
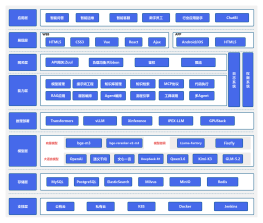
大模型训练与推理全栈知识体系-持续更新
2026-04-26 10:34:01 0 举报大模型训练与推理全栈知识体系是一个动态进化的文档集合,旨在全面覆盖构建和维护尖端机器学习系统所需的所有知识。本体系精确地整合了从基础算法学习、模型设计、优化策略、硬件选型、软件配置,到大规模数据处理与分析的各个层面。它还包括了关于部署模型、监控性能、实时推理以及反馈循环的详细信息,确保用户能够高效地将大模型融入实际应用场景。其中的每个内容条目都被精心修饰,标注了实用性和相关性,方便用户根据最新的技术发展和行业标准进行选择和学习。无论您是初学者、研究人员还是实践经验丰富的工程师,本全栈知识体系都将为您提供持续学习和发展的宝贵资源。
训练
推理
AIBrix
架构
微调
模板推荐
作者其他创作
大纲/内容
1. 数据层核心概念(决定微调的上限)
核心原则:垃圾数据进,垃圾模型出,数据质量 >> 数据数量 >> 模型大小 >> 调参技巧。核心概念与要点:数据核心要求:领域分布对齐、指令格式标准化、标注高质量、多样性充足、无脏数据、无信息泄露。核心流程:数据采集→数据清洗(去重、去噪、过滤低质内容)→隐私脱敏→标注与质检→样本构建→数据集拆分(训练集 / 验证集 / 测试集)→数据版本管理。关键风险概念:灾难性遗忘(微调后模型丢失通用能力)、过拟合(训练集效果好,线上泛化能力差)、数据泄露(测试集数据混入训练集,导致评估失真)。样本设计核心:指令模板设计、多轮对话样本构建、正负样本配比、领域知识与通用能力样本的平衡。
核心概念:更新预训练模型的全部参数,完整适配目标场景。
模型管理:checkpoint 保存、断点续训、版本管理
三、准确率(Accuracy)
核心定义:准确率是模型预测正确的样本占总样本的比例,是分类 / 判别类任务的经典指标。在大模型的不同阶段,准确率的定义和权重差异极大,不能一概而论。分场景定义:预训练阶段:Token 级准确率定义:模型预测的下一个 token,与真实 ground truth token 完全匹配的比例。特点:与 Loss/PPL 负相关,但因大模型词表规模通常达数万级别,预训练中 token 准确率普遍不高,仅作辅助参考,不是核心优化目标。微调阶段:样本级准确率定义:和传统机器学习一致,即模型预测的标签与真实样本标签完全一致的样本占比。特点:是文本分类、情感分析、意图识别等判别类微调任务的核心业务指标,优先级远高于 Loss。模型能力评估:任务级准确率定义:大模型在下游基准任务上的正确率,比如 MMLU(知识问答)的 5 选 1 准确率、GSM8K(数学推理)的解题正确率、HumanEval 的代码生成通过率等。span style=\"font-size:inherit;\
7.断点续训、容错与扩缩容异常断训后从最新 checkpoint 恢复多机故障自动替换节点弹性增减卡、重排分布式组
模型注册到 MLflow
AIBrix Engine Runtime AIBrix引擎运行时AI引擎运行时是AIBrix控制平面与推理引擎Pod之间的重要桥梁,可实现模型管理、引擎配置、可观测性以及对厂商无关引擎的支持
Heterogeneous GPU Inference (Experimental)异构GPU推理(实验性)
4、模型注册:将打包好的模型注册到 MLFlow Model Registry,标记为 Staging,触发审批流程;
将退役的模型版本标记为 Archived,永久保留完整的元数据档案(训练、评估、部署全记录),满足合规审计要求;归档对应的模型权重、实验数据,实现全程可追溯、可审计。
二、教师模型蒸馏:工业界的主流数据来源1. 2026 年蒸馏技术的最新进展• 对比蒸馏:不仅蒸馏教师模型的输出概率,还蒸馏不同输入之间的相对关系,提升模型的泛化能力• 对齐蒸馏:同时蒸馏教师模型的回答和对齐能力,使学生模型不仅能力强,还更安全、更符合人类偏好• 拒绝采样蒸馏:让教师模型生成多个答案,只选择最好的一个用于训练,避免能力贪缩• 多模态蒸馏:用多模态大模型生成图文、音视频问答数据,训练多模态小模型2. 商业风险的最新变化• 开源教师模型崛起;• 商业模型条款收紧;• 白盒蒸馏成为趋势3. 能力贪缩的系统性解决方案• 难度感知蒸馏:根据样本的难度动态调整蒸馏权重,给高难度样本更高的权重• 负样本蒸馏:同时蒸馏教师模型的错误答案,让学生模型学会区分正确和错误• 混合难度数据:在蒸馏数据中加入一定比例的高难度人工标注数据,平衡难度分布• 迭代式蒸馏:用蒸馏得到的学生模型作为新的教师模型,生成更高难度的数据,反复迭代提升能力
3. 流量与调度负载均衡、流量控制、限流熔断多实例调度、GPU/NPU 调度多区域 / 多可用区分发
3. 提供多租户资源管控,保障生产服务的资源隔离与稳定性。
MoE 专家并行的负载不均解决办法:Top-2 路由 + 无损失动态偏置均衡 + 共享专家和稀疏专家的混合架构 + 专家容量兜底
1. 提供托管式 Jupyter Notebooks 交互式开发环境,云原生资源隔离,按需分配 GPU/CPU 资源;
2. 实验跟踪:在微调代码中嵌入 MLFlow Tracking API,记录超参、训练指标、LoRA 权重;
统一格式:标准化模型打包格式
Kubeflow 核心能力
1. 通用推理框架TorchServeTriton Inference Server(行业标准)TensorFlow ServingONNX Runtime
事件总线能力
3. Prefix Tuning 前缀微调生活案例:给学生发一张 “作文专用小纸条”,每写一句都看一眼• 学生本人不动,知识不动。• 纸条上写:“先开头→再举例→最后总结”• 每一层思考都偷偷看这张纸条,引导思路,但不改脑子。• 对应微调:给每一层注意力加可训练前缀向量,不改动模型权重,适合生成任务。
2.低时延高吞吐调度Dynamic BatchingContinuous BatchingPagedAttention迭代级调度
主节点把数据切分开来,分给不同节点。类比:老师把大试卷分割成几份,分发给小组去做。
MLflow Models:跨框架的模型标准化打包
数据加速:分布式存储(对象存储、分布式存储)DataCache、数据预加载高速读写、小文件优化
5. 生产部署与推理服务阶段
1. 参数:学习率、批次大小、模型参数量、GPU 数量、分布式策略(如 DeepSpeed ZeRO 级别);
不用单独的「价值预测模型」做基线,而是让模型自己生成多个答案「自己和自己比」,用组内相对得分做优化信号,引导模型学习更优的生成策略。
1. 事实性 FactualityFactScore、FActScore、FEVER判断内容是否真实、不编造、可验证。关键:知识问答、百科、咨询类必测。2. 有用性 / 相关性 UsefulnessBERTScore、MoverScore语义相似度,比 BLEU 更贴近人类。3. 安全性 Safety有害性、偏见、歧视、违法风险常用:RealToxicityPrompts、BOLD、HateCheck4. 推理能力 ReasoningGSM8K(数学)、MMLU(学科)、BBH、COT 评测看逻辑、多步推理、数学计算。5. 指令遵循 Instruction FollowingIFEval、MT-Bench、AlpacaEval看是否按格式、按要求、按步骤回答。6. 长文本能力长文理解、长上下文一致性、信息检索常用:LongBench、ScrollBench
2. LLM 专属自动扩缩容 (APA)
1. 模型管理模型上传、版本管理模型格式转换、打包模型生命周期管理
GPU Optimizer:GPU优化器:一种基于分析器的优化器,可优化异构服务,动态调整分配,在保持服务保障的同时最大限度地提高成本效益
3. 模型打包:用 MLFlow Models 将最优 LoRA 模型打包成统一格式;
6. 并行策略
中小模型(7B-13B):优先用FSDP,显存效率高,代码侵入性低;大模型(70B+):采用3D 并行(DP+TP+PP),最大化利用集群资源;MoE 模型:专家并行+FSDP/TP,将专家模块拆分到多卡,非专家层用数据 / 张量并行。
3. 模型评估与验证阶段
每个节点都收集到所有节点的数据。可以看作 “Gather+ Broadcast”。类比:每个学生都拿到全班同学的作业副本。
7.可观测体系指标监控调用日志 & 链路追踪自动告警、异常检测
场景 1:通用基座从零预训练(最严谨,有理论支撑)设定步骤:1、定总有效训练 Token 数:理论最优值:Chinchilla 定律给出的最优配比是「总 Token 数 = 20× 模型参数量」,比如 7B 模型最优 Token 数约 140B;2、定全局有效 Batch Size:预训练行业标准全局 Batch Size 为1M~4M Token,最常用 2M Token,平衡收敛稳定性、训练效率和通信开销。
LoRA(Low-Rank Adaptation):核心概念:在 Transformer 的注意力层(Q/K/V 等)旁新增低秩矩阵支路,训练时只更新低秩矩阵,推理时可合并到原权重,无额外推理延迟。QLoRA(Quantized LoRA):核心概念:在 LoRA 基础上,对基座模型做 4bit/8bit 量化冻结,进一步大幅降低显存需求,让消费级显卡也能微调大模型。衍生方案:AdaLoRA(自适应秩分配)、DoRA(权重分解低秩适配)、LoHa/LoKr(更高阶的低秩适配),核心掌握其相比基础 LoRA 的优化点与适用场景,无需深入算法细节。
RLHF(基于人类反馈的强化学习):
