
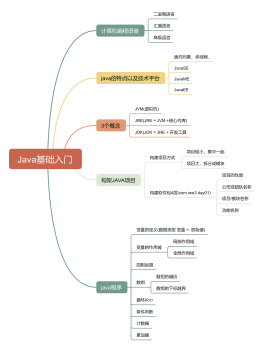
Java大全
2021-02-18 11:21:58 0 举报AI智能生成
java知识点梳理大全
高效工作方式
模板推荐
作者其他创作
大纲/内容
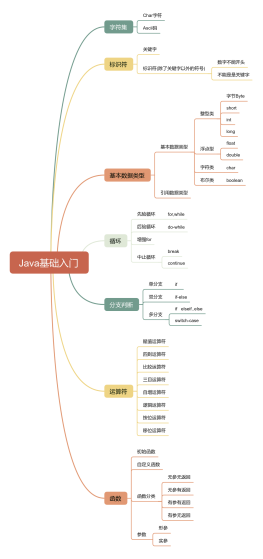
集合
list
有序,可重复
collection——Iterable
迭代器设计模式
一般集合继承了Iterator
next
checkForComodification//检查列表是否修改,若修改则抛出异常(非线程安全)
modCount != expectedModCount
检查游标的位置,若游标的位置比数组长度还大则抛异常
游标向后移动1,最后进行赋值
remove
checkForComodification
删除lastRet索引处的元素<br> ArrayList.this.remove(lastRet);
cursor = lastRet;//游标前移,由于是删除remove方法删除的是lastRet位置的元素则游标需要前移才能保证可以遍历到所有的元素<br>
hasNext
cursor游标记录当前索引的位置,是从0开始的,和集合大小比较,判断还有没有元素
判断游标是否到达最后的位置,若没有表示还有元素,若有则没有元素了
https://www.jianshu.com/p/910e2a24c70d
实现类
AbstractList
ArrayList
数据结构object[]数组
构造函数初始化数组,默认大小10
扩容,oldCapacity + (oldCapacity >> 1),右移一位,原始大小的1.5倍
扩容方法Arrays.copyOf——System.arraycopy
适合随机查找和遍历,不适合插入和删除
Vector
和list相似,存储的对象分配一块连续的地址空间
扩容,vector在每次扩张容量的时候,将容量扩展2倍,这样对于小对象来说,效率是很高的
线程安全
访问它比访问ArrayList慢
数组的索引是连续的而且数组的长度是固定的,无法自由增加数组的长度
AbstractSequentialList
LinkedList
数据结构Node对象的双向列表(pre、next),每个链表有First,Last头尾节点<br>
当作堆栈、队列和双向队列使用
添加元素
取出尾结点,将newNode的prev指向last,后节点指向null,last指向newNode
如果链表为空, 就直接first和last都指向最新节点
如果链表不为空,链表next就指向最新节点
set
无序,不可重复
collection——Iterable
实现类
AbstractCollection
AbstractSet
HashSet
LinkedHashSet
根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序
遍历集合LinkedHashSet集合里的元素时,集合将会按元素的添加顺序来访问集合里的元素
底层数据结构是哈希表
储存
HashSet会调用该对象的hashCode方法来得到该对象的hashCode值
然后根据该hashCode值决定该对象在HashSet中的存储位置
特点
Hash算法来存储集合中的元素,因此具有很好的存取和查找性能
HashSet集合判断两个元素的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode方法返回值也相等
不用一个个遍历索引去访问,这就是它比数组快的原因
实现
hashmap
构造函数,默认是构造hashmap(初始值16,负载因子0.75)
添加元素add,实现就是通过hashmap添加,key进去去重
SortSet
AbstractSet
TreeSet
SortedSet实现类
数据结构红黑树,默认整形排序为从小到大
Comparator comparator()
红黑树
根节点是红色
所有叶子节点是黑色,并且是null
每个红色节点的两个子节点是黑色
从任一节点到其子树,每个叶子节点的路径都包含相同数量的黑色节点
去重实现通过TreeMap
map
Map集合是有Key和Value的,Collection集合是只有Value
实现类
TreeMap
TreeMap因为是通过红黑树实现
