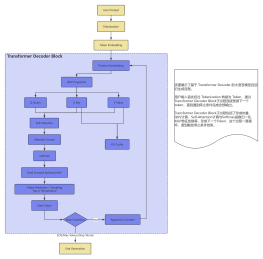
基于 Transformer 的自回归生成流程
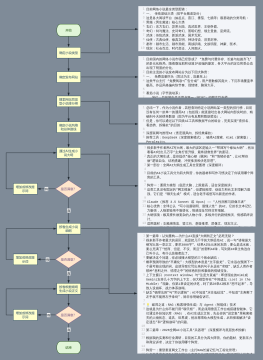
2026-03-06 22:03:28 0 举报该图展示了大语言模型(LLM)在推理阶段基于 Transformer Decoder 架构进行文本生成的整体流程。模型通过自回归(Auto-Regressive)的方式逐步生成下一个 Token,并不断将生成结果加入上下文中,直到满足停止条件为止。 整个流程可以分为 输入处理、Decoder计算、Token生成与循环控制三个阶段。 首先是 输入处理阶段。 用户输入的文本(User Prompt)首先经过 Tokenization 被切分为离散的 Token 序列,然后通过 Token Embedding 将 Token 转换为高维向量表示。为了让模型能够理解 Token 在序列中的位置,还会加入 Position Embedding(位置编码),从而形成完整的输入向量序列。 随后进入 Transformer Decoder Block。在这一阶段,输入向量会经过多个 Decoder 层(通常为数十层),每一层包含两个核心模块: 第一部分是 Self-Attention 机制。 输入向量首先通过 QKV Projection 投影为 Query、Key、Value 三个向量。模型通过计算 Query 与 Key 的相关性得到 Attention Scores,再通过 Softmax 将其归一化为注意力权重,从而对 Value 进行加权聚合。这一过程使模型能够关注输入序列中最相关的上下文信息。 为了提升推理效率,模型会将历史生成 Token 的 Key 和 Value 缓存在 KV Cache 中。在生成后续 Token 时,无需重新计算之前的 Key 和 Value,从而显著降低计算量,提高推理速度。 第二部分是 Feed Forward Network(MLP)。 在 Attention 计算之后,数据会进入前馈神经网络(MLP)进行进一步的非线性变换,从而增强模型的表达能力。 完成 Decoder 层计算后,模型会进入 Token Prediction / Sampling 阶段。 模型根据当前输出向量计算下一 Token 的概率分布,并通过 Temperature、Top-p 等采样策略选择下一个 Token。 生成的 Next Token 会进入一个判断步骤: 如果满足 停止条件(Stop Condition),例如生成了 EOS Token、达到最大 Token 数(Max Tokens)或匹配到 Stop Words,则生成过程结束。 如果未满足停止条件,则会执行 Append to Context,将新生成的 Token 加入上下文序列,并重新输入 Decoder 继续生成下一个 Token。 通过这种不断循环的方式,模型可以逐步生成完整的文本序列,这种生成机制被称为 自回归生成(Auto-Regressive Generation)。 整体而言,该流程图展示了大语言模型推理阶段的核心计算路径,以及 Attention 机制、KV Cache 加速、自回归循环与停止机制等关键组成部分。
模板推荐
作者其他创作
大纲/内容




0 条评论
下一页