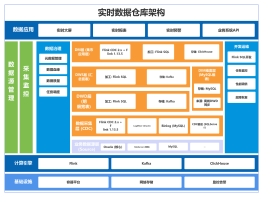
数据仓库
2015-11-03 15:19:04 7 举报数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。它为企业决策者提供了深入观察、分析和应用整个企业内的各种数据的能力。数据仓库通常包含大量历史数据,这些数据经过清洗和转换后以多维形式存储,以便进行高级分析和报表生成。数据仓库的主要特点是其数据的集成性和时间序列性,这使得它能够提供对过去和现在业务情况的全面视图,从而帮助企业做出更好的战略决策。
模板推荐
作者其他创作
大纲/内容




0 条评论
下一页