红黑树结构天然支持排序,默认情况下通过Key值的自然顺序进行排序
AbstractMap
HashMap
1.7
数组+链表
构造函数直接初始化,大小16,负载因子0.75
链表头节点插入
数组大于阀值直接扩容
扩容,元素按新数组大小直接重新hash
多线程容易导致循环列表
循环列表,get链表遍历会形成死循环
扩容大小是原来数组大小的两倍
1.8
数组+链表+红黑树
构造函数不会初始化,根据传入初始化值,赋值集合大小>=2的幂次方
put操作,key进行hash,低16位和高16位做一个异或操作,得到最后hash值
putValue才会进行集合初始化
数组大小大于64,链表大于8,转换红黑树
扩容,分高低位,低位保持不变,高位原来hash值+原数组大小
尾结点插入
左移一位,构造一个新的数组
线程不安全
ConcurrentHashMap
线程安全
sizeCtil
判断是否有线程在进行初始化
cas 进行初始化
并发扩容,判断是多线程还是单线程
数组元素扩容的阀值
并发扩容,分段形式,来并发实现数据的迁移
如果桶较少的话,默认一个 CPU(即一个线程)处理 16 个桶
已经被处理,设置成fwd
根据CPU核心数,分配每个CPU处理的桶数量目的是让每个 CPU 处理的桶一样多,避免出现转移任务不均匀的现象
赋值
头节点加锁
hash和key相等就进行覆盖
通过countCell数组的方式来实现并发增加元素的个数
默认情况下构建两个长度的CounterCell[]
并发量不大的情况下,基于cas去计算baseCount元素个数
多线程情况下,数组进行扩容,并发去赋值元素个数
hash
特点
根据对象的hashCode方法来得到该对象的hashCode值,根据hash值确定储存位置
不用一个个遍历索引去访问,这就是它比数组快的原因
类型
HashMap
HashTable
数据结构:数组+链表
线程安全
初始默认大小11,负载因子0.75
链表头插法
rehash总元素个数超过容量*加载因子时,扩容为原来 2 倍并重新散列
JVM
类加载
加载
二进制字节流
方法区运行时的数据结构
堆中生成一个代表这个类的Class对象
验证
文本格式验证
utf-8文件(魔数、版本)
字节码验证
指令
符号引用验证
类、字段、方法对应的引用解析能否正常
元数据验证
语意分析(final、private、abstract)
解析
类变量的初始值
准备
符合引用转化成直接引用
初始化
执行类构造器<clinit>()方法
<clinit>方法在多线程执行的时候会被加锁
类加载器
双亲委派模式
如果一个类加载器收到了类加载的请求,首先不是尝试加载这个类
这个请求委派给父类加载器去完成
加载请求最终都应该传送到顶层的启动类加载器
父加载器无法完成这个请求,子加载器才会尝试去加载
loadClass加载——this.parent != null进行递归——findBootstrapClassOrNull
类型
扩展类加载器
启动类加载器Bootstrap ClassLoader
应用程序类加载器
内存模型
线程私有
程序计数器
循环、跳转、异常处理
字节码解释器
字节码的行号指示器
虚拟机栈
局部变量表
变量
栈帧
多个方法顺序调用
不同变量运算操作
动态链接
其他类的一个方法调用
方法出口
方法调用完返回出口(正常、异常)
64位linux默认虚拟机栈大小:1024KB,-Xss或者-XX:ThreadStackSize设置
本地方法栈
native方法
线程共享
方法区
类信息、常量、静态变量、即时编译后的代码
常量池
符号引用、容器计数器、标识符、直接引用
字面量(文本字符串,生命final的常量值)
回收目标
常量池的回收、类型卸载
堆
新生代
edu区
S0
S1
老年代
内存分配
堆包含一个链表来维护已用和空闲的内存块
线程共享的Java堆中可能划分多个线程私有的分配缓冲区(TLAB)
垃圾回收器
新生代
serial
单线程
ParNew
多线程
默认开启收集线程和CPU的数量一致
通过-XX:+ParallelGCThreads 控制线程数量
Parallel Scavenge
多线程
目的 达到一个可控制的吞吐量
吞吐量 = 运行用户代码时间 / (运行用户代码时间+垃圾收集时间)
收集时间短
运行代码时间长
-XX:+UseAdaptiveSizePolicy GC自适应调整策略
