• 模型健康状态实时探测:内置 TCP 层、HTTP 层、业务层三级健康检查机制,实时监测所有模型端点的可用性、延迟、错误率,同步上报给管控层;
1. Prompt 标准化管控
基于历史监控数据与执行日志,实现策略的自动优化与迭代: •
3. 流量准入与过载保护
3. 多维度分级限流策略
• 生产级落地细节: 1. 上下文智能压缩:与 Harness 记忆管理模块联动,自动对历史上下文、工具返回结果去重、过滤、压缩,仅保留与当前任务强相关的核心信息,可减少 30%-50% 的 Prompt Token 消耗; 2. 工具调用 Token 优化:Agent 高频工具调用场景中,仅注入与当前工具调用强相关的上下文,工具定义仅保留核心参数,去除冗余描述,大幅降低工具调用的固定 Token 消耗; 3. 多模态成本优化:自动执行图片压缩、分辨率自适应、关键帧提取,非必要场景不使用高分辨率模型,可降低多模态场景 70% 以上的成本; 4. 输出 Token 约束优化:在 Prompt 中明确约束输出长度与格式,设置合理的最大 Token 上限,杜绝无效的 Completion Token 消耗。
4. 告警与通知体系
• 生产级落地细节: 1. 异常识别:自动识别预算超支、Token 消耗突增、无效 Token 占比过高等异常情况; 2. 根因分析:基于全链路日志,定位异常根因(如业务逻辑漏洞、无效循环请求、路由规则不合理、模型滥用等); 3. 整改建议:针对根因输出可落地的整改方案,同步优化对应的管控规则。
• 针对不同类型的推理实例,配置独立的连接池参数(最大连接数、最小空闲连接数、连接超时时间、空闲连接回收时间),适配不同实例的性能特性;
推理池化管理
4. 配额与限流规则配置
3. 敏感信息过滤与数据安全管控
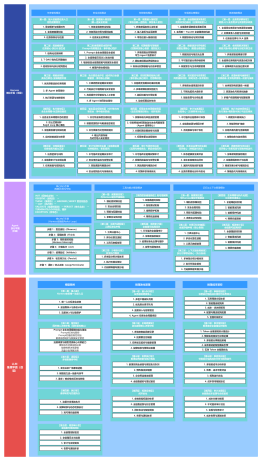
【第四层:审计治理层】全链路成本追溯与合规管控(合规保障)【层级核心定位】审计治理层是成本管控的合规保障层,满足企业级财务审计、合规管控要求,同时实现成本责任的清晰划分,形成完整的治理闭环。
2. 优先级分级子队列
• 核心职责:提前定义「任务复杂度→模型等级」的匹配规则,为事中智能路由提供决策依据,落地「简单任务用低成本小模型,复杂任务用高精度大模型」的核心降本逻辑。
• 实时接收执行层上报的模型健康状态、错误率、延迟数据,当主模型触发故障阈值(错误率 > 5%、连续探活失败、延迟超标),自动决策触发故障转移,将流量切换到备用模型;
• 队列容量管控:每个队列配置最大容量与最大排队时长,超过容量的请求直接触发降级(路由到低成本兜底模型)或返回友好提示,避免队列无限膨胀导致系统雪崩;
• 生产级落地细节: 1. 多维度成本分摊:按租户、业务线、部门、用户、项目维度,精准分摊推理成本,实现谁使用、谁承担; 2. 财务核算对接:支持导出符合企业财务要求的核算报表,对接 ERP、财务系统,实现成本的自动化核算; 3. 成本可视化:为每个业务线、部门提供专属的成本看板,清晰展示自身的成本消耗、预算剩余、降本效果。
• 熔断降级:当模型端点的错误率超过阈值时,自动熔断该端点,停止向其分发流量,避免故障扩散;极端场景下自动降级到本地兜底模型,保障核心业务不中断。
2. 全链路追踪与日志管理
• 预设多级故障转移规则,定义主模型、一级备用、二级备用、兜底模型的多级兜底链路;
• 支持模型的动态上下线,新增模型厂商 / 版本仅需新增适配插件,无需修改上层业务代码,实现无缝扩展。
• 生产级落地细节: 1. 合规审计:支持等保 2.0、GDPR、行业监管要求的合规审计,输出合规审计报表; 2. 财务审计:支持审计人员全权限追溯成本消耗的全链路数据,提供完整的审计凭证; 3. 内控管理:支持设置审计人员、管理员、业务人员的分级权限,实现权责分离。
1. 流量分发落地执行
• 支持 GPU 池化与切片:适配 NVIDIA MIG、阿里云 GPU 池化等技术,将物理 GPU 切分为多个逻辑切片,实现细粒度的算力分配与隔离,提升 GPU 资源利用率。
• 实时指标采集:实时采集实例的吞吐量、平均延迟、P99 延迟、错误率、GPU 显存占用、算力利用率、KV Cache 命中率等核心指标,同步至 Harness 可观测体系。
• 异常根因分析:自动识别队列堆积、延迟突增、错误率升高等异常情况,定位根因(如实例故障、流量突增、参数配置不合理),输出可落地的优化建议。
• 基于全局 TraceID,实现从请求入队→调度决策→批量聚合→实例执行→响应返回的全链路追踪,完整还原请求的整个生命周期;
• 核心职责:评估成本管控策略对业务效果的影响,确保降本不牺牲核心业务体验。
