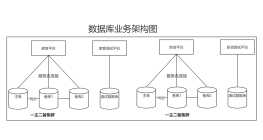
数据库架构
如何设计一个关系型数据库
程序:<br>存储管理、缓存机制、SQL解析、日志管理、权限管理、容灾机制、索引管理、锁管理<br>文件系统-存储的硬件
<ol><li>**为什么要使用索引?</li></ol>避免全表扫描,提升检索效率<br><ol><li>**什么样的信息能成为索引?</li></ol>主键、唯一键和普通键<br><ol><li>**索引的数据结构?</li></ol>二叉查找树建立二分查找<br>B-树、B+树、Hash结构<br><ol><li>**密集索引和稀疏索引和区别?</li></ol>密集索引每个搜索码都对应一个索引项<br>稀疏索引只为部分搜索码建立索引项
关系型数据库
存储形式为行、列的表类型,Oracle、DB2、Microsoft SQL Server、MySQL
非关系型数据库
key-value形式:Hbase、Redis、MongoDB
InnoDB
若存在主键,该主键为密集索引<br>若不存在,该表第一个唯一非空索引则为密集索引<br>若不满足,该表则会存在一个隐藏的密集索引
索引模块衍生问题
优化慢查询SQL:<br>1、根据慢日志定位慢SQL<br>2、使用explain分析SQL<br>3、修改SQL或者尽量走索引
查询慢日志:<br>show variables like '%quer%'; <br>show status like '%slow_queries%'; # 查询慢请求状态<br>set global slow_query_log = on; # 打开慢查询日志<br>set global long_query_time = 1; # 设置超时时间
explain + 查询SQL;
关键字:type:<br>如果为index 和all 表示为全表扫描
关键字:extra:<br>如果为using filesort 和 using temporary 表示无法使用索引
加索引:<br>alter table 表名 add index idx_name(列名);
索引的最左匹配原则成因:<br>最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。<br>
索引是建立的越多越好吗?<br>数据量小的表不需要建立索引,增加索引会产生额外的开销<br>数据变更需要维护索引,更多的索引需要占用更多的资源<br>更多索引需要更多的空间
数据库事务
四大特性:ACID<br>原子性<br>一致性<br>隔离性<br>持久性
查询隔离级别:select @@tx_isolation;<br>更改事务隔离级别:set session transaction
问题:脏读、不可重复读、幻读<br>隔离级别:未提交读、已提交读、可重复度、串行化。<br>1、事务的特性:原子性、一致性、隔离性、持久性<br>2、多事务同时执行的时候,可能会出现的问题:脏读、不可重复读、幻读<br>3、事务隔离级别:未提交读、已提交读、可重复读、串行化<br>4、不同事务隔离级别的区别:<br>未提交读:一个事务还未提交,它所做的变更就可以被别的事务看到<br>已提交读:一个事务提交之后,它所做的变更才可以被别的事务看到---oracle数据库<br>可重复读:一个事务执行过程中看到的数据是一致的。未提交的更改对其他事务是不可见的---MySQL<br>串行化:对应一个记录会加读写锁,出现冲突的时候,后访问的事务必须等前一个事务执行完成才能继续执行
事务隔离级别越高,串行化越严重,这样就降低了事务的并发度,
having group by sum(case when sign_in = 1 then 1 else 0 end)as chuqinNum,
SQL语句优化
<ol><li>查询语句无论是使用哪种判断条件 等于、小于、大于, WHERE 左侧的条件查询字段不要使用函数或者表达式</li><li>使用 EXPLAIN 命令优化你的 SELECT 查询,对于复杂、效率低的 sql 语句,我们通常是使用 explain sql 来分析这条 sql 语句,这样方便我们分析,进行优化。</li><li>当你的 SELECT 查询语句只需要使用一条记录时,要使用 LIMIT 1</li><li>不要直接使用 SELECT *,而应该使用具体需要查询的表字段,因为使用 EXPLAIN 进行分析时,SELECT * 使用的是全表扫描,也就是 type = all。</li><li>为每一张表设置一个 ID 属性</li><li>避免在 WHERE 字句中对字段进行 NULL 判断</li><li>避免在 WHERE 中使用 != 或 <> 操作符</li><li>使用 BETWEEN AND 替代 IN</li><li>为搜索字段创建索引</li><li>选择正确的存储引擎,InnoDB 、MyISAM 、MEMORY 等</li><li><span style="font-size: inherit;">使用 LIKE %abc% 不会走索引,而使用 LIKE abc% 会走索引</span></li><li>对于枚举类型的字段(即有固定罗列值的字段),建议使用ENUM而不是VARCHAR,如性别、星期、类型、类别等</li><li>拆分大的 DELETE 或 INSERT 语句</li><li>选择合适的字段类型,选择标准是 尽可能小、尽可能定长、尽可能使用整数。</li><li>字段设计尽可能使用 NOT NULL</li></ol>