全局有效 Batch Size:和单卡显存几乎无关真正决定模型训练效果、收敛速度的,是全局有效 Batch Size,而不是单卡 Batch Size。全局有效Batch Size = 单卡Batch Size × 显卡数量 × 梯度累积步数全局 Batch Size 的最优值,和显卡显存大小没有任何关系,完全由训练场景的行业共识、模型收敛目标决定示例:7B 模型预训练,目标全局 Batch Size=2M Token8 卡 A100:单卡 Batch Size 拉到 131072 Token,梯度累积 2 步即可达标;
2. 偏好对齐微调(模型行为与价值观对齐)
优势:拟合效果最好,领域适配最充分,能最大程度保留通用能力与新增能力的平衡。劣势:算力 / 显存要求极高、训练成本高、有严重的灾难性遗忘风险、模型存储成本高、合规与分发限制多。适用场景:超大高质量领域数据集、基座模型较小(如 7B 及以下)、需要深度领域适配且算力预算充足、不频繁迭代的场景。红线:千亿级大模型几乎不做全参数微调,企业级场景 90% 以上不优先选择该方案。
微调技术体系的核心分类与选型要点
2. 结合 K8s RBAC 能力,管控模型从开发到生产的权限与审批流程,实现多租户隔离。
流量拆分
MLFlow核心能力
启动命令参数化运行
三、对齐模型专用评估(SFT / DPO / GRPO 之后必测)
2. KFP 实现自动化重训练流水线,当模型效果衰减时,自动触发「数据更新→重训练→评估→部署」的全流程;
场景 4:参数高效微调(LoRA/QLoRA,企业落地首选)核心原则:以任务复杂度和数据集规模为核心,优先用 Epoch 数控制,步数极少,核心防过拟合。LoRA 仅训练模型 0.1%~1% 的参数,收敛极快,不需要大量步数,过多步数只会导致过拟合。1、定训练 Epoch 数:通用对话 / 垂直客服微调:1~3 个 Epoch;领域知识问答微调:2~5 个 Epoch;风格 / 格式 / 指令适配微调:0.5~2 个 Epoch,几百条样本几百步就够;代码 / 复杂推理微调:3~5 个 Epoch,不要超过 10 个。2、算单 Epoch 步数:先统计训练集总有效 Token 数,结合全局 Batch Size,算出单 Epoch 需要的步数。3、总步数 = Epoch 数 × 单 Epoch 步数。4、早停兜底:监控验证集的任务指标(如准确率、BLEU、 Rouge)指标停止提升就立即停止,哪怕没跑完预设步数
低秩适配类(企业最常用)
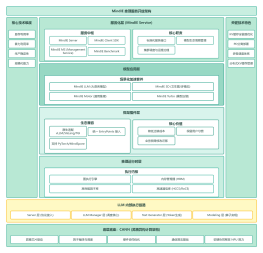
MLFlow(机器学习全生命周期管理工具集)
3. 编译优化模型编译 (AOT/JIT)硬件专属编译优化
Serving
监控运维层
事件过滤
Knative 弹性伸缩
节点先把数据切分,分发给不同节点,然后在每个节点上进行归约运算。分布式训练(尤其是 ZeRO 优化、张量并行)和 分布式推理 的刚需,核心解决显存占用高、通信的问题类比:每个小组先做一部分题,再把结果交换并整合。
多租户与运维支撑组件Multi-Tenancy in Kubeflow:Kubeflow的多租户
模型训练
L2 Distributed KVCache and Cross-Engine KV ReuseL2分布式KV缓存和跨引擎KV复用
模型设计
推理阶段总显存 ≈ 模型权重显存(30-80%) + KVCache显存(15-60%) + 中间激活值/临时现存 (5-15%)+ 预留冗余(10%-20%)
推理关键技术(框架核心)
实验管理
3. 跟踪数据集版本、特征处理指标,与后续训练任务强绑定,实现全链路溯源。
监督微调 SFT(学任务 / 指令)
KubeFlow(云原生端到端 MLOps 平台)
解决方案:借助AIBrix v0.3.0,我们推出了一个可投入生产的KVCache卸载框架,该框架支持高效的内存分层和低开销的跨引擎复用。默认情况下,该框架利用基于L1 DRAM的缓存,通过减轻GPU内存压力且不带来高延迟,已经能显著提升性能。对于需要多节点共享或更大规模复用的场景,AIBrix允许用户选择性启用L2远程缓存,从而充分发挥分布式KV缓存层的优势。
4. 3D 并行(3D Parallelism)核心原理:是数据并行 DP + 张量并行 TP + 流水线并行 PP三种基础策略的协同融合,也是千亿 / 万亿参数大模型训练的标配方案。通常用 PP 将模型按层拆分为多个阶段,解决模型深度问题;每个阶段内部用 TP 拆分张量,解决单层超大参数问题;整体再叠加 DP 做数据维度的扩展,提升全局批次规模与训练吞吐量。
2. 参数高效微调(PEFT)
4. Prompt Tuning 提示微调生活案例:只在作文开头给一句引导语• 学生完全不变,只在最开始给一句提示:“请写一篇关于春天的记叙文”• 不教新东西,不改变习惯,只靠开头一句话引导。• 对应微调:只训练输入层的软提示,参数极少、极省显存,但大模型才好用。
生产级推理部署组件 KServe:• TFServing• KFServing• Seldon
请求队列管理
场景 2:领域增量预训练(企业最常用,垂直领域适配)平衡「领域知识学习」和「灾难性遗忘」,步数宁少勿多,核心由领域有效 Token 数、通用语料混合比例决定,以「领域任务指标 + 通用能力指标」双监控做收敛判断。设定步骤1/定总训练 Token 数:核心是领域有效 Token 数,工业界常用范围:千万级~百亿级 Token,根据领域数据规模定;2/定全局有效 Batch Size:行业常用 500K~2M Token,比预训练略小,平衡收敛稳定性和过拟合风险。
Stateful vs Stateless 有状态与无状态这由StormService和RoleSet规范中的Stateful字段决定。它定义了RoleSet是使用StatefulRoleSyncer还是StatelessRoleSyncer,这会导致不同的行为。
Supported Autoscaling Mechanisms 支持的自动扩展机制
对齐技术的演进方案,ORPO 将 SFT 与偏好对齐合并为单阶段训练,进一步简化流程、降低成本;需掌握其核心优势、适用场景与落地门槛,做选型决策。
开发与交互式实验组件:Jupyter Notebooks
微调
Accelerator Diagnose Tools:加速器诊断工具:提供自动故障检测和模拟测试,以提高故障恢复能力。
把所有节点的数据集中到一个节点上。将多卡上的梯度 / 参数计算结果归集到主节点(分布式训练和推理)类比:小组作业收上来交给班长。
一、Loss(损失值)
推理服务管理(平台层能力)
2. KFP 串联「数据→训练→评估」的自动化流水线;
2. 记录重训练的全流程元数据,生成新的模型版本,实现模型迭代的全链路可追溯;
核心概念:使用高质量的「指令 - 输出」配对标注数据,训练模型遵循用户指令、掌握领域知识、输出符合格式要求的内容,是企业微调最核心的环节。架构师核心要点:SFT 的效果上限由数据质量决定,而非参数量;需掌握 SFT 的数据要求、样本设计原则、训练目标,以及领域适配 SFT、指令遵循 SFT 的差异。
5. CPO / Safety Preference Alignment专门做安全对齐、无害性偏好对:安全回答 > 不安全回答常用于风控、合规、拒绝危险请求。
AIBrix StormService AIBrix 风暴服务StormService是一个专门的组件,旨在管理和编排prefill/decoder分离架构中推理容器的生命周期。此外,它还可用于监控各种部署模式,例如张量并行(TP)、管道并行(PP),甚至单GPU模型部署。
Reduce Scatter(归约分发)
Knative框架(Serverless)
原生支撑事件驱动的 Serverless 开发模式
3.模型编译与加速图编译、算子融合量化引擎(INT8/FP8)硬件专属优化(CUDA/CANN)
训练模型:Jupyter
每个节点把数据切分后,分别发给其他所有节点。解决多设备间的不规则数据置换问题,再MoE 混合专家模型的专家并行,大模型张量并行 / 序列并行的维度转换。类比:每个学生把自己笔记分章节抄一份,发给全班同学。
1. LLM 网关与智能路由(流量大脑)
预训练和微调阶段总显存 ≈ 模型参数显存 + 梯度显存 + 优化器状态显存 + 激活值显存 + 预留冗余(10%-20%)
技术挑战:许多推理引擎,例如vLLM,会使用内置的KV缓存来缓解这一问题,充分利用闲置的HBM和DRAM。然而,单节点KV缓存存在一些关键限制:内存容量受限、引擎专用存储导致无法在实例间共享,以及难以支持KV迁移和预填充-解码分离等场景。
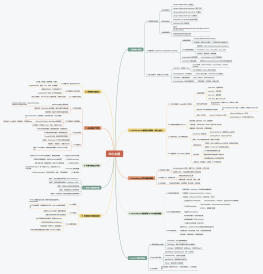
微调全流程的核心环节与关键概念
2. 数据准备(训练成败核心)数据采集、爬取、购买、业务数据接入数据清洗:去重、去噪、过滤低质、敏感信息清洗数据预处理:分词、token 化、格式标准化、分桶数据构建:预训练语料 / SFT 指令数据 / 偏好数据(RLHF)数据集划分:训练集、验证集、测试集
3. 批次
Global Batch Size(全局批次大小):所有 GPU / 节点一次迭代处理的总样本数,直接影响训练稳定性与收敛速度。参考值:7B 模型通常用 256-1024,70B 模型用 1024-4096;需结合显存与 GPU 数量调整。梯度累积(Gradient Accumulation):显存不足时的 “折中方案”,通过多次前向 / 反向传播累积梯度后再更新参数。计算逻辑:Global Batch Size = 单卡Batch Size × GPU数量 × 累积步数;注意:累积步数越多,训练速度越慢,需平衡显存与效率。
镜像与环境管理:PyTorch、CUDA、CANN、依赖库
