
kubernetes
2020-12-09 16:50:11 0 举报AI智能生成
k8s 学习笔记
k8s 学习笔记
模板推荐
作者其他创作
大纲/内容
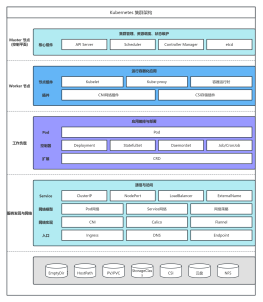
master
概念
Master是Cluster的大脑,它的主要职责是调度,即决定将应用放<br>在哪里运行。Master运行Linux操作系统,可以是物理机或者虚拟<br>机。为了实现高可用,可以运行多个Master。默认配置下Kubernetes不会将Pod调度到Master节<br>点
Cluster
组成
master
API Server
API Server提供HTTP/HTTPS RESTful API,即Kubernetes API。<br>API Server是Kubernetes Cluster的前端接口,各种客户端工具(CLI或<br>UI)以及Kubernetes其他组件可以通过它管理Cluster的各种资源。
Scheduler(kube-scheduler)
Scheduler负责决定将Pod放在哪个Node上运行。Scheduler在调度<br>时会充分考虑Cluster的拓扑结构,当前各个节点的负载,以及应用对<br>高可用、性能、数据亲和性的需求。
Controller Manager(kube-controller-manager)
Controller Manager负责管理Cluster各种资源,保证资源处于预期<br>的状态。Controller Manager由多种controller组成,包括replication<br>controller、endpoints controller、namespace controller、serviceaccounts<br>controller等。<br>不同的controller管理不同的资源。例如,replication controller管<br>理Deployment、StatefulSet、DaemonSet的生命周期,namespace<br>controller管理Namespace资源。
etcd
etcd负责保存Kubernetes Cluster的配置信息和各种资源的状态信<br>息。当数据发生变化时,etcd会快速地通知Kubernetes相关组件
Pod网络
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,<br>flannel是其中一个可选方案。
概念
master运行着的Daemon服务包括<br>kube-apiserver、kube-scheduler、kube-controller-manager、etcd和Pod<br>网络(例如flannel)
node
概念
Node是Pod运行的地方,Kubernetes支持Docker、rkt等容器<br>Runtime。Node上运行的Kubernetes组件有kubelet、kube-proxy和Pod<br>网络(例如flannel)
kubelet
kubelet是Node的agent,当Scheduler确定在某个Node上运行Pod<br>后,会将Pod的具体配置信息(image、volume等)发送给该节点的<br>kubelet,kubelet根据这些信息创建和运行容器,并向Master报告运行<br>状态
kube-proxy
每个Node都会运行kube-proxy服务,它负责将访问service的<br>TCP/UPD数据流转发到后端的容器。如果有多个副本,kube-proxy会<br>实现负载均衡。
Pod网络
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,<br>flannel是其中一个可选方案。
概念
Cluster是计算、存储和网络资源的集合,Kubernetes利用这些资<br>源运行各种基于容器的应用
Controller
类型
Deployment
Deployment可以管理Pod的多个副<br>本,并确保Pod按照期望的状态运行
ReplicaSet
ReplicaSet实现了Pod的多副本管理。使用Deployment时会<br>自动创建ReplicaSet,也就是说Deployment是通过ReplicaSet来管理<br>Pod的多个副本的,我们通常不需要直接使用ReplicaSet。
DaemonSet
DaemonSet用于每个Node最多只运行一个Pod副本的场景。<br>正如其名称所揭示的,DaemonSet通常用于运行daemon
StatefuleSet
StatefuleSet能够保证Pod的每个副本在整个生命周期中名称<br>是不变的,而其他Controller不提供这个功能。当某个Pod发生故障需<br>要删除并重新启动时,Pod的名称会发生变化,同时StatefuleSet会保<br>证副本按照固定的顺序启动、更新或者删除。
Job
Job用于运行结束就删除的应用,而其他Controller中的Pod<br>通常是长期持续运行。
概念
Kubernetes通常不会直接创建Pod,而是通过Controller来管理Pod<br>的。Controller中定义了Pod的部署特性,比如有几个副本、在什么样<br>的Node上运行等。为了满足不同的业务场景,Kubernetes提供了多种<br>Controller,包括Deployment、ReplicaSet、DaemonSet、StatefuleSet、<br>Job等
架构图
k8s arch
Flannel网络架构图
Kubernetes工作流程
总体架构图
1.kubectl get nodes --查看节点信息<br><br>2.kubectl cluster-info --查看集群信息<br><br>3.kubectl run kubernetes-bootcamp \<br>--image=docker.io/jocatalin/kubernetes-bootcamp:v1 \<br>--port=8080 <br> 部署一个应用kubernetes-bootcamp 镜像为docker.io/jocatalin/kubernetes-bootcamp:v1 端口为8080<br><br>4.kubectl get pods --查看当前pod<br><br><br>5.kubectl expose deployment/kubernetes-bootcamp \<br>--type="NodePort" \<br>--port 8080<br> 把8080端口映射到节点的端口,因为pod 只能在集群内部访问,我们需要从外部访问应用<br> 6.kubectl get services --查看应用被映射到节点的哪个端口<br><br> 7.curl host01:32320 --访问指定节点端口对应的pod应用<br><br> 8.kubectl get deployments --查看副本数<br><br> 9.kubectl scale deployments/kubernetes-bootcamp --replicas=3 //将kubernetes-bootcamp的副本增加到3个<br><br> 10.kubectl scale deployments/kubernetes-bootcamp --replicas=2 //将kubernetes-bootcamp的副本数减少到2个<br><br> 11.kubectl set image deployments/kubernetes-bootcamp<br>kubernetes-bootcamp=jocatalin/kubernetes-bootcamp:v2 //将kubernetes-bootcamp 应用的版本升级到v2<br><br>12.kubectl rollout undo deployments/kubernetes-bootcamp //将kubernetes-bootcamp 应用版本回退到上个版本<br>13.kubectl get pods --all-namespaces -o wide #展示出IP和node信息<br>14.kubectl describe deployment kubernetes-bootcamp #展示deploy 详细信息<br>15.kubectl describe replicasets #命令可以打印出rs控制器的详细状态<br>16.kubectl describe pod kubernetes-bootcamp #展示pod 详细信息<br>17.kubectl delete deployment nginx-deployment #删除指定的资源<br>18.kubectl delete -f xxx.yaml #指定配置文件删除容器<br>19.kubectl taint node k8s-master node-role.kubernetes.io/master- #允许将master节点 当做node节点使用<br>20.kubectl taint node k8s-master node-role.kubernetes.io/master="" #禁止将master节点当做 node节点使用<br>21.kubectl label node k8s-node1 disktype=ssd #为node 指定label <br>22.kubectl get node --show-labels #查看节点的label<br>23.kubectl label node k8s-node1 disktype- 删除节点k8s-node1 上的label 名称disktype<br>24.kubectl get daemonset --namespace=kube-system #查看系统默认的deamonset组件<br>25.kubectl api-versions #查看apiserver 支持的版本<br>26.kubectl get pod --show-all #查看所有的pod<br>27.kubectl logs *** #查看pod的log信息<br>28.kubectl get jobs #查看所有的job<br>29.kubectl get cronjob #查看CronJob的状态<br>30.kubectl describe service httpd #获取服务详情 <br>31.kubectl rollout history deployment httpd #查看revison历史记录<br>32.kubectl rollout undo deployment httpd --to-revision=1 #回退到指定的记录点<br>33.kubectl exec -it busybox sh #进入busyboxy 容器内部<br>34.kubectl exec podname touch /a/b #在容器内部创建文件<br>35.kubectl get revisions #获取快照<br>36.kubectl get configurations #获取配置信息<br>37.kubectl get configuration knative-helloworld -oyaml #获取指定配置信息的yaml格式显示<br>38.kubectl get ksvc 获取 knative service 服务<br>39.kubectl rollout status #查看 Deployment 对象的状态变化<br>40.kubectl get rs #<br>41.kubectl label nodes <node-name> <label-key>=<label-value> #给pod 打标签<br>
Pod
引入POD的原因
可管理性
通信和资源共享
二种使用方式
运行单一容器。
运行多个容器
概念
Pod是Kubernetes的最小工作单元。每个Pod包含一个或多个容<br>器。Pod中的容器会作为一个整体被Master调度到一个Node上运行
Node
概念
Node的职责是运行容器应用。Node由Master管理,Node负责监<br>控并汇报容器的状态,同时根据Master的要求管理容器的生命周期。<br>Node运行在Linux操作系统上,可以是物理机或者是虚拟机
service
概念
Service定义了外界访问一组特定Pod的方式。Service<br>有自己的IP和端口,Service为Pod提供了负载均衡。
Namespace
默认namespace
default:创建资源时如果不指定,将被放到这个Namespace中。<br>kube-system:Kubernetes自己创建的系统资源将放到这个<br>Namespace中。
概念
Namespace可以将一个物理的Cluster逻辑上划分成多个虚拟<br>Cluster,每个Cluster就是一个Namespace。不同Namespace里的资源是<br>完全隔离的。
运行容器
kubectl run httpd-app --image=httpd --replicas=2 这条命令经过哪些流程处理?
① kubectl发送部署请求到API Server。<br>② API Server通知Controller Manager创建一个deployment资源。<br>③ Scheduler执行调度任务,将两个副本Pod分发到k8s-node1和<br>k8s-node2。<br>④ k8s-node1和k8s-node2上的kubectl在各自的节点上创建并运行<br>Pod。
用户通过kubectl<br> (1)创建Deployment。<br>(2)Deployment创建ReplicaSet。<br>(3)ReplicaSet创建Pod。<br>(4)对象的命名方式是“子对象的名字=父对象<br>名字+随机字符串或数字”
kubectl apply -f xxx.yaml 声明pod
① apiVersion是当前配置格式的版本。<br>② kind是要创建的资源类型,这里是Deployment。<br>③ metadata是该资源的元数据,name是必需的元数据项。<br>④ spec部分是该Deployment的规格说明。<br>⑤ replicas指明副本数量,默认为1。<br>⑥ template定义Pod的模板,这是配置文件的重要部分。<br>⑦ metadata定义Pod的元数据,至少要定义一个label。label的key<br>和value可以任意指定。<br>⑧ spec描述Pod的规格,此部分定义Pod中每一个容器的属性,<br>name和image是必需的。
Failover
设 master ,node1,node2 共3个节点 ,<br>当前共运行5个pod,node1 运行3个pod,node2 运行2个pod,<br>此时node2 突然宕机,此时会发生什么?<br>1.k8s 会监测到node2 不可用,将node2上的pod 标记为unknow 状态<br>2.k8s 会在node1 上创建2个pod 维持总得pod数在 5个<br>3.当node2 恢复后 标记为unknow的pod 会被删除<br><br>
label
kubectl label node k8s-node1 disktype=ssd 为node k8s-node1 声明label 名称disktype
