
java
2022-09-14 17:28:20 0 举报仅支持查看
AI智能生成
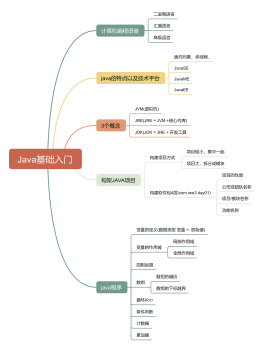
java基础
java语言的组成部分
模板推荐
作者其他创作
大纲/内容
java基本信息
历史
95年推出,09年被甲骨文收购
特定
健壮性
分布式
跨平台
面向对象
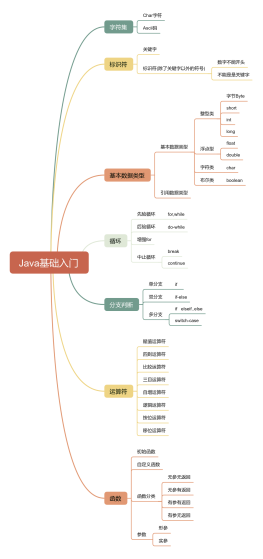
数据类型
基本数据类型
整数
byte
1位8字节 -128~127 0~255
short
2位16字节 -32768~32767 0~65535
int
4位32字节 ±21个亿
long
float <br>
32位 1位符号位 8位指数位 23位尾数位
8位64字节 -2^63~(2^63)-1
浮点<br>
double
8位64字节
char
16位无符号整数(本质上是不分正负的整数)
boolean
0 1<br>
数字类型的大小:byte<short<int<long<float<double<br>
二进制转换: 拆分成几个2的N次幂相加 负数正数的二进制数取反再+1<br>
引用数据类型
字符串 String
StringBuilder
可变 不同步
StringBuffer
可变 <font color="#f15a23">同步</font>
String
String的值是常量不能变,改变的只有指向
特性
不变性:<b><font color="#f15a23"><br></font></b>
类名被final修饰,表示不可被继承,避免子类破坏不可变性
底层存储的char变量也是用final修饰且私有而且没有暴露修改方法
极致的优化:String的性能极差,所以提出了<b>常量池</b>的概念。当使用赋值符=创建字符串的时候,会在常量池中创建一个字符串,如果以后再有相同的字符串赋值的话就直接指向常量池;如果是使用new 创建String的时候,先看常量池中是否有这个字符串,如果没有就在常量池中创建一个,最后再去堆内存中创建一个字符串的空间并赋值引用
注意:
<b><font color="#f15a23">String 使用“=”直接赋值的话,会在常量池中创建这个“值”</font></b>
类 Class
类(Class)
描述某个事物的标准
构造函数:方法名和类名一样的方法(没有返回值)new一个对象的时候就会被触发
对象
把虚拟的类变成实体
面向对象的特征
封装
private
把不必要的属性和方法隐藏起来<br>
继承
extends
一个类可以使用另一个类公开的方法和属性<br>
多态
父类 引用 = new 子类()<font color="#f15a23">一个类的引用或者动作在不同的条件下会有不同的表现形态</font>
抽象 abscract
抽象方法
抽象的意思是从某个事物的某一个角度去描述
public abscract 方法()
不含方法体
抽象类
1.概念:当类不足以准确的描述一个对象,那么这个类就是抽象类
2.写法:权限修饰符 abscract class 类名 {}
3.特点
如果这个类中含有<b><font color="#f15a23">一个或以上的抽象方法</font></b>,那么这个类一定是抽象类
抽象类,可以定义普通方法,也<font color="#f15a23">可以</font>不包含抽象方法
抽象类 不能有构造函数,所以也不能new一个对象出来,如果想用抽象类里面的普通方法和变量的话就需要 <b><font color="#f15a23">向上转型</font></b>
重载和重写
重载:同一个类中,多个方法名相同,参数的类型、数量、顺序不同 叫方法的重载
重写:存在继承关系的父子类中,子类重新改写父类的方法,叫重写
接口 interface
只能定义抽象函数,1.8以后可以定义default方法(这个特性出来了极大的减少了接口和类之间的区别)
只能定义全局静态常量
特点:支持多继承
接口<font color="#c41230">不是类</font>,像是一个抽象方法的集合
枚举 enum
把一堆常量放在一个枚举类里面,这个枚举类会限制它的引用变量的值,<b><u><font color="#f15a23">存在类内容检查机制</font></u></b>
Array
定义数组:
类型[] 引用名 = new 类型[长度]
类型[] 引用名 = new 类型[]{具体的元素}
类型[] 引用名 = {具体的元素}
意义:<br>
当出现大量相同数据类型的数据时,不需要开辟那么多个变量区域,因此出现了数组
数组的复制
复制
System.arraycopy(原数组,从哪一位复制,新数组,复制多长)<br>
Arrays.copyOf(原数组,复制的长度) 有上面的方法实现的<br>
扩容<br>
创建一个新的数组,长度是想要用的长度,然后把原数组复制过去,再把新数组复制给原数组<br>
冒泡排序
for(i=0;i<numbers.length-1;i++){<br> for(j=0;j<numbers.length-1-i;j++){<br> if(numbers[j]>numbers[j+1]){<br> int temp=numbers[j];<br> numbers[j]=numbers[j+1];<br> numbers[j+1]=temp;<br> }<br> }<br> }
精确小数类(BigDecimal):用来解决小数计算的经度丢失问题
运算及流程控制
运算:
数学运算符:+ - * / % ++ --
i++ 先引用 i 的值进行代码运算,<b><u>再去改变 i 的值</u></b>
++i 先把i+1 再去代入代码
逻辑运算符:& && | || !<br>
关系运算符:> < >= <= != ==<br>
三目: 条件?真值:假值<br>
位运算:>> << 有符号位移 >>>无符号右移<br>
