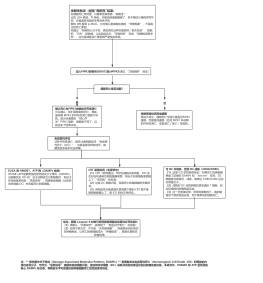
2.数据预处理
异常值处理
把异常值视为缺失值处理,但其实除了对数据非常熟悉,不建议删除异常值,它可以让我们的结果更泛化,面对新数据的时候性能能比较好
缺失值处理
利用随机森林插值法补齐
为什么用随机森林?因为可以用结果推断原因
统一量纲处理
归一化
是什么?我想要的数据在1-10000,我们把他缩到一个里面
只需要输入一个模型就行,你的模糊集里面也学过
标准化
就是正态分布的标准化
适用于假设服从于正态分布的数据、线性回归、SVM
正态变换
一些比较偏的分布(比如房价、人均收入等),改变分布类型。(上面两个改变不了分布)
对于一些不符合正态分布的可以通过偏态分布、对数变换、box-cox方法把他变成类似于正态分布的东西
数据编码
名义变量,进行独热编码
如颜色、性别、城市、类别
独热编码:本体之间不存在顺序特征,又K个变量只需要K-1个就可以设置变量,因为这可以互相推出来
连续特征处理
我把数据分成几个箱子,进行封箱
好处
1.降低噪声:有的模型对噪声很敏感,这样会降低模型预测的准确性
2.提升数据的鲁棒性:对异常值不敏感
3.有利于补充数据之间的反比例关系:某些模型更适合拟合
坏处
解决数据不平衡问日
过采样、欠采样
练习题里面又900个有问题,100个没问题,这算是没学习好
1.随机过采样radom over samping
我们把那100个题随机复制一下,复制成900个,这样就好。解决了解决数据不均衡的问题。
<b>注意:不能给考试的东西做过采样,之恶能给训练集做采样</b>
优点:容易实现
缺点:可能导致过拟合,因为模型并没有引入新信息
写代码实现,借助大模型。最后一行:把X和Y带入到变量中进行实例化,这里就成功把数据变成900 900了
2.SMOTE过采样(synthetic minitory over samping thchnique)
对这些关系进行插值,可能会生成噪声样本,但是这是新数据
3.欠采样
不会太用,其意义是把900个数据删除到100个
特征工程
特征筛选
1.特征筛选我们现在要专注的方向:少做题,结果不变,对于那些会影响我们判断的变量我们直接删去不做,只找到特征
2.题目加工:多个题和合成一道题,学名叫做低维映射,这些必定会丢失信息,因为这里面包含了噪声信息
常见:lasso筛选和shap筛选,导师不懂可以吹一嘴
特征加工(特征工程)
引入
1.数据整理:把知识进行分类,循序渐进学习
2.数据延申:
特征工程的常见措施
1.借助热力图判断,把最重要的特征构造交互,交互项a*b(当某几个特征同时出现的时候,y的值会进行突变)
2.数据有周期
3.尝试a+b,不具有解释性,单纯为准确率服务
4.模型训练
调参思想
训练集、测试集、验证集
它的作用:防止考核的时候考得很好是恰好捧出来的,降低偶然概率,于是我们就再考一边
训练集:做训练,需要进行过采样和欠采样的结合
验证集:用于模型和超参数的选拔,同时可以提前监控过拟合的可能性
测试机:用来评估性能的测试
过拟合和欠拟合
过拟合:我学的东西太死板了,以至于我不能对同种物品进行延伸
欠拟合:我的验证集和测试集都很差,没有学好规律
具体怎么调参
代码
调参方法1:网格搜索:暴力方法,检索每一组数据
子主题
这里也可以固定1个,去变4个,减少工作量(局部网格搜索)
做法:<br>1.定义随机森林模型<br>2。定义参数网格<br>3。初始网格搜索,是否可以做交叉验证,<br>4。输出最佳参数
调参方法2:贝叶斯优化:搜索的更快
我先做一座,结果发现有几个标签没啥大影响,我就给每个参数进行甲醛,权重小的参数就比较
调参方法3:optuna调参框架
<b>水论文用,写个复杂公式再加个图表</b>
遗传算法、粒子群算法:启发式算法,均为动物园算法
n折交叉验证:对同一组目标训练n组以上让他们更可信
子主题
5.模型评估
回归指标
r方,越接近1越好
调整后的R方,引入了对模型复杂度的惩罚,考虑了模型中的自变量,更常用
rmse均方根误差,E(Δx平凡)越小越好,预测误差
mse均方误差,越小越高
平均绝对误差MAE
MAPE:人通常对较大的绝对数值不敏感,而对比例比较敏感
分类指标
二分类指标(根据混淆矩阵计算得出)
什么是混淆矩阵?其实很简单,就是给我们提供四种可能性(针对分类问题)
auc值:根据ROC曲线得出,原理比较复杂
子主题
准确率,召回率,精确率
这些分数有这么多,是因为关注的指标不同,如更管制是不是被忽略了?更关注shi'bu'shi
多分类指标
每一个指标都有二分类
平均指标,如微平均和宏平均
其他指标:时间:时间越短越厉害
6.解释性分析
shap方法分析贡献度和方向
哪个特征越重要,哪个线就越长/月上面越重要,正贡献还是负贡献<br>同时用shap库对评估指标最好的一个模型分析特征重要性、贡献方向
pdpbox分析
7.一些答疑(拓展部分是4及以后)
1.分类/回归问题的输出是什么样的?
