException,这是一个非检查型异常。
异常层次结构
Java 的异常类继承自 Throwable 类,Throwable 类有两个主要的子类:<br><br><ul><li>Error:通常用于表示 Java 虚拟机运行时的严重问题,如内存溢出(OutOfMemoryError)。这些问题通常是不可恢复的。</li><li>Exception:用于表示程序中的异常情况。异常分为检查型和非检查型。</li></ul><br>Throwable 类的层次结构如下:<br>Throwable<br>│<br>├── Error<br>│ ├── OutOfMemoryError<br>│ └── StackOverflowError<br>│<br>└── Exception<br> ├── IOException<br> ├── SQLException<br> ├── RuntimeException<br> │ ├── NullPointerException<br> │ ├── ArrayIndexOutOfBoundsException<br> │ └── ArithmeticException<br> └── ClassNotFoundException<br>
异常处理机制
Java 通过 try, catch, finally 关键字提供异常处理机制,以便开发者能够捕获和处理异常,防止程序崩溃。
try-catch 块
try-catch 块用于捕获异常并进行处理。<br><br>语法:<br>try {<br> // 可能抛出异常的代码<br>} catch (ExceptionType e) {<br> // 异常处理代码<br>}<br><br>例子:<br>public class TryCatchExample {<br> public static void main(String[] args) {<br> try {<br> int result = 10 / 0; // 会抛出 ArithmeticException<br> } catch (ArithmeticException e) {<br> System.out.println("Error: " + e.getMessage());<br> }<br> }<br>}<br>在上面的代码中,try 块内的代码抛出了 ArithmeticException,catch 块捕获并处理了它。<br>
finally 块
finally 块是可选的,它用于在 try-catch 块后执行,无论是否发生异常,finally 中的代码总会执行,通常用于资源的释放(例如关闭文件流、数据库连接等)。<br><br>语法:<br>try {<br> // 可能抛出异常的代码<br>} catch (ExceptionType e) {<br> // 异常处理代码<br>} finally {<br> // 最终执行的代码(例如资源释放)<br>}<br><br>例子:<br>public class FinallyExample {<br> public static void main(String[] args) {<br> try {<br> System.out.println("In try block");<br> int result = 10 / 0; // 会抛出 ArithmeticException<br> } catch (ArithmeticException e) {<br> System.out.println("Error: " + e.getMessage());<br> } finally {<br> System.out.println("Finally block executed");<br> }<br> }<br>}<br>输出:<br>In try block<br>Error: / by zero<br>Finally block executed<br>即使发生了异常,finally 块中的代码依然会被执行。<br>
throw 关键字
throw 关键字用于手动抛出异常。在需要的地方,开发者可以显式抛出异常来通知调用者发生了异常。<br><br>语法:<br>throw new ExceptionType("Error message");<br><br>例子:<br>public class ThrowExample {<br> public static void main(String[] args) {<br> try {<br> checkAge(15); // 传入不合法的年龄<br> } catch (IllegalArgumentException e) {<br> System.out.println(e.getMessage());<br> }<br> }<br><br> public static void checkAge(int age) {<br> if (age < 18) {<br> throw new IllegalArgumentException("Age must be 18 or older");<br> }<br> System.out.println("Valid age");<br> }<br>}<br>在这个例子中,checkAge 方法检查年龄,如果年龄小于 18,则抛出一个 IllegalArgumentException。<br>
throws 关键字
throws 关键字用于声明一个方法可能会抛出的异常。它通常用于检查型异常,让调用者显式地处理或继续抛出异常。<br><br>语法:<br>public void method() throws ExceptionType {<br> // 可能抛出异常的代码<br>}<br><br>例子:<br>import java.io.*;<br><br>public class ThrowsExample {<br> public static void main(String[] args) {<br> try {<br> readFile("file.txt");<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> }<br><br> // 声明 readFile 方法可能会抛出 IOException<br> public static void readFile(String fileName) throws IOException {<br> FileInputStream file = new FileInputStream(fileName);<br> }<br>}<br>在这个例子中,readFile 方法声明它可能抛出 IOException,所以在 main 方法中,我们需要使用 try-catch 来捕获和处理它。<br>
自定义异常
Java 允许开发者创建自己的异常类,通常用于业务逻辑中特定的异常情况。自定义异常类需要继承 Exception 或 RuntimeException 类。<br><br>语法:<br>public class CustomException extends Exception {<br> public CustomException(String message) {<br> super(message);<br> }<br>}<br><br>例子:<br>public class CustomExceptionExample {<br> public static void main(String[] args) {<br> try {<br> validateAge(15); // 年龄小于 18<br> } catch (InvalidAgeException e) {<br> System.out.println(e.getMessage());<br> }<br> }<br><br> public static void validateAge(int age) throws InvalidAgeException {<br> if (age < 18) {<br> throw new InvalidAgeException("Age must be 18 or older");<br> }<br> System.out.println("Valid age");<br> }<br>}<br><br>class InvalidAgeException extends Exception {<br> public InvalidAgeException(String message) {<br> super(message);<br> }<br>}<br>在这个例子中,我们创建了一个自定义异常 InvalidAgeException,用于验证年龄是否合法。<br>
总结
<ul><li>异常分类:Java 异常分为检查型异常(Checked Exception)和非检查型异常(Unchecked Exception)。</li><li>异常处理:通过 try-catch、finally、throw 和 throws 来捕获、处理、抛出和声明异常。</li><li>自定义异常:开发者可以创建自定义异常类来表示特定的异常情况。</li><li>异常的最佳实践:<br></li><li>捕获并处理必要的异常,不要盲目捕获所有异常。</li><li>使用特定的异常类型(例如 IOException、SQLException)进行精确处理。</li><li>异常信息应尽量清晰,方便后期排查问题。</li></ul>
整理
一、内部类
1、内部类访问规则
a、内部类可以直接访问外部类中的成员,包括私有。
之所以可以直接访问外部类中的成员,是因为内部类中持有一个外部类的引用,格式:外部类名.this
b、外部类要访问内部类,必须建立内部类对象。
2、访问格式:
a、当内部类 定义在外部类的成员位置上,而且非私有,可以在外部其他类中。
格式:
外部类名.内部类名 变量名 = new 外部类对象().new 内部类对象();
静态内部类:
b、当内部类在成员位置上,就可以被成员修饰符所修饰。
比如,private:将内部类在外部类中进行封装。static:内部类具备static的特性。
当内部类被static修饰后,只能直接访问外部类中的static成员,出现了访问局限。
在外部其他类中,要如何直接访问static内部类的静态成员呢?
外部类.内部类.方法
注意:
当内部类中定义了静态成员,该内部类必须是static修饰的。
当外部类中的静态方法访问内部类时,内部类也必须是静态的。
3、内部类定义规则
当描述事物时,事物的内部还有事物,该事物用内部类来描述。因为内部事物在使用外部事物的内容。
内部类定义在局部时
a、不可以被成员修饰符所修饰。
b、可以直接访问外部类中的成员,因为还持有外部类中的引用。但是不可以访问它所在的局部中的变量。只能访问被final修饰的局部变量。
二、匿名内部类
1、定义:匿名内部类其实就是内部的简写格式。
2、定义匿名内部类的前提:
内部类必须是继承一个类或者实现接口(内部类可以直接集成外部类)。
3、匿名内部类的格式:
new 父类或者接口(){定义子类的内容}
4、其实匿名内部类就是一个匿名子类对象。可以理解为带内容的对象。
5、匿名内部类中定义的方法最好不要超过三个。
三、异常
1、定义:就是程序在运行时出现不正常情况。
2、由来:问题也是现实生活中一个具体的事物,也可以通过java的类的形式进行描述,并封装成对象。其实就是java对不正常情况进行描述后的现象。
3、对于问题的划分:一种是严重的问题,一种是非严重的问题。
a、严重:java通过Error类进行描述。
对于Error一般不便携针对性的代码对其进行处理。
b、非严重:java通过Execption类进行描述。
对于Exception可以使用针对性的处理方式进行处理。
无论Error或者Exception都具有一些共性内容。
比如:不正常情况的信息,引用原因等。
异常体系:
Throwable:
|---Error
|---Exception
4、异常的处理
java提供了特有的语句进行处理。
try{
需要被检测的代码;
} catch {
捕捉到的异常
e.getMessage(); 异常信息
e.toString();异常名称:异常信息
e.printStackTrace();异常名,异常信息,异常出现的位置。
其实jvm默认的异常处理机制,就是在调用printStackTrace方法,打印异常的堆栈跟踪信息。
} finally {
一定会执行的语句;
}
5、异常声明
throws Exception 在function通过throws的关键字声明了该功能有可能会出现问题。
在函数上声明异常。
便于提高安全性,让调用处进行处理。不处理编译失败。
6、对多异常的处理
a、声明异常时,建议声明更为具体的异常。这样处理的可以更具体。
b、对方声明几个异常,就对应有几个catch块。
如果多个catch块中的异常出现继承关系,父类异常catch块放下面。
建议在catch处理时,catch中一定要定义具体处理方式。不要简单定义一句,e.printStackTrace(),也不要简单的就书写一条输出语句。
7、自定义异常
因为项目中会出现特有的问题,而这些问题并未被java所描述并封装对象。所以对于这些特有的问题可以按照java的对问题封装的思想。将特有的问题。进行自定义的异常封装。
必须是自定义类继承Exception。
继承Exception原因:
异常体系有一个特点:因为异常类和异常对象都被抛出。
他们都具备可抛性。这个可抛性是Throwable这个体系中独有的特点。
只有这个体系中的类和对象才可以呗throws和throw操作。
自定义异常时,如果该异常的发生,无法再继续进行运算,就让自定义异常继承RuntimeException
8、throws和throw的区别
throws使用在函数上。
throw使用在函数内。
throws后面跟的异常类。可以跟多个。用逗号隔开。
throw后面跟的是异常对象。
9、RuntimeException异常
Exception中有一个特殊的子类异常RuntimeException运行时异常。
如果在函数内容抛出该异常,函数上可以不用什么,编译一样通过。
如果在函数上声明了该异常。调用者可以不用进行处理,编译一样通过。
原因:
之所以不用在函数上声明,是因为不需要让调用者处理。
当该异常发生,希望程序停止。因为在运行时,出现了
无法继续运算的情况,希望停止程序后,对代码进行修正。
对于异常分两种:
a、编译时被检测的异常。
b、编译时不被检测的异常(运行时异常,RuntimeException以及其子类)
10、异常在子父类覆盖中的体现:
a、子类在覆盖父类时,如果父类的方法抛出异常,那么子类的覆盖方法,只能抛出父类的异常或该异常的子类。
b、如果父类方法抛出多个异常,那么子类的覆盖方法时,只能抛出父类异常的子集。
c、如果父类或者接口的方法中没有异常抛出,那么子类在覆盖时,也不可以抛出异常。如果子类方法发生了异常,就必须要进行try处理,绝对不能抛。
11、finally
finally代码块:定义一定执行的代码,通常用于关闭资源。
数组
描述
数组(Array)是 Java 中最基本的数据结构之一,它用于存储相同数据类型的多个元素。数组的特点是长度固定,元素存储在连续的内存空间中,支持随机访问。
数组的特点
<ul><li>类型固定:数组中的所有元素必须是相同的数据类型。</li><li>大小固定:数组一旦创建,长度不可改变。</li><li>索引访问:数组索引从 0 开始,支持随机访问(O(1) 时间复杂度)。</li><li>内存连续:数组存储在连续的内存块中,访问效率高。</li></ul>
数组的声明和初始化
一维数组
1、声明数组<br>数据类型[] 数组名; // 推荐写法<br>数据类型 数组名[]; // 兼容 C 风格,但不推荐<br>示例:<br>int[] arr; // 推荐<br>int arr[]; // 也可以,但不推荐<br><br>2、分配内存<br>数组名 = new 数据类型[数组长度];<br>示例:<br>arr = new int[5]; // 创建一个长度为 5 的 int 数组,默认值为 0<br><br>3、声明并初始化<br>int[] arr = new int[5]; // 默认所有元素为 0<br>int[] arr2 = {1, 2, 3, 4, 5}; // 直接初始化<br>int[] arr3 = new int[]{10, 20, 30}; // 另一种初始化方式<br><br>4、访问数组元素<br>System.out.println(arr2[0]); // 访问索引 0 的元素(1)<br>arr2[2] = 100; // 修改索引 2 的值<br><br>5、遍历数组<br>for (int i = 0; i < arr2.length; i++) {<br> System.out.println(arr2[i]);<br>}<br>增强 for 循环(推荐)<br>for (int num : arr2) {<br> System.out.println(num);<br>}<br>
二维数组
1、声明<br>int[][] matrix; // 推荐<br>int matrix[][]; // 兼容 C 语言风格<br><br>2、初始化<br>matrix = new int[3][4]; // 创建 3 行 4 列的二维数组,默认值为 0<br>或直接初始化:<br>int[][] matrix = {<br> {1, 2, 3},<br> {4, 5, 6},<br> {7, 8, 9}<br>};<br><br>3、访问元素<br>System.out.println(matrix[1][2]); // 访问第 2 行第 3 列的元素<br><br>4、遍历二维数组<br>for (int i = 0; i < matrix.length; i++) {<br> for (int j = 0; j < matrix[i].length; j++) {<br> System.out.print(matrix[i][j] + " ");<br> }<br> System.out.println();<br>}<br>增强 for 循环<br>for (int[] row : matrix) {<br> for (int num : row) {<br> System.out.print(num + " ");<br> }<br> System.out.println();<br>}<br>
不规则(Jagged)数组
Java 允许创建行数固定,但列数不同的不规则数组。<br><br>int[][] jaggedArray = new int[3][]; // 3 行但列数未指定<br>jaggedArray[0] = new int[2]; // 第一行 2 列<br>jaggedArray[1] = new int[3]; // 第二行 3 列<br>jaggedArray[2] = new int[4]; // 第三行 4 列<br><br>遍历不规则数组:<br>for (int i = 0; i < jaggedArray.length; i++) {<br> for (int j = 0; j < jaggedArray[i].length; j++) {<br> System.out.print(jaggedArray[i][j] + " ");<br> }<br> System.out.println();<br>}<br>
数组的常见操作
复制数组
1、手动复制<br>int[] arr1 = {1, 2, 3, 4, 5};<br>int[] arr2 = new int[arr1.length];<br><br>for (int i = 0; i < arr1.length; i++) {<br> arr2[i] = arr1[i];<br>}<br><br>2、使用 System.arraycopy()<br>System.arraycopy(arr1, 0, arr2, 0, arr1.length);<br>参数:<br><ul><li>arr1:源数组</li><li>0:源数组起始索引</li><li>arr2:目标数组</li><li>0:目标数组起始索引</li><li>arr1.length:复制的元素个数</li></ul><br>3、使用 Arrays.copyOf()<br>import java.util.Arrays;<br><br>int[] arr3 = Arrays.copyOf(arr1, arr1.length);<br><br>4、使用 clone()<br>int[] arr4 = arr1.clone();<br>
排序数组
1、使用 Arrays.sort()(默认升序)<br>import java.util.Arrays;<br><br>int[] arr = {5, 2, 9, 1, 6};<br>Arrays.sort(arr); // 排序后:{1, 2, 5, 6, 9}<br><br>2、使用 Arrays.sort(arr, Comparator.reverseOrder())(降序)<br>import java.util.Arrays;<br>import java.util.Collections;<br><br>Integer[] arr = {5, 2, 9, 1, 6}; // 必须使用 Integer[] 而非 int[]<br>Arrays.sort(arr, Collections.reverseOrder());<br>
查找元素
1、遍历查找<br>int[] arr = {1, 2, 3, 4, 5};<br>int target = 3;<br>boolean found = false;<br><br>for (int num : arr) {<br> if (num == target) {<br> found = true;<br> break;<br> }<br>}<br>System.out.println("找到目标元素:" + found);<br><br>2、使用 Arrays.binarySearch()(前提是数组必须已排序)<br>import java.util.Arrays;<br><br>int[] arr = {1, 2, 3, 4, 5};<br>int index = Arrays.binarySearch(arr, 3);<br>System.out.println("索引:" + index); // 输出:2<br>
计算数组最大值和最小值
int[] arr = {5, 2, 9, 1, 6};
int max = arr[0];
int min = arr[0];
for (int num : arr) {
if (num > max) max = num;
if (num < min) min = num;
}
System.out.println("最大值:" + max);
System.out.println("最小值:" + min);
Arrays 工具类
<br>
总结
<ul><li>数组的大小固定,必须先声明长度。</li><li>数组索引从 0 开始。</li><li>Arrays 工具类提供了丰富的操作方法。</li><li>多维数组可以是规则或不规则的。</li><li>使用 System.arraycopy()、clone()、Arrays.copyOf() 复制数组。</li></ul>Java 数组是高效的数据存储方式,掌握其用法有助于提升编程能力! 🚀
整理
一、数组的定义<br>1、概念:同一种类型数据的集合,其实数组就是一个容器。<br>2、数组的好处:可以自动给数组的元素从0开始编号,方便操作这些元素。<br>3、格式:<br>int[] x = new int[3];<br>int 代表的是元素类型。<br>x 是数组类型。<br>二、数组的内存结构<br>1、栈内存特点:数据使用完毕,会自动释放空间。<br>2、堆内存的特点:<br><br>三、数组排序<br>1、选择排序<br>内循环一次,最值出现在头角标位置上。<br>public static void selectSort(int[] arr){<br>for(int x = 0; x < arr.length-1; x++){<br>for(int y = x+1; y <arr.length; y++){<br>if(arr[x] > arr[y]){<br>int temp = arr[x];<br>arr[x] = arr[y];<br>arr[y] = temp;<br>}<br>}<br>}<br>}<br>2、冒泡排序<br>相邻的两个元素进行比较,如果符合条件换位。<br>第一圈:最值出现在最后一位。<br>public static void bubbleSort(int[] arr){<br>for(int x = 0; x < arr.length-1; x++){<br>for(int y = 0; y < arr.length-x-1; y++){//-x:让每一次比较的元素减少,-1:避免角标越界<br>if(arr[y] > arr[y+1]){<br>int temp = arr[y];<br>arr[y] = arr[y+1];<br>arr[y+1] = temp;<br>}<br>}<br>}<br>}<br>3、位置置换功能抽取<br>无论什么排序,都需要对满足条件的元素进行位置置换。所以可以把这部分相同的代码提取出来,单独封装成一个函数。<br>public static void swap(int[] arr, int a, int b){<br>int temp = arr[a];<br>arr[a] = arr[b];<br>arr[b] = temp;<br>}<br>4、折半查找<br>提高效率、但是必须要保证该数组是有序的。<br>第一种:<br>public static int halfSearch(int[] arr, int key){<br>int min,max,mid;<br>min = 0;<br>max = arr.length-1;<br>mid = (max+min)/2;<br><br>while(arr[mid] != key){<br>if(arr[mid] > key){<br>min = mid +1;<br>} else {<br>max = mid -1;<br>}<br>if(min > max){<br>return -1;<br>}<br>mid = (max+min)/2;<br>}<br>return mid;<br>}<br>第二种:<br>public static int halfSearch_2(int [] arr, int key){<br>int min = 0,max = arr.length-1, mid;<br>while(min <= max){<br><br>mid = (max+min)>>1;//<br><br>if(key>arr[mid]){<br>min = mid +1;<br>} else if(key < arr[mid]){<br>max = mid -1;<br>} else {<br>return mid;<br>}<br>}<br>return -1;<br>}<br>
集合
描述
Java 集合框架(Java Collections Framework, JCF)是 Java 提供的一个强大工具集,用于存储、操作和管理数据集合。它包含List、Set、Queue 和 Map 等多种数据结构,并提供了常用算法支持(如排序、搜索等)。
集合框架概述
<br>
Collections 工具类
<br>
List 接口(有序,可重复)
<br>
ArrayList
import java.util.ArrayList;
public class TestArrayList {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Java");
list.add("Python");
list.add("C++");
System.out.println(list.get(1)); // Python
list.remove("C++");
System.out.println(list); // [Java, Python]
}
}
底层实现<br>
ArrayList 是基于动态数组(Object[] 数组)实现的。初始时,ArrayList 会创建一个容量为 10 的数组,当存储的元素超出数组容量时,ArrayList 会自动扩容。扩容策略通常是原来容量的 1.5 倍。
特点
<ul><li><span style="font-size: inherit;">查询效率高:由于内部是数组,ArrayList 支持通过索引快速访问元素,时间复杂度为 O(1)。</span></li><li><span style="font-size: inherit;">插入和删除效率较低:插入和删除操作的时间复杂度通常为 O(n),尤其是在数组中间进行插入或删除时,因为需要移动大量元素。</span></li><li><span style="font-size: inherit;">扩容时的性能开销:当 ArrayList 达到最大容量时,它会进行扩容,并将原数组中的元素复制到新数组,这会带来额外的性能开销。</span></li></ul><br>
适合场景
适用于查询操作较多,插入和删除操作较少的场景。
LinkedList
import java.util.LinkedList;
public class TestLinkedList {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
list.add(10);
list.add(20);
list.addFirst(5);
list.addLast(30);
System.out.println(list); // [5, 10, 20, 30]
list.removeFirst();
System.out.println(list); // [10, 20, 30]
}
}
底层实现<br>
LinkedList 是基于双向链表实现的。每个元素(节点)包含三个部分:数据、指向前一个节点的指针、指向后一个节点的指针。链表的头和尾分别保存对第一个节点和最后一个节点的引用。
特点
<ul><li><span style="font-size: inherit;">插入和删除效率高:在链表的头部和尾部插入和删除操作的时间复杂度为 O(1)(只需修改指针)。但在链表的中间插入或删除时,需要遍历链表,时间复杂度为 O(n)。</span></li><li><span style="font-size: inherit;">查询效率较低:由于链表不能通过索引直接访问元素,需要从头部开始遍历,查询的时间复杂度为 O(n)。</span></li><li><span style="font-size: inherit;">内存消耗较大:每个元素除了存储数据外,还需要存储前后指针,这导致 LinkedList 的内存占用比 ArrayList 更大。</span></li></ul>
适用场景
适用于频繁插入和删除操作的场景,特别是在头部或尾部插入删除。
Vector
底层实现<br>
Vector 的底层实现与 ArrayList 类似,也是基于动态数组实现的。但与 ArrayList 不同的是,Vector 在扩容时的增量是原数组大小的两倍。这样,Vector 可能会比 ArrayList 占用更多的内存。
特点
<ul><li><span style="font-size: inherit;">线程安全:Vector 的方法是同步的,这意味着它在多线程环境中是安全的。</span></li><li><span style="font-size: inherit;">性能:由于同步开销,Vector 的性能相对较差,一般不推荐使用。通常可以使用 ArrayList 或者在需要线程安全的情况下,使用 CopyOnWriteArrayList。</span></li><li>性能问题:由于每次方法调用时都会进行同步,这使得 Vector 在单线程或线程不敏感的场景下性能较差。同步开销导致了性能瓶颈。</li></ul>
适用场景
如果你在多线程环境下需要线程安全的动态数组,Vector 是一个选择,但大多数情况下可以通过其他线程安全集合类(如 CopyOnWriteArrayList)来替代。
CopyOnWriteArrayList
底层实现<br>
<ul><li>CopyOnWriteArrayList 是线程安全的 List 实现,基于数组实现。其核心特性是写时复制(Copy-on-Write),即每次对集合进行修改操作时(如 add、remove、set 等),都会创建一个新的数组来存储数据,而不是修改原有的数据数组。</li><li>读取操作不需要加锁,因此它非常适合读多写少的场景。</li></ul>
特点
<ul><li><span style="font-size: inherit;">线程安全:所有的修改操作(如插入、删除)会创建一个新的数组,因此不会影响正在执行的读取操作。</span></li><li><span style="font-size: inherit;">写操作性能差:由于每次写操作都要复制整个数组,写操作的性能较差。每次修改都需要重新分配和复制数组,性能瓶颈较明显。</span></li><li><span style="font-size: inherit;">读取操作快速:读操作不需要加锁,性能较好。</span></li></ul>
适用场景
适用于读多写少的场景,特别是在需要高并发的读操作时。
各实现类的对比
<br>
总结
<ul><li>如果你需要频繁的查询操作,并且不关心插入删除的性能,ArrayList 是一个不错的选择。</li><li>如果你需要频繁在列表的头尾进行插入和删除操作,LinkedList 是更优的选择。</li><li>如果你需要一个线程安全的 List,并且性能要求不是特别高,可以使用 Vector(不过 CopyOnWriteArrayList 更适合读取操作为主的场景)。</li><li>CopyOnWriteArrayList 是一个很适合读多写少的场景,它的线程安全机制保证了多线程的安全性,但写操作性能相对较差。</li></ul>根据具体的业务需求,选择合适的实现类可以提高程序的性能。
面试题
ArrayList 和 LinkedList 有什么区别?
