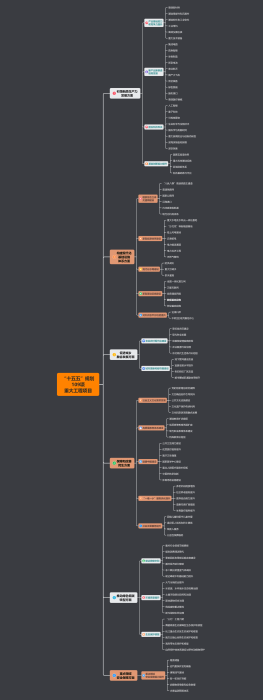
模型分类
LLM大语言模型<br>(Large Language Model)<br>
小型模型<br>
参数量:百万-十亿,如Model-1M或者Lite/Small<br>
中型模型<br>
参数量:十亿至三百亿 1B-30B,Billion十亿<br>
大型模型<br>
参数量:三百亿至二千亿 30B-200B<br>
超大型模型
参数量:二千亿以上 200B以上<br>
GPT-4o中的4o代表的是“omni”,意为“全能”或“所有”的概念
多模态模型
是一种能够处理和整合<b>多种类型数据</b>(如文本、图像、音频、视频等)的<b>深度学习模型</b>
特点
<b>多才多艺:</b>能够同时处理和融合来自多种模态的数据,实现<b>信息互补和综合理解</b><br>
<b>理解力强:</b>不仅能看懂单个信息,还能理解这些<b>信息之间的关系</b><br>
<b>能干多种活:</b>支持多个任务(如<b>图像分类、文本生成、情感分析</b>等)在一个模型中进行,提高模型的<b>泛化能力和效率</b><br>
<b>学习能力强:</b>多模态模型往往先在大规模多模态数据集上进行预训练,学习跨模态的共同表示,之后再针对具体任务进行微调,以适应特定应用场景<br>
专有模型
医疗健康:MedBench<br>
自动驾驶
工作原理
通俗原理:根据上下文,猜下一个词(的概率)<br>
深入理解
<b><font color="#e74f4c">大模型训练:</font></b>就是让AI“努力学习”的过程。就像教一个孩子从不懂到懂,AI也需要通过大量数据来学习知识和技能<br><b>1、喂数据:</b>让AI“疯狂刷题”<br><b>2、调参数:</b>帮AI“找到最佳学习方法”<br><b>3、迭代升级:</b>让AI“越学越聪明”<br><font color="#4669ea"><b>Tips:</b></font><br>a、大模型阅读人类说过的所有的话,这就是<b>「机器学习」</b><br>b、训练过程会把不同token同时出现的概率存入<b>「神经网络」</b>文件。保存的数据就是<b>「参数」</b>,也叫<b>「权重」</b><br>
<b><font color="#e74f4c">大模型推理:</font></b>通俗来讲,就是<b>AI“动脑筋思考并给出答案”</b>的过程。就像你做完数学题、写完作文一样,AI也需要通过一系列计算来“想”出结果<br>1、接收输入:AI的“耳朵和眼睛”<br>2、计算匹配:AI的“大脑运算”<br>3、输出答案:AI的“嘴巴”<br><font color="#4669ea"><b>Tips:</b></font><br>a、给推理程序若干token,程序会<b>加载大模型权重,</b>算出概率最高的下一个token<br>b、用生成的token,再结合上文,就能继续生成下一个token,以此类推
Token
通俗来讲,就是<b><font color="#4669ea">AI处理语言时的“最小单位”</font></b>,就像我们读文章时的一个字或一个词<br>1、字符:最小的书写单位,比如汉字;“苹果”=2个字符<br>2、词:有语义的单位,比如“苹果”;“苹果”=1个词<br><b><font color="#4669ea">3、Token:</font></b>AI处理的最小单位,可以自定义;<font color="#4669ea">“苹果”=1或2个Token(看怎么拆)</font><br>
拆分方式
<b>中文:</b>可能按字/词/偏旁部首来拆(比如“我爱北京”拆成“我”、“爱”、“北京”)<br>
<b>英文:</b>英文可能按空格和子词来拆(比如“running”拆成“run”和“##ing”)<br>
AI应用分类
助手类
ChatGPT、DeepSeek、通义千问、Kimi Chat、文小言、智谱清言<br>
搜索类
Perplexity、秘塔AI、Devv<br>
定制Agent
ChatGPT GPTS、coze、dify<br>
生活应用类<br>
