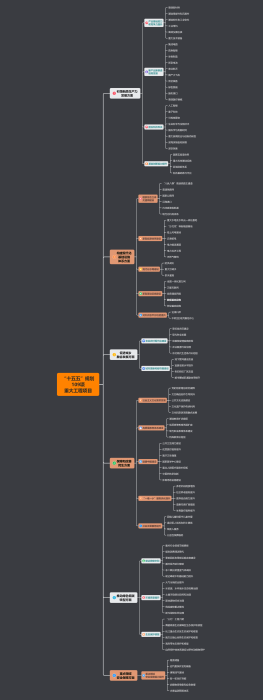
GPT
1、Pretrain(预训练)<br>
<b><font color="#e0c431">基本流程:</font></b><br>1、不停阅读大量文字资料<br>2、学习人类如何使用文字(一字一字地学习)<br>3、学习最多的人类知识;学习文字表达方式
<b>核心问题:<br></b>因只是输出了“候选字”的概率清单<br>预训练模型(Pretrain)输出<b>非常像“接话茬”,<br>并不是在“做任务”</b><br>
2、SFT(Supervised Fine-Tuning)<br>有监督的微调
<b style=""><font color="#e0c431">有监督(Supervised)学习:</font></b>使用有标签的数据进行训练,学习的过程叫有监督学习<br><b style=""><font color="#e0c431">无监督(Unsupervised)学习:</font></b>使用无标签的数据进行训练,学习的过程叫无监督学习<br><b><font color="#e0c431">自监督(Self-Supervised)学习:</font></b>Pretrain阶段的处理方式,叫自监督学习<br><b><font color="#e0c431">半监督(Semi-Supervised)学习:</font></b>Pretrain+SFT 叫半监督学习(不缺数据,但缺标签)
核心问题:会做任务,但离能优秀的做任务,<b>还是有很大差距</b><br>
3、Reward Model(奖励模型)<br>
按业务自定义的规则做的偏好打分
<b>ORM(Outcome Reward Model): </b>在生成模型中,通常是<b><font color="#e0c431">对生成的结果整体</font></b>做一个打分<br>
<b>PRM (Process Reward Model):</b>生成的过程分步骤,每一步打分,更细粒度的奖励<font color="#e0c431"><b>-->新宠</b></font><br>
a、准备一系列Prompt,让模型给每个Prompt 生成多个Response(几万到几十万条Prompt )<br>b、设计一下<font color="#e0c431"><b>如何标注?打分?评级?排序?</b></font><br>c、找一批人来做标注工作,继续训练需要每条逐一评估<br>d、拥有了标注数据之后,<font color="#e0c431">开始训练Reward Model</font><br>e、目标:大模型任<font color="#e0c431">意给一个Prompt-Response pair</font>,Reward Model 就<font color="#e0c431">可以给出一个打分<br></font>f、利用Reward Model 去完成后续步骤
<br>
4、PPO(Proximal Policy Optimization)<br>近端策略优化<br>
一种强化学习算法,由OpenAI于2017年提出,主要用于优化策略梯度方法。核心思想:通过限制策略更新的幅度,确保训练过程的稳定性,同时兼顾样本利用效率。在大模型中,<b><font color="#e0c431">PPO常与"人类反馈强化学习"(RLHF)配合使用</font></b>,就像教练+评委的组合<br>
<b>a、SFT:</b>相当于"临摹字帖":用海量文本教大模型学会基本语言规则,<b>此时PPO不参与,模型死记硬背</b><br><b>b、Reward Model:</b>相当于<b>"老师批改作文"</b>,给不同质量的回答打分,训练出一个<b>"评分AI"(奖励模型)</b>,后续代替人类打分<br><b>c、PPO优化:</b>相当于<b>"作文特训班"</b>,模型开始自己写作文,PPO负责两个关键控制<br><b> c.1、探索控制:</b>允许尝试新句式(如把"很高兴"改成"欣喜若狂")<br><b> c.2、幅度限制:</b>防止突然写起诗歌(通过概率比值裁剪)<br>
Llama
1、Pretrain(预训练)<br>
<b><font color="#e0c431">基本流程:</font></b><br>1、不停阅读大量文字资料<br>2、学习人类如何使用文字(一字一字地学习)<br>3、学习最多的人类知识;学习文字表达方式
