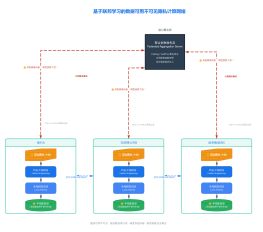
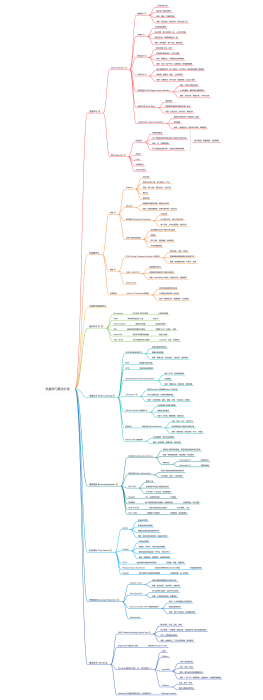
RLHF人类反馈强化学习架构图
2026-03-15 10:59:19 0 举报该图表详细展示了RLHF(人类反馈强化学习)的完整技术架构,流程分为三个核心阶段。阶段一为SFT监督微调,利用指令数据集训练模型遵循能力;阶段二为奖励模型训练,基于人类偏好数据构建奖励模型以学习打分;阶段三为PPO强化学习,引入KL散度约束优化策略模型。最终通过有用性与安全对齐维度,输出最终对齐模型。
模板推荐
作者其他创作
大纲/内容



0 条评论
下一页