原理
名词解析
SDOWN:subjectively down,主观下线.
ODOWN:objectively down,客观下线
转换过程
1、每个sentinel实例在启动后,都会和已知的slaves/master以及其他sentinels建立TCP连接,并周期性发送PING(默认为1秒),在交互中,如果redis-server无法在”down-after-milliseconds”时间内响应或者响应错误信息,都会被认为此redis-server处于SDOWN状态<br>2、SDOWN的server为master,那么此时sentinel实例将会向其他sentinel间歇性(一秒)发送”is-master-down-by-addr ”指令并获取响应信息,如果足够多的sentinel实例检测到master处于SDOWN,那么此时当前sentinel实例标记master为ODOWN…其他sentinel实例做同样的交互操作.配置项”sentinel monitor ”,如果检测到master处于SDOWN状态的slave个数达到,那么此时此sentinel实例将会认为master处于ODOWN.<br>3、每个sentinel实例将会间歇性(10秒)向master和slaves发送”INFO”指令,如果master失效且没有新master选出时,每1秒发送一次”INFO”;”INFO”的主要目的就是获取并确认当前集群环境中slaves和master的存活情况.<br>4、经过上述过程后,所有的sentinel对master失效达成一致后,开始故障转移.
自动发现机制
Sentinel与slaves”自动发现”机制: <br><br>在sentinel的配置文件中,都指定了port,此port就是sentinel实例侦听其他sentinel实例建立链接的端口.在集群稳定后,最终会每个sentinel实例之间都会建立一个tcp链接,此链接中发送”PING”以及类似于”is-master-down-by-addr”指令集,可用用来检测其他sentinel实例的有效性以及”ODOWN”和”failover”过程中信息的交互.在sentinel之间建立连接之前,sentinel将会尽力和配置文件中指定的master建立连接.sentinel与master的连接中的通信主要是基于pub/sub来发布和接收信息,发布的信息内容包括当前sentinel实例的侦听端口.
选举
1. 每个做主观下线的 Sentinel 节点向其他 Sentinel 节点发送命令,要求将它设置为领导者.<br>2. 收到命令的 Sentinel 节点如果没有同意通过其他 Sentinel 节点发送命令,那么将同意该请求,否则拒绝<br>3. 如果该 Sentinel 节点发现自己的票数已经超过 Sentinel 集合半数且超过 quorum ,那么它将成为领导者<br>4. 如果此过程有多个 Sentinel 节点成为了领导者,那么将等待一段时间重新进行选举
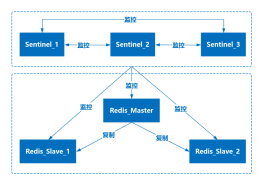
原理
心跳机制+投票裁决。每个sentinel会向其它sentinal、master、slave定时发送消息,以确认对方是否活着,如果发现对方在指定时间内未回应,则暂时认为对方宕机。若哨兵群中的多数sentinel都报告某一master没响应,系统才认为该master真正宕机,通过Raft投票算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置。
缺点
1、如果是从节点下线了,sentinel是不会对其进行故障转移的,连接从节点的客户端也无法获取到新的可用从节点<br>2、无法实现动态扩容