动态调整edu sur区的大小
晋升老年代年龄大小自动调整
复制算法
将可用内存按容量划分大小相等的的两块
将存活的对象放在另一块内存中
将已使用的内存进行一次清理
老年代
CMS
获取最短回收时间、停顿时间为目标的收集器
初始标记
标记GCRoot能直接关联的对象,速度很快
并发标记
标记其他不被回收的对象
三色标记算法
黑色:引用链当前节点和子节点已经被标记过
灰色:当前节点被标记,子节点还未标记
白色:未被标记的节点
会导致漏标的情况
并发问题<br>A-B-D是一个引用链,AB都被标记是黑色和灰色,D没有被标记是白色<br>正好D与B断开链接,被标为垃圾对象<br>而D又正好与A建立了关系,A就灰色<br>A就要向下标记,如果A有两个属性都标向了D<br>第一个属性对D进行标记,A成了黑色,第二个属性再去操作发现A是黑色标记,它确定子节点被标记过了,导致D就不会被标记,D一直就是垃圾对象
重新标记
修正并发标记期间,用户线程运作导致标记产生变动的那一部分
停顿时间比初始标记时间较长,远比并发标记时间短
从gcroot的引用链进行从新标记,有一部分标记结果会被记录到栈缓存中
并发清除
标记——清除 算法
标记出所有要回收的对象
标记完成后统一回收被标记的对象
优点
并发收集,低停顿
并发标记、并发清除,用户线程影响相对于少一点
缺点
默认回收线程数 (CPU+3)/4
当CPU小于4,消耗会显得比较大,占用线程大于50%
无法处理浮动垃圾
并发清理期间,用户线程还在运行,新的垃圾产生
CMS老年代使用到68%的空间就会被激活
临时启用Serial Old 进行回收
启动单线程,会导致卡顿,老年代空间大,清除比较慢
碎片过多,对大对象分配有影响,没有足够连续内存,触发Full GC
Serial Old
单线程
CMS 后备预案
Paralled Old
Parallel Scavenge 收集器 搭配使用 吞吐量提高
标记整理
让所有存活的对象都向一端移动
然后直接清理掉端边界以外的内存
G1
物体上不再区分老年代新生代,逻辑上还是有的
整个Java堆划分多个大小相等的region区域
局部采用复制算法
整体采用标记-整体算法
流程
初始标记
并发标记
重新标记
选择清除
根据垃圾回收的时间,回收之后的内存,维护一个优先列表
每次根据允许的收集时间,收集回收价值最大的regin
内存扫描
一个对象分配在某个region中,可能与别的region有引用关系,导致全堆扫描
G1的每个region都有一个与之对应的remembered Set
region中对象的引用关系,会被维护到被引用对象所属的remembered set
对象
Object
存储
连接方式
直接引用
reference直接存放对象的内存地址
句柄
堆中分出一块内存做句柄池
局部变量表reference就是对象的句柄地址
句柄包含实例数据和数据类型的地址信息
对比
对象会进行gc变动,只是指针变量,方便垃圾回收
直接指针最大优势是访问速度快
引用类型
强引用
只要强引用还在,垃圾收集器永远不会回收掉被引用的对象
关键字new创建的对象所关联的引用就是强引用
软引用
系统将要发生内存溢出之前,将这些对象进行第二次回收
缓存
弱引用
被弱引用关联的对象只能生存到下一次垃圾回收之前
缓存
虚引用
无法通过虚引用获取对象实例
希望这个对象在被收集时收到一个系统通知
可用来跟踪对象被垃圾回收器回收的活动,当一个虚引用关联的对象被垃圾收集器回收之前会收到一条系统通知
结构
new Object 对象储存在堆
Object类型在方法区
object在线程栈帧局部变量表
是否开启压缩,压缩class指针,普通指针
何时回收
对象死亡
对象没有关联GCRoot引用链,会被第一次进行标记筛选
object——finalize方法
finalize方法已被调用过,没有必要执行,直接回收
对象放置F-Quene队列中
低优先级线程区执行,GC在F-Quene进行第二次标记
重新建立引用链可不被回收
方法区回收
废弃常量
无用的类
回收算法
引用计数算法
python垃圾回收算法
给对象添加一个引用计数器,每个地方引用,引用一次,计数器加一
循环引用问题
可达性分析算法
以GCRoot的对象作为起点
当一个对象没有任何引用链相连,GC不可达,对象不可用
gcroot
栈帧本地变量表引用的对象
Native方法引用的对象
