AI
推荐
模板社区
专题
登录
免费注册
首页
流程图
详情
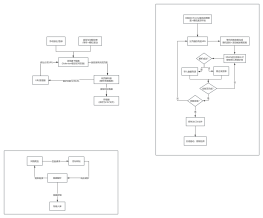
动态网页爬虫数据采集流程
2026-04-18 22:50:08
0
举报
分享方式
仅支持查看
动态网页爬虫数据采集流程
其他岗位
模板推荐
作者其他创作
大纲/内容
网络爬虫
当前页完成?
渲染与加载处理(等待+模拟滚动)
发起请求
数据存储
存入数据列表
取出分页URL
手动验证/登录
否
网页解析器(解析房源数据)
数据解析
解析成功?
解析到新分页URL
关闭驱动,爬取结束
响应请求
浏览器下载器(Selenium驱动访问页面)
存储器(保存为CSV文件)
是
提取目标数据
页数足够?
提取链接
保存为CSV文件
等待页面加载完成随机延时+滚动触发懒加载
目标网站
存储入库
初始化Chrome驱动反爬配置+模拟真实环境
分页遍历构造URL
URL管理器
返回渲染完成页面
跳过该房源
XPath定位房源卡片提取核心房源字段
收藏
立即使用
动态网页爬虫数据采集流程
PO_vz78mJ
职业:暂无
去主页
Collect
Get Started
1:1联系
Collect
Get Started
对账流程1
Collect
Get Started
人工费支付流程1
Collect
Get Started
申请流程1
评论
0
条评论
下一页
Document