ArrayList 是基于动态数组实现的,查询操作较快,但插入和删除操作较慢。LinkedList 是基于双向链表实现的,插入和删除操作较快,但查询操作较慢。
Vector 和 ArrayList 的区别是什么?
Vector 与 ArrayList 类似,但 Vector 在扩容时会将数组容量增加到原大小的两倍,并且它是线程安全的(通过同步方法实现)。而 ArrayList 通常扩容为原大小的 1.5 倍,并且不是线程安全的。
什么是 CopyOnWriteArrayList?它为什么适用于读多写少的场景?
CopyOnWriteArrayList 是一种线程安全的 List 实现,通过写时复制的方式保证线程安全。每次修改操作都会复制一个新的数组,因此读取操作不需要加锁,适合读多写少的场景。
ArrayList 的底层实现原理是什么?
面试问题:<br><ul><li>ArrayList 是如何存储元素的?</li><li>ArrayList 是如何扩容的?</li><li>ArrayList 的查询、插入、删除操作的时间复杂度是多少?</li></ul><br>答案:<br><ul><li>存储方式:ArrayList 底层是基于动态数组(Object[])实现的,元素按顺序存储在数组中。</li><li>扩容机制:当 ArrayList 的容量不足时,它会自动扩容,扩容的比例通常是当前容量的 1.5 倍。扩容时,会创建一个新的更大的数组,并将原数组中的元素拷贝到新数组中。</li><li>时间复杂度:<br>查询操作:O(1)(通过索引直接访问数组元素)。<br>插入操作:O(n)(在数组中间插入时,需要移动元素)。<br>删除操作:O(n)(在数组中删除元素时,也需要移动元素)。</li></ul>
LinkedList 的底层实现原理是什么?
面试问题:<br><ul><li>LinkedList 是如何存储元素的?</li><li>LinkedList 和 ArrayList 的区别是什么?</li><li>LinkedList 在插入和删除操作上的效率如何?</li></ul><br>答案:<br><ul><li>存储方式:LinkedList 底层是基于双向链表实现的。每个元素(节点)包含三部分:数据、指向前一个节点的指针、指向后一个节点的指针。</li><li>与 ArrayList 的区别:LinkedList 是链表结构,ArrayList 是基于数组的结构。LinkedList 的查询操作较慢(O(n)),但是插入和删除操作(特别是在头部和尾部)非常高效(O(1))。</li><li>时间复杂度:</li><li>查询操作:O(n)(需要遍历链表)。<br>插入操作:O(1)(在头尾插入,移动指针即可)。<br>删除操作:O(1)(在头尾删除,修改指针即可)。</li></ul>
Vector 的底层实现原理是什么?
面试问题:<br><ul><li>Vector 与 ArrayList 有什么不同?</li><li>Vector 如何扩容?</li><li>Vector 是如何保证线程安全的?</li></ul><br>答案:<br><ul><li>存储方式:Vector 与 ArrayList 相似,底层也是基于动态数组实现的。不同之处在于,Vector 在扩容时是将容量增加为原来大小的两倍,而 ArrayList 是 1.5 倍。</li><li>扩容机制:Vector 的扩容机制是每次扩容时将原数组大小翻倍(2x 扩容)。这可能导致在内存占用上更为浪费,但在某些场景下可以减少扩容的频率。</li><li>线程安全:Vector 在方法调用上是同步的,因此它是线程安全的。但是同步机制带来了性能上的开销,不推荐在单线程或性能要求较高的场景中使用。</li></ul>
CopyOnWriteArrayList 的底层实现原理是什么?
面试问题:<br><ul><li>CopyOnWriteArrayList 是如何保证线程安全的?</li><li>CopyOnWriteArrayList 如何实现读写操作?</li><li>CopyOnWriteArrayList 的性能特点是什么?</li></ul><br>答案:<br><ul><li>线程安全实现:CopyOnWriteArrayList 采用写时复制(Copy-on-Write)的方式来保证线程安全。每次对列表的修改(如 add、remove)都会创建一个新的数组副本,修改副本数组的内容,而不会直接修改原数组。读取操作不需要加锁,因此是非常高效的。</li><li>读写操作:<br>读取操作:所有的读取操作(如 get、size)直接操作原始数据,无需加锁,性能非常高。<br>写操作:每次修改都会复制整个数组(这导致写操作性能较差),然后修改新数组并替换原数组。</li></ul><ul><li>性能特点:适用于读多写少的场景,因为它在写操作时会复制整个数组,这对于写操作频繁的场景性能不佳。读操作的性能几乎不受影响,适合并发读的场景。</li></ul><br>
ArrayList 和 LinkedList 的扩容机制有什么不同?
面试问题:<br><ul><li>ArrayList 的扩容机制和 LinkedList 的扩容机制有何不同?</li></ul><br>答案:<br><span style="font-size: inherit;">1. ArrayList 扩容机制:</span><br><ul><li>当 ArrayList 达到最大容量时,会通过扩容来增加容量。扩容通常是当前数组容量的 1.5 倍。扩容时,会创建一个新的数组,并将原数组中的元素复制到新数组中。</li></ul><span style="font-size: inherit;">2. LinkedList 扩容机制:</span><br><ul><li>LinkedList 是基于链表的,它没有固定的容量概念,因为链表节点是动态分配的。没有数组那样的“扩容”过程,链表只需要通过指针的重新连接来增加或删除元素。</li></ul>
ArrayList 和 LinkedList 的性能差异?
面试问题:<br><ul><li>在什么情况下应该使用 ArrayList,在什么情况下应该使用 LinkedList?</li><li>ArrayList 和 LinkedList 的性能差异在哪些方面表现最明显?</li></ul><br>答案:<br><ul><li>ArrayList 适合查询操作较多的场景,特别是需要通过索引快速访问元素的场合。</li><li>LinkedList 适合插入和删除操作较多的场景,尤其是在头部或尾部插入删除时效率较高。</li><li>性能差异:<br>查询操作:ArrayList 的查询操作时间复杂度为 O(1),而 LinkedList 的查询操作时间复杂度为 O(n),因为需要遍历链表。<br>插入删除操作:ArrayList 的插入和删除操作(尤其是中间插入删除)时间复杂度为 O(n),而 LinkedList 在头部或尾部的插入和删除操作时间复杂度为 O(1)。</li></ul><br>
Map 接口(键值对存储)
<br>在 Java 中,Map 是一个用于存储键值对的集合接口,允许通过键来映射到值。与 List 不同,Map 是无序的(除非使用特殊的实现类如 TreeMap)。常见的 Map 实现类包括:<br><br>1. HashMap<br>2. TreeMap<br>3. LinkedHashMap<br>4. Hashtable<br>5. ConcurrentHashMap<br>6. IdentityHashMap<br>7. WeakHashMap<br>下面我们将详细讲解每个实现类的底层实现原理,并对它们进行对比。<br>
HashMap
import java.util.HashMap;
import java.util.Map;
public class TestHashMap {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("Alice", 25);
map.put("Bob", 30);
map.put("Alice", 28); // 覆盖旧值
System.out.println(map.get("Alice")); // 28
System.out.println(map.containsKey("Bob")); // true
map.remove("Bob");
}
}
底层实现原理
<ul><li>HashMap 是基于哈希表(HashMap 底层通过数组 + 链表或红黑树实现)实现的。它的基本思想是通过键的哈希值来决定元素在数组中的位置。</li><li>扩容机制:当 HashMap 中的元素个数超过负载因子(默认值是 0.75)时,会进行扩容。扩容是通过将数组容量加倍,并重新计算每个键值对的哈希值来完成的。</li><li>链表与红黑树:如果数组中的某个桶(bucket)存在大量元素(默认超过 8 个元素),HashMap 会将链表转换为红黑树来提高性能,降低查找时间复杂度。</li></ul>
特点
特点:<br><ul><li>查询效率:通过哈希表,查询、插入和删除操作的平均时间复杂度为 O(1)。</li><li>线程安全:HashMap 是非线程安全的。</li><li>性能:由于没有进行同步控制,相比于 Hashtable,它的性能更好。</li></ul>
TreeMap
import java.util.TreeMap;
public class TestTreeMap {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
map.put(3, "C");
map.put(1, "A");
map.put(2, "B");
System.out.println(map); // {1=A, 2=B, 3=C}(按 key 升序)
}
}
底层实现原理
<ul><li>TreeMap 是基于红黑树(Red-Black Tree)实现的。红黑树是一种自平衡的二叉搜索树,保证了键的顺序。</li><li>有序性:TreeMap 会根据键的自然顺序或自定义比较器来排序元素。</li></ul>
特点
<ul><li>查询效率:查找、插入、删除操作的时间复杂度为 O(log n),因为树的高度是对数级别的。</li><li>线程安全:TreeMap 不是线程安全的。</li><li>有序性:元素是按照键的自然顺序或者根据构造时指定的比较器顺序排列的。</li></ul>
LinkedHashMap
底层实现原理
<ul><li>LinkedHashMap 继承自 HashMap,并且在 HashMap 的基础上增加了双向链表结构(即每个元素都有指向前一个元素和后一个元素的指针)。</li><li>顺序性:它可以保持插入顺序或者按访问顺序(通过构造时设置 accessOrder 参数)排序。</li></ul>
特点
<ul><li>查询效率:由于其底层是基于哈希表,查询、插入和删除操作的时间复杂度为 O(1)。</li><li>有序性:保持插入顺序或访问顺序。</li><li>线程安全:LinkedHashMap 不是线程安全的。</li></ul>
Hashtable
底层实现原理
<ul><li>Hashtable 是基于哈希表实现的,和 HashMap 类似,区别在于 Hashtable 是线程安全的,并且它的扩容机制与 HashMap 不完全相同(Hashtable 扩容时会按照原容量的 2 倍进行扩展)。</li><li>线程安全:Hashtable 是通过对所有方法加锁来实现线程安全的。</li></ul>
特点
<ul><li>查询效率:与 HashMap 相似,查询、插入和删除操作的平均时间复杂度为 O(1)。</li><li>线程安全:Hashtable 是线程安全的,但由于方法同步的开销,它的性能较差。</li><li>不允许 null 键和值:Hashtable 不允许 null 键或 null 值。</li></ul>
ConcurrentHashMap
底层实现原理
<ul><li>ConcurrentHashMap 采用了分段锁(Segment Lock)技术来实现高效的并发访问。它将 Map 分成多个段(Segment),每个段都有自己的锁,只有操作同一段的数据时,才会发生锁竞争。它通过将哈希表划分为多个“段”,提高了并发度。</li><li>扩容机制:它采用分段扩容,不会像 HashMap 那样在全表扩容时锁住整个表,避免了锁竞争。</li></ul>
特点
<ul><li>线程安全:ConcurrentHashMap 是线程安全的,支持高并发的读取和写入操作。</li><li>查询效率:查询操作的时间复杂度为 O(1),插入和删除操作在低竞争情况下也接近 O(1)。</li><li>写操作效率:在高并发情况下,写操作比 Hashtable 和 synchronizedMap 更高效。</li></ul>
IdentityHashMap
底层实现原理
IdentityHashMap 和 HashMap 类似,都是基于哈希表实现的,但是它与 HashMap 的区别在于,它通过对象的内存地址进行比较,而不是通过 equals() 方法来比较键值。
特点
<ul><li>键比较方式:IdentityHashMap 使用 == 来比较键,而不是 equals() 方法。因此它适用于一些需要通过对象的内存地址来比较键的场景。</li><li>查询效率:查询、插入和删除操作的时间复杂度为 O(1)。</li></ul>
WeakHashMap
底层实现原理
WeakHashMap 是一种特殊的 Map 实现,它使用了弱引用(WeakReference)来存储键。当键不再被引用时,垃圾回收器会自动回收键及其对应的值。
特点
<ul><li>自动垃圾回收:WeakHashMap 中的键如果没有强引用,它们会被垃圾回收器回收。</li><li>查询效率:查询、插入和删除操作的时间复杂度为 O(1)。</li></ul>
Map 各实现类的对比
<br>
总结
<ul><li>HashMap:最常用的 Map 实现类,适用于一般的无序、非线程安全的场景。</li><li>TreeMap:适用于需要按键排序的场景,保证键的有序性。</li><li>LinkedHashMap:保留插入顺序或访问顺序,适用于需要维持元素顺序的场景。</li><li>Hashtable:已经较为过时,使用较少,通常推荐使用 ConcurrentHashMap 替代。</li><li>ConcurrentHashMap:适用于多线程环境,具有较高的</li></ul>
面试题
ConcurrentHashMap 和 Hashtable 的底层实现原理有什么区别?
面试问题:<br><ul><li>ConcurrentHashMap 和 Hashtable 有什么区别?</li><li>ConcurrentHashMap 是如何实现线程安全的?</li></ul><br>答案:<br><ul><li>底层实现:<br>Hashtable 是一个线程安全的哈希表,它通过对整个表的同步来保证线程安全。这意味着当一个线程访问某个元素时,其他线程需要等待,导致性能瓶颈。<br>ConcurrentHashMap 通过分段锁(Segment Locks)机制进行优化,内部将数据分为多个段(Segment),每个段可以独立加锁。因此,在多线程环境下,不同段的操作不会互相阻塞,提升了并发性能。</li></ul><ul><li>线程安全实现:<br>Hashtable 通过对整个哈希表加锁实现线程安全。<br>ConcurrentHashMap 通过分段锁机制和精细化的锁控制(如只锁需要修改的段)实现高效的并发访问。</li></ul><br>
TreeMap 和 HashMap 的底层实现有何不同?
