
智能体开发框架总览
2026-06-27 00:25:27 0 举报AI智能生成
Python智能体开发相关概念及总览
AI
智能体
Python
模板推荐
作者其他创作
大纲/内容
AgentScope 2.0 智能体框架思维导图(2026-06-26)
<b>注意</b>:本文档代码示例基于 AgentScope 2.0 官方文档和公开资料整理。由于框架 API 仍在持续演进,实际使用时请参考官方文档确认最新的 API 签名和用法。
一、AgentScope 2.0 基础概念
1. 什么是 AgentScope
AgentScope 是阿里通义实验室开源的 AI 智能体应用开发框架
帮助开发者完成从大模型到智能体的构建与部署
AgentScope 2.0 是架构级重写,从"透明开发的实验框架"升级为"生产就绪的智能体工程底座"
2. AgentScope 2.0 的核心价值
稳定运行
解决长链路断裂问题
支持重试与备用模型机制
确保任务执行的连续性
安全控制
三级权限控制(allow/deny/confirm)
工具调用行为边界检查
危险操作自动进入用户审批流程
生产部署
内置 FastAPI 多租户服务
支持本地/Docker/E2B 环境抽象
状态持久化与会话管理
3. MD-LAD 架构哲学
三个维度
<b>Platform(平台层)</b>:系统级配置,包括模型密钥、权限策略、全局 Workspace,对应 agentscope.init()
<b>App(应用层)</b>:应用级定义,包括 Agent 结构、工具组合、工作流拓扑,对应 Agent、Tool、Pipeline
<b>User(用户层)</b>:会话级实例,包括对话历史、文件上传、实时偏好,对应 Session、Context、Event
洋葱式结构
外层 Platform、中间 App、核心 User Session
每一层只与相邻层通信,不跨层直接操作
多租户支持成为先天设计而非后期补丁
4. 八大核心构建模块
模块
Agent Service
Agent
Message & Event
Tool
Context
Permission
Middleware
Workspace
Model
功能
FastAPI 多租户服务、Session 管理、流式输出
ReAct/Harness 推理-行动循环引擎
ContentBlock、事件流
ToolBase/MCP 工具调用
压缩/截断/缓存上下文管理
三级权限控制
5 个执行钩子
Local/Docker/E2B 环境抽象
多模型接入、容错降级、并发批处理
二、智能体设计模式
1. ReAct 模式
核心思想
<b>ReAct(Reasoning + Acting)</b>:先思考,再行动,然后观察结果,并根据结果调整下一步的思考和行动
这是一个<b>动态迭代</b>的过程,每一步都可以根据新信息进行调整
工作流程
推理阶段(Reasoning)
智能体调用大语言模型分析当前任务
生成思考内容(Thought)
决定是否需要调用工具,以及调用哪个工具
行动阶段(Acting)
根据推理结果调用相应工具
执行具体操作(如搜索、计算、API 调用等)
观察阶段(Observing)
获取工具执行结果
将结果反馈给大语言模型
模型根据结果进行下一步推理
循环直至完成
重复"推理→行动→观察"的循环
直到任务完成或达到最大迭代次数
代码示例(Python)
执行过程示例
ReAct 模式的优势
<b>动态适应</b>:每一步都可以根据新信息调整策略
<b>透明可控</b>:思考过程可见,便于调试和干预
<b>灵活应对</b>:能够处理不确定性和意外情况
2. Plan and Execute(PE)模式
核心思想
<b>规划与执行</b>:在执行前先制定完整计划,然后严格按照计划执行
这是一种<b>静态规划</b>的方法,计划在执行开始前就已完整制定
工作流程
规划阶段(Planning)
智能体调用强大的大语言模型全面分析任务
生成一个详尽的、多步骤的行动计划
计划是静态的,包含所有执行步骤
执行阶段(Execution)
智能体严格按照预先制定的计划执行
每一步可能调用各种工具完成具体任务
只有在整个计划执行完毕或遇到重大障碍时才重新规划
代码示例(Python)
执行过程示例
Plan and Execute 模式的优势
<b>结构化执行</b>:任务分解清晰,步骤明确
<b>可预测性</b>:执行过程可预测,便于管理
<b>高效完成</b>:提前规划避免重复工作
3. 两种模式的对比
特性
计划方式
灵活性
可预测性
适用场景
资源消耗
人工干预
ReAct
动态生成,逐步调整
高,适应变化
低,每步可能变化
不确定性高的任务
可能重复推理
适合实时介入
Plan and Execute
静态规划,执行前完整制定
低,按计划执行
高,执行过程可预测
步骤明确的复杂任务
一次性规划,高效执行
适合事前审核计划
4. AgentScope 2.0 中的模式支持
ReActAgent
AgentScope 2.0 默认提供 ReActAgent 类
实现完整的 ReAct 循环:推理→行动→观察
支持异步流式输出和人机协作
PlanNotebook
提供计划管理功能
可以与 ReActAgent 结合使用
支持制定和管理多步骤计划
HarnessAgent
对 ReActAgent 的增强包装
提供工作区、会话持久化、记忆压缩等能力
适合长期运行场景
三、AgentScope 2.0 事件系统
1. 事件系统概述
核心概念
AgentScope 2.0 将智能体的每一步操作都以类型化事件暴露
支持流式推送,前端可以实时展示执行过程
事件系统让人工确认、人工介入和外部工具执行成为框架内生能力
事件类型
推理相关事件
PreReasoningEvent
推理开始前触发
包含输入消息和生成选项
可用于修改推理参数或中断推理
ReasoningChunkEvent
推理过程中逐块触发
包含模型生成的部分内容
可用于实时展示思考过程
PostReasoningEvent
推理完成后触发
包含完整的推理结果
可用于检查结果或请求停止
行动相关事件
PreActingEvent
工具调用前触发
包含工具调用信息
可用于权限检查或修改调用参数
ActingChunkEvent
工具执行过程中逐块触发
包含工具返回的部分结果
可用于实时展示执行进度
PostActingEvent
工具执行完成后触发
包含完整的工具执行结果
可用于检查结果或请求停止
系统事件
ToolResultEvent
工具执行结果事件
包含工具调用的完整结果
用于将结果反馈给模型
RequireUserConfirmEvent
需要用户确认事件
当执行敏感操作时触发
等待用户确认后继续执行
UserInterruptEvent
用户中断事件
用户主动中断智能体执行
支持中断后恢复
ContextCompressEvent
上下文压缩事件
当上下文过长时触发
自动压缩历史对话
消息事件
TextEvent
文本消息事件
包含模型生成的文本内容
用于实时展示回复内容
ToolUseEvent
工具使用事件
包含工具调用信息
用于展示智能体的工具调用
2. 事件系统的作用
实时监控
通过事件流实时监控智能体执行过程
观察每一步推理和行动
及时发现问题并干预
人机协作
通过 RequireUserConfirmEvent 实现人工确认
通过 UserInterruptEvent 实现实时中断
支持中断后恢复,不丢失上下文
扩展能力
通过 Middleware 钩子监听和处理事件
自定义事件处理逻辑
实现日志记录、性能监控、安全审计等功能
3. 事件系统代码示例
注册事件监听器(Python)
使用 Middleware(Python)
四、Agent 职责、核心方法与执行流程
1. Agent 核心职责
接收输入
接收用户消息或外部事件
支持多种消息格式(文本、图片、文件等)
处理消息路由和分发
管理上下文
维护会话历史(短期记忆)
管理长期记忆
处理上下文压缩和截断
推理与决策
调用大语言模型进行推理
生成工具调用计划
判断任务完成条件
工具执行
调用工具完成具体任务
管理工具执行状态
处理工具执行结果
权限控制
检查工具调用权限
处理敏感操作的用户确认
确保操作在安全边界内执行
状态管理
管理智能体运行状态
支持状态持久化和恢复
处理并发和异步执行
2. Agent 核心方法
核心接口方法
call() / reply()
运行推理-行动循环,返回响应消息
支持同步和异步调用
支持流式输出
observe()
将消息添加到上下文,不触发推理
用于接收环境消息或其他智能体消息
返回 Mono<Void>(Java)或 None(Python)
streamEvents()
以流式方式产出 AgentEvent 对象
实时返回执行过程中的各种事件
适合前端实时展示
ReActAgent 核心方法
_reasoning()
推理阶段核心方法
调用大语言模型生成思考和工具调用计划
返回推理结果
_acting()
行动阶段核心方法
执行工具调用
返回工具执行结果
_is_finished()
判断任务是否完成
检查是否达到最大迭代次数
根据推理结果判断是否完成
3. Agent 主循环流程
循环概述
每次 call() 调用时运行推理-行动循环
循环包含推理、行动、观察三个阶段
直到任务完成或达到最大迭代次数
详细流程
步骤1:接收输入
获取用户消息或外部事件
将消息添加到上下文(短期记忆)
步骤2:准备上下文
加载系统提示词
加载对话历史
加载工具定义
必要时压缩上下文
步骤3:推理阶段
调用 _reasoning() 方法
大语言模型分析当前状态
生成思考内容和工具调用计划
步骤4:检查完成条件
调用 _is_finished() 判断
如果完成,生成最终回复
如果未完成,进入行动阶段
步骤5:权限检查
检查工具调用权限
如果需要用户确认,触发 RequireUserConfirmEvent
等待用户确认后继续
步骤6:行动阶段
调用 _acting() 方法
执行工具调用(串行或并行)
获取工具执行结果
步骤7:观察阶段
将工具结果添加到上下文
更新工具状态
返回步骤3继续循环
步骤8:返回结果
循环结束后生成最终消息
返回响应给用户
流程图
4. Agent 配置示例(Python)
五、Agent 工具类型
1. 工具类型概述
自定义工具
开发者自行定义的工具函数
支持同步和异步函数
支持流式输出
MCP(Model Context Protocol)
模型上下文协议
标准化的工具调用接口
支持跨框架、跨语言调用
内置 BASH
内置的命令行执行工具
支持执行 shell 命令
有严格的权限控制
Skill(技能)
可复用的技能模块
封装特定领域的知识和能力
可以组合使用
2. 自定义工具
创建自定义工具(Python)
同步工具
异步工具
使用装饰器定义工具
注册自定义工具
3. MCP(Model Context Protocol)
MCP 概述
MCP 是一种标准化的工具调用协议
允许模型通过统一的接口调用外部工具
支持跨框架、跨语言的工具调用
MCP 客户端配置(Python)
MCP 服务端开发(Python)
4. 内置 BASH 工具
功能概述
AgentScope 2.0 内置命令行执行工具
支持执行 shell 命令
有严格的权限控制和安全检查
使用内置 BASH 工具
安全控制
检查高风险命令(如 rm -rf、格式化等)
限制执行目录
支持用户确认机制
记录命令执行日志
5. Skill(技能)
Skill 概述
Skill 是可复用的技能模块
封装特定领域的知识和能力
可以组合使用,形成更复杂的能力
创建 Skill(Python)
使用 Skill
6. 工具执行方式
串行执行
工具按顺序逐个执行
适合有依赖关系的工具调用
默认执行方式
并行执行
多个工具同时执行
适合无依赖关系的工具调用
通过 parallel_tool_calls=True 启用
批量执行
一次调用多个工具
适合需要获取多个信息源的场景
返回多个工具的执行结果
六、AgentScope 2.0 高级特性
1. 记忆系统
短期记忆(Short-Term Memory)
存储对话历史
用于当前会话的上下文管理
支持多种实现(内存、文件、数据库)
长期记忆(Long-Term Memory)
存储长期知识和经验
支持智能体自主管理或静态控制
支持向量检索和语义匹配
记忆管理模式
agent_control:允许智能体通过工具函数自己控制长期记忆
static_control:在每次回复的开始/结束时自动检索/记录信息
both:同时激活上述两种模式
代码示例(记忆配置)
2. 权限系统
三级权限控制
<b>allow</b>:直接允许执行
<b>deny</b>:拒绝执行
<b>confirm</b>:需要用户确认后执行
权限配置示例(Python)
3. Middleware(中间件)
五个关键钩子
on_pre_reasoning:推理前
on_post_reasoning:推理后
on_pre_acting:行动前
on_post_acting:行动后
on_handle_interrupt:处理中断
Middleware 示例(Python)
4. 工作流编排
Pipeline(流水线)
支持多智能体协作
顺序执行或并行执行
支持条件分支
代码示例(Pipeline)
七、AgentScope 2.0 部署与运维
1. 部署方式
本地开发部署
直接运行 Python 脚本
适合开发和测试
Docker 部署
使用 Docker 容器运行
便于环境隔离和迁移
云端部署
使用 AgentScope 内置的 FastAPI 服务
支持多租户
适合生产环境
2. 配置示例(Docker)
3. 监控与日志
实时监控
监控应用状态
监控 API 调用次数和延迟
监控模型使用情况
日志管理
记录所有 API 调用
记录模型请求和响应
支持日志导出和分析
八、AgentScope 2.0 学习资源
官方文档
AgentScope 官方文档:<a href="https://docs.agentscope.io">https://docs.agentscope.io</a>
API 参考:<a href="https://docs.agentscope.io/v2/api">https://docs.agentscope.io/v2/api</a>
教程:<a href="https://docs.agentscope.io/v2/tutorial">https://docs.agentscope.io/v2/tutorial</a>
社区资源
GitHub:<a href="https://github.com/modelscope/agentscope">https://github.com/modelscope/agentscope</a>
中文社区:<a href="https://github.com/modelscope/agentscope/discussions">https://github.com/modelscope/agentscope/discussions</a>
教程与示例
快速入门:<a href="https://docs.agentscope.io/v2/tutorial/quickstart">https://docs.agentscope.io/v2/tutorial/quickstart</a>
ReAct 智能体:<a href="https://docs.agentscope.io/v2/tutorial/quickstart_agent">https://docs.agentscope.io/v2/tutorial/quickstart_agent</a>
工具使用:<a href="https://docs.agentscope.io/v2/tutorial/task_tool">https://docs.agentscope.io/v2/tutorial/task_tool</a>
九、总结
AgentScope 2.0 核心要点
<b>架构升级</b>:从实验框架到生产级工程底座
<b>事件系统</b>:类型化流式事件,支持实时监控和干预
<b>权限控制</b>:三级权限控制,确保安全边界
<b>ReAct 模式</b>:推理-行动循环,动态适应任务
<b>工具系统</b>:支持自定义工具、MCP、内置 BASH、Skill
<b>记忆管理</b>:短期记忆+长期记忆,支持多种管理模式
<b>Middleware</b>:五个关键钩子,支持扩展和定制
<b>工作流编排</b>:支持多智能体协作
学习建议
从官方文档开始,了解基本概念
创建简单的 ReAct 智能体,熟悉核心流程
学习工具开发,创建自定义工具
了解事件系统和 Middleware,实现扩展功能
尝试工作流编排,实现多智能体协作
部署到生产环境,体验完整的运维能力
AgentScope 2.0 适用场景
智能客服:自动回答问题,调用工具查询信息
数据分析:自动收集数据、分析趋势、生成报告
代码开发:自动编写代码、测试、审查
内容生成:自动生成文章、报告、文档
任务自动化:自动执行多步骤任务
多智能体协作:多个智能体分工完成复杂任务
Python 智能体 (LangChain) 常用方法思维导图
一、LangChain 简介与安装
1. 什么是 LangChain
LangChain 是一个开源框架,用于构建基于大模型的 AI 应用
核心思想:模块化设计,将不同组件"链"在一起
口号:Build applications with LLMs through composability
主要功能:连接大模型、外部数据、工具调用、记忆管理
2. LangChain 生态系统
langchain-core:基础抽象和 LCEL(LangChain Expression Language)
langchain-community:第三方集成(向量库、工具、文档加载器)
langchain-openai/langchain-anthropic:大模型厂商集成
langgraph:构建有状态的多步骤工作流
langserve:部署为 REST API
langsmith:调试、测试、评估平台
3. 安装方法
基础安装
完整安装
安装 LangGraph
验证安装
4. 配置 API Key
使用 .env 文件
环境变量设置
二、核心概念
1. Model - 大模型
定义
智能体的"大脑",负责理解问题、推理决策、生成回答
LangChain 不提供模型,而是提供统一接口对接各类模型
支持:OpenAI、Anthropic、Google、HuggingFace、国产模型等
分类
LLM:文本输入 -> 文本输出(如 GPT-3.5)
ChatModel:消息列表输入 -> 消息输出(如 GPT-4)
2. Prompt - 提示词
定义
指导模型行为的指令集合
系统提示词:定义角色、规则、背景知识
用户提示词:具体问题或任务
提示词模板
可复用的提示词结构,支持变量填充
提高开发效率,保证一致性
3. Chain - 链
定义
将多个组件串联起来的处理管道
如:Prompt -> Model -> Output Parser
LCEL:LangChain Expression Language,声明式构建链
常见链类型
LLMChain:基础链
RetrievalQAChain:检索增强问答链
SequentialChain:顺序执行链
RouterChain:路由链(根据问题选择不同链)
4. Agent - 智能体
定义
Agent = LLM + Tools + Loop
能够自主规划步骤、调用工具、循环执行直到任务完成
核心工作模式:ReAct(Reasoning + Acting)
ReAct 循环
5. Tool - 工具
定义
智能体可以调用的外部功能
如:搜索引擎、计算器、数据库查询、API 调用、文件读写
工具类型
内置工具:LangChain 提供的标准工具
自定义工具:开发者根据需求编写
MCP 工具:Model Context Protocol,标准化工具接口
6. Memory - 记忆
定义
保存对话历史,实现多轮对话上下文连贯
短期记忆:当前对话历史
长期记忆:用户画像、知识图谱
记忆类型
ChatMessageHistory:内存级对话历史
BufferMemory:简单缓冲区
ConversationBufferMemory:带对话历史的缓冲区
VectorStoreRetrieverMemory:基于向量检索的长期记忆
三、大模型调用
1. ChatOpenAI - OpenAI 格式模型
基础调用
多轮对话
流式输出
2. HuggingFace 模型
加载本地模型
3. 国产模型(兼容 OpenAI 格式)
通义千问
DeepSeek
四、提示词模板
1. ChatPromptTemplate
基础模板
带多个变量
2. MessagesPlaceholder - 对话历史占位符
带记忆的模板
3. FewShotPromptTemplate - 少样本模板
带示例的模板
五、链式调用 (LCEL)
1. LCEL 基础
简单链
流式链
2. 复杂链
添加输出解析器
六、多轮对话记忆
1. ChatMessageHistory
基础用法
2. RunnableWithMessageHistory
带记忆的链
3. 长期记忆
基于向量的记忆
七、工具调用
1. 定义工具
使用 @tool 装饰器
手动定义工具
2. 绑定工具到模型
让模型知道可用工具
3. 执行工具调用
手动执行
八、Agent 智能体
1. ReAct Agent
基础 Agent
2. Tool Calling Agent
创建工具调用 Agent
3. Agent 高级配置
设置最大迭代次数
自定义停止条件
九、RAG (检索增强生成)
1. RAG 流程
核心步骤
加载文档
分割文本
向量化
存储到向量库
检索相关文档
结合文档生成回答
2. 完整 RAG 示例
加载和处理文档
创建 RAG 链
3. 不同的 Chain Type
chain_type 选项
"stuff": 将所有文档填充到提示词中(适合小文档)
"map_reduce": 分别处理每个文档,然后合并结果
"refine": 逐步精炼回答
"map_rerank": 分别处理,然后根据分数选择最佳
十、LangGraph - 流程编排
1. LangGraph 基础
什么是 LangGraph
基于状态机的工作流框架
将步骤建模为图中的节点和边
支持循环、条件分支、并行执行
适合构建复杂的多步骤 Agent
2. 简单工作流
定义状态和节点
运行工作流
3. 带工具调用的工作流
ReAct 工作流
十一、实战示例
1. 智能客服
完整示例
2. 代码生成助手
带工具调用的 Agent
3. 研究助手
RAG + Agent 组合
十二、注意事项
1. 常见问题
工具调用失败
记忆丢失
提示词过长
2. 性能优化
缓存机制
异步调用
批量处理
3. 安全注意事项
输入验证
敏感信息保护
十三、常用速查表
模型加载
Method
ChatOpenAI()
ChatHuggingFace()
Usage
OpenAI 格式模型
HuggingFace 模型
Example
ChatOpenAI(model="gpt-3.5-turbo")
ChatHuggingFace(pipeline=pipe)
提示词模板
Method
ChatPromptTemplate.from_messages()
MessagesPlaceholder()
FewShotPromptTemplate()
Usage
聊天格式模板
对话历史占位符
少样本模板
Example
ChatPromptTemplate.from_messages([("system", "..."), ("user", "...")])
MessagesPlaceholder(variable_name="history")
FewShotPromptTemplate(examples=..., example_prompt=...)
