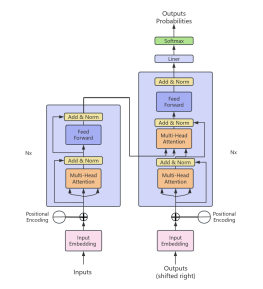
Transformer网络模型结构图
2026-03-17 14:50:38 5 举报Transformer是谷歌在2017年的论文《Attention Is All You Need》中提出的,用于NLP的各项任务,现在是谷歌云TPU推荐的参考模型。本图是Transformer内部的Encoder和Decoder完整结构。可以看到Encoder包含一个Muti-Head Attention模块,是由多个Self-Attention组成,而Decoder包含两个Muti-Head Attention. Muti-Head Attention上方还包括一个Add&Norm 层,Add表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。 Transformer中单词的输入表示由单词Embedding和位置Embedding(Positional Encoding)相加得到。