kubectl get node --show-labels 查看node上的label<br>
kubectl label node k8s-node1 disktype - <br>删除node k8s-node1上的label disktype<br>Pod并不会重新部署,依然在k8s-node1上运行
如何使用label,声明pod 的文件里指定nodeSelector
controller
Deployment部署的副本Pod会分布在各个Node上,每个Node都可<br>能运行好几个副本
几种状态
DESIRED
表示期望的状态是n个READY的副本
CURRENT
表示当前副本的总数
UP-TO-DATE
表示当前已经完成更新的副本数
AVAILABLE
表示当前处于READY状态的副本数
DaemonSet的不同之处在于:每个Node上最多只<br>能运行一个副本。
应用场景
在集群的每个节点上运行存储Daemon,比如glusterd或<br>ceph
在每个节点上运行日志收集Daemon,比如flunentd或<br>logstash。
在每个节点上运行监控Daemon,比如Prometheus Node<br>Exporter或collectd
系统默认运行的deamonset
kube-flannel-ds
kube-proxy
job
普通job
定时job
并行性
parallelism同时运行多少pod
completionsJob成功完成Pod的总数
pod
重新启动策略
Never
此失败容器不会被重启
OnFailure
此失败容器会被重启
Pod的IP是在容器<br>中配置
状态
CrashLoopBackOff: 容器退出,kubelet正在将它重启<br>InvalidImageName: 无法解析镜像名称<br>ImageInspectError: 无法校验镜像<br>ErrImageNeverPull: 策略禁止拉取镜像<br>ImagePullBackOff: 正在重试拉取<br>RegistryUnavailable: 连接不到镜像中心<br>ErrImagePull: 通用的拉取镜像出错<br>CreateContainerConfigError: 不能创建kubelet使用的容器配置<br>CreateContainerError: 创建容器失败<br>m.internalLifecycle.PreStartContainer 执行hook报错<br>RunContainerError: 启动容器失败<br>PostStartHookError: 执行hook报错 <br>ContainersNotInitialized: 容器没有初始化完毕<br>ContainersNotReady: 容器没有准备完毕 <br>ContainerCreating:容器创建中<br>PodInitializing:pod 初始化中 <br>DockerDaemonNotReady:docker还没有完全启动<br>NetworkPluginNotReady: 网络插件还没有完全启动
镜像拉取方式
Always
总是拉取 pull<br>
IfNotPresent
默认值,本地有则使用本地镜像,不拉取
Never
只使用本地镜像,从不拉取
Service
概念
Service从逻辑上代表了一组Pod,具体是哪些Pod则是<br>由label来挑选的。Service有自己的IP,而且这个IP是不变的。客户端<br>只需要访问Service的IP,Kubernetes则负责建立和维护Service与Pod的<br>映射关系。无论后端Pod如何变化,对客户端不会有任何影响,因为<br>Service没有变
创建Service
新建deployment
新建service
① v1是Service的apiVersion。 <br>② 指明当前资源的类型为Service。<br> ③ Service的名字为httpd-svc。<br> ④ selector指明挑选那些label为run: httpd的Pod作为Service的后 端。 <br>⑤ 将Service的8080端口映射到Pod的80端口,使用TCP协议。
查看service命令
kubectl get service #获取service列表
kubectl describe service service_name #获取服务详情
Service ClusterIp
Cluster IP是一个虚拟IP
由Kubernetes节点上的iptables规则管<br>理
通过Cluster IP 连接绑定的pod
iptables将访问Service的流量转发到后端Pod
使用类似<br>轮询的负载均衡策略
Cluster的每一个节点都配置了相同的<br>iptables规则确保了整个Cluster都能够通过Service的Cluster IP<br>访问Service
流程图
外网如何访问Service
声明要暴露server 到外网
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/httpd-svc:" -m tcp --dport 31254 -j KUBE-MARK-MASQ<br>-A KUBE-NODEPORTS -p tcp -m comment --comment "default/httpd-svc:" -m tcp --dport 31254 -j KUBE-SVC-RL3JAE4GN7VOGDGP<br>每个节点新增两个iptables 规则
EXTERNAL-IP为nodes,表示可通过Cluster每个节点自身<br>的IP访问Service。<br>PORT(S)为8080:32312。8080是ClusterIP监听的端口,<br>32312则是节点上监听的端口。Kubernetes会从30000~32767中分配一<br>个可用的端口,每个节点都会监听此端口并将请求转发给Service<br>
自定义暴露node端口<br>nodePort在node上,负责对外通信,NodeIP:NodePort<br>port在service上,负责处理对内的通信,clusterIP:port<br>targetPort 负责与kube-proxy代理的port和Nodeport数据进行通信<br>containerPort 在容器上,用于被pod绑定<br>
Rolling Update<br>滚动更新
概念
滚动更新是一次只更新一小部分副本,成功后再更新更多的副<br>本,最终完成所有副本的更新
特点
1.滚动更新的最大好处是零停机,整个<br>更新过程始终有副本在运行,从而保证了业务的连续性。<br>2.每次更新应用时,Kubernetes都会记录下当前的配<br>置,保存为一个revision(版次),这样就可以回滚到某个特定<br>revision<br>
例子
把nginx:1.7.8升级到nginx:1.7.9
创建nginx.yaml<br>执行kubectl apply -f nginx.yaml<br> nginx.ynginx:1.7.8 的deployment
详细步骤<br>(1)创建Deployment nginx。<br>(2)创建ReplicaSet nginx-1728888140。<br>(3)创建三个Pod。<br>(4)当前镜像为httpd:1.7.8。
修改yaml 中nginx image 版本为1.7.9 <br>重新执行kubectl apply -f nginx.yaml