链式调用
Method
prompt | llm | parser
chain.invoke()
chain.stream()
Usage
LCEL 链
调用链
流式输出
Example
chain = prompt | llm | output_parser
chain.invoke({"input": "..."})
for chunk in chain.stream(...):
工具定义
Method
@tool 装饰器
Tool()
llm.bind_tools()
Usage
快速定义工具
手动定义工具
绑定工具到模型
Example
@tool def func(...):
Tool(name=..., func=..., description=...)
llm.bind_tools(tools)
Agent 创建
Method
create_react_agent()
create_tool_calling_agent()
AgentExecutor()
Usage
ReAct Agent
工具调用 Agent
执行 Agent
Example
create_react_agent(llm, tools, prompt)
create_tool_calling_agent(llm, tools, prompt)
AgentExecutor(agent=agent, tools=tools)
RAG 组件
Component
TextLoader
RecursiveCharacterTextSplitter
FAISS
RetrievalQA
Usage
加载文档
分割文本
向量存储
检索问答链
Example
TextLoader("file.txt")
RecursiveCharacterTextSplitter(chunk_size=1000)
FAISS.from_documents(splits, embeddings)
RetrievalQA.from_chain_type(llm, retriever=retriever)
LangGraph
Component
StateGraph
add_node()
add_edge()
compile()
Usage
创建状态图
添加节点
添加边
编译工作流
Example
StateGraph(AgentState)
workflow.add_node("name", func)
workflow.add_edge("start", "end")
app = workflow.compile()
常用工具
Tool
TavilySearchResults
Calculator
PythonREPL
FileReader
create_retriever_tool
Usage
搜索引擎
计算器
Python 代码执行
文件读取
检索工具
常用模型
Model
gpt-3.5-turbo
gpt-4o
qwen-turbo
deepseek-chat
claude-3-sonnet
Provider
OpenAI
OpenAI
阿里
DeepSeek
Anthropic
Use Case
通用对话
复杂任务
国产通用
代码助手
长文本处理
Hugging Face Transformers 常用方法思维导图
一、Hugging Face 简介与安装
1. 什么是 Hugging Face
Hugging Face 是一个开源 AI 社区和平台,提供完整的 MLOps 解决方案
核心产品:Transformers 库、Datasets 库、Evaluate 库、Hub 平台
Hub 托管超过 90 万个模型、20 万个数据集和 35 万个应用
口号:Build, train and deploy state-of-the-art models
2. Transformers 库定位
提供统一接口加载和使用各种预训练 Transformer 模型
支持 PyTorch、TensorFlow、JAX 等深度学习框架
涵盖 NLP、CV、语音、多模态等多种任务
自动处理模型下载、缓存、版本管理
3. 安装方法
基础安装
安装 PyTorch
安装其他依赖
4. 配置国内镜像
二、Pipeline - 快速推理接口
1. 什么是 Pipeline
Pipeline 是 Transformers 提供的高层次 API
封装了 Tokenizer 和 Model,一行代码完成推理
支持多种任务类型,无需关心底层细节
自动处理文本编码、模型调用、结果解码
2. 支持的任务类型
text-generation:文本生成
text-classification:文本分类
sentiment-analysis:情感分析
question-answering:问答
fill-mask:填空
summarization:文本摘要
translation_en_to_zh:英文转中文
image-classification:图像分类
automatic-speech-recognition:语音识别
3. 基础使用
文本生成
情感分析
问答系统
文本摘要
机器翻译
4. Pipeline 参数
model:模型名称或路径
tokenizer:分词器名称或路径
device:设备(-1=CPU,0=GPU)
batch_size:批量大小
max_length:最大长度
truncation:是否截断
padding:是否填充
do_sample:是否采样
temperature:温度
top_k:Top-K 采样
top_p:Nucleus 采样
三、Tokenizer - 分词器
1. 什么是 Tokenizer
Tokenizer 将文本转换为模型可理解的数字序列
核心功能:分词、编码、解码
不同模型使用不同的分词器(BPE、WordPiece、SentencePiece)
必须与模型配套使用
2. 核心概念
Token:文本被切分成的最小单位(单词、子词或字符)
Vocabulary:模型训练时使用的词元集合,每个词元对应唯一 ID
Special Tokens:[CLS]分类、[SEP]分隔、[PAD]填充、[MASK]掩码、[BOS]/[EOS]开始/结束
3. Tokenizer 基础使用
加载分词器
编码文本
批量编码
解码
4. 编码参数
padding:是否填充(True/'longest'/'max_length')
truncation:是否截断(True/'longest_first')
max_length:最大长度
return_tensors:返回张量类型('pt'/'tf'/'np')
add_special_tokens:是否添加特殊标记
四、AutoModel - 自动模型加载
1. AutoModel 家族
AutoModel
AutoModelForSequenceClassification
AutoModelForTokenClassification
AutoModelForQuestionAnswering
AutoModelForCausalLM
AutoModelForMaskedLM
2. 模型配置
五、模型推理与输出处理
1. 基础推理流程
2. 模型输出类型
logits:原始预测值
loss:损失值(训练时)
last_hidden_state:隐藏状态
pooler_output:池化输出
start_logits/end_logits:问答位置预测
3. GPU 加速
六、文本生成
1. 基础文本生成
2. 生成策略
贪婪搜索
随机采样
Top-K 采样
Nucleus 采样
Beam Search
3. 高级参数
repetition_penalty:重复惩罚
eos_token_id:结束标记 ID
bad_words_ids:禁止生成的 token
七、模型微调
1. 加载数据集
2. 配置训练参数
3. 训练模型
4. 参数高效微调(PEFT)
八、模型保存与加载
1. 保存模型
2. 加载模型
3. 导出模型
九、量化与加速
1. 动态量化
2. 混合精度
3. 使用 accelerate
十、实战示例
1. 情感分析系统
2. 文本生成聊天机器人
3. 中文文本分类
4. 文档问答系统
十一、注意事项
1. 常见问题
模型下载慢:配置 HF_ENDPOINT 镜像
显存不足:使用 smaller 模型、量化、减少 batch_size
分词器不匹配:确保模型和分词器名称一致
2. 性能优化
使用批量推理
使用 accelerate 处理多 GPU
开启混合精度
3. 安全注意事项
不要硬编码 API Key
注意模型许可证
注意模型输出偏见
十二、常用速查表
模型加载
Method
AutoModel.from_pretrained()
AutoModelForSequenceClassification.from_pretrained()
AutoModelForCausalLM.from_pretrained()
AutoTokenizer.from_pretrained()
Usage
Base model
Classification
Text generation
Tokenizer
Example
AutoModel.from_pretrained('bert-base-chinese')
AutoModelForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
AutoModelForCausalLM.from_pretrained('gpt2')
AutoTokenizer.from_pretrained('bert-base-chinese')
Pipeline Tasks
Task
text-generation
text-classification
sentiment-analysis
question-answering
summarization
Usage
Text generation
Text classification
Sentiment analysis
QA
Summarization
Example
pipeline('text-generation', model='gpt2')
pipeline('text-classification')
pipeline('sentiment-analysis')
pipeline('question-answering')
pipeline('summarization')
Text Generation Params
Param
max_length
do_sample
temperature
top_k
top_p
repetition_penalty
Usage
Maximum length
Enable sampling
Randomness
Top-K sampling
Nucleus sampling
Repetition penalty
Tokenizer Params
Param
padding
truncation
max_length
return_tensors
add_special_tokens
Usage
Padding strategy
Truncation strategy
Maximum length
Tensor type
Add special tokens
Common Models
Model
bert-base-chinese
gpt2
distilbert-base-uncased
Helsinki-NLP/opus-mt-en-zh
facebook/bart-large-cnn
Usage
General Chinese
Text generation
Lightweight
Translation
Summarization
Language
Chinese
English
English
Bilingual
English
Transformer 常用方法思维导图
一、Transformer 基础定义
1. 什么是 Transformer
2017年谷歌论文《Attention Is All You Need》提出的深度学习架构
完全抛弃RNN/LSTM循环结构,全程依靠注意力机制建模序列
当前大语言模型、AI绘画、语音模型的底层底座
核心优势:
序列可并行计算,训练速度远超循环网络
自注意力直接捕捉长距离依赖,不会梯度消失
通用架构:文字、图片、音频、时序数据都能用
2. 三大架构形态
Encoder-only(仅编码器)
代表模型:BERT
用途:语义理解(情感分类、实体识别、检索、阅读理解)
特点:双向自注意力,能同时看前文后文
Decoder-only(仅解码器)
代表模型:GPT、LLaMA、豆包等对话大模型
用途:文本生成(对话、写作、代码生成、续写)
特点:仅掩码单向自注意力,只能看见已生成内容
Encoder-Decoder(完整架构)
代表模型:原始Transformer、T5、BART
用途:机器翻译、长文摘要、文本改写
特点:包含交叉注意力,解码器借助编码器输入生成
3. 安装依赖
PyTorch 安装
Transformers 库安装
验证安装
二、输入预处理模块
1. 词嵌入 Embedding
概念释义
文字不能直接输入模型,先建立词表
把每个字/词转换成固定长度数字向量(语义向量)
意思相近的词向量数值接近
图像Transformer(ViT)把图片切成小块Patch,每个Patch当作一个"单词"
PyTorch 实现示例
输出结果
2. 位置编码 Positional Encoding
概念释义
Transformer没有循环结构,本身分不清词语先后顺序
必须手动注入位置信息
作用:让模型区分「猫追狗」和「狗追猫」两种完全不同语义
正弦余弦位置编码(原始论文)
可学习位置嵌入(现代大模型主流)
3. 输入归一化 & Dropout
概念释义
归一化:标准化向量数值,稳定训练
Dropout:随机屏蔽部分特征,防止模型过拟合
代码示例
三、核心注意力机制
1. 自注意力 Self-Attention
概念释义
一句话人话:序列里每个token,和序列所有token互相计算关联权重,自主判断谁更重要
三个核心向量:
Q 查询:当前词要找相关内容
K 键:所有词自带的语义标签
V 值:所有词存储的真实语义信息
计算流程
输入分别乘权重矩阵得到 Q、K、V
Q 和所有K做点乘,算出相似度分数(关联度)
除以√dk缩放,避免数值过大梯度爆炸
Softmax把分数转为总和为1的权重
使用权重对所有V加权求和,得到融合全文上下文的新向量
代码实现
输出结果
2. 多头自注意力 Multi-Head Attention
概念释义
把Q/K/V平均拆分成多组独立小维度
每组单独跑自注意力(头与头并行计算)
最后拼接融合,多视角捕捉关系
细分两种:
双向自注意力(编码器用):能同时看前文、后文
掩码自注意力(解码器内层):加右上三角掩码,防止偷看未来文字
代码实现
输出结果
掩码自注意力(解码器专用)
输出结果
3. 交叉注意力 Cross-Attention
概念释义
只有完整Transformer解码器才有
解码器的Q来自已生成文本
K、V来自编码器输出的原文特征
用途:翻译时,生成英文单词时专门去匹配对应的中文原文
代码实现
输出结果
四、编码器 Encoder
1. 单层编码器结构
概念释义
两层子模块,顺序:多头自注意力 → 前馈网络FFN
每层标配三件套:残差连接 + 层归一化LayerNorm + Dropout
输出:融合全局上下文的特征矩阵
代码实现
输出结果
2. 完整编码器(多层堆叠)
代码实现
输出结果
五、解码器 Decoder
1. 单层解码器结构
概念释义
三层子模块,顺序:掩码多头自注意力 → 交叉注意力 → FFN
掩码多头自注意力(Masked Multi-Head Self-Attention)
多头交叉注意力(Multi-Head Cross-Attention)
前馈神经网络(Feed-Forward Neural Network)
每层标配:残差连接 + 层归一化LayerNorm + Dropout
掩码自注意力:只能看见当前位置左侧已生成文字
防止解码器在生成第 i 个词时看到第 i 个词之后的词
使用下三角掩码矩阵实现
交叉注意力:读取编码器的全局原文特征
代码实现
输出结果
2. 完整解码器(多层堆叠)
代码实现
输出结果
六、位置编码
1. 为什么需要位置编码
问题
Transformer 没有循环结构,无法感知序列顺序
需要显式地为每个位置添加位置信息
解决方案
在词嵌入上加上位置编码向量
位置编码包含了位置的相对和绝对信息
2. 正弦余弦位置编码
数学公式
代码示例
特点
位置编码是固定的,不需要学习
可以处理任意长度的序列
相对位置信息可以通过正弦余弦的性质得到
3. 可学习位置编码
代码实现
特点
位置编码是可学习的参数
模型可以根据任务自动调整位置编码
但受限于 max_len,无法处理超过 max_len 的序列
七、输出层
1. 输出层结构
概念释义
解码器顶层输出向量经过:
线性层:把特征维度映射到词表大小维度
Softmax:输出词表中每个字的预测概率
采样策略:贪心采样、Top-k、Top-p,选出下一个字
代码实现
输出结果
2. 采样策略
贪心采样(最简单)
Top-k 采样(常用)
Top-p 采样(核采样)
八、前馈神经网络
1. 定义
结构
两层线性变换,中间夹着 ReLU 激活函数
输入输出维度都是 d_model
中间层维度通常是 d_model 的 4 倍
代码实现
作用
对每个位置的表示进行非线性变换
增加模型的表达能力
每个位置独立处理,不涉及序列间的交互
九、完整 Transformer 模型
1. Encoder-Decoder 完整模型
代码实现
输出结果
2. Decoder-only 模型(GPT风格)
代码实现
输出结果
十、Transformer 变体
1. BERT
特点
双向预训练模型
使用掩码语言模型(MLM)和下一句预测(NSP)任务
仅使用编码器部分
代码示例
2. GPT
特点
单向预训练模型
使用因果语言模型(CLM)任务
仅使用解码器部分
自回归生成
代码示例
3. T5
特点
统一框架:将所有 NLP 任务转换为文本到文本任务
使用编码器-解码器架构
预训练任务:Span Corruption
代码示例
4. Vision Transformer (ViT)
特点
将 Transformer 应用于计算机视觉
将图像划分为多个 patch
每个 patch 作为一个 token 输入
代码示例
十一、配套关键概念
1. 残差连接 Residual Connection
概念释义
公式:输出 = 子层输入 + 子层计算结果
作用:深层堆叠几十上百层网络时,保证梯度能正常回传,不会消失
让超大模型可训练的关键技术
代码示例
2. 层归一化 Layer Normalization
概念释义
Transformer默认用LN,作用是把每层输入数值约束在稳定区间
加速收敛、提升训练稳定性
和CNN的BN不同:LN对单一样本做标准化,BN对一批样本做标准化
两种放置方式:
Post-LN:原始论文,注意力计算完再归一化
Pre-LN:现代大模型主流,先归一化再送入注意力
代码示例
3. 前馈网络 FFN
概念释义
独立作用于每个token,不依赖其他词
扩大特征维度再压缩
学习复杂语义非线性特征
常用激活函数:ReLU、GELU(现代大模型主流)
代码示例
4. 掩码 Mask
概念释义
两种掩码:
序列掩码(Padding Mask):屏蔽句子填充的无意义空白token
未来掩码(Look-ahead Mask):解码器专用,遮挡后文
代码示例
输出结果
5. 权重共享
概念释义
词嵌入层与最终输出分类层共享权重
减少参数量、提升效果
几乎所有大模型标配
代码示例
输出结果
十二、拓展衍生概念
1. ViT(视觉Transformer)
概念释义
把图片切块当序列处理
用于图像分类、检测、分割
流程:图片→切块→Patch嵌入→位置编码→Transformer编码器→分类头
代码示例
2. RoPE旋转位置编码
概念释义
替代正弦位置编码,现在主流大模型使用
通过旋转矩阵给向量注入位置信息
保持相对位置不变性
代码示例
3. KV缓存
概念释义
推理加速技术,缓存历史K/V向量
生成时不用重复计算,大幅提升对话速度
每次只计算新token的注意力
代码示例
十三、使用 Transformers 库调用预训练模型
1. 使用 BERT 进行文本分类
代码示例
2. 使用 GPT2 进行文本生成
代码示例
3. 使用 Transformer 进行机器翻译
代码示例
十四、训练 Transformer 模型
1. 数据准备
代码示例
2. 训练循环
代码示例
十五、Transformer 训练技巧
1. 学习率调度
预热学习率
余弦退火
2. 梯度裁剪
代码实现
作用
防止梯度爆炸
稳定训练过程
3. 标签平滑
代码实现
作用
防止模型过于自信
提高泛化能力
4. 混合精度训练
代码实现
作用
减少显存占用
加速训练
十六、三种架构对比汇总
架构对比表
特性
结构
注意力
核心能力
代表模型
适用场景
是否偷看未来
交叉注意力
Encoder-only (BERT)
多层编码器堆叠
双向自注意力
语义理解
BERT、RoBERTa
情感分类、实体识别、检索
否(双向可见)
无
Decoder-only (GPT)
多层解码器堆叠
掩码单向自注意力
文本生成
GPT、LLaMA、豆包
对话、写作、代码生成
否(掩码遮挡)
无
Encoder-Decoder (Transformer)
编码器+解码器全套
双向+掩码+交叉注意力
翻译、摘要
T5、BART、原始Transformer
机器翻译、长文摘要
否(解码器掩码)
有(解码器)
核心区别总结
Encoder-only
输入:完整句子
输出:句向量或标签
特点:双向理解,适合分类、理解任务
Decoder-only
输入:前缀提示
输出:续写文本
特点:单向生成,适合对话、创作任务
Encoder-Decoder
输入:源文本 + 目标文本前缀
输出:目标文本后缀
特点:端到端转换,适合翻译、摘要任务
十七、Transformer 应用场景
1. 自然语言处理
机器翻译
文本分类
问答系统
文本生成
2. 计算机视觉
图像分类
目标检测
3. 语音处理
语音识别
语音合成
4. 多模态
图文理解
十八、注意事项
1. 常见错误
维度不匹配
忘记添加位置编码
解码器忘记加掩码
2. 性能优化
混合精度训练
梯度累积
3. 训练技巧
学习率调度
标签平滑
十九、常用速查表
注意力机制公式
步骤
QKV计算
相似度
权重归一化
输出
公式
Q = X·W_q, K = X·W_k, V = X·W_v
scores = Q·K^T / √d_k
weights = softmax(scores)
output = weights·V
说明
输入投影到三个空间
缩放点积
转为概率分布
加权求和
Transformer 超参数
子主题
激活函数对比
函数
ReLU
GELU
SwiGLU
公式
max(0, x)
x·Φ(x)
x·σ(βx) · Wx + b
特点
简单快速,可能死亡
平滑,现代大模型首选
PaLM使用,更好的效果
位置编码对比
类型
正弦余弦
可学习
RoPE
特点
固定公式,外推性好
训练得到,更灵活
旋转矩阵,相对位置
使用模型
原始Transformer
BERT、GPT
LLaMA、Qwen
采样策略对比
策略
贪心
Top-k
Top-p
Temperature
特点
选概率最大的token
从概率最高的k个中采样
累积概率到p停止
调整概率分布陡峭度
适用场景
确定性输出
平衡多样性
自适应多样性
控制随机性
PyTorch 常用方法思维导图
一、PyTorch 简介与安装
1. 什么是 PyTorch
PyTorch 是一个基于 Python 的科学计算框架
主要用于深度学习研究和开发
由 Facebook AI Research (FAIR) 开发
特点:动态计算图、自动微分、GPU 加速、简洁易用
2. PyTorch vs TensorFlow
特性
计算图
调试
灵活性
生产部署
研究社区
PyTorch
动态(运行时构建)
直观,类似 Python
高
较新
活跃
TensorFlow
静态(编译时构建)
较复杂
较低
成熟
广泛
3. 安装方法
CPU 版本
GPU 版本(CUDA 12.1)
验证安装
4. 基础概念
张量(Tensor)
PyTorch 的核心数据结构