回归问题输出的是一个连续的值,<br>分类问题输出的是一个离散的值,即使harmax,但是机器学习是软分类,softmax,输出的是一个概率。<br>所以,返回的是阈值还是最大值呢?其实是就是默认选最大<br>同时,判正的概率是被阈值控制的,<br>
(1)分类 的ROC曲线是怎么画出来的?
<font color="#e74f4c"><b>我们把所有阈值都取了个遍,输出的是概率,所以每个点就对应每个模型<br>直线和曲线的本质反应的是阈值的分布(阈值-指标的映射)</b></font><br><b>直线:</b>比如有三组结果:(0.7,0.3)(0.9,0.1)(0.8,0.2),我们前面的这个0.70.80.9都比较大,<br>所以说他这个从0取到0.7它就不会有波动,就产生了一个直线。<br>曲线:
(2)为什么不选IOC值进行调参?
IOC曲线本身是来源于ROC曲线的面积得出来的,反应的是整个模型的性能<br>但是我们这个问题不需要模型的综合性能,只需要一个精确指标。<br>比如说我判断的是电商公司A是不是又信贷风险,IOC曲线就是把这个公司包括信贷之内的所有指标都综合下来<br>这样太过宽泛的研究结果无疑是对科研的一种自杀。<br>但是这个指标也有其意义,于是我们引出创新点:
2.项目的创新点是什么?
如上面所说,判断正的概率是被阈值控制的,所以我们可以对这个阈值进行二次调参<br>第一次:用IOC曲线进行调参,评价的是模型的综合水平<b><font color="#e74f4c">(给老师的提问埋伏笔)</font></b><br>第二次:用精确率或者召回率进行调参,通过阈值来判断我们想研究的这个指标的水平
二次调参的目的是什么?<b><font color="#e74f4c">“针对阈值的调参” 核心是:分类模型输出概率后,通过调整 “判定正类 / 负类的临界值”,适配具体场景需求,让模型性能(如准确率、召回率)更优,是提升模型实用性的关键创新点。</font></b>
<b>二次调参的必要性(底层逻辑)</b>
体现自己的反思、科研、学习能力
4.精度改进思路是什么?<br>(这些可以作为次要创新点)
1.对数据进行改进
1.数据本身矛盾(特征相同但是标签不同)
比如两份 “身高、体重、年龄完全一样” 的样本,一份标签是 “患病”,一份是 “健康”—— 这种数据会让模型困惑:“同样的特征,到底该预测哪个标签?”,哪怕训练集精度也上不去,更别提泛化到测试集了。
遇到这种情况,要先排查是否有 “未知<b>特征遗漏</b>”(比如这两个样本其实有 “是否熬夜” 这个没收集的关键特征),如果是数据错误,需要<b>清洗或补充数据</b>。
2.特征不足(关键信息缺失)
比如想预测 “地域”,但只给了 “身高、体重、收入” 这些特征 —— 这些特征和 “地域” 的关联性极弱,模型根本找不到规律,结果就是 “验证集看着还行,测试集精度暴跌”(泛化性差)
而是要回头补数据 —— 比如补充 “常居城市、消费习惯” 等和 “地域” 强相关的特征,精度才可能有本质提升。
2.特征工程:放大有用的,放小没用的
机器学习:手动挖掘重要信息,这代表着你需要对这个领域非常了解,有限制性
深度学习:可以自动找到特征
图像数据用 CNN 层
文本数据用 Transformer 层
时序数据用 LSTM/GRU 层
3.对模型进行改进
1.多模型对比,前面已经讲了
2.多模型融合:取各精华
加权融合,适合模型差距不大的场景
stacking融合,适合模型结果差距大的场景,利用交叉验证对模型进行二次优化,多元函数求极值
集成学习