
大模型中的核心概念与架构全解
2026-03-30 09:24:00 0 举报AI智能生成
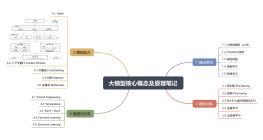
大模型从基础架构到模型训练,再到模型能力和推理与生成的应用全部核心概念和工作原理与示例笔记。 基础架构:LLM大语言模型、Transformer架构、神经网络、深度学习与机器学习 模型训练:预训练、微调、RLHF反馈强化学习、监督学习与无监督学习 模型能力:Token、Context Window、向量Embedding、机制Attention、多模态Multimodal 推理与生成应用:Prompt Engineering,Temperature、Top-P与Top-K,Few-shot与Zero-shot Learning等
一图看懂AI
LLM
tOKEN
tRANSFORMER
神经网络
AI
模板推荐
作者其他创作
大纲/内容
基础架构
大预言模型(LLM)
本质:
参数大:系统的“记忆单元”
GPT-4:万亿级参数
训练数据大
人类几乎所有公开文字知识
海量语料库
统计学的极致应用 ≠ 真正思考
工作原理
输入开头 → 预测最可能的下一个字
核心机制:统计语言,非理解语言(基于概率预测下一个词)
写诗
写代码
回答问题
文本生成
Transform架构
核心机制:自注意力(Self-Attention)
同时关注全文所有位置,理解词间关系
量大核心优势
1、并行计算快
2、长距离依赖强
处理方式对比
传统序列模型(RNN/LSTM)
今天-天气-很好-...-公园
顺序处理,读到后面容易遗忘前文
Transformer
并行处理,同时关注全文
支撑能力:超长上下文理解,连贯长对话
没有Transformer = 没有 ChatGPT
神经网络
核心结构:三层架构
输入层
接收原始数据,如图像像素值
隐藏层
计算与特征变换
输出层
输出预测结果,分类概率
工作原理:反向传播训练
1、前向传播
输入数据
逐层计算
得到预测结果(初始随机猜测)
2、计算误差
比较预测与真实值
计算损失函数
量化错误程度
Loss = 预测 - 真实
3、反向传播
误差逐层回传,计算各权重梯度,确定调整方向
4、更新:调整权重
梯度下降优化
目标:找到让误差最小的那组权重参数
min Loss(w) → 最优权重 w*
深度学习
传统神经网络
1、输入层:原始数据
2、隐藏层:1层
3、输出层:简单分类
抽象能力有限,智能学习浅层特征
深度学习网络
1、Layer1:边缘、线条
2、Layer2-5:形状、纹理
3、Layer6-15:眼睛、鼻子
4、Layer16-50+:人脸识别
输出:高级语义理解
身份识别、表情分析、场景理解
核心洞察
深度歇息不是新发明,是硬件算力追上了理论
深度学习成功三要素
1、大数据
2、大算力
3、好算法
本质:深度学习就是层次数很多的神经网络
机器学习
范式对比
传统编程
机器学习
三大学习范式
1、监督学习
有标签数据,教它什么是“对的”
2、无监督学习
无标签数据,自己发现数据结构
3、强化学习
奖惩信号、试错中成长
典型应用场景
1、推荐系统
个性化内容推送
2、风控系统
欺诈检测、信用评估
3、搜索排序
相关性排名优化
4、语音识别
语音转文字
5、图像识别
物体检测
大模型(LLM / Foundation Model)
机器学习的产物,规模与复杂度达到新高度
海量参数:百万~万亿级
海量数据:TB~PB级训练
涌现能力:通用智能表现
机器学习是AI的核心方法论,其他都是它的具体体现形式
模型训练
预训练 Pre-training
核心训练目标:预测下一个词(Next token Prediction)
1、数据输入层:海量无标注文本
网页数据 Common Crawl(数万亿词)