1. 全参数微调(Full Fine-Tuning)
2. DPO(Direct Preference Optimization)直接用偏好数据训练,不需要 RM!把偏好优化变成分类任务:p(好回答) > p(坏回答)
数据飘逸
1. 需求与目标定义:确定模型类型:LLM、多模态、CV、ASR确定规模:基座 / 微调 / 领域小模型确定指标:loss、困惑度、准确率、业务效果
6. QLoRA 量化 LoRA(单卡神器)生活案例:给学生戴 超薄超轻折叠眼镜 + 简化课本• 在 LoRA 眼镜基础上:把课本内容压缩成迷你版,不影响理解,但超级省空间、省力气。• 原本要搬大书包,现在口袋书就能学。• 对应微调:4bit 量化模型 + LoRA,消费级显卡也能训 70B 大模型,效果几乎不掉。
2. 训练层核心概念(管控训练效果与成本)
架构师无需精通调参,但需掌握核心超参数的意义、训练优化技术的作用,以及风险管控要点:核心超参数概念:学习率(LR,微调最核心的超参数,PEFT 场景远小于全参数微调)、批次大小(Batch Size)、训练轮数(Epoch)、权重衰减、学习率调度(Warmup、余弦退火)、梯度累积。训练优化核心技术:混合精度训练(FP16/BF16/FP8,降低显存占用,提升训练速度)、量化训练、梯度检查点(显存换计算,降低峰值显存)、分布式训练策略(数据并行、模型并行)。关键风险概念:过拟合 / 欠拟合、训练不稳定(损失震荡 / 不收敛)、模式崩溃(输出重复 / 单一)、灾难性遗忘。
一、偏好数据(Preference Data)构建方法人类标注偏好(Human Preference)AI 自动标注(LLM-as-Judge)基于规则 / 关键词的弱监督偏好在线用户行为偏好(Implicit Feedback)
PPO:老前辈,效果强但难训、容易崩DPO:现在最常用,简单、稳、不用折腾 RM 和 RLGRPO:想比 DPO 更强、尤其做数学 / 代码 / 长文本KTO:数据不好凑不成对,单点标注就行ORPO:不想分 SFT 和对齐两步,想一步训完
3. 环境与资源准备算力集群:GPU/NPU 服务器、无收敛叶脊网络存储:对象存储 /文件存储/存数据/ checkpoint框架环境:PyTorch / MindSpore + 分布式通信库(NCCL/HCCL)容器镜像:统一依赖、CUDA/CANN、加速库
Broadcast(广播)
1. 预训练阶段显存占用详解:预训练基础参数开销 +训练阶段额外开销+ 激活值开销:基础参数开销: 基础参数显存(7B 参数,FP16 精度,主流预训练精度):参数数量 × 2 字节(FP16)= 基础显存例如:7B 参数 = 7×10^9 × 2B = 14GB;13B=26GB;70B=140GB;175B=350GB。训练阶段额外开销(全参数预训练):(1)梯度:与参数等大(FP16 下 7B=14GB);(2)AdamW 优化器状态:2×FP32× 参数数量(7B=56GB);基础参数合计:(7B FP16 全量预训练):14(参数)+14(梯度)+56(优化器)= 84GB(未算激活值)。激活值开销:受 Batch Size(BS)、序列长度(Seq Len)、模型层数影响。公式简化为:激活值显存 ≈ BS × Seq Len × 隐藏层维度 × 层数 × 精度例:7B 模型(隐藏层维度: 4096,32 层),BS=8,Seq Len=2048,FP16:8×2048×4096×32×2B ≈ 40GB叠加基础 84GB,总显存需求≥124GB(需 A100 80GB×2 卡模型并行)。
监控:Prometheus
任务管理
1. 对接 Prometheus/Grafana,监控推理服务的性能指标(延迟、吞吐量、错误率、GPU 利用率);
1. Model Registry 提供中心化模型注册中心,实现模型版本全生命周期管理(自动版本号、变更记录、阶段标记:Staging/Production/Archived);
1. 核心组件KServe(原 KFServing) 提供云原生生产级推理服务部署能力,支持自动扩缩容、蓝绿发布、A/B 测试、金丝雀发布、动态批处理;
4. 生产冗余系数通用在线场景:固定乘1.2(20% 冗余),规避显存碎片、峰值波动、请求毛刺;超长序列 / 高并发波动场景:乘1.25~1.3,留足弹性空间;绝对不能低于 10% 的冗余,否则极易出现 OOM。
超参调优Hyperparameter Tuning:Katib
1. 实验开发:用 MLFlow Projects 打包大模型微调项目,定义环境依赖和运行参数;
经典的对齐方案,分为 SFT→奖励模型训练→强化学习(PPO)三步;架构师需掌握其核心流程、极高的落地复杂度、算力成本与稳定性风险,企业级场景非强需求不优先选型。
训练服务过程
2. 将评估结果与训练实验、模型版本强绑定,形成完整的模型档案;
(二)按训练目标与对齐阶段分类
1. 从 Registry 中拉取指定阶段(如 Production)的模型版本,提供标准化模型加载接口,无缝适配各类部署框架;
推理框架
AIBrix Autoscaler AIBrix自动缩放器AIBrix提供了一个全面的自动扩展框架,专为在Kubernetes(K8s)上运行的大型语言模型(LLM)服务量身定制。它支持多种扩展模式,将原生的Kubernetes组件与专为LLM工作负载设计的增强功能相结合。这使得用户能够灵活地为其工作负载模式和性价比目标选择最合适的自动扩展器。
4. 分布式 KV 缓存(性能倍增器)
我用老师教学生写作文这个生活场景,把 7 种 LLM 微调方法一次性讲明白,保证看完就懂、不记公式。
一、人工标注:质量天花板与成本控制的平衡1. 分层标注流水线(工业界标准做法):采用 **\"AI 预标注 + 众包初筛 + 专家终审\"** 的三级流水线2. 量化成本与效率数据(2026 年国内市场)3. 一致性保障的工程化方法4. 最新最佳实践• 最小可行标注集:冷启动阶段仅需 50-100 条高质量专家标注数据即可定义质量标杆。• 标注任务拆解:• 将复杂的标注任务拆解为多个简单的子任务• 动态标注:根据模型的表现,动态调整标注重点,进行数据飞轮
1. 持续跟踪线上推理的业务效果指标,与离线训练的基线指标做对比,监控模型漂移 / 数据漂移;
大语言模型(LLM)训练与评估场景
Kubeflow Central Dashboard
FSDP(Fully Sharded Data Parallel)是 PyTorch 官方原生实现的全分片数据并行方案,核心思想与 ZeRO-3 完全一致,都是对参数、梯度、优化器状态做分布式分片。原生 DDP (Distributed Data Parallel,分布式数据并行):多卡数据分片 + 模型副本 + 梯度全局同步:AllReduce=Reduce Scatter+AllGather
固定维度打分:有用性事实准确性逻辑性流畅度安全性格式合规性偏好程度(更喜欢 A 还是 B)常用方式:成对比较(优于打分)盲测多人标注 + Fleiss Kappa 一致性校验
3. 多组实验的可视化对比,快速筛选最优模型。
AIBrix Data Plane AIBrix 数据平面数据平面组件提供可配置的组件,用于调度、编排和处理推理请求,从而实现灵活且高性能的模型执行。
JAX(google)
All Reduce (全归约)
5. 模型部署:审批通过后,将模型标记为 Production,从 Registry 拉取模型,通过 MLFlow Deployments 一键部署到 KServe/AIBrix 推理服务。
API for Control Plane Integration:用于控制平面集成的API:它确保控制平面和推理Pod之间的无缝通信。这使得LoRA适配器控制器、自动扩展器和冷启动管理器等组件能够与推理容器动态交互,以云原生方式管理资源。
7. 模型退役与归档阶段
AIBrix Data Plane AIBrix 控制平面控制平面的组件负责管理模型元数据的注册、自动扩展、模型适配器注册,并执行各种类型的策略。
现代模型日益增长的需求以及大语言模型推理中不断增加的上下文长度,导致键值缓存(KV caches)消耗的 GPU 内存越来越多,甚至逼近了最先进 GPU 的硬件极限。最近的一些系统,如 Dynamo、LMCache 和 MoonCake,已经开发出了将键值缓存卸载到外部存储层级的解决方案,涵盖从 CPU 内存到固态硬盘(SSDs)的范围。键值缓存卸载(KVCache Offloading) 也支持将键值缓存卸载到 CPU 内存,只需启用其基于动态随机存取存储器(DRAM)的 L1Cache 即可。虽然这种方法不支持在多个引擎之间共享键值缓存,但它消除了分布式键值缓存设置和配置的复杂性。更重要的是,通过利用 CPU 内存显著更大的容量,这种方法能带来显著的性能提升——使其成为那些优先考虑可扩展的键值缓存容量而非跨引擎键值复用的使用场景的理想解决方案。
4. 精度
FP16(半精度):经典混合精度方案,显存占用比 FP32 减少 50%,训练速度提升 2-4 倍。BF16(bfloat16):FP16 的 “升级版”,指数位与 FP32 相同(8 位),无需损失缩放,数值稳定性更好。FP8(8 位浮点):最新精度格式,显存与速度比 BF16 再提升近 1 倍,但硬件支持有限(仅 H100、L4 等新一代 GPU)。
奖励模型(RM)+ 偏好数据
定义运行环境(多环境支持:原生支持 Conda 环境、Docker 容器、系统 Python环境)