3. 流量分发策略决策
LLM 推理平面(底层)
• 极端场景降级:当所有主备实例都出现过载、故障时,自动执行降级策略,将低优先级请求调度到低成本兜底实例,暂停非核心业务,保障高优先级核心任务的算力资源。
5. 合规红线定义
• 模型预热能力: 1. 定时预热:基于业务流量的潮汐规律,在流量高峰到来前(如工作日早 8 点),定时启动实例,发送模拟业务请求,完成权重加载、显存初始化、推理引擎预热,让实例进入最佳工作状态; 2. 流量预测预热:基于历史流量数据,通过时序模型预测未来流量趋势,在流量增长前提前扩容并预热实例,应对突发流量洪峰; 3. 任务触发预热:与 Harness 任务管控模块联动,当检测到长任务、复杂任务、高优先级任务即将启动时,提前预热对应高能力模型实例,避免任务启动时的冷启动延迟; 4. 预热内容规范:采用覆盖模型核心能力(Function Call、多模态、长上下文)的真实业务请求作为预热内容,而非简单的空请求,确保模型所有组件都完成预热。
• 可用性指标监控:包括请求成功率、错误率、模型切换次数、故障转移次数、熔断次数;
2. Prompt 防篡改刚性校验
• 预设流量分发规则,包括:权重分发、灰度发布、A/B 测试、场景化智能路由;
• 核心职责:实现成本的精准分摊,对接企业财务核算体系。
• 内置主流模型厂商的原生协议全适配,同时兼容 OpenAI 兼容协议、开源模型本地部署协议,实现开箱即用的多模型支持;
• 连接池管理:内置模型实例的连接池,复用 TCP/HTTP2/gRPC 连接,避免每次请求建立新连接导致的延迟,配置独立的最大连接数、最小空闲连接数、空闲回收机制;
• 动态调优批量聚合参数:基于业务流量规律、请求类型,自动调整批量聚合的触发阈值,在吞吐量与延迟之间找到最佳平衡;
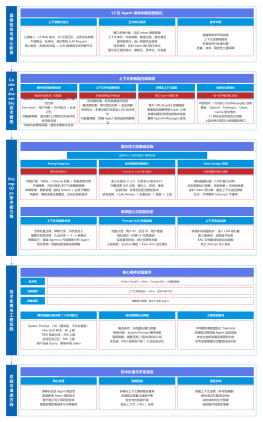
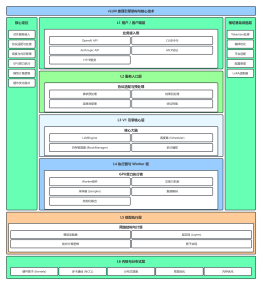
【第五层:观测审计层】全链路可观测闭环【层级核心定位】观测审计层是模型网关所有能力的可追溯、可优化支撑,与 Harness 可观测治理模块深度联动,实现模型调用全链路的 100% 可观测、可审计、可追溯、可优化。
• 三级健康探测机制: 1. TCP 层:检测实例端口连通性,秒级探测; 2. HTTP 层:检测接口状态码、服务可用性,10 秒级探测; 3. 业务层:发送标准化探活请求,检测模型推理的正确性、延迟、错误率,30 秒级探测;
• 实例恢复切回:当故障实例恢复健康后,按比例灰度将流量切回,避免流量突增导致实例再次故障;
• 场景化路由执行:按照管控层的智能路由决策,将请求精准分发到匹配的模型实例,实现简单任务到小模型、复杂任务到大模型的精准路由。
2. 智能路由规则库
• 多维度聚合触发机制,满足任一条件即触发批量聚合,平衡吞吐量与延迟: 1. 数量触发:聚合请求数达到预设阈值(如 8-32 条,根据 GPU 规格调整); 2. 时间触发:最大等待时长达到阈值(如 100-500ms),避免请求饥饿; 3. Token 窗口触发:聚合请求的总 Token 数达到模型的最优批量窗口(通常为模型上下文窗口的 30%-50%),最大化 Token 利用率;
【第二层:事中管控层】任务执行前的成本规则与边界定义(前置管控)【层级核心定位】事中管控层是推理成本管控的核心执行层,覆盖从请求发起、模型调用到结果返回的完整推理链路,严格遵循事前规划层的规则,实时执行 Token 计量、预算管控、限流、智能路由与无效 Token 优化,是实现降本目标的核心环节。
• 全链路 PII 与企业敏感数据识别脱敏:自动识别敏感信息,支持不可逆脱敏与格式保留加密(FPE)两种模式,彻底杜绝敏感数据泄露;
• 将管控层输出的标准化请求体,自动转换为目标模型原生 API 的请求格式,包括参数映射、消息体格式转换、模型特有参数适配;
• 模型元数据管理:内置模型注册中心,统一管理所有接入模型的元数据,包括厂商、版本、能力边界、上下文窗口上限、Token 计费规则、接口地址、鉴权方式,为管控层的调度决策提供数据支撑。
• 核心调度规则:高优先级队列有请求时,暂停低优先级队列的调度;紧急队列可直接抢占正在执行的低优先级任务的算力资源,保障核心任务零延迟响应;同时配置低优先级任务的最小资源保障,避免请求饥饿。
3. 审计与合规管控
• 弹性扩缩容联动:与 K8s、云厂商弹性服务联动,基于执行队列的长度、实例负载、流量预测,自动扩缩容实例副本数量,流量高峰时自动扩容,低峰时自动缩容,平衡性能与成本;
