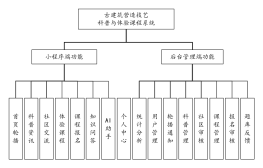
聚焦网络爬虫结构图
2016-06-13 21:02:29 0 举报网络爬虫是一种自动浏览万维网的网络机器人。其基本结构通常包括控制器、解析器和资源库三部分。控制器负责给爬虫发出指令,如去哪里爬取数据,如何爬取等;解析器则负责分析网页内容,提取出有价值的信息,如文本、图片、链接等;资源库用于存储爬取到的数据。此外,网络爬虫还可能包含一个调度器,用于控制爬虫的工作流程,如什么时候去爬取新的网页,什么时候更新已爬取的网页等。网络爬虫的工作过程通常是首先从种子URL开始,然后通过解析器解析出该页面上的所有链接,再将这些链接添加到待爬取队列中,如此循环,直到满足停止条件为止。