书籍文献 Books/Papers(高质量长文)
百科知识 Wikipedia(结构化知识)
代码仓库 GitHub Code(编程能力)
2、训练过程:大规模计算
算力投入
数万块顶级GPU
持续训练数月
成本:数千万至上亿美元
训练机制
自监督学习
无需人工标注
数据即标签
学习内容
语法结构 - 语义理解
常识推理 - 逻辑关系
跨领域知识压缩
3、训练产出:基座模型(Base Model)
形象比喻:博览群书的书呆子
基座模型 / Foundation Model
掌握语法、常识、逻辑、专业知识
不会对话、不听指令、无法使用
后续阶段:SFT - RLHF
微调 Fine-tuning
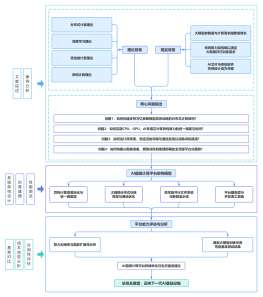
大模型微调(Fine-tuning)架构流程图
从通用机座到专业领域的精准适配
1、起点 - 预训练基座模型
比喻:大学毕业生
什么都懂一点
预训练模型(Base Model)
通识能力已具备 - 类似大学通识教育
成本对比
参数规模:千万 ~ 亿级 ~ 数十亿 ~ 数千亿 ~ 数万亿
2、微调输入 - 高质量专业数据
数据规模
几千 ~ 几万条样本,远小于预训练数据量
数据质量
高质量 - 任务相关
人工标注或筛选
数据格式
问答对 / 指令 - 回复
特定领域语料
3、微调方法 - 高效参数调整
全量微调
调整全部参数
效果好 * 成本高
LoRA 微调 ★ 主流
仅调整 0.1% ~ 1% 参数
低秩适配
其他方法
Adapter/Prefix-tuning
各有适用场景
4、应用场景 - 领域专精模型
客服场景
企业话术定制
标准化应答
智能客服系统
法律场景
法律文书撰写
案例分析
法律助手
医疗场景
医学问答
病历分析
医疗辅助诊断
更多领域
金融 * 教育
代码 * 创作
垂直领域应用
RLHF人类反馈强化学习
基座模型
预训练+微调后
1、输入问题/提示
多问答生成
回答A
回答B
回答C
回答...
2、模型生成多个候选回答
人类反馈环节(核心)
人工标注员(人类裁判)
偏好排序结果(B>A>C(质量排名))
3、人工对回答质量进行排序评判
激励模型
学习人类偏好,自动给回答打分
4、用排序数据训练奖励模型
强化学习优化(PPO)
策略模型生成回答
奖励模型打分
更新模型参数
迭代优化
RLHF = 人类偏好数据+奖励模型+强化学习 → 让模型输出符合人类价值观的高质量回答
核心流程
1、生成候选回答
2、人工排序偏好
3、训练奖励模型
4、强化学习优化
核心思想:人类示范好坏、模型学会分辨
RLHF解决问题
✖ 胡说八道
✖ 输出不安全内容
✖ 不遵循指令
✔ 有帮助
✔ 诚实可靠
监督学习
监督学习是最常用也是最直观的机器学习方式
监督学习架构流程图
Supervised Learning —— 有老师知道的学习方式,标签即老师
监督学习核心
输入X → 模型 → 输出Y (预测)
核心公式:f(x) = y
训练流程
训练数据(人工标注)
输入X(特征)
标签Y(答案)
模型学习
学习X→Y映射
调整参数权重
预测输出
预测值
损失计算
LOSS = |Y - Y|
计算预测误差
两大问题类型
分类问题(Y=离散类别)
垃圾邮件识别
医学诊断、疾病分类
回归问题(Y=连续数值)
房价预测具体金额
销量预测具体数量
主要局限
需要大量人工标注数据
标注成本高昂
标注质量影响模型效果
监督的含义
标签 = 老师 = 正确答案
告诉模型什么是对的,模型从示例中学习规律
大模型中的应用
微调阶段核心方法
学习回答格式风格
提升指令遵循能力
局限:需要大量人工标注数据,这个成本很高。标注质量也直接影响模型效果。
大模型的微调阶段大量使用监督学习,让模型学会按照人类期望的格式和风格回答问题