面试问题:<br><ul><li>TreeMap 和 HashMap 的底层实现有什么区别?</li><li>TreeMap 是如何保持元素有序的?</li></ul><br>答案:<br><ul><li>底层实现:<br>HashMap 是基于哈希表实现的,元素的存储顺序与插入顺序无关。<br>TreeMap 是基于红黑树(自平衡二叉搜索树)实现的,因此元素是按照键的自然顺序或指定的比较器顺序进行排序的。</li></ul><ul><li>排序机制:<br>TreeMap 会根据键的顺序对元素进行排序(自然排序或自定义比较器排序),HashMap 没有排序功能,它是无序的。</li></ul><br>
HashMap 的底层实现原理是什么?
面试问题:<br><ul><li>HashMap 如何存储元素?</li><li>HashMap 的扩容机制是怎样的?</li><li>HashMap 是如何处理哈希冲突的?</li></ul>答案:<br><ul><li>存储方式:HashMap 底层使用数组 + 链表(或红黑树)的方式存储数据。每个键值对通过哈希值映射到数组的某个桶(bucket)中。</li><li>扩容机制:HashMap 默认负载因子为 0.75。当元素个数超过当前容量的 75% 时,会进行扩容(将数组大小加倍)。</li><li>哈希冲突处理:当两个键的哈希值相同且落入同一个桶时,HashMap 使用链表存储这些元素(JDK 1.8 之后,链表长度大于 8 时,会转换为红黑树,以提高查找效率)。</li></ul>
TreeMap 的底层实现原理是什么?
面试问题:<br><ul><li>TreeMap 是如何保证元素有序的?</li><li>TreeMap 的查询、插入、删除操作的时间复杂度是多少?</li></ul>答案:<br><ul><li>有序性:TreeMap 底层使用红黑树(自平衡的二叉搜索树)。元素按照键的自然顺序或构造时提供的 Comparator 排序。</li><li>时间复杂度:TreeMap 的查询、插入和删除操作的时间复杂度为 O(log n),因为红黑树的高度是对数级别的。</li></ul>
LinkedHashMap 的底层实现原理是什么?
面试问题:<br><ul><li>LinkedHashMap 是如何维护插入顺序的?</li><li>LinkedHashMap 的查询效率如何?</li></ul>答案:<br><ul><li>存储方式:LinkedHashMap 底层是基于 HashMap 实现的,同时在每个元素中维护了指向前一个和后一个元素的指针,从而形成双向链表。这使得它可以按插入顺序或访问顺序(根据构造时的参数)存储元素。</li><li>查询效率:由于底层是哈希表结构,LinkedHashMap 的查询、插入和删除操作的时间复杂度为 O(1),与 HashMap 相同。</li></ul>
Hashtable 的底层实现原理是什么?
面试问题:<br><ul><li>Hashtable 和 HashMap 有什么区别?</li><li>Hashtable 如何处理哈希冲突?</li><li>Hashtable 的扩容机制是什么?</li></ul>答案:<br><ul><li>存储方式:Hashtable 底层是基于哈希表实现的,和 HashMap 类似,但 Hashtable 是线程安全的。</li><li>线程安全:Hashtable 通过对所有方法进行同步来保证线程安全,虽然保证了线程安全,但同步带来了性能开销。</li><li>哈希冲突处理:Hashtable 使用链表法来处理哈希冲突。</li><li>扩容机制:Hashtable 的默认负载因子为 0.75,扩容时会将数组的容量翻倍,扩容时会对整个 Hashtable 锁定,导致性能问题。</li></ul>
ConcurrentHashMap 的底层实现原理是什么?
面试问题:<br><ul><li>ConcurrentHashMap 是如何保证线程安全的?</li><li>ConcurrentHashMap 的扩容是如何进行的?</li><li>ConcurrentHashMap 的查询效率如何?</li></ul>答案:<br><ul><li>线程安全实现:ConcurrentHashMap 采用了分段锁的机制,将整个哈希表划分为多个段(Segment)。每个段都有自己的锁,保证并发操作时只有操作同一段的数据才会发生锁竞争。这样,多个线程可以并发访问不同段的数据,减少锁的争用。</li><li>扩容机制:ConcurrentHashMap 通过分段扩容的方式扩展容量,而不是像 HashMap 那样一次性扩容整个表,因此在高并发下扩容操作的影响较小。</li><li>查询效率:查询操作的时间复杂度是 O(1),由于采用了分段锁,写操作也能在低竞争情况下达到 O(1) 的时间复杂度。</li></ul>
IdentityHashMap 的底层实现原理是什么?
面试问题:<br><ul><li>IdentityHashMap 和 HashMap 有什么区别?</li><li>IdentityHashMap 的键是如何比较的?</li></ul>答案:<br><ul><li>存储方式:IdentityHashMap 底层和 HashMap 类似,都是通过哈希表实现的。但不同之处在于,IdentityHashMap 使用对象的内存地址进行键的比较,而不是通过 equals() 方法进行比较。</li><li>键比较方式:IdentityHashMap 使用 == 运算符来比较键(对象的内存地址),而 HashMap 使用 equals() 方法来比较键。</li></ul>
WeakHashMap 的底层实现原理是什么?
面试问题:<br><ul><li>WeakHashMap 是如何保证键值的自动回收的?</li><li>WeakHashMap 和 HashMap 的主要区别是什么?</li></ul>答案:<br><ul><li>存储方式:WeakHashMap 底层也是基于哈希表实现的。不同的是,WeakHashMap 使用弱引用(WeakReference)来存储键。弱引用的对象在垃圾回收时,如果没有强引用指向它,就会被回收。</li><li>自动回收:当 WeakHashMap 中的键对象不再被强引用时,垃圾回收器会自动回收这些键对象及其对应的值。</li><li>区别:与 HashMap 不同,WeakHashMap 中的键在没有强引用的情况下会被自动回收,这对于缓存类应用非常有用。</li></ul>
HashMap 如何处理哈希冲突?
面试问题:<br><ul><li>HashMap 如何处理哈希冲突?</li><li>当桶内链表长度过长时,HashMap 是如何优化的?</li></ul>答案:<br><ul><li>哈希冲突处理:HashMap 通过链表法来解决哈希冲突。多个哈希值相同的元素会存储在同一个桶中,形成链表。</li><li>链表转红黑树:当某个桶中的链表长度超过 8(JDK 1.8 及之后的版本),HashMap 会将链表转换为红黑树,从而将查找、插入的时间复杂度从 O(n) 降低到 O(log n),优化性能。</li></ul>
TreeMap 和 HashMap 的区别是什么?
面试问题:<br><ul><li>TreeMap 和 HashMap 的底层实现有什么不同?</li><li>TreeMap 和 HashMap 在性能上的区别是什么?</li></ul>答案:<br><ul><li>底层实现:TreeMap 是基于红黑树实现的,而 HashMap 是基于哈希表实现的。</li><li>有序性:TreeMap 会保持元素的排序(自然顺序或通过比较器),而 HashMap 不保证元素顺序。</li><li>查询性能:HashMap 的查询操作时间复杂度是 O(1),而 TreeMap 的查询操作时间复杂度是 O(log n),因为红黑树的查找是对数级别的。</li></ul>
Hashtable 和 ConcurrentHashMap 的区别是什么?
面试问题:<br><ul><li>Hashtable 和 ConcurrentHashMap 在多线程环境下的表现有什么区别?</li><li>Hashtable 是如何保证线程安全的?</li></ul>答案:<br>线程安全:<br><ul><li>Hashtable 通过对每个方法加锁来保证线程安全,导致高并发时性能较差。</li><li>ConcurrentHashMap 通过分段锁机制进行高效的线程安全保证,不同的段可以并发访问,因此性能比 Hashtable 更优。</li><li>性能:ConcurrentHashMap 提供更高的并发性能,支持高效的读写操作,而 Hashtable 由于整体加锁,性能较低。</li></ul>
HashMap 中为什么要重写 hashCode() 和 equals() 方法?
面试问题:<br><ul><li>HashMap 中的 hashCode() 和 equals() 方法如何影响元素的存储和查找?</li></ul>答案:<br><ul><li>hashCode() 方法:hashCode() 用于确定元素的哈希值,HashMap 根据哈希值将元素放入不同的桶中。两个对象如果有相同的 hashCode(),会导致哈希冲突。</li><li>equals() 方法:在发生哈希冲突时,HashMap 会使用 equals() 方法来进一步比较两个对象是否相等。如果两个对象的 equals() 方法返回 true,则认为它们是相同的,不会被插入到集合中。</li></ul>
Set 接口(无序,不可重复)
<br>Set 是一个不允许重复元素的集合,它继承自 Collection 接口,主要用于存储不重复的元素。Java 中常见的 Set 实现类包括:HashSet、LinkedHashSet、TreeSet、EnumSet 和 CopyOnWriteArraySet 等。<br>
HashSet
import java.util.HashSet;<br><br>public class TestHashSet {<br> public static void main(String[] args) {<br> HashSet<String> set = new HashSet<>();<br> set.add("Apple");<br> set.add("Banana");<br> set.add("Apple"); // 重复元素不会添加<br><br> System.out.println(set); // 可能输出 [Banana, Apple](无序)<br> }<br>}<br>
底层实现
<ul><li>HashSet 是基于哈希表(HashMap)实现的,元素是通过其 hashCode() 值进行存储的。</li><li>每个元素的存储位置由其 hashCode() 确定,哈希冲突通过链表或红黑树进行解决。</li></ul>
特点
<ul><li>查询效率:平均情况下,插入、删除、查找操作的时间复杂度为 O(1)。</li><li>无序性:HashSet 不保证元素的顺序,元素的存储顺序和输出顺序可能不同。</li><li>线程安全:HashSet 是非线程安全的,不适合在并发环境中直接使用。</li></ul>
扩容机制
默认的负载因子是 0.75,当元素个数超过当前容量的 75% 时,HashSet 会进行扩容,扩容过程会导致性能下降。
TreeSet
import java.util.TreeSet;
public class TestTreeSet {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(5);
set.add(2);
set.add(8);
System.out.println(set); // [2, 5, 8](升序排列)
}
}
底层实现
TreeSet 是基于红黑树实现的,红黑树是一种自平衡的二叉搜索树,元素按自然顺序或通过比较器进行排序。
特点
<ul><li>有序性:TreeSet 会按照元素的自然顺序或通过构造时提供的 Comparator 进行排序。</li><li>查询效率:查询、插入和删除操作的时间复杂度是 O(log n),因为树的高度是对数级别的。</li><li>线程安全:TreeSet 是非线程安全的。</li></ul>
LinkedHashSet
底层实现
LinkedHashSet 继承自 HashSet,并在 HashSet 的基础上增加了双向链表(LinkedHashMap)来维护元素的插入顺序。
特点
<ul><li>有序性:LinkedHashSet 保持插入顺序或访问顺序(通过构造时的 accessOrder 参数)。</li><li>查询效率:与 HashSet 相同,平均情况下操作的时间复杂度为 O(1)。</li><li>线程安全:LinkedHashSet 是非线程安全的。</li></ul>
EnumSet
底层实现
EnumSet 是 Set 接口的一个特殊实现,专门用于存储枚举类型的元素。它的底层使用 bit vector(位向量)来存储元素,从而提供高效的性能。
特点
<ul><li>高效性:EnumSet 在存储枚举类型时非常高效,通常比其他 Set 实现类性能更好。</li><li>有序性:EnumSet 会根据枚举的定义顺序来存储元素。</li><li>线程安全:EnumSet 不是线程安全的。</li></ul>
CopyOnWriteArraySet
底层实现
CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 实现的,使用写时复制的方式(即每次写操作时都会复制原始数组)。
特点
<ul><li>线程安全:CopyOnWriteArraySet 是线程安全的,适用于读多写少的场景。</li><li>性能问题:由于每次写操作都要复制数组,性能开销较大,因此不适用于写操作频繁的场景。</li></ul>
面试题
HashSet 的底层实现原理是什么?
面试问题:<br><ul><li>HashSet 是如何存储元素的?</li><li>HashSet 如何处理哈希冲突?</li><li>HashSet 是如何保证元素唯一性的?</li></ul>答案:<br><ul><li>存储方式:HashSet 底层是基于 HashMap 实现的。每个元素作为 HashMap 的键存储,值是一个固定的常量。通过 hashCode() 值确定存储位置。</li><li>哈希冲突处理:和 HashMap 类似,HashSet 使用链表法来处理哈希冲突,JDK 1.8 之后如果链表长度大于 8,会转为红黑树。</li><li>唯一性:HashSet 通过键的 hashCode() 和 equals() 方法判断元素是否唯一。若两个元素的 hashCode() 相同且 equals() 返回 true,则认为它们是相同的元素。</li></ul>
TreeSet 的底层实现原理是什么?
面试问题:<br><ul><li>TreeSet 是如何保证元素有序的?</li><li>TreeSet 如何处理重复元素?</li></ul>答案:<br><ul><li>有序性:TreeSet 底层使用红黑树(自平衡的二叉查找树)。元素根据自然顺序或构造时提供的 Comparator 排序。</li><li>去重机制:TreeSet 会自动去除重复元素。它通过元素的 compareTo() 方法(或 Comparator)来判断元素是否相等。两个元素如果是相同的,根据比较结果会被认为是重复的,不能加入集合中。</li></ul>
LinkedHashSet 的底层实现原理是什么?
面试问题:<br><ul><li>LinkedHashSet 和 HashSet 的区别是什么?</li><li>LinkedHashSet 如何保证元素的插入顺序?</li></ul>答案:<br><ul><li>存储方式:LinkedHashSet 底层是基于 HashMap 实现的,但与 HashMap 不同,它使用双向链表来维护元素的插入顺序(或访问顺序)。</li><li>区别:LinkedHashSet 除了采用 HashSet 的哈希表结构外,还使用了双向链表来维护插入顺序,使得 LinkedHashSet 在遍历时按照元素的插入顺序进行遍历。HashSet 没有顺序保证。</li><li>插入顺序保证:通过双向链表维护元素的顺序,在每个元素节点中存储指向前后元素的引用,从而保证插入顺序。</li></ul>
EnumSet 的底层实现原理是什么?
面试问题:<br><ul><li>EnumSet 的底层是如何实现的?</li><li>为什么 EnumSet 性能比其他 Set 实现类更好?</li></ul>答案:<br><ul><li>底层实现:EnumSet 是专门为枚举类型设计的,它底层使用位向量(bit vector)实现,每个枚举值在内部映射为一个位(bit),从而提供高效的存储和查找。</li><li>性能优势:由于采用了位向量的方式,EnumSet 对枚举元素的存储和查找都非常高效,通常比其他基于哈希表或树的 Set 实现更快。</li></ul>
CopyOnWriteArraySet 的底层实现原理是什么?
面试问题:<br><ul><li>CopyOnWriteArraySet 是如何实现线程安全的?</li><li>CopyOnWriteArraySet 适用于哪些场景?</li></ul>答案:<br><ul><li>线程安全实现:CopyOnWriteArraySet 通过使用 CopyOnWriteArrayList 实现线程安全。每次修改集合(如添加或删除元素)时,都会复制整个底层数组,确保读操作不受写操作的影响。</li><li>适用场景:适用于读多写少的场景,因为写操作的代价较高(每次修改都需要复制整个数组),但读操作是非常快速的。</li></ul>
Queue 接口(队列 FIFO)
<br>
LinkedList 作为队列
import java.util.LinkedList;
import java.util.Queue;
public class TestQueue {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<>();
queue.add("A");
queue.add("B");
queue.add("C");
System.out.println(queue.poll()); // A(FIFO)
System.out.println(queue.peek()); // B(查看队首)
}
}
PriorityQueue
import java.util.PriorityQueue;
public class TestPriorityQueue {
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(10);
pq.add(5);
pq.add(20);
System.out.println(pq.poll()); // 5(最小优先)
}
}
总结
<ul><li>List 适用于有序、可重复数据</li><li>Set 适用于无序、不重复数据</li><li>Queue 适用于队列或任务调度</li><li>Map 适用于键值对存储</li><li>Collections 提供了常用算法</li></ul>掌握 Java 集合框架,可以高效管理数据结构,提高编程能力! 🚀
整理
Map
|--HashTable:底层是哈希表数据结构,不可以存入null键和null值,该集合是线程同步的。jdk1.0出现的。效率低。
|--HashMsp:底层是哈希表数据结构,允许使用null键和null值,该集合是线程不同步的。jdk1.2出现的。效率高。
|--TreeMap:底层是二叉树数据结构,线程不同步。可以用于给map集合中的进行排序。(和set很像,set底层是使用了Map集合)。
map集合的两种取出方式:
1、keyset:将map中所有的键存入到set集合。因为set具备迭代器。所有可以迭代方式取出所有的键,在根据get方法,获取每一个键对应的值。
2、entrySet:将map集合中的映射关系存入到了set集合中,而这个关系的数据类型就是:Map.Entry。
Map.Entry:其实Entry也是一个接口,它是Map接口中的一个内部接口。
Map集合使用是因为具备映射关系。
一、HashMap
1、无序不可重复。
2、数组加链表 单向链表
3、默认长度为16
4、扩容因子0.75
5、查询速度快,耗费内存。空间换时间
二、HashTable
三、ArrayList
四、LinkedList
1、双向链表
五、vercort
六、高级for循环
格式:for(数据类型变量名:被遍历的集合(Collection)或者数组)
对集合进行遍历。
只能获取集合元素。但是不能对集合进行操作。
迭代器除了遍历,还可以进行remove集合中元素的动作。
如果是用ListIterator, 还可以在遍历过程中对集合进行增删改查的动作。
传统for循环和高级for有什么区别呢?
高级for有一个局限性,必须有被遍历的目标。
建议在遍历数组的时候,还是希望使用传统for。因为传统for可以定义角标。
七、可变参数。
其实就是上一种数组参数的简写形式。
不用每一次都手动的建立数组对象。
只要将要操作的元素作为参数传递即可。
隐式将这些参数封装成了数组。
多线程<br>
描述
Java 的多线程(Multithreading)是并发编程的核心,它允许多个任务(线程)同时运行,提高程序的执行效率。Java 提供了 Thread 类和 Runnable 接口来创建和管理线程,同时还提供了 Executor 框架、同步机制(如 synchronized 关键字、锁等)来保证线程安全。
线程的基本概念
什么是线程?