多维数组,类似 NumPy 的 ndarray
支持 GPU 加速和自动微分
计算图
描述张量操作的有向无环图
动态图:每次前向传播时重新构建
用于自动计算梯度
自动微分(Autograd)
自动计算张量操作的梯度
使用反向传播算法
通过 requires_grad=True 启用
二、张量操作
1. 创建张量
基本创建方法
指定数据类型
2. 张量属性
基本属性
维度操作
3. 张量运算
基本运算
比较运算
统计运算
4. 索引与切片
基本索引
高级索引
5. 张量拼接与分割
拼接
分割
6. 张量广播
广播机制
三、自动微分(Autograd)
1. 基本概念
梯度计算
停止梯度追踪
分离梯度
2. 复杂梯度计算
标量输出
向量输出
矩阵输出
3. 梯度累积
多次反向传播
四、神经网络模块(nn.Module)
1. 基本模块
定义网络
前向传播
2. 常用层
线性层
卷积层
池化层
循环层
激活函数
3. 损失函数
分类损失
回归损失
4. 参数管理
查看参数
参数初始化
冻结参数
五、优化器
1. 常用优化器
SGD
Adam
AdamW
RMSprop
2. 学习率调度
学习率衰减
自定义学习率
六、数据加载
1. Dataset 与 DataLoader
自定义 Dataset
内置数据集
2. 数据变换
图像变换
自定义变换
七、模型训练
1. 训练循环
基础训练循环
验证循环
2. GPU 训练
设备配置
多 GPU 训练
3. 混合精度训练
基本用法
八、模型保存与加载
1. 保存模型
保存完整模型
保存模型参数
保存训练状态
2. 加载模型
加载完整模型
加载模型参数
加载训练状态
3. 跨设备加载
CPU 加载 GPU 模型
GPU 加载 CPU 模型
九、常用工具
1. 可视化
TensorBoard
2. 梯度检查
检查梯度
3. 性能分析
性能分析器
十、实战示例
1. 图像分类
完整示例
2. 文本分类
完整示例
3. 回归任务
完整示例
十一、注意事项
1. 常见错误
形状不匹配
梯度为 None
CUDA 内存不足
2. 性能优化
数据加载优化
模型优化
3. 调试技巧
打印张量信息
使用 assert 检查
十二、常用速查表
张量创建
方法
torch.tensor()
torch.zeros()
torch.ones()
torch.rand()
torch.randn()
torch.eye()
torch.arange()
说明
从列表创建
创建全零张量
创建全一张量
均匀分布随机
正态分布随机
单位矩阵
等差数列
示例
torch.tensor([1, 2, 3])
torch.zeros(3, 4)
torch.ones(3, 4)
torch.rand(3, 4)
torch.randn(3, 4)
torch.eye(3)
torch.arange(0, 10)
张量操作
方法
x.view()
x.reshape()
x.unsqueeze()
x.squeeze()
x.permute()
torch.cat()
torch.stack()
说明
改变形状
改变形状(更灵活)
增加维度
减少维度
转置维度
拼接张量
堆叠张量
示例
x.view(2, 12)
x.reshape(2, 12)
x.unsqueeze(0)
x.squeeze(0)
x.permute(1, 0, 2)
torch.cat([a, b], dim=0)
torch.stack([a, b], dim=0)
数学运算
方法
torch.mm()
torch.bmm()
torch.matmul()
x.sum()
x.mean()
x.max()
x.argmax()
说明
矩阵乘法
批量矩阵乘法
矩阵乘法(自动广播)
求和
均值
最大值
最大值索引
示例
torch.mm(a, b)
torch.bmm(a, b)
torch.matmul(a, b)
x.sum(dim=0)
x.mean(dim=1)
x.max(dim=0)
x.argmax(dim=1)
神经网络层
层
Linear
Conv2d
MaxPool2d
LSTM
Embedding
Dropout
BatchNorm2d
说明
线性层
2D 卷积
最大池化
循环层
嵌入层
正则化
批归一化
代码
nn.Linear(10, 20)
nn.Conv2d(3, 16, 3)
nn.MaxPool2d(2)
nn.LSTM(100, 200)
nn.Embedding(10000, 128)
nn.Dropout(0.5)
nn.BatchNorm2d(16)
损失函数
损失函数
CrossEntropyLoss
BCELoss
BCEWithLogitsLoss
MSELoss
L1Loss
SmoothL1Loss
用途
多分类
二元分类
二元分类(带 logits)
回归
回归(L1)
回归(平滑 L1)
代码
nn.CrossEntropyLoss()
nn.BCELoss()
nn.BCEWithLogitsLoss()
nn.MSELoss()
nn.L1Loss()
nn.SmoothL1Loss()
优化器
优化器
SGD
SGD + Momentum
Adam
AdamW
RMSprop
特点
基础优化器
带动量
自适应学习率
Adam + 权重衰减
自适应学习率
代码
optim.SGD(model.parameters(), lr=0.01)
optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optim.Adam(model.parameters(), lr=0.001)
optim.AdamW(model.parameters(), lr=0.001)
optim.RMSprop(model.parameters(), lr=0.01)
学习率调度
调度器
StepLR
CosineAnnealingLR
ExponentialLR
LambdaLR
说明
按步长衰减
余弦退火
指数衰减
自定义函数
代码
StepLR(optimizer, step_size=10)
CosineAnnealingLR(optimizer, T_max=100)
ExponentialLR(optimizer, gamma=0.95)
LambdaLR(optimizer, lr_lambda=fn)
设备操作
操作
检查 GPU
设置设备
模型移到 GPU
数据移到 GPU
清理显存
代码
torch.cuda.is_available()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
data = data.to(device)
torch.cuda.empty_cache()
保存与加载
操作
保存完整模型
保存参数
加载完整模型
加载参数
代码
torch.save(model, 'model.pth')
torch.save(model.state_dict(), 'model.pth')
model = torch.load('model.pth')
model.load_state_dict(torch.load('model.pth'))
学习机制对比
一、神经学习机制概述
1. 什么是神经学习机制
神经网络通过调整权重参数来学习数据模式的过程
模仿人脑神经元之间的连接方式,通过大量数据训练实现预测、分类、生成等任务
核心思想:从数据中自动提取特征,无需人工设计特征工程
2. 学习机制分类维度
数据流向:前馈网络 vs 循环网络
注意力机制:有无注意力机制
数据类型:序列数据 vs 图像数据 vs 图数据
训练方式:监督学习 vs 无监督学习 vs 强化学习
3. 常见学习机制汇总
前馈神经网络(FFNN)
卷积神经网络(CNN)
循环神经网络(RNN)
长短期记忆网络(LSTM)
门控循环单元(GRU)
Transformer
图神经网络(GNN)
生成对抗网络(GAN)
二、前馈神经网络 FFNN
1. 概念释义
最简单的神经网络结构,数据从输入层单向流向输出层
没有循环连接,每层神经元只与下一层神经元连接
由输入层、隐藏层、输出层组成,隐藏层可以有多层
2. 核心特点
优点
结构简单,易于理解和实现
训练速度快,适合简单任务
可以拟合复杂的非线性函数
缺点
无法处理序列数据,缺乏记忆能力
需要大量参数来处理复杂任务
容易过拟合,需要正则化
3. 适用场景
简单分类任务(如手写数字识别)
回归任务(如房价预测)
特征提取的基础组件
4. 结构示意图
5. 代码示例
三、卷积神经网络 CNN
1. 概念释义
专门为处理网格结构数据(如图像)设计的神经网络
通过卷积操作自动提取局部特征,利用权值共享减少参数数量
核心思想:局部感受野、权值共享、池化降采样
2. 核心组件
卷积层(Convolutional Layer)
使用卷积核扫描输入特征图
每个卷积核提取一种特定特征(边缘、纹理、形状)
多个卷积核并行提取多种特征
池化层(Pooling Layer)
对特征图进行降采样,保留重要信息
常见池化方式:最大池化、平均池化
减少参数数量,防止过拟合
激活函数
引入非线性,增强模型表达能力
常用:ReLU、GELU、Swish
全连接层
将卷积提取的特征映射到最终输出
用于分类或回归任务
3. 核心特点
优点
权值共享,参数量远少于全连接网络
自动提取特征,无需人工设计
平移不变性,对图像旋转、缩放有一定鲁棒性
层次化特征提取,从简单到复杂
缺点
缺乏序列建模能力,无法处理时序数据
全局信息捕捉能力有限
需要大量图像数据训练
4. 适用场景
图像分类(如ImageNet)
目标检测(如YOLO、Faster R-CNN)
图像分割(如U-Net)
图像生成(如DCGAN)
人脸识别
5. 结构示意图
6. 代码示例
7. 经典架构
LeNet-5
1998年提出,第一个现代CNN
结构:输入→卷积→池化→卷积→池化→全连接→输出
用途:手写数字识别
AlexNet
2012年提出,深度学习里程碑
8层网络,使用ReLU激活函数
首次使用GPU加速训练
用途:ImageNet图像分类
VGGNet
2014年提出,深度卷积网络
16-19层,使用3×3小卷积核
结构规整,易于扩展
ResNet
2015年提出,残差网络
引入残差连接,解决梯度消失问题
可训练数百层甚至上千层网络
EfficientNet
2019年提出,高效网络
同时优化深度、宽度、分辨率
参数量少,精度高
四、循环神经网络 RNN
1. 概念释义
专门为处理序列数据设计的神经网络
网络内部有循环连接,能够保存状态信息
每一步的输出不仅依赖当前输入,还依赖之前的隐藏状态
核心思想:将序列数据按时间步展开,共享参数
2. 核心结构
隐藏状态(Hidden State)
网络的"记忆",存储之前的信息
每一步更新:h_t = tanh(W_hh * h_{t-1} + W_xh * x_t + b_h)
传递到下一步,实现信息累积
时间步展开
3. 核心特点
优点
天然适合处理序列数据
能够捕捉序列中的时间依赖关系
参数共享,模型简洁
缺点
梯度消失/爆炸问题,难以处理长序列
计算串行,无法并行化
对早期信息的记忆能力有限
4. 适用场景
文本分类
情感分析
语音识别
机器翻译(早期)
时间序列预测
5. 结构示意图
6. 代码示例
五、长短期记忆网络 LSTM
1. 概念释义
RNN的改进版本,专门解决梯度消失问题
通过门控机制控制信息的流入和流出
包含输入门、遗忘门、输出门,能够选择性地记住或遗忘信息
核心思想:用门控单元替代简单的隐藏状态更新
2. 核心组件
遗忘门(Forget Gate)
决定哪些信息需要从细胞状态中删除
输出0-1之间的值,0表示完全遗忘,1表示完全保留
公式:f_t = σ(W_f * [h_{t-1}, x_t] + b_f)
输入门(Input Gate)
决定哪些新信息需要存入细胞状态
包含两部分:
i_t = σ(W_i * [h_{t-1}, x_t] + b_i):决定更新哪些位置
C_t~ = tanh(W_C * [h_{t-1}, x_t] + b_C):生成新的候选值
细胞状态(Cell State)
LSTM的核心记忆单元,类似传送带
状态更新:C_t = f_t * C_{t-1} + i_t * C_t~
输出门(Output Gate)
决定细胞状态的哪些部分输出到隐藏状态
公式:o_t = σ(W_o * [h_{t-1}, x_t] + b_o)
隐藏状态:h_t = o_t * tanh(C_t)
3. 核心特点
优点
解决了RNN的梯度消失问题
能够记住长距离依赖关系
门控机制灵活,适合复杂序列建模
缺点
结构复杂,计算开销大
仍然是串行计算,无法完全并行化
参数较多,训练需要更多数据
4. 适用场景
机器翻译
文本生成
语音识别
命名实体识别
视频分析
5. 结构示意图
6. 代码示例
六、门控循环单元 GRU
1. 概念释义
LSTM的简化版本,将遗忘门和输入门合并为更新门
去掉了细胞状态,直接在隐藏状态上操作
结构更简单,计算效率更高
核心思想:用更少的门控单元实现类似LSTM的效果
2. 核心组件
更新门(Update Gate)
控制前一时刻隐藏状态有多少保留到当前时刻
公式:z_t = σ(W_z * [h_{t-1}, x_t] + b_z)
重置门(Reset Gate)
控制前一时刻隐藏状态有多少用于计算候选隐藏状态
公式:r_t = σ(W_r * [h_{t-1}, x_t] + b_r)
候选隐藏状态
结合重置后的前一状态和当前输入
公式:h_t~ = tanh(W_h * [r_t * h_{t-1}, x_t] + b_h)
隐藏状态更新
结合更新门和候选状态
公式:h_t = (1 - z_t) * h_{t-1} + z_t * h_t~
3. 核心特点
优点
比LSTM结构更简单,参数更少
计算效率更高,训练速度更快
在许多任务上性能接近LSTM
缺点
表达能力略低于LSTM
仍然存在梯度消失问题(比RNN好)
串行计算,无法完全并行化
4. 适用场景
语音识别
文本分类
时间序列预测
资源受限场景(移动端部署)
5. 结构示意图
6. 代码示例
七、Transformer
1. 概念释义
2017年谷歌提出,完全基于注意力机制的神经网络
抛弃了RNN的循环结构,使用自注意力机制捕捉序列依赖
能够并行处理序列,训练速度远超循环网络
是当前大语言模型(GPT、LLaMA)、AI绘画(Diffusion)的底层架构
2. 核心组件
自注意力机制(Self-Attention)
序列中每个token与所有token计算关联权重
三个核心向量:Q(查询)、K(键)、V(值)
公式:Attention(Q,K,V) = softmax(Q·K^T / √d_k)·V
多头自注意力(Multi-Head Attention)
将Q/K/V拆分成多组,每组独立计算注意力
多视角捕捉不同类型的关系
最后拼接融合
位置编码(Positional Encoding)
注入位置信息,弥补没有循环结构的缺陷
常用:正弦余弦编码、可学习位置嵌入、RoPE
前馈网络(FFN)
独立处理每个token的非线性变换
两层全连接+激活函数
残差连接与层归一化
残差连接:解决梯度消失问题
层归一化:稳定训练,加速收敛
3. 核心特点
优点
并行计算,训练速度快
直接捕捉长距离依赖,无梯度消失问题
通用架构,适用于多种数据类型
可扩展性强,支持大规模预训练
缺点
计算复杂度高(O(n²))
内存消耗大,处理超长序列受限
需要大量数据和算力训练
4. 三种架构形态
Encoder-only(BERT)
双向自注意力,适合语义理解
用途:分类、检索、阅读理解
Decoder-only(GPT)
掩码单向自注意力,适合文本生成
用途:对话、写作、代码生成
Encoder-Decoder(T5)
完整架构,适合序列转换
用途:翻译、摘要、文本改写
5. 适用场景
自然语言处理(NLP)
计算机视觉(ViT)
语音处理
多模态学习
时间序列分析
6. 结构示意图
7. 代码示例
八、图神经网络 GNN
1. 概念释义
专门为处理图结构数据设计的神经网络
通过消息传递机制,让节点从邻居节点获取信息
核心思想:节点的表示由自身特征和邻居特征共同决定
适用于社交网络、分子结构、知识图谱等非欧几里得数据
2. 核心组件
图结构
节点(Vertex):实体,如用户、分子、商品
边(Edge):节点之间的关系,如好友关系、化学键
邻接矩阵:表示节点之间的连接关系
消息传递(Message Passing)
节点从邻居收集信息并更新自身表示
公式:h_v^(k) = AGGREGATE({h_u^(k-1) | u ∈ N(v)})
常见聚合函数:求和、均值、最大值、注意力
图卷积层
对图数据进行卷积操作
常见类型:GCN、GAT、GraphSAGE
3. 常见GNN类型
GCN(图卷积网络)
使用拉普拉斯矩阵进行卷积
简单高效,适合同构图
公式:H^(l+1) = σ(Ã · H^(l) · W^(l))
GAT(图注意力网络)
使用注意力机制聚合邻居信息
可以自适应学习不同邻居的重要性
适合异构图和关系图
GraphSAGE
通过采样邻居节点进行归纳学习
适合大规模图数据
无需预计算整个图的嵌入
4. 核心特点
优点
天然适合图结构数据
能够捕捉节点之间的复杂关系
归纳能力强,可处理未见过的节点
缺点
计算复杂度高,难以处理超大规模图
需要图结构信息,数据准备复杂
可解释性较差
5. 适用场景
社交网络分析(推荐系统)
分子结构预测(药物发现)
知识图谱推理
交通流量预测
蛋白质结构分析
6. 代码示例
九、生成对抗网络 GAN
1. 概念释义
由生成器和判别器组成的对抗性学习框架
生成器试图生成逼真的数据,判别器试图区分真实数据和生成数据
两者相互博弈,共同提升性能
核心思想:最小最大博弈,生成器最小化判别器的辨别能力,判别器最大化辨别能力
2. 核心组件
生成器(Generator)
从随机噪声中生成数据
学习真实数据的分布
结构:噪声输入→多层神经网络→生成数据
判别器(Discriminator)
判断输入数据是真实的还是生成的
输出概率值(0-1)
结构:数据输入→多层神经网络→概率输出
对抗训练
生成器目标:让判别器把生成数据判断为真实数据
判别器目标:正确区分真实数据和生成数据
交替训练,逐步提升生成质量
3. 核心特点
优点
生成质量高,可生成逼真的图像、文本
无需标注数据(无监督学习)
多样性好,可生成不同风格的样本
缺点
训练不稳定,容易模式崩溃
难以控制生成内容
评估困难,缺乏统一的评价指标
4. 常见变体
DCGAN(深度卷积GAN)
使用卷积神经网络作为生成器和判别器
适合图像生成任务
StyleGAN
引入风格控制,可生成不同风格的图像
支持分辨率逐渐提升的训练策略
CycleGAN
实现无配对图像转换
如马→斑马、夏天→冬天
GPT(生成式预训练Transformer)
虽然通常不归为GAN,但也是一种生成模型
使用Transformer解码器进行自回归生成
5. 适用场景
图像生成(如人脸生成、艺术创作)
图像转换(风格迁移、图像修复)
文本生成(对话、写作)
数据增强(生成训练样本)
6. 代码示例
十、各学习机制对比汇总
1. 核心特性对比表
特性
数据流向
序列处理
长距离依赖
并行计算
参数共享
记忆能力
注意力机制
适用数据
FFNN
前馈
不支持
不支持
支持
无
无
无
结构化数据
CNN
前馈
不支持
有限
支持
卷积核共享
无
无
图像、网格
RNN
循环
支持
弱
不支持
时间步共享
弱
无
序列数据
LSTM
循环
支持
强
不支持
时间步共享
强
无
序列数据
GRU
循环
支持
中
不支持
时间步共享
中
无
序列数据
Transformer
前馈+注意力
支持
极强
支持
层内共享
强
核心组件
序列、图像
GNN
消息传递
不直接支持
依赖图结构
部分支持
图结构共享
依赖邻居
可选
图数据
GAN
对抗
支持
不适用
支持
网络内共享
无
无
图像、文本
2. 优缺点对比表
机制
FFNN
CNN
RNN
LSTM
GRU
Transformer
GNN
GAN
优点
简单、快速、易实现
权值共享、自动特征提取、平移不变性
天然支持序列、参数共享
解决梯度消失、长距离依赖、门控灵活
结构简单、效率高、性能接近LSTM
并行计算、长距离依赖、通用架构
适合图数据、捕捉关系、归纳能力强
生成质量高、无需标注、多样性好
缺点
无记忆、不支持序列、参数多
无序列建模、全局信息有限
梯度消失、串行计算、记忆有限
结构复杂、计算开销大、串行
表达能力略低、仍有梯度问题
计算复杂、内存消耗大、数据需求高
计算复杂、数据准备难、可解释性差
训练不稳定、难以控制、评估困难
3. 适用场景对比表
任务类型
图像分类
目标检测
图像生成
文本分类
机器翻译
对话生成
时间序列预测
社交网络分析
分子结构预测
推荐系统
推荐机制
CNN
CNN
GAN、扩散模型
RNN、LSTM、Transformer
Transformer
Transformer(Decoder-only)
LSTM、GRU
GNN
GNN
GNN、Transformer
原因
自动提取视觉特征、平移不变性
局部特征提取能力强
生成质量高、多样性好
捕捉文本语义
并行计算、长距离依赖
自回归生成、上下文理解
处理时序依赖
处理图结构关系
分子是天然图结构
捕捉用户-物品关系
4. 发展趋势对比
机制
FFNN
CNN
RNN
LSTM
GRU
Transformer
GNN
GAN
提出时间
1980s
1998(LeNet)
1986
1997
2014
2017
2016
2014
当前状态
基础组件,仍在使用
视觉领域主导
逐渐被LSTM/GRU取代
仍在使用,但被Transformer超越
轻量级替代方案
当前主导架构
快速发展中
图像生成主导
发展趋势
作为其他网络的基础层
与Transformer融合(ViT)
基本被Transformer取代
特定场景仍有优势
资源受限场景使用
继续优化效率(如Sparse Transformer)
图+Transformer融合
与扩散模型竞争
十一、选择建议
1. 根据数据类型选择
图像数据
首选:CNN、ViT(视觉Transformer)
原因:自动特征提取、平移不变性
序列数据(文本、语音)
首选:Transformer(GPT、BERT)
备选:LSTM、GRU(资源受限场景)
图数据(社交网络、分子)
首选:GNN(GCN、GAT、GraphSAGE)
原因:专门处理图结构
结构化数据(表格)
首选:FFNN、Transformer
原因:简单直接,特征工程重要
2. 根据任务类型选择
分类/回归任务
数据量小:FFNN、简单CNN
数据量大:Transformer
图结构:GNN
生成任务
图像生成:GAN、扩散模型
文本生成:Transformer(Decoder-only)
序列转换:Transformer(Encoder-Decoder)
关系推理任务
首选:GNN、Transformer
原因:捕捉实体间关系
3. 根据资源约束选择
计算资源充足(GPU集群)
首选:Transformer、大型模型
原因:并行计算,可训练大规模模型
资源受限(移动端、边缘设备)
首选:轻量级CNN、GRU、量化模型
原因:计算效率高,内存占用小
4. 根据训练数据量选择
数据量小(几千-几万样本)
首选:预训练模型微调(BERT、ViT)
原因:利用预训练知识,减少数据需求
数据量大(百万+样本)
首选:从头训练Transformer、大型CNN
原因:充分利用数据,训练更好的模型
十二、常见问题解答
1. Transformer是否完全取代了RNN/LSTM?
大部分场景是的,Transformer在并行计算和长距离依赖上有明显优势
但在某些特定场景(如实时语音识别、资源受限设备),LSTM/GRU仍有优势
2. CNN和Transformer谁更适合图像任务?
CNN适合局部特征提取,计算效率高
Transformer(ViT)适合全局特征理解,需要更多数据
当前趋势是两者融合(如ConvNeXt、Swin Transformer)
3. GNN和Transformer的关系?
GNN处理图结构数据,Transformer处理序列数据
可以将图数据线性化为序列输入Transformer
也可以在GNN中引入注意力机制(如GAT)
4. GAN和扩散模型谁更好?
GAN生成质量高,但训练不稳定
扩散模型训练稳定,但推理速度慢
当前扩散模型更流行,如Stable Diffusion
5. 如何选择合适的学习机制?