详细步骤<br>(1)Deployment httpd的镜像更新为nginx:1.7.8。 <br>(2)新创建了ReplicaSet nginx-1810152781,<br>镜像为 nginx:1.7.9,并且管理了三个新的Pod。 <br>(3)之前的ReplicaSet nginx-1728888140里面已经没有任何Pod。<br>具体过程可以通过kubectl describe deployment nginx <br>
回退
kubectl rollout<br>history deployment nginx #查看版本记录
kubectl apply -f nginx.1.7.8.yaml --record<br>--record的作用是将当前命令记录到revision记录<br>
kubectl rollout undo deployment nginx --to-revision=2<br>#--to-revision 回退到指定的记录点
参数
maxSurge
此参数控制滚动更新过程中副本总数超过DESIRED的上限
可以是具体的整数(比如3),也可以是百分百,向上取<br>整
默认值为25%
设DESIRED为10,那么副本总数的最大值为<br>roundUp(10 + 10 * 25%) =13,所以我们看到CURRENT就是13
maxSurge值越大,初始创建的新副本数量就越多
maxUnavailable
此参数控制滚动更新过程中,不可用的副本相占DESIRED的最<br>大比例
maxUnavailable可以是具体的整数(比如3),也可以是百分<br>百,向下取整
maxUnavailable默认值为25%
设DESIRED为10,那么可用的副本数至少要为<br>10 - roundDown(10 * 25%)= 8,所以我们看到AVAILABLE是8
maxUnavailable值越大,初始销毁的旧副本数量就越多
更新案例
设副本数10 maxSurge和maxUnavailable都取默认值则启动流程如下:<br>(1)创建3个新副本使副本总数达到13个。<br>(2)销毁2个旧副本使可用的副本数降到8个。<br>(3)当2个旧副本成功销毁后,再创建2个新副本,使副本总数<br>保持为13个。<br>(4)当新副本通过Readiness探测后,会使可用副本数<br>增加,超过8。<br>113<br>(5)进而可以继续销毁更多的旧副本,使可用副本数回到8。<br>(6)旧副本的销毁使副本总数低于13,这样就允许创建更多的<br>新副本。<br>(7)这个过程会持续进行,最终所有的旧副本都会被新副本替<br>换,滚动更新完成。<br>
Health Check
默认
每个容器启动时<br>都会执行一个进程,此进程由Dockerfile的CMD或ENTRYPOINT指<br>定。如果进程退出时返回码非零,则认为容器发生故障,Kubernetes<br>就会根据restartPolicy重启容器。restartPolicy默认的启动策略是AlWays
Liveness
使用场景
类似500 或者其他用户自定义的检查
使用方法
在创建的pod声明文件中增加以下<br>livenessProbe:<br>exec:<br>command:<br>- cat<br>- /tmp/healthy<br>initialDelaySeconds: 5#指定容器启动5秒之后执行健康检查<br>periodSeconds: 5 #指定每5秒执行一次Liveness探测
概念
Liveness探测让用户可以自定义判断容器是否健康的条件。如果<br>探测失败,Kubernetes就会重启容器
Readiness
概念
Readiness探测则是告诉Kubernetes什么时候可以将容器<br>加入到Service负载均衡池中,对外提供服务,探测到服务异常不重启,<br>需要配合liveness 使用
使用方法
在创建的pod声明文件中增加以下<br>readinessProbe:<br> exec:<br> command:<br> - cat<br> - /tmp/healthy<br> initialDelaySeconds: 5<br> periodSeconds: 5<br>
使用场景
需要检查此服务是否可以对外提供服务,<br>探测到服务异常后把此服务冲负载均衡池中摘除
Liveness VS Readiness
Liveness探测和Readiness探测是两种Health Check机制,如<br>果不特意配置,Kubernetes将对两种探测采取相同的默认行为,即通<br>过判断容器启动进程的返回值是否为零来判断探测是否成功
两种探测的配置方法完全一样,支持的配置参数也一样。<br>不同之处在于探测失败后的行为:Liveness探测是重启容器;<br>Readiness探测则是将容器设置为不可用,不接收Service转发的请求。
Liveness探测和Readiness探测是独立执行的,二者之间没<br>有依赖,所以可以单独使用,也可以同时使用。用Liveness探测判断<br>容器是否需要重启以实现自愈;用Readiness探测判断容器是否已经准<br>备好对外提供服务。
Readiness实例
1)容器启动10秒之后开始探测。<br>(2)如果http://[container_ip]:8080/healthy返回代码不是200~<br>400,表示容器没有就绪,不接收Service web-svc的请求。<br>(3)每隔5秒探测一次。<br>(4)直到返回代码为200~400,表明容器已经就绪,然后将其<br>加入到web-svc的负载均衡中,开始处理客户请求。<br>(5)探测会继续以5秒的间隔执行,如果连续发生3次失败,容<br>器又会从负载均衡中移除,直到下次探测成功重新加入。
数据管理
作用
为集群<br>中的容器提供存储
生命周期
独立于容器,Pod中的容器可能被销毁和重<br>建,但Volume会被保留
概念
Volume是一个目录
特点
当Volume被mount到Pod,Pod中的所有容器都可以访<br>问这个Volume
Pod中的所有容器都可以共享Volume,它们可以指定各自的<br>mount路径
静态供给
emptyDir
概念
一个<br>emptyDir Volume是Host上的一个空目录
特点
emptyDir Volume对于容器来说是持久的,对于Pod则不是。当<br>Pod从节点删除时,Volume的内容也会被删除。但如果只是容器被销<br>毁而Pod还在,则Volume不受影响。
其优点是能够方便地为Pod<br>中的容器提供共享存储,不需要额外的配置。它不具备持久性,如果<br>Pod不存在了,emptyDir也就没有了
生命周期
emptyDir Volume的生命周期与Pod一致
使用场景
emptyDir特别<br>适合Pod中的容器需要临时共享存储空间的场景
hostPath
特点
如果Pod被销毁了,hostPath对应的目录还是会被保留,从这一点<br>来看,hostPath的持久性比emptyDir强。不过一旦Host崩溃,hostPath<br>也就无法访问了
概念
hostPath Volume的作用是将Docker Host文件系统中已经存在的目<br>录mount给Pod的容器大部分应用都不会使用hostPath Volume,<br>因为<br>这实际上增加了Pod与节点的耦合,限制了Pod的使用
使用场景
需<br>要访问Kubernetes或Docker内部数据(配置文件和二进制库)的应用<br>则需要使用hostPath
定义了三个hostPath:volume k8s、certs和pki,分别对应<br>Host目录/etc/kubernetes、/etc/ssl/certs和/etc/pki
Storage Provider
Ceph
