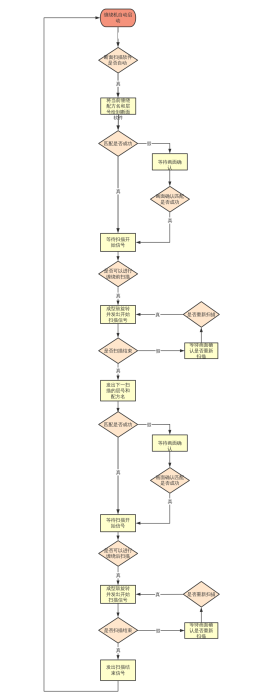
scanAll(path);监听该目录当有新文件时进行扫描
定时器每三秒扫描未处理的任务进行处理OcrTaskScheduler#processPendingTasks
结束
根据ocr回调方法Article内容接口/api/search/updateArticleByCallBack
BINARY_CONTENT其他类型
更新Article内容
判断文件格式是否可识别
数据更新至ES库if (articleList.size() == 50) {
生成缩略图
把文件放置在mineru/input目录后生成识别任务对象
成功识别后请求 callback 接口回传任务状态、识别内容等
判断文件类型为文本/ocr识别类、其他
创建监听器
file_search一搜
// 允许的文件后缀列表private static final List ALLOWED_EXTENSIONS = Arrays.asList(\"pdf\
请求ocr识别接口,不等待识别结果识别完成后ocr 请求回调接口完成内容更新
fileWalkTree处理目录中已有的文件,并计算数量
new File(mineru/input目录)调用 minerU 识别接口http://localhost:8000/file_parse
ocr-task识别引擎
保存数据至 Path 表
visitFile浏览处理每个文件getArticle
TEXT_CONTENT文本类型txt创建通用文档,提取内容其他文本类型向下走
转换为 pdf
各种判空及目录重复判断
提交识别多文件文件接口/api/v1/ocr/submitWithControl
String callbackUrl = \"http://\" + serverIp + \":\" + serverPort + \"/api/search/updateArticleByCallBack\";
增加一搜扫描识别文件目录接口/api/path/save
更新Article内容至 ES