static 常量引用的对象 final
对象分配
大对象直接进入老年代
对象主要分配在新生代的Edu区
如果有本地线程分配缓存,线程优先TLAB分配
防止分配时锁竞争
栈上分配
满足逃逸分析
标量替换,参数直接在栈上
对象回收
长期存活对象
对象在Edu出生,经历一次Minro GC 任然活着,年龄加1
当年龄增加到15的时候,就会被晋升到老年代<br>
-XX:MaxTenuringThreshold 设置年龄阈值
动态对象
如果Sur空间中相同年龄所有对象大小的总和大于Sur空间一半
空间分配担保
发生Minro GC时,检查每次晋升老年代的平均大小是否大于老年代剩余空间大小
大于,直接进行Full GC
小于,再判断是允许分配担保失败
允许就进行Minro GC
不允许就进行Full GC
防止频繁 Full GC
监控工具
测试环境
jconsole
jvmsual
生产环境
athas
dasharod
thread -n
thread -b
jprofile
jdk
jstack
jmap
jmap -histo:live <pid>
jmap -dump:live,format=b,file=路径.hprof pid 日志打印
ema内存分析
jmap -heap
jstat
jstat -gcutil pid 1000
jps
jinfo
ps p 1115 -L -o pcpu,pid,tid,time,tname,cmd
top
cat /proc/cpuinfo 查看cpu信息
load average
后面的三个数字分别表示距离现在一分钟,五分钟,十五分钟的负载情况
一般来说这个值不要超过 0.7*CPU核数
Tasks-->进程数(任务数)
running--> 正在运行的进程数
sleeping --> 238个进程正在休眠
%Cpu(s)
user 用户空间占用cpu的百分比
system 内核空间占用cpu的百分比
wa-->IO wait IO等待占用cpu的百分比
id-->空闲cpu百分比
KiB Mem
3775264 total -->物理内存总量3.7G
250100 free --> 空闲内存总量250M
2495300 used --> 2.4G已经使用
1029864 buff/cache --> 1G缓存
KiB Swap
4064252 total-->交换区总量(4G
2789544 free-->空闲交换区总量(2.7G)
1274708 used-->使用的交换区总量(1.2G)
在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了
字符串
String
final类型
实现final char[] 数组
字符串拼接
字节码实现new StringBuilder对象
常量池
1.6
Perm Space(永久代)
堆中的对象和永久代的对象分离的
创建方式
new对象,字符串在堆中生成
intern方法,都会在常量池中创建字符串对象(若此时常量池不存在该字面量)
1.6之后
Perm Space 移出放到堆中
创建方式
new对象,堆中会生成一个字符串对象,同时常量池也会生成一个字面量
intern 方法会先判断常量池中是否存在与 s3 相同字符串的对象,若有,则返回该引用;<br>若无,则在常量池创建一个引用指向 s3,然后返回该引用,返回 s3 引用
String s3 = new String(“123”) + new String(“123”); <br>1、首先涉及到字面量 “123” 肯定会在常量池中创建 “123” 字面量对象, 2、然后再在堆中创建一个 ”123123” 对象,返回该引用给 s3<br>s3.intern();<br>2、intern 方法会先判断常量池中是否存在与 s3 相同字符串的对象,若有,则返回该引用;<br>若无,则在常量池创建一个引用指向 s3(指向的还是堆),然后返回该引用,返回 s3 引用
StingBuilder
实现AbstractStringBuilder
数据结构char[] value,非fina类型
非线程安全
StringBuffer
实现AbstractStringBuilder
构造方法根据参数初始化,默认大小是16
数组长度不够,扩容(value.length * 2 + 2)
System.arraycopy扩容方式
arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
Object src : 原数组
int srcPos : 从元数据的起始位置开始
Object dest : 目标数组
int destPos : 目标数组的开始起始位置
int length : 要copy的数组的长度
潜复制,复制结果是一维的引用变量传递给副本的一维数组,修改副本时,会影响原来的数组。
直接通过指针遍历赋值,默认情况下是拷贝地址的,所以它们还是指向同一块内存
数据结构char[] value,非fina类型
线程安全syncronized
JUC
线程基础
状态
start
runnable
time_waiting
waiting
block
方法
sleep
不会释放锁,进入阻塞队列
wait
释放锁,进入等待队列
join
join 当前线程等待,其他join线程执行后执行等待线程
可以超时设置
不需要获取到锁
yield
调用 yield()方法会让当前线程交出CPU资源,让CPU去执行其他的线程。
调用yield()方法并不会让线程进入阻塞状态,而是让线程重回就绪状态
不会释放锁
开启方式
继承Thread
实现Runnable接口
实现Callable接口
结果阻塞FutureTask
关键字
syncornized
加锁方法
代码块
每个对象都有一个监视器锁(monitor)
ObjectMonitor() {<br> _count = 0; //用来记录该对象被线程获取锁的次数<br> _waiters = 0;<br> _recursions = 0; //锁的重入次数<br> _owner = NULL; //指向持有monitor对象的线程 <br> _WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet<br> _WaitSetLock = 0 ;<br> _EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表
如果该线程已经占有该monitor,则进入数+1
如果其他线程占有该monitor,则monitor的进入数不为0,则该线程进入阻塞状态,直到monitor为0,重新获取monitor的所有权
方法区
字节码多了个ACC_SYNCORNIZED标识
调用方法时会检查这个标志,如果被设置了,执行线程先获取monitor,再执行方法代码,再释放monitor
锁优化
对象
对象头
markword
分代年龄
hashcode
锁状态
锁标志位
类型引用指针
对象数据
padding
1.5
重量级锁
1.6
偏向锁
cas判断
检查一下对象头的markword是否有偏向锁线程id
对象头和栈帧的锁记录里储存了偏向锁的线程id
轻量级锁
对象的mark word 储存在栈帧中
线程尝试使用cas将对象头中的markword替换为指向锁记录的指针
重量级锁
串行化执行
cas
AtomicInteger
基于 Unsafe 类实现
this,Unsafe 对象本身
需要通过这个类来获取 value 的内存偏移地址
valueOffset,value 变量的内存偏移地址
expect,期望更新的值
update,要更新的最新值
原理
// 比较当前值与期望值,如果相同则更新,不同则直接返回<br> while (cur_as_bytes[offset] == compare_value)
// 调用汇编指令cmpxchg执行CAS操作,期望值为cur,更新值为new_val<br> jint res = cmpxchg(new_val, dest_int, cur);
自旋区别
自旋是没有条件的for选好,基于java 自身实现的
AtomicStampedReference
ABA问题
AtomicStampedReference,通过为引用建立个 Stamp 类似版本号的方式
LongAdder
LongAdder 适合于高并发场景下,特别是写大于读的场景
LongAdder 内部维护了 base 变量和 Cell[] 数组
cells数组中的元素进行操作,当要更新的位置的元素为空时插入新的cell元素
LongAdder 操作后返回的是个近似准确的值,最终也会返回一个准确的值
volatile