Ceph文件系统的/some/path/in/side/cephfs目录被mount到容器路<br>径/test-ceph。
特点
相对于emptyDir和hostPath,这些Volume类型的最大特点就是不<br>依赖Kubernetes
Volume的底层基础设施由独立的存储系统管理,与<br>Kubernetes集群是分离的。数据被持久化后,即使整个Kubernetes崩<br>溃也不会受损。
(1)当前Volume来自AWS EBS。<br>(2)EBS Volume已经提前创建,并且知道确切的volume-id
Pod通常是由应用的开发人员维护,而Volume则通常是由存储系<br>统的管理员维护。开发人员要获得上面的信息,要么询问管理员,要<br>么自己就是管理员
GlusterFS
GCE
AWS Elastic Block Store
PersistentVolume
类型
AWS EBS
Ceph
NFS
使用方法
在k8s master节点搭建nfs服务器
创建PersistentVolume yaml文件
① capacity指定PV的容量为1GB。<br>② accessModes指定访问模式为ReadWriteOnce,支持的访问模式<br>有3种:ReadWriteOnce表示PV能以read-write模式mount到单个节点,<br>ReadOnlyMany表示PV能以read-only模式mount到多个节点,<br>ReadWriteMany表示PV能以read-write模式mount到多个节点。<br>③ persistentVolumeReclaimPolicy指定当PV的回收策略为<br>Recycle,支持的策略有3种:Retain表示需要管理员手工回收;<br>Recycle表示清除PV中的数据,效果相当于执行rm -rf/thevolume/*;<br>Delete表示删除Storage Provider上的对应存储资源,例如AWS EBS、<br>GCE PD、Azure Disk、OpenStack Cinder Volume等。<br>④ storageClassName指定PV的class为nfs。相当于为PV设置了一<br>个分类,PVC可以指定class申请相应class的PV。<br>⑤ 指定PV在NFS服务器上对应的目录。
创建PersistentVolumeClaim yaml <br>指定PersistentVolume
指定PV的容量、访问模式和class即<br>可。
创建pod 指定PersistentVolumeClaim
指定PVC 使用
不支持Delete 回收策略
概念
简称(PV)外部存储系统中的一块存储空间,由<br>管理员创建和维护
特点
与Volume一样,PV具有持久性,生命周期独立<br>于Pod。
回收策略
Retain
表示需要管理员手工回收
Recycle
表示清除PV中的数据,效果相当于执行rm -rf/thevolume/*
Delete
表示删除Storage Provider上的对应存储资源
PersistentVolumeClaim
概念
简称(PVC)是对PV的申请PVC<br>通常由普通用户创建和维护需要为Pod分配存储资源时,<br>用户可以<br>创建一个PVC,指明存储资源的容量大小和访问模式(比如只读)等<br>信息,<br>Kubernetes会查找并提供满足条件的PV
特点
用户只需要告诉Kubernetes需要什<br>么样的存储资源,而不必关心真正的空间从哪里分配、如何访问等底<br>层细节信息。这些Storage Provider的底层信息交给管理员来处理,只<br>有管理员才应该关心创建PersistentVolume的细节信息。
删除persistentVolumeClaim
命令kubectl delete pvc pvcname
Kubernetes启动了一个新Pod<br>Pod的名称为recycler-for-pvcname
此时与该pvc 绑定的pv 状态变成released表示已经解除了与pvc的绑定,<br>正在清除数据,清楚完成后状态重新变为Available,可以重新申请pvc绑定到pv上
动态供给
概念
如果没有满<br>足PVC条件的PV,会动态创建PV
特点
动态供给有明显<br>的优势:不需要提前创建PV,减少了管理员的工作量,效率高
遇到的问题
在数据卷阶段删除pvc 后pv的状态变成released 无法自动恢复到aviable 状态。<br>如果pv的回收策略是recycle 则会启动一个新的pod 这个pod需要到google下载<br>镜像,需要通过命令 kubectl describe pod podname 查看下载的image 名称<br>到hub.docker.com 找到相关镜像重新打包成 gcr/io 开头的镜像
在集成nfs 网络文件的时候,在pv声明文件中配置映射到nfs 公共目录的地方需要注意目录的权限问题
Secret
概念
Secret会以密文的方式存储数据,避免了直接在配置文件中保存<br>敏感信息Secret会以Volume的形式被mount到Pod,容器可通过文件<br>的方式使用Secret中的敏感数据;此外,容器也可以环境变量的方式<br>使用这些数据
创建方式
kubectl create secret generic mysecret --from-literal=username=admin
echo -n admin > ./username<br>echo -n 123456 > ./password<br>kubectl create secret generic mysecret --from-file=./username
cat << EOF > env.txt<br>username=admin<br>password=123456<br>EOF<br>kubectl create secret generic mysecret --from-env-file=env.txt
kubectl apply -f mysecret.yaml
数据编码
echo -n admin | base64
数据解码
echo -n MTIzNDU2 | base64 --decode
查看value
kubectl edit secret mysecret
查看条目key
kubectl describe secret mysecret
在Pod中使用Secret
volume 方式
环境变量形式
环境变量读取Secret很方便,但无法支撑Secret动<br>态更新
ConfigMap
概念
ConfigMap的创建和使用方式与Secret非常类似,主要的不同是<br>数据以明文的形式存放
创建方式
kubectl create configmap myconfigmap --from-literal=config1
echo -n xxx > ./config1<br>echo -n yyy > ./config2<br>kubectl create configmap myconfigmap --from-file=./config1
cat << EOF > env.txt<br>config1=xxx<br>config2=yyy<br>EOF<br>kubectl create configmap myconfigmap --from-env-file=env.txt
kubectl apply -f myconfig.yaml
Helm
概念
Kubernetes的包管理器从零创建新chart。<br>与存储chart的仓库交互,拉取、保存和更新chart。<br>在Kubernetes集群中安装和卸载release。<br>更新、回滚和测试release。