【第四层:执行层】请求转发与兜底执行【层级核心定位】执行层是管控层决策的最终落地执行单元,核心目标是按照管控层的决策指令,完成请求的最终转发、负载均衡、故障转移执行、兜底处理,保障模型调用的高可用、高可靠。
1. 唯一入口标准化封装
2. 故障转移与动态切换执行
• 核心职责:基于事前规划的配额规则与实时预算消耗情况,执行多维度流量管控,避免异常流量、无效请求导致的成本暴增。
2. 不可篡改审计日志
低优先级:成本优先,强制降级到低成本模型,严格管控预算,适用于批量数据处理、非紧急离线任务、测试场景
3. 合规与财务审计
• 故障摘除:当实例触发故障阈值(连续 3 次探活失败、错误率 > 5%、P99 延迟超标 3 倍),立即将其从调度池中摘除,停止分发新请求;
• 决策新模型版本的灰度流量比例、按用户 / 业务线的分流规则、按任务类型的智能路由策略;
1. 推理实例全纳管与绑定执行队列
提升推理吞吐量、GPU 利用率的核心能力,基于连续批处理(Continuous Batching)技术,将多个单请求聚合成最优批量请求,最大化利用模型的上下文窗口与 GPU 算力
• 实例保活能力: 1. 连接池保活:内置长连接池,复用 HTTP/2、gRPC 长连接,配置最小空闲连接数,避免连接频繁创建销毁导致的延迟; 2. 探活保活请求:定期向空闲实例发送轻量级探活保活请求,保持实例的热状态,避免模型因长时间空闲卸载权重、释放显存,导致后续请求冷启动; 3. 会话保持:针对支持会话上下文的模型,保持与实例的会话连接,避免每次请求重新初始化会话,降低多轮对话的延迟。
• 每个队列组配置独立的容量上限、QPS 配额、算力资源配额、最大排队时长,支持按日 / 月重置,适配企业多部门、SaaS 多客户的管理架构;
• 内置连接健康检测机制,自动剔除失效连接,新建健康连接,保障请求的成功率;
• 批量响应拆分与路由:模型返回批量响应后,自动按原始请求的 TraceID 精准拆分,路由回对应的 Agent 任务,同时记录每个请求的 Token 消耗、延迟数据,上报至观测层。
1. 成本分摊与核算
一、Prompt 全生命周期管控能力落地
1. Token 全维度精准计量统计
• 支持长任务的队列挂起 / 恢复:当 Agent 任务因工具调用、人工介入暂停时,自动挂起对应队列中的请求,任务恢复后自动唤醒,避免无效排队;
3. 请求 / 响应格式标准化转换
【第三层:事后优化层】任务执行后的成本分析与规则迭代(闭环优化)【层级核心定位】事后优化层是成本管控的闭环优化载体,与 Harness 可观测治理模块深度联动,基于全量历史执行数据,完成成本分析、效果评估、规则迭代与异常根因定位,实现成本管控体系的持续优化,越用越省、越用越精准。
2. 故障转移决策逻辑
高优先级:效果优先,不限制成本,仅做异常消耗拦截,适用于核心生产业务、紧急故障处理、高合规要求任务
• 数据出境合规管控:内置地域路由规则,可配置敏感数据仅能发送到国内部署的模型端点,禁止发送到境外模型,解决数据出境合规风险。
• 核心职责:全面复盘成本消耗情况,精准定位高消耗环节与降本空间。
• 内置全局流量过载保护,当请求量超过网关处理阈值时,自动触发请求排队与限流,避免网关雪崩
• 支持连接池监控,实时采集连接数、空闲连接数、等待连接数、连接创建失败率等指标,同步至观测层。
基于实例健康状态,自动执行故障转移与降级决策,保障推理服务的高可用
4. 成本异常根因定位
• Token 感知调度:基于请求的预估 Token 长度,分配对应算力规格的实例,避免长请求阻塞小实例、短请求浪费大实例算力的问题。
二、流量调度与模型切换核心决策能力
• 支持通过 TraceID、任务 ID、用户 ID、模型版本、时间范围等多维度快速检索日志,实现执行过程的 100% 复现。
• 核心职责:严格遵循事前规划的路由规则,实现「简单任务用低成本小模型,复杂任务用高精度大模型」的精准匹配,在保障效果的前提下最大化降低成本,仅这一项能力即可降低 30%-60% 的推理成本。
推理成本管控
4. 成本驱动的智能路由引擎
• 对不同模型的核心能力进行统一抽象,包括:Function Call / 工具调用、多模态理解、结构化输出、流式输出、长上下文、JSON 模式等,抹平不同厂商的能力实现差异;
• 生产级落地细节: 1. 预算分配优化:基于历史成本消耗与业务价值,优化五级预算的分配比例,向高价值业务倾斜; 2. 路由规则优化:基于效果回检数据,优化任务复杂度 - 模型映射规则,提升路由准确率与降本效果; 3. 复杂度评估模型迭代:基于历史执行数据,迭代任务复杂度预评估模型,提升评估准确率; 4. 限流策略优化:基于业务流量规律,优化配额与限流规则,平衡业务体验与成本管控。