<ul><li>线程(Thread) 是 CPU 任务调度的最小单位,一个 Java 进程可以有多个线程并发执行。</li><li>多线程(Multithreading) 允许多个线程在同一进程中并发执行,共享进程资源(如内存、变量等)。</li><li>多线程的目标 是提高 CPU 利用率,但需要注意线程同步,避免数据竞争和死锁问题。</li></ul>
创建线程的方式
Java 提供了两种主要方式来创建线程:<br><ul><li>继承 Thread 类</li><li>实现 Runnable 接口(推荐,避免 Java 的单继承限制)</li></ul>
继承 Thread 类
步骤:<br><ol><li>创建一个类继承 Thread。</li><li>重写 run() 方法,定义线程要执行的任务。</li><li>创建线程对象,并调用 start() 方法启动线程。</li></ol><br>示例:<br>class MyThread extends Thread {<br> public void run() {<br> for (int i = 0; i < 5; i++) {<br> System.out.println(Thread.currentThread().getName() + " -> " + i);<br> }<br> }<br>}<br><br>public class TestThread {<br> public static void main(String[] args) {<br> MyThread t1 = new MyThread();<br> MyThread t2 = new MyThread();<br> t1.start();<br> t2.start();<br> }<br>}<br>输出示例:<br>Thread-0 -> 0<br>Thread-1 -> 0<br>Thread-0 -> 1<br>Thread-1 -> 1<br>...<br>注意:<br><ul><li>start() 不能重复调用,否则会抛出 IllegalThreadStateException。</li><li>不要直接调用 run() 方法,否则线程不会并行执行,而只是普通方法调用。</li></ul>
实现 Runnable 接口(推荐方式)
步骤:<br><ol><li>定义一个类实现 Runnable 接口。</li><li>实现 run() 方法。</li><li>创建 Thread 对象,并传入 Runnable 实例。</li><li>调用 start() 启动线程。</li></ol><br>示例:<br>class MyRunnable implements Runnable {<br> public void run() {<br> for (int i = 0; i < 5; i++) {<br> System.out.println(Thread.currentThread().getName() + " -> " + i);<br> }<br> }<br>}<br><br>public class TestRunnable {<br> public static void main(String[] args) {<br> Thread t1 = new Thread(new MyRunnable());<br> Thread t2 = new Thread(new MyRunnable());<br> t1.start();<br> t2.start();<br> }<br>}<br>推荐原因:<br><ul><li>避免 Java 单继承的限制(可以同时继承其他类)。</li><li>更灵活,可以与线程池、Executors 框架配合使用。</li></ul>
线程的生命周期
Java 线程的生命周期包含以下 5 个状态:<br><br><ol><li><span style="font-size: inherit;">新建(NEW):线程对象被创建,但未启动。</span></li><li><span style="font-size: inherit;">就绪(RUNNABLE):调用 start(),等待 CPU 调度。</span></li><li><span style="font-size: inherit;">运行(RUNNING):线程获取 CPU 时间片,正在执行 run()。</span></li><li><span style="font-size: inherit;">阻塞(BLOCKED, WAITING, TIMED_WAITING):<br></span>BLOCKED:等待获取锁。<br>WAITING:等待通知(wait())。<br>TIMED_WAITING:超时等待(sleep()、join())。</li><li>终止(TERMINATED):线程执行完毕或被强制终止。</li></ol><br>
线程控制
sleep() 让线程休眠
<ul><li>Thread.sleep(ms):让当前线程暂停执行 ms 毫秒。</li><li>线程休眠后,CPU 会去执行其他线程。<br></li></ul><br>class SleepExample extends Thread {<br> public void run() {<br> for (int i = 1; i <= 5; i++) {<br> System.out.println(Thread.currentThread().getName() + " -> " + i);<br> try {<br> Thread.sleep(1000); // 休眠 1 秒<br> } catch (InterruptedException e) {<br> e.printStackTrace();<br> }<br> }<br> }<br>}<br><br>public class TestSleep {<br> public static void main(String[] args) {<br> Thread t1 = new SleepExample();<br> t1.start();<br> }<br>}<br>
join() 等待线程执行完毕
<ul><li>join() 让当前线程等待指定线程执行完毕后再继续执行。</li></ul><br>class JoinExample extends Thread {<br> public void run() {<br> for (int i = 1; i <= 5; i++) {<br> System.out.println(Thread.currentThread().getName() + " -> " + i);<br> }<br> }<br>}<br><br>public class TestJoin {<br> public static void main(String[] args) throws InterruptedException {<br> Thread t1 = new JoinExample();<br> t1.start();<br> t1.join(); // 主线程等待 t1 执行完毕<br> System.out.println("Main 线程继续执行");<br> }<br>}
线程同步(synchronized)
为什么需要同步?
多个线程同时访问共享资源时,可能会导致数据不一致的问题(如线程安全问题)。<br><br>示例(无同步,可能出现问题):<br>class BankAccount {<br> private int balance = 100;<br><br> public void withdraw(int amount) {<br> if (balance >= amount) {<br> System.out.println(Thread.currentThread().getName() + " 正在取款 " + amount);<br> balance -= amount;<br> System.out.println("余额:" + balance);<br> }<br> }<br>}<br><br>public class TestSync {<br> public static void main(String[] args) {<br> BankAccount account = new BankAccount();<br> new Thread(() -> account.withdraw(80)).start();<br> new Thread(() -> account.withdraw(80)).start();<br> }<br>}<br>可能的错误结果(余额变负):<br>Thread-0 正在取款 80<br>余额:20<br>Thread-1 正在取款 80<br>余额:-60 <-- 线程安全问题!
使用 synchronized 解决
class BankAccount {
private int balance = 100;
public synchronized void withdraw(int amount) { // 线程同步
if (balance >= amount) {
System.out.println(Thread.currentThread().getName() + " 正在取款 " + amount);
balance -= amount;
System.out.println("余额:" + balance);
}
}
}
线程池(Executor 框架)
使用 ExecutorService 线程池,避免频繁创建销毁线程的开销:<br><br>import java.util.concurrent.ExecutorService;<br>import java.util.concurrent.Executors;<br><br>public class TestThreadPool {<br> public static void main(String[] args) {<br> ExecutorService executor = Executors.newFixedThreadPool(3);<br><br> for (int i = 1; i <= 5; i++) {<br> executor.execute(() -> System.out.println(Thread.currentThread().getName() + " 正在执行任务"));<br> }<br> executor.shutdown(); // 关闭线程池<br> }<br>}
总结
<ul><li>创建线程的两种方式:继承 Thread 或实现 Runnable(推荐)。</li><li>常用方法:start()、sleep()、join()。</li><li>线程同步:synchronized、Lock。</li><li>使用 Executor 线程池 提高效率,避免资源浪费。</li></ul>Java 多线程能有效提升程序性能,但需要合理管理以避免竞态条件和死锁问题! 🚀
整理
一、概述
1、进程:是一个正在执行中的程序。每一个进程执行都有一个执行顺序。该顺序是一个执行路径,或者叫一个控制单元。
2、线程:就是进程中的一个独立的控制单元。线程在控制着进程的执行。
一个进程中至少有一个线程。
二、创建线程继承thread类
class Demo extends Thread{
public void run(){
System.out.println("demo run");
}
}
1、步骤:
1)、定义类继承Thread。
2)、复写Thread类中的run方法。
目的:将自定义的代码存储在run方法中,让线程运行。
3)、调用线程的start方法。
该方法两个作用:启动线程,调用run方法。
2、发现运行结果每一次都不同。因为多个线程都在获取CPU的执行权,CPU执行到谁,谁就运行。明确一点,在某一个时刻,只能有一个程序在运行。(多核除外)
CPU在做着快速的切换,以达到看上去是同时运行的结果。我们可以形象的把多线程的运行行为看成是在互相抢夺CPU的执行权限。这就是多线程的一个特性:随机性。谁抢到谁执行,至于执行多久,CPU说的算。
3、为什么要覆盖run方法?
thread类用于描述线程。该类就定义了一个功能,用于存储线程要运行的代码。该存储功能的方法就是run方法。也就是说thread类中的run方法,用于存储线程要运行的代码。
4、线程运行状态:
a、start()运行状态
b、sleep()睡眠 冻结状态
c、wait()等待 冻结状态 放弃了执行资格
d、stop()结束
e、临时状态:阻塞 具备运行资格,没有执行权
f、notify()唤醒 进入临时状态
5、获取线程对象以及名称
thread-编号
a、currentThread:获取当前线程对象。
b、getName:获取线程名称。
c、设置线程名称:setName或者构造函数。
三、创建线程—实现Runnable接口
1、步骤:
a、定义类实现Runnable接口
b、覆盖Runnable接口中的run方法。
将线程要运行的代码存放在该run方法中。
c、通过Thread类建立对象。
d、将Runnable接口的子类对象作为实际参数专递给Thread类的构造函数。
为什么要将Runnable接口的子类对象传递给Thread的构造函数。
因为,自定义的run方法所属的对象是Runnable接口的子类对象。
所以要让线程去执行指定对象的run方法。就必须明确该run方法所属对象。
e、调用Thread类的start方法开启线程并调用Runnable接口子类的run方法。
2、实现方式和继承方式有什么区别呢?
a、继承Thread:线程代码存放在Thread子类run方法中。
b、实现Runnable:线程代码存放在接口的子类的run方法中。
实现方式好处:避免了单继承的局限性。
在定义线程时,建议使用实现方式。
四、多线程安全问题
1、问题原因:
当多条语句在操作同一个线程共享数据时,一个线程对多条语句只执行了一部分,还没有执行完,另一个线程参与进来执行。导致共享数据的错误。
解决办法:
对多条操作共享数据的语句,只能让一个线程都执行完。在执行过程中,其他线程不可以参与
同步代码块:
synchronized(对象){
需要被同步的代码
}
对象如同锁:
持有锁的线程可以在同步中执行。没有持有锁的线程即使获取CPU的执行权,也进不去,因为没有获取锁。
同步的前提:
1、必须要有两个或者两个以上的线程。
2、必须是多个线程使用同一个锁。
3、必须保证同步中只能有一个线程在运行。
好处:解决了多线程的安全问题。
弊端:多个线程需要判断锁,较为消耗资源。
2、如何查找问题:
a、明确哪些代码是多线程运行代码。
b、明确共享数据。
c、明确多线程运行代码中哪些语句是操作共享数据的。
3、同步函数
a、同步函数用的是哪个锁?
函数需要被对象调用,那么函数都有一个所属对象引用,就是this。所以同步函数使用的锁的this。
b、如果同步函数被静态修饰后,使用的是什么锁?
通过验证,发现不是this。因为静态方法中也不可以定义this。
静态进内存是,内存中没有本类对象,但是一定有该类对应的字节码对象。
类名.class 该对象的类型是class
静态的同步函数,使用的锁是该方法所在类的字节码文件对象。 类名.class
4、死锁
同步中嵌套同步。
死锁产生的原因:
1) 系统资源的竞争
通常系统中拥有的不可剥夺资源,其数量不足以满足多个进程运行的需要,使得进程在 运行过程中,会因争夺资源而陷入僵局,如磁带机、打印机等。只有对不可剥夺资源的竞争 才可能产生死锁,对可剥夺资源的竞争是不会引起死锁的。
2) 进程推进顺序非法
进程在运行过程中,请求和释放资源的顺序不当,也同样会导致死锁。例如,并发进程 P1、P2分别保持了资源R1、R2,而进程P1申请资源R2,进程P2申请资源R1时,两者都 会因为所需资源被占用而阻塞。
信号量使用不当也会造成死锁。进程间彼此相互等待对方发来的消息,结果也会使得这 些进程间无法继续向前推进。例如,进程A等待进程B发的消息,进程B又在等待进程A 发的消息,可以看出进程A和B不是因为竞争同一资源,而是在等待对方的资源导致死锁。
3) 死锁产生的必要条件
产生死锁必须同时满足以下四个条件,只要其中任一条件不成立,死锁就不会发生。
a、互斥条件:
进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
b、不剥夺条件:
进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
c、循环等待条件:
存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, ..., pn},其中Pi等 待的资源被P(i+1)占有(i=0, 1, ..., n-1),Pn等待的资源被P0占有
如何避免死锁
在有些情况下死锁是可以避免的。三种用于避免死锁的技术:
1、加锁顺序(线程按照一定的顺序加锁)
2、加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
3、死锁检测
那么当检测出死锁时,这些线程该做些什么呢?
一个可行的做法是释放所有锁,回退,并且等待一段随机的时间后重试。这个和简单的加锁超时类似,不一样的是只有死锁已经发生了才回退,而不会是因为加锁的请求超时了。虽然有回退和等待,但是如果有大量的线程竞争同一批锁,它们还是会重复地死锁(编者注:原因同超时类似,不能从根本上减轻竞争)。
一个更好的方案是给这些线程设置优先级,让一个(或几个)线程回退,剩下的线程就像没发生死锁一样继续保持着它们需要的锁。如果赋予这些线程的优先级是固定不变的,同一批线程总是会拥有更高的优先级。为避免这个问题,可以在死锁发生的时候设置随机的优先级。
死锁的解除
1、资源剥夺法
挂起某些死锁进程,并抢占它的资源,将这些资源分配给其他的死锁进程。但应防止被挂起的进程长时间得不到资源,而处于资源匮乏的状态。
2、撤销进程法
强制撤销部分、甚至全部死锁进程并剥夺这些进程的资源。撤销的原则可以按进程优先级和撤销进程代价的高低进行。
3、进程回退法
让一(多)个进程回退到足以回避死锁的地步,进程回退时自愿释放资源而不是被剥夺。要求系统保持进程的历史信息,设置还原点。
五、线程间通讯
1、定义:其实就是多个线程在操作同一个资源,但是操作的动作不同。
2、解决安全问题
3、等待唤醒机制
wait、notify()、notifyAll()、
都使用在同步中,因为要对持有监视器(锁)的线程操作。所以要使用在同步中,因为只有同步才具有锁。
为什么这些操作线程的方法要定义在object类中?
因为这些方法在操作同步中线程时,都必须要标识它们所操作线程持有的锁,只有同一个锁上的被等待线程,可以被同一个锁上面的notify唤醒。不可以对不同锁中的线程进行唤醒。
也就是说,等待和唤醒必须是同一个锁。而锁可以是任意对象,所以可以被任意对象调用的方法定义在object类中。
六、停止线程
stop方法已经过时。
如何停止线程?
只有一种,run方法结束。
开启多线程运行,运行代码通常是循环结构。
只要控制住循环,就可以让run方法结束,也就是线程結束。
特殊情况:
当线程处于了冻结状态.
就不会读取到标记。那么线程就不会结束。
当没有指定的方式让冻结的线程恢复到运行状态是,这时需要对冻结进行清除。
强制让线程恢复到运行状态中来。这样就可以操作标记让线程结東。
Thread类提供该方法interrupt() ;
IO流
描述
Java IO(输入/输出)流用于处理文件、网络、控制台等数据输入与输出。Java 提供了字节流(Byte Stream) 和 字符流(Character Stream) 进行数据传输,并支持缓冲流、对象流、数据流等高级特性。
Java IO 流概述
IO 流的分类
<br>
字节流(InputStream 和 OutputStream)
字节流可以处理任何类型的数据(如文件、图片、音频),常见的实现类包括:<br><br><ul><li>文件流:FileInputStream、FileOutputStream</li><li>缓冲流:BufferedInputStream、BufferedOutputStream</li><li>数据流:DataInputStream、DataOutputStream</li><li>对象流:ObjectInputStream、ObjectOutputStream</li></ul>
读取文件(FileInputStream)
FileInputStream 逐字节读取文件数据,适用于二进制文件(图片、音频等)。<br><br>import java.io.FileInputStream;<br>import java.io.IOException;<br><br>public class ReadFile {<br> public static void main(String[] args) {<br> try (FileInputStream fis = new FileInputStream("test.txt")) {<br> int data;<br> while ((data = fis.read()) != -1) { // 逐字节读取<br> System.out.print((char) data);<br> }<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> }<br>}<br>注意:<br><ul><li>read() 方法返回单个字节(-1 表示读取结束)。</li><li>用 try-with-resources 语法自动关闭流。</li></ul>
写入文件(FileOutputStream)
FileOutputStream 用于写入二进制数据。<br><br>import java.io.FileOutputStream;<br>import java.io.IOException;<br><br>public class WriteFile {<br> public static void main(String[] args) {<br> try (FileOutputStream fos = new FileOutputStream("output.txt")) {<br> String content = "Hello, Java IO!";<br> fos.write(content.getBytes()); // 写入字节数组<br> System.out.println("写入完成");<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> }<br>}<br>注意:<br><ul><li>write() 方法写入字节数组。</li><li>getBytes() 将字符串转换为字节数组。</li></ul>
字符流(Reader 和 Writer)
字符流主要用于处理文本文件,常见的实现类:<br><br><ul><li>文件流:FileReader、FileWriter</li><li>缓冲流:BufferedReader、BufferedWriter</li><li>字符数组流:CharArrayReader、CharArrayWriter</li></ul>
读取文本文件(FileReader)
FileReader 逐字符读取文件,适用于文本数据。<br><br>import java.io.FileReader;<br>import java.io.IOException;<br><br>public class ReadTextFile {<br> public static void main(String[] args) {<br> try (FileReader reader = new FileReader("test.txt")) {<br> int data;<br> while ((data = reader.read()) != -1) { // 逐字符读取<br> System.out.print((char) data);<br> }<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> }<br>}
写入文本文件(FileWriter)
FileWriter 用于写入文本数据。<br><br>import java.io.FileWriter;<br>import java.io.IOException;<br><br>public class WriteTextFile {<br> public static void main(String[] args) {<br> try (FileWriter writer = new FileWriter("output.txt")) {<br> writer.write("Hello, Java IO!\n");<br> writer.write("文件写入成功!");<br> System.out.println("写入完成");<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> }<br>}
缓冲流(Buffered Stream)
缓冲流可以提高 IO 读取速度,减少磁盘 IO 访问次数。<br><br><ul><li>BufferedInputStream / BufferedOutputStream(字节缓冲)</li><li>BufferedReader / BufferedWriter(字符缓冲)</li></ul>
使用 BufferedReader 读取文本
使用 BufferedReader 按行读取文本,提高效率。<br><br>import java.io.BufferedReader;<br>import java.io.FileReader;<br>import java.io.IOException;<br><br>public class ReadBuffered {<br> public static void main(String[] args) {<br> try (BufferedReader br = new BufferedReader(new FileReader("test.txt"))) {<br> String line;<br> while ((line = br.readLine()) != null) { // 按行读取<br> System.out.println(line);<br> }<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> }<br>}
对象流(Object Stream)
ObjectOutputStream 和 ObjectInputStream 用于序列化和反序列化 Java 对象,适用于存储对象到文件。
对象写入文件
import java.io.*;
class Person implements Serializable { // 必须实现 Serializable 接口
private static final long serialVersionUID = 1L;
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
public class SerializeObject {
public static void main(String[] args) {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.ser"))) {
Person p = new Person("Alice", 25);
oos.writeObject(p);
System.out.println("对象序列化成功");
} catch (IOException e) {
e.printStackTrace();
}
}
}
读取对象
public class DeserializeObject {
public static void main(String[] args) {
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.ser"))) {
Person p = (Person) ois.readObject();
System.out.println("姓名:" + p.name + ", 年龄:" + p.age);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
NIO(New IO)
Java 1.4 引入了 java.nio(非阻塞 IO),相比传统 IO 速度更快,适用于高并发网络通信。<br><br>NIO 核心组件<br><ul><li>Buffer:数据缓冲区(ByteBuffer、CharBuffer)</li><li>Channel:数据通道(FileChannel、SocketChannel)</li><li>Selector:多路复用器(用于管理多个通道)</li></ul><br>示例:<br>import java.nio.file.*;<br><br>public class TestNIO {<br> public static void main(String[] args) throws Exception {<br> Path path = Paths.get("test.txt");<br> byte[] data = Files.readAllBytes(path);<br> System.out.println(new String(data));<br> }<br>}<br>
总结
<br>
整理
I0流:用来处理设备之间的数据传输。
Java对数据的操作是通过流的方式,Java用于操作流的对象都在IO包中。
流按操作数据分为两种:字节流与字符流。
流按流向分为:输入流,输出流。
字节流的抽象基类:
● InputStream,OutputStream.
字符流的抽象基类:
● Reader Writer。
注:由这四个类派生出来的子类名称都是
以其父类名作为子类名的后缀。
●如: InputStream的子类FilelnputStream.