chart
chart是创建一个应用的信息集合,包括各种Kubernetes对象的<br>配置模板、参数定义、依赖关系、文档说明等。chart是应用部<br>署的自包含逻辑单元。可以将chart想象成apt、yum中的软件安<br>装包。
release
release是chart的运行实例,代表了一个正在运行的应用。当<br>chart被安装到Kubernetes集群,就生成一个release。chart能<br>够多次安装到同一个集群,每次安装都是一个release。
未使用前有哪些问题
(1)传统服务区很难管理、编辑和维护如此多的服务。每个服务都有若干<br>配置,缺乏一个更高层次的工具将这些配置组织起来。<br>(2)不容易将这些服务作为一个整体统一发布。部署人员需要<br>首先理解应用都包含哪些服务,然后按照逻辑顺序依次执行kubectl<br>apply,即缺少一种工具来定义应用与服务,以及服务与服务之间的<br>依赖关系。<br>(3)不能高效地共享和重用服务。比如两个应用都要用到<br>MySQL服务,但配置的参数不一样,这两个应用只能分别复制一套<br>标准的MySQL配置文件,修改后通过kubectl apply部署。也就是说,<br>不支持参数化配置和多环境部署。<br>(4)不支持应用级别的版本管理。虽然可以通过kubectl rollout<br>undo进行回滚,但这只能针对单个Deployment,不支持整个应用的回<br>滚。<br>(5)不支持对部署的应用状态进行验证。比如是否能通过预定<br>义的账号访问MySQL。虽然Kubernetes有健康检查,但那是针对单个<br>容器,我们需要应用(服务)级别的健康检查。
组件
Helm客户端
在本地开发chart。<br>管理chart仓库。<br>与Tiller服务器交互。<br>在远程Kubernetes集群上安装chart。<br>查看release信息。<br>升级或卸载已有的release。
管理chart
Tiller服务器
监听来自Helm客户端的请求。<br>通过chart构建release。<br>在Kubernetes中安装chart,并跟踪release的状态。<br>通过API Server升级或卸载已有的release
管理<br>release
会启动 deployment service pod 想逛组件
命令
helm search #会显示chart位于哪个仓库
helm repo add#添加更多的仓库
helm install stable/mysql #安装远程mysql
① chart本次部署的描述信息。<br>NAME是release的名字,因为我们没用-n参数指定,所以Helm随<br>机生成了一个,这里是fun-zorse。<br>NAMESPACE是release部署的namespace,默认是default,也可以<br>通过--namespace指定。<br>STATUS为DEPLOYED,表示已经将chart部署到集群。<br>② 当前release包含的资源:Service、Deployment、Secret和<br>PersistentVolumeClaim,其名字都是fun-zorse-mysql,命名的格式为<br>ReleasName-ChartName。<br>③ NOTES部分显示的是release的使用方法,比如如何访问<br>Service、如何获取数据库密码以及如何连接数据库等。
如何查看安装过后的chart 文件
安装过后 会在以下目录生成归档文件<br>~/.helm/cache/archive中找到chart的tar包
解压归档文件
Chart.yaml
描述chart的概要信息
values.yaml
chart支持在安装时根据参数进行定制化配置,而values.yaml则提<br>供了这些配置参数的默认值
templates目录
各类Kubernetes资源的配置模板都放置在这里<br>Helm会将<br>values.yaml中的参数值注入模板中,生成标准的YAML配置文件<br>
特点
模板增加<br>了应用部署的灵活性,能够适用不同的环境
helm list#显示已经部署的release
helm delete#可以删除release
helm inspect values image #查看自定image的配置信息
helm install--values=myvalues.yaml image #将设置好的文件安装到 image 中
helm install {IMAGEG} -set args="" -n {CUSTOMER_DIFINE_IMAGE_NAME} #通过set 方式设置参数 安装到image 中
helm list #列表
helm status {IMAGE}# 查看最新状态
helm history#可以查看release所有的版本
helm rollback#可以<br>回滚到任何版本
helm upgrade#对其进行升级,通过--values<br>或--set应用新的配置
helm create mychart #创建chart
helm install --dry-run --debug#会模拟安装chart
安装方式chart
(1)安装仓库中的chart,例如helm install stable/nginx。<br>(2)通过tar包安装,例如helm install ./nginx-1.2.3.tgz。<br>(3)通过chart本地目录安装,例如helm install ./nginx。<br>(4)通过URL安装,例如helm install<br>https://example.com/charts/nginx-1.2.3.tgz。
仓库
local #本地
stable#远程
k8s 网络
Pod内容器之间的通信
特点
每个Pod都有自己的IP<br>地址
不同Pod之间不存在端口冲突的问题
概念
当Pod被调度到某个节点,Pod中的所有容器都在这个节点上运<br>行,这些容器共享相同的本地文件系统、IPC和网络命名空间
概念
个Pod都有自己的IP地址,同一个Pod中的容器共享Pod的IP,能够通过localhost通信
Pod之间的通信
概念
Pod的IP是集群可见的,即集群中的任何其他Pod和节点都可以通<br>过IP直接与Pod通信,这种通信不需要借助任何网络地址转换、隧道<br>或代理技术。Pod内部和外部使用的是同一个IP,这也意味着标准的<br>命名服务和发现机制,比如DNS可以直接使用
特点
Pod间可以直接通过IP地址通信,但前提是Pod知道对方的IP
Pod与Service的通信
概念
Service提供了访问Pod的抽象层。<br>无论后端的Pod如何变化,Service都作为稳定的前端对外提供服务。<br>同时,Service还提供了高可用和负载均衡功能,Service负责将请求转<br>发给正确的Pod。
外部访问
概念
Pod的IP还是Service的Cluster IP,它们只能在Kubernetes集<br>群中可见,对集群之外的世界,这些IP都是私有的
NodePort
Service通过Cluster节点的静态端口对外提供服务。<br>外部可以通过<nodeip>:<nodeport>访问Service。</nodeport></nodeip>
LoadBalancer
Service利用cloud provider提供的load<br>balancer对外提供服务,cloud provider负责将load balancer<br>的流量导向Service。目前支持的cloud provider有GCP、AWS、<br>Azur等。