• 能力自动降级适配:当目标模型不支持某项能力时,自动执行适配降级,比如模型不支持原生 Function Call 时,自动通过 Prompt 工程实现工具调用能力,保障上层业务逻辑的一致性;
• 核心职责:定位预算超支、异常成本消耗的根因,输出整改方案,避免同类问题重复发生。
• 全量记录每一次请求的调度过程、批量聚合情况、实例分配、执行状态、耗时、Token 消耗、错误信息,日志采用分布式存储,写入后不可篡改、不可删除,永久归档;
2. 效果 - 成本平衡评估
• 采用「固定模板 + 动态变量」的标准化结构,锁死不可修改的系统规则、安全要求、交付规范,仅开放预设的动态变量位给 Agent 注入业务内容
• 预设多维度动态切换规则,包括:任务复杂度驱动切换、预算消耗驱动切换、任务阶段驱动切换、SLA 要求驱动切换;
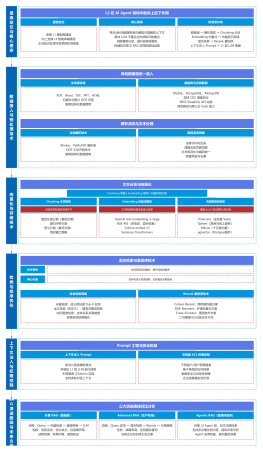
【第一层:接入队列层】与Harness模型网关管控层联动(业务感知调度核心)【层级核心定位】接入队列层是推理池化管理的唯一请求入口,与 Harness 模型网关管控层无缝对接,核心是实现业务感知的请求分类、隔离与准入,而非简单的 FIFO 排队。它终结了不同优先级、不同租户、不同生命周期的请求混排导致的「高优先级任务被阻塞、单租户流量冲击全平台、长任务饥饿」等生产级问题。
3. 企业级连接池管理
• 核心职责:明确成本管控的不可突破红线,安全合规永远优先于成本降低,避免为了降本产生合规风险。
• 典型规则示例:长任务前期规划用高精度大模型,中期执行用性价比模型,后期校验用大模型;预算消耗超过阈值时,自动切换到低成本模型;
【第一层:接入层】Harness体系唯一法定入口【层级核心定位】接入层是 Harness 体系内所有 LLM 推理请求的唯一法定入口,彻底终结 Agent 业务直连多模型 API 的碎片化架构,实现「一次接入,调用全量模型」的核心目标,同时完成请求的准入校验与全链路生命周期绑定。
1. 全维度指标监控体系
• 模型动态切换执行:严格按照管控层的动态切换规则,将请求分发到切换后的目标模型,同时保持会话上下文的一致性,实现任务执行过程中的无感知模型切换;
• 决策简单任务路由到低成本小模型,复杂任务路由到高精度大模型,实现效果与成本的平衡。
• 性能指标监控:包括平均延迟、P95/P99 延迟、首 Token 延迟、吞吐量、流量分发占比;
• 合规审计报表:支持生成日 / 月 / 季合规审计报表,包括敏感数据处理情况、违规请求拦截情况、数据出境管控情况;
覆盖队列、调度、实例、成本四大维度的核心指标,提供实时监控大盘、多维度查询、自定义看板,核心指标包括: • 队列指标:队列长度、平均排队等待时长、请求拒绝率、优先级调度占比、租户配额使用率; • 性能指标:平均延迟、P95/P99 延迟、首 Token 延迟、吞吐量、批量聚合率、平均批量大小、Token 吞吐率; • 资源指标:GPU 算力利用率、显存占用、实例在线率、扩缩容事件数、KV Cache 命中率; • 可用性指标:请求成功率、错误率、故障转移次数、熔断次数、重试成功率; • 成本指标:Token 利用率、算力资源浪费率、实例运行时长、单请求平均成本。
【第一层:事前规划层】任务执行前的成本规则与边界定义(前置管控)【层级核心定位】事前规划层是成本管控的前置防线,与 Harness 任务管控、权限管控模块深度联动,在 Agent 任务执行前,提前定义成本管控的所有规则、边界、预算与策略,从源头锁定成本上限,避免事中无规则管控、事后预算超支。所有规则一经配置,事中执行层严格遵循,不可被 Agent 自主修改。
• 核心职责:基于任务优先级,明确差异化的成本管控策略,平衡核心业务效果与整体成本控制,避免一刀切降本影响核心业务 SLA。
• 连接超时:网关与实例建立连接的最大等待时间,典型配置 1-3s,超时后自动重试下一个健康实例;
• 请求的身份认证、权限校验、会话绑定授权的 Agent 实例、用户、业务线可发起模型调用请求;
• 模型能力匹配调度:基于请求的模型要求、能力需求(Function Call、多模态、长上下文、代码生成),精准调度到对应能力的实例组,避免能力不匹配导致的推理失败;
• 生产级落地细节: 1. 主体配额:为每个租户、业务线、用户配置独立的日 / 月请求配额、QPS 上限; 2. 模型配额:为高成本大模型配置独立的调用配额与 QPS 上限,避免大量请求集中到高成本模型; 3. 异常限流规则:提前定义高频重复请求、无效循环请求、恶意刷 Token 请求的识别规则与拦截策略。
• 每个请求绑定全局唯一 TraceID、Agent 任务 ID、任务阶段、生命周期状态,实现请求与 Agent 任务的强关联;