看数据类型:图像→CNN/ViT,文本→Transformer,图→GNN
看任务类型:分类→任意,生成→Transformer/GAN
看资源约束:充足→大模型,受限→轻量级模型
十三、学习路径建议
入门阶段
理解神经网络基础(FFNN、反向传播)
学习CNN(卷积、池化、经典架构)
学习RNN(循环结构、梯度消失问题)
进阶阶段
深入理解LSTM/GRU(门控机制)
掌握Transformer(自注意力、多头注意力)
学习GNN(消息传递、图卷积)
高级阶段
学习预训练模型(BERT、GPT、ViT)
掌握生成模型(GAN、扩散模型)
研究最新论文,跟踪前沿进展
实践建议
从简单任务开始(MNIST分类、文本分类)
尝试中等难度任务(图像分类、机器翻译)
挑战复杂任务(大模型微调、多模态学习)
十四、常用工具与框架
深度学习框架
PyTorch:灵活易用,研究首选
TensorFlow:工业界广泛使用
JAX:Google推出,函数式编程
预训练模型库
Hugging Face Transformers:最全预训练模型集合
PyTorch Hub:PyTorch官方模型库
TensorFlow Hub:TensorFlow官方模型库
图神经网络库
PyTorch Geometric:PyTorch生态的GNN库
DGL(Deep Graph Library):通用GNN框架
Spektral:TensorFlow/Keras生态的GNN库
可视化工具
TensorBoard:训练过程可视化
Weights & Biases:实验管理平台
Netron:神经网络结构可视化
十五、总结
核心要点
<b>FFNN</b>是基础,适合简单任务
<b>CNN</b>适合图像,自动提取特征
<b>RNN/LSTM/GRU</b>适合序列,处理时序依赖
<b>Transformer</b>是当前主导,并行计算+长距离依赖
<b>GNN</b>适合图数据,处理关系推理
<b>GAN</b>适合生成任务,对抗训练
发展趋势
Transformer继续主导NLP和多模态领域
CNN与Transformer融合(如ViT、Swin)
GNN快速发展,处理复杂关系数据
大模型预训练+微调成为主流范式
学习建议
理解每种机制的核心思想和适用场景
通过实践代码加深理解
跟踪最新论文和技术进展
从简单到复杂,逐步提升能力
CNN卷积神经网络思维导图
一、CNN 基础概念
1. 什么是卷积神经网络
CNN是专门为处理网格结构数据(如图像)设计的深度学习模型
通过卷积操作自动提取图像中的局部特征,如边缘、纹理、形状等
核心思想:局部感受野、权值共享、池化降采样
与传统全连接网络相比,CNN参数量更少,训练效率更高
2. CNN 的发展历程
早期阶段(1980-1990)
1980年:Fukushima提出Neocognitron,CNN的雏形
1998年:LeCun提出LeNet-5,第一个现代CNN,用于手写数字识别
发展阶段(2010-2015)
2012年:AlexNet,深度学习里程碑,首次使用GPU加速
2014年:VGGNet,更深的网络结构,使用3×3小卷积核
2014年:GoogLeNet(Inception),多尺度特征融合
成熟阶段(2015-至今)
2015年:ResNet,残差连接解决梯度消失问题
2016年:DenseNet,密集连接网络
2019年:EfficientNet,高效网络设计
3. CNN 的核心思想
局部感受野(Local Receptive Field)
每个神经元只关注输入图像的一小部分区域
类似人眼观察图像时,先看局部再整合全局
感受野大小由卷积核大小决定
权值共享(Weight Sharing)
同一个卷积核在整幅图像上共享参数
大幅减少参数量,避免过拟合
假设图像的特征在不同位置具有相同的统计特性
池化降采样(Pooling)
对特征图进行降采样,保留重要信息
减少计算量和内存占用
增加平移不变性
4. CNN 与全连接网络的对比
特性
参数数量
特征提取
平移不变性
空间信息保留
训练效率
适用数据
全连接网络
多(如224×224×3图像需要约3800万参数)
需要人工设计特征
不具备
丢失
低
结构化数据
CNN
少(通过权值共享)
自动提取特征
具备
保留
高
图像、网格数据
二、CNN 核心组件详解
1. 卷积层(Convolutional Layer)
概念释义
卷积层是CNN的核心,负责提取图像特征
使用卷积核(Filter/Kernel)扫描输入特征图
每个卷积核提取一种特定类型的特征,如边缘、纹理、角点等
多个卷积核并行工作,提取多种特征
卷积核(Kernel/Filter)
小型矩阵,通常为3×3、5×5、7×7
包含可学习的权重参数
卷积核的深度(通道数)与输入特征图的通道数一致
卷积操作过程
将卷积核放在输入特征图的左上角
对应位置元素相乘后求和,得到输出特征图的一个值
按步长(Stride)滑动卷积核,重复上述过程
直到扫描完整个输入特征图
代码示例(手动实现卷积)
输出结果
PyTorch 实现
输出结果
卷积参数详解
步长(Stride)
卷积核每次滑动的像素数
步长为1:逐个像素滑动,输出尺寸与输入相近
步长为2:隔一个像素滑动,输出尺寸减半
作用:控制输出特征图的尺寸
填充(Padding)
在输入特征图周围添加额外的像素(通常为0)
作用:
保持输出特征图尺寸与输入一致(Same Padding)
避免边缘信息丢失
控制感受野大小
输出尺寸计算公式
2. 池化层(Pooling Layer)
概念释义
池化层对卷积层输出的特征图进行降采样
保留重要特征,减少参数数量和计算量
增加模型的平移不变性,即图像轻微移动不影响识别结果
最大池化(Max Pooling)
选取区域内的最大值作为输出
保留最显著的特征(如边缘、角点)
最常用的池化方式
平均池化(Average Pooling)
计算区域内所有值的平均值作为输出
保留区域的整体信息
常用于网络末端的特征汇总
代码示例
输出结果
全局平均池化(Global Average Pooling)
对整个特征图进行平均池化
每个通道输出一个值
替代全连接层,减少参数数量
代码示例
输出结果
3. 激活函数(Activation Function)
概念释义
激活函数为网络引入非线性,增强模型表达能力
如果没有激活函数,网络只能学习线性关系
常用激活函数:ReLU、GELU、Swish、Sigmoid、Tanh
ReLU(Rectified Linear Unit)
公式:f(x) = max(0, x)
特点:计算简单、梯度消失问题缓解
缺点:部分神经元可能永久失活(Dying ReLU)
Leaky ReLU
公式:f(x) = max(αx, x),α通常为0.01
解决ReLU的神经元失活问题
GELU(Gaussian Error Linear Units)
公式:f(x) = x·Φ(x),Φ(x)是标准正态分布的CDF
特点:平滑、性能优于ReLU
现代大模型的首选激活函数
代码示例
输出结果
4. 归一化层(Normalization Layer)
概念释义
归一化层对网络中间层的输出进行标准化处理
稳定训练过程,加速收敛
常用归一化方式:BatchNorm、LayerNorm、InstanceNorm、GroupNorm
Batch Normalization(BN)
对每个批次的样本进行归一化
计算每个特征在批次上的均值和方差
作用:加速收敛、缓解内部协变量偏移
Layer Normalization(LN)
对每个样本的所有特征进行归一化
不依赖批次大小,适合小批次训练
Transformer中常用
代码示例
5. 全连接层(Fully Connected Layer)
概念释义
全连接层将卷积提取的特征映射到最终输出
每个神经元与前一层所有神经元连接
用于分类或回归任务的最终决策
代码示例
6. Dropout层
概念释义
Dropout随机屏蔽部分神经元,防止过拟合
训练时随机丢弃,测试时全部保留
常用丢弃率:0.1-0.5
代码示例
三、CNN 经典架构详解
1. LeNet-5
架构概述
1998年由LeCun提出,第一个现代CNN
用于手写数字识别(MNIST数据集)
结构简单,包含卷积层、池化层、全连接层
网络结构
代码示例
2. AlexNet
架构概述
2012年由Alex Krizhevsky提出
深度学习的里程碑,首次使用GPU加速训练
在ImageNet竞赛中取得突破性成绩
核心创新
使用ReLU激活函数替代Tanh
使用Dropout防止过拟合
使用数据增强(翻转、裁剪、颜色变换)
使用GPU并行训练
网络结构
代码示例
3. VGGNet
架构概述
2014年由牛津大学Visual Geometry Group提出
使用3×3小卷积核堆叠,替代大卷积核
结构规整,易于扩展
核心创新
使用多个3×3卷积核替代一个大卷积核(如3个3×3替代1个7×7)
感受野相同,但参数量更少(3×(3×3×C²) vs 7×7×C²)
引入非线性激活函数的次数更多
VGG-16结构
代码示例
4. GoogLeNet(Inception)
架构概述
2014年由Google提出
使用Inception模块,多尺度特征融合
参数量比AlexNet少,但精度更高
Inception模块
并行使用不同大小的卷积核(1×1、3×3、5×5)
使用1×1卷积进行降维,减少计算量
同时进行最大池化
最后拼接所有分支的输出
代码示例(Inception模块)
5. ResNet
架构概述
2015年由微软研究院提出
引入残差连接(Residual Connection),解决梯度消失问题
可训练数百层甚至上千层网络
深度学习领域的里程碑
残差连接原理
问题:深层网络训练时梯度消失,无法有效训练
解决方案:引入捷径连接,让梯度直接跳过某些层
公式:H(x) = F(x) + x,其中F(x)是残差函数
ResNet模块
ResNet-18结构
6. EfficientNet
架构概述
2019年由Google提出
使用复合缩放方法,同时优化深度、宽度、分辨率
在参数量和计算量更少的情况下,精度超过之前的模型
复合缩放原理
深度缩放(Depth):增加网络层数
宽度缩放(Width):增加卷积核数量
分辨率缩放(Resolution):增加输入图像尺寸
公式:depth = α^φ, width = β^φ, resolution = γ^φ,其中α·β²·γ² ≈ 2
代码示例(使用预训练模型)
四、CNN 训练技巧
1. 数据预处理
图像归一化
将像素值从[0, 255]归一化到[0, 1]或[-1, 1]
使用数据集的均值和标准差进行标准化
代码示例
数据增强(Data Augmentation)
随机翻转、裁剪、旋转、颜色变换
增加训练数据多样性,防止过拟合
代码示例
2. 优化器选择
SGD(随机梯度下降)
基础优化器,学习率固定或手动调整
适合大规模训练
Adam(自适应矩估计)
自适应学习率,训练更稳定
当前最常用的优化器
AdamW
Adam的改进版本,权重衰减更有效
现代大模型训练的首选
代码示例
3. 学习率调度
余弦退火(Cosine Annealing)
学习率按余弦曲线周期性变化
效果稳定,当前主流选择
学习率预热(Warmup)
训练初期使用较小学习率,逐步增加到目标学习率
稳定训练初期的梯度
代码示例
4. 正则化方法
Weight Decay(权重衰减)
对权重参数施加L2正则化
防止模型过拟合
Dropout
随机丢弃部分神经元
在全连接层或卷积层后使用
Label Smoothing(标签平滑)
将硬标签转换为软标签
防止模型过度自信
代码示例
5. 训练循环
完整训练循环代码
五、CNN 应用场景
1. 图像分类
任务描述
给定一张图像,判断其所属类别
如:猫、狗、汽车、飞机等
常用数据集
MNIST:手写数字识别(10类)
CIFAR-10:10类物体识别(32×32图像)
ImageNet:1000类图像分类(224×224图像)
代码示例(使用预训练模型)
2. 目标检测
任务描述
在图像中检测多个物体的位置和类别
输出物体的边界框和类别标签
常用算法
YOLO(You Only Look Once):实时检测,速度快
Faster R-CNN:精度高,速度较慢
SSD:平衡速度和精度
代码示例(使用YOLO)
3. 图像分割
任务描述
将图像中的每个像素分类到特定类别
如:语义分割(每个像素一个类别)、实例分割(区分同一类别的不同实例)
常用算法
U-Net:医学图像分割
Mask R-CNN:实例分割
DeepLab:语义分割
代码示例(U-Net)
4. 图像生成
任务描述
根据输入生成新的图像
如:文本到图像、图像超分辨率、风格迁移
常用算法
GAN(生成对抗网络)
扩散模型(Diffusion Models)
VAE(变分自编码器)
代码示例(使用Stable Diffusion)
5. 人脸识别
任务描述
识别图像中的人脸并匹配身份
用于身份验证、监控等场景
常用算法
FaceNet
ArcFace
InsightFace
六、CNN 常见问题与解决方案
1. 过拟合问题
表现
训练集准确率高,验证集准确率低
模型在训练数据上表现很好,但泛化能力差
解决方案
增加训练数据量
使用数据增强
添加Dropout层
使用权重衰减(Weight Decay)
提前停止训练(Early Stopping)
使用更简单的模型
2. 梯度消失问题
表现
训练过程中梯度趋近于0
深层网络难以训练
解决方案
使用ReLU激活函数
使用残差连接(ResNet)
使用批量归一化(BatchNorm)
调整学习率
3. GPU内存不足
表现
训练时出现"Out of Memory"错误
无法加载大型模型或大数据批次
解决方案
减小批次大小(Batch Size)
使用梯度累积
使用半精度训练(FP16)
使用模型并行或数据并行
使用更小的模型
4. 训练速度慢
表现
每个epoch需要很长时间
大规模数据集训练困难
解决方案
使用GPU训练
使用多GPU并行训练
使用数据加载器的num_workers参数
使用混合精度训练
使用预训练模型微调
5. 模型不收敛
表现
训练损失不下降或波动很大
模型输出始终为随机值
解决方案
检查数据预处理是否正确
调整学习率
检查损失函数是否正确
检查优化器配置
增加训练轮数
七、CNN 与其他架构的对比
1. CNN vs RNN
特性
数据类型
计算方式
空间信息
时间依赖
训练速度
适用场景
CNN
图像、网格数据
并行计算
保留
不支持
快
图像分类、目标检测
RNN
序列数据
串行计算
丢失
支持
慢
文本生成、语音识别
2. CNN vs Transformer
特性
核心机制
局部特征
全局特征
计算复杂度
训练数据需求
适用场景
CNN
卷积操作
强
弱
O(n²·k²),k为卷积核大小
相对较少
图像处理
Transformer
自注意力机制
弱
强
O(n²·d),d为特征维度
大量数据
自然语言处理、多模态
3. CNN vs ViT(视觉Transformer)
特性
特征提取方式
局部感受野
全局依赖
数据需求
计算效率
精度
CNN
卷积操作
天然支持
需要深层堆叠
适中
高
高(传统图像任务)
ViT
自注意力机制
需要足够数据学习
直接建模
大量
低(长序列)
高(大规模数据)
八、学习路径建议
入门阶段
理解CNN基础概念(卷积、池化、激活函数)
实现简单的CNN模型(如LeNet-5)
在MNIST数据集上进行训练和测试
进阶阶段
学习经典CNN架构(AlexNet、VGG、ResNet)
理解残差连接、批量归一化等核心技术
在CIFAR-10、ImageNet数据集上训练模型
高级阶段
学习目标检测、图像分割等高级任务
掌握数据增强、正则化等训练技巧
研究最新论文,如EfficientNet、Swin Transformer
实践建议
从简单任务开始(MNIST分类)
使用PyTorch官方教程学习
尝试复现经典论文
参加Kaggle竞赛积累经验
九、常用工具与资源
深度学习框架
PyTorch:灵活易用,研究首选
TensorFlow:工业界广泛使用
JAX:Google推出,函数式编程
数据集
MNIST:手写数字识别
CIFAR-10/100:图像分类
ImageNet:大规模图像分类
COCO:目标检测、分割
预训练模型库
torchvision:PyTorch官方模型库
Hugging Face Transformers:最全预训练模型
TensorFlow Hub:TensorFlow官方模型库
可视化工具
TensorBoard:训练过程可视化
Weights & Biases:实验管理平台
Netron:神经网络结构可视化
学习资源
Stanford CS231n:卷积神经网络课程
PyTorch官方教程:<a href="https://pytorch.org/tutorials/">https://pytorch.org/tutorials/</a>
Fast.ai课程:深度学习实战
十、总结
CNN 核心要点
<b>卷积层</b>:自动提取局部特征,权值共享减少参数
<b>池化层</b>:降采样,增加平移不变性
<b>激活函数</b>:引入非线性,增强表达能力
<b>归一化层</b>:稳定训练,加速收敛
<b>残差连接</b>:解决深层网络梯度消失问题
CNN 经典架构演变
LeNet-5(1998):现代CNN雏形
AlexNet(2012):深度学习里程碑
VGG(2014):小卷积核堆叠
GoogLeNet(2014):多尺度特征融合
ResNet(2015):残差连接突破深度限制
EfficientNet(2019):复合缩放优化效率
CNN 应用领域
图像分类、目标检测、图像分割
图像生成、图像超分辨率
人脸识别、医学影像分析
自动驾驶、安防监控
学习建议
理解每个组件的作用和原理
通过代码实践加深理解
从简单模型到复杂模型逐步学习
关注最新研究进展
Dify,Coze,LangChain对比
子主题
子主题
子主题
LangGraph 常用方法思维导图
一、LangGraph 简介
1. 什么是 LangGraph
LangGraph 是 LangChain 生态中的工作流编排框架
基于状态机实现节点、边的编排
支持循环、条件分支、并行执行
适合构建复杂的多步骤 Agent
2. LangGraph vs LangChain
特性
用途
状态管理
循环支持
条件分支
并行执行
LangChain
链式调用、简单工作流
有限
有限
有限
有限
LangGraph
复杂状态机、多步骤流程
完整的状态管理
原生支持
完整支持
支持
3. 核心概念
State(状态)
贯穿整个工作流的数据结构
通常使用 TypedDict 定义
每个节点读取和更新状态
Node(节点)
工作流中的一个步骤
是一个函数,接收状态并返回更新后的状态
可以是 LLM 调用、工具调用、数据处理等
Edge(边)
节点之间的连接关系
定义数据流向
可以是条件边或无条件边
Graph(图)
由节点和边组成的完整工作流
使用 StateGraph 构建
需要编译后才能运行
4. 安装方法
基础安装
完整安装
验证安装
二、核心组件
1. State(状态定义)
使用 TypedDict
使用 Pydantic
状态更新
2. Node(节点定义)
基础节点
带工具调用的节点
条件节点
3. Edge(边定义)
无条件边
条件边
多条条件边
4. Graph(图构建)
基础图构建
带循环的图
三、工作流模式
1. 顺序执行
简单顺序
带条件的顺序
2. 循环执行
ReAct 循环
有限循环
3. 条件分支
多路分支
正确的多路分支
4. 并行执行
简单并行
使用线程的并行
四、高级特性
1. 检查点(Checkpointing)
启用检查点
恢复检查点
自定义检查点存储
2. 消息历史
集成 LangChain 记忆
3. 工具调用集成
完整工具调用流程
4. RAG 集成
检索增强工作流
5. 子图
创建子图
五、可视化
1. 绘制工作流图
使用 ASCII 图
使用 Mermaid 图
Mermaid 示例输出
2. LangSmith 追踪
启用 LangSmith
查看追踪
访问 <a href="https://smith.langchain.com/">https://smith.langchain.com/</a>
查看工作流执行的每一步
检查状态变化和 LLM 调用
六、实战示例
1. 聊天机器人
完整示例
2. 研究助手
带工具调用的 Agent
3. 代码审查助手
多步骤工作流
4. 多 Agent 协作
专家团队工作流
七、注意事项
1. 常见错误
状态更新错误
循环条件错误
节点名称冲突
2. 性能优化
缓存中间结果
异步节点
3. 调试技巧
打印状态变化
使用 LangSmith
八、常用速查表
核心组件
组件
StateGraph
add_node()
set_entry_point()
add_edge()
add_conditional_edges()
END
compile()
invoke()
说明
创建状态图
添加节点
设置入口点
添加无条件边
添加条件边
结束节点
编译工作流
调用工作流
代码
StateGraph(AgentState)
workflow.add_node("name", func)
workflow.set_entry_point("name")
workflow.add_edge("from", "to")
workflow.add_conditional_edges("node", fn, mapping)
workflow.add_edge("node", END)
app = workflow.compile()
app.invoke(input_data)
状态定义
方式
TypedDict
Pydantic
dict
说明
类型安全的状态
带验证的状态
简单字典
代码
class State(TypedDict): ...
class State(BaseModel): ...
state = {"key": value}
节点类型
类型
处理节点
路由节点
条件节点
工具节点
说明
执行具体操作
决定流向
返回布尔值
调用外部工具
示例
def process(state): ...
def route(state): return "node_name"
def check(state): return True
def execute_tool(state): ...
检查点
操作
内存检查点
编译时启用
指定 session_id
自定义存储
代码
checkpointer = MemorySaver()
app = workflow.compile(checkpointer=checkpointer)
config={"configurable": {"thread_id": "user1"}}
class CustomCheckpointSaver(BaseCheckpointSaver): ...