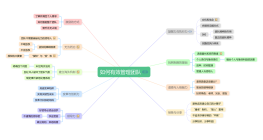
无监督学习
无监督学习是让模型自己在数据里找规律,没人告诉它什么是对的
典型任务:
聚类
把相似的东西归到一起,比如把用户分成几个群体;
降维
降维就是把高维数据压缩,便于可视化和后续处理;
大模型的预训练其实就是无监督学习。没有人标注这个词后面应该接什么,模型自己从几千亿词的语料里学习语言规律
无监督学习架构流程图
Unsupervised Learning —— 没有老师,模型自己在数据中发现规律
对比监督学习
有标签Y指导,X→Y 映射学习
无监督学习核心
只有输入X,没有标签Y,自己找规律
核心价值
标注数据类
无标签数据遍地都是
海量无标签数据(输入)
互联网文本
图片视频
用户行为
传感器数据
量大典型任务
聚类(Clustering)
把相似的东西归到一起
用户分群
高价值/普通/流失
新闻分类
自动发现主题
降维(Dimensionality Reduction)
高维数据压缩,保留关键信息
数据可视化:1000维→2维
特征压缩:去噪提效
大模型预训练 = 无监督学习(应用)
大模型预训练 = 无监督学习
没有人标注这个词后面应该接什么
模型从几千亿词的语料中自己薛西语言规律
1、海量无标签(预训练)
2、少量有标签(微调)
数据成本对比
标注数据:贵
无标签数据:几乎免费
性价最高路线:无监督预训练 → 少量监督微调
用海量无标签数据打底,再用少量指标数据调优
模型能力
Token
定义:Token 是大模型处理文本的最小单位,它是通过分词算法切出来的片段。英文里 Token 通常是一个词或者词的一部分,中文里可能是一个字,也可能是半个词。
Token分词处理架构流程
大模型处理文本的最小单位 —— 模型只认数字,不认文字
常见误解
Token = 一个字
Token = 一个词
正确理解
Token = 分词算法切出的片段
可能是词、字或词的一部分
原始文本输入(1、输入)
分词器(Tokenizer):将文本切分为Token序列
2、切分
分词示例
英文:unbelievable
un + believ + able = 3 ge Tokens
中文:清华大学
清华 + 大学 = 2~4 个Tokens(视分词器)
3、编码
Token → 数字编号映射
每个Token对应词表中的唯一ID
un → 1234
believe → 5678
able → 9012
输出序列:[1234, 5678, 9012]
4、处理
大模型处理(只处理数字序列,不处理文字)
成本计算
按Token数量收费
1000字中文 ≈ 1500~2000 Token
上下文窗口
窗口按Token计算
Prompt越长,回复空间越小
能力限制
输入+输出 ≤ 窗口上限
如 GPT-4:8K/32K/128K
其他说明
为什么要搞这么复杂?
因为模型没法直接处理文字,它只认数字。分词器的任务就是把文本切成 Token,然后每个 Token 对应一个编号,模型处理的是这些编号序列
Token数量直接决定成本
调用 GPT-4 按 Token 收费,输入输出都算。一篇1000字的中文文章大概是1500-2000个 Token
Token 限制也影响模型能力。模型的上下文窗口是按 Token 计算的,你的 Prompt 太长,留给模型回复的 Token 就少了。
估算成本和设计 Prompt 时,心里要有 Token 这根弦,这是计费的基本单位。
上下文窗口 Context Window
上下文窗口就是模型一次能看到多少内容
你和 ChatGPT 聊天,它能记住之前说过什么,靠的就是上下文窗口
窗口越大,能记住的对话越多,处理的文档越长
GPT-3.5 是4K Token,GPT-4 Turbo 到了128K,Claude 3 更是到了200K
这个窗口是怎么工作的?