●如: Reader的子类FileReader
一、字符流
1、写入缓冲区: BufferredWriter
缓冲区的出现是为了提高流的操作效率而出现的。所以在创建缓冲区之前,必须要先有流对象。
该缓冲区提供了一个跨平台的换行符。 newLine();
1)、创建一个字符写入流对象。
2)、为了提高字符写入流效率,加入缓冲技术。只要将需要被提高效率的流对象座位参数传递给缓冲区的构造函数即可。
2、读取缓存流:BufferredReader
该缓冲区提供了一个一次读一行的方法readLine(); 方便于对文本数据的获取。
当返回null时,表示读到文件末尾
1)、创建一个读取流对象new FileReader()和文件相关联。
2)、为了提高效率,加入缓冲技术,将字符读取流对象座位参数传递给缓冲对象的构造函数。
readLine方法的原理(装饰设计模式)
无论是读一行,获取读取多个字符。其实最终
都是在在硬盘上一个一个读取。所以最终使用
的还是read方法- -次读-一个的方法。
装饰设计模式:
当想要对已有的对象进行功能增强时,可以定义类,将已有对象传入,基于已有的功能,并提供加强功能。那么定义的该类称为装饰类。
装饰类通常会通过构造方法接收被装饰的对象,并基于被装饰的对象的功能,提供更强的功能。
装饰模式和继承的区别:
装饰模式比继承要灵活,避免了继承体系的臃肿,而且降低了类与类之间的关系。
装饰类因为增强已有对象所具备的功能和已有的是相同的,只不过提供了更强的功能。所以装饰类和被装饰类通常是都属于一个体系中的。
二、字节流
FileInputStrem();
FileOutputStrem();
缓存区:
BufferedInputStream();
BufferedOutputStream();
三、读取键盘录入
System.out:对应的是标准输出设备,控制台。
System.in:对应的标准输入设备,键盘。
四、流操作基本规律
最痛苦的就是流对象很多,不知道该用哪一个。
通过两个明确来完成:
1、明确源和目的。
源:输入流。InputStream Reader。
目的:输出流。OutPutStream Writer。
2、操作的数据是否是纯文本。
是:字符流。
不是:字节流。
3、当体系明确后,在明确要使用哪个具体的对象。
通过设备来区分:
源设备:内存、硬盘、键盘。
目的设备:内存、硬盘(文件)、控制台。
示例1:
将一个文本文件中数据存储到另一个文件中。复制文件。
源:因为是源,所以使用读取流。Inputstream Reader
是不是操作文本文件。
是!这时就可以选择Reader,这样体系就明确了。
接下来明确要使用该体系中的哪个对象。
明确设备:硬盘。上一个文件。
Reader体系中可以操作文件的对象是FileReader
是否需要提高效率:
是!加入Reader体系中缓冲区BufferedReader 。
FileReader fr . new FileReader ("a. txt") ;
Buf feredReader bufr = new Buf feredReader (fr) ;
目的: Outputstream writer
是否是纯文本:是! writer。
设备:硬盘,一个文件。
writer体系中可以操作文件的对象FileWriter。
是否需要提高效率:是!加入writer体系中缓冲区Bufferedwriter
FileWriter fw = new FileWriter ("b. txt") ;
Bufferedwriter bufw = new BufferedWriter (fw) ;
示例2:
需求:将键盘录入的数据保存到一个文件中。
这个需求中有源和日的都存在。
那么分别分析
源:InputStream Reader
是不是纯文本?是! Reader
设备:键盘。对应的对象是system. in。
不是选择Reader吗? System. in对应的不是字节流吗?
为了操作键盘的文本数据方便。转成字符流按照字符串操作是最方便的。
所以既然明确了Reader,那么就将system。in转换成Reader。
用了Reader体系中转换流, InputStreamReader
InputStreamReader isr = new InputStreamReader (System.in) ;
需要提高效率吗?需要! BufferedReader
BufferedReader bufr = new BufferedReader (isr) ;
目的::OutputStream writer
是否是存文本?是! writer.
设备:硬盘。一个文件。使用Filewriter.
FileWriter fw . new FileWriter ("c.txt") ;
需要提高效率吗?需要。
Bufferedwriter bufw = new Bufferedwriter (fw) ;
***************************************************************
扩展一下:想要把录入的数据按照指定的编码表(utf-8),将数据存到文件中。
目的:OutputStream writer
是否是存文本?是! writer.
设备:硬盘。一个文件。
使用Filewriter,但是存储时,需要加入指定编码表,而指定的编码表只有转换流可以指定。所以要使用的对象是OutputStreamWriter。而该转换流对象要接收一个字节输出流。而且还可以操作的文件的字节输出流。FileOutSrream。
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("d.txt","UTF-8")) ;
需要提高效率吗?需要。
Bufferedwriter bufw = new Bufferedwriter (osw ) ;
所以,转换流什么时候使用,字符和字节至今的桥梁,通常涉及到字符编码转换时,需要用到转换流。
***************************************************************
五、File类
用来讲文件或者文件夹封装成对象。
方便对文件与文件夹的属性进行操作。
Fi1e类常见方法:
1, 创建。
boolean createNewFile():在指定位置创建文件,如果该文件已经存在,则不创建,返回false.
和输出流不一样,输出流对象一建立创建文件。而且文件已经存在,会覆盖。
mkdir:创建文件夹。
mkdirs:创建多级文件夹。
2,删除。
boolean delete():删除失败返回f se.
void deleteOnExit():在程字遇出时别除指定文件。
3、判断
exists():文件是否存在。
isFile:是否是文件。
isDirectory:是否是文件夹。
isHidden:是否是隐藏。
isAbsolute:是否是绝对路径。
记住在判断文件对象是否是文件或者目录时,必须要先判断该文件对象是否存在。
4、获取信息
getName():获取名称。
getPath():获取路径。
getParent():获取绝对路径中的文件父目录。如果获取的是相对路径返回null。如果相对路径中有上一层目录,那么该目录就是返回结果。
getAbsolute():获取绝对路径。
lastModified():最后一次修改时间。
length():文件大小。
六、properties
Properties是hashtable的子类。也就是说它具备map集合的特点,而且它里面存储的键值对都是字符串。是集合中和IO技术相结合的集合容器。
特点:
可以用于键值对形式的配置文件。
那么在加载数据时,需要数据有固定格式:键=值。
合并流:SequenceInputStream。Enumeration en = vector.elements();
切割流:SplitFile
七、RandomAccessFile
该类不是算是Io体系中子类。
而是直接继承自object.
但是它是I0包中成员。因为它具备读和写功能.
内部封装了一个数组,而且通过指针对数组的元素进行操作。
可以通过getFilePointer获取指针位置,
同时可以通过seek改变指针的位置。
其实完成读写的原理就是内部封装了字节输入流和输出流。
通过构造函效可以看出,该类只能操作文件。
而且操作文件还有模式:
如果模式为只读r.不会创建文件。会去读取一一个已存在文件,如果该文件不存在,则会出现异常。
如果模式rw,操作的文件不存在,会自动创建。如果存在会覆盖.
八、PipedInputStream、PipedOutStream(管道流)
多用于多线程中,单线程容易造成死锁。
九、ByteArrayInputStream
用于操作字节数组的流对象。
ByteArrayInputstream :在构造的时候,斋要接收数据源,:
而且效据源是一一个字节效组。
ByteAr rayOutputStream:
在构造的时候,不用定义数据目的,因为该对象中已经内部封装了可变长度的字节数组.
这就是数据目的地。
因为这两个流对象都操作的数組,并没有使用系统资源。
所以,不用进行close关闭。
常见的编码表
●ASCII:美国标准信息交换码。,用一个字节的7位可以表示。
●IS08859-1:拉丁码表。欧洲码表,用一个字节的8位表示。
●GB2312: 中国的中文编码表。
●GBK:中国的中文编码表升级,融合了更多的中文文字符
号。
●Unicode:国际标准码,融合了多种文字。
●所有文字都用两个字节来表示Java语言使用的就是unicode
●UTF-8:最多用三个字节来表示一个字符。
string-->byte[]; str .getBytes (charsetName) ;
byte[] -->String; new String (byte [],charsetName) ;
进制
Java 中的数值可以用不同的进制表示,包括 二进制(Binary)、八进制(Octal)、十进制(Decimal)和十六进制(Hexadecimal)。Java 提供了一些内置的方法来转换和处理不同进制的数值。
Java 支持的进制
<br>
进制表示
在 Java 中,可以直接使用不同进制的数值:<br><br>public class NumberSystems {<br> public static void main(String[] args) {<br> int decimal = 10; // 十进制<br> int binary = 0b1010; // 二进制<br> int octal = 012; // 八进制<br> int hex = 0xA; // 十六进制<br><br> System.out.println("十进制: " + decimal);<br> System.out.println("二进制: " + binary);<br> System.out.println("八进制: " + octal);<br> System.out.println("十六进制: " + hex);<br> }<br>}<br><br>输出结果:<br>十进制: 10<br>二进制: 10<br>八进制: 10<br>十六进制: 10<br>
进制转换
十进制转其他进制
Java 提供 Integer.toBinaryString()、Integer.toOctalString() 和 Integer.toHexString() 方法进行转换。<br><br>public class DecimalToOthers {<br> public static void main(String[] args) {<br> int num = 42;<br> System.out.println("十进制: " + num);<br> System.out.println("二进制: " + Integer.toBinaryString(num));<br> System.out.println("八进制: " + Integer.toOctalString(num));<br> System.out.println("十六进制: " + Integer.toHexString(num));<br> }<br>}<br>输出:<br>十进制: 42<br>二进制: 101010<br>八进制: 52<br>十六进制: 2a
其他进制转十进制
Java 提供 Integer.parseInt(String s, int radix) 方法,将不同进制的字符串转换为十进制数。<br><br>public class OthersToDecimal {<br> public static void main(String[] args) {<br> System.out.println("二进制转十进制: " + Integer.parseInt("101010", 2));<br> System.out.println("八进制转十进制: " + Integer.parseInt("52", 8));<br> System.out.println("十六进制转十进制: " + Integer.parseInt("2A", 16));<br> }<br>}<br>输出:<br>二进制转十进制: 42<br>八进制转十进制: 42<br>十六进制转十进制: 42
负数的二进制表示
在 Java 中,整数使用 补码(Two’s Complement) 表示:<br><ul><li>正数:直接使用二进制表示。</li><li>负数:取反(所有位取反)+ 1。</li></ul><br>示例:<br>public class NegativeBinary {<br> public static void main(String[] args) {<br> int num = -5;<br> System.out.println("十进制: " + num);<br> System.out.println("二进制(补码): " + Integer.toBinaryString(num));<br> }<br>}<br><br>输出:<br>十进制: -5<br>二进制(补码): 11111111111111111111111111111011<br><br>解析:<br>5 的二进制:00000000000000000000000000000101<br>取反:11111111111111111111111111111010<br>加 1:11111111111111111111111111111011<br>
进制转换进阶
自定义进制转换
可以使用 Integer.toString(int num, int radix) 进行任意进制转换(2 到 36)。<br><br>public class CustomBaseConversion {<br> public static void main(String[] args) {<br> int num = 255;<br> System.out.println("十进制转二进制: " + Integer.toString(num, 2));<br> System.out.println("十进制转八进制: " + Integer.toString(num, 8));<br> System.out.println("十进制转十六进制: " + Integer.toString(num, 16));<br> }<br>}
Java 8+ 新特性
Integer.toUnsignedString()
Java 8 提供了 toUnsignedString() 方法,可以处理无符号整数进制转换。<br><br>public class UnsignedConversion {<br> public static void main(String[] args) {<br> int num = -5;<br> System.out.println("无符号二进制: " + Integer.toUnsignedString(num, 2));<br> }<br>}<br><br>输出:<br>无符号二进制: 4294967291<br>(-5 在无符号整数中被解释为 4294967291)<br>
进制的实际应用
颜色表示(十六进制)
int red = 0xFF0000; // 纯红色
System.out.println("红色值: " + red);
文件权限(八进制)
int permission = 0755; // Linux 文件权限
System.out.println("权限: " + permission);
位运算(用于权限管理、加密)
int read = 0b0001; // 读权限
int write = 0b0010; // 写权限
int execute = 0b0100; // 执行权限
int permission = read | write; // 赋予读写权限
System.out.println("权限: " + Integer.toBinaryString(permission));
总结
<br>
整理
一、进制的由来:<br>任何数据在计算机中都是以二进制的形式存在的。二进制早起由电信号开关演变而来。<br><br>二、十进制和二进制之间的转换<br>1、十进制-->二进制<br>原理:对十进制数进行除2运算。<br>2、二进制-->十进制<br>原理:二进制数乘以2的过程。<br>110=0*2(0)+1*2(1)+1*2(2)<br> 6 = 0 + 2 + 4<br><br>三、其他进制转换<br>1、十六进制<br>四个二进制位就是一个十六进制位。<br>0101-1010<br> 5 A = 5A<br>2、八进制<br>三个二进制位代表一位<br>001-011-010<br> 1 3 2 = 132<br><br>四、负数二进制<br>1、负数的二进制表现形式就是二进制取反+1<br>2、取反:将二进制的1变成0,0变成1。<br>3、负数最高位是1、正数的最高位是0。<br>
设计模式
描述
设计模式(Design Pattern)是一套被反复使用、多数人知晓、经过分类编目的代码设计经验总结。它们提供了解决常见软件设计问题的最佳实践,旨在提高代码的可复用性、可读性和可维护性。
设计模式的分类
设计模式通常分为三大类:<br><br><ul><li>创建型模式(Creational Patterns):关注对象的创建方式,提高代码的灵活性和可扩展性。</li><li>结构型模式(Structural Patterns):关注对象之间的结构关系,使代码更易扩展和维护。</li><li>行为型模式(Behavioral Patterns):关注对象之间的通信方式,提高系统的灵活性和可扩展性。</li></ul>
设计模式的具体介绍
创建型模式(Creational Patterns)
<br>
结构型模式(Structural Patterns)
<br>
行为型模式(Behavioral Patterns)
<br>
设计模式的应用场景示例
单例模式
应用场景:需要全局唯一实例,如数据库连接池、线程池、日志管理器等。
示例(Java 实现单例模式 - 懒汉式,线程安全):<br><br>public class Singleton {<br> private static volatile Singleton instance;<br> <br> private Singleton() {} // 私有构造方法,防止外部实例化<br> <br> public static Singleton getInstance() {<br> if (instance == null) {<br> synchronized (Singleton.class) {<br> if (instance == null) {<br> instance = new Singleton();<br> }<br> }<br> }<br> return instance;<br> }<br>}<br>
工厂方法模式
应用场景:需要解耦对象的创建过程,例如 JDBC 连接获取、日志框架等。
示例(Java 工厂方法模式):<br><br>interface Product {<br> void use();<br>}<br><br>class ConcreteProductA implements Product {<br> public void use() {<br> System.out.println("使用产品A");<br> }<br>}<br><br>class ConcreteProductB implements Product {<br> public void use() {<br> System.out.println("使用产品B");<br> }<br>}<br><br>abstract class Factory {<br> abstract Product createProduct();<br>}<br><br>class ConcreteFactoryA extends Factory {<br> public Product createProduct() {<br> return new ConcreteProductA();<br> }<br>}<br><br>class ConcreteFactoryB extends Factory {<br> public Product createProduct() {<br> return new ConcreteProductB();<br> }<br>}<br>
观察者模式
应用场景:需要订阅-发布机制,例如 GUI 事件监听、消息推送等。
示例(Java 实现观察者模式):<br><br>import java.util.ArrayList;<br>import java.util.List;<br><br>interface Observer {<br> void update(String message);<br>}<br><br>class ConcreteObserver implements Observer {<br> private String name;<br> <br> public ConcreteObserver(String name) {<br> this.name = name;<br> }<br><br> @Override<br> public void update(String message) {<br> System.out.println(name + " 收到消息: " + message);<br> }<br>}<br><br>class Subject {<br> private List<Observer> observers = new ArrayList<>();<br> <br> public void addObserver(Observer observer) {<br> observers.add(observer);<br> }<br> <br> public void notifyObservers(String message) {<br> for (Observer observer : observers) {<br> observer.update(message);<br> }<br> }<br>}<br><br>public class ObserverPatternDemo {<br> public static void main(String[] args) {<br> Subject subject = new Subject();<br> Observer observer1 = new ConcreteObserver("观察者1");<br> Observer observer2 = new ConcreteObserver("观察者2");<br><br> subject.addObserver(observer1);<br> subject.addObserver(observer2);<br><br> subject.notifyObservers("更新通知");<br> }<br>}<br>
设计模式的优缺点
<br>
结论
设计模式是软件设计的重要工具,它们提高了代码的可读性、可维护性和扩展性。掌握并合理运用这些模式,可以让开发更加高效,同时减少代码的重复性和不必要的耦合。
多线程
多线程概述
多线程(Multithreading)是一种并发执行多个任务的编程技术,属于操作系统提供的并发机制之一。它能够提高程序的执行效率,充分利用多核 CPU 资源,适用于需要同时处理多个任务的场景,如 Web 服务器、爬虫、数据处理等。
在多线程编程中,每个线程都有自己的执行路径,并共享进程的资源(如内存、文件句柄等)。常见的多线程编程语言包括 Java、C++、Python 等。
线程 vs 进程
<br>
多线程的优势与劣势
优势
<ul><li>提高程序执行效率:可以利用多核 CPU 资源,实现并发执行。</li><li>增强响应能力:适用于 GUI、服务器等需要异步处理的应用,防止 UI 卡顿。</li><li>更高的资源利用率:多个线程可以共享进程的资源,如内存、文件句柄等。</li></ul>
劣势