推理阶段算力评估方法:一、核心定义(先记这 4 个)Batch Size(BS):一次推理跑多少条样本Seq Len(L):每条样本的 Token 长度Flops per token(Fₜ):模型每生成 1 个 Token 需要的计算量Latency(T):推理耗时(秒)二、大模型推理:单 Token 计算量公式:Decoder-only 模型(LLaMA、Qwen、GPT 类)每 Token 浮点计算量:Ft=2×N×1012FLOPs/tokenN:模型参数量,单位 B(十亿)乘 2:前向传播矩阵乘的标准估算例:70B 模型Ft=2×70×1012=140×1012 FLOPs/token三、一次推理总计算量(最常用)1)Prefill 阶段(输入编码)输入长度:LprefillFLOPsprefill=Ft×Lprefill×BS2)Decode 阶段(逐字生成)生成长度:LdecodeFLOPsdecode=Ft×Ldecode×BS3)总 FLOPsFLOPstotal=FLOPsprefill+FLOPsdecode
Metadata
版本管理
ZeRO(Zero Redundancy Optimizer,零冗余优化器)ZeRO的核心思想:将模型副本中的优化器状态、梯度与参数进行分布式切分,从而显著降低单卡内存负担。彻底打破传统数据并行 “每卡存储完整模型副本” 的冗余设计,将模型训练的三大核心显存占用(优化器状态、梯度、模型参数)按设备数分布式分片,每卡仅存储 1/N 的非冗余数据,用可控的通信开销换取指数级的显存节省,大幅降低大模型训练 / 全参数微调的硬件门槛,是当前工业界大模型训练的标配技术。
二、奖励模型 RM(Reward Model)训练方法1. Pairwise Ranking RM(成对排序,最经典)2. Pointwise RM(单点打分)3. Bradley-Terry / Plackett-Luce 多排序 RM
5. 正则
Dropout:随机 “丢弃” 部分神经元,防止过拟合;但大模型中使用较少(可能影响训练稳定性),通常仅在小模型或微调时启用(如dropout_rate=0.1)。权重衰减(Weight Decay):通过惩罚大权重防止过拟合,是 AdamW 的核心超参。参考值:大模型通常设为0.01-0.1(如 LLaMA 用 0.1);需与学习率配合调整(学习率大时权重衰减可适当增大)。
MLFlow Recipes:预构建的 ML 流水线模板,内置数据处理、训练、评估、部署的最佳实践
2. 记录模型部署的版本、环境、实例信息,实现从训练到部署的全链路可追溯;
领域适配微调:让模型掌握特定行业(金融 / 医疗 / 法律 / 制造)的知识、术语与逻辑。任务适配微调:让模型优化特定任务能力,如工具调用、代码生成、SQL 生成、多轮对话、摘要生成。行为对齐微调:让模型符合定制化的输出风格、格式规范、安全准则、业务流程要求。
1. Tracking 模块全程记录训练超参、损失曲线、评估指标、硬件资源占用;
1. 偏好对齐质量AlpacaEval、MT-Bench:让更强模型(GPT-4/Claude)当裁判打分。Win Rate:新模型 vs 基线模型,人类 / AI 更喜欢谁。2. 奖励模型相关性RM 打分与人类打分Pearson/Spearman 相关系数越高说明 RM 越准。3. 多样性 & 不重复Self-BLEU、Dist-n(distinct n-gram)防止模式崩溃、复读机。4. 对齐不崩溃通用能力不掉、知识不忘、流畅度不降对比 SFT 前后 PPL、MMLU 等
RLHF/DPO/GRPO(对齐人类偏好)
RoleSet:角色集:角色集表示一组角色的集合,其中每个角色可承担特定功能(例如,预填充或解码)。
训练阶段
1. 全量微调 Full Fine-Tuning生活案例:把学生重新回炉重造一遍• 原来的学生:基础很好,但写作文不太会。• 做法:从三观、习惯、知识全部重新教一遍,连写字姿势、说话逻辑都改。• 结果:作文写得超级好,但代价极大、很累、容易把以前会的东西忘掉。• 对应微调:更新模型全部参数,效果最好,但费卡、费时间、容易遗忘。
自动扩缩容
MLflow + Kubeflow 协同架构
1. LLM-as-Judge(AI 裁判)用更强模型打分:1~5 分制维度:有用性、事实性、逻辑、安全、格式优点:快、便宜、可规模化缺点:有偏见、不稳定2. 对比胜率 Pairwise ComparisonA 回答 vs B 回答 → 选出更好的用于:DPO/GRPO 训练数据模型版本迭代对比3. 基准套件(一站式跑)MMLU:学科综合能力C-Eval / GAOKAO:中文高考题GSM8K / Math:数学HumanEval / MBPP:代码MT-Bench:对话综合IFEval:指令遵循
单卡Batch Size怎么算?AI 模型理解成一个做题的学生,Batch Size(批次大小) 就是一次性给学生的题目数量,一个题目就是一个样本,题目中的文字是一个TOKEN:训练场景:学生一次看完 N 道题,做完、对答案、总结错题规律,再更新自己的解题方法(模型参数),这 N 就是训练的 Batch Size;推理场景:学生一次性同时做 N 道题,批量给出答案,这 N 就是推理的 Batch Size。单卡Batch Size上限 = (显卡总显存 - 固定显存占用 - 10%~20%安全冗余)÷ 单样本激活值显存占用概念说明:1、样本:一条完整的、独立的任务数据,由一串连续的 Token 组成,是模型一次输入输出的完整单元。2、Token:大模型处理文本的最小粒度3、单样本激活值显存占用:模型训练场景中,单 Token 激活值是 Batch Size 可变显存占用的核心来源,其大小由模型结构、精度、训练优化开关(FlashAttention、梯度检查点)三大核心因素决定;推理场景下激活值占用极低,几乎可忽略。BF16/FP16 精度单样本单 Token 的激活值显存,稳定在 150~200 Bytes固定显存占用:包括模型权重、梯度、优化器状态、框架预留显存。例:7B 模型 BF16 全参数训练,这部分固定占用就超过 40GB,和 Batch Size 大小没有关系。可变显存占用:核心是前向传播的激活值、反向传播的中间梯度、注意力临时张量,是 Batch Size 的核心限制项。Batch Size 越大,这部分占用指数级增长,直接触发 OOM。总激活值显存 = 单 Token 激活值 × 单卡总 Token 数(单卡 Batch Size× 序列长度)
Observability可观测性:它提供了一个统一的接口,用于跨不同推理引擎进行监控,支持一致的性能跟踪和故障排除。
Gather(收集)
2. 大模型专用推理框架vLLM(最主流)Text Generation Inference(TGI)TensorRT-LLM(英伟达)MindSpeedLightLLM、FastLLM、Qwen-Server
BLEU看 n-gram 重叠,机器翻译最经典。ROUGE-1/2/L看精确率 / 召回率,摘要标配。METEOR考虑同义词,比 BLEU 更贴近人类判断。PERPLEXITY(困惑度)模型语言流畅度,越低越好。F1 / Acc / Precision / Recall分类、抽取、NER、指令遵循任务。
算力计算分析
5. LoRA 低秩适配(目前最主流)生活案例:给学生加一副 “作文专用隐形眼镜”• 学生本身完全不动。• 戴上一副轻薄眼镜,只修正看世界的角度,不改变大脑。• 写完作文,眼镜可以摘掉、换一副、存起来。• 推理时:眼镜直接融到眼睛里,看不出区别,速度不变。• 对应微调:只训练低秩小矩阵,效果接近全量,无推理延迟,工业标配。
2. 指标:训练 / 验证 loss、准确率、显存占用、训练速度(tokens/s);
3. 基于指标阈值自动标记合格 / 不合格模型,触发后续注册 / 驳回流程。
Distributed KV Cache Runtime:分布式KV缓存运行时:提供跨节点的可扩展、低延迟缓存访问。通过支持KV缓存重用,它减少了冗余计算并提高了令牌生成效率。
1. 模型权重显存速算核心公式:模型权重显存 ≈ 参数量 × 单参数字节数
AI Engine Runtime:AI引擎运行时:一种轻量级边车,可分担管理任务、执行策略并抽象化引擎交互。
数据版本控制
张量并行是一种将模型中的张量(如权重矩阵)依据维度划分至多个GPU上并行计算的策略。切分机制主要包含两种:行切分(Row Parallelism),即权重矩阵沿行方向分割;列切分(Column Parallelism),即权重矩阵沿列方向分割。每个节点处理切分后的子张量。最后,通过集合通信操作(如All-Gather或All-Reduce)来合并结果。
1. 自动记录全量评估指标(如大模型的 ROUGE/BLEU 值、幻觉率、安全合规通过率,传统模型的准确率 / 召回率)、性能压测数据;
分布式训练技术
2. 推理引擎优化图优化、算子融合内存优化、连续 Batch动态 Batch、异步推理
2. MLflow Projects 打包数据处理、特征工程的代码与运行环境,保证跨环境可复现;
3.微调的目标场景分类
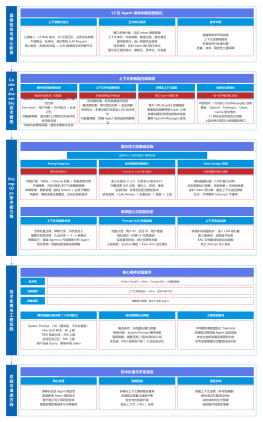
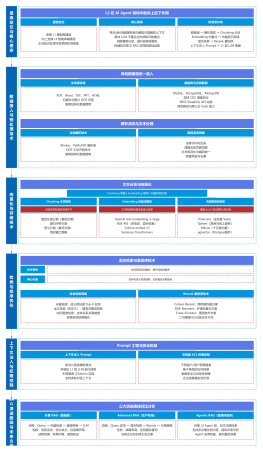
AIBrix架构图:https://aibrix.readthedocs.io/latest/index.html
训练框架
Model Adapter (Lora) controller:模型适配器(LoRA)控制器:支持每个Pod部署多个LoRA,显著提高了可扩展性和资源效率。
数据接入与数据服务
Optimizer-based Autoscaling 基于优化器的自动扩缩容利用离线分析数据和优化求解器来主动确定最佳资源分配。它包括(1)大语言模型请求监控和(2)GPU优化器。