网络方案
概念
Kubernetes采用<br>了Container Networking Interface(CNI)规范<br>CNI是由CoreOS提出的容器网络规范,<br>使用了插件(Plugin)模<br>型创建容器的网络栈,<br>
CNI网络栈
类型
Flannel
Calico
Network Policy
概念
Network Policy是Kubernetes的一种资源<br>不是所有的Kubernetes网络方案都支持Network Policy。<br>比<br>如Flannel就不支持,Calico是支持的<br>
特点
Network Policy通过<br>Label选择Pod,并指定其他Pod或外界如何与这些Pod通信。
Network Policy并指定其他Pod或外界如何与这些Pod通信
当为Pod定义了Network Policy时,只有<br>Policy允许的流量才能访问Pod
Canal
概念
它用Flannel实现<br>Kubernetes集群网络,同时又用Calico实现Network Policy
特点
DaemonSet
属于 kube-system这个<br>namespace
Weave
Net
概念
用户无<br>论选择哪种方案,得到的网络模型都一样,即每个Pod都有独立的<br>IP,可以直接通信。区别在于不同方案的底层实现不同,有的采用基<br>于VxLAN的Overlay实现,有的则是Underlay,性能上有区别。再有<br>就是是否支持Network Policy。
容器网络模型
docker
Container Network Model(CNM)
有哪些使用的项目
Cisco Contiv、Kuryr、Open Virtual,<br>Networking(OVN)、Project Calico、<br> VMware、Weave和Plumgrid
组件
Network Sandbox
容器内部的网络栈,包括网络接口、路由表、DNS等配置的管理。<br>Sandbox可用Linux网络命名空间、<br>FreeBSD Jail等机制进行实现。一个Sandbox可以包含多个Endpoint
Endpoint
用于将容器内的Sandbox与外部网络相连的网络接口。<br>可以使用veth对、Open vSwitch的内部port等技术进行实现。<br>一个Endpoint仅能够加入一个Network。
Network
可以直接互连的Endpoint的集合。<br>可以通过Linux网桥、<br>VLAN等技术进行实现。<br>一个Network包含多个Endpoint。
coreos
Container Network Interface(CNI)
有哪些使用的项目
Kubernetes、rkt、Apache Mesos、Cloud Foundry和Kurma等项目采纳。<br>另外,Contiv Networking, Project Calico、Weave、SR-IOV、Cilium、Infoblox、<br>Multus、Romana、Plumgrid和Midokura等项目也为CNI提供网络插件的具体实现<br>
概念
容器
概念
是拥有独立Linux网络命名空间的环境,<br>例如使用Docker或rkt创建的容器。<br>关键之处是容器需要拥有自己的Linux网络命名空间,<br>这是加入网络的必要条件
网络
概念
表示可以互连的一组实体,这些实体拥有各自独立、<br>唯一的IP地址,可以是容器、<br>物理机或者其他网络设备(比如路由器)等。
类型
CNI Plugin
概念
CNI Plugin负责为容器配置网络资源
IPAM
概念
IPAM Plugin负责对容器的IP地址进行分配和管理
实现
host-local
dhcp
包含内容
ips段
分配给容器的IP地址(也可能包括网关)
routes段
路由规则记录
dns段
DNS相关的信息
实践
Master
规格选择
集群规模有关,集群规模越大,所需要的Master规格也越大
集群规模
如何衡量
节点数量/Pod数量/部署频率/访问量
规格建议
1-5个节点,Master规格:4C8G(不建议2C4G)<br>6-20个节点,Master规格:4C16G<br>21-100个节点,Master规格:8C32G<br>100-200个节点,Master规格:16C64G
磁盘大小
保存的内容
docker镜像、系统日志、应用日志
考虑点
每个节点上要部署的Pod数量,每个Pod的日志大小、镜像大小、临时数据,再加上一些系统预留的值
pod 限制
静态资源调度
节点剩余资源=节点总资源-已经分配出去的资源
所有Pod上都要声明resources。对于没有声明resources的Pod,它被调度到某个节点后,Kubernetes也不会在对应节点上扣掉这个Pod使用的资源
示例
应用场景
就是一个节点上调度了太多的Pod,导致节点负载太高,完全没法对外提供服务。怎么避免这种情况出现呢
配置监控 <br>
监控点
Master和Worker 节点
配置Liveness Probe和Readiness Probe <br>
为什么需要配置Liveness Probe?
Pod处于Running状态和Pod能正常提供服务是完全不同的概念,一个Running状态的Pod,里面的进程可能发生了死锁而无法提供服务。但是因为Pod还是Running的,Kubernetes也不会自动重启这个Pod。所以我们要在所有Pod上配置Liveness Probe,探测Pod是否真的存活,是否还能提供服务。如果Liveness Probe发现了问题,Kubernetes会重启Pod
为什么需要配置Readiness Probe?
Readiness Probe用于探测Pod是不是可以对外提供服务了。应用启动过程中需要一些时间完成初始化,在这个过程中是没法对外提供服务的,通过Readiness Probe,我们可以告诉Ingress或者Service能不能把流量转发给这个Pod上。当Pod出现问题的时候,Readiness Probe能避免新流量继续转发给这个Pod。
配置restart policy <br>
Always: 总是自动重启<br><br>OnFailure:异常退出才自动重启 (进程退出状态非0)<br><br>Never:永远不重启
应用场景
Pod运行过程中进程退出是个很常见的问题,无论是代码里的一个bug,还是占用内存太多被OOM killer干掉,都会导致应用进程退出,Pod挂掉。Pod退出了怎么办
启动时等待下游服务,不要直接退出 <br>
应用场景
第一种场景:等待其它模块Ready,比如我们有一个应用里面有两个容器化的服务,一个是Web Server,另一个是数据库。其中Web Server需要访问数据库。但是当我们启动这个应用的时候,并不能保证数据库服务先启动起来,所以可能出现在一段时间内Web Server有数据库连接错误。为了解决这个问题,我们可以在运行Web Server服务的Pod里使用一个InitContainer,去检查数据库是否准备好,直到数据库可以连接,Init Container才结束退出,然后Web Server容器被启动,发起正式的数据库连接请求。<br> 第二种场景:初始化配置,比如集群里检测所有已经存在的成员节点,为主容器准备好集群的配置信息,这样主容器起来后就能用这个配置信息加入集群。 其它使用场景:如将pod注册到一个中央数据库、下载应用依赖等。<br>
进程与POD
特点
每个进程一个容器或一个pod 多个进程
尽量避免直接使用Pod,尽可能使用Deployment/StatefulSet,并且让应用的scale在两个以上
如果多个进程放到一个POD 有什么问题?
