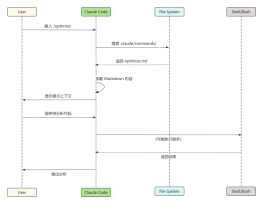
常见错误
只列了几个显而易见的危险模块(比如 os、sys),<br>但漏掉了很多隐蔽的攻击面
允许的模块(白名单)
ALLOWED_MODULES = {
'pandas', # 数据处理,读取 DataFrame,基础统计
'numpy', # 数值计算,矩阵运算
'matplotlib', # 可视化,生成图表
'seaborn', # 高级可视化(基于 matplotlib)
'json', # JSON 数据格式处理
'math', # 基础数学函数
'statistics', # 统计函数(均值、方差等)
'datetime', # 日期时间处理(财务数据经常需要)
'collections' # Counter、defaultdict 等工具类
}
禁止的模块和函数(黑名单)
FORBIDDEN_MODULES = {<br> 'os', # 系统操作,可以执行 shell 命令<br> 'sys', # 系统模块,可以修改 Python 运行时<br> 'subprocess', # 子进程,可以执行任意系统命令<br> 'socket', # 网络 socket,可以建立任意网络连接<br> 'requests', # HTTP 请求,可以外传数据<br> 'urllib', # URL 处理,同上<br> 'http', # HTTP 库<br> 'ftplib', # FTP,文件传输<br> 'smtplib', # 邮件发送,可以泄露数据<br> 'pickle', # 反序列化,存在代码执行漏洞<br> 'shelve', # 基于 pickle,同上<br> 'ctypes', # 调用 C 库,可以绕过 Python 层限制<br> 'cffi', # 同上<br> 'importlib', # 动态 import,可以绕过模块白名单<br> 'builtins', # 内置模块,可以重新访问被屏蔽的函数<br>}<br><br><br>
FORBIDDEN_BUILTINS = {
'exec', # 动态代码执行
'eval', # 表达式求值(同样危险)
'compile', # 编译代码对象
'open', # 文件 IO
'__import__', # 动态 import
'vars', # 访问对象变量字典,可以探测内部状态
'globals', # 访问全局变量
'locals', # 访问局部变量
'dir', # 列出对象属性,辅助攻击者探测
'getattr', # 属性访问,可以绕过一些限制
'setattr', # 属性设置
'delattr', # 属性删除
}
静态扫描的危险模式
除了模块和函数黑名单,我们还对代码字符串做正则扫描,检测一些特定的攻击模式:
import re
DANGEROUS_PATTERNS = [
r'__class__', # 对象继承链遍历
r'__bases__', # 基类访问
r'__subclasses__', # 子类枚举,Python 沙箱逃逸的常见手段
r'__globals__', # 全局变量访问
r'__builtins__', # 内置函数访问
r'__code__', # 函数代码对象
r'__dict__', # 对象字典
r'chr\(\s*\d+\s*\)', # chr() 可以用来构造被过滤的字符串
r'\\x[0-9a-fA-F]{2}', # 十六进制转义,绕过字符串过滤
r'exec\s*\(', # exec 调用
r'eval\s*\(', # eval 调用
r'open\s*\(', # open 调用
r'import\s+os', # os 模块 import
r'import\s+sys', # sys 模块 import
r'import\s+subprocess' # subprocess import
]
def static_security_check(code: str) -> tuple[bool, str]:
"""静态安全检查,返回 (is_safe, reason)"""
for pattern in DANGEROUS_PATTERNS:
if re.search(pattern, code):
return False, f"检测到危险模式: {pattern}"
return True, ""
chr(111) + chr(115) 可以构造出字符串 "os",然后通过 __import__() 加载 os 模块,绕过简单的字符串匹配。所以我们专门加了 chr() 调用的检测规则。