循环
while
do-while
for
foreach
条件控制
if-else if-else
switch-case
byte short char int 1.8以后可以添string<br>
修饰符
public
全友好,可以修饰类
protected
本类友好,父子继承友好
缺省
同包友好,可以修饰类
private
本类友好
关键字
abstract
修饰方法:类必须也是抽象类,继承的子类必须重写被修饰的方法
修饰类:是抽象类不能实例化,可以定义任意类型的变量和方法,不一定有抽象方法
调用抽象类的方法或者变量:需要用子类进行向上转型
final
修饰类:不能被继承
修饰方法:不能被重写,但是可以继承
修饰变量:值不能变,必须有初始值,常量
不能修饰构造方法
static
修饰方法:静态方法,可以直接用类名.方法名()调用
修饰变量:全局变量,所有的实例对象公用一个,一个对象修改了他的值,其他的对象也会受影响
静态代码块:优先于一切方法块(包括main)执行内部内容
特点:非静态方法能调用静态,静态方法不能调用非静态的方法及变量
lang包
lang包里面的类不需要引入直接就可以用
包装类
为了保证Java的特性,万事万物皆对象,可以通过方法把基本数据类型转化成引用类型
自动拆装箱:JDK1.5之后可以自动的把基本类转成应用类
常量池
范围:-128~127
存在常量池中的数据可以拿来直接用,不会在内存中再次创建
参数的传递
固定参数
String
<font color="#f15a23"><b>String传递的时候,其实传的是引用名在堆中地址,因为Sting具有不可变性,当方法内对该地址的字符串重新赋值,则相当于在内存中重新创建一对象,对实参不产生影响</b></font>
引用数据类型
<font color="#f15a23"><b>引用数据类型(数组、类)作为参数的时候传递过去的是引用/内存地址传递</b></font>
基本数据类型
<font color="#f15a23"><b>传递的是基本数据类型,在传递的是值的一个副本,在方法内对形参操作,不影响实参的值。值</b></font>
可变参数
写法:类型 ...形参名
在需要传的参数不确定的情况下使用
注意
1. 每个方法<font color="#f15a23"><b>只能有一个</b></font>可变参数
2. 可变参数只是<b><font color="#f15a23">最后一个</font></b>形参
3. 可变参数在方法中当做<font color="#f15a23"><b>数组</b></font>使用
Math类
floor 向下取整
ceil 向上取整
round 四舍五入
random 随机数[0,1)
File类
构造函数
File file = new File("文件路径");
File file = new File("文件目录(父路径)","文件名(子路径)");<br>
File father = new File("父路径"); File file = new File(father,"子文件路径");
Random类
Random() 产生一个随机数
new Random().next(最大值);
Object类
<font color="#f15a23">所有类的父类/超类</font>
常用方法
toString
toString 是打印类的地址、类名等类的信息,如果想要输出需要的格式,请<font color="#f15a23" style="font-weight: bold;">类中重写</font><font color="#000000" style="">toString方法,return出需要的数据格式</font>
equals
底层是使用<b><font color="#f15a23"> == 实现</font></b>的所以比较的内存地址,有些类重写了这个方法,比如String 比较的是值
hashCode
hashCode是<font color="#f15a23" style="font-weight: bold;">Java.lang.Object.hashCode()或者Java.lang.System.identityHashCode()</font><font color="#381e11" style="">的返回值</font>,都能获取一个对象的标识,官方称呼: 标识哈希码;
克隆
创建一个对象的副本
用处:<b><font color="#c41230">当你的对象要求为不可变的时候,在传对象的时候,可以考虑clone。例如方法的参数传递,传递对象的时候是引用传递,如果不希望改变原始对象的数据,则就可以使用克隆。</font></b>
浅克隆
条件:<b><font color="#c41230"> 类实现Cloneable接口,且重写了clone方法。</font></b>详细的写法去看笔记
缺点:不能复制类中所存储的其他类
深克隆
条件:<b><font color="#c41230">关联类1储关联对象2,关联类2实现了浅克隆,关联类1中实现了Cloneable并重写了clone方法</font></b>
Java的工具包
Date类
时间类,操作时间的,<b><font color="#f15a23">从JDK1.0以后就建议使用Calender</font></b>
Calender类
<font color="#f15a23">推荐使用的日期时间类</font>
它是一个<b><font color="#f15a23">抽象类</font></b>
使用Calendar.getInstance()创建对象
get(Calendar关键字)获取,set(Calendar关键字,值)设置时间对象
simpleDateFormat(辅助)
设计如日期输出的格式
常用的格式:<b><font color="#f15a23">yyyy-MM-dd HH:mm:ss</font></b>