<b>核心问题:<br></b>因只是输出了“候选字”的概率清单<br>预训练模型(Pretrain)输出<b>非常像“接话茬”,<br>并不是在“做任务”</b><br>
2、Reward Model(奖励模型)<br>----强化学习
按业务自定义的规则做的偏好打分
<b>ORM(Outcome Reward Model): </b>在生成模型中,通常是<b><font color="#e0c431">对生成的结果整体</font></b>做一个打分<br>
<b>PRM (Process Reward Model):</b>生成的过程分步骤,每一步打分,更细粒度的奖励<font color="#e0c431"><b>-->新宠</b></font><br>
a、准备一系列Prompt,让模型给每个Prompt 生成多个Response(几万到几十万条Prompt )<br>b、设计一下<font color="#e0c431"><b>如何标注?打分?评级?排序?</b></font><br>c、找一批人来做标注工作,继续训练需要每条逐一评估<br>d、拥有了标注数据之后,<font color="#e0c431">开始训练Reward Model</font><br>e、目标:大模型任<font color="#e0c431">意给一个Prompt-Response pair</font>,Reward Model 就<font color="#e0c431">可以给出一个打分<br></font>f、利用Reward Model 去完成后续步骤
<br>
3、Rejection Sampling(拒绝采样)<br>
<b><font color="#e0c431">通俗来讲:</font></b>相当于让AI像阅卷老师一样筛选优质答案,从海量草稿中只保留满分作文,丢弃不及格答案<br>
<b><font color="#e0c431">基本流程:</font></b><br>1、生成多个答案<br>2、用预设标准打分(如逻辑正确性、步骤完整性)做质量评估,类似老师用红笔批改作文<br>3、采样决策:只保留最高分答案用于训练,其他答案被"拒绝"<br>
<b><font color="#e0c431">vs传统采样:</font></b><br><b>1、样本质量:</b>拒绝采样只保留最优解,普通采样优劣混杂<br><b>2、训练效率:</b>拒绝采样需多次生成,普通采样一次生成<br><b>3、资源消耗:</b>拒绝采样计算量高,普通采样计算量低<br>
4、SFT(Supervised Fine-Tuning)<br>有监督的微调
<b style=""><font color="#e0c431">有监督(Supervised)学习:</font></b>使用有标签的数据进行训练,学习的过程叫有监督学习<br><b style=""><font color="#e0c431">无监督(Unsupervised)学习:</font></b>使用无标签的数据进行训练,学习的过程叫无监督学习<br><b><font color="#e0c431">自监督(Self-Supervised)学习:</font></b>Pretrain阶段的处理方式,叫自监督学习<br><b><font color="#e0c431">半监督(Semi-Supervised)学习:</font></b>Pretrain+SFT 叫半监督学习(不缺数据,但缺标签)
核心问题:会做任务,但离能优秀的做任务,<b>还是有很大差距</b><br>
5、DPO(Direct Preference Optimization)<br>直接偏好优化
一种无需显式奖励模型的对齐方法,通过直接优化策略模型与人类偏好数据的一致性,实现大模型的高效对齐
用"选秀评委"的比喻来解释DPO(直接偏好优化):<br><b><font color="#e0c431">a、传统RLHF(像层层筛选的偶像选拔):</font></b>1)海选阶段(SFT);2)评委培训(RM);3)晋级赛(PPO反复调整)<br><b><font color="#e0c431">b、DPO的革新(像直通决赛的达人秀):</font></b>直接把人类偏好变成训练信号,省去"训练评委"环节,核心原理是:<br>1)将偏好数据转化为概率差(好比直接记录观众投票数)<br>2)用数学方法保证:好回答的概率 > 差回答的概率<br>3)通过损失函数直接优化策略(评委意见直接变成训练指令)<br>
优势对比