大模型压缩技术
2025-12-10 06:07:55 0 举报AI智能生成
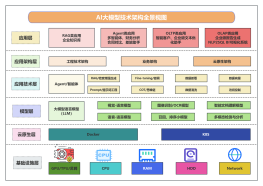
大模型压缩技术是专为优化大型神经网络模型性能的先进技术。这项技术的核心在于将大型模型变得更加精简,同时保持其原有的性能或仅略作牺牲,这对于需要较少计算资源和更快推理时间的应用非常关键。该技术可用于深度学习模型的各种文件类型,包括训练过的权重文件和模型架构定义文件。 技术的核心内容包括但不限于参数共享,量化,模型分解,以及知识蒸馏等策略。参数共享减少了冗余计算;量化将浮点数权重映射到更低精度的数据类型;模型分解技术则将大型矩阵转换为多个小矩阵乘积;知识蒸馏传递大模型的知识到一个更小但效率更高的模型。通过这些方法,我们可以实现模型压缩而不显著牺牲性能,这些修饰语如"高效"、"节能"、"轻量化"和"加速"突出了大模型压缩技术在提升效率和可行性的方面。
模板推荐
作者其他创作
大纲/内容

Collect

Collect

Collect

Collect
0 条评论
下一页