石头扫地机器人、小米智能门锁、Siri、小爱同学、小度智能屏<br>
大模型幻觉
是指模型生成的内容与现实世界事实或用户输入不一致的现象,分为 事实性幻觉 和 忠实性幻觉
减少幻觉的几个方向
提高数据质量
模型校准<br>
增强上下文理解
引入外部知识
用户反馈机制<br>
大模型应用业务架构<br>
AI Embedded AI嵌入<br>通常被用来提升现有应用智能化程度,改善用户体验或增加功能<br>
<br>
AI Copilot AI助理模式<br>大模型是用户的合作伙伴<br>协助用户完成任务
<br>
AI Agent AI智能体模式<br>被设计为独立的代理系统<br>具有高度自治能力<br>能代表用户处理事务
<br>
大模型应用技术架构
提示词<br>
<b>代表:</b>ChatGPT、文心一言<br><b>特点:</b>用户发一句提示词prompt,大模型回一句“输出结果”<br><b>本质:在大模型基础上,套了一层聊天应用的壳,</b>调用大模型的解码器,输入参数是 " 提示词 Prompt " ,得到的结果是 解码器 针对提示词 以及综合训练的大模型向量数据根据概率生成的 " 输出结果 "<br>
Agent + Function Calling
1、用户在 应用程序 中输入 " 提示词 " ;<br>2、进行函数调用,AI大模型分析提示词,发现需要调用"应用程序" 的API , 这是 大模型 "回调"应用/大模型 的功能;调用 API 功能完毕后,继续看是否满足 " 提示词 " 的要求,不满足的话继续进行 函数调用,直到满足为止继续执行下一步<br>3、输出符合 " 提示词 " 要求的 文本结果;<br><b><font color="#4669ea">说明:</font></b>Agent + Function Calling 技术架构 使用非常广泛 , 可以 将<font color="#4669ea"><b>自己开发的应用功能嵌入到 AI 大模型中 </b></font>, 将复杂的逻辑分解成 更小的/可管理的部分 , 每个部分通过<b>调用 不同的函数 实现</b><br>
" RAG = Embeddings + Vector Database " 技术架构
RAG:Retrieval-Augmented Generation,检索增强生成,结合 " <b>Embeddings 嵌入 " 和 " Vector Database 向量数据库 " </b>,该架构用于 自然语言处理领域 的 <b>信息检索 和 生成任务<br></b>1、<b><font color="#4669ea">Embeddings 嵌入是把文字转为容易计算的编码向量</font></b>,是将 词语或文本 映射到高维向量空间的技术<br><b><font color="#4669ea">2、向量数据库Vector Database</font></b>是一种专门用于存储和检索向量数据的数据库系统 , 可以通过特定的数据结构和算法加速向量之间的比较和匹配过程<br>执行流程:<br>a、用户输入 " 提示词 " <br>b、AI 大模型 拿到 " 提示词 " 之后 , 先到 " 向量数据库 " 中 , 检索所有可能与该 " 提示词 " 相关的知识<br>c、根据 " 提示词 " 从向量数据库中检索出来的知识一起传递给AI 大模型 , <font color="#e74f4c"><b>相当于将 " 检索出来的知识 " 追加到了提示词中</b></font>,后面的 AI大模型执行就相当于Agent+Function Calling 技术架构过程<br>
Fine-tuning 微调 技术架构
Fine-tuning:是在一个已有的 AI 大模型基础上 , 进行微调操作<br>1、<b>要预训练模型</b> , 初期要有一个已经 训练好的 GPT 大模型<br>2、将 预训练模型 应用到特定的任务上 , 每个任务要有:输入数据格式、输出要求、评估指标<br>3、验证数据集评估模型性能 , 如果对结果不满意 , <font color="#e74f4c"><b>持续进行 超参数调整 和 Fine-tuning 策略的优化</b></font> , 直到得到满意结果为止