成本与权限
MLflow Model Registry:企业级模型资产与生命周期管理
多框架原生支持:内置 PyTorch/TensorFlow/ONNX/Sklearn/XGBoost 等主流框架的打包接口
概念漂移
Pooled Mode 池化模式池化模式将角色集内的每个角色视为共享池的一部分。在这种模式下,每个角色应能独立扩展。它旨在处理不同角色有不同扩展需求的场景。Resource Pool:资源池:预填充或解码实例形成一个共享池。Independent Role Scaling:独立角色扩展:每个角色都可以根据其特定负载和要求独立扩展。
调度与编排:KubernetesVolcano / YARN / Slurm任务队列、优先级调度、弹性训练
Kubeflow 流水线触发训练
Tools for Serving:• KFServing• Seldon Core Serving• TensorFlow Serving(TFJob)• NVIDIA Triton Inference Server• TensorFlow Batch Prediction
MLFlow Deployments统一的模型部署接口,支持一键部署到多种推理服务
All Gather(全收集)
单卡 Batch Size 的最终取值,不是只看显存序列长度:同样的显存,序列长度从 2048 涨到 4096,单卡样本数必须直接减半 —— 因为总 Token 数和激活值占用翻倍,这也是大模型长序列训练必须大幅降低 Batch Size 的原因。训练优化开关:开不开 FlashAttention、梯度检查点,会让激活值显存占用差 3~10 倍,直接改变 Batch Size 的上限。比如不开梯度检查点,7B 模型的单卡 Batch Size 上限可能直接减半。训练效率(吞吐最优):不是 Batch Size 越大,训练速度越快。当 Batch Size 超过某个阈值,会出现显存带宽饱和、GPU 调度开销增加,反而导致每秒处理的 Token 数(吞吐)下降。工业界通常会选「比显存上限略低,但吞吐最高」的 Batch Size,而非极限值。训练稳定性:过大的单卡 Batch Size,在微调场景可能导致梯度方差异常、训练震荡,甚至出现梯度爆炸 / NaN,有时会主动下调 Batch Size,优先保证收敛稳定。精度选型:BF16/FP16 比 FP32 显存直接减半,INT8 训练能再降一半,会大幅提升 Batch Size 的上限,同样的显存能承载更大的 Batch Size。Batch Size 决策流程(优先级从高到低)先根据训练场景,确定目标全局有效 Batch Size(效果优先,行业共识锚定);固定训练基础配置:精度、序列长度、FlashAttention、梯度检查点等核心优化开关;根据单卡显存大小,测试出单卡 Batch Size 的最优上限(不 OOM、吞吐最高);用公式倒推梯度累积步数,精准凑出目标全局 Batch Size;配套调整学习率(线性缩放)、梯度裁剪等超参,保证训练稳定收敛。
模型开发层
4. 调度优化动态批处理(Dynamic Batching)多请求复用、迭代级调度资源超配、QoS 保证
7. Volcano 调度集成(资源调度中枢)
All to All(全对全)
4. 模型注册与资产管理阶段
1. 大模型训练算力需求测算:训练总运算量(FLOPs)≈ 6 × 模型参数量 × 训练总token数(最优训练Token数 ≈ 20 × 模型参数量)公式来源:Transformer 训练中,每个 token 的前向传播需要2×参数量次运算(矩阵乘的乘加),反向传播需要4×参数量次运算(输入梯度 + 参数梯度),合计 6 倍关系。适用场景:全参数预训练、全参数微调;PEFT 微调仅需计算可训练参数的运算量,总需求会大幅降低。测算步骤与示例需求:7B 开源模型,全参数微调,训练数据量 1 亿 token,用 A100 80GB 显卡,测算需要的卡时。算总运算量:6 × 7e9 × 1e8 = 4.2e18 FLOPs = 4200 PFLOPs算单卡有效算力:A100 FP16 峰值 312 TFLOPS,微调场景利用率 30% → 312 × 0.3 = 93.6 TFLOPS = 0.0936 PFLOPS per card算总卡时需求:4200 PFLOPs ÷ 0.0936 PFLOPS ≈ 44871 小时落地换算:8 卡 A100 机器,需要 44871 ÷ 8 ≈ 5609 小时 ≈ 234 天;64 卡集群,需要≈700 小时≈29 天。补充:LoRA 微调场景,可训练参数量仅 0.1%,总运算量会降低 99% 以上,单张 RTX 4090 即可在几小时内完成。训练总Token数 = 全局Batch Size × 训练步数全局Batch Size = 单卡Batch Size × 显卡数量 × 梯度累积步数示例:8 卡 A100 训练,单卡 Batch Size=32,梯度累积步数 = 4,序列长度 = 2048(TOKEN),则全局 Batch Size=32×8×4=1024 个样本,对应单步 Token 数 = 1024×2048(单样本TOKEN数量)≈200 万 Token;训练 1 万步,总 Token 数≈2000 亿。
训练服务
3. 评估层核心概念(对齐业务目标,验证落地效果)
架构师需建立「技术指标 + 业务指标」双维度的评估体系,避免实验室效果与线上效果脱节:核心评估维度:基础能力保留:通用语言能力、常识推理能力是否未因微调丢失。业务效果:领域知识准确率、指令遵循率、输出格式合规率、业务核心指标(如工具调用成功率、SQL 生成准确率)。安全与合规:幻觉率、有害内容生成风险、偏见与歧视、合规性。性能指标:推理速度、显存占用、并发能力。核心评估方法:自动评估(困惑度 Perplexity、ROUGE/BLEU、行业基准 MMLU/CMMLU 等)、人工评估(业务专家 + 产品 + 安全团队的多维度评分)、对抗性评估、线上 A/B 测试。关键概念:泛化能力、鲁棒性、分布外(OOD)性能、幻觉率。
四、自动化评估方法(工业界最常用)
模型服务上线:Serving
4. 部署与推理层核心概念(落地到业务架构的关键)
微调的最终目标是上线服务,架构师需掌握微调后模型的部署全流程核心概念,对接业务系统:模型后处理:权重合并(LoRA 权重与基座模型合并)、模型量化(4bit/8bit、AWQ/GPTQ,平衡精度与推理成本)、模型蒸馏 / 剪枝(进一步压缩模型,提升推理效率)。部署核心概念:推理引擎(vLLM、TGI、TensorRT-LLM,核心提升吞吐、降低延迟)、服务化封装(OpenAI 兼容接口)、高可用架构、弹性扩缩容、多模型调度。核心权衡:精度损失 vs 推理成本、显存占用 vs 并发能力、延迟 vs 吞吐。
Reduce(归约)
模型验证和超参调优:Katib
训练配置与超参设定
AIBrix KVCache Offloading FrameworkAIBrix KV缓存卸载框架
2. 峰值 KV Cache 显存速算(核心变量项,3 秒算出)单请求KV Cache显存 ≈ 2 × 层数 × 隐藏层维度 × 序列长度 × 精度字节数 / 1024³峰值 KV Cache 总显存计算:峰值KV Cache总显存 = 单请求KV Cache显存 × 最大并发数 × 最大序列长度
Abstracting Vendor-Specific Inference Engines:抽象特定供应商的推理引擎:AI引擎运行时旨在与各种推理引擎协同工作,包括大多数主流的推理引擎。然而,这些引擎的编程接口各不相同。AIRuntime没有与任何特定引擎紧密耦合,而是对模型加载/卸载、适配器配置和性能监控等关键操作进行了抽象,使新的推理后端能够以最小的阻力集成进来。
6.高可用架构健康检查、自愈限流、降级、熔断灰度、蓝绿、彩虹
6. 正式训练(核心执行)前向传播:(将一批训练样本输入模型,输出对应的预测值。)计算损失:loss-利用损失函数量化预测输出与真实标签之间的偏差。反向传播:梯度计算,从损失值出发,沿网络反向计算各参数的梯度。span style=\"font-weight:normal; font-size:inherit;\
4. 模型选型与初始化基座选择:开源基座 / 自研从头训结构配置:层数、维度、头数、参数量、上下文长度权重初始化:随机初始化 / 加载已有预训练权重分布式配置:TP/PP/DP/FSDP/MoE 并行策略
3. Katib 实现自动化超参调优,批量优化模型效果。
MLflow Tracking实验跟踪与元数据管理
数据层
4. RLAIF(RL from AI Feedback)用 LLM-as-Judge 替代人类标注流程:AI 打分 → RM → PPO/DPO
模型构建:Fairing
1. 基于流水线规则自动触发模型注册流程,对接 MLflow Registry;
1. RLHF(Reinforcement Learning from Human Feedback)算法:PPO(Proximal Policy Optimization)流程:SFT → RM → PPO 用 RM 奖励不断更新模型
3. Katib 组件提前开展超参搜索预实验,锁定最优超参范围。
3. 高密度 LoRA 管理(多租户引擎)
Supported Routing Strategies:random、Least-request、throughtput、prefix-cache、least-busy-time、least-kev-cache、least-latency、prfix-cache-preble、pd、session-affinity...