异常类
Throwable 异常的父类
Exception 异常
可以被解决成不影响代码运行的模式
try-catch-finally
try :尝试运行一部分代码,如果有异常就会运行catch里面弹出
catch:try内部出现宜昌的时候会执行catch块
finally:
<b><font color="#f15a23">无论什么时候</font></b>在try执行之后执行
特殊情况:try里面直接 System.exit(0)
Throws
throws 用在方法声明处<b><font color="#f15a23">方法声明处</font></b>方法声明处,声明该方法可能发生的异常类型
当调用的类中使用 throw 抛错的话 调用的类就要用Throws处理 , 或者使用try-catch
Throw
当程序员觉得什么条件下会出错就是用 throw 抛出来个异常类
自定义异常
请看笔记
Error 错误
错误不能解自动解决,需要改代码处理
Iterator
Collections
List
ArrayList
<b style="color: rgb(241, 90, 35);">可变数组,</b><font color="#381e11">允许存入任何类型的数据,null也行,可以使用</font><font color="#f15a23" style="font-weight: bold;">泛型<></font><font color="#381e11">来限制元素的类型,存入的是引用类型,如果是</font><b style=""><font color="#f15a23">基本类型会对数据自动装箱</font></b>
<b style="color: rgb(241, 90, 35);">查询效率高(因为是数组)</b><font color="#381e11">,增删效率低</font>
常用方法
add
添加
get
获取
remove
移除
clear
清空
contains
是否集合中是否有这个类型的元素
size
长度
toArray
变成数组
LinkedList
<b><font color="#f15a23">双向循环链类型,</font></b>允许存入任何类型的数据,null也行,可以使用泛型<>来限制元素的类型,存入的是引用类型,如果是基本类型会对数据自动装箱
<b style="color: rgb(241, 90, 35);">增删效率高</b><font color="#381e11">,查询效率低</font>
常用方法
add
addFirst
addLast
get
getFrist
getLast
remove
removeLast
removeFirst
模拟堆栈
peek
peekFirst
peekLast
poll
pollFirst
pollLast
pop
push
Vector
和ArrayList 类似 只不过 <b><font color="#f15a23">支持同步/线程安全</font></b>
set
HashSet
使用哈希类型排序的可变数组
可以使用foreach 和 Iterator迭代输出
<font color="#f15a23">使用hashcode方法保证内容不重复</font>
ThreeSet
无序不重复的红黑树型集合
特点 无序且不重复
结构 红黑树(二叉树)
<b><font color="#f15a23">使用compareTo方法保证值不重复</font></b>
map
HashMap
按照Hash表排列的键值对,<font color="#f15a23" style=""><b>键和值都不能重复</b>,可以是null</font>
<font color="#f15a23">比较方法:先比较hashCode,如果内存地址不一样就直接打入集合,如果哈希值相同,在比较equals</font>
想要比较里具体的值,可以重写hashCode以及equals 重写的详情请看笔记
不同步
转成线程同步的方法
Collections.synchroizedCollection
TreeMap
按照自然顺序排列的键值对集合,<b><font color="#f15a23">不能重复,键不能为空</font></b>
HashTable
支持线程同步,但是不建议使用
IO流
特性:
先进先出,先读到的流最先被写出去;
顺序存取,读取的时候是一串一串的,写出的时候也是按照顺序写不能随机访问
分类
低级流
FileInputStream
FileOutPutStream
高级流
FiledReader
FileWriter
序列化 Serializable
当某个类需要通过流进行打散处理就需要实现serializable接口
多线程
进程
操作系统应用中的一个任务,它包含了某些资源的区域,系统利用这个区域划分出一些<b>执行单元(线程)</b>
线程
线程是最小的执行单元
特性:
线程只能<b>归属于</b>一个进程,并且可以访问该进程上面的资源。当线程创建后会主动申请一个<b>主线程(默认优先级是5)</b>
实现方法:
继承Thread类
实现Runnable接口
常用方法:
getId() 返回线程的标识符<br><br>getName() 返回线程名<br><br>getPriority() 返回优先级<br><br>setPriority(int level) 设置优先级<br><br>getState() 返回线程状态<br><br>isAlive() 线程是否处于运行状态<br><br>isDaemon() 是否是进程守护<br><br>setDaemon(boolean b) 设置进程守护<br><br>isInterrupted() 是否被中断
线程安全
同步和异步
同步:方法1调用方法2,方法1停下等待,直到方法2运行结束
异步:方法1调用方法2,方法1不受方法2的影响