• 生产级落地细节: 1. 预算层级划分:按「全局平台级→租户级→业务线级→单任务级→Agent 实例级」五级分配,适配企业多部门、多业务线、SaaS 多租户的管理架构; 2. 预算配置规则:支持手动分配、自动按比例分配、按日 / 月 / 季周期自动重置,同时支持预算池共享、上下级预算灵活调配; 3. 四档阈值预设:为每一级预算提前设置「预警(80%)→限流(90%)→降级(95%)→熔断(100%)」触发阈值,明确每一档的处置动作,事中自动执行。
• 生产级落地细节: 1. 效果达标率统计:统计智能路由的整体效果达标率、分任务类型达标率、分模型达标率; 2. 投入产出比评估:评估不同模型、不同业务线的成本投入与业务价值产出比,为模型选型、预算分配提供数据支撑; 3. 业务影响分析:定位因成本管控导致的业务效果下降、用户投诉等问题,输出优化方案。
• 提示词注入攻击全量检测:内置多层级注入攻击识别引擎,对用户输入、动态变量、工具返回结果进行全量扫描,拦截包含「忽略系统提示词、修改 Agent 规则、越权操作」等注入指令的请求,覆盖嵌套式、隐式、编码式的注入攻击;
• 智能重试机制: 1. 仅对可重试异常(连接超时、5xx 服务器错误、实例临时不可用)执行重试,对参数错误、权限不足、内容违规等不可重试异常,直接返回失败; 2. 采用指数退避算法,每次重试的等待时间递增,避免重试风暴导致实例压力过大; 3. 重试时优先调度到不同的健康实例,避免在同一个故障实例上重复重试,提升重试成功率; 4. 配置最大重试次数(典型 3 次),超过次数后触发故障转移或降级兜底。
• 生产级落地细节: 1. 全量日志记录:记录每一次模型请求的 TraceID、请求内容、Token 消耗、路由切换、预算扣减、管控动作、响应结果; 2. 不可篡改设计:日志采用分布式存储,写入后不可修改、不可删除,永久归档; 3. 全链路追溯:支持通过 TraceID、用户 ID、任务 ID、时间范围,快速追溯单次请求的全链路成本消耗与管控动作。
• 生产级落地细节: 1. 基础映射规则:预设任务复杂度等级(S/A/B/C/D 级)与模型等级的标准映射 2. 强制合规规则:定义敏感数据、高合规要求任务的强制路由规则。 3. Agent 场景定制规则:支持长任务混合路由(规划 / 校验用大模型,执行用小模型)、长上下文分片路由、阶梯式降级路由等,适配 Agent 多轮循环、长任务等复杂场景; 4. 白名单机制:预设核心业务、高优先级任务的路由白名单,白名单内任务不执行成本优化策略,优先保障效果。
5. 无效 Token 全链路优化
• 核心职责:实现 Token 消耗的 100% 精准、无死角计量,是所有成本管控动作的基础底座。
• 原生支持 HTTP/2、gRPC 长连接复用,大幅降低 TCP 连接建立的握手延迟与系统开销;
• 开源模型适配:覆盖 Llama 系列、Qwen 系列、等本地 / 私有化部署模型,兼容 vLLM、TensorRT-LLM 等主流推理框架的 API 协议;
1. 多租户隔离队列组
模型网关
【第四层:观测反馈层】与Harness可观测体系联动(闭环优化)【层级核心定位】观测反馈层是推理池化管理的闭环优化载体,与 Harness 全局可观测治理模块深度联动,实现推理全链路的100% 可观测、可追溯、可审计、可优化。通过全维度数据采集与分析,反向优化调度策略、批量参数、扩缩容规则,形成持续优化的闭环。
1. 全链路指标监控
• 决策主模型恢复健康后,是否自动切回、按比例灰度切回,保障执行效果的一致性。
• 自动优化调度策略:基于历史延迟、成功率数据,优化优先级调度、负载均衡规则,降低尾延迟,提升整体吞吐量;
• 故障转移无感知执行:当管控层触发故障转移决策后,自动将后续流量无感知切换到备用模型端点,已失败的请求按照重试策略自动转发到新的模型端点,上层业务无感知;
• 背压机制:当下游实例负载过高、队列堆积超过阈值时,主动降低入口流量速率,实现流量自平衡,保护推理实例不被打垮;
• 多渠道通知:支持邮件、企业微信、钉钉、短信等多渠道告警推送,按告警等级推送给对应的负责人;
• 总请求超时:从发送请求到收到完整响应的最大等待时间,根据任务复杂度配置 30-120s,超时后取消请求,触发 Harness 任务重试或回滚策略;
• 自动故障转移:按照预设的多级兜底链路,将故障实例的存量请求、新请求,无感知调度到备用健康实例组,上层业务无感知;
• 核心职责:基于历史数据,持续优化事前规划层的所有规则,形成闭环优化。
• 核心职责:基于事前规划的预算体系与阈值,实时监控预算消耗进度,触发阈值后自动执行对应的管控动作,实现预算的刚性可控,彻底杜绝预算超支。