可视化
方法
draw_ascii()
draw_mermaid()
LangSmith
说明
绘制 ASCII 图
生成 Mermaid 代码
详细追踪
代码
app.get_graph().draw_ascii()
app.get_graph().draw_mermaid()
os.environ["LANGCHAIN_TRACING_V2"] = "true"
工作流模式
模式
顺序执行
循环执行
条件分支
并行执行
子图
说明
依次执行节点
重复执行节点
根据条件选择路径
同时执行多个节点
嵌套工作流
实现方式
add_edge() 链式连接
add_conditional_edges() + add_edge()
add_conditional_edges()
threading/multiprocessing
编译子图后作为节点调用
常用工具集成
工具
ChatOpenAI
@tool
bind_tools()
RetrievalQA
ChatMessageHistory
用途
大模型调用
自定义工具
绑定工具到模型
检索问答
对话历史
代码
llm = ChatOpenAI(model="gpt-3.5-turbo")
@tool def func(): ...
llm_with_tools = llm.bind_tools(tools)
RetrievalQA.from_chain_type(llm, retriever)
ChatMessageHistory()
常见配置
配置项
thread_id
checkpointing
verbose
tracing
说明
会话 ID
启用检查点
详细输出
LangSmith 追踪
示例
{"configurable": {"thread_id": "user1"}}
compile(checkpointer=MemorySaver())
os.environ["LANGCHAIN_VERBOSE"] = "true"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
Dify AI应用开发平台思维导图(2026-06-25)
一、Dify 基础概念
1. 什么是 Dify
Dify 是一个开源的 AI 应用开发平台,允许用户通过可视化方式构建 AI 应用
提供完整的 AI 应用开发、部署和管理功能
支持多种大模型(如 OpenAI、DeepSeek、阿里云百炼等)
核心特点:低代码/无代码、可视化编排、多模型支持、插件扩展
2. Dify 的核心价值
快速构建 AI 应用
无需编写大量代码,通过可视化界面即可构建复杂 AI 应用
支持对话机器人、智能客服、知识库问答等多种场景
统一模型管理
集成多种大模型,统一 API 调用方式
支持模型切换,无需修改应用代码
提供模型性能对比和成本分析
完整的开发工具链
提供 Prompt 调试、测试、版本管理等工具
支持应用部署到云端或本地
提供详细的使用统计和分析
3. Dify 与其他平台的对比
特性
开发方式
模型支持
知识库
部署方式
插件系统
适用人群
Dify
可视化 + 代码
多种模型
内置支持
云端/本地
支持
开发者/非开发者
LangChain
纯代码
多种模型
需要集成
需要自行部署
丰富
开发者
Coze
可视化
多种模型
内置支持
云端
支持
非开发者
4. Dify 的架构设计
核心组件
API Gateway:统一 API 入口
Model Provider:模型服务管理
Prompt Engine:Prompt 引擎
Knowledge Base:知识库管理
Plugin System:插件系统
架构特点
模块化设计,易于扩展
支持水平扩展,高可用性
数据隔离,多租户支持
二、Dify 安装与部署
1. 环境要求
系统要求
操作系统:Linux、Windows、macOS
Python:3.8+
Docker:20.10+
依赖服务
PostgreSQL:数据库
Redis:缓存
MinIO:对象存储(可选)
2. Docker 部署(推荐)
安装 Docker
下载 Dify
启动服务
访问界面
Web 界面:<a href="http://localhost:8080">http://localhost:8080</a>
默认用户名:<a href="mailto:admin@dify.ai">admin@dify.ai</a>
默认密码:password
3. 本地开发部署
安装依赖
配置环境变量
初始化数据库
启动服务
4. 云服务部署
Dify Cloud
官方托管服务,无需自行部署
访问地址:<a href="https://cloud.dify.ai">https://cloud.dify.ai</a>
免费版提供基础功能,付费版提供更多资源
一键部署到云平台
支持阿里云、腾讯云、华为云等
提供一键部署脚本
参考官方文档:<a href="https://docs.dify.ai/docs/getting-started/deployment">https://docs.dify.ai/docs/getting-started/deployment</a>
三、Dify 核心功能详解
1. 应用类型
对话应用(Chat App)
创建智能对话机器人
支持多轮对话、上下文管理
适用于客服、助手、教育等场景
知识库应用(Knowledge App)
创建基于知识库的问答系统
支持文档上传、向量检索
适用于企业知识库、产品手册等场景
工作流应用(Workflow App)
创建复杂的 AI 工作流
支持多步骤编排、条件分支、循环
适用于数据分析、内容生成、自动化任务等场景
2. 模型管理
模型配置
添加模型
进入「模型配置」页面
点击「添加模型」
选择模型类型(如 OpenAI、DeepSeek、阿里云百炼等)
填写 API Key 和其他配置
点击「保存」
模型参数
API Key:模型服务的密钥
Base URL:模型服务的地址(默认或自定义)
最大 token 数:单次请求的最大 token 数
温度:控制生成内容的随机性(0-1)
超时时间:请求超时时间
模型测试
测试模型
在模型配置页面点击「测试」
输入测试文本
查看模型返回结果
验证模型配置是否正确
模型对比
对比不同模型
进入「模型对比」页面
选择需要对比的模型
输入测试文本
查看各模型的返回结果和性能指标
3. Prompt 工程
Prompt 编辑器
可视化编辑
支持富文本编辑
支持变量插入(如用户输入、上下文信息)
支持条件语句
支持代码块
Prompt 模板
提供多种预设模板(如问答、总结、翻译等)
支持自定义模板
支持模板版本管理
Prompt 调试
调试工具
实时预览 Prompt 效果
查看完整的 Prompt 内容(包括变量替换后的结果)
支持历史记录回溯
支持 A/B 测试
调试步骤
在 Prompt 编辑器中编写 Prompt
点击「调试」按钮
输入测试输入
查看模型返回结果
根据结果调整 Prompt
Prompt 优化技巧
明确指令
清晰说明任务要求
使用结构化的指令格式
提供示例
提供少量示例帮助模型理解
使用 few-shot learning
控制输出格式
指定输出格式(如 JSON、Markdown)
使用约束条件
4. 知识库管理
文档上传
支持的文档格式
文本文件:.txt、.md、.json
办公文档:.docx、.xlsx、.pptx
PDF 文件:.pdf
网页内容:URL 链接
上传步骤
进入「知识库」页面
点击「新建知识库」
输入知识库名称和描述
上传文档或添加 URL
点击「开始处理」
文档处理
文档解析
自动解析文档内容
支持表格、图片、公式等内容提取
处理大文档时自动分段
向量索引
将文档内容转换为向量
使用向量数据库进行存储和检索
支持多种向量数据库(如 Milvus、Chroma、Qdrant)
索引配置
分块大小:文档分段的大小(默认 500 字符)
重叠大小:分段之间的重叠字符数(默认 50)
向量模型:用于生成向量的模型
知识库问答
检索增强生成(RAG)
用户提问时,先检索知识库中相关内容
将检索结果作为上下文输入给模型
模型基于上下文生成回答
问答配置
检索数量:每次检索的文档片段数量
相似度阈值:检索结果的相似度阈值
上下文拼接方式:如何将多个检索结果拼接
代码示例(使用 Dify API 进行知识库问答)
5. 插件系统
插件类型
官方插件
Web Search:网页搜索
Calculator:计算器
Weather:天气查询
Date/Time:日期时间
File Read/Write:文件读写
自定义插件
支持创建自定义插件
插件可以调用外部 API
支持 Python、JavaScript 等语言
创建插件
步骤
进入「插件中心」页面
点击「创建插件」
填写插件信息(名称、描述、图标等)
定义插件参数
编写插件代码
测试插件
发布插件
插件代码示例(Python)
使用插件
在对话中使用
在应用配置中启用插件
在 Prompt 中调用插件
模型会自动判断何时调用插件
在工作流中使用
在工作流编辑器中添加插件节点
配置插件参数
连接插件节点到其他节点
6. 工作流编排
工作流编辑器
可视化界面
拖拽式节点编排
支持多种节点类型(模型调用、插件调用、条件判断、循环等)
实时预览工作流结构
节点类型
模型节点
调用大模型生成内容
支持多种模型
配置模型参数
插件节点
调用插件执行特定任务
支持官方和自定义插件
条件节点
根据条件判断执行路径
支持多种条件判断(等于、包含、正则等)
循环节点
循环执行一组节点
支持固定次数循环和条件循环
变量节点
定义和修改变量
支持多种变量类型
工作流示例(内容生成工作流)
场景描述
用户输入一个主题
系统先搜索相关信息
然后调用模型生成文章
最后保存文章到文件
工作流结构
配置步骤
创建工作流应用
添加「变量节点」,命名为「主题」
添加「插件节点」,选择「网页搜索」,配置搜索关键词为「主题」变量
添加「变量节点」,命名为「搜索结果」,保存搜索结果
添加「模型节点」,配置 Prompt 使用「搜索结果」变量生成文章
添加「插件节点」,选择「保存文件」,配置文件名和内容
连接所有节点
测试工作流
7. 应用部署
部署方式
API 部署
生成 API 密钥
通过 REST API 调用应用
支持同步和异步调用
网页嵌入
生成嵌入代码
嵌入到网站或应用中
支持自定义样式
移动端部署
支持 iOS 和 Android
使用官方 SDK
提供原生体验
API 调用示例
Python 示例
JavaScript 示例
网页嵌入示例
获取嵌入代码
进入应用详情页面
点击「部署」标签
选择「网页嵌入」
复制嵌入代码
嵌入代码
四、Dify 高级功能
1. 会话管理
上下文管理
自动管理对话上下文
支持上下文窗口配置
支持上下文压缩(当上下文过长时自动压缩)
会话历史
保存完整的会话历史
支持会话恢复
支持会话导出
代码示例(管理会话)
2. 用户管理
用户认证
支持 API Key 认证
支持 OAuth 认证
支持自定义认证
用户权限
支持多租户
支持角色管理(管理员、开发者、用户)
支持细粒度权限控制
用户统计
查看用户使用情况
统计 API 调用次数
分析用户行为
3. 监控与日志
实时监控
监控应用状态
监控 API 调用次数和延迟
监控模型使用情况
日志管理
记录所有 API 调用
记录模型请求和响应
支持日志导出和分析
告警设置
设置 API 调用频率告警
设置错误率告警
设置模型超时告警
4. 数据安全
数据加密
传输加密(HTTPS)
存储加密
API Key 加密存储
数据隔离
多租户数据隔离
用户数据隔离
支持数据脱敏
合规性
支持 GDPR 合规
支持数据导出和删除
提供数据处理记录
5. 性能优化
缓存机制
缓存模型响应
缓存知识库检索结果
支持自定义缓存策略
负载均衡
支持多实例部署
支持请求分发
支持自动扩缩容
异步处理
支持异步 API 调用
支持批量处理
支持任务队列
五、Dify 应用场景
1. 智能客服
场景描述
企业需要一个智能客服系统
能够自动回答常见问题
能够转接人工客服
实现步骤
创建知识库,上传产品手册和常见问题
创建对话应用,配置 Prompt
启用知识库检索功能
配置人工转接条件
部署应用
关键配置
Prompt:引导模型使用知识库回答问题
知识库检索:设置合适的相似度阈值
人工转接:设置无法回答时的转接条件
2. 企业知识库
场景描述
企业需要一个内部知识库系统
员工可以查询公司政策、流程等信息
支持自然语言查询
实现步骤
创建知识库,上传公司文档
创建知识库应用,配置检索参数
设置访问权限
部署应用
关键配置
文档分块:设置合适的分块大小
向量模型:选择合适的向量模型
权限控制:设置员工访问权限
3. 内容生成
场景描述
营销团队需要批量生成营销文案
需要根据产品信息生成不同风格的文案
需要自动优化文案质量
实现步骤
创建工作流应用
添加变量节点,定义产品信息
添加模型节点,配置多种 Prompt 模板
添加条件节点,根据产品类型选择模板
添加插件节点,保存生成的文案
测试和优化工作流
关键配置
Prompt 模板:创建多种风格的模板
变量定义:定义产品信息变量
工作流逻辑:设计合理的流程
4. 数据分析
场景描述
业务团队需要快速分析数据
能够用自然语言查询数据
能够自动生成分析报告
实现步骤
创建工作流应用
添加插件节点,连接数据库
添加模型节点,生成 SQL 查询
添加插件节点,执行 SQL 查询
添加模型节点,生成分析报告
测试和优化工作流
关键配置
数据库连接:配置数据库插件
SQL 生成:配置模型生成 SQL
报告生成:配置模型生成报告
5. 教育助手
场景描述
学生需要一个学习助手
能够解答学科问题
能够提供学习建议
实现步骤
创建知识库,上传教材和学习资料
创建对话应用,配置教育相关的 Prompt
启用知识库检索功能
配置学习进度跟踪
部署应用
关键配置
Prompt:引导模型以教育者的身份回答
知识库:上传相关学习资料
进度跟踪:使用变量记录学习进度
六、Dify 最佳实践
1. Prompt 工程最佳实践
明确任务目标
在 Prompt 中清晰说明任务要求
使用结构化的指令格式
避免模糊的表述
提供上下文信息
提供必要的背景信息
使用变量引用外部数据
保持上下文简洁
控制输出格式
指定输出格式(如 JSON、Markdown)
使用约束条件
提供输出示例
迭代优化
使用调试工具测试 Prompt
根据测试结果调整 Prompt
记录优化历史
2. 知识库最佳实践
文档准备
整理清晰的文档结构
去除无关内容
确保文档质量
索引配置
根据文档类型调整分块大小
设置合适的重叠大小
选择合适的向量模型
检索优化
设置合适的相似度阈值
调整检索数量
使用混合检索策略
维护更新
定期更新知识库内容
删除过期文档
优化检索效果
3. 工作流最佳实践
模块化设计
将复杂流程拆分为多个模块
使用变量传递数据
设计可复用的节点组合
错误处理
添加错误处理节点
设置重试机制
记录错误日志
性能优化
减少不必要的节点
使用异步处理
合理使用缓存
测试验证
测试每个节点的功能
测试完整流程
测试边界情况
4. 部署最佳实践
环境配置
根据业务需求选择部署方式
配置合适的资源(CPU、内存、存储)
设置监控和告警
安全配置
使用 HTTPS
配置 API Key 管理
设置访问权限
性能优化
使用负载均衡
配置缓存
优化数据库连接
七、Dify 常见问题与解决方案
1. 模型调用失败
原因
API Key 错误或过期
模型服务不可用
网络连接问题
解决方案
检查 API Key 是否正确
测试模型服务是否正常
检查网络连接
2. 知识库检索效果差
原因
文档质量差
分块大小不合适
向量模型不匹配
解决方案
优化文档质量
调整分块大小
尝试不同的向量模型
3. 应用响应慢
原因
模型响应慢
知识库检索慢
工作流节点过多
解决方案
使用更快的模型
优化知识库检索
简化工作流
4. 部署失败
原因
环境配置错误
依赖服务未启动
端口被占用
解决方案
检查环境配置
确保依赖服务正常运行
检查端口占用情况
5. 权限问题
原因
用户权限不足
API Key 权限不足
多租户配置错误
解决方案
检查用户权限设置
检查 API Key 权限
检查多租户配置
八、Dify 学习资源
官方文档
Dify 官方文档:<a href="https://docs.dify.ai">https://docs.dify.ai</a>
API 参考:<a href="https://docs.dify.ai/docs/api-reference">https://docs.dify.ai/docs/api-reference</a>
部署指南:<a href="https://docs.dify.ai/docs/getting-started/deployment">https://docs.dify.ai/docs/getting-started/deployment</a>
社区资源
GitHub:<a href="https://github.com/langgenius/dify">https://github.com/langgenius/dify</a>
Discord:<a href="https://discord.gg/FngNHpbcY7">https://discord.gg/FngNHpbcY7</a>
中文社区:<a href="https://github.com/langgenius/dify/discussions">https://github.com/langgenius/dify/discussions</a>
教程与示例
官方教程:<a href="https://docs.dify.ai/docs/tutorial">https://docs.dify.ai/docs/tutorial</a>
示例项目:<a href="https://github.com/langgenius/dify/tree/main/examples">https://github.com/langgenius/dify/tree/main/examples</a>
视频教程:官方 YouTube 频道
相关工具
向量数据库:Milvus、Chroma、Qdrant
大模型:OpenAI、DeepSeek、阿里云百炼
前端框架:React、Vue
九、Dify 与其他工具的集成
1. 与 LangChain 集成
使用 LangChain 作为工具
在 Dify 中创建自定义插件
调用 LangChain 的功能
扩展 Dify 的能力
代码示例
2. 与数据库集成
支持的数据库
MySQL
PostgreSQL
SQLite
MongoDB
使用步骤
创建数据库插件
配置数据库连接
在工作流中使用数据库节点
执行 SQL 查询或 NoSQL 操作
3. 与企业系统集成
常见集成场景
与 CRM 系统集成
与 ERP 系统集成
与知识库系统集成
集成方式
使用 API 调用
使用 Webhook
使用自定义插件
十、总结
Dify 核心要点
<b>可视化开发</b>:通过拖拽方式构建 AI 应用
<b>多模型支持</b>:集成多种大模型,统一管理
<b>知识库功能</b>:内置知识库管理和 RAG 功能
<b>工作流编排</b>:支持复杂的多步骤工作流
<b>插件系统</b>:支持官方和自定义插件
<b>完整部署</b>:支持云端和本地部署
Dify 适用场景
智能客服:自动回答用户问题
企业知识库:内部知识查询
内容生成:批量生成文案
数据分析:自然语言查询数据
教育助手:学习辅助
Dify 学习建议
从官方文档开始,了解基本概念
创建简单的对话应用,熟悉界面
学习知识库功能,尝试 RAG
学习工作流编排,构建复杂应用
尝试创建自定义插件
参与社区讨论,获取更多资源
Dify 未来发展方向
支持更多大模型
增强多模态能力(图像、语音)
优化性能和扩展性
提供更多行业解决方案
加强社区生态建设
Coze AI应用开发平台思维导图(2026-06-25)
一、Coze 基础概念
1. 什么是 Coze
Coze 是字节跳动推出的 AI 应用开发平台,允许用户通过可视化方式构建智能应用
提供完整的 AI 应用开发、测试、部署和运营工具链
支持多种大模型(如豆包、GPT、DeepSeek等)
核心特点:低代码/无代码、可视化编排、多模型支持、插件扩展、数据分析
2. Coze 的核心价值
快速构建智能应用
无需编写大量代码,通过拖拽方式即可构建复杂 AI 应用
支持对话机器人、智能客服、知识库问答、自动化工作流等场景
统一模型管理
集成多种大模型,统一 API 调用方式
支持模型切换,无需修改应用代码
提供模型性能监控和成本分析
完整的开发工具链
提供 Prompt 调试、测试、版本管理等工具
支持应用部署到云端或嵌入到其他应用
提供详细的使用统计和数据分析
3. Coze 与 Dify 的对比
特性
开发方式
模型支持
知识库
部署方式
插件系统
数据分析
适用人群
生态系统
Coze
可视化为主
豆包、GPT、DeepSeek等
内置支持
云端为主
丰富
内置
非开发者/开发者
字节系产品集成
Dify
可视化 + 代码
多种模型
内置支持
云端/本地
支持
内置
开发者/非开发者
开源社区驱动
4. Coze 的应用场景
智能客服:自动回答用户问题
企业知识库:内部知识查询
内容生成:批量生成文案、报告
自动化工作流:多步骤任务自动化
数据分析:自然语言查询数据
教育助手:学习辅助和答疑
二、Coze 核心功能详解
1. 应用类型
对话应用(Chat Bot)
创建智能对话机器人
支持多轮对话、上下文管理
适用于客服、助手、教育等场景
支持自定义欢迎语、菜单、快捷回复
知识库应用(Knowledge Bot)
创建基于知识库的问答系统
支持文档上传、向量检索
适用于企业知识库、产品手册等场景
支持多文档关联和检索
工作流应用(Workflow)
创建复杂的 AI 工作流
支持多步骤编排、条件分支、循环
适用于数据分析、内容生成、自动化任务等场景
支持定时触发和事件触发
网页应用(Web App)
创建独立的网页应用
支持自定义界面和交互
适用于展示型应用、工具型应用
2. 模型管理
模型配置
支持的模型
豆包系列:Doubao Pro、Doubao Ultra
OpenAI 系列:GPT-3.5、GPT-4
DeepSeek 系列:DeepSeek Chat、DeepSeek Code
其他模型:支持自定义模型接入
添加模型步骤
进入「模型管理」页面
点击「添加模型」
选择模型类型
填写 API Key 和其他配置
点击「保存」
模型参数说明
API Key:模型服务的密钥
Base URL:模型服务的地址
最大 token 数:单次请求的最大 token 数(影响回答长度)
温度(Temperature):控制生成内容的随机性(0-1,值越大越随机)
Top P:核采样参数,控制生成内容的多样性
超时时间:请求超时时间
模型测试
测试方法
在模型配置页面点击「测试」
输入测试文本
查看模型返回结果
验证模型配置是否正确
模型对比
对比功能
进入「模型对比」页面
选择需要对比的模型
输入测试文本
查看各模型的返回结果和性能指标
根据对比结果选择合适的模型
3. Prompt 工程
Prompt 编辑器
可视化编辑界面
支持富文本编辑
支持变量插入(如用户输入、上下文信息)
支持条件语句(if-else)