定义:
当<b>多个线程</b>访问某个<b>公共资源</b>的时候,<b>运行结果和属性的变化和我们设想的相同</b>,那么就是线程安全
线程不安全的原因:
当多个线程访问共享资源的时候,由于某些原因使得时间判断分配出现了问题,会导致线程跳过某些关键性的验证,使得数据变化超过预期
解决方法
锁机制 synchronize
使用方法:
修饰词 返回类型 方法名(参数列表){<br> synchronize(守卫对象){<br> 里面填写同一时间内只能被一个线程执行的代码片段<br> }<br>}
守卫对象(个人命名):一般来说是this,也可以是类型为Object的成员变量,这个守卫对象主要是调用wait、notify以及join方法,<b><font color="#c41230">只有在同一个锁下或者是同一个守卫对象才能去唤醒处于waiting状态的线程</font></b>
常用方法:
wait( [long mills] )
使线程从Running状态转变成Waiting状态,并且等待notify方法来唤醒
notify()
该方法可以将<b>同一个锁下</b>调用wait方法之后处于waiting状态的线程,随机唤醒一个使其变成<b>Runnable</b>状态
notifyAll()
该方法可以将<b>同一个锁下</b>处于waiting状态的线程,全部被唤醒处于<b>Runnable</b>状态
join()
在线程2中使用线程1.join()方法会使线程2处于waiting状态,直到线程1运行结束后再抢占资源
<b>join底层源码调用的是wait(0)方法,wait(0)是可以被自动<font color="#c41230">隐式</font><font color="#000000">唤醒的,但是需要调用join方法的对象去隐式的调用notify()方法,所以调用了join方法时候就必须等待调用join方法这对象执行完成后再去执行</font></b>
线程池
特性:
ExecutorService是Java提供的管理线程池的类,主要有两个作用:控制线程数量,线程的重用
当一个程序中有大量的线程并在任务结束后销毁,这样会给系统带来**过度的**资源消耗,以及过度的切换,最终导致系统崩溃
种类
newFixedThreadPool( int 线程数 ) 创建固定的线程数量可以共享,无人介入的方式来运行这些线程
newCachedThreadPool() 创建一个线程数量可变的线程池,但是在以前构造的线程可用时将他们重用
队列
BlockQueue
阻塞队列
定义
当队列列是空的的时候,执行获取操作的线程会被阻塞;当队列是满的时候就添加操作的线程会阻塞
常用方法
插入
add(e)<br>
返回值
boolean
成功
返回true
失败
抛出异常 IllegalStateException
常见异常
IllegalStateException
超过队列长度
NullPointerException
添加的值为<font color="#f44336">空/null</font>
IllegalArgumentException
如果指定元素的某个属性阻止其添加到此队列中。<font color="#f44336">可能是给元素被其它线程锁死</font>
官方说明
如果可以在不违反容量限制的情况下立即将指定元素插入此队列,则成功时返回true,如果当前没有可用空间,则引发IllegalStateException。当使用容量受限的队列时,通常最好使用offer
offer(e)
返回值
Boolean
成功
true
失败
false
常见异常
ClassCastException
如果指定元素的类阻止其添加到此队列中
NullPointerException
添加的值为<font color="#f44336">空/null</font>
IllegalArgumentException<br>
如果指定元素的某个属性阻止其添加到此队列中。<font color="#f44336">可能是给元素被其它线程锁死</font>
offer(e,time,unit)<br>
返回值
成功
true
失败
false
说明
将指定的元素添加到队列中,如果队列满了则在指定的等待时间内等待。
参数
e
添加到队列的元素
time
指定的等待时长
unit
等待时长的单位
put(e)
返回值
无
常见异常
NullPointerException
添加的值为<font color="#f44336">空/null</font>
IllegalArgumentException<br>
如果指定元素的某个属性阻止其添加到此队列中。<font color="#f44336">可能是给元素被其它线程锁死</font>
说明
将指定的元素插入此队列,如有必要,等待空间变得可用。即添加的时候如果队列满了则线程等待,变为阻塞状态
移除
remove()
说明
从该队列里删除指定的Object。更正式的说,如果这个队列包含一个或者多个这样的元素,则删除元素
返回值
boolean
成功
true
异常
ClassCastException
如果指定元素的类阻止其添加到此队列中
NullPointerException
添加的值为<font color="#f44336">空/null</font>
poll()
poll(time,unit)
take()
说明
检索并移除该队列头部,如果队列是空,则等待有元素
返回
从队列头部移除的元素
异常
InterruptedException
等待被中断
原理示意图
通信
Socket类
通常称为<b><font color="#c41230">套接字</font></b>,用于描述IP地址和端口,是一个通信链的句柄值,在网上的主机一般运行一个多服务的软件,同时提供了几种服务,每个服务都打开一个Socket类并绑定到一个端口上,不同的端口对应不同的服务