• 全类型实例统一纳管,实现一套架构管控所有推理资源: 1. 闭源商用模型:OpenAI、Anthropic、通义千问等厂商的 API 端点,支持多账号、多 Key 的池化管理; 2. 私有化部署模型:基于 vLLM、TensorRT-LLM 部署的开源模型实例,支持单机多卡、多机分布式部署; 3. 边缘 / 本地模型:端侧部署的轻量模型、本地 CPU 推理实例; 4. Serverless 推理服务:云厂商 Serverless 推理实例、弹性推理服务;
1. 全协议多厂商兼容适配
• 提供实时监控大盘、多维度指标查询、自定义看板,支持实时告警配置。
• 核心职责:实现预算风险、异常消耗的实时通知,提前规避成本风险。
【第二层:全局调度层】池化管理核心决策中枢【层级核心定位】全局调度层是推理池化管理的「大脑」,是所有调度决策的核心中枢。它基于接入队列的请求、实例执行层的健康状态、Harness 管控层的规则,执行智能调度、批量聚合、故障转移决策,是提升吞吐量、保障高可用、平衡成本与效果的核心环节。
• 灰度发布与 A/B 测试执行:严格按照管控层的灰度规则,将指定比例、指定范围的流量分发到目标模型版本,实现无缝灰度上线;
3. 规则迭代优化
• 核心职责:满足企业内控、监管合规、财务审计的要求。
• 前置基础流量过滤,拦截非法请求、格式错误请求、无权限请求,避免无效请求进入后续处理链路
• 操作审计:记录所有规则配置、模型上下线、权限变更的操作日志,实现权责分离、操作可追溯。
3. 成本 - 优先级矩阵
2. 批量聚合控制器
• 基于全局 TraceID,实现从请求接入→管控层处理→适配层转换→执行层转发→模型响应→结果返回的全链路日志追踪;
4. 成本告警与通知体系
• 异常格式统一封装:抹平不同厂商的错误码、异常信息差异,向上层输出标准化的异常类型与处理建议,避免上层业务适配多套异常处理逻辑。
• 核心职责:从根源上减少不必要的 Token 消耗,进一步放大降本效果,解决 Agent 场景中高频出现的上下文冗余、工具调用 Token 浪费等问题。
• 生产级落地细节: 1. 多渠道通知:支持邮件、企业微信、钉钉、短信等多渠道告警; 2. 分级告警:按风险等级(预警、一般、严重、紧急),推送给对应的负责人; 3. 自定义告警规则:支持用户自定义告警触发条件,适配不同业务的管控需求。
• 告警联动处置:支持告警触发后自动执行故障转移、熔断、扩缩容等处置动作,实现故障的自动化闭环处理,减少人工介入成本。
• 不可篡改审计日志:所有模型调用行为、管控动作、路由切换、安全拦截操作,全部写入不可篡改的审计系统,满足企业内控、等保 2.0、行业监管的审计要求;
• 每个租户队列组下,拆分「紧急 > 高 > 中 > 低」四级优先级子队列,与 Harness 任务管控模块联动,实现 Agent 任务全生命周期的优先级动态调度: • 紧急队列:核心生产故障处理、合规审计、高 SLA 保障的 VIP 任务,支持绝对抢占式调度; • 高优先级队列:核心业务长任务、复杂推理任务、多轮 Agent 执行任务; • 中优先级队列:常规对话、基础文案生成、通用 RAG 查询任务; • 低优先级队列:离线批量数据处理、非紧急任务、测试场景;
• 针对金融、医疗等强合规场景,支持队列与物理实例、GPU 切片的硬绑定,实现租户间的物理隔离,满足合规要求。
• 生产级落地细节: 1. 预算驱动限流:主体预算消耗越接近阈值,限流幅度越大,从根源上控制成本增速; 2. 优先级分级限流:预算紧张时,优先限流低优先级任务,中优先级任务适度限流,高优先级核心任务不受影响; 3. 主体配额限流:严格执行事前配置的主体 QPS 与请求配额,超配额请求直接拦截; 4. 异常防刷限流:自动识别高频重复请求、无效循环请求、恶意刷 Token 请求,触发后直接拦截; 5. 模型级限流:严格执行高成本大模型的调用配额,超配额请求自动降级到低成本模型。
与 Harness 模型网关的超时策略联动,实现三级超时控制,避免请求无限等待、无效占用资源:
2. 全链路准入与身份认证
• 实例分组与绑定队列:按模型类型、版本、能力、租户归属,将实例划分为不同实例组,每个实例组绑定独立的执行队列,调度层将批量请求分发到对应执行队列,按顺序执行,避免单实例请求堆积;
• 优化扩缩容与预热策略:基于流量预测与历史负载数据,优化弹性扩缩容的触发阈值、定时预热的时间窗口,提升资源利用率,降低算力成本;
• 合规内容过滤:内置涉政、涉黄、涉暴、违法违规内容检测,过滤 Prompt 中的违规内容,避免触发模型厂商的合规限制,同时满足企业内控要求;