字节码ACC_VOLATILE
内存可见性
CPU访问内存
L1、L2私有缓存,L3共享缓存
通过lock指令
当cpu的缓存行的值失效了,要通知其他cpu拥有这个值的缓存行失效了
其他cpu需要从内存中在读取一遍值
通过缓存行去访问Cache_line
主存类型
RAM随机存储器:可读可写,死机,可能会数据丢失
ROM可读存储器:只能读不能写
Cache高速缓存
防止指令重排序
jvm加了内存屏障
读屏障
Load1和Load2不会乱序
写屏障
store和 store不会乱序
读写屏障
load和store不会乱序
写读屏障
store和load不会乱序
屏障前的指令不会被排到屏障后去,屏障后的指令也不会排到屏障前去
lock
AbstractQueuedSynchronizer
读锁、写锁ReentrantReadWriteLock
读锁:共享锁,读共享,读写互斥
写锁:独占锁、互斥
可重入
公平锁、非公平锁ReentrantLock
lock
unlock
区别
非公平锁,lock直接cas设置锁标志状态1
非公平锁,加入AQS队列后,成为头节点,会进行tryAcquire争夺锁,不会判断前面会有阻塞线程
AQS
维护了一个Node节点类
头节点head,尾结点tail
引用变量pre,next
自旋的方式,形成头尾节点,双向列表
保存阻塞中的线程以及获取同步状态的线程
waitStatus:volatile关键字修饰的节点等待状态
CANCELLED 值为1
因为超时或者中断,结点会被设置为取消状态
被取消状态的结点不应该去竞争锁
结点会被踢出队列,被GC回收
SIGNAL 值为-1
后继节点的线程处于等待的状态
当前节点的线程如果释放了同步状态或者被取消
会通知后继节点、后继节点会获取锁并执行
CONDITION 值为-2
节点在等待队列中、节点线程等待在Condition
当其它线程对Condition调用了singal()方法该节点会从等待队列中移到同步队列中
PROPAGATE 值为-3
读写锁中存在的状态
代表后续还有资源,可以多个线程同时拥有同步状态
参考https://www.cnblogs.com/wait-pigblog/archive/2018/07/16/9315700.html
线程池
创建方式
Executors工具类
newFixedThreadPool
固定线程池
核心线程数,最大线程数一样
空闲线程不会被回收
LinkedBlockingQueue阻塞队列
任务数多但资源占用不大,平台消息推送,短信消息
newCachedThreadPool
缓存线程池,每来一个任务,开启一个线程
核心线程数是0,最大线程数是Interge.MAX_VALUE
空闲线程每60秒进行回收
场景:订阅发布场景,消息队列
SynchronousQueue
不储存元素的阻塞队列
每一个put操作必须等待一个take操作,否则不能添加操做
newScheduledThreadPool
延时线程
实现类型
scheduleWithFixedDelay
initialDelay 延时启动时间,delay 每次延时调用时间
任务执行完,固定延迟一定时间
scheduleAtFixedRate
当任务执行时间小于延时时间,等到延时时间到,才会执行
当任务执行时间大于延时时间,任务执行完,直接执行
参数确定核心线程,最大线程数是Integer_Max
空闲线程不会回收
DelayedWorkQueue延时队列
实现PriorityQueue
优先级队列实现commpareTo()来实现优先级
让延时时间最长的放在队列的末尾
场景:定时器,延迟队列,缓存
newSingleThreadExecutor
单线程线程池
核心线程数和最大线程数都是1
空闲线程不会回收
LinkedBlockingQueue阻塞队列
当列队满,队列会阻塞插入元素得线程,直到队列不满
队列为空时,获取元素的线程会等待队列不为空
AQS、Condition
当往队列插入一个元素,队列不可用,阻塞生产这通过lockSupport.park()
当往队列获取元素,队列不可用,阻塞生产这通过lockSupport.park()
场景:异步,安全单线程执行
new ThreadPoolExecutor
参数
核心线程数corePoolSize
最大线程数maximumPoolSize
回收时间keepAliveTime