模型每次推理时,会把整个对话历史加上你的新输入一起处理。窗口满了就得砍掉早期内容,所以长对话后期你会发现模型忘了开头的事。
核心定义
模型单次推理能处理的最大Token数量
窗口内容构成
对话历史:之前的所有对话记录
新输入:用户当前的问题
输出预留空间:模型生成回复的空间
主流模型窗口大小对比
GPT-3.5:4K Token
GTP-4:8K / 32K
GPT-4 Turbo:128K
Claude3:200K Token(约等于一本书)
企业应用场景
文档问答:长文本理解
代码分析:完整项目处理
报告总结:长篇内容压缩
多轮对话:保持上下文连贯
《迷失在中间》问题
注意力强度:
开头 ★★★,中间 ★,结尾★★★
关键信息应放在开头或结尾
中间位置容易被模型“忽略”
窗口溢出处理
长对话后期,模型会忘记开头内容
解决方案
摘要压缩
选择性保留
其他说明
企业应该特别关注这个参数:文档问答、代码分析、长报告总结,都需要大窗口。窗口太小,文档塞不进去;窗口够大,一次能处理一整本书。
窗口大不等于用得好,研究表明,Token 放在窗口中间的内容,模型注意力反而最弱,这叫迷失在中间问题。所以关键信息要放开头或结尾
上下文窗口是大模型能力的硬约束,选模型时这是核心参数
向量嵌入 Embedding
说明
Embedding 是把文字变成数字的魔法,也是语义搜索的底层原理。
计算机不认识文字,只认识数字。Embedding 的作用是把一段文本变成一个向量,也就是一串数字,比如768个或1536个浮点数。这串数字承载了这段文本的语义信息。
神奇的是,语义相近的文本,向量也会相近。我喜欢吃苹果和我爱吃水果这两句话,虽然文字不同,但它们的向量在高维空间里距离很近。
Embedding技术架构流程
输入层INPUT
原始文本
“我喜欢吃苹果”
文档库
数万篇文档
用户问题
Query查询
对比文本
“我爱吃水果”
核心处理层(Embedding)
Embedding模型
text-embedding-ada-002等专用模型
向量输出层 VECTORS
2、向量转换
向量A
[0.23, -0.45, 0.12, ...] 768/1536维
文档向量集
批量转换存储
查询向量
实时转换
向量B
[0.21, -0.48, 0.15, ...]
3、批量存储:向量数据库 VECTOR DB
向量索引:高维空间存储
最近邻搜索(ANN):余弦相似度 / 欧氏距离
4、查询匹配:语义相似度计算 SIMILARITY
语义相似度计算 SIMILARITY
距离计算:向量A → 向量B
相似度结果:语义相近 = 距离近
5、检索结果:应用层 APPLICATION
核心原理
文字 → 数字向量
语义近 = 距离近
高维空间表征
专用Embedding模型
ARG 检索增强生成
向量匹配 - 内容检索 - LLM回答
语义搜索引擎
超越关键词的智能搜索
关键区别
Embedding模型 - 文本转向量
LLM 大语言模型 - 对话生成
其他说明
向量数据库
你把几万篇文档都转成向量存起来,用户问问题时也转成向量,然后找最近邻的那些文档。
RAG 技术的核心
用向量匹配找到相关内容,再让大模型基于这些内容回答
Embedding 模型和大语言模型是两回事
OpenAI 有专门的 text-embedding-ada-002 模型,只负责把文本变向量,不能聊天
做企业知识库、智能搜索、推荐系统,Embedding 是必修课
机制 Attention
Attention 是 Transformer 的灵魂,没有它就没有今天的大模型
传统处理文本的方式是顺序读取,读到后面就容易忘前面。Attention 机制让模型在处理每个词时,都能回头看全文,决定该重点关注哪些词。
核心公式就三个矩阵(简称:QKV)
Query
Key
Value
每个词都会生成这三个向量,Query 和 Key 做点积算出注意力权重,权重决定这个词该把多少注意力分配给其他词,然后用权重加权 Value 得到输出
举个例子,这只猫很可爱,因为它毛茸茸的这句话,当模型处理它这个词时,Attention 会让它特别关注猫这个词,因为它指代的就是猫
Attention 注意力机制:Transform的灵魂
核心问题与解决思路
传统方式:顺序读取,读到后面容易忘前面
【改进】Attention:全局关注,处理每个词时回看全文
决定重点关注哪些词,动态分配注意力权重
QKV核心计算机制
Query(Q):查询向量 - 我要找什么
Key(K):键向量 - 我是什么
Value(V):值向量 - 我的内容
Q:K → 注意力权重
权重* V → 输出
每个词生成Q/K/V
Attention类型
Self-Attention
每个词关注全文所有词
Transformer核心
Cross-Attention
一个序列关注另一个序列
如:翻译时目标语言 → 源语言
Multi-Head Attention
并行多组Attention
GPT-4:100+注意头
Self-Attention实例
这只猫很可爱,因为它毛茸茸的
它 → 猫,高注意力权重,指代关系识别
Multi-Head并行机制:拼接Concat
Head1:语法关系
Head2:语义关系
Head3:位置关系
...