TCP和UDP的区别
TCP会对传输的数据进行验证,并且保证数据全部到达以及到达的顺序;UDP不会对数据做检查,也不保证数据是否能到达,是否按顺序到达,但是速度较快 ,适合做视频聊天、网络游戏等项目
反射
定义<br>
反射是java的一种自我管理的机制,可以通过对象找到对应的类并管理它
作用
可以通过反射机制发现对象的类型、方法、属性以及构造函数等,<font color="#c41230"><b>也可以通过反射创建对象</b></font>,实现动态代理
使用方式
创建Class<br>
Class cls = 类名.clss<br>
Class cls = Class.forName("全类名")<br>
Class cls = 对象.getClass()<br>
方法
创建对象<br>
getInstance()
获取成员变量<br>
getFields()
getField( String name )
getDeclaredFilds()
getDeclaredFild( String name )
获取构造函数<br>
getConstructors()
getConstructor( Class<?>...parameterTypes )
getDeclaredConstructors()
getDeclaredConstructor( Class<?>...parameterTpes )
获取成员方法<br>
getMethods()
getMethod(String name , Class<?>...parameterTypes)
getDeclaresMethods()
getDeclaresMethod(String name,Class<?>...parameterTypes)
JDBC
DriverManager 驱动管理接口
Class.forName("com.mysql.jdbc.Driver") 注册驱动
DriverManager.getConnection(URL,USER,PASSWORD)
Connection 数据库关联接口
conn.PrepareStatement(String sql);获得预处理对象
PreparedStatement 预处理接口
继承了Statement ,预编译Sql对象,效率高,并且使用setXXX方法拼接字符串,防止sql注入
sql的安全拼接:使用 问号“?”来占变量的位置,例如:String sql = "Insert into employee (Ename,Esex,Eage) values (?,?,?)";
Set数据类型(String、int、Time等等)
作用:把变量拼接到由“?”站位的字符串中
语法:PrepareStatementObject.Set[Type](第几个问号 , 变量 );
Statement 接口
是PrepareStatement的父接口,静态的非预编译,效率低,容易被sql注入
ResultSet 结果集
详细的查询方法点击链接
SQL<br>
DDL数据库定义语言 建库之类的
Create 创建库&表
数据类型
整数:INT
字符串(需要指定长度):Varchar、char
浮点:FLOAT、DOUBLE
日期类型:Date、DateTime、TimeStamp、Time、Year
数据约束
not null 值不为空
auto_increment 自动增长
unique 唯一
primary key 主键
foreign key 外键
check 检查数据是否符合设置的条件CHECK(列字段的限制表这式)
DML 数组库操作语言
增加
insert Into 表名 [(列字段1,…,列字段n)] values(对应的值 自增长的用null站位)
删除
Delete from 表 where 删除的条件
修改
upDate 表 set 字段1=值,…,字段2=值2
查询
1.基本查询:select 输出的列字段 from 表
2. 条件查询: select 列 from 表 where 查询的条件
模糊查询
3. 排序输出
语法:select 列字段… from 表 where 条件 order by 列名1[asc升/desc降],列2[asc/desc];
4.分组查询
语法: select 列名 from 表 group by 列 [having 条件];
5. 分页查询
语法: select 列 from 表 limit 参数1,参数2;
6. 表连接
语法: select 表1.列,表2.列 from 表1 联接关键字 表2 on 条件(比如相同的部分);
内连接 inner join
左连接 Left Join
右链接 Right Join
7. Union 多表联合
8. 正则
语法:Select 列 from 表 where 列 regexp ‘正则基本语法’
子句执行顺序
开始->FROM子句->WHERE子句->GROUP BY子句->HAVING子句->ORDER BY子句->SELECT子句->LIMIT子句->最终结果
爬虫
爬虫不犯法,你可以爬网站展示出来的所有数据,犯法的是破解数据库
常见的爬虫工具
httpclient
只能获取响应中的体内容,无法解析
htmlUnit
也可以获取网页整页信息,抓取二次提交的数据
jsoup
基于java的爬虫技术,可以获取整页信息,二次提交页也可以获取
python
beautifulsoup 代码简单 爬虫分析网页逻辑和jsoup一样
jsoup
爬取页面数据,会以html格式展示,但是存在很多问题
如何抓取整个页面
如何抓取一个网站的所有页面(有效的a标签分析)
如何定位一个准确的信息内容
二次提交的数据如何获取
需要登录如何获取
避开反爬虫
如何抓取整个页面
常用方法
Jsoup.connect( String url )
参数
[String] 目标连接
返回值
[Connection.Response] 请求返回对象