<ul><li>同步问题:多个线程访问共享资源时可能引发竞争(Race Condition),需要使用同步机制(如锁)。</li><li>上下文切换开销:线程切换会消耗 CPU 资源,过多线程可能导致系统性能下降(线程爆炸问题)。</li><li>死锁风险:不当的同步策略可能导致多个线程相互等待资源,导致程序无法继续执行。</li></ul>
多线程的核心问题
线程同步
多个线程访问共享资源时可能会产生数据竞争(Race Condition),需要使用同步机制:<br><br><ul><li>互斥锁(Mutex):保证同一时间只有一个线程访问资源。</li><li>信号量(Semaphore):允许多个线程访问资源,但控制访问数量。</li><li>条件变量(Condition Variable):线程间通信机制,配合锁使用。</li></ul>
示例(Java 互斥锁):<br><br>class SharedResource {<br> private int count = 0;<br> private final ReentrantLock lock = new ReentrantLock();<br><br> public void increment() {<br> lock.lock();<br> try {<br> count++;<br> } finally {<br> lock.unlock();<br> }<br> }<br>}<br>
线程安全
某些数据结构和方法是线程安全的,如:<br><br><ul><li>Java:ConcurrentHashMap、CopyOnWriteArrayList、AtomicInteger</li><li>Python:queue.Queue(线程安全队列)</li><li>C++:std::atomic(原子操作)</li></ul>
死锁
多个线程相互等待对方释放资源,导致程序无法继续执行。例如:<br><br>class Deadlock {<br> private static final Object LOCK1 = new Object();<br> private static final Object LOCK2 = new Object();<br><br> public static void main(String[] args) {<br> new Thread(() -> {<br> synchronized (LOCK1) {<br> synchronized (LOCK2) {<br> System.out.println("Thread 1");<br> }<br> }<br> }).start();<br><br> new Thread(() -> {<br> synchronized (LOCK2) {<br> synchronized (LOCK1) {<br> System.out.println("Thread 2");<br> }<br> }<br> }).start();<br> }<br>}<br>
避免死锁的方式<br><br><ul><li>固定加锁顺序:所有线程按相同顺序获取锁。</li><li>使用 tryLock():尝试获取锁,失败则放弃,避免死锁。</li></ul>
线程池
线程池(Thread Pool)是一种管理线程的方式,通过复用线程减少创建/销毁开销,提高性能。
适用场景
适合使用多线程的场景
<ul><li>I/O 密集型任务(如网络请求、文件读写)</li><li>高并发服务(如 Web 服务器、爬虫)</li><li>后台任务(如日志记录、定时任务)</li></ul>
不适合使用多线程的场景
<ul><li>CPU 密集型任务(如大规模计算)→ 推荐使用多进程</li><li>任务较少、生命周期短的任务(线程创建/销毁开销较大)</li><li>需要严格顺序执行的任务</li></ul>
JVM
JVM 概述
Java 虚拟机(Java Virtual Machine,JVM)是 Java 语言的核心,它提供了 Java 代码的执行环境,使得 Java 具有 跨平台性(Write Once, Run Anywhere)。JVM 主要负责 类加载、内存管理、字节码执行、垃圾回收(GC)等。
JVM 体系结构
JVM 主要由以下几个核心组件组成:
<ul><li>类加载子系统(Class Loader)</li><li>运行时数据区(Runtime Data Areas)</li><li>执行引擎(Execution Engine)</li><li>本地接口(Native Interface)</li><li>垃圾回收(Garbage Collection, GC)</li></ul>
JVM 的整体架构:
+----------------------------------------------------+
| Java 虚拟机(JVM) |
+----------------------------------------------------+
| 本地方法接口 | 执行引擎(解释器 & JIT 编译器) |
+----------------------------------------------------+
| 运行时数据区 |
| 方法区 | 堆 | 栈 | 本地方法栈 | 程序计数器 |
+----------------------------------------------------+
| 类加载子系统 |
+----------------------------------------------------+
类加载子系统(Class Loader)
JVM 采用 类加载器(Class Loader) 机制将 .class 字节码文件加载到内存,并进行解析、验证和初始化。Java 提供了 双亲委派模型(Parent Delegation Model) 来管理类加载。
类加载的过程
类加载主要分为 5 个步骤:<br><br><ul><li>加载(Loading):读取 .class 文件,将其转换为 JVM 运行时数据结构。</li><li>验证(Verification):检查字节码是否符合 JVM 规范,确保安全性。</li><li>准备(Preparation):分配静态变量的内存,并赋初始值。</li><li>解析(Resolution):将符号引用转换为直接引用。</li><li>初始化(Initialization):执行类的静态初始化代码(static {})。</li></ul>
JVM 内置的类加载器
<br>
JVM 运行时数据区(Runtime Data Areas)
JVM 内存分为 五大区域:
<ul><li>方法区(Method Area)</li><li>堆(Heap)</li><li>虚拟机栈(JVM Stack)</li><li>本地方法栈(Native Method Stack)</li><li>程序计数器(PC Register)</li></ul>
方法区(Method Area)
<ul><li>存储 类的元数据(如类信息、静态变量、常量池、方法字节码)。</li><li>在 JDK 1.7 之前 方法区是 永久代(PermGen),从 JDK 1.8 开始 被 元空间(Metaspace) 取代。</li><li>垃圾回收主要针对常量池和无用的类。</li></ul>
堆(Heap)
堆是 JVM 内存中最大的一部分,用于存放对象实例。<br><ul><li>垃圾回收(GC)主要在堆中进行。</li></ul>堆的划分:<br>新生代(Young Generation)<br><ul><li>Eden 区:新对象最先分配在 Eden 区。</li><li>Survivor 区(S0/S1):经过多次 GC 的存活对象进入 Survivor 区。</li></ul>老年代(Old Generation)<br><ul><li>长生命周期对象进入老年代,主要存储大对象和长期存活的对象。</li></ul>
虚拟机栈(JVM Stack)
<ul><li>线程私有,每个方法执行都会创建一个 栈帧(Stack Frame),用于存储 局部变量表、操作数栈、动态链接、方法返回地址。</li><li>栈溢出(StackOverflowError):递归调用过深可能导致栈空间耗尽。</li></ul>
本地方法栈(Native Method Stack)
运行 JNI(Java Native Interface) 方法时使用,主要执行 C 语言编写的本地代码。
程序计数器(PC Register)
<ul><li>记录当前线程正在执行的字节码指令地址。</li><li>多线程切换时,PC 记录上一次执行位置,保证线程正确恢复。</li></ul>
执行引擎(Execution Engine)
JVM 通过 解释器(Interpreter) 和 JIT 编译器(Just-In-Time Compiler) 执行 Java 字节码。
解释执行
逐行解释字节码,执行速度较慢,但启动快。
JIT 编译
热点代码(HotSpot) 由 JIT 编译器优化,转换为机器码,提高运行速度。<br>JIT 包含:<br><ul><li>C1 编译器(Client Compiler):针对短生命周期代码优化。</li><li>C2 编译器(Server Compiler):针对高性能场景优化。</li></ul>
垃圾回收(GC, Garbage Collection)
JVM 的 GC 负责自动回收不再使用的对象,主要在 堆(Heap) 进行。
垃圾回收算法
<ul><li>引用计数法(Reference Counting):简单高效,但无法处理循环引用。</li><li>可达性分析(Reachability Analysis):JVM 主要使用的算法,判断对象是否可达。</li></ul>
标记-清除算法(Mark-Sweep)
流程:
<ol><li>标记阶段:从 GC Roots 开始,标记所有可达对象。</li><li>清除阶段:清除所有未被标记的对象,释放内存。</li></ol>
优点:
简单直接,适用于不需要频繁 GC 的应用。
缺点:
<ul><li>内存碎片化:回收后留下许多不连续的内存空间,影响大对象分配。</li><li>效率较低:GC 过程中,程序需要暂停(Stop-the-World)。</li></ul>
示例图
GC Roots → [对象 A] → [对象 B] (标记)
↓
[对象 C] (标记)
↓
[对象 D] (未标记) ❌ 清除
复制算法(Copying)
流程:
<ol><li>将对象分配在新生代的 Eden 区。</li><li>GC 时,将存活对象复制到 Survivor 区(S0 或 S1)。</li><li>清空 Eden 区和旧的 Survivor 区,腾出空间。</li></ol>
优点:
<ul><li>避免内存碎片化(因为总是把存活对象复制到新区域)。</li><li>适用于新生代对象,大部分对象生命周期短,复制成本低。</li></ul>
缺点:
<ul><li>额外的内存消耗(通常需要 2 个 Survivor 区,占堆 1/3)。</li><li>不适用于存活率高的对象(如老年代)。</li></ul>
示例图
Eden (对象 A, B, C) + Survivor 1 (对象 D) → Survivor 2 (复制 A, B, C, D) → 清空 Eden + Survivor 1<br>
标记-整理算法(Mark-Compact)
流程:
<ul><li>标记阶段:和标记-清除算法一样,标记存活对象。</li><li>整理阶段:将存活对象压缩到一端,清理无用对象,避免碎片化。</li></ul>
优点:
<ul><li>适用于老年代(Old Generation),避免内存碎片。</li><li>比复制算法更节省空间,无需预留 Survivor 区。</li></ul>
缺点:
整理阶段的移动操作开销较大。
示例图:
[存活对象] [无用对象] [存活对象] [无用对象] → [存活对象] [存活对象] [空闲空间]
分代回收(Generational Garbage Collection)
由于对象生命周期不同,JVM 采用 分代 GC,不同区域使用不同算法:
新生代(Young Generation):大部分对象生命周期短,使用 复制算法。
老年代(Old Generation):对象存活时间长,使用 标记-整理算法。
永久代/元空间(Metaspace):存放类元数据,GC 较少触发。
示例:
堆(Heap) = [Young Generation (Eden + S0 + S1)] + [Old Generation] + [Metaspace]
垃圾回收器
<br>
查看 JVM 默认 GC
java -XX:+PrintCommandLineFlags -version
Serial GC(串行垃圾回收器)
<ul><li>单线程执行 GC,适用于单核 CPU。</li><li>Stop-the-World 时间较长。</li><li>适用于 小型应用(如嵌入式设备)。</li></ul>
参数
-XX:+UseSerialGC<br>
Parallel GC(并行垃圾回收器)
<ul><li>多线程 GC,适用于 高吞吐量应用。</li><li>适用于 大内存场景(默认用于 JDK 8)。</li></ul>
参数
-XX:+UseParallelGC
CMS GC(Concurrent Mark-Sweep)
<ul><li>低延迟(低停顿),适用于 需要快速响应的应用(如 Web 服务器)。</li><li>并发执行 GC 任务,减少 Stop-the-World 时间。</li></ul>缺点:<br><ul><li>容易产生碎片化。</li><li>需要更多 CPU 资源。</li></ul>
参数:
-XX:+UseConcMarkSweepGC
G1 GC(Garbage First)
<ul><li>JDK 9+ 默认 GC,适用于 大堆内存应用(如 4GB 以上)。</li><li>区域化管理内存(Heap 被划分为多个小块)。</li><li>避免碎片化,优先回收垃圾最多的区域。</li><li>适用于 低延迟、高吞吐应用。</li></ul>
参数
-XX:+UseG1GC<br>
ZGC(低延迟 GC,JDK 11+)
<ul><li>适用于超大内存(100GB+)应用。</li><li>GC 停顿时间低于 10ms。</li><li>不移动对象,避免长时间 STW。</li></ul>
参数:
-XX:+UseZGC
总结
<br>
垃圾回收的基本概念
什么时候触发垃圾回收?
<ul><li>当堆内存不足时(如 OutOfMemoryError 之前)。</li><li>当对象不可达(无法通过任何引用访问)。</li><li>由 GC 触发策略决定(不同 GC 采用不同策略)。</li></ul>
如何判断对象是否需要回收?
JVM 采用 两种主要的对象存活判断方法:<br><br>引用计数法(Reference Counting)<br><br><ul><li>每个对象维护一个引用计数器,每次被引用时 +1,引用失效时 -1。</li><li>缺点:无法处理循环引用(即对象相互引用但不被外部对象引用)。<br></li></ul><br>可达性分析(Reachability Analysis)(JVM 采用)<br>通过 GC Roots 作为起点,遍历可达对象。<br>GC Roots 包括:<br><ul><li>栈帧中的本地变量表(线程活动区域)</li><li>方法区中的静态变量、常量池</li><li>JNI(Native 方法)引用的对象</li></ul>不可达对象会被 GC 处理。<br>
JVM 调优
JVM 提供了多种参数用于性能优化:
堆内存设置
java -Xms512m -Xmx1024m -XX:NewRatio=2 -XX:SurvivorRatio=8
GC 日志
java -XX:+PrintGCDetails -XX:+PrintGCDateStamps
总结
<ul><li>JVM 负责 Java 代码的执行,提供内存管理、类加载、GC 等功能。</li><li>运行时数据区 包括 方法区、堆、栈、本地方法栈、程序计数器。</li><li>执行引擎采用解释器+JIT 编译器,提升执行效率。</li><li>垃圾回收(GC)优化 JVM 性能,常见 GC 包括 G1、ZGC、CMS。</li><li>JVM 调优可以提升 Java 应用的性能,合理配置内存和 GC 参数是关键。</li></ul>
面试题
Java基础
八大基础类型
<ul><li>数字型: 字节类型(byte)、短整型short、整型int、长整型Long、单精度浮点数float、双精度浮点数double</li><li>字符型: 字符类型char、</li><li>布尔型: 布尔类型boolean、</li></ul>
java三大特性
<ul><li>封装: 使用private关键字,让对象私有,防止无关的程序去使用。</li><li>继承: 继承某个类,使子类可以使用父类的属性和方法。</li><li>多态: 同一个行为,不同的子类具有不同的表现形式。</li></ul>
重载和重写的区别
<ul><li>重载: 发生在同一类中,函数名必须一样,参数类型、参数个数、参数顺序、返回值、修饰符可以不一样。</li><li>重写: 发生在父子类中,函数名、参数、返回值必须一样,访问修饰符必须大于等于父类,异常要小于等于父类,父类方法是private不能重写。</li></ul>
pubilc、protected、(dafault)不写、private修饰符的作用范围
<ul><li>pubilc: 同一个类、同一个包、不同包的子类、不同包的非子类都可以访问。</li><li>protected: 同一个类、同一个包、不同包的子类可以使用,不同包的非子类不能。</li><li>(dafault)不写: 同一个类、同一个包可以使用,不同包的子类、不同包的非子类不能。</li><li>private: 只有同一个类可以。</li></ul>
==和equals的区别
<ul><li>==:基础类型比较的值,引用类型比较的是地址值。</li><li>equals: 没有重写比较地址值是否相等,重写比较的内容是否相对。比如String类重写equals,源码首先比较是否都是String对象,然后再向下比较。</li></ul>
hashcode()值相同,equals就一定为true
不一定,因为 "重地"和"通话"的hashcode值就相同,但是equals()就为false。
但是equals()为true,那么hashcode一定相同。
为什么重写equals(),就要重写hashcode()?
保证同一对象,如果不重写hashcode,可能会出现equals比较一样,但是hashcode不一样的情况。
short s = 1;s = s + 1;(程序1)和 short s = 1; s += 1;(程序2)是否都能正常运行
程序1会编译报错,因为 s + 1的1是int类型,因为类型不兼容。强制转换失败。<br>程序2可以正常运行,因为java在复合赋值解释是 E1 += E2,等价于 E1 = (T)(E1 + E2),T是E1的类型,因此s += 1等价于 s = (short)(s + 1),所以进行了强制类型的转换,所以可以正常编译。
说出下面程序的运行结果,及原因
public static void main(String[] args) {<br> Integer a = 128, b = 128, c = 127, d = 127;<br> System.out.println(a == b);<br> System.out.println(c == d);<br>}<br>结果:false,true<br><br>因为Integer = a,相当于自动装箱(基础类型转为包装类),因为Integer引入了IntegerCache来缓存一定的值,IntegerCache默认是 -128~127,所以128超过了范围,a和b不是相同对象,c和d是相同对象。<br>可以通过jvm启动时,修改缓存的上限。
&和&&的区别
<ul><li>&&: 如果一边为假,就不比较另一边。又叫短路运算符。</li><li>&: 不论一边是真是假,都会比较另一边。如果表达式两边不是Boolean类型时候,表示按位运算。</li></ul>
String、StringBuffer、StringBuilder的区别
<ul><li>String: 适用于少量字符串。创建之后不可更改,对String的修改会生成新的String对象。</li><li>StringBuilder: 适用于大量字符串,线程不安全,性能更快。单线程使用</li><li>StringBuffer: 适用于大量字符串,线程安全。多线程使用,用synchronized关键字修饰。</li></ul>
什么是反射
在运行过程中,对于任何一个类都能获取它的属性和方法,任何一个对象都能调用其方法,动态获取信息和动态调用,就是反射。
浅拷贝和深拷贝的区别
<ul><li>浅拷贝: 基础数据类型复制值,引用类型复制引用地址,修改一个对象的值,另一个对象也随之改变。</li><li><span style="font-size: inherit;">深拷贝: 基础数据类型复制值,引用类型在新的内存空间复制值,新老对象不共享内存,修改一个值,不影响另一个。</span></li><li><span style="font-size: inherit;">深拷贝相对浅拷贝速度慢,开销大。</span></li></ul>
构造器能被重写吗
不能,可以被重载。
并发和并行
<ul><li>并发: 宏观上看是一个处理器"同时"处理多个任务(实际上多个任务轮流使用时间片)。微观上是同一时间只有一个任务在执行。(一个人同时吃两个苹果)</li><li>并行: 多个处理器同时处理多个任务。(两个人同时吃两个苹果)</li></ul>
实例变量和类变量。
类变量是被static所修饰的,没有被static修饰的叫实例变量也叫成员变量。同理也存在类对象和实例对象,类方法和实例方法。<br><br>//类变量<br>public static String kunkun1 = "鸡你太美";<br><br>//实例变量(成员变量)<br>public String kunkun2 = "鸡你不美";
说出下面程序的运行结果,及原因
public class InitialTest {<br> public static void main(String[] args) {<br> A ab = new B();<br> ab = new B();<br> }<br>}<br>class A {<br> static { // 父类静态代码块<br> System.out.print("A");<br> }<br> public A() { // 父类构造器<br> System.out.print("a");<br> }<br>}<br>class B extends A {<br> static { // 子类静态代码块<br> System.out.print("B");<br> }<br> public B() { // 子类构造器<br> System.out.print("b");<br> }<br>}<br><br>结果:ABabab<br><br>原因:<br><ul><li>①执行顺序是 父类静态代码块(父类静态变量) -> 子类静态代码块(子类静态变量) -> 父类非静态代码块 -> 父类构造方法 -> 子类非静态代码块 -> 子类构造方法</li><li>②静态代码块(静态变量)只执行一次。</li></ul>
抽象类和接口的区别
<ul><li>抽象类只能单继承,接口可以实现多个。</li><li>抽象类有构造方法,接口没有构造方法。</li><li>抽象类可以有实例变量,接口中没有实例变量,有常量。</li><li>抽象类可以包含非抽象方法,接口在java7之前所有方法都是抽象的,java8之后可以包含非抽象方法。</li><li>抽象类中方法可以是任意修饰符,接口中java8之前都是public,java9支持private。</li><li>扩展:普通类是亲爹,手把手教你怎么学,抽象类(多个类具有相同的东西,拿出来放抽象类)是师傅,教你一部分秘籍,然后告诉你怎么学。接口(规范了某些行为)是干爹,只给你秘籍,怎么学全靠你。</li></ul>
Error和Exception有什么区别
<ul><li>Error: 程序无法处理,比较严重的问题,程序会立即崩溃,jvm停止运行。</li><li>Exception: 程序本身可以处理(向上抛出或者捕获)。编译时异常和运行时异常</li></ul>
NoClassDefFoundError和ClassNotFoundException区别
<ul><li>NoClassDefFoundError: 在打包时漏掉了某些类或者打包时存在,然后你把target里的类删除,然后jvm运行时找不到报错。</li><li>ClassNotFoundException: 在编译的时候某些类找不到,然后报错。</li></ul>
如果try{} 里有一个 return 语句,那么finally{} 里的代码会不会被执行,什么时候被执行,在 return 前还是后?
会执行,在return之前执行,如果finally有return那么try的return就会失效。
final关键字有哪些用法?