支持循环语句
支持代码块
支持预设模板
Prompt 模板
提供多种预设模板(如问答、总结、翻译、创意写作等)
支持自定义模板
支持模板版本管理和复用
Prompt 调试
调试工具功能
实时预览 Prompt 效果
查看完整的 Prompt 内容(包括变量替换后的结果)
支持历史记录回溯
支持 A/B 测试对比不同 Prompt
调试步骤
在 Prompt 编辑器中编写 Prompt
点击「调试」按钮
输入测试输入
查看模型返回结果
根据结果调整 Prompt
Prompt 优化技巧
明确指令
清晰说明任务要求
使用结构化的指令格式(如编号列表)
避免模糊的表述
提供示例
提供少量示例帮助模型理解任务
使用 few-shot learning 方法
示例要具有代表性
控制输出格式
指定输出格式(如 JSON、Markdown、表格)
使用约束条件
提供输出示例
迭代优化
使用调试工具测试 Prompt
根据测试结果调整 Prompt
记录优化历史,便于回溯
4. 知识库管理
文档上传
支持的文档格式
文本文件:.txt、.md
办公文档:.docx、.xlsx、.pptx
PDF 文件:.pdf
网页内容:URL 链接
图片内容:支持 OCR 识别
上传步骤
进入「知识库」页面
点击「新建知识库」
输入知识库名称和描述
上传文档或添加 URL
点击「开始处理」
文档处理
文档解析
自动解析文档内容
支持表格、图片、公式等内容提取
处理大文档时自动分段
向量索引
将文档内容转换为向量表示
使用向量数据库进行存储和检索
支持多种向量数据库(如 Milvus、Chroma)
索引配置参数
分块大小:文档分段的大小(默认 500 字符)
重叠大小:分段之间的重叠字符数(默认 50)
向量模型:用于生成向量的模型
索引类型:支持精确检索和模糊检索
知识库问答
检索增强生成(RAG)
用户提问时,先检索知识库中相关内容
将检索结果作为上下文输入给模型
模型基于上下文生成回答
支持引用来源标注
问答配置参数
检索数量:每次检索的文档片段数量(默认 5)
相似度阈值:检索结果的相似度阈值(0-1)
上下文拼接方式:如何将多个检索结果拼接
引用格式:引用来源的显示格式
代码示例(使用 Coze API 进行知识库问答)
5. 插件系统
插件类型
官方插件
Web Search:网页搜索
Calculator:计算器
Weather:天气查询
Date/Time:日期时间
File Read/Write:文件读写
Email:发送邮件
Calendar:日历管理
Translation:翻译
自定义插件
支持创建自定义插件
插件可以调用外部 API
支持 Python、JavaScript 等语言
支持通过 HTTP 请求调用
创建插件
创建步骤
进入「插件中心」页面
点击「创建插件」
填写插件信息(名称、描述、图标等)
定义插件参数(输入、输出)
编写插件代码或配置 API 调用
测试插件
发布插件
插件代码示例(Python)
使用插件
在对话中使用
在应用配置中启用插件
在 Prompt 中调用插件
模型会自动判断何时调用插件
插件结果会作为上下文传入模型
在工作流中使用
在工作流编辑器中添加插件节点
配置插件参数
连接插件节点到其他节点
插件输出可以作为后续节点的输入
6. 工作流编排
工作流编辑器
可视化界面
拖拽式节点编排
支持多种节点类型
实时预览工作流结构
支持节点复制和粘贴
节点类型
开始节点
工作流的起始点
定义输入参数
模型节点
调用大模型生成内容
支持多种模型
配置模型参数和 Prompt
插件节点
调用插件执行特定任务
支持官方和自定义插件
配置插件参数
条件节点
根据条件判断执行路径
支持多种条件判断(等于、包含、正则等)
支持多分支
循环节点
循环执行一组节点
支持固定次数循环和条件循环
支持循环变量
变量节点
定义和修改变量
支持多种变量类型(字符串、数字、数组、对象)
支持变量运算
结束节点
工作流的结束点
定义输出结果
工作流示例(内容生成工作流)
场景描述
用户输入一个主题
系统先搜索相关信息
然后调用模型生成文章大纲
根据大纲生成完整文章
最后保存文章到文件
工作流结构
配置步骤
创建工作流应用
添加「开始节点」,定义输入参数「主题」
添加「插件节点」,选择「网页搜索」,配置搜索关键词为「主题」变量
添加「变量节点」,命名为「搜索结果」,保存搜索结果
添加「模型节点」,配置 Prompt 使用「搜索结果」变量生成大纲
添加「变量节点」,命名为「大纲」,保存大纲
添加「模型节点」,配置 Prompt 使用「大纲」变量生成文章
添加「插件节点」,选择「保存文件」,配置文件名和内容
添加「结束节点」,定义输出结果
连接所有节点
测试工作流
7. 应用部署
部署方式
API 部署
生成 API 密钥
通过 REST API 调用应用
支持同步和异步调用
支持批量调用
网页嵌入
生成嵌入代码
嵌入到网站或应用中
支持自定义样式和主题
支持响应式布局
移动端部署
支持 iOS 和 Android
使用官方 SDK
提供原生体验
支持推送通知
小程序部署
支持微信小程序
支持抖音小程序
提供小程序组件
API 调用示例
Python 示例
JavaScript 示例
网页嵌入示例
获取嵌入代码
进入应用详情页面
点击「部署」标签
选择「网页嵌入」
配置嵌入选项(样式、主题、尺寸等)
复制嵌入代码
嵌入代码
三、Coze 高级功能
1. 会话管理
上下文管理
自动管理对话上下文
支持上下文窗口配置(如最近 10 轮对话)
支持上下文压缩(当上下文过长时自动压缩)
支持自定义上下文策略
会话历史
保存完整的会话历史
支持会话恢复(通过 conversation_id)
支持会话导出(JSON 格式)
支持会话搜索
代码示例(管理会话)
2. 用户管理
用户认证
支持 API Key 认证
支持 OAuth 认证
支持自定义认证(如企业内部认证)
支持匿名用户访问
用户权限
支持多租户
支持角色管理(管理员、开发者、用户)
支持细粒度权限控制
支持用户分组
用户统计
查看用户使用情况
统计 API 调用次数
分析用户行为(如常见问题、使用时长)
支持用户画像
3. 监控与日志
实时监控
监控应用状态(在线/离线)
监控 API 调用次数和延迟
监控模型使用情况(token 消耗、响应时间)
监控错误率和异常情况
日志管理
记录所有 API 调用
记录模型请求和响应(支持脱敏)
记录用户行为日志
支持日志导出和分析
告警设置
设置 API 调用频率告警
设置错误率告警(如错误率超过 5%)
设置模型超时告警
设置资源使用告警(如内存、CPU)
4. 数据安全
数据加密
传输加密(HTTPS/TLS)
存储加密(数据库加密)
API Key 加密存储
用户数据加密
数据隔离
多租户数据隔离
用户数据隔离
支持数据脱敏(如隐藏敏感信息)
支持数据删除
合规性
支持 GDPR 合规
支持数据导出和删除请求
提供数据处理记录
支持审计日志
5. 性能优化
缓存机制
缓存模型响应(相同请求直接返回缓存)
缓存知识库检索结果
支持自定义缓存策略(如缓存时间、缓存大小)
支持缓存预热
负载均衡
支持多实例部署
支持请求分发(基于用户、基于负载)
支持自动扩缩容(根据负载自动调整实例数量)
支持故障转移
异步处理
支持异步 API 调用(适用于耗时任务)
支持批量处理(如批量生成内容)
支持任务队列(后台执行任务)
支持 Webhook 回调(任务完成后通知)
四、Coze 应用场景
1. 智能客服
场景描述
企业需要一个智能客服系统
能够自动回答常见问题
能够转接人工客服
支持多渠道接入(网页、APP、小程序)
实现步骤
创建知识库,上传产品手册和常见问题
创建对话应用,配置 Prompt
启用知识库检索功能
配置人工转接条件(如无法回答时转接)
配置欢迎语和快捷回复
部署应用到各渠道
关键配置
Prompt:引导模型使用知识库回答问题
知识库检索:设置合适的相似度阈值(如 0.7)
人工转接:设置无法回答时的转接条件和提示语
快捷回复:设置常见问题的快捷按钮
2. 企业知识库
场景描述
企业需要一个内部知识库系统
员工可以查询公司政策、流程、技术文档等信息
支持自然语言查询
支持文档版本管理
实现步骤
创建知识库,上传公司文档(政策、流程、技术文档等)
创建知识库应用,配置检索参数
设置访问权限(如部门权限、角色权限)
配置文档版本管理
部署应用到企业内部平台
关键配置
文档分块:根据文档类型调整分块大小(技术文档可适当增大)
向量模型:选择适合中文的向量模型
权限控制:设置员工访问权限(如普通员工只能查看公开文档)
版本管理:启用文档版本管理,支持版本对比和回滚
3. 内容生成
场景描述
营销团队需要批量生成营销文案
需要根据产品信息生成不同风格的文案(如正式、活泼、专业)
需要自动优化文案质量
需要批量导出文案
实现步骤
创建工作流应用
添加变量节点,定义产品信息(名称、特点、目标人群等)
添加模型节点,配置多种 Prompt 模板(不同风格)
添加条件节点,根据产品类型选择合适的模板
添加插件节点,保存生成的文案到文件或数据库
添加循环节点,支持批量生成
测试和优化工作流
关键配置
Prompt 模板:创建多种风格的模板(正式、活泼、专业等)
变量定义:定义产品信息变量(名称、特点、目标人群等)
工作流逻辑:设计合理的流程(输入→选择模板→生成→保存)
批量处理:使用循环节点支持批量生成
4. 数据分析
场景描述
业务团队需要快速分析数据
能够用自然语言查询数据(如"上个月销售额是多少?")
能够自动生成分析报告
支持数据可视化
实现步骤
创建工作流应用
添加插件节点,连接数据库(MySQL、PostgreSQL等)
添加模型节点,生成 SQL 查询(根据用户的自然语言查询)
添加插件节点,执行 SQL 查询并获取结果
添加模型节点,根据查询结果生成分析报告
添加插件节点,生成数据可视化图表
测试和优化工作流
关键配置
数据库连接:配置数据库插件(连接字符串、用户名、密码)
SQL 生成:配置模型生成 SQL(提供示例 SQL 帮助模型理解)
报告生成:配置模型生成分析报告(指定报告格式和结构)
数据可视化:使用图表插件生成可视化图表
5. 教育助手
场景描述
学生需要一个学习助手
能够解答学科问题(数学、语文、英语等)
能够提供学习建议和学习计划
支持作业辅导和知识点讲解
实现步骤
创建知识库,上传教材和学习资料
创建对话应用,配置教育相关的 Prompt(如以老师身份回答)
启用知识库检索功能(检索教材内容)
配置学习进度跟踪(使用变量记录学习进度)
添加插件节点,支持作业提交和批改
部署应用
关键配置
Prompt:引导模型以教育者的身份回答(耐心、详细、易懂)
知识库:上传相关学习资料(教材、习题、知识点讲解)
进度跟踪:使用变量记录学习进度(如已学章节、做题数量)
作业辅导:配置作业提交和批改功能
五、Coze 最佳实践
1. Prompt 工程最佳实践
明确任务目标
在 Prompt 中清晰说明任务要求
使用结构化的指令格式(如编号列表)
避免模糊的表述(如"写一篇文章"改为"写一篇关于人工智能的科普文章,字数500字,适合中学生阅读")
提供上下文信息
提供必要的背景信息(如目标受众、使用场景)
使用变量引用外部数据(如用户输入、知识库内容)
保持上下文简洁(只提供必要信息,避免冗余)
控制输出格式
指定输出格式(如 JSON、Markdown、表格)
使用约束条件(如字数限制、语言风格)
提供输出示例(如"请按照以下格式输出:标题、正文、总结")
迭代优化
使用调试工具测试 Prompt
根据测试结果调整 Prompt(如调整指令、增加示例)
记录优化历史,便于回溯和对比
2. 知识库最佳实践
文档准备
整理清晰的文档结构(如分章节、分主题)
去除无关内容(如广告、重复信息)
确保文档质量(准确、完整、最新)
对长文档进行拆分(便于检索)
索引配置
根据文档类型调整分块大小(技术文档可适当增大,如 1000 字符)
设置合适的重叠大小(确保上下文连贯,如 100 字符)
选择合适的向量模型(中文文档选择中文向量模型)
定期更新索引(当文档内容更新时)
检索优化
设置合适的相似度阈值(如 0.7-0.8)
调整检索数量(根据需求设置,如 3-10)
使用混合检索策略(关键词检索 + 向量检索)
优化 Prompt 中的检索结果引用方式
维护更新
定期更新知识库内容(添加新文档、删除过期文档)
优化检索效果(根据用户反馈调整配置)
监控知识库使用情况(如热门查询、未命中查询)
3. 工作流最佳实践
模块化设计
将复杂流程拆分为多个模块(如数据输入、处理、输出)
使用变量传递数据(避免硬编码)
设计可复用的节点组合(如常用的模型调用+插件调用组合)
使用注释说明节点功能
错误处理
添加错误处理节点(如捕获异常、重试机制)
设置重试机制(如 API 调用失败时重试 3 次)
记录错误日志(便于排查问题)
提供友好的错误提示(如"系统繁忙,请稍后重试")
性能优化
减少不必要的节点(如移除多余的变量节点)
使用异步处理(适用于耗时任务)
合理使用缓存(如缓存频繁查询的结果)
优化模型调用(选择合适的模型、调整参数)
测试验证
测试每个节点的功能(确保单个节点正常工作)
测试完整流程(确保端到端流程正常)
测试边界情况(如空输入、异常输入)
测试性能(如响应时间、吞吐量)
4. 部署最佳实践
环境配置
根据业务需求选择部署方式(API 部署、网页嵌入、移动端)
配置合适的资源(如 API 调用频率限制、存储空间)
设置监控和告警(如错误率告警、响应时间告警)
配置日志记录(便于排查问题)
安全配置
使用 HTTPS(确保数据传输安全)
配置 API Key 管理(定期轮换密钥、限制 IP 访问)
设置访问权限(如限制特定用户或 IP 访问)
启用数据脱敏(隐藏敏感信息)
性能优化
使用负载均衡(分散请求压力)
配置缓存(减少重复计算)
优化数据库连接(使用连接池)
启用压缩(减少数据传输量)
六、Coze 常见问题与解决方案
1. 模型调用失败
常见原因
API Key 错误或过期
模型服务不可用(如维护、限流)
网络连接问题
请求参数错误(如格式错误、缺少必要参数)
解决方案
检查 API Key 是否正确(在模型配置页面验证)
测试模型服务是否正常(使用模型测试功能)
检查网络连接(尝试访问模型服务地址)
检查请求参数(对照 API 文档确认参数格式)
2. 知识库检索效果差
常见原因
文档质量差(如内容不完整、不准确)
分块大小不合适(过大或过小)
向量模型不匹配(如使用英文向量模型处理中文文档)
相似度阈值设置不当(过高或过低)
解决方案
优化文档质量(补充完整内容、修正错误)
调整分块大小(根据文档类型和长度调整)
更换向量模型(选择适合当前文档语言的模型)
调整相似度阈值(逐步测试找到最佳值)
3. 应用响应慢
常见原因
模型响应慢(如模型服务负载高)
知识库检索慢(如向量数据库性能问题)
工作流节点过多(如不必要的节点增加处理时间)
网络延迟(如客户端与服务器距离远)
解决方案
使用更快的模型(如选择响应时间更短的模型)
优化知识库检索(如增加缓存、优化索引)
简化工作流(移除不必要的节点)
使用 CDN 加速(减少网络延迟)
4. 部署失败
常见原因
环境配置错误(如缺少依赖、端口被占用)
权限不足(如文件读写权限、数据库权限)
配置参数错误(如 API Key 错误、数据库连接字符串错误)
资源不足(如内存、CPU 不足)
解决方案
检查环境配置(确保所有依赖已安装)
检查权限设置(确保应用有足够的权限)
检查配置参数(对照文档确认参数正确)
增加资源(如增加内存、CPU)
5. 权限问题
常见原因
用户权限不足(如尝试访问无权访问的功能)
API Key 权限不足(如尝试调用未授权的 API)
多租户配置错误(如数据隔离失败)
角色配置错误(如角色权限设置错误)
解决方案
检查用户权限(确保用户有足够的权限)
检查 API Key 权限(确保 API Key 有调用权限)
检查多租户配置(确保数据隔离正确)
检查角色配置(确保角色权限设置正确)
七、Coze 学习资源
官方文档
Coze 官方文档:<a href="https://docs.coze.cn">https://docs.coze.cn</a>
API 参考:<a href="https://docs.coze.cn/docs/api-reference">https://docs.coze.cn/docs/api-reference</a>
部署指南:<a href="https://docs.coze.cn/docs/getting-started/deployment">https://docs.coze.cn/docs/getting-started/deployment</a>
社区资源
GitHub:<a href="https://github.com/coze">https://github.com/coze</a>
Discord:官方社区
中文社区:官方论坛或讨论群
教程与示例
官方教程:<a href="https://docs.coze.cn/docs/tutorial">https://docs.coze.cn/docs/tutorial</a>
示例项目:官方提供的示例应用
视频教程:官方 YouTube/B 站频道
相关工具
向量数据库:Milvus、Chroma、Qdrant
大模型:豆包、OpenAI、DeepSeek
前端框架:React、Vue
八、Coze 与其他工具的集成
1. 与企业系统集成
常见集成场景
与 CRM 系统集成(如 Salesforce、钉钉 CRM)
与 ERP 系统集成(如 SAP、用友)
与知识库系统集成(如 Confluence、Notion)
与 OA 系统集成(如钉钉、企业微信)
集成方式
使用 API 调用(通过插件调用企业系统 API)
使用 Webhook(接收企业系统的事件通知)
使用自定义插件(开发专门的集成插件)
2. 与数据分析工具集成
支持的工具
MySQL、PostgreSQL、SQLite
MongoDB、Redis
数据仓库(如 Snowflake、BigQuery)
BI 工具(如 Tableau、Power BI)
集成步骤
创建数据库插件
配置数据库连接
在工作流中使用数据库节点
执行查询并获取结果
生成分析报告或可视化图表
3. 与社交媒体平台集成
支持的平台
微信公众号、小程序
抖音、快手
微博
Facebook、Twitter
集成方式
使用平台 API(通过插件调用)
使用 Webhook(接收平台事件)
使用官方 SDK(如微信 SDK)
九、Coze 与 Dify 的选择建议
选择 Coze 的情况
需要与字节系产品集成(如抖音、飞书)
偏好纯可视化开发方式
需要丰富的官方插件和模板
希望快速构建应用并上线
偏好云端托管,无需自行部署
选择 Dify 的情况
需要本地部署(数据安全要求高)
偏好代码+可视化的开发方式
需要高度定制化(如自定义模型、自定义插件)
希望参与开源社区(贡献代码、定制功能)
需要与非字节系产品深度集成
综合建议
小型项目、快速上线:选择 Coze
企业级项目、数据安全要求高:选择 Dify
需要高度定制化:选择 Dify
需要丰富的模板和插件:选择 Coze
十、总结
Coze 核心要点
<b>可视化开发</b>:通过拖拽方式构建 AI 应用,无需编写大量代码
<b>多模型支持</b>:集成多种大模型(豆包、GPT、DeepSeek等),统一管理
<b>知识库功能</b>:内置知识库管理和 RAG 功能,支持多种文档格式
<b>工作流编排</b>:支持复杂的多步骤工作流,包含多种节点类型
<b>插件系统</b>:丰富的官方插件和自定义插件支持
<b>完整部署</b>:支持 API 部署、网页嵌入、移动端部署等多种方式
Coze 适用场景
智能客服:自动回答用户问题,支持多渠道接入
企业知识库:内部知识查询,支持自然语言搜索
内容生成:批量生成文案、报告,支持多种风格
数据分析:自然语言查询数据,自动生成分析报告
教育助手:学习辅助和答疑,支持作业辅导
Coze 学习建议
从官方文档开始,了解基本概念和操作
创建简单的对话应用,熟悉界面和功能
学习知识库功能,尝试 RAG 检索增强生成
学习工作流编排,构建复杂应用
尝试创建自定义插件,扩展应用功能
参与社区讨论,获取更多资源和经验
Coze 未来发展方向
支持更多大模型(如国产模型)
增强多模态能力(图像、语音、视频)
优化性能和扩展性(支持更大规模应用)
提供更多行业解决方案(如金融、医疗、教育)
加强社区生态建设(开源更多功能、提供更多模板)
LlamaIndex RAG框架思维导图(2026-06-26)
<b>注意</b>:本文档内容基于 LlamaIndex 官方文档和公开资料整理。由于框架 API 仍在持续演进,实际使用时请参考官方文档确认最新的 API 签名和用法。
一、LlamaIndex 基础概念
1. 什么是 LlamaIndex
定义
LlamaIndex(前身为 GPT Index)是一个专门为 LLM 构建 RAG(检索增强生成)应用的数据框架
由 Jerry Liu 于 2022 年底发起,2023 年更名为 LlamaIndex
官方定位:"用于构建上下文增强型(Context-augmented)LLM 应用程序的数据框架"
核心价值
如果把大模型比作"大脑",LlamaIndex 的定位就是"记忆增强系统"
它不仅仅关注如何向模型提问(Prompt Engineering),更侧重于数据管理(Data Management)的全生命周期
核心目标:打破私有数据孤岛,让 LLM 能够以最低的成本、最高的精度访问海量外部知识
项目现状
GitHub 超过 49K Star,月 PyPI 下载量 680 万
支持 78 种向量存储、104 种 LLM 提供商、6 种索引类型
已发布 v0.10+ 版本,完成了核心架构的模块化重构
2. LlamaIndex 的作用
解决的核心问题
LLM 的知识局限性
LLM 的知识是静态的,训练数据截止日期之前的公开信息,你的私有数据它从未见过
上下文窗口有限,即使是 GPT-4 的 128K 上下文,也只能容纳约 50 份文档,远不够
直接塞入所有文档不现实:成本高昂,响应缓慢,而且绝大部分内容是无关的
传统方案的困境
方案 1:Fine-tuning(微调)
做法:用你的数据重新训练 LLM
问题:成本极高(数万美元起)、需要大量标注数据、数据更新需要重新微调、模型可能"遗忘"原有能力
方案 2:全部塞进 Prompt
做法:把所有文档拼接到提示词里
问题:上下文长度限制、API 成本线性增长、响应速度慢
方案 3:关键词搜索 + LLM
做法:先用传统搜索找文档,再让 LLM 总结
问题:关键词匹配不理解语义、找不到同义表达、需要手动设计搜索逻辑
LlamaIndex 的解决方案:RAG
RAG = Retrieval(检索)+ Augmented(增强)+ Generation(生成)
RAG 的优势
✅ 无需微调,成本低
✅ 数据更新实时生效(更新索引即可)
✅ 只检索相关内容,节省 token 成本
✅ 语义理解(向量相似度匹配)
✅ 可解释性强(能看到引用了哪些文档)
3. LlamaIndex 与普通 RAG 的联系与区别
联系
都基于 RAG 范式
两者都遵循"检索→增强→生成"的基本流程
都使用向量数据库进行语义检索
都旨在解决 LLM 的知识局限性问题