request.body()
返回值
[String] 整个页面的html字符串
Jsoup.connect(url).get()
返回值
[Document] 目标网页对象
Jsoup.clean(String html , String baseUri, Whitelist whitelist)
简化网页结构 将没用的标签属性删除
获取script的内容
ele.data()
HttpClient
Get请求
模拟浏览器发起get请求
基本步骤
1. 创建HTTPClient对象
CloseableHttpClientclient = HttpClients.createDefault()
2. 创建URI对象 设置请求参数(不需要参数的可以将url直接写到第三步)
URIBuilder uri = new URIBuilder("请求地址");<br>uri.addParameter( [String key] , [String value] );
3. 创建请求体 并设置请求头
HTTPGet get = new HttpGet(uri.build()); // 如果没有参数可以直接填URL<br>get.addHeader( "Accept" , "*/*" );<br>get.addHeader( "Host" , "https://www.baidu.com" )
4. 发起请求获取响应体 并解析数据
// 使用http客户端发起请求 获取响应结果<br> response = client.execute(get);<br> // 查看响应状态码<br> if (response.getStatusLine().getStatusCode() == 200){<br> // 解析响应获取网页结构<br> String html = EntityUtils.toString(response.getEntity(), "utf8");<br> System.out.println(html);<br> }
Post请求
模拟post请求,并实现表单提交
基本步骤
1. 创建HTTPClient对象
CloseableHttpClientclient = HttpClients.createDefault()
2. 创建post对象,设置访问的url
// 创建Post对象,设置访问url<br> HttpPost post = new HttpPost("http://yun.itheima.com/search");<br>
3. 设置提交的参数
// 设置提交参数<br> ArrayList<NameValuePair> params = new ArrayList<>();<br> // 添加NameValuePair的实现类<br> params.add(new BasicNameValuePair("keys","Java"));<br> // 创建表单Entity对象,第一个参数是封装好的表单数据,第二个参数是编码格式<br> UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params, "utf8");<br> // 将表单对象设置进去<br> post.setEntity(formEntity);<br>
4. 发起请求获取响应体 并解析数据
// 使用http客户端发起请求 获取响应结果<br> response = client.execute(post);<br> // 查看响应状态码<br> if (response.getStatusLine().getStatusCode() == 200){<br> // 解析响应获取网页结构<br> String html = EntityUtils.toString(response.getEntity(), "utf8");<br> System.out.println(html);<br> }
客户端连接池
基本使用步骤
1. 创建连接池管理器
// 创建连接池管理器<br> PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();<br><br> // 设置最大连接数<br> cm.setMaxTotal(100);<br><br> // 设置每个主机最大连接数 当访问同一个Host的时候最多分配多少个连接<br> cm.setDefaultMaxPerRoute(10);<br>
2. 使用连接池管理器
// 获取连接<br> CloseableHttpClient client = HttpClients.custom().setConnectionManager(cm).build();<br><br> HttpGet httpGet = new HttpGet("http://47.110.139.194/api/getArticles?cid=4&rowNumber=0&lastFileID=0&pageSize=20&orderby=");<br><br>下面和正常的解析一样
Okhttp
绕过证书验证
