电商创业AI客服训练:自然语言处理模型优化指南
2025-05-12 01:20:40 0 举报AI智能生成
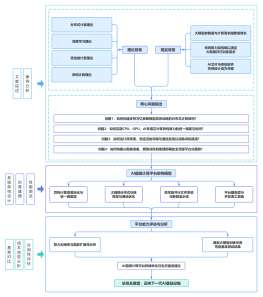
电商创业AI客服训练:自然语言处理模型优化指南
模板推荐
作者其他创作
大纲/内容



0 条评论
下一页