• 闭源商用模型适配:覆盖 OpenAI 全系列、Anthropic Claude 全系列• 等主流厂商的全版本 API;
• 故障恢复切回执行:当主模型端点恢复健康后,按照管控层的决策,自动 / 手动按比例将流量切回主模型,保障执行效果的一致性。
• 前置流量过滤:拦截格式错误、无权限、超配额、预算耗尽的请求,避免无效请求进入队列占用资源;
2. 预热保活控制器
1. 多维度智能调度引擎
• 支持通过 TraceID、任务 ID、租户 ID、实例 ID、时间范围等多维度快速检索日志,实现问题的快速定位、根因分析与执行过程复现。
3. 高可用兜底保障
• 实例状态标签体系:基于探测结果,为每个实例打上「健康 / 亚健康 / 故障 / 离线」标签,只有健康实例会进入调度池;
实时采集所有纳管推理实例的全维度状态数据,为调度决策提供精准的数据支撑
1. 五级预算分配体系
【第二层:管控层】网关核心决策中枢(刚性管控核心)【层级核心定位】管控层是模型网关的大脑,是所有刚性管控规则的执行中枢,核心落地两大能力:一是Prompt 全生命周期的标准化、防篡改、敏感信息过滤;二是模型动态切换、故障转移、流量分发的核心决策,所有请求必须经过管控层的校验与决策后,才能进入后续链路。
2. 全链路日志与追踪
• 成本与安全指标:包括总 Token 消耗、分模型 / 分业务线 Token 消耗、拦截的注入攻击次数、敏感信息过滤次数;
• 内置上下文标准化与智能压缩能力,自动对历史对话、工具返回结果进行格式统一、去重、过滤,避免无效信息占用上下文窗口,解决上下文腐烂问题;
• 优先级优先调度:严格遵循「紧急 > 高 > 中 > 低」的优先级顺序,优先调度高优先级队列的请求,紧急队列支持抢占式调度;
• 多维度告警规则:支持模型故障、错误率超标、延迟超标、预算超支、安全攻击、异常流量等多维度告警;
• 生产级落地细节: 1. 实时进度同步:每一次 Token 消耗后,实时更新五级预算的消耗进度,毫秒级同步到管控中枢; 2. 分级处置自动执行:严格遵循事前预设的四档阈值执行管控: • 预警阈值(80%):向管理员、业务负责人发送多渠道告警,提前预警预算风险; • 限流阈值(90%):自动对该主体下的低优先级任务执行限流,缩减 QPS 配额; • 降级阈值(95%):自动执行成本降级策略,非核心任务路由到更低成本模型,关闭非必要高消耗功能; • 熔断阈值(100%):自动熔断非核心任务,仅保留白名单内的高优先级核心任务,彻底杜绝预算超支。
• 系统 Prompt 哈希锁死机制:• Harness 安全模块生成的系统 Prompt,写入网关只读存储并生成唯一哈希摘要;每一次请求的系统 Prompt,都会先进行哈希校验,与预设摘要不一致的直接拦截拒绝
【第三层:适配层】多模型兼容中枢【层级核心定位】适配层是模型网关的「翻译官」,核心目标是抹平不同模型厂商、不同版本、不同部署形态的 API 协议、能力边界、参数格式差异,实现上层业务的无感知兼容,是「一次接入,全模型调用」的核心支撑。
• 超时控制:内置连接超时、首 Token 超时、总请求超时的三级超时控制,避免请求无限等待;
• 生产级落地细节:明确禁止为了降本绕过安全合规校验、禁止将敏感数据路由到境外模型、禁止为了降本牺牲核心业务 SLA 等红线规则,事中执行层严格遵循。
• 核心职责:提前配置全维度的流量与调用配额,为事中限流策略提供执行依据,避免异常流量、无效请求导致的成本暴增。
• 核心职责:建立从平台到单任务的全层级预算管控体系,实现成本的精细化分配与刚性约束,彻底杜绝预算超支。
• 将目标模型返回的原生响应体,自动转换为网关统一的标准化响应格式,包括文本内容、工具调用指令、Token 消耗统计、Finish Reason、错误信息的统一封装;
• 内置 Prompt 模板管理中心:统一管理全局规则 Prompt、任务级系统 Prompt、工具级 Prompt,实现模板的版本控制、灰度发布、只读锁定;
• 智能重试机制:仅对连接超时、5xx 服务器错误等可重试异常执行重试,采用指数退避算法,重试时优先选择不同的模型实例,避免重试风暴;
3. 流量准入与容量管控
• 按照管控层的流量分发策略,执行多维度负载均衡,包括轮询、权重、一致性哈希、就近路由等策略,实现多模型端点的流量均匀分发;
2. 预算实时管控与分级处置
摒弃单纯的轮询、FIFO 调度,采用业务感知 + 资源感知的多维度调度策略
• 所有切换规则事前预设,事中自动执行,对上层 Agent 业务完全透明,无需修改任何业务逻辑。
• 全量记录每一次请求的 Prompt、模型参数、路由决策、模型切换记录、故障转移日志、模型响应、Token 消耗、处理结果,日志不可篡改,永久归档;