回收时间单位TimeUnit
ThreadFactory
线程个性化设置:命名、优先级
BlockingQueue阻塞队列
拒绝策略RejectedExecutionHandler
直接丢弃
抛异常,线程数不够reject
当前线程执行
丢掉队列末端任务,放到尾部
动态调整线程池
setCorePoolSize
线程池会直接覆盖原来的corePoolSize值
当前线程,大于配置值,进行回收
当前线程,小于配置值,进行创建新线程
修改线程池核心大小、最大核心大小、队列长度
执行流程
execute
(workerCountOf(c) < corePoolSize
addWorker(command, true)
compareAndIncrementWorkerCount(c)
new Worker(firstTask)
runWorker(this)
task = getTask()
workQueue.take();
w.lock();
beforeExecute(wt, task);
task.run();
afterExecute(task, thrown);
w.unlock();
workQueue.offer(command)
!addWorker(command, false)
reject(command);
调优
CPU密集型
CPU性能相对硬盘、内存要好很多,数据库的读写操作
CPU时间片切换少,设置更多线程
最大线程数 = CPU核心数的两倍
(线程等待时间+线程cpu时间)/ 线程cpu时间 * 核心数 = 线程数
IO密集型
大部份时间用来做计算、逻辑判断,CPU切换比较频繁
最大线程数 = CPU核心数+1
场景
任务数多但资源占用不大
电商平台消息推送或短信通知
被处理的消息对象内容简单所占用资源非常少
线程池
CPU内核数2-4倍(经验值)的值设置核心线程与扩展线程
创建线程池时设置较长的任务队列
合理固定的线程数可以使得CPU的使用率更加平滑
newThreadPoolExecutor(16, 16, 0, TimeUnit.SECONDS, queue);
任务少资源占有大
文件流、长文本对象或批量数据加工的处理
如日志收集、图片流压缩或批量订单处理等场景
线程池
合理较小的任务队列长度
newThreadPoolExecutor(16, 64, 30, TimeUnit.SECONDS, queue);
合理设置扩展线程空闲回收的等待时长以节省不必要的开销
任务多资源占有大
如遇任务资源较大、任务数较多同时处理效率不高的场景下
线程池
首先需要考虑任务的产生发起需要限流
任务的发起能力应当略小于任务处理能力
当遇到任务处理能力不足的情况下,任务发起方的作业将被阻塞(prefetch)
newThreadPoolExecutor(64, 64, 0, TimeUnit.SECONDS, queue);
场景
死锁
原因
互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用
请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放
循环等待
预防
资源一次性分配:一次性分配所有资源,这样就不会再有请求了
请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放
可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源
方案
确定的顺序获得锁
超时放弃
检测死锁
首先为每个进程和每个资源指定一个唯一的号码
然后建立资源分配表和进程等待表
解除死锁
剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态
撤消进程:可以直接撤消死锁进程或撤消代价最小的进程
工具
Jstack
Jconsole
athas
线程异常
submit
这个异常将被Future.get封装在ExecutionException中重新抛出
execute
异常处理器UncaughtExceptionHandler

Collect
Get Started

Collect
Get Started

Collect
Get Started
Collect
Get Started
评论
0 条评论
下一页