private static class TrustAllHostnameVerifier implements HostnameVerifier {<br> @Override<br> public boolean verify(String hostname, SSLSession session) {<br> return true;<br> }<br> }<br><br> private static class TrustAllCerts implements X509TrustManager {<br> @Override<br> public void checkClientTrusted(X509Certificate[] chain, String authType) throws CertificateException {<br> }<br><br> @Override<br> public void checkServerTrusted(X509Certificate[] chain, String authType) throws CertificateException {<br> }<br><br> @Override<br> public X509Certificate[] getAcceptedIssuers() {<br> return new X509Certificate[0];<br> }<br> }<br><br> private static SSLSocketFactory createSSLSocketFactory() {<br> SSLSocketFactory ssfFactory = null;<br><br> try {<br> SSLContext sc = SSLContext.getInstance("TLS");<br> sc.init(null, new TrustManager[]{new TrustAllCerts()}, new SecureRandom());<br><br> ssfFactory = sc.getSocketFactory();<br> } catch (Exception e) {<br> }<br><br> return ssfFactory;<br> }<br><br> public static void main(String[] args) throws IOException {<br> OkHttpClient.Builder builder = new OkHttpClient.Builder();<br> builder.sslSocketFactory(createSSLSocketFactory());<br> builder.hostnameVerifier(new TrustAllHostnameVerifier());<br><br> OkHttpClient client = builder.build();<br><br> Request request = new Request.Builder()<br> .url("https://www.hkma.gov.hk/chi/regulatory-resources/regulatory-guides/by-subject-current/consumer-protection/")<br> .get()<br> .addHeader("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36")<br> .build();<br> Response response = client.newCall(request).execute();<br> System.out.println(response.body().string());<br> }<br>
反反爬虫
构造合理的 HTTP 请求头
Accept
作用:浏览器端可以接收到的媒体类型
常用:accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding
作用:浏览器声明接受的编码方式,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate)
指令
gzip
便是采用Lempel-Ziv coding(LZ77)压缩算法,以及32位CRC校验的编码方式。
compress
采用 Lempel-Ziv-Welch (LZW) 压缩算法。
deflate
采用 zlib 结构和 deflate 压缩算法。
br
表示采用 Brotli 算法的编码方式。
identity
用于指代自身(例如:未经过压缩和修改)。除非特别指明,这个标记始终可以接受。
*
匹配其他任意未在该请求头字段重列出的编码方式。假如请求头字段不存在的话,这个只是默认值。他并不代表任意算法都支持,而仅仅标识算法之间无优先次序<br>
:q=
代表优先级,也叫权重
例如:Accept-Encoding: zh-CN,zh;q=0.8
Accept-Language
作用:声明浏览器接收的语言
指令
language
用含有两到三个字符串表示的语言码或完整的语言标签。如zh-CN,en-US
*
任意语言
;q=
权重
例如:<br>
accept-language: zh-CN,zh;q=0.9,en;q=0.8
Connection
作用:决定当前事务完成后,是否关闭网络连接。如果是Keep-alive ,网络连接就是持久的不会关闭。除去标准的逐段传输(hop-by-hop)头(<b><font color="#c41230">Keep-Alive,Transfer-Encoding,TE,Connection,Trailer,Upgrade(en-US),Proxy-Authorization,Proxy-Authenticate</font></b>),任何逐段传输头都需要列出。
指令
close 表名客户端/服务器先要关闭网络连接,这是HTTP/1.0请求的默认值
只是用逗号分割
例如:
Connection : keep-alive
Host
作用:请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常在HTTP URL中提取出来(<b><font color="#c41230">在HTTP/1.1发送请求时,该报头域是必需的</font></b>)。
语法:Host: <host> : <port>
指令
<host>:服务器的域名
<port>(可选):服务器监听的TCP端口号
例如:Host: developer.mozilla.org
Referer
