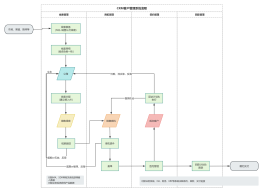
抓取流程
2017-03-27 06:48:27 0 举报抓取流程通常包括以下步骤:首先,确定目标网站和数据源。然后,使用网络爬虫工具(如Python的BeautifulSoup库或Scrapy框架)编写代码来抓取网页内容。接下来,解析网页源代码,提取所需的数据信息。在这个过程中,可能需要处理各种问题,如反爬虫策略、动态加载内容等。一旦数据被提取,将其存储在适当的格式中,如CSV文件或数据库。最后,对抓取到的数据进行清洗和分析,以便于进一步的应用。整个抓取流程需要不断优化,以提高抓取速度、准确性和稳定性。
模板推荐
作者其他创作
大纲/内容







0 条评论
下一页