OpenAI o1 (Strawberry) 深度架构全景图
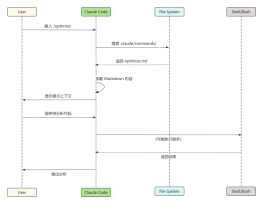
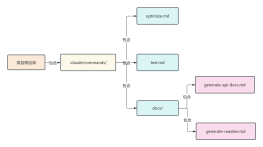
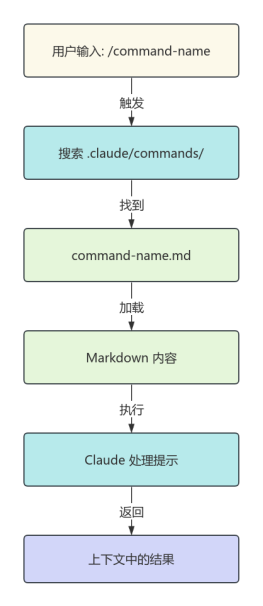
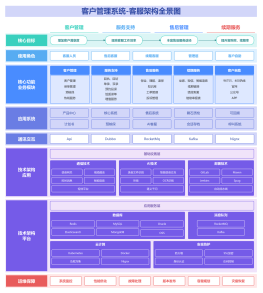
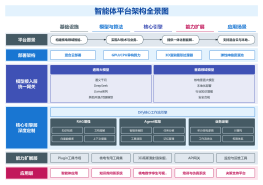
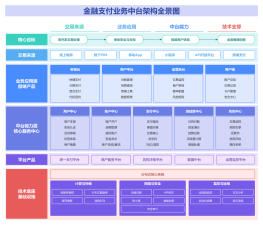
2026-02-03 07:38:20 0 举报【揭秘AI新物种】OpenAI o1 (Strawberry) 深度架构全景图:机器如何学会“慢思考”? 本图表是全网稀缺的 OpenAI o1 技术原理拆解,完美适配 ProcessOn 格式。不同于传统大模型的“直觉式回答”,本图深入剖析了 o1 独有的 “推理侧强化学习 (Inference-time Scaling)” 机制。 内容涵盖三大核心板块: 宏观范式:System 1(快思考)到 System 2(慢思考)的架构跃迁。 推理回环:可视化展示 Hidden CoT 中的拆解、回溯与自纠错路径。 训练秘辛:Process Reward Model (PRM) 如何指导模型优化思维链。 无论你是要解释 o1 为什么“慢但强”,还是研究 AGI 的下一阶段演进,这张逻辑缜密的架构图都是你的最佳素材!
模板推荐
作者其他创作
大纲/内容



0 条评论
下一页