Head N:其他模式
输出:融合多维度注意力的向量表示
其他说明
Self-Attention 是每个词关注全文所有词,这是 Transformer 的核心
Cross-Attention:用于让一个序列关注另一个序列,比如翻译任务里目标语言关注源语言。
Multi-Head Attention 是并行跑多组 Attention,每组学习不同的关注模式,最后拼起来
Attention 赋予了模型处理长距离依赖的能力,这是语言理解的关键
多模态 Multimodal
概念说明
多模态是大模型竞争的新战场,纯文本模型已经是上一代产品了
多模态的意思是模型能处理多种类型的信息:文本、图像、音频、视频。GPT-4V 能看图说话,Gemini 能理解视频,这就是多模态能力。
多模态大模型架构流程
输入层:Input Modalities
文本 Text:自然语言输入
图像 Image:图片/截图/照片
音频 Audio:语音/声音
视频 Video:连续帧序列
其他:表格/代码/3D
编码层:Encoders
Tokenizer:词元化处理
Vision Transformer:图块切分编码
Audio Encoder:频谱特征提取
Video Encoder:时序帧编码
专用 Encoder:领域编码
核心处理层:Core Processing
典型应用场景
图片问答分析
表格数据理解
草图生成代码
会议语音总结
视频内容理解
模态对齐<br>Cross-Modal<br>Alignment
Transformer<br>统一架构处理<br>多头注意力机制
输出投影<br>OutPut Projection
核心技术挑战
1、模态对齐
2、统一表征
3、海量配对数据
4、跨模态理解
5、高训练成本
输出层:Output Generation
文本回复
图像生成
语音合成
视频理解
多模态融合
其他说明
实现思路:把不同模态都转成向量,送进同一个 Transformer 架构
图像用 Vision Transformer 切成小块编码,音频用专门的编码器处理,最后和文本的 Embedding 一起进入模型。
应用场景
拍张照片问这是什么植物
上传一张表格让模型分析
画个草图让模型生成 UI 代码
发段语音让模型总结会议纪要
推理与生成
Prompt Engineering
概念说明
Prompt Engineering 就是和大模型说话的艺术,同一个需求,写法不同,效果天差地别
本质:大模型是根据你的输入预测输出,你给的上下文越清晰、越有结构,模型的输出就越符合预期
Prompt Engineering<br>上下文清晰 → 输出精准
1、角色设定(Role Setting)<br>激活专业知识分布
具体做法:
“你是资深产品经理”<br>“你是10年经验架构师”<br>“你是专业数据分析师”
原理:匹配训练语料
2、任务分解(Task Decomposition)<br>分步骤引导输出
执行步骤:
1)先分析需求背景<br>2)再列出可选方案<br>3)最后给出结论
原理:降低推理复杂度
3、示例引导(Few-shot Learning)<br>直观展示期望格式
示例模式:
<ul><li>Zero-shot:无示例</li><li>one-shot:单个示例</li><li>Few-shot:多个示例</li></ul>
原理:上下文学习
4、格式约束(Format Control)<br>JSON/表格/列表
输出格式:
<ul><li>JSON结构化数据</li><li>Markdown表格</li><li>编号列表/要点</li></ul>
原理:便于程序理解
5、位置原则(Position Matters)<br>首尾优先中间弱化
位置策略:
重要指令放开头<br>关键约束放结尾<br>背景信息放中间
原理:注意力分配
底层原理:概率分布预测
上下文越清晰、越有结构 → 模型输出越符合预期(非玄学,是数学)
完整工作流程
用户需求(User Request) → Prompt构建(Apply Techniques) → 模型推理(LLM Processing) → 输出结果(Quality Output) → 迭代优化(Refine)
反馈循环:根据输出质量调整Prompt
核心结论:Prompt Engineering 是使用大模型的必备技能,投入时间研究绝对值得
几个核心技巧
1)角色设定:告诉模型你是一个资深产品经理,它输出的内容就会更专业。模型在训练时见过大量专业角色的写作,设定角色等于激活这部分知识。
2)任务分解:复杂任务别一句话扔过去,要分步骤引导。先分析需求,再列出方案,最后给出结论,一步一步来效果更好。
3)示例引导:给模型看几个例子,告诉它输出应该长什么样,这叫 Few-shot。比起抽象描述,例子更直观有效。
4)格式约束:明确要求输出 JSON、表格、列表,模型会严格遵守,便于后续处理。