<ul><li>修饰类: 不能被继承。</li><li>修饰方法: 不能被重写。</li><li>修饰变量: 声明时给定初始值,只能读取不能修改。如果是对象引用不能改,但是对象的属性可以修改。</li></ul>
jdk1.8的新特性
<ul><li>①lambda 表达式</li><li>②方法引用</li><li>③加入了base64的编码器和解码器</li><li>④函数式接口</li><li>⑤接口允许定义非抽象方法,使用default关键字即可</li><li>⑥时间日期类改进</li></ul><br>
http中重定向和转发的区别
<ul><li>重定向发送两次请求,转发发送一次请求</li><li>重定向地址栏会变化,转发地址栏不会变化</li><li>重定向是浏览器跳转,转发是服务器跳转</li><li>重定向可以跳转任意网址,转发只能跳转当前项目</li><li>重定向会有数据丢失,转发不会数据丢失</li></ul>
get和post请求的区别 delete、put
<ul><li>get相对不安全,数据放在url中(请求行),post放在body中(请求体),相对安全。</li><li>get传送的数据量小,post传送的数据量大。</li><li>get效率比post高,是form的默认提交方法。</li></ul>
cookie和session的区别
<ul><li>存储位置不同:cookie放在客户端电脑,session放在服务器端内存的一个对象</li><li>存储容量不同:cookie <=4KB,一个站点最多保存20个cookie,session是没有上限的,但是性能考虑不要放太多,而且要设置session删除机制</li><li>存储数据类型不同:cookie只能存储ASCll字符串,session可以存储任何类型的数据</li><li>隐私策略不同:cookie放在本地,别人可以解析,进行cookie欺骗,session放在服务器,不存在敏感信息泄露</li><li>有效期不同:可以设置cookie的过期时间,session依赖于jsessionID的cookie,默认时间为-1,只需要关闭窗口就会失效</li></ul>
java中的数据结构
数组、链表、哈希表、栈、堆、队列、树、图
什么是跨域?跨域的三要素
跨域指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制
协议、域名、端口
注意:localhost和127.0.0.1虽然都指向本机,但也属于跨域
tomcat三个默认端口及其作用
<ul><li>8005:这个端口负责监听关闭tomcat的请求。</li><li>8009:接受其他服务器的请求</li><li>8080:用于监听浏览器发送的请求</li></ul>
throw 和 throws 的区别?
<ul><li>throw:抛出一个异常。</li><li>throws:声明一个异常。</li></ul>
说一下你熟悉的设计模式
<ul><li>单例模式: 保证被创建一次,节省系统开销。</li><li>工厂模式: 解耦代码。</li><li>观察者模式: 定义了对象之间的一对多的依赖,这样一来,当一个对象改变时,它的所有的依赖者都会收到通知并自动更新。</li><li>代理模式: 代理对象具备被代理对象的功能,并代替被代理对象完成相应操作,并能够在操作执行的前后,对操作进行增强处理。</li><li>模板模式: 较少代码冗余。例如:redis模板。</li></ul>
实例化对象有哪几种方式
<ul><li>① new</li><li>② clone()</li><li>③ 反射</li><li>④先序列化在反序列化</li></ul>
java中什么样的类不能被实例化
抽象类: abstract关键字修饰的类。
序列化和反序列化
<ul><li>序列化: 把对象转为字节序列的过程,在传递和保存对象时,保证了对象的完整性和可传递性,便于在网络传输和保存在本地文件中。</li><li>反序列化: 把字节序列转为对象的过程,通过字节流的状态和信息描述,来重建对象。</li></ul>
序列化的优点
将对象转为字节流存储到硬盘上,当JVM噶了的话,字节流还会在硬盘上等待,等待下一次JVM的启动,把序列化的对象,通过反序列化为原来的对象,减少储存空间和方便网络传输(因为是二进制)。
你知道什么是单点登录吗?
单点登录(SSO:Single Sign On): 同一账号在多系统中,只登录一次,就可以访问其他系统。多个系统,统一登录。
列如:在一个公司下,有多个系统,比如淘宝和天猫,你登录上淘宝,就不用再去登录天猫了。
实现单点登录的方式
<ul><li>① Cookie: 用cookie为媒介,存放用户凭证。登录上父应用,返回一个加密的cookie,访问子应用的时候,会对cookie解密校验,通过就可以登录。不安全和不能跨域免登。</li><li>② 分布式session实现: 用户第一次登录,会把用户信息记录下来,写入session,再次登录查看session是否含有对应信息。session系统不共享,使用缓存等方式来解决。</li><li>③重定向: 父应用提供一个GET方式的登录接口A,用户通过子应用重定向连接的方式访问这个接口,如果用户还没有登录,则返回一个登录页面,用户输入账号密码进行登录,如果用户已经登录了,则生成加密的token,并且重定向到子应用提供的验证token的接口B,通过解密和校验之后,子应用登录当前用户,虽然解决了安全和跨域,但是没前两种简单。</li></ul>
sso(单点登录)与OAuth2.0(授权)的区别?
<ul><li>单点登录: 就是一个公司多个子系统登录问题。</li><li>OAuth2.0: 是授权问题,比如微信授权问题。是一种具体的协议。</li></ul>
如何防止表单提交
<ul><li>①js屏蔽提交按钮。</li><li>②给数据库添加唯一约束。</li><li>③利用Session防止表单重复提交。会有一个token标记,表单提交的时候拦截器会检查是否一致,不一致就不通过。</li><li>④使用AOP切入实现。自定义注解,然后新增切入点,然后每次都记录过期时间,然后做比较。</li></ul>
泛型是什么?有什么好处?
本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。<br>好处:<br><ul><li>①类型安全</li><li>②消除强制类型转换</li><li>③提高性能</li><li>④提高代码的复用性</li></ul>
值传递和引用传递
<ul><li>值传递: 函数调用时会把实际参数,复制一份到函数中,函数中对参数进行操作,并不会影响参数实际的值。</li><li>引用传递: 将实际参数的地址值传递到函数中,函数对参数进行操作,会影响到实际参数的值。</li><li>注意: java中不存在引用传递(即使传的是对象,那也只是传递了对象的引用地址的副本,也属于值传递)。</li></ul>
java集合
List、Set、Map的区别
<ul><li>List集合有序、可重复的单例集合。</li><li>Set集合无序、不可重复的单例集合。</li><li>Map集合无序、k不可重复,v可重复的双例集合。</li></ul>
List、Set、Map常用集合有哪些?
List
vector
底层是数组,方法加了synchronized来保证线程安全,所以效率较慢,使用ArrayList替代。
ArrayList
线程不安全,底层是数组,因为数组都是连续的地址,所以查询比较快。增删比较慢,增会生成一个新数组,把新增的元素和原有元素放到新数组中,删除会导致元素移动,所以增删速度较慢。
LinkedList
线程不安全,底层是链表,因为地址不是连续的,都是一个节点和一个节点相连,每次查询都得重头开始查询,所以查询慢,增删只是断裂某个节点对整体影响不大,所以增删速度较快。
Set
HashSet
底层是哈希表(数组+链表或数组+红黑树),在链表长度大于8时转为红黑树,在红黑树节点小于6时转为链表。其实就是实现了HashMap,值存入key,value是一个final修饰的对象。
TreeSet
底层是红黑树结构,就是TreeMap实现,可以实现有序的集合。String和Integer可以根据值进行排序。如果是对象需要实现Comparator接口,重写compareTo()方法制定比较规则。
LinkedHashSet
实现了HashSet,多一条链表来记录位置,所以是有序的。
Map
TreeMap
底层是红黑树,key可以按顺序排列。
HashMap
底层是哈希表,可以很快的储存和检索,无序,大量迭代情况不佳。
LinkedHashMap
底层是哈希表+链表,有序,大量迭代情况佳。
ArrayList的初始容量是多少?扩容机制是什么?扩容过程是怎样?
初始容量: 默认10,也可以通过构造方法传入大小。<br><br>扩容机制: 原数组长度 + 原数组长度/2(源码中是原数组右移一位,也就相当于除以2)<br>注意:扩容后的ArrayList底层数组不是原来的数组。<br><br>扩容过程: 因为ArrayList底层是数组,所以它的扩容机制和数组一样,首先新建一个新数组,长度是原数组的1.5倍,然后调用Arrays.copyof()复制原数组的值,然后赋值给新数组。
什么是哈希表
根据关键码值(Key value)而直接进行访问的数据结构,在一个表中,通过H(key)计算出key在表中的位置,H(key)就是哈希函数,表就是哈希表。
什么是哈希冲突
不同的key通过哈希函数计算出相同的储存地址,这就是哈希冲突。
解决哈希冲突
(1)开放地址法<br>如果发生哈希冲突,就会以当前地址为基准,再去寻找计算另一个位置,直到不发生哈希冲突。<br>寻找的方法有:① 线性探测 1,2,3,m<br>② 二次探测 1的平方,-1的平方,2的平方,-2的平方,k的平方,-k的平方,k<=m/2<br>③ 随机探测 生成一个随机数,然后从随机地址+随机数++。<br><br>(2)链地址法<br>冲突的哈希值,连到到同一个链表上。<br><br>(3)再哈希法(再散列方法)<br>多个哈希函数,发生冲突,就在用另一个算计,直到没有冲突。<br><br>(4)建立公共溢出区<br>哈希表分成基本表和溢出表,与基本表发生冲突的都填入溢出表。
HashMap的hash()算法,为什么不是h=key.hashcode(),而是key.hashcode()^ (h>>>16)
得到哈希值然后右移16位,然后进行异或运算,这样使哈希值的低16位也具有了一部分高16位的特性,增加更多的变化性,减少了哈希冲突。
为什么HashMap的初始容量和扩容都是2的次幂
因为计算元素存储的下标是(n-1)&哈希值,数组初始容量-1,得到的二进制都是1,这样可以减少哈希冲突,可以更好的均匀插入。
HashMap如果指定了不是2的次幂的容量会发生什么?
会获得一个大于指定的初始值的最接近2的次幂的值作为初始容量。
HashMap为什么线程不安全
<ul><li>jdk1.7中因为使用头插法,再扩容的时候,可能会造成闭环和数据丢失。</li><li>jdk1.8中使用尾插法,不会出现闭环和数据丢失,但是在多线程下,会发生数据覆盖。(put操作中,在putVal函数里) 值的覆盖还有长度的覆盖。</li></ul>
解决Hashmap的线程安全问题
<ul><li>(1)使用Hashtable解决,在方法加同步关键字,所以效率低下,已经被弃用。</li><li>(2)使用Collections.synchronizedMap(new HashMap<>()),不常用。</li><li>(3)ConcurrentHashMap(常用)</li></ul>
ConcurrentHashMap的原理
<ul><li>jdk1.7: 采用分段锁,是由Segment(继承ReentrantLock:可重入锁,默认是16,并发度是16)和HashEntry内部类组成,每一个Segment(锁)对应1个HashEntry(key,value)数组,数组之间互不影响,实现了并发访问。</li><li>jdk1.8: 抛弃分段锁,采用CAS(乐观锁)+synchronized实现更加细粒度的锁,Node数组+链表+红黑树结构。只要锁住链表的头节点(树的根节点),就不会影响其他数组的读写,提高了并发度。</li></ul>
为什么用synchronized代替ReentrantLock
①节省内存开销。ReentrantLock基于AQS来获得同步支持,但不是每个节点都需要同步支持,只有链表头节点或树的根节点需要同步,所以使用ReentrantLock会带来很大的内存开销。<br>②获得jvm支持,可重入锁只是api级别,而synchronized是jvm直接支持的,能够在jvm运行时做出相应的优化。<br>③在jdk1.6之后,对synchronized做了大量的优化,而且有多种锁状态,会从 无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁一步步转换。<br><br>AQS (Abstract Queued Synchronizer): 一个抽象的队列同步器,通过维护一个共享资源状态( Volatile Int State )和一个先进先出( FIFO )的线程等待队列来实现一个多线程访问共享资源的同步框架。
HashMap为什么使用链表
减少和解决哈希冲突,把冲突的值放在同一链表下。
HashMap为什么使用红黑树
当数据过多,链表遍历较慢,所以引入红黑树。
HashMap为什么不一上来就使用红黑树
维护成本较大,红黑树在插入新的数据后,可能会进行变色、左旋、右旋来保持平衡,所以当数据少时,就不需要红黑树。
说说你对红黑树的理解
<ul><li>①根节点是黑色。</li><li>②节点是黑色或红色。</li><li>③叶子节点是黑色。</li><li>④红色节点的子节点都是黑色。</li><li>⑤从任意节点到其子节点的所有路径都包含相同数目的黑色节点。</li><li>红黑树从根到叶子节点的最长路径不会超过最短路径的2倍。保证了红黑树的高效。</li></ul>
为什么链表长度大于8,并且表的长度大于64的时候,链表会转换成红黑树?
因为链表长度越长,哈希冲突概率就越小,当链表等于8时,哈希冲突就非常低了,是千万分之一,我们的map也不会存那么多数据,如果真要存那么多数据,那就转为红黑树,提高查询和插入的效率。
为什么转成红黑树是8呢?而重新转为链表阈值是6呢?
因为如果都是8的话,那么会频繁转换,会浪费资源。
为什么负载因子是0.75?
加载因子越大,填满的元素越多,空间利用率越高,但发生冲突的机会变大了;<br>加载因子越小,填满的元素越少,冲突发生的机会减小,但空间浪费了更多了,而且还会提高扩容rehash操作的次数。<br>“冲突的机会”与“空间利用率”之间,寻找一种平衡与折中。<br>又因为根据泊松分布,当负载因子是0.75时,平均值时0.5,带入可得,当链表为8时,哈希冲突发生概率就很低了。
什么时候会扩容?
元素个数 > 数组长度 * 负载因子 例如 16 * 0.75 = 12,当元素超过12个时就会扩容。
链表长度大于8并且表长小于64,也会扩容
为什么不是满了扩容?
因为元素越多,空间利用率是高了,但是发生哈希冲突的几率也增加了。
扩容过程
<ul><li>jdk1.7: 会生成一个新table,重新计算每个节点放进新table,因为是头插法,在线程不安全的时候,可能会出现闭环和数据丢失。</li><li>jdk1.8: 会生成一个新table,新位置只需要看(e.hash & oldCap)结果是0还是1,0就放在旧下标,1就是旧下标+旧数组长度。避免了对每个节点进行hash计算,大大提高了效率。e.hash是数组的hash值,,oldCap是旧数组的长度。</li></ul>
HashMap和Hashtable的区别
<ul><li>①HashMap,运行key和value为null,Hashtable不允许为null。</li><li>②HashMap线程不安全,Hashtable线程安全。</li></ul>
集合为什么要用迭代器(Iterator)
更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。
如果不用迭代器,只能for循环,还必须知道集合的数据结构,复用性不强。
多线程
线程是什么?多线程是什么?
线程: 是最小的调度单位,包含在进程中。
多线程: 多个线程并发执行的技术。
守护线程和用户线程
守护线程: jvm给的线程。比如:GC守护线程。<br>用户线程: 用户自己定义的线程。比如:main()线程。<br><br>拓展:<br>Thread.setDaemon(false)设置为用户线程<br>Thread.setDaemon(true)设置为守护线程
线程的各个状态
<ul><li>新建(New): 新建一个线程。</li><li>就绪(Runnable): 抢夺cpu的使用权。</li><li>运行(Running): 开始执行任务。</li><li>阻塞(Blocked): 让线程等待,等待结束进入就绪队列。</li><li>死亡(Dead): 线程正常结束或异常结束。</li></ul>
线程相关的基本方法有 wait,notify,notifyAll,sleep,join,yield 等
wait(): 线程等待,会释放锁,用于同步代码块或同步方法中,进入等待状态<br>sleep(): 线程睡眠,不会释放锁,进入超时等待状态<br>yield(): 线程让步,会使线程让出cpu使用权,进入就绪状态<br>join(): 指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。<br>notify(): 随机唤醒一个在等待中的线程,进入就绪状态。<br>notifyAll(): 唤醒全部在等待中的线程,进入就绪状态。
wait()和sleep()的区别?
<ul><li>① wait() 来自Object,sleep()来自Thread。</li><li>② wait()会释放锁,sleep()不会释放锁。</li><li>③ wait()只能用在同步方法或代码块中,sleep()可以用在任何地方。</li><li>④ wait()不需要捕获异常,sleep()需要捕获异常。</li></ul>
为什么 wait()、notify()、notifyAll()方法定义在 Object 类里面,而不是 Thread 类?
<ul><li>① 锁可以是任何对象,如果在Thread类中,那只能是Thread类的对象才能调用上面的方法了。</li><li>② java中进入临界区(同步代码块或同步方法),线程只需要拿到锁就行,而并不关心锁被那个线程持有。</li><li>③ 上面方法是java两个线程之间的通信机制,如果不能通过类似synchronized这样的Java关键字来实现这种机制,那么Object类中就是定义它们最好的地方,以此来使任何Java对象都可以拥有实现线程通信机制的能力。</li></ul>
start()和run()的区别
<ul><li>start()方法: 是启动线程,调用了之后线程会进入就绪状态,一旦拿到cpu使用权就开始执行run()方法,不能重复调用start(),否则会报异常。</li><li>run()方法: 就相当于一个普通的方法而已。直接调用run()方法就还只有一个主线程,还是会顺序执行,也可以重复调用run()方法。</li></ul>
实现多线程的方式
<ul><li>①继承Thread类。</li><li>②实现Runnable接口</li><li>③实现Callable接口</li><li>④线程池</li></ul>
Runnable和Callable的区别
<ul><li>①Runnable没有返回值,Callable有返回值。</li><li>②Runnable只能抛出异常,不能捕获,Callable 能抛出异常,也能捕获。</li></ul>
线程池的好处
<ul><li>① 线程是稀缺资源,使用线程池可以减少线程的创建和销毁,每个线程都可重复使用。</li><li>② 可以根据系统的需求,调整线程池里面线程的个数,防止了因为消耗内存过多导致服务器崩溃。</li></ul>
线程池的七大参数
<ul><li>corePoolSize: 核心线程数,创建不能被回收,可以设置被回收。</li><li>maximumPoolSize: 最大线程数。</li><li>keepAliveTime: 空闲线程存活时间。</li><li>unit: 单位。</li><li>workQueue: 等待队列。</li><li>threadFactory: 线程工程,用于创建线程。</li><li>handler: 拒绝策略。</li></ul>
线程池的执行过程
<ul><li>①接到任务,判断核心线程池是否满了,没满执行任务,满了放入等待队列。</li><li>②等待队列没满,存入队列,等待执行,满了去查看最大线程数。</li><li>③最大线程数没满,执行任务,满了执行拒绝策略。</li></ul>
四大方法
<ul><li>①ExecutorService executor = Executors.newCachedThreadPool(): 创建一个缓存线程池,灵活回收线程,任务过多,会oom。</li><li>②ExecutorService executor = Executors.newFixedThreadPool(): 创建一个指定线程数量的线程池。提高了线程池的效率和线程的创建的开销,等待队列可能堆积大量请求,导致oom。</li><li>③ExecutorService executor = Executors.newSingleThreadPool(): 创建一个单线程,保证线程的有序,出现异常再次创建,速度没那么快。</li><li>④ExecutorService executor = Executors.newScheduleThreadPool(): 创建一个定长的线程池,支持定时及周期性任务执行。</li></ul>
四大拒绝策略
①new ThreadPoolExecutor.AbortPolicy(): 添加线程池被拒绝,会抛出异常(默认策略)。<br>②new ThreadPoolExecutor.CallerRunsPolicy(): 添加线程池被拒绝,不会放弃任务,也不会抛出异常,会让调用者线程去执行这个任务(就是不会使用线程池里的线程去执行任务,会让调用线程池的线程去执行)。<br>③new ThreadPoolExecutor.DiscardPolicy(): 添加线程池被拒绝,丢掉任务,不抛异常。<br>④new ThreadPoolExecutor.DiscardOldestPolicy(): 添加线程池被拒绝,会把线程池队列中等待最久的任务放弃,把拒绝任务放进去。
shutdown 和 shutdownNow 的区别?