作用:告诉服务器,请求是从哪里来的。<br><b><font color="#c41230">有两种情况,referer不会发送:</font></b><br> 采用本地文件协议,如“data”或者“file”;<br> 当前请求页面采用的是非安全协议,而原网页采用的是安全协议(HTTPS)
语法:Referer : <url>
指令:<url> 当前页面被链接而至的前一页面的绝对路径或者相对路径
例如:Referer: https://developer.mozilla.org/en-US/docs/Web/JavaScript
User-Agent
作用:告诉服务器,客户端使用的操作系统和浏览器的名称和版本
语法
User-Agent: <product> / <product-version> <comment>
指令
priduct:产品识别码
product-version:产品版本号
comment:零个或多个关于组成产品信息的注释
例如
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)
cache-control
作用:通用消息头字段,被用于在http请求和响应中,通过指定指令来实现缓存机制。缓存指令是单向的,这意味着在请求中设置的指令,不一定被包含在响应中。
语法
缓存请求指令:
Cache-Control: max-age=<seconds>
Cache-Control: max-stale[=<seconds>]
Cache-Control: min-fresh=<seconds><br>
Cache-control: no-cache<br>
Cache-control: no-store<br>
Cache-control: no-transform<br>
Cache-control: only-if-cached
缓存响应指令
Cache-control: must-revalidate<br>
Cache-control: no-cache<br>
Cache-control: no-store<br>
Cache-control: no-transform<br>
Cache-control: public<br>
Cache-control: private<br>
Cache-control: proxy-revalidate<br>
Cache-Control: max-age=<seconds><br>
Cache-control: s-maxage=<seconds>
指令
可缓存性
public
表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存,即使是通常不可缓存的内容。(例如:1.该响应没有max-age指令或Expires消息头;2. 该响应对应的请求方法是 POST 。)
private
表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它)。私有缓存可以缓存响应内容,比如:对应用户的本地浏览器。
no-cache
在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证(协商缓存验证)。
no-store
缓存不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存。
到期
max-age=<seconds>
设置缓存存储的最大周期,超过这个时间缓存被认为过期(单位秒)。与Expires相反,时间是相对于请求的时间。
s-maxage=<seconds>
覆盖max-age或者Expires头,但是仅适用于共享缓存(比如各个代理),私有缓存会忽略它。
<span style="color: rgb(33, 33, 33); font-family: consolas, "Liberation Mono", courier, monospace; font-size: 16px; font-weight: 700; letter-spacing: -0.0444444px; background-color: rgb(238, 238, 238);">max-stale[=<seconds>]</span>
表明客户端愿意接收一个已经过期的资源。可以设置一个可选的秒数,表示响应不能已经过时超过该给定的时间。
min-fresh=<seconds>
表示客户端希望获取一个能在指定的秒数内保持其最新状态的响应。
重新验证和重新加载
must-revalidate<br>
一旦资源过期(比如已经超过max-age),在成功向原始服务器验证之前,缓存不能用该资源响应后续请求。
<dt style="box-sizing: border-box; font-weight: 700; color: rgb(33, 33, 33); font-family: arial, x-locale-body, sans-serif; font-size: 16px; letter-spacing: -0.0444444px;"><code style="box-sizing: border-box; background-color: rgb(238, 238, 238); -webkit-box-decoration-break: clone; font-family: consolas, "Liberation Mono", courier, monospace; padding: 0px 3px; overflow-wrap: break-word;">proxy-revalidate</code></dt>
与must-revalidate作用相同,但它仅适用于共享缓存(例如代理),并被私有缓存忽略。
例如:cache-control: max-age=0



评论
0 条评论
下一页