Temperature
Temperature 控制的是模型回答的随机性,数值越高越天马行空,越低越保守
技术原理:模型输出其实是一个概率分布,每个可能的下一个词都有一个概率,Temperature 调整的是这个分布的陡峭程度
<b>Temperature参数</b><br>控制输出概率分布的陡峭程度
低 Temperature<br>T=0~0.3<br>选择概率最高的此,输出确定稳定
输出特性:准确、稳定、可重复、保守
适用场景
代码编写与调试
数学计算与推理
事实性问答
格式化数据处理
中 Temperature<br>T=0.7<br>平衡准确性与多样性
输出特性:适度变化、质量可控
适用场景
通用对话交互
内容总结归纳
翻译润色
常规文档写作
高 Temperature<br>T=0.7 ~ 1.0+<br>概率分布拉平,输出更随机<br>根据效果调整
输出特性:创意丰富、多样性高、可能发散
适用场景
创意写作与故事
头脑风暴
广告文案创作
艺术风格探索
注意事项
T过低:输出重复啰嗦,缺乏变化
建议:从0.7开始调整
T过高:容易胡说八道,事实错误、逻辑混乱
技术原理:
模型输出为概率分布 → Temperature 调整分布陡峭程度 → 影响词语选择的随机性
核心结论:
Temperature是需要实验调整的参数,根据具体任务选择合适数值
什么场景用什么值?
写代码、做数学题、事实问答用低 Temperature,比如0.1到0.3,需要准确稳定。
写故事、做头脑风暴、生成创意文案用高 Temperature,比如0.7到1.0,需要多样性。
重点说一下,Temperature 设太高容易胡说八道,产生事实错误或逻辑混乱。设太低又会重复啰嗦,缺乏变化。
建议:默认从0.7开始调,根据具体任务再微调,这是个需要实验的参数。
其他说明
Temperature 等于0时,模型每次都选概率最高的那个词,输出完全确定,每次问同一个问题答案一样。
Temperature 等于1时,按原始概率随机采样,输出有变化
Temperature 大于1时,概率分布被拉平,小概率词也有更大机会被选中,输出更随机、更有创意
Top-P / Top-K
概念说明
这两个参数和 Temperature 一样,都是控制输出随机性的,但方式不一样。
Top-K 的逻辑:
只考虑概率最高的 K 个词,其他词直接排除。
设 K 等于50,模型每一步只在最可能的50个词里选。
好处是避免选到特别离谱的词,坏处是有时候正确答案刚好在第51位就被错过了。
Top-P / Top-K 采样参数架构<br>大语言模型输出随机性控制机制对比
采样策略控制层<br>控制候选词范围,影响输出随机性
Top-K采样<br>推荐值:K=40 ~ 100
固定数量筛选
只考虑概率最高的K个词,其余排除
工作原理
1、模型输出所有词的概率分布
2、按概率排序,取前K个词
3、在这K个词中随机采样
示例:
K=50,每步固定在前50个候选词中选择
特点:
✔ 避免离谱选词
✖ 可能错过正确答案(若在K+1位)
Top-P采样<br>(推荐值:P=0.9 ~ 0.95)
累计概率筛选
选词直到累积概率达到P值
工作原理
1、模型输出所有词的概率分布
2、按概率排序,累加直到 ≥P
3、在选中的词集合中随机采样
示例
P=0.9,可能选5个词或100个词,取决于概率分布形态
特点
✔ 自适应候选数量
✔ 更智能的筛选(动态核采样)
实践建议
不建议同时调整多个参数
常见做法:Temperature = 1<br>用 Top-P控制采样范围
OpenAI默认Top-P = 1<br>(等于不限制)
核心结论
参数无万能值,需根据具体任务实验调优
补充说明
Top-P 更智能一点,也叫核采样。它不看数量看累积概率:把词按概率从高到低排,选到累积概率达到 P 为止。设 P 等于0.9,可能只选了5个词,如果前5个概率加起来够0.,也可能选了100个词,如果概率分布很平。
实际使用时,一般不和 Temperature 同时调。常见做法是固定 Temperature 等于1,用 Top-P 控制采样范围。OpenAI 默认 Top-P 等于1,等于没限制。
Top-P 等于0.9 到0.95是比较常用的范围,既保证一定随机性,又不会选到太离谱的词。
Few-shot Learning
Few-shot Learning 是让大模型瞬间学会新任务的秘诀,而且不用重新训练
Few-shot Learning在Prompt中提供示例,模型举一反三
工作机制<br>(预训练模型已学会从上下文推断任务模式,示例激活此能力)
Prompt构成
1、示例输入 → 示例输出
2、示例输入 → 示例输出
3、示例输入 → 示例输出
?、示例输入 → (待生成)
情感分析示例
这个电影太无聊了 → 负面
今天心情超好 → 正面
这家餐厅服务态度真差 → ?