<ul><li>① shutdown没有返回值,shutdownNow会返回没有执行完任务的集合。</li><li>②shutdown不会抛出异常,shutdownNow会抛出异常。</li><li>③shutdown会等待执行完线程池的任务在关闭,shutdownNow会给所以线程发送中断信号,然后中断任务,关闭线程池。</li></ul>
什么是死锁?
各进程互相等待对方手里的资源,导致各进程都阻塞,无法向前推进的现象。
造成死锁的四个必要条件
<ul><li>互斥: 当资源被一个线程占用时,别的线程不能使用。</li><li>不可抢占: 进程阻塞时,对占用的资源不释放。</li><li>不剥夺: 进程获得资源未使用完,不能被强行剥夺。</li><li>循环等待: 若干进程之间形成头尾相连的循环等待资源关系。</li></ul>
线程安全主要是三方面
<ul><li><span style="font-size: inherit;">原子性: 一个或多个操作,要么全部执行,要么全部不执行(执行的过程中是不会被任何因素打断的)。</span></li><li><span style="font-size: inherit;">可见性: 一个线程对主内存的修改可以及时的被其他线程观察到。</span></li><li><span style="font-size: inherit;">有序性: 程序执行的顺序按照代码的先后顺序执行。<br><br></span></li><li><span style="font-size: inherit;">保证原子性</span></li><li><span style="font-size: inherit;">使用锁 synchronized和 lock。</span></li><li><span style="font-size: inherit;">使用CAS (compareAndSet:比较并交换),CAS是cpu的并发原语)。<br><br></span></li><li><span style="font-size: inherit;">保证可见性</span></li><li><span style="font-size: inherit;">使用锁 synchronized和 lock。</span></li><li><span style="font-size: inherit;">使用volatile关键字 。<br><br></span></li><li><span style="font-size: inherit;">保证有序性</span></li><li><span style="font-size: inherit;">使用 volatile 关键字</span></li><li><span style="font-size: inherit;">使用 synchronized 关键字。</span></li></ul><br>
volatile和synchronized的区别
<ul><li>① synchronized是关键字,lock是java类,默认是不公平锁(源码)。</li><li>② synchronized适合少量同步代码,lock适合大量同步代码。</li><li>③ synchronized会自动释放锁,lock必须放在finally中手工unlock释放锁,不然容易死锁。</li></ul>
JMM(java内存模型)
java内存模型,一个抽象的概念,不是真是存在,描述的是一种规则或规范,和多线程相关的规则。需要每个JVM都遵循。
JMM的约定
<ul><li>①线程解锁前,必须把共享变量立即刷回主存。</li><li>②线程加锁前,必须读取主存中的最新值到工作内存中。</li><li>③加锁和解锁必须是同一把锁。</li></ul>
JMM的八个命令
为了支持JMM,定义了8条原子操作,用于主存和工作内存的交互。<br><br>lock(锁定): 作用于主内存的变量,把一个变量标识为一条线程独占状态。<br>unlock(解锁): 作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。<br><br>read(读取): 作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用。<br>load(载入): 作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。<br><br>use(使用): 作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎。<br>assign(赋值): 作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量。<br><br>store(存储): 作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以遍随后的write的操作。<br>write(写入): 作用于主内存的变量,它把store操作从工作内存中的一个变量的值传送到主内存的变量中。
为什么要有JMM,用来解决什么问题?
解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
JVM
jvm是什么?
java虚拟机,是实现java跨平台的核心组件。
jvm的作用
java中所有的类,必须被装载到jvm中才能使用,装载由类加载器完成,.class这个类型可以在虚拟机运行,但不是直接和操作系统交互,需要jvm解释给操作系统,解释的时候需要java类库,这样就能和操作系统交互。
java文件的加载过程
.java -> .class -> 类加载器 -> jvm
jdk、jre、jvm的区别
<ul><li>jdk: 包含java运行环境和开发环境、jvm、java类库。</li><li>jre: 包含java运行环境和jvm、java类库。</li><li>jvm: java虚拟机,是跨平台的核心组件。</li></ul>
类加载器的作用
将.class文件装载到jvm中,实质就是把文件从硬盘写到内存。
类加载器的类型
引导类加载器(Bootstrap ClassLoader): c++编写,jvm自带的加载器,负责加载java核心类库,该加载器无法直接获取。<br>拓展类加载器(Extension ClassLoader): 加载jre/lib/etc目录下的jar包。<br>系统类加载器(Application ClassLoader): 加载当前项目目录下的类或jar包,最常用的加载器。<br>自定义加载器(Custom ClassLoader): 开发人员自定义的。需要继承ClassLoader
双亲委派机制的加载过程
<ul><li>①接到类加载的请求。</li><li>②向上委托给父类加载器,直到引导类加载器。</li><li>③引导类加载器检查能否加载当前这个类,如果能,使用当前加载器,请求结束,如果不能,抛出异常,通知子加载器进行加载。</li><li>④重复③。</li></ul>
双亲委派机制的优缺点
<ul><li>优点:保证类加载的安全性,不管那个类被加载,都会被委托给引导类加载器,只有类加载器不能加载,才会让子加载器加载,这样保证最后得到的对象都是同样的一个。</li><li>缺点:子加载器可以使用父加载器加载的类,而父加载器不能使用子加载器加载的类。</li></ul>
为什么要打破双亲委派机制
子加载器可以使用父加载器加载的类,而父加载器不能使用子加载器加载的类。<br>例如:使用JDBC连接数据库,需要用到 com.mysql.jdbc.Driver和DriverManager类。然而DriverManager被引导类加载器所加载,而com.mysql.jdbc.Driver被当前调用者的加载器加载,使用引导类加载器加载不到,所以要打破双亲委派机制。
打破双亲委派机制的方式
<ul><li>① 自定义类加载器,重写loadclass方法。</li><li>② 使用线程上下文类(ServiceLoader:使父加载器可以加载子加载器的类)。</li></ul>
jvm的每个部分储存的都是什么
<ul><li>方法区(线程共享): 常量池、静态(static)变量以及方法信息(方法名、返回值、参数、修饰符等)等。</li><li>堆(线程共享): 是虚拟机内存中最大的一块,储存的是实例对象和数组。</li><li>本地方法栈(线程不共享): 调用的本地方法,被native修饰的方法,java不能直接操作操作系统,所以需要native修饰的方法帮助。</li><li>虚拟机栈(线程不共享): 8大基本类型、对象引用、实例方法。</li><li>程序计数器(线程不共享): 每个线程启动是都会创建一个程序计数器,保存的是正在执行的jvm指令,程序计数器总是指向下一条将被执行指令的地址。</li></ul>
内存溢出(oom)和栈溢出
<ul><li>内存溢出的原因: (1)内存使用过多或者无法垃圾回收的内存过多,使运行需要的内存大于提供的内存。</li><li> (2)长期持有某些资源并且不释放,从而使资源不能及时释放,也称为内存泄漏。</li><li>解决: (1)进行jvm调优。-Xmx:jvm最大内存。-Xms:启动初始内存。-Xmn:新生代大小。 -Xss:每个虚拟机栈的大小。</li><li> (2)使用专业工具测试。</li><li>手动制造: 一直new对象就ok。<br><br></li><li>栈溢出原有: 线程请求的栈容量大于分配的栈容量。</li><li>解决: (1)修改代码 (2)调优 -Xss</li><li>手动制造: 一直调用实例方法。</li></ul><br>
垃圾回收的作用区域
作用在方法区和堆,主要实在堆中的伊甸园区。年轻代分为(伊甸园区和幸存区)
怎么判断对象是否可回收
可达性分析算法: 简单来说就是一个根对象通过引用链向下走,能走到的对象都是不可回收的。可作为根对象有: 虚拟机栈的引用的对象,本地栈的引用的对象,方法区引用的静态和常量对象。<br><br>引用计数算法: 每个对象都添加一个计数器,每多一个引用指向对象,计数器就加一,如果计数器为零,那么就是可回收的。
四种引用类型 强引用 软引用 弱引用 虚引用
<ul><li>强引用: 基于可达性分析算法,只有当对象不可达才能被回收,否则就算jvm满了,也不会被回收,会抛出oom。</li><li>软引用: 一些有用但是非必须的对象,当jvm即将满了,会将软引用关联对象回收,回收之后如果内存还是不够,会抛出oom。</li><li>弱引用: 不论内存是否够,只要开始垃圾回收,软引用的关联对象就会被回收。</li><li>虚引用: 最弱的引用和没有一样,随时可能被回收。</li></ul>
垃圾回收算法
(1)标记-清除算法(适用老年代): 先把可回收的对象进行标记,然后再进行清除。<br>优点: 算法简单。<br>缺点: 产生大量的内存碎片,效率低。<br><br>(2)复制算法(适用年轻代): 把内存分成两个相同的块,一个是from,一个是to,每次只使用一个块,当一个块满了,就把存活的对象放到另一个块中,然后清空当前块。主要用在年轻区中的幸存区。<br>优点: 效率较高,没有内存碎片。<br>缺点: 内存利用率低。<br><br>(3)标记-整理算法(适用老年代): 标记-清除算法的升级版,也叫标记-压缩算法,先进行标记,然后让存活对象向一端移动,然后清除掉边界以外的内存。<br>有点: 解决了内存利用率低和避免了内存碎片。<br>缺点: 增加了一个移动成本。
轻GC(Minor GC)和 重GC(Full GC)
<ul><li>轻GC: 普通GC,当新对象在伊甸园区申请内存失败时,进行轻GC,会回收可回收对象,没有被回收的对象进入幸存区,新对象分配内存极大部分都是在伊甸园区,所以这个区GC比较频繁。一个对象经历15次GC,会进入老年区,可以设置。</li><li>重GC: 全局GC,对整个堆进行回收,所以要比轻GC慢,因此要减少重GC,我们所说的jvm调优,大部分都是针对重GC。</li></ul>
什么时候会发生重GC
<ul><li>①当老年区满了会重GC:年轻区对象进入或创建大对象会满。</li><li>②永久代满了会重GC。</li><li>③方法区满了会重GC。</li><li>④system.gc()会重GC 。</li><li>⑤轻GC后,进入老年代的大小大于老年代的可用内存会,第一次轻GC进入老年代要2MB,第二次的时候会判断是否大于2MB,不满足就会重GC。</li></ul>
锁
悲观锁和乐观锁
<ul><li>悲观锁: 在修改数据时,一定有别的线程来使用,所以在获取数据的时候会加锁。java中的synchronized和Lock都是悲观锁。</li><li>乐观锁: 在修改数据时,一定没有别的线程来使用,所以不会添加锁。但是在更新数据的时候,会查看有没有线程修改数据。比如:版本号和CAS原理(无锁算法)。</li></ul>
悲观锁和乐观锁的场景
<ul><li>悲观锁: 更适合写操作多的场景,因为先加锁可以保证数据的正确。</li><li>乐观锁: 更适合读操作多的场景,因为不加锁会让读操作的性能提升。</li></ul>
自旋锁和自适应自旋锁
<ul><li>前言:因为线程竞争,会导致线程阻塞或者挂起,但是如果同步资源的锁定时间很短,那么阻塞和挂起的花费的资源就得不偿失。</li><li>自旋锁: 当竞争的同步资源锁定时间短,就让线程自旋,如果自旋完成后,资源释放了锁,那线程就不用阻塞,直接获取资源,减少了切换线程的开销。实现原理是CAS。</li><li>缺点:占用了处理器的时间,如果锁被占用的时间短还好,如果长那就白白浪费了处理器的时间。所以要限定自旋次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。</li></ul><br><ul><li>自适应自旋锁: 自旋次数不固定,是由上一个在同一个锁上的自旋时间和锁拥有者的状态决定。如果在同一个锁对象上,自旋刚刚获得锁,并且持有锁的线程在运行,那么虚拟机会认为这次自旋也可能成功,那么自旋的时间就会比较长,如果某个锁,自旋没成功获得过,那么可能就会直接省掉自旋,进入阻塞,避免浪费处理器时间。</li></ul>
无锁、偏向锁、轻量级锁、重量级锁
这四个锁是专门针对synchronized的,在 JDK1.6 中,对 synchronized 锁的实现引入了大量的优化,并且 synchronized 有多种锁状态。级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。<br><ul><li>无锁: 就是乐观锁。</li><li>偏向锁: 当只有一个线程访问加锁的资源,不存在多线程竞争的情况下,那么线程不需要重复获取锁,这时候就会给线程加一个偏向锁。(对比Mark Word解决加锁问题,避免CAS操作)</li><li>轻量级锁: 是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。(CAS+自旋)</li><li>重量级锁: 若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。(将除了拥有锁的线程以外的线程都阻塞)</li></ul>
公平锁和非公平锁
<ul><li>公平锁: 多个线程按照申请锁的顺序来获取锁。 Lock lock = new ReentrantLock(true); 默认是非公平锁,设置为true是公平锁。</li><li>优点:等待线程不会饿死。</li><li>缺点:CPU唤醒线程得开销比非公平锁要大。</li></ul><br><ul><li>非公平锁: 多个线程获取锁的顺序并不是按照申请锁的顺序。 sybchronized和lock都是非公平锁。</li><li>优点:减少唤醒线程得开销。</li><li>缺点:可能会出现线程饿死或者很久获得不了锁。</li></ul>
可重入锁
可重入锁: 也叫递归锁,同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁。(前提:锁对象是同一个对象或者类)。ReentrantLock和synchronized都是可重入锁。
独享锁和共享锁
<ul><li>独享锁: 独占锁是指锁一次只能被一个线程所持有。如果一个线程对数据加上排他锁后,那么其他线程不能再对该数据加任何类型的锁。获得独占锁的线程即能读数据又能修改数据。synchronized和Lock的实现类就是独占锁。</li><li>共享锁: 共享锁是指锁可被多个线程所持有。如果一个线程对数据加上共享锁后,那么其他线程只能对数据再加共享锁,不能加独占锁。获得共享锁的线程只能读数据,不能修改数据。</li></ul>
互斥锁和读写锁
<ul><li>互斥锁: 是独享锁的实现,某一资源同时只允许一个访问者对其访问。具有唯一和排它性。</li><li>读写锁: 是共享锁的实现,读写锁管理一组锁,一个是只读的锁,一个是写锁。读锁可以在没有写锁的时候被多个线程同时持有,而写锁是独占的。写锁的优先级要高于读锁。并发度要比互斥锁高,因为可以拥有多个读锁。</li></ul>
分段锁
是锁的设计,不是具体的某一种锁,分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
ConcurrentHashMap的锁机制jdk1.7用的就是分段锁。
锁优化技术
<ul><li>锁粗化: 将多个同步块的数量减少,并将单个同步块的作用范围扩大,本质上就是将多次上锁、解锁的请求合并为一次同步请求。</li><li>锁消失: 锁消除是指虚拟机编译器在运行时检测到了共享数据没有竞争的锁,从而将这些锁进行消除。</li></ul>
CAS原理
什么是CAS?
CAS(Compare And Swap): 比较并替换,是一种无锁算法。在不使用锁的情况下实现多线程之间的变量同步。
V: 主存的值
E: 预期的值
N: 新值
CAS实现过程
注意:<br>① 在线程开启的时候,会从主存中给每个线程拷贝一个变量副本到本线程各自的运行环境中。<br>② 失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次发起尝试。<br><br>并发环境: 执行 +1 操作,主存 V 初始值为 0,有两个线程 T1和T2。各自副本变量V1、V2为0,假设T1先拿到执行权<br><br><ul><li>第一步: T1 读取当前 V1 的值赋值给 E1。</li><li>第二步: T1 执行 +1 操作,N1 = E1 + 1。</li><li>第三步: E1 和 主存 V比较,发现 E1 = V。</li><li>第四步: 将N1,写入主存,主存 V 变为 1。</li><li>第五步: T2拿到执行权,T2读取当前V2 的值赋值给 E2(这时V2还是0)。</li><li>第六步: T2 执行 +1 操作,N2 = E2 + 1。</li><li>第七步: E2 和 主存 V 比较,发现 E2 != V。</li><li>第八步: 重新获取 主存的值,V = 1,赋值给 V2,V2 赋值给E2。</li><li>第九步: T2 执行 +1 操作,N2 = E2 + 1。</li><li>第十步: E2 和 主存 V比较,发现 E2 = V。</li><li>第十一步: 将N2,写入主存,主存 V 变为 2。完成任务。<br></li></ul><br>原文地址:https://blog.csdn.net/twotwo22222/article/details/128944814?spm=1001.2014.3001.5502<br>
CAS的缺点
<ul><li>1.循环时间长<br>如果很多线程都去修改一个值,就会一直不成功一直尝试。</li></ul><ul><li>2.只能保证一个共享变量是原子操作</li><li>3.ABA问题和解决方法</li></ul>原因: 线程1操作变量改为A,线程挂起,然后线程2操作变量改为X,又改为Z,最后改为A,其实中间变量的值已经被改变。<br>解决:<br>① 使用 AtomicStampReference 类,增加了一个标记 stamp,可以判断数据有没有被修改过。<br><br>public class AtomicStampedReference<V> {<br><br> private static class Pair<T> {<br> final T reference;<br> final int stamp;<br> private Pair(T reference, int stamp) {<br> this.reference = reference;<br> this.stamp = stamp;<br> }<br> static <T> Pair<T> of(T reference, int stamp) {<br> return new Pair<T>(reference, stamp);<br> }<br> }<br>② 可以使用版本号,其实和上面stamp原理差不多。<br>
i++和++i是原子性操作吗?
不是原子性操作。不是一条单独的指令。是三条指令
第一步:获取这个值
第二步:+1
第三步:写回这个值
i++ 不加lock和synchronized怎么保证原子性?
有Atomic类里面有AtomicInteger类(底层是CAS)。<br><br> //提供了硬件级别的原子操作,方法都是 native 修饰<br> private static final Unsafe unsafe = Unsafe.getUnsafe();<br> private static final long valueOffset;<br> public final boolean compareAndSet(int expect, int update) {<br> //valueOffset=V,E=expect,N=update<br> return unsafe.compareAndSwapInt(this, valueOffset, expect, update);<br> }<br><br><br> 实例:<br> public static void main(String[] args) {<br> //初始值是0,源码里面有注释<br> AtomicInteger a1 = new AtomicInteger();<br><br> //初始值是250<br> AtomicInteger a2 = new AtomicInteger(250);<br><br> //以原子方式将当前值递增1并在递增后返回新值。它相当于i++操作。<br> int i1 = a1.incrementAndGet();<br> System.out.println(i1); // 1<br> <br> //以原子方式递增当前值并返回旧值。它相当于++i操作。<br> int i2 = a2.getAndIncrement();<br> System.out.println(i2); // 250<br> }
框架
springboot
springcloud
mybatis
缓存
redis
memcached
消息队列
数据库

收藏
立即使用
Collect
Get Started

Collect
Get Started

Collect
Get Started
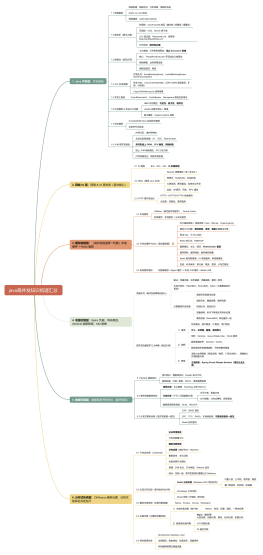
Collect
Get Started
评论
0 条评论
下一页