都支持私有数据接入
都可以加载本地文档、数据库、API 数据等
都支持将私有数据转换为 LLM 可用的格式
区别
普通 RAG(自研/简单实现)
优势
轻量,适合简单场景
完全可控,可自定义实现
劣势
需要自行实现数据加载、切分、向量化、索引构建等全流程
缺乏高级检索策略(如混合检索、递归检索)
缺乏评估和监控工具
不适合复杂场景和大规模数据
LlamaIndex
优势
高度封装,提供完整的工具链
支持多种索引类型(向量索引、树状索引、关键词索引等)
提供高级检索策略(混合检索、递归检索、句子窗口检索等)
内置评估工具(Evaluation-First 理念)
支持数据更新和增量索引
丰富的生态系统(LlamaHub 数据加载器)
劣势
学习曲线相对较陡
有一定的复杂度
对比表格
特性
数据加载
文档切分
索引构建
检索策略
评估工具
增量更新
生态系统
适用场景
普通 RAG(自研)
需要自行实现
需要自行实现
需要自行实现
简单向量检索
需要自行实现
需要自行实现
无
简单场景、小规模数据
LlamaIndex
100+ 内置 Data Loader
多种切分策略和工具
6 种索引类型
混合检索、递归检索、句子窗口等
内置评估框架
原生支持
丰富的 LlamaHub
复杂场景、大规模数据、生产环境
4. LlamaIndex 与其他框架的对比
LlamaIndex vs LangChain
定位差异
<b>LangChain(通用编排者)</b>:通用的 LLM 应用开发框架,侧重于"计算逻辑"的编排,擅长管理复杂的 Agent 行为链、工具调用以及多模态交互的流程控制
<b>LlamaIndex(数据专家)</b>:专注于数据处理与检索的垂直框架,侧重于"数据结构"的优化,在 RAG 领域拥有更深的护城河
优势对比
特性
Agent 编排
工具调用
数据索引
检索策略
知识图谱
评估工具
LangChain
✅ 强
✅ 强
⚠️ 中等
⚠️ 中等
✅ 强
⚠️ 中等
LlamaIndex
⚠️ 中等
⚠️ 中等
✅ 强
✅ 强
⚠️ 中等
✅ 强
选择建议
需要复杂的 Agent 流程、工具调用链:选择 LangChain
需要高质量的 RAG、复杂的检索策略:选择 LlamaIndex
两者可以结合使用:LangChain 负责流程编排,LlamaIndex 负责数据检索
LlamaIndex vs Haystack
定位差异
<b>Haystack</b>:欧洲开源社区驱动的 RAG 框架,注重模块化和可扩展性
<b>LlamaIndex</b>:美国开源社区驱动的 RAG 框架,注重易用性和功能完整性
优势对比
特性
模块化设计
多模态支持
索引类型
评估工具
生态系统
Haystack
✅ 强
✅ 强
⚠️ 中等
⚠️ 中等
⚠️ 中等
LlamaIndex
⚠️ 中等
⚠️ 中等
✅ 强
✅ 强
✅ 强
二、LlamaIndex 完整工作流程
1. 流程概览
数据流全景
五个标准化流水线
<b>数据摄入(Ingestion)</b>:加载各种格式的数据
<b>文档解析(Parsing)</b>:将数据转换为标准化的 Document 对象
<b>索引构建(Indexing)</b>:构建高效的数据索引
<b>检索(Retrieval)</b>:根据用户问题检索相关内容
<b>生成(Generation)</b>:调用 LLM 生成最终答案
2. 详细流程步骤
步骤 1:数据加载(Data Loading)
加载数据源
通过 Data Loaders 加载各种格式的数据
LlamaHub 提供 100+ 种数据加载器
支持:PDF、Word、Excel、网页、数据库、Notion、Slack 等
代码示例
步骤 2:文档切分(Text Splitting)
切分原因
长文档直接向量化会丢失局部语义
需要将文档切分为小的文本块(Node),便于精准检索
切分策略
按字符数切分(默认)
按句子切分
按段落切分
按 Token 切分
代码示例
步骤 3:索引构建(Indexing)
索引类型选择
VectorStoreIndex:向量索引(最常用)
TreeIndex:树状索引(适合长文档摘要)
KeywordTableIndex:关键词表索引(适合精确匹配)
KnowledgeGraphIndex:知识图谱索引(适合关系推理)
SummaryIndex:摘要索引(适合快速概览)
MultiModalIndex:多模态索引(适合图文混合)
代码示例(向量索引)
步骤 4:创建查询引擎(Query Engine)
查询引擎类型
Default Query Engine:默认查询引擎
Retriever Query Engine:自定义检索器的查询引擎
Router Query Engine:路由查询引擎(根据问题选择不同索引)
Sub Question Query Engine:子问题查询引擎(拆分复杂问题)
代码示例
步骤 5:执行查询与输出(Querying)
查询过程
用户输入问题
查询引擎将问题转换为向量
在向量数据库中检索最相关的节点
将检索结果与问题组合成 Prompt
调用 LLM 生成回答
返回回答和引用来源
代码示例(完整流程)
三、LlamaIndex 组成部分
1. Document(文档)
基础定义
Document 是 LlamaIndex 对原始数据源的标准化封装,是整个 RAG 流程的数据入口
它并非仅指传统的文本文档,而是涵盖所有可被加载的结构化/非结构化数据的抽象载体
核心属性
text
核心属性,存储文档的原始文本内容
如 TXT 文件的全部字符、PDF 解析后的文本
metadata
元数据字典,用于记录文档的上下文信息
是「回答溯源」和「多文档管理」的核心依据
常见字段:
file_name:文档文件名
file_path:文档绝对路径
creation_date:文档创建时间
category:自定义文档分类
id_:唯一标识符
关键特性
多源适配性:100+ 内置 Data Loader,可将不同数据源转为统一的 Document 对象
不可变性:原始 Document 一旦加载,内容不会被修改
编码保障:加载中文文档时需指定 encoding="utf-8"
批量加载:通过 SimpleDirectoryReader 批量加载
2. Node(节点)
基础定义
Node 是 LlamaIndex 对 Document 的最小可检索单元,也被称为文本块
它是将原始长文档切分后生成的子文本片段,是 RAG 流程中向量化和检索的核心对象
切分原因
长文档直接向量化会丢失局部语义(如一个 10000 字符的文档,其向量无法精准表征某一段落的含义)
将文档切分为小的文本块后,每个块的向量能够更精准地表征其内容
核心属性
node_id
节点唯一标识
text
节点的文本内容
metadata
节点的元数据(继承自 Document)
relationships
与其他节点的关系信息(父子关系、兄弟关系等)
embedding
节点的向量表示
切分策略
字符切分(SentenceSplitter)
按固定字符数切分
适合大多数场景
参数:chunk_size(块大小)、chunk_overlap(重叠大小)
句子切分(SentenceWindowNodeParser)
按句子边界切分
保持句子完整性
适合需要上下文连贯的场景
Token 切分(TokenTextSplitter)
按 Token 数切分
适合需要精确控制上下文长度的场景
代码示例
3. Index(索引)
基础定义
Index 是为了快速检索而构建的数据结构
将 Node 组织成便于 LLM 消费的中间表示形式
LlamaIndex 支持多种索引类型,每种适用于不同的场景
索引类型详解
VectorStoreIndex(向量索引)
原理
将每个 Node 转换为向量表示(Embedding)
将向量存储在向量数据库中
查询时通过向量相似度匹配找到最相关的 Node
适用场景
语义检索、问答系统、文档搜索
最常用的索引类型
代码示例
TreeIndex(树状索引)
原理
将文档组织成树形结构
根节点是文档的完整摘要
子节点是文档的各个部分的摘要
查询时从根节点开始,逐步向下查找最相关的节点
适用场景
长文档摘要、层次化检索
适合需要从整体到局部理解文档的场景
代码示例
KeywordTableIndex(关键词表索引)
原理
为每个文档提取关键词
构建关键词到文档的映射表
查询时通过关键词匹配找到相关文档
适用场景
精确匹配、关键词搜索
适合需要按关键词快速定位的场景
代码示例
KnowledgeGraphIndex(知识图谱索引)
原理
从文档中提取实体和关系
构建知识图谱
查询时通过图遍历找到相关的知识
适用场景
关系推理、知识问答
适合需要理解实体之间关系的场景
代码示例
SummaryIndex(摘要索引)
原理
为文档生成摘要
将摘要存储起来
查询时直接返回摘要
适用场景
快速概览、文档摘要
适合需要快速了解文档内容的场景
代码示例
索引选择建议
场景
语义问答、文档搜索
长文档摘要、层次化检索
精确匹配、关键词搜索
关系推理、知识问答
快速概览、文档摘要
图文混合、多模态
推荐索引类型
VectorStoreIndex
TreeIndex
KeywordTableIndex
KnowledgeGraphIndex
SummaryIndex
MultiModalIndex
4. Retriever(检索器)
基础定义
Retriever 是 LlamaIndex 中从 Index 中检索相关 Node 的核心组件
是 Query Engine 的"检索子模块"
唯一职责:接收用户问题的向量表示,从 Index 中筛选出与问题语义最相似的 Node 集合
检索器类型
VectorIndexRetriever(向量检索器)
原理
将用户问题转换为向量
在向量数据库中进行相似度搜索
返回最相关的 Top-K 个节点
代码示例
KeywordTableSimpleRetriever(关键词检索器)
原理
提取用户问题中的关键词
在关键词表中查找匹配的文档
返回相关文档
代码示例
TreeIndexRetriever(树状检索器)
原理
从树的根节点开始,逐层向下检索
根据相关性选择分支
返回最相关的叶子节点
代码示例
高级检索策略
混合检索(Hybrid Search)
原理
同时使用向量检索和关键词检索
合并两种检索结果
提高检索的准确性和召回率
代码示例
递归检索(Recursive Retrieval)
原理
先检索得到初步结果
根据初步结果再次检索
逐步深入,找到更精准的答案
适用场景
需要多步推理的复杂问题
需要从多个文档中综合信息的场景
句子窗口检索(Sentence Window Retrieval)
原理
为每个句子创建一个窗口(包含前后几个句子)
查询时检索句子窗口
保持句子的上下文连贯性
代码示例
5. Query Engine(查询引擎)
基础定义
Query Engine 是 LlamaIndex 中负责整个"检索+生成"流程的核心组件
它封装了检索、后处理和合成的复杂逻辑
对外提供简洁的查询接口
查询引擎类型
Default Query Engine(默认查询引擎)
原理
结合索引和检索器
执行检索→构建 Prompt→调用 LLM→生成回答的完整流程
最简单、最常用的查询引擎
代码示例
Retriever Query Engine(自定义检索器查询引擎)
原理
使用自定义的检索器
可以灵活配置检索策略
适合需要定制检索逻辑的场景
代码示例
Router Query Engine(路由查询引擎)
原理
根据用户问题的类型,自动选择合适的索引进行查询
支持多索引协同工作
适合需要处理多种类型问题的场景
代码示例
Sub Question Query Engine(子问题查询引擎)
原理
将复杂问题拆分为多个子问题
分别查询每个子问题
综合所有子问题的答案生成最终回答
适用场景
需要多步推理的复杂问题
需要从多个角度回答的问题
代码示例
6. Chat Engine(对话引擎)
基础定义
Chat Engine 是支持多轮对话的查询引擎
能够维护对话历史上下文
适合需要进行多轮交互的场景
对话引擎类型
Simple Chat Engine(简单对话引擎)
原理
基于索引构建简单的对话系统
维护对话历史
每次查询时将对话历史作为上下文
代码示例
Condense Question Chat Engine(压缩问题对话引擎)
原理
将对话历史压缩为一个独立的问题
将压缩后的问题发送给查询引擎
避免上下文过长
适用场景
需要长时间对话的场景
上下文窗口有限的情况
代码示例
四、LlamaIndex 常用代码示例
1. 完整的最小化 RAG 系统
2. 使用本地模型(Qwen)
3. 增量索引更新
4. 使用 LlamaParse 解析复杂文档
5. 配置自定义嵌入模型和 LLM
6. 评估 RAG 系统性能
五、LlamaIndex 高级特性
1. 多模态支持
原理
支持图文混合数据的处理
通过多模态嵌入模型将图片和文本转换为统一的向量表示
支持基于图片内容的检索
代码示例
2. 知识图谱构建
原理
从文档中自动提取实体和关系
构建知识图谱
支持基于图的推理和查询
代码示例
3. Workflow 工作流
原理
事件驱动的工作流系统
支持多个步骤的编排
支持条件分支、循环等控制结构
代码示例
4. Agent 系统
原理
基于 LlamaIndex 构建智能体
智能体可以使用 RAG 作为工具
支持 FunctionAgent、ReActAgent、CodeActAgent
代码示例
六、LlamaIndex 生态系统
1. LlamaHub
定义
LlamaHub 是 LlamaIndex 的数据连接器生态
提供 100+ 种数据加载器
支持从各种数据源加载数据
支持的数据源
文件系统:PDF、Word、Excel、Markdown 等
云服务:AWS S3、Google Drive、Dropbox 等
SaaS 应用:Notion、Slack、Confluence、Jira 等
数据库:MySQL、PostgreSQL、SQLite 等
API:REST API、GraphQL 等
使用方法
2. LlamaCloud
定义
LlamaCloud 是 LlamaIndex 的托管服务
提供 LlamaParse(文档解析服务)
提供向量数据库托管服务
提供模型 API 服务
LlamaParse
世界上最好的文档解析器
支持复杂的 PDF、表格、图表等
输出格式:Markdown、JSON 等
使用方法
3. 创建 Llama 应用
create-llama
官方提供的应用生成器
一键创建 LlamaIndex 应用
支持多种模板和配置
使用方法
七、LlamaIndex 学习资源
官方文档
LlamaIndex 官方文档:<a href="https://docs.llamaindex.ai">https://docs.llamaindex.ai</a>
Python API 参考:<a href="https://docs.llamaindex.ai/en/stable/api_reference/">https://docs.llamaindex.ai/en/stable/api_reference/</a>
TypeScript 文档:<a href="https://ts.llamaindex.ai/">https://ts.llamaindex.ai/</a>
社区资源
GitHub:<a href="https://github.com/run-llama/llama_index">https://github.com/run-llama/llama_index</a>
Discord:官方社区
Twitter:@LlamaIndex
LlamaHub:<a href="https://llamahub.ai/">https://llamahub.ai/</a>
教程与示例
快速入门:<a href="https://docs.llamaindex.ai/en/stable/getting_started/">https://docs.llamaindex.ai/en/stable/getting_started/</a>
完整教程:<a href="https://docs.llamaindex.ai/en/stable/tutorials/">https://docs.llamaindex.ai/en/stable/tutorials/</a>
示例项目:<a href="https://github.com/run-llama/llama_index/tree/main/examples">https://github.com/run-llama/llama_index/tree/main/examples</a>
学习路径建议
从官方文档的快速入门开始,了解基本概念
构建一个最小化的 RAG 系统,熟悉完整流程
学习不同的索引类型,了解各自的适用场景
学习高级检索策略,提升检索效果
学习评估方法,优化 RAG 系统性能
尝试构建多模态应用或智能体应用
八、总结
LlamaIndex 核心要点
<b>定位明确</b>:专门为 RAG 场景设计的数据框架,连接 LLM 和私有数据
<b>完整工具链</b>:从数据加载、索引构建、检索到生成的完整流程
<b>多种索引类型</b>:支持向量索引、树状索引、关键词索引、知识图谱索引等
<b>高级检索策略</b>:支持混合检索、递归检索、句子窗口检索等
<b>评估框架</b>:内置 Evaluation-First 理念,支持系统性能评估
<b>丰富生态</b>:LlamaHub 提供 100+ 数据加载器,LlamaCloud 提供托管服务
<b>灵活扩展</b>:支持自定义嵌入模型、LLM、检索器等
LlamaIndex 适用场景
企业知识库问答系统
文档搜索和摘要
智能客服
数据分析和报告生成
多模态应用(图文检索)
智能体应用(带 RAG 能力)
与其他框架的选择建议
需要高质量 RAG、复杂检索策略:选择 LlamaIndex
需要复杂 Agent 流程、工具调用链:选择 LangChain
两者可以结合使用:LangChain 负责流程编排,LlamaIndex 负责数据检索
学习建议
从官方文档开始,理解核心概念(Document、Node、Index、Retriever、Query Engine)
实践构建简单的 RAG 系统,熟悉完整流程
尝试不同的索引类型和检索策略,理解各自的优缺点
使用评估工具优化系统性能
深入学习高级特性(多模态、知识图谱、Workflow、Agent)
LlamaIndex RAG-CLI 命令行工具思维导图(2026-06-26)
<b>注意</b>:本文档内容基于 LlamaIndex 官方文档和公开资料整理。由于框架 API 仍在持续演进,实际使用时请参考官方文档确认最新的命令参数和用法。
一、RAG-CLI 基础概念
1. 什么是 RAG-CLI
定义
RAG-CLI 是 LlamaIndex 提供的<b>命令行工具</b>,用于快速构建和使用 RAG(检索增强生成)系统
官方名称:llamaindex-cli rag
发布时间:2024 年 1 月正式发布
核心价值
解决的痛点
构建 RAG 系统通常需要编写大量 Python 代码
需要配置向量数据库、嵌入模型、LLM 等多个组件
对于初学者来说,上手门槛较高
RAG-CLI 的解决方案
<b>零代码</b>:无需编写 Python 代码,只需命令行即可完成 RAG 系统构建
<b>一键式</b>:一条命令即可完成文件导入、索引构建、问答等操作
<b>交互式</b>:支持聊天模式,在终端中进行多轮对话
<b>可扩展</b>:支持自定义模型和数据库
官方定位
"无需编写一行代码即可体验检索增强生成(RAG)"
"将本地文件转化为智能问答系统的最快方式"
2. RAG-CLI 的主要作用
作用一:本地文件问答
功能描述
将本地文件(PDF、Word、Markdown、TXT 等)导入向量数据库
通过命令行提问,基于文件内容生成答案
支持单轮提问和多轮对话
使用场景
<b>快速查阅文档</b>:无需打开文档,直接通过命令行提问
<b>知识库问答</b>:将企业知识库导入,快速查询信息
<b>代码文档问答</b>:将代码文档导入,查询 API 使用方法
示例流程
作用二:交互式聊天
功能描述
在终端中打开聊天界面(Chat REPL)
支持多轮对话,上下文保持
支持流式输出,实时显示回答
使用场景
<b>深度对话</b>:需要多轮追问的场景
<b>探索性提问</b>:不确定具体问题,需要逐步探索
<b>演示展示</b>:在终端中展示 RAG 能力
示例流程
作用三:创建完整应用
功能描述
基于导入的文件创建完整的 LlamaIndex 应用
包含 FastAPI 后端和 NextJS 前端
一键生成、安装依赖并运行
使用场景
<b>快速原型</b>:需要快速搭建演示应用
<b>内部工具</b>:需要搭建简单的内部知识库应用
<b>学习参考</b>:查看生成的代码结构,学习 LlamaIndex 应用开发
示例流程
作用四:数据管理
功能描述
管理向量数据库中的数据
支持添加、删除、清空数据
支持查看导入的文件列表
使用场景
<b>数据更新</b>:添加新的文档到知识库
<b>数据清理</b>:清空旧的索引数据
<b>数据管理</b>:管理知识库内容
示例流程
3. RAG-CLI 工作原理
架构概述
数据流向
核心组件
1. 文件加载器(File Loader)
支持多种文件格式:PDF、Word、Markdown、TXT、Python 等
使用 LlamaIndex 的 Data Loaders 进行文件解析
自动识别文件类型,调用对应的解析器
2. 文档处理器(Document Processor)
文档切分:将长文档切分为小的文本块(Chunk)
元数据提取:提取文件名、路径等元数据
文本清洗:去除多余空格、换行符等
3. 向量索引器(Vector Indexer)
使用嵌入模型将文本块转换为向量
默认使用 OpenAI 的 text-embedding-3-small
向量存储在本地 Chroma 数据库中
4. 查询引擎(Query Engine)
将用户问题转换为向量
在向量数据库中检索最相关的文本块
将检索结果与问题组合,调用 LLM 生成答案
默认配置
模型配置
<b>LLM</b>:OpenAI GPT-3.5-turbo(默认)
<b>嵌入模型</b>:OpenAI text-embedding-3-small(默认)
<b>向量数据库</b>:本地 Chroma(默认)
注意事项
默认使用 OpenAI API,需要设置 OPENAI_API_KEY
本地数据会发送到 OpenAI API 进行处理
可以自定义为本地模型,实现完全离线运行
二、RAG-CLI 安装与配置
1. 安装步骤
步骤 1:安装 LlamaIndex
步骤 2:安装 Chroma 向量数据库
步骤 3:验证安装
输出示例
2. 环境配置
设置 OpenAI API Key
Linux/Mac
Windows PowerShell
Windows CMD
验证配置
3. 自定义配置
使用本地模型
步骤 1:安装 Ollama
步骤 2:下载模型
步骤 3:创建自定义 CLI 脚本
步骤 4:运行自定义脚本