模型性能
1.有监督微调(SFT,Supervised Fine-Tuning)
训练平台
5. 可观测性QPS、时延、错误率、吞吐量硬件利用率(GPU/NPU/CPU)日志、调用链、告警
与 KFP 集成
Adding New KVCache Backends 添加新的KV缓存后端通过实现Connector接口,可以轻松添加新的KVCache后端
加速技术:混合精度 / FP8 训练梯度累积、ZeRO 优化算子融合、算子编译、图优化检查点断点续训
6. 高可用&容错健康检查、自动重启故障隔离、滚动更新多副本、跨节点部署
5.高性能网络gRPC / HTTP2RDMA 推理加速无损低时延网络
Eventing
专家并行(Expert Parallelism)是MoE(混合专家模型)中的一种并行计算范式,其核心在于将各专家(子模型)部署于不同的GPU节点,从而实现计算负载的分布式承载,优化资源利用率。专家层中,每位专家专精于处理某一类token(如语法、语义等)。路由网络依据输入token的特征,动态筛选出少数专家进行激活处理,其余专家保持休眠状态。MoE通过明确的任务分工与按需调度算力,显著提升了模型的整体运行效率。专家并行的根本差异在于:输入数据需经由动态路由机制分发至对应的专家,这一过程引发全节点范围内的数据重分配。待所有专家完成处理后,必须将分布在各节点的输出结果,严格按照原始输入序列进行重组与归位。跨设备的数据交换模式,被定义为All-to-All通信。专家并行机制易受负载不均的制约:若某专家接收的token数量超出其处理容量,将导致部分Tokens无法及时处理,进而形成系统瓶颈。因此,构建高效、均衡的门控机制与专家选择策略,是成功部署专家并行架构的核心前提。
2. 支持自定义评估规则,不通过的模型直接终止流水线,避免不合格模型进入生产环节。
2. 微调阶段显存占用详解微调的显存占用分全参数微调和参数高效微调(PEFT) 两类,后者是企业落地主流:(1)全参数微调(极少用)显存逻辑与预训练一致,但序列长度 / BS 更小,显存需求略低:例:7B 模型 FP16 全参数微调(BS=2,Seq Len=1024):参数(14GB)+ 梯度(14GB)+ 优化器(56GB)+ 激活值(≈10GB)= ≈94GB 核心问题:显存需求高 + 灾难性遗忘风险,架构师需明确「非核心场景不推荐」。(2)PEFT(LoRA/QLoRA,企业首选)显存占用的核心是冻结基座模型(仅加载不更新)+ 少量可训练参数:冻结基座的显存优化:QLoRA 将基座模型量化为 4bit/8bit,显存占用直接降 75%/50%:7B FP16(14GB)→ 4bit QLoRA(3.5GB);13B FP16(26GB)→ 4bit QLoRA(6.5GB);70B FP16(140GB)→ 4bit QLoRA(35GB)。可训练 LoRA 参数的显存开销(忽略不计):LoRA 的低秩矩阵参数量≈模型总参数的 0.1%-1%,例:7B 模型 LoRA(rank=64)仅≈12MB 可训练参数,其梯度 + 优化器状态合计≈100MB,对显存无实质影响。实际显存参考(4bit QLoRA,BS=4,Seq Len=2048):
数据治理
核心组件协同闭环
7. AdaLoRA 自适应 LoRA生活案例:给学生配一副 “智能自动调焦眼镜”• 普通 LoRA 眼镜度数固定。• AdaLoRA:看重点内容时度数加深,看不重要内容度数变浅,自动分配精力。• 同样一副眼镜,** smarter、效果更好 **。• 对应微调:不同层自适应分配秩大小,同样参数量,效果比普通 LoRA 更强。
资源调度与编排
流水线编排核心组件 Kubeflow Pipelines(KFP):• Python SDK• DSL compiler• Pipeline Web Server• Pipeline Service• Kubernetes Resources• Machine Learning • Metadata Service• Artifact Storage• Orchestration Controllers
分布式训练支持:DP/MP/PP/FSDP/MoE
模型评估
场景 1:在线对话服务(低延迟、高并发、常规序列长度)示例:7B INT4 模型,业务要求峰值并发 64 路,单请求最大序列长度 2048token模型权重:3.5GB峰值 KV Cache:0.25MB × 64 × 2 = 32GB中间激活:0.35GB20% 冗余:(3.5+32+0.35)×1.2 ≈ 43GB推荐显卡:A100 80GB ,最低也要 A10 24GB(需限制并发上限)
一台节点把自己的数据发给所有节点。常用于模型参数的初始化。(参数初始化:预训练、微调、推理部署阶段)类比:老师发讲义,每个学生都能拿到一份。
流水线并行 PP:把模型本身拆分成若干层部分,由不同的 GPU 分别执行各自负责的模块。流水线并行,则是把模型的各层——无论是单层还是连续的多层——分布到不同 GPU 上,数据按层序依次传递,形成类似流水线的并行处理流程。
3. Artifacts:自动存储模型 checkpoint、训练日志、配置文件、tokenizer 等,支持对接 S3/MinIO 等分布式存储(适配大模型的超大文件存储)。
1. 创建标准化实验项目,统一管理实验元数据规范;
4. 模型标准化打包,兼容 KServe、Triton、AIBrix 等主流部署框架。
背景:对大型语言模型需求的增长,加剧了对高效内存管理和缓存的需求,以优化推理性能并降低成本。在聊天机器人和基于智能体的系统等多轮使用场景中,重叠的令牌序列会导致预填充阶段出现冗余计算,从而浪费资源并限制吞吐量。
Fairing:打包构建image
TensorFlow / Keras
数据校验工具
五、人工评估方法(最准但最贵)
下线退役模型的推理服务,释放 K8s 集群资源,归档相关的流水线、任务记录。
3. 跟踪批量推理任务的效果指标,与离线评估指标做对比,提前发现模型效果衰减。
审批流与权限管控
Metrics-based Autoscaling 基于指标的自动扩缩容HPA(水平Pod自动扩缩器):纯粹基于CPU利用率对演示部署进行扩展。KPA(Knative Pod 自动扩缩器):关键绩效指标(KPA):通过激进的应急扩展处理由vllm支持的Llama2-7b模型的短期峰值。APA(高级 Pod 自动扩缩器):应用波动容忍度减少对延迟敏感的大语言模型服务的规模波动。
2. 训练与微调阶段
封装为标准化项目MLproject标准化文件
MLflow 跟踪实验
Inference Graph(多模型编排)
2. 服务发布与托管一键部署推理服务多版本、灰度发布、流量切分自动扩缩容、缩容(Serverless)
6. 统一 AI 运行时(标准化底座)
事件路由
StormService在其层级支持两种运行模式:滚动更新和原地更新。在RoleSet层级,支持滚动的三种更新模式:并行、顺序和交错。
训练阶段关注指标
7 种SFT(有监督微调 Supervised Fine-Tuning)核心微调方法
1. KFP 调度自动化模型评估任务,按需分配资源运行离线效果评估、偏见检测、安全合规校验、推理性能压测;
模型部署层
数据准备
ORPO/IPO/KTO:
Frameworks for Training • Chainer • MPI • MXNet • PyTorch • TensorFlow
基于 RM 的对齐算法:RLHF 家族、DPO 家族
2. Kubeflow Pipelines(KFP)定义数据预处理流水线,完成数据清洗、特征工程、数据集版本管理;
核心定义:PPL 是专门衡量语言模型文本建模能力的核心指标,通俗理解为:模型对下一个 token 的预测的 “不确定 / 困惑程度”。PPL 数值越低,模型对文本的预测越精准,语言流畅度建模能力越强。核心特点:语言建模能力的黄金指标:是大模型预训练阶段的核心评估指标,直接反映模型对自然语言的拟合能力;与 Loss 完全单调负相关:Loss 下降,PPL 必然同步下降,二者的收敛、过拟合趋势完全一致;对比有严格前提:只有在完全相同的测试集、词表大小、序列长度下,不同模型的 PPL 才有对比意义,跨领域、跨词表的 PPL 对比无任何价值;有明确的能力边界:PPL 仅能衡量语言流畅度,无法衡量模型的推理能力、事实准确性、指令遵循能力、人类偏好对齐效果。甚至对齐后的模型,PPL 会小幅上升,但用户体验会显著提升。
DPO(直接偏好优化):
混合并行:在实际部署中,尤其是在训练参数规模达万亿级别的超大规模模型时,单一并行方式几乎从不独立使用,取而代之的是融合多种机制的混合并行架构(即协同运用多种并行技术)。例如:数据并行 + 张量并行:数据并行负责分发训练批次,张量并行则分解单个样本的巨型张量运算。流水线并行 + 专家并行:流水线并行将模型按层切分,专家并行则对每一层内的稀疏专家模块进行独立划分。更进一步的优化形态是 3D并行,即通过“数据并行 + 张量并行 + 流水线并行”的三维协同拆分,实现计算负载的立体化均衡,已成为当前万亿级模型训练的标准化范式。
张量并行的优势在于应对单个张量规模过大的场景,能有效降低单节点的内存压力。张量并行的局限在于,随着切分维度的增加,节点间的通信成本显著上升;同时,其工程实现难度较高,需精心规划张量切分策略与通信协调机制。
分布式训练调度组件Training Operator:TF-OperatorPyTorch-OperatorCaffe2-OperatorMPI-OperatorMXNet-Operator
