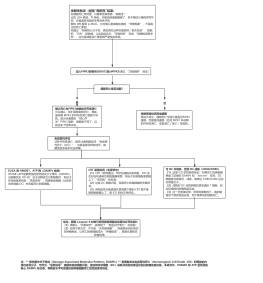
总体流程
客户端 -> 连接器 -> 分析器 -> 优化器 -> 执行器 -> 存储引擎<br>
Update流程
1、执行器请求存储引擎读旧数据
2、存储引擎从 BufferPool 读取数据<br>
3、若 BufferPool 不存在,则从数据库文件加载所在的页到缓存<br>
4、存储引擎将数据存入 undo log 的版本链中,然后返回给执行器<br>
4、执行器修改数据后提交给存储引擎,存储引擎存入 BufferPool<br>
5、存储引擎向 redo log buffer 中写入数据,标记状态为 prepare<br>
6、根据持久化策略,redo log buffer 将数据写入 redo log 文件<br>
7、执行器将 Update操作 写入 binlog<br>
8、事务提交且写入binlog成功后,将 redo log 中的 prepare 状态变更为 commit<br>
9、Buffer Pool 中的新数据所在的页写入 Double Write Buffer 文件<br>
10、Buffer Pool 中的新数据所在的页写入 idb 数据库磁盘文件<br>
内部二阶段提交
过程:先写redo log,状态为prepare -> 再写 binlog -> redolog 状态变更为 commit<br>
意义:保证 redo log 和 binlog 的一致性<br>