模型输出:负面
为何有效
预训练阶段见过海量问答对和任务示例
学会从上下文推断,任务模式和预期输出
实用技巧(最佳实践)
示例要典型
覆盖主要情况:正面、负面至少各一个
格式要一致
分隔符、结构统一,便于模型识别模式
数量要适度
3-5个示例通常足够,太多则边际收益递减
核心优势
成本低、见效快、无需重新训练 —— 最实用的Prompt技巧
传统方式:需准备数据集,需重新训练模型
补充说明
核心思想很简单:在 Prompt 里给几个示例,模型就能举一反三。你想让模型做情感分析,不用写代码、不用准备数据集,直接在 Prompt 里写:
这个电影太无聊了 负面 今天心情超好 正面 这家餐厅服务态度真差
模型看了前两个例子,就知道第三句该输出负面。
为什么能行?大模型在预训练时见过海量的问答对和任务示例,它学会了从上下文里推断任务模式。你给的例子激活了它的这部分能力。
几个实用技巧
示例要典型,覆盖主要情况。情感分析至少给正面和负面各一个
示例要一致,格式统一。如果第一个例子用冒号分隔,后面都要用冒号
示例不用太多,3到5个通常足够。太多了占用上下文窗口,边际收益递减
Few-shot 是最实用的 Prompt 技巧,成本低、见效快,优先掌握
Zero-shot Learning
说明
Zero-shot 比 Few-shot 更厉害,一个例子都不给,模型照样能做任务
怎么做到的?直接用自然语言描述任务就行
请把下面这段话翻译成英文,请判断这条评论是正面还是负面,请从这篇文章中提取关键信息
模型能理解你的指令,直接执行。
Zero-shot Learning工作原理架构<br>(无需示例,直接用自然语言指令驱动模型执行任务)
Zero-shot Learning<br>不提供任何示例,模型直接理解并执行任务
神奇之处:只要会说话就能指挥模型干活,无需任何编程
传统AI方式:每个任务需准备训练数据,需专门训练模型
核心原理
翻译任务
指令:请把下面这段话翻译成英文<br>模型直接输出英文翻译
情感分析
指令:请判断这条评论是正面还是负面<br>模型直接输出判断结果
信息提取
指令:请从这篇文章中提取关键信息<br>模型直接输出关键信息
适用场景对比
Zero-shot 适用场景
任务简单直接
输出格式无严格要求
快速测试原型验证
Few-shot 适用场景
任务有特定模式
希望输出格式一致
Zero-shot 效果不佳时
核心结论
Zero-shot 是大模型的通用能力体现,Few-shot是精准调教手段,两者结合效果最佳
补充说明
这才是大模型真正神奇的地方。以前的 AI 系统,你想让它做什么任务,就得准备对应的训练数据。大模型的 Zero-shot 能力意味着,你只要会说话,就能指挥它干活。
但 Zero-shot 不是万能的。复杂任务、需要特定格式输出的任务,Zero-shot 效果往往不如 Few-shot。因为纯靠描述容易产生歧义,模型理解和你的预期可能有偏差。
什么时候用 Zero-shot?任务简单直接、输出格式没有严格要求、或者想快速测试时。什么时候用 Few-shot?任务有特定模式、希望输出格式一致、或者 Zero-shot 效果不好时。
记住一点,Zero-shot 是大模型的通用能力体现,Few-shot 是精准调教的手段,两者结合效果最好。

Collect
Get Started

Collect
Get Started
Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