• 多维度告警规则:支持实例故障、错误率超标、延迟突增、队列堆积、资源不足、预算超支、安全攻击等多维度告警,支持自定义告警阈值与触发条件;
• 强制注入标准化的输出格式要求,保障模型返回结果的格式一致性,降低上层 Agent 的解析失败率。
4. 全链路超时与重试管控
• 为每个租户、业务线、部门配置独立的专属队列组,与 Harness 权限管控模块深度联动,实现租户间的资源、流量、故障完全隔离,避免单租户的流量洪峰、异常请求影响其他租户;
• 封装标准化的请求 / 响应格式无需关心底层模型的厂商、版本、API 协议差异
• 暴露统一的 RESTful API、gRPC 接口与 SDK所有 Agent 的模型调用请求必须 100% 通过该入口提交
• 支持任务取消联动:当 Agent 任务终止、取消时,自动清理队列中对应的所有请求,释放算力资源,杜绝「幽灵流量」占用资源。
4. Agent 任务生命周期绑定
1. 多维度成本分析体系
中优先级:效果与成本平衡,优先执行智能路由降本,适用于常规业务任务、通用对话、基础文案生成
• 告警联动:支持告警触发后自动执行故障转移、熔断降级等处置动作,实现故障的自动化闭环处理。
2. 模型能力统一抽象与抹平
• 生产级落地细节: 1. 前置任务复杂度预评估:请求发送前,用轻量级低成本小模型在 100ms 内完成任务复杂度评估,从任务类型、逻辑复杂度、专业要求、上下文要求四个维度,输出任务复杂度等级,几乎不增加额外成本与延迟; 2. 智能路由执行:基于复杂度评估结果,匹配事前规则库中「效果达标、成本最低」的最优模型,无感知完成路由切换,对上层 Agent 业务完全透明; 3. 效果回检闭环(不牺牲效果的核心保障):模型返回结果后,自动执行目标对齐、准确性、格式合规、安全合规多维度校验,校验不通过的请求,自动路由到更高一级模型重新推理,确保业务效果不打折; 4. Agent 场景定制路由:针对 Agent 长任务,自动执行混合路由 —— 任务拆解规划与最终交付校验用高精度大模型,中间执行步骤用性价比小模型,可降低长任务 50%-70% 的成本; 5. 实时参数优化:路由到对应模型的同时,自动匹配最优推理参数(温度、最大 Token 上限),避免模型输出冗余内容,进一步降低 Token 消耗。
• 生产级落地细节: 1. 多维度成本报表:按主体、链路、功能、模型、时间维度,生成日 / 月 / 季成本报表,清晰展示成本分布、消耗趋势、降本效果; 2. 降本效果量化:精准统计智能路由、无效 Token 优化等策略带来的成本降低金额、降本比例、Token 节省量; 3. 消耗 TOP 排行:输出高消耗租户、业务线、任务、模型的 TOP 排行,精准定位核心成本消耗点。
• 核心职责:全链路记录成本管控的所有动作,实现 100% 可追溯、可复现。
3. 闭环优化与智能调优
【第三层:实例执行层】推理实例纳管与执行落地【层级核心定位】实例执行层是调度决策的最终落地单元,是推理算力的最终载体。核心目标是统一纳管全类型异构推理实例,实现实例的预热保活、连接复用、超时重试、容错兜底,保障推理请求的稳定、低延迟执行,同时与 K8s 等云原生平台联动,实现弹性扩缩容。
• 首 Token 超时:发送请求后,收到模型第一个 Token 的最大等待时间,典型配置 5-15s,超时后取消当前请求,重试备用实例;
3. 实例状态监控与健康管理
1. 模型动态切换规则决策
4. 故障转移与降级决策器
• 资源感知调度:实时采集实例的 GPU 显存占用、负载、排队长度、延迟数据,将请求调度到负载最低、延迟最小的健康实例,避免单实例过载,平衡整体负载;
• 公平调度:基于租户的算力配额、预算消耗,公平分配调度资源,避免单租户占用全部算力,保障所有租户的基础 SLA;
• 预算绑定管控:与 Harness 成本管控模块联动,实时同步租户 / 业务线的预算消耗进度,预算达到限流 / 熔断阈值时,自动对对应队列执行限流、降级、熔断操作,从源头控制成本增速。
• 批量请求标准化封装: 1. 闭源商用模型:原生适配厂商 Batch API,实现官方标准批量处理; 2. 开源私有化模型:适配 vLLM、TensorRT-LLM 等推理框架的连续批处理接口,支持预填充(Prefill)与解码(Decoding)阶段的分离调度,匹配两个阶段不同的算力需求特征,进一步提升效率; 3. 无原生批量能力的模型:实现伪批量封装,将多个请求的 Prompt 标准化拼接,模型返回后自动拆分响应,对上层业务完全透明;
• 动态变量白名单校验:严格校验动态变量的内容范围,仅允许注入预设白名单内的业务内容,禁止注入包含系统指令、规则修改的内容,从根源上避免变量注入导致的 Prompt 篡改。