使用其他向量数据库
示例:使用 Pinecone
三、RAG-CLI 命令详解
1. 命令格式
基本格式
完整选项列表
2. 命令详解
选项:-f / --files
功能描述
指定要导入的文件或目录
支持文件路径、目录路径、通配符模式
导入的文件会被处理并存储到向量数据库中
使用示例
示例 1:导入单个文件
示例 2:导入多个文件
示例 3:导入目录下所有文件
示例 4:使用通配符
支持的文件格式
PDF(.pdf)
Word(.docx)
Markdown(.md)
文本文件(.txt)
Python 文件(.py)
其他支持的格式
选项:-q / --question
功能描述
指定要提问的问题
系统会基于已导入的文件内容生成答案
支持中文和英文提问
使用示例
示例 1:简单提问
示例 2:中文提问
示例 3:复杂问题
输出示例
选项:-c / --chat
功能描述
打开交互式聊天界面(Chat REPL)
支持多轮对话,上下文保持
支持流式输出,实时显示回答
使用示例
示例 1:打开聊天界面
示例 2:导入文件后打开聊天
聊天界面示例
选项:-v / --verbose
功能描述
显示详细的执行信息
包括文件处理进度、索引构建进度、检索过程等
适合调试和了解内部流程
使用示例
示例 1:详细模式导入文件
示例 2:详细模式提问
输出示例
选项:--clear
功能描述
清空向量数据库中所有已嵌入的数据
重新开始构建索引
注意:此操作不可恢复
使用示例
示例 1:清空数据
输出示例
选项:--create-llama
功能描述
基于已导入的文件创建完整的 LlamaIndex 应用
包含 FastAPI 后端和 NextJS 前端
一键生成、安装依赖并运行
使用示例
示例 1:创建应用
交互流程示例
3. 组合使用示例
示例 1:导入文件并立即提问
示例 2:详细模式导入文件并打开聊天
示例 3:清空数据后重新导入并提问
四、RAG-CLI 常用代码示例
1. 基础使用示例
示例 1:快速上手
示例 2:导入多个文件
示例 3:详细模式调试
2. 高级使用示例
示例 1:创建自定义 CLI 工具
使用方式
示例 2:创建 LlamaIndex 应用
示例 3:使用环境变量配置
3. 实际应用场景示例
场景 1:企业知识库问答
场景 2:代码文档问答
场景 3:技术文档问答
五、RAG-CLI 常见问题与解决方案
1. API Key 相关问题
问题:API Key 未设置
错误信息
解决方案
问题:API Key 无效
错误信息
解决方案
检查 API Key 是否正确
检查 API Key 是否过期
检查 API Key 是否有足够的权限
检查网络连接是否正常
2. 文件相关问题
问题:文件路径错误
错误信息
解决方案
检查文件路径是否正确
检查文件是否存在
使用绝对路径
使用通配符时确保有匹配的文件
问题:文件格式不支持
错误信息
解决方案
检查文件格式是否支持
转换为支持的格式(如 PDF、TXT、MD)
查看官方文档了解支持的格式列表
3. 依赖相关问题
问题:Chroma 未安装
错误信息
解决方案
问题:依赖版本冲突
错误信息
解决方案
更新依赖
创建虚拟环境
4. 性能相关问题
问题:导入文件速度慢
解决方案
减少同时导入的文件数量
使用更快速的嵌入模型
使用本地模型避免网络延迟
检查硬件资源(CPU、内存)
问题:回答生成慢
解决方案
使用更轻量的 LLM 模型
减少检索的文本块数量
使用流式输出
检查网络连接
5. 数据管理问题
问题:无法清空数据
错误信息
解决方案
检查文件权限
手动删除 Chroma 数据库目录
六、RAG-CLI 学习资源
官方文档
RAG-CLI 官方文档
包含安装、使用、自定义等详细指南
LlamaIndex 官方文档
完整的框架文档
社区资源
GitHub
LlamaIndex 主仓库
官方博客
RAG-CLI 发布博客
视频教程
YouTube 上搜索 "LlamaIndex RAG-CLI"
B 站上搜索 "LlamaIndex RAG-CLI"
学习路径建议
入门阶段
阅读官方文档,理解 RAG-CLI 的基本概念
安装依赖,配置环境
尝试导入文件并提问
进阶阶段
学习自定义配置,使用本地模型
尝试创建完整的 LlamaIndex 应用
学习调试和优化技巧
高级阶段
深入理解 RAG-CLI 的工作原理
开发自定义的 CLI 工具
贡献代码到 LlamaIndex 社区
七、总结
RAG-CLI 核心要点
<b>定位明确</b>:LlamaIndex 的命令行工具,用于快速构建和使用 RAG 系统
<b>零代码</b>:无需编写 Python 代码,命令行即可完成所有操作
<b>一键式</b>:一条命令即可完成文件导入、索引构建、问答等操作
<b>交互式</b>:支持聊天模式,在终端中进行多轮对话
<b>可扩展</b>:支持自定义模型和数据库,可完全本地化运行
<b>快速原型</b>:支持一键创建完整的 LlamaIndex 应用
RAG-CLI 适用场景
<b>快速查阅文档</b>:无需打开文档,直接通过命令行提问
<b>知识库问答</b>:将企业知识库导入,快速查询信息
<b>代码文档问答</b>:将代码文档导入,查询 API 使用方法
<b>演示展示</b>:在终端中展示 RAG 能力
<b>快速原型</b>:需要快速搭建演示应用
<b>学习参考</b>:学习 LlamaIndex 的使用方法
RAG-CLI 与 Python API 的对比
特性
<b>使用方式</b>
<b>上手难度</b>
<b>灵活性</b>
<b>适合场景</b>
<b>代码控制</b>
RAG-CLI
命令行
低
中
快速原型、简单任务
无
Python API
代码编写
中
高
复杂应用、深度定制
完全控制
学习建议
从官方文档开始,理解 RAG-CLI 的基本概念和使用方法
实践运行几个示例,熟悉命令行操作
尝试自定义配置,使用本地模型
探索创建完整的 LlamaIndex 应用
深入学习 LlamaIndex 的 Python API,实现更复杂的功能
LlamaPack 预打包模块系统思维导图(2026-06-26)
<b>注意</b>:本文档内容基于 LlamaIndex 官方文档和公开资料整理。由于框架 API 仍在持续演进,实际使用时请参考官方文档确认最新的 API 签名和用法。
一、LlamaPack 基础概念
1. 什么是 LlamaPack
定义
LlamaPack 是 LlamaIndex 提供的<b>社区驱动的预打包模块/模板系统</b>
由 LlamaIndex 团队于 2023 年 11 月正式发布
官方定位:"用于快速启动 LLM 应用的预打包模块中心"
核心价值
解决的痛点
构建 LLM 应用时,每个用例都需要从零开始选择和组合组件(LLM、嵌入模型、向量数据库、切分策略、检索算法等)
需要耗费大量调优和开发时间
对于初学者来说,选择合适的组件组合非常困难
LlamaPack 的解决方案
提供<b>开箱即用的预打包模块</b>,针对特定场景已经配置好最佳实践
提供<b>可定制的模板</b>,可以根据需求进行修改
社区驱动,持续丰富的模板库
项目现状
在 LlamaHub 上有大量 Pack 可用
支持通过 Python 和 CLI 两种方式使用
所有 Pack 都包含详细的 README 文档
2. LlamaPack 的作用
作用一:快速启动 LLM 应用
场景示例
场景 1:快速搭建 RAG 系统
不用从零开始配置向量数据库、嵌入模型、切分策略
只需下载一个 RAG Pack,几行代码即可运行
适合快速原型验证
场景 2:快速搭建 Streamlit 应用
下载 Streamlit Chatbot Pack
一键启动完整的聊天机器人界面
适合演示和内部工具
场景 3:快速实现特定功能
需要简历解析?下载 Resume Parser Pack
需要多模态检索?下载 Multi-modal Retrieval Pack
需要代码分析?下载 Code Hierarchy Pack
作用二:学习最佳实践
学习价值
每个 Pack 都是一个完整的示例项目
可以查看 Pack 的源代码,学习最佳实践
了解如何组合 LlamaIndex 的各个组件
学习如何配置参数、优化性能
学习方式
下载 Pack 后查看源代码
理解每个组件的作用
尝试修改参数,观察效果
基于 Pack 创建自己的应用
作用三:作为代码模板
定制价值
Pack 不仅可以直接使用,还可以作为模板进行定制
将 Pack 下载到本地后,可以修改任意代码
保留最佳实践,同时适应特定需求
适合团队内部复用
定制流程
下载 Pack 到本地目录
查看并理解源代码
根据需求修改代码
重新导入并使用修改后的 Pack
3. LlamaPack 与 LlamaIndex 的联系与区别
联系
依赖关系
LlamaPack 是 LlamaIndex 的<b>扩展生态</b>,依赖于 LlamaIndex 核心框架
所有 Pack 都使用 LlamaIndex 的核心组件(Document、Node、Index、Query Engine 等)
Pack 的开发基于 LlamaIndex 的 API
统一生态
LlamaPack 与 LlamaIndex 共享同一个生态系统(LlamaHub)
Pack 的下载和管理与 LlamaIndex 的其他组件(Data Loaders、Tools)统一
Pack 可以与 LlamaIndex 的其他组件混合使用
共同目标
都致力于降低 LLM 应用开发门槛
都遵循模块化设计理念
都支持社区贡献和扩展
区别
定位差异
特性
<b>定位</b>
<b>粒度</b>
<b>灵活性</b>
<b>易用性</b>
<b>适用场景</b>
LlamaIndex
核心框架,提供基础组件
细粒度,组件级别
高,可自由组合
中,需要了解组件
需要深度定制的场景
LlamaPack
预打包模块,提供完整解决方案
粗粒度,应用级别
中,基于模板定制
高,开箱即用
需要快速启动的场景
类比理解
LlamaIndex = 乐高积木套装
提供各种基础积木(Document、Node、Index、Query Engine)
需要自己设计和搭建
灵活性高,可以搭建任何东西
需要一定的学习成本
LlamaPack = 乐高成品模型
已经搭建好的完整模型
可以直接使用,无需自己搭建
可以拆开重新搭建,进行定制
适合快速获得成果
选择建议
选择 LlamaIndex 的情况
需要深度定制某个组件
需要构建非常特殊的应用
已经熟悉 LlamaIndex 的各个组件
需要完全掌控代码细节
选择 LlamaPack 的情况
需要快速启动项目
需要原型验证
需要学习最佳实践
需要复用成熟的解决方案
两者结合使用
使用 LlamaPack 快速启动项目
使用 LlamaIndex 核心组件进行深度定制
在 Pack 的基础上扩展功能
二、LlamaPack 组成部分
1. LlamaPack 核心结构
Pack 类
基础定义
每个 LlamaPack 都是一个 Python 类
继承自 LlamaIndex 的 BaseLlamaPack 基类
实现特定的功能逻辑
核心方法
__init__ 方法
初始化 Pack 的各种组件
配置参数
构建内部的索引、查询引擎等
get_modules 方法
返回 Pack 内部的所有模块
允许外部访问和使用 Pack 的子组件
返回值是一个字典,包含各种组件
run 方法
执行 Pack 的核心功能
根据不同的 Pack,run 方法的参数和返回值不同
通常接受用户查询,返回回答或处理结果
Pack 目录结构
标准结构
详细说明
__init__.py
导出 Pack 的主类
通常包含 from .base import PackName 语句
方便外部导入
base.py
Pack 的核心实现文件
包含 Pack 类的定义
实现 __init__、get_modules、run 等方法
requirements.txt
Pack 的依赖列表
下载 Pack 时会自动安装这些依赖
确保 Pack 可以正常运行
README.md
Pack 的使用说明文档
包含安装方法、初始化参数、使用示例等
是使用 Pack 的重要参考
2. LlamaPack 模块类型
按功能分类
RAG 流程类 Pack
定义
封装完整的 RAG 流程
包含数据加载、索引构建、查询引擎等所有组件
通常针对特定的向量数据库或嵌入模型优化
示例
VoyageQueryEnginePack:使用 Voyage AI 嵌入的 RAG 系统
DeepMemoryPack:使用 DeepLake 的深度记忆检索
TimescaleVectorAutoRetrieval:使用 Timescale 的自动检索
应用模板类 Pack
定义
封装完整的应用模板
包含前端界面和后端逻辑
可以直接运行
示例
StreamlitChatbotPack:Streamlit 聊天机器人应用
GradioChatbotPack:Gradio 聊天机器人应用
功能组件类 Pack
定义
封装特定的功能组件
可以作为子模块导入使用
提供特定的能力
示例
ResumeParserPack:简历解析
LLaVaCompletionPack:多模态完成
CodeHierarchyAgentPack:代码层级分析
评估监控类 Pack
定义
封装评估和监控功能
用于评估 RAG 系统的性能
提供可观测性
示例
TruLensEvalPack:TruLens 评估
ArizePhoenixQueryEnginePack:Arize Phoenix 监控
数据处理类 Pack
定义
封装数据处理功能
用于特定格式的数据处理
提供数据转换能力
示例
LlamaParsePack:文档解析
MultiModalRetrievalPack:多模态数据检索
按复杂度分类
轻量级 Pack
特点
代码量少,结构简单
专注于单一功能
易于理解和定制
示例
SimpleQueryEnginePack:简单的查询引擎
BasicRAGPack:基础的 RAG 流程
重量级 Pack
特点
代码量大,功能复杂
包含多个子组件
提供完整的解决方案
示例
StreamlitChatbotPack:完整的聊天机器人应用
CodeHierarchyAgentPack:复杂的代码分析系统
3. LlamaPack 管理方式
下载方式
Python API 方式
代码示例
参数说明
pack_name:Pack 的名称,必须与 LlamaHub 上的名称一致
download_dir:下载目录,Pack 会被下载到该目录下
返回值:Pack 类,可以直接用于实例化
CLI 方式
命令示例
参数说明
pack_name:Pack 的名称
--download-dir 或 -d:下载目录
安装方式对比
方式
Python API
CLI
优点
可以在代码中直接使用
简单快捷,一行命令
缺点
需要写代码
需要手动导入
适用场景
程序化下载、自动化脚本
交互式使用、一次性下载
使用方式
方式一:开箱即用
代码示例
优点
最简单的使用方式
几行代码即可运行完整功能
适合快速原型验证
方式二:检查模块
代码示例
优点
可以访问 Pack 的内部组件
可以单独使用某个组件
适合调试和学习
方式三:定制模板
步骤说明
<b>下载 Pack</b>
<b>查看源代码</b>
打开 ./voyage_pack/base.py
理解 Pack 的实现逻辑
<b>修改代码</b>
修改 LLM 配置
修改嵌入模型
修改切分策略
添加自定义逻辑
<b>重新导入使用</b>
优点
可以完全定制 Pack 的行为
保留最佳实践的基础上进行扩展
适合生产环境使用
三、LlamaPack 常用代码示例
1. 下载并使用 RAG Pack
2. 使用 Streamlit Chatbot Pack
3. 定制 Pack 模板
4. 使用代码层级分析 Pack
5. 使用多模态检索 Pack
6. 使用简历解析 Pack
7. 使用评估 Pack
四、LlamaPack 常见类型与示例
1. RAG 流程类 Pack
VoyageQueryEnginePack
功能描述
使用 Voyage AI 嵌入模型的 RAG 系统
包含完整的数据加载、索引构建、查询流程
针对 Voyage AI 的嵌入模型进行优化
初始化参数
documents:文档列表
embed_model:嵌入模型(可选,默认使用 Voyage AI)
llm:语言模型(可选,默认使用 GPT-4)
代码示例
DeepMemoryPack
功能描述
使用 DeepLake 的深度记忆检索系统
支持多轮对话中的上下文记忆
适合需要长期记忆的场景
初始化参数
documents:文档列表
deeplake_path:DeepLake 存储路径
llm:语言模型
代码示例
2. 应用模板类 Pack
StreamlitChatbotPack
功能描述
完整的 Streamlit 聊天机器人应用
包含前端界面和后端逻辑
支持文件上传和文档问答
使用方式
界面特点
支持文件上传(PDF、Word、Markdown 等)
支持历史对话
支持引用来源显示
支持流式输出
3. 功能组件类 Pack
CodeHierarchyAgentPack
功能描述
代码层级分析系统
将代码文件切分为层次结构(函数、类、方法)
支持代码理解和查询
初始化参数
documents:代码文档列表
llm:语言模型
code_splitter:代码切分器(可选)
代码示例
ResumeParserPack
功能描述
简历解析系统
从 PDF/Word 简历中提取结构化信息
支持自定义问题查询
初始化参数
llm:语言模型(可选)
代码示例
4. 评估监控类 Pack
TruLensEvalPack
功能描述
使用 TruLens 进行 RAG 系统评估
支持多种评估指标(相关性、正确性、流畅性等)
提供可视化报告
初始化参数
documents:文档列表
eval_questions:评估问题列表
llm:语言模型
代码示例
ArizePhoenixQueryEnginePack
功能描述
使用 Arize Phoenix 进行 RAG 系统监控
支持实时追踪查询性能
提供错误分析和优化建议
初始化参数
documents:文档列表
llm:语言模型
代码示例
五、LlamaPack 最佳实践
1. 选择合适的 Pack
根据场景选择
快速原型验证
选择开箱即用的 Pack
优先选择 RAG 流程类 Pack
如:VoyageQueryEnginePack、DeepMemoryPack
演示和展示
选择应用模板类 Pack
优先选择带界面的 Pack
如:StreamlitChatbotPack
特定功能需求
选择功能组件类 Pack
根据具体需求选择
如:简历解析选 ResumeParserPack
系统评估和监控
选择评估监控类 Pack
如:TruLensEvalPack、ArizePhoenixQueryEnginePack
查看 Pack 文档
查看 README
下载前先查看 LlamaHub 上的 README
了解 Pack 的功能、参数、使用方法
确认是否符合需求
查看依赖
确认 Pack 的依赖是否与项目兼容
注意 Python 版本要求
注意第三方服务的 API Key 要求
2. 定制 Pack 的技巧
保留最佳实践
理解 Pack 的设计
查看 Pack 的源代码
理解为什么这样配置
保留合理的配置
渐进式修改
先运行原始 Pack,确认功能正常
逐步修改一个参数,测试效果
避免一次性修改过多
常见定制点
修改 LLM
将 GPT-4 改为 Claude 或其他模型
修改模型参数(temperature、max_tokens 等)
添加自定义 LLM
修改嵌入模型
将默认嵌入模型改为其他模型
修改嵌入模型参数
添加自定义嵌入模型
修改切分策略
修改 chunk_size 和 chunk_overlap
更换切分器类型
添加自定义切分逻辑
修改检索策略
修改 similarity_top_k
添加混合检索
添加后处理步骤
3. Pack 的复用和共享
内部复用
创建组织模板
将常用的 Pack 定制后保存为内部模板
团队成员可以直接使用
保持一致性
文档化定制
记录定制的内容和原因
分享给团队成员
建立知识共享
社区贡献
提交新 Pack
如果开发了有用的 Pack,可以提交到 LlamaHub
遵循贡献指南
提供详细的 README 文档
改进现有 Pack
发现 Pack 的问题可以提交 PR
提供更好的配置建议
优化代码性能
六、LlamaPack 学习资源
官方文档
LlamaPack 官方介绍
包含 Pack 的概念、使用模式、模块指南
LlamaPack 示例
包含完整的使用示例
LlamaHub
所有 Pack 的列表和详细信息
可以按类别筛选 Pack
社区资源
GitHub
LlamaIndex 主仓库
Pack 的源代码
Discord
LlamaIndex 官方 Discord 服务器
可以提问和讨论
博客文章
LlamaPack 发布博客
学习路径建议
入门阶段
阅读官方文档,理解 LlamaPack 的概念
下载并运行一个简单的 Pack(如 VoyageQueryEnginePack)
熟悉 Pack 的基本使用流程
进阶阶段
尝试不同类型的 Pack
学习查看和修改 Pack 的源代码
尝试定制一个 Pack
高级阶段
开发自己的 Pack
提交到 LlamaHub
参与社区贡献
七、总结
LlamaPack 核心要点
<b>定位明确</b>:LlamaIndex 的预打包模块系统,提供开箱即用的解决方案
<b>社区驱动</b>:在 LlamaHub 上有大量 Pack 可用,持续更新
<b>多种使用方式</b>:支持开箱即用、检查模块、定制模板三种方式
<b>降低门槛</b>:让开发者可以快速启动 LLM 应用,无需从零开始
<b>学习价值</b>:每个 Pack 都是一个完整的示例,可以学习最佳实践
<b>灵活定制</b>:可以下载后修改源代码,适应特定需求
LlamaPack 适用场景
需要快速启动项目时
需要原型验证时
需要学习最佳实践时
需要复用成熟的解决方案时
需要快速搭建演示应用时
与 LlamaIndex 的关系
LlamaPack 依赖于 LlamaIndex 核心框架
LlamaIndex 提供基础组件,LlamaPack 提供完整解决方案
两者可以结合使用,发挥最大价值
学习建议
从官方文档开始,理解 LlamaPack 的概念
实践运行几个不同类型的 Pack,熟悉使用流程
查看 Pack 的源代码,学习如何组合 LlamaIndex 组件
尝试定制一个 Pack,适应自己的需求
探索 LlamaHub 上的更多 Pack,发现有用的解决方案
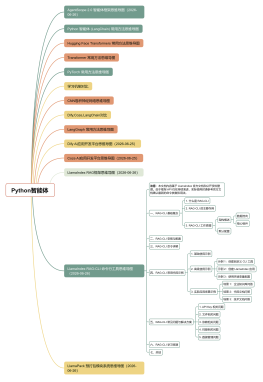
收藏
立即使用

收藏
立即使用
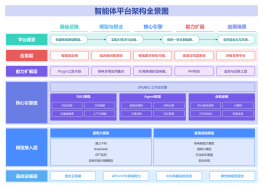
Collect
Get Started
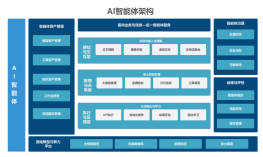
Collect
Get Started
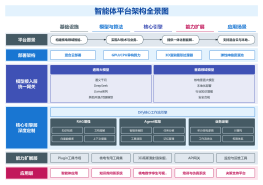
Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