1.判断Pod整体的资源占用会变复杂,不方便实施前面提到resource limit<br>2.容器内只有一个进程的情况,进程挂了,外面的容器引擎可以清楚的感知到,然后重启容器,如果容器内有多个进程,某个进程挂了,容器未必受影响,外部的容器引擎感知不到容器内进程挂了,也不会对容器做任何操作,但是容器实际上已经不能正常工作了
如果直接使用Pod ,不实用Deployment/StatefulSet的话有什么问题?
如果应用只有一个实例,当实例挂掉的时候,虽然Kubernetes能够将实例重新拉起,但是中间不可避免的存在一段时间的不可用。甚至更新应用,发布一个新版本的时候,也会出现这种情况
磁盘的选择 <br>
SSD
对于Worker节点,尽量选择“挂在数据盘”。因为这个盘是专门提供给/var/lib/docker,使用来存放本地镜像的。避免后续如果镜像太多撑爆根磁盘。在运行一段时间后,本地会存在很多无用的镜像。比较快捷的方式就是,先下线这台机器,重新构建这个磁盘,然后再上线。
日常运维设置 <br>
对于ECS的监控,日常运维一定设置CPU, Memory,磁盘的告警。再次说明一下,尽量将/var/lib/docker放在独立一个盘上<br><br>一定配置日志收集
网络选择 <br>
如果需要连接外部的一有服务,如 rds等,则需要考虑复用原有的VPC,而不是取创建一个新的VPC。因为VPC间是隔离的。但是可以通过创建一个新的交换机,把k8s的机器都放在这个交换机,便于管理。<br><br>网络插件的选择:目前支持两种插件,一种是flannel,直通VPC,性能最高。一种是Terway,提供k8s的网络策略管理。<br><br>POD CIDR,整个集群的POD的网络。这个不能设置太小。因为设置太小,能支持的节点数量就受限了。这个与高级选项中“每个节点POD的数量有关”。例如POD CIDR是/16的网段,那么就有256*256个地址,如果每个几点POD数量是128,则最多可以支持512个节点
如何选择Worker的规格?
确定整个集群的日常使用的总核数以及可用度的容忍度。例如总的核数有160核,同时容忍10%的错误。那么最小选择10台ECS为16核的机器,并且高峰运行的负荷不要超过16090%=144核。如果容忍度是20%,那么最小选择5台32核的机器,并且高峰运行的负荷不要超过16080%=128核。这样确保,就算有一台机器整体crash都可以支持得住业务运行。<br><br>但是上面这个计算只是理论值,因为规格小的机器,很可能剩余不可利用的资源的比例就高。所以不是越小的机器越好。<br><br>选择好CPU:Memory的比例。对于使用内存比较多的应用例如java类应用,建议考虑使用1:8的机型。
POD
定义
关于 Pod 最重要的一个事实是:它只是一个逻辑概念<br>其实是一组共享了某些资源的容器,Pod 里的所有容器,<br>共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume<br>Pod,实际上是在扮演传统基础设施里“虚拟机”的角色;<br>而容器,则是这个虚拟机里运行的用户程序<br>
默认容器Infra
Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,<br>则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起
镜像
k8s.gcr.io/pause
特点
汇编语言编写,解压后的大小也只有 100~200 KB 左右
属性
NodeSelector:是一个供用户将 Pod 与 Node 进行绑定的字段
NodeName:一旦 Pod 的这个字段被赋值,Kubernetes 项目就会被认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字
HostAliases:定义了 Pod 的 hosts 文件(比如 /etc/hosts)里的内容
shareProcessNamespace=true意味着这个 Pod 里的容器要共享 PID Namespace
hostNetwork: true
hostIPC: true
hostPID: true
Init Containers
Containers
ImagePullPolicy它定义了镜像拉取的策略
Always
Never
IfNotPresent
Lifecycle
是在容器状态发生变化时触发一系列“钩子
postStart
在容器启动后,立刻执行一个指定的操作
preStop
则是容器被杀死之前同步的
Metadata
Spec
Status
Pending这个状态意味着,Pod 的 YAML 文件已经提交给了 Kubernetes,API 对象已经被创建并保存在 Etcd 当中。但是,这个 Pod 里有些容器因为某种原因而不能被顺利创建
Running这个状态下,Pod 已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中
Succeeded这个状态意味着,Pod 里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见
Failed这个状态下,Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。
Unknown这是一个异常状态,意味着 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题
子主题
子主题
思考题
Kubernetes 使用的这个“控制器模式”,跟我们平常所说的“事件驱动”,有什么区别和联系吗?
事件往往是一次性的,如果操作失败比较难处理,但是控制器是循环一直在尝试的,更符合kubernetes申明式API,最终达到与申明一致
对于我们这个 nginx-deployment 来说,它创建出来的 Pod 的 ownerReference 就是 nginx-deployment 吗?或者说,nginx-deployment 所直接控制的,就是 Pod 对象么?
deployment会创建rs,然后由rs创建pod,所以pod的owner应该是rs? <br>
自由主题

收藏
立即使用

Collect
Get Started

Collect
Get Started

Collect
Get Started
Collect
Get Started
评论
0 条评论
下一页