三、自指令生成:低成本数据扩展的利器1. 2026 年自指令技术的突破• Multi-Agent Debate 生成:让多个 Agent 针对同一个问题进行辩论,生成多角度、高质量的问答数据,质量接近人工标注• Self-Play 生成:让模型扮演不同的角色进行交互,生成自然的多轮对话数据,特别适合对话系统训练• 工具增强自指令:让模型调用搜索引擎、计算器、代码解释器等工具生成数据,突破自身能力边界• 迭代式自指令:用生成的数据微调模型,再用微调后的模型生成更高质量的数据,形成正循环2. Evo-Instruct 的最新进展• OpenAI Evo 2:引入了更复杂的指令进化策略,包括逻辑复杂化、多步推理、反事实推理等,可生成难度极高的推理数据• 字节跳动 Evo-Chinese:针对中文场景优化的指令进化算法,解决了原版 Evo-Instruct 中文数据质量差的问题• 领域自适应 Evo-Instruct:可针对特定领域(如医疗、法律)生成专业的指令数据,无需大量领域种子数据3. 突破能力边界的方法• 外部知识注入;• 人类反馈引导;• 跨模型迁移4. 工程实现细节• 种子指令选择标准:种子指令应覆盖所有目标任务类型,且具有代表性和多样性• 过滤规则设计:包括长度过滤、重复过滤、语言过滤、逻辑一致性过滤、毒性过滤等• 质量评分:训练专门的质量评分模型,对生成的数据进行打分,只保留高分数据• 多样性控制:通过调整温度参数、使用不同的提示词、引入随机因素等方式保证数据的多样性
MLFlow Evaluate:内置模型评估工具
一、传统生成类指标(经典硬指标)
Pods:Pod:角色集内的每个角色都包含多个Pod,这些Pod是执行推理任务的实际容器。
监控、日志、告警:(算力利用率、loss、学习率、吞吐量)
权重打底 + Cache 算顶 + 引擎优化 + 冗余保命
1. 通用推理框架容器化、K8s 编排Serverless、Knative 弹性服务网格、流量治理
关键概念解释(架构师视角)模型参数显存:模型权重本身占用的显存,是基础开销(如 FP32 精度下,10 亿参数≈4GB 显存,FP16精度,10参数≈2GB显存)。梯度显存:反向传播时计算的参数梯度,大小与模型参数完全一致(仅训练阶段存在,推理无)。优化器状态显存:优化器(如 AdamW)维护的动量、二阶矩等状态,是训练显存的核心大头(AdamW 的优化器状态≈2 倍模型参数显存)。激活值显存:前向传播时产生的中间张量(如 Transformer 每层的 Attention 输出、FFN 输出),受 Batch Size、序列长度、模型层数影响极大。显存冗余:框架预留、碎片、数据加载等开销,实际估算需额外加 10%-20%。
AIOps/MLOps
灰度发布
(一)按参数更新范围分类
训练步数(也叫 Iteration/Step),指模型完成一次参数更新的完整循环1. 核心公式(大模型训练通用,优先用 Token 数计算):总训练步数 = 计划训练Epoch数 × 单Epoch步数单Epoch训练步数 = 总有效训练Token数 ÷ 全局有效Batch Size(每步更新的总Token数)全局有效Batch Size(Token)= 单卡单步Token数 × 显卡数量 × 梯度累积步数单卡单步Token数 = 单卡样本数 × 单样本序列长度关键澄清:梯度累积 N 步,才算 1 次完整的训练步数(1 个 Step),因为只有累积完 N 步,才会做一次参数更新。
大规模训练:TFJob
6. GRPO(Group Relative Policy Optimization,分组相对策略优化)Deepseek新一代大模型偏好对齐算法,属于 RLHF 简化版。核心是去掉 Critic / 价值网络、用组内相对奖励做 PPO,训练更稳、显存更低、适合长文本 / 推理任务。GRPO:PPO 简化版 → 保留策略梯度优势,但砍掉 Critic→ 用 同 Prompt 多输出分组(Group) → 组内算相对优势 → 更稳更快
2. 深度适配 vLLM、TensorRT-LLM 等大模型推理引擎,支持分布式推理、长上下文优化;
事件源接入
3. 管理模型效果基线,触发指标异常告警与自动化重训练流程。
KubeFlow流程图
3. 实现模型元数据全链路追溯(关联对应数据集、训练代码、超参、评估结果);
AIBrix Router AIBrix 路由器AIBrix Router 是嵌入在 AIBrix 大模型服务栈中的一个可插件化智能流量管理组件。它通过外部处理钩子设计为 Envoy 网关扩展,作为所有大模型推理请求的单一入口点。
Request Router:请求路由器:充当中央请求分配器,执行公平性策略、速率控制(每分钟令牌数/每分钟请求数)和工作负载隔离。
阶段标记:Staging(待发布)、Production(生产中)、Archived(已归档)
显存计算分析
核心功能
模型效果
Three-layer Architecture 三层架构StormService:这是一个顶级CRD,用于封装整个服务。它定义了服务单元的规格并跟踪其状态,包括副本数量(即RoleSet)、RoleSet的统一模板、更新策略以及其他配置。
大模型评估方法体系:传统指标 → 大模型专用指标 → 对齐类评估 → 自动化评估 → 人工评估
5. 缓存优化KV Cache 复用、Cache 预分配多层缓存(GPU / 内存 / 磁盘)
MindSpore
分布式训练技术:数据并行 DP张量并行 TP流水线并行 PP3D 并行 FSDP 完全分片数据并行MoE 专家并行
5. 训练配置与超参设定优化器:AdamW、 Lion学习率:warmup、衰减策略批次:batch size、梯度累积精度:FP16/BF16/FP8 混合精度正则:dropout、权重衰减并行策略、checkpoint 保存策略
所有节点一起归约,并且每个节点都能拿到结果。可以看作 “Reduce + Broadcast”。类比:老师算出平均分后,把结果再告诉所有学生。
PaddlePaddle
5. 分布式推理编排(大规模引擎)
RayClusterFleet:编排多节点推理,确保分布式环境中的最佳性能。
无缝对接 Knative提供统一的部署接口
1. 开发与实验准备阶段
L1 Engine DRAM Cache Management L1引擎DRAM缓存管理
四、真实用户交互数据:最有价值的数据来源1. 隐私合规的最新要求• 明确要求用户数据必须经过脱敏处理,不得泄露用户个人信息• 数据最小化原则:只收集必要的用户交互数据,不得收集与服务无关的信息• 用户知情权和选择权• 数据留存期限2. 隐式反馈的最新方法除了传统的点赞、点踩等显式反馈,工业界越来越多地使用隐式反馈来筛选高质量数据• 用户行为反馈:是否复制回答、是否分享回答、是否继续提问、停留时间、鼠标轨迹等• 对话结束方式:自然结束的对话质量通常高于用户主动中断的对话• A/B 测试反馈:在 A/B 测试中表现更好的模型生成的回答,质量通常更高3. 数据飞轮的闭环设计完整的闭环流程是:1. 模型上线,服务用户2. 收集用户交互数据和反馈3. 自动筛选高质量的交互样本4. 用筛选出的样本微调模型5. 新版本模型上线,进行 A/B 测试6. 根据 A/B 测试结果,优化数据筛选策略7. 重复上述过程,形成正循环
GRPO(Group Relative Policy Optimization)
2. Adapter Tuning 适配器微调生活案例:给学生戴一个 “作文专用小耳机”• 学生本身完全不动,脑子、知识都不变。• 耳朵里塞一个小适配器,只教它怎么写作文。• 写别的科目时,摘掉耳机;写作文戴上。• 对应微调:冻结大模型,只训练插入的小网络,不影响原能力,多任务可切换,但推理稍微慢一点。
全链路追溯
8.模型评估与导出:验证集评估:困惑度 PPL、loss、准确率;benchmark 评测;人工评估:流畅度、安全性、业务效果;模型格式转换、导出、上线推理;
把各个节点的结果聚合在一起,比如求和、取最大值。核心是从 “分散信息” 中提取 “聚合价值”。类比:每个小组交答案,老师统一计算平均分。
Replica Mode 副本模式:副本模式将每个角色集视为服务的独立副本。如果您已经知道P/D比率,可以直接配置角色集并进行复制。Independent Replicas:独立副本:每个角色集独立运行,对一个角色集的更改不会直接影响其他角色集。Scaling at RoleSet Level:在角色集级别进行扩展:扩展操作通过添加或移除整个角色集实例来执行。
推理平台
对大型语言模型日益增长的需求极大地增加了对庞大KV缓存容量的需求。虽然CPU内存卸载能有效满足中等规模的扩展需求,但处理大规模、动态工作负载的生产环境需要更高的可扩展性——尤其是当内存需求超过单节点容量时。为解决这一问题,AIBrix将分布式KV缓存服务作为其L2Cache后端,该后端可跨多个节点横向扩展以满足容量需求。与此同时,随着大语言模型部署在集群中的多个引擎上扩展,引擎间KV缓存的冗余会导致显著的效率低下。对常见提示前缀的重复计算会浪费GPU周期和HBM带宽。AIBrix通过高性能的共享分布式KV缓存实现高效的跨引擎KV复用,从而解决这一挑战,在大规模场景下优化资源利用率
Autoscaling 自动缩放副本模式:StormService在其自定义资源定义(CRD)上启用了/scale子资源。扩展单位是RoleSet。这包括通过动态标签选择器扩展StormService状态,以及实现控制器逻辑以确保该选择器被正确填充,从而允许外部自动扩展器有效地管理StormService副本。池化模式:在池化模式下,角色集中的每个角色都应能独立扩展。
SFT 微调数据来源
PyTorch
3. 对接 K8s 服务网格、监控告警体系,保障推理服务的高可用与可观测性。
3. 硬件专属推理引擎TensorRT(NVIDIA)MindIE(昇腾)ONNX RuntimeOpenVINO(Intel)
推理加速优化(推理核心性能)
4.分布式推理张量并行 TP流水线并行 PP多机推理协同
预训练 Pre-training(学语言 / 知识)
