AI
推荐
模板社区
专题
登录
免费注册
首页
流程图
详情
通用网络爬虫结构图
2016-06-13 21:02:29
0
举报
分享方式
仅支持查看
通用网络爬虫是一种自动获取网页内容的程序,其基本结构包括初始URL集合、URL队列、页面下载器、页面解析器、链接过滤器和数据存储器。初始URL集合是爬虫开始爬取的URL列表,URL队列用于存储待爬取的URL,页面下载器负责从URL中下载网页内容,页面解析器用于解析下载的网页内容并提取所需信息,链接过滤器用于过滤掉不需要爬取的链接,数据存储器用于存储爬取到的数据。
模板推荐
作者其他创作
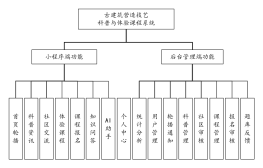
大纲/内容
Web
页面链接
页面内容
URL队列
页面爬行模块
页面库
初始URL
页面分析模块
链接过滤模块
收藏
立即使用
DeepWeb 爬虫体系结构
收藏
立即使用
增量爬虫体系结构图
收藏
立即使用
聚焦网络爬虫结构图
收藏
立即使用
通用网络爬虫结构图
流星258
职业:暂无
去主页
Collect
Get Started
系统结构图
Collect
Get Started
结构图
Collect
Get Started
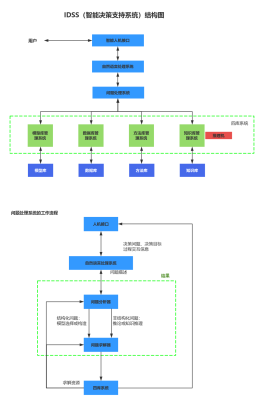
智能决策系统结构图
Collect
Get Started
爬虫系统架构图
评论
0
条评论
下一页
Document