在数据平面上,它通过AIBrix卸载连接器与推理引擎(例如vLLM)紧密集成,该连接器采用优化的CUDA内核,显著加速GPU和CPU之间的数据移动。为实现内存可扩展性,其多层缓存管理器动态平衡存储层间的工作负载,在减轻GPU内存容量限制的同时最大限度降低延迟损耗。该框架支持可插拔的淘汰策略(例如LRU、S3FIFO)和多种后端存储选项(例如InfiniStore),能够通过选择性的KV缓存卸载来减少网络和PCIe争用。关键是,其缓存放置模块可以与集中式分布式KV缓存集群管理器协同工作,以最大化全局KV缓存利用率。这实现了跨引擎的KV复用,并确保了集群范围内的资源效率,将孤立的KV缓存实例转变为可扩展的共享KV缓存基础设施。
6. 线上监控与运维迭代阶段
7. Checkpoint 保存策略
保存频率:每 N 步(如 1000-5000 步)或每个 epoch 保存一次;保存内容:模型权重、优化器状态、训练步数、学习率、随机种子等(支持断点续训);版本管理:仅保留最近 M 个 checkpoint(如 5-10 个),避免磁盘溢出;断点续训:加载最新 checkpoint 后,需恢复优化器状态、学习率调度器状态,确保训练连续性。
前缀 / 提示调优类
MLflow Projects: 可复现的 ML 项目打包
Kubeflow Pipelines(KFP)
1.优化器
AdamW:大模型训练的 “标配” 优化器,在 Adam 基础上解耦了权重衰减与梯度更新,避免 L2 正则化被自适应学习率干扰。核心超参:beta1=0.9(一阶矩平滑系数)、beta2=0.999(二阶矩平滑系数)、epsilon=1e-8(数值稳定项)、weight_decay=0.01(权重衰减,通常设为 0.01-0.1)。Lion:新兴的轻量级优化器,仅用一阶矩更新参数,计算量比 AdamW 低 30%-50%,显存占用更少。核心特点:更新步长更 “激进”,学习率通常需设为 AdamW 的 1/3-1/10(如 AdamW 用 3e-4,Lion 用 1e-4);适合超大模型或长序列训练。
特征存储
当前企业对齐的主流方案,直接基于偏好配对数据优化模型,绕过奖励模型与 PPO 环节,大幅降低训练复杂度、算力成本与显存要求,效果与 RLHF 相当甚至更优。
五、其他未来四个关键数据来源1. Agent 交互合成数据(2026 年最火的合成数据方法):让多个具有不同角色和能力的 Agent 进行交互,生成高质量的多轮对话、辩论、协作数据2. 开源数据集二次加工:现有的开源数据集进行清洗、过滤、重写、增强,得到高质量的 SFT 数据3. 跨领域迁移数据:将一个领域的高质量数据迁移到另一个领域,利用已有的高质量数据快速构建新领域的数据集4. 对抗性数据:专门生成模型容易出错的样本,用于提升模型的鲁棒性和安全性
1. 模型优化量化:INT8/FP8/FP16/BF16剪枝、蒸馏、结构优化KV Cache 优化、PagedAttention
训练关键技术(框架核心)
场景 2:超长文档 / 知识库问答(长序列、低并发、大输入)示例:13B INT4 模型,业务要求单请求最大 32k token,并发 4 路模型权重:13B×0.5B=6.5GB峰值 KV Cache:0.5MB × 4 × 32 = 64GB中间激活:0.65GB25% 冗余:(6.5+64+0.65)×1.25 ≈ 89GB推荐方案:单卡 H100 80GB 不够,需 2 卡张量并行,每卡至少 80GB 显存
2. 提供模型审批流、权限管控能力,满足企业级合规要求;
数据湖、数据仓库
3. 中间激活 / 临时显存用 vLLM/TGI 等优化引擎:按模型权重显存的 10% 估算即可,优化后的中间激活占用极低;用原生 HuggingFace/Transformers:按模型权重显存的 30% 估算,原生框架显存浪费严重。
1. Training Operator 调度分布式训练 / 微调任务,原生支持 PyTorch/TensorFlow 等框架,完美适配大模型多机多卡分布式训练;
Deployment Mode 部署模式StormService 支持两种部署模式:副本模式和池化模式。
2. 自动保存模型权重(含大模型 LoRA 权重)、训练代码、环境依赖,保证实验可复现;
二、LLM 大模型核心评估(现在主流)
Decentralized Network去中心化架构
Scatter(分发)
数据并行 DP:将训练数据均匀分割,分发至多个并行运行的GPU(Worker)上;每个GPU均持有完全相同的模型架构与参数副本,独立执行前向传播与反向传播,独立计算局部梯度;各Worker GPU通过节点间通信,采用All-Reduce机制,将本地梯度聚合至一个中心化GPU(Server);Server GPU对收拢的所有梯度执行求和或均值运算,生成全局梯度;Server GPU将全局梯度通过broadcast广播方式,同步回传至每一个Worker GPU,用于更新本地模型权重;更新完成后,所有Worker的模型参数实现严格一致。
场景 3:全参数监督微调(SFT)核心原则:数据质量优先于数量,步数由 Epoch 数决定,宁少勿多。工业界标准做法是只训 1~3 个 Epoch,绝对不会训超过 5 个 Epoch。1、定训练 Epoch 数:通用对话 SFT:1~2 个 Epoch,避免过拟合,保证泛化能力;垂直领域 SFT:2~3 个 Epoch,适配业务专属范式,不要超过 3 个;数据量极少的场景:最多 3 个 Epoch,优先提升数据质量,而非增加步数2、算单 Epoch 步数:先统计训练集总有效 Token 数,结合全局 Batch Size,算出单 Epoch 需要的步数。3、总步数 = Epoch 数 × 单 Epoch 步数。4、早停兜底:监控验证集 Loss、 Rouge/BLEU 等生成指标,若验证集 Loss 连续上升,立即早停,避免过拟合。示例:13B 模型做金融客服 SFT,高质量标注样本 5 万条,总 Token 数 5 亿;全局 Batch Size=256K Token,单 Epoch 步数 = 5 亿 ÷ 256K ≈ 1953 步,计划训 2 个 Epoch,总步数≈3900 步。
AIBrix云原生编排平台
2. 学习率
Warmup(预热):训练初期逐步提升学习率,避免初始梯度不稳定导致模型 “崩坏”。常见策略:线性 warmup(从 0 线性增长到目标学习率)、余弦 warmup(平滑增长);步数通常设为总训练步数的 1%-5%(如 2000-5000 步)。衰减策略:训练后期逐步降低学习率,帮助模型收敛。余弦退火(Cosine Annealing):大模型首选,学习率按余弦曲线从峰值平滑衰减到最小值(如 1e-5),符合 “快收敛 - 慢微调” 的规律;线性衰减:学习率线性下降,实现简单;常数衰减:固定学习率,仅适合小规模数据集或微调场景。
Prefix Tuning / Prompt Tuning / P-Tuning v2:核心概念:不更新模型权重,只在输入层 / Transformer 层新增可训练的前缀向量 / 软提示 Token,适配目标任务。架构师核心要点:显存成本极低,但效果弱于 LoRA 系列,泛化能力差,仅适合单一场景的简单任务适配,企业级复杂场景不优先推荐。其他轻量化 PEFT:IA3(Infused Adapter by Inhibiting and Amplifying Inner Activations)核心概念:通过对激活值做逐元素缩放,仅训练极少量参数,比 LoRA 参数量更少。架构师核心要点:训练成本更低,适合显存极度受限的场景,需了解其与 LoRA 的效果与场景差异。
Kubeflow 部署推理
LLM-Specific Autoscale:大模型专属自动扩展:支持实时、秒级扩展,利用KV缓存利用率和推理感知指标动态优化资源分配
4. API 网关 & 协议HTTP/gRPC/REST API兼容 OpenAI 接口规范流式输出(Stream)支持
ControllerRevision 控制器修订在Kubernetes生态系统中,ControllerRevision是一个关键的资源对象,用于记录控制器(如Deployment、StatefulSet等)的版本信息。在AIBrix项目中,采用ControllerRevision机制来跟踪StormService的版本变化,为版本管理、回滚操作和系统状态追溯提供了有力支持。
3. IPO / KTO / SLiC / ORPO 等新一代对齐方法这些都是 DPO 的改进版,目标都是:更稳、更强、更简单IPO(Iterative Preference Optimization)更稳定,抑制模式崩溃KTO(Kalman Filtering-based...):支持单点偏好,不一定非要成对ORPO(Odds Ratio Preference Optimization):把 SFT + DPO 合并一步训完,SFT + 对齐一步到位SLiC、SPIN:自迭代蒸馏类偏好对齐
最常见的曲线组合解读:1. 理想状态:正常收敛,Train Loss 和Val Loss两者最终差距很小(通常 < 10%)2. 过拟合(Overfitting)Val Loss 先下降,达到一个最低点后开始上升,Train Loss 持续下降,越来越低解决办法:1、早停;2、增加数据量或数据增强;3、正则化;4、降低模型复杂度或参数量;3. 欠拟合(Underfitting)Train Loss val Loss都很高,处于高位且平行下降解决办法:1、增加模型复杂度;2、延迟训练时间;3、调整超参数(增大学习率、batch size);4、减少正则化强度4. 数据泄露(Data Leakage):Train Loss 和 Val Loss 都非常低,且几乎重合,验证测试集结果很差;解决办法:1、重新划分数据集,避免训练与验证数据重复;2、去重处理

收藏
立即使用

收藏
立即使用
收藏
立即使用
收藏
立即使用

Collect
Get Started
Collect
Get Started

Collect
Get Started
Collect
Get Started
评论
0 条评论
下一页