内存回收<br>
过期策略
策略方式
立即过期策略<br>
为每个key创建一个定时器(对内存友好,但会占用大量cpu)
惰性过期策略
当访问一个key的时候再判断是否过期(对内存不够友好)
<b><font color="#f68b1f" style=""><u>redis采用惰性过期策略和定期过期策略</u></font></b>
<u>redis通过<font color="#f68b1f">expire</font>和<font color="#f68b1f">persist(移除可以的过期时间)</font>设置<font color="#f68b1f">过期时间</font>和<font color="#f68b1f">永久生效</font></u><br>
算法<br>
LRU 默认 最近最少使用
LFU<br>
Random<br>
持久化
RDB(redis database缩写快照)
在指定的时间间隔内将内存中的数据集快照写入磁盘 <font color="#f15a23"> fock子进程全量备份文件</font><br>RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化
优点
只有一个dump.rdb文件(<font color="#f15a23">快照</font>),方便持久化<br>
RDB文件紧凑,<font color="#f15a23">全量备份</font>,非常适合用于进行<font color="#f15a23">备份和灾难恢复</font>。
性能最大化,子进程完成数据备份,不影响主进程<br>(生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。)<br>
数据集大时比AOF恢复快
缺点
数据安全性低,<font color="#f15a23">在快照持久化期间修改的数据不会被保存,会</font><b><font color="#f15a23">有数据丢失的问题</font><br>fock出的子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。</b>
AOF(append only file)<br>
将redis执行的每次命令放到一个日志文件中记录;<font color="#f15a23">操作记录保存到文件,增量备份</font>,fock子进程将文件重写 当开启两种方式备份时,优先使用AOF恢复数据<br>
优点
<font color="#f15a23">数据安全</font>,可保证数据不丢失
AOF也有三种触发机制<br>(1)每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好 <br>(2)每秒同步everysec:(默认)异步操作,每秒记录 如果一秒内宕机,有数据丢失 并且就算发生故障停机,也最多只会丢失一秒钟的数据<br>(3)不同no:从不同步<br>AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
<b><font color="#f15a23">rewrite模式</font></b>会对过大的文件进行合并重写,删除其中的某些命令<br>
缺点<br>
AOF文件比RDB文件大,数据恢复启动时慢
redis持久化数据和缓存扩容的方式
缓存扩容方式
使用<b><font color="#f68b1f">一致性哈希</font></b>实现动态扩容缩容
持久化数据扩容方式<br>
必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情<br>况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
选型<br>
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
常用工具
redisson<br>
一个高级的分布式协调Redis客服端,能帮助用户在分布式环境中轻松实现一些Java的对象
功能简单,不支持字符串操作,不支持排序,事务,<b><font color="#c41230">管道</font></b>,分区等特性<br>
jedis<br>
redis的java客户端,提供比较全的redis命令操作<br>
lettuce
非关系型数据库
非关系型数据库特点
1、存储非结构化的数据,比如文本、图片、音频、视频。 <br>2、表与表之间没有关联,可扩展性强。<br> 3、保证数据的最终一致性。遵循 BASE(碱)理论。 Basically Available(基本 可用); Soft-state(软状态); Eventually Consistent(最终一致性)。 <br>4、支持海量数据的存储和高并发的高效读写。 <br>5、支持分布式,能够对数据进行分片存储,扩缩容简单。<br>
常见的非关系型数据库
1、KV 存储,用 Key Value 的形式来存储数据。比较常见的有 Redis 和 MemcacheDB。<br>2、文档存储,MongoDB。 <br>3、列存储,HBase。<br> 4、图存储,这个图(Graph)是数据结构,不是文件格式。Neo4j。 <br>5、对象存储。<br> 6、XML 存储等等等等。<br>
网站
官网介绍:https://redis.io/topics/introduction 中文网站:http://www.redis.cn<br>介绍 http://redisdoc.com/topic/persistence.html
常用命令
存值set qingshan 2673<br>取值get qingshan<br>查看所有键 keys *<br>获取键总数 dbsize<br>查看键是否存在 exists qingshan<br>删除键 del qingshan jack<br>重命名键 rename qingshan pengyuyan<br>查看类型 type qingshan<br>
高并发带来的问题<br>
雪崩<br>
大量热点数据同时过期 (因为设置了相同的过期时 间,刚好这个时候 Redis 请求的并发量又很大,就会导致所有的请求落到数据库。)
解决方案<br>
过期时间设置随机值,避免大量失效<br>
永不过期<br>
加互斥锁或者使用队列,针对同一个 key 只允许一个线程到数据库查询
给每个缓存增加是否失效标记,失效后马上刷新缓存 或者预先更新<br>
穿透<br>
请求数据库不存在的值,redis失去作用<br>
解决方法<br>
缓存空数据,设置短时间失效
不然的话数据库已经新增了这一条记录,应用也 还是拿不到值。
采用布隆过滤器
将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的<br>查询压力
特点<br>
1、如果布隆过滤器判断元素在集合中存在,不一定存在 2、如果布隆过滤器判断不存在,一定不存在
布隆过滤器把误判率默认设置为 0.03,也可以在创建的时候指定。<br>位图的容量是基于元素个数和误判率计算出来的。<br>存储 100 万个元素只占用了 0.87M 的内存,生成了 5 个哈希函数。
<font color="#f15a23">存在一定的误判率;过滤器越长误判率越小;哈希函数越多,效率越差,误判率越小</font>
应用场景<br>
因为要判断数据库的值是否存在,所以第一步是加载数据库所有的数据。在去 Redis 查询之前,先在布隆过滤器查询,如果 bf 说没有,那数据库肯定没有,也不用去查了。 如果 bf 说有,才走之前的流程。
问题 如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在?<br>在海量元素中快速判断一个元素是否存在<br>
原理<br>
<font color="#f15a23">使用多次哈希函数计算每次得到位置,将位置标记为1,做有一个位置为0,则表示数据一定不存在</font><br>
击穿<br>
缓存中没有,数据库中有,(一般为缓存时间到期)
解决方案
热点数据永不过期
<b>加互斥锁</b>
缓存降级<br>
服务出现异常或非核心业务影响核心业务,仍然保证核心系统能使用,可以根据关键数据判断实现缓存降级或者手动降级<br>
目的<br>
保障核心业务可用
为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略
interview
为什么要放在内存中?
内存的速度更快,10wQPS<br>减少计算时间,减轻数据库压力
和memcache的区别
memcache只能存储KV、没有持久化机制、不支持主从复制、是多线程的
Redis为什么这么快?<br>
纯内存结构<br>
请求单线程<br>
同步非阻塞IO<br>
同步:用户线程和内核的交互方式<br>
阻塞:线程调用内核IO操作<br>
多路复用<br>
多个TCP连接复用一个或多个线程<br>
数据一致性保障?<br>
流程
1、如果数据在 Redis 存在,应用就可以直接从 Redis 拿到数据,不用访问数据库。<br>2、如果 Redis 里面没有,先到数据库查询,然后写入到 Redis,再返回给应用。
方案<br>
先更新数据库,再删除缓存
总之,对于后删除缓存失败的情况,我们的做法是不断地重试删除或异步删除,直到成功。保证数据的最终一致性
先删除缓存,再更新数据库
异常<br>
异常情况: <br>1、删除缓存,程序捕获异常,不会走到下一步,所以数据不会出现不一致。<br> 2、删除缓存成功,更新数据库失败。 因为以数据库的数据为准,所以不存在数据 不一致的情况。<br>
看起来好像没问题,但是如果有程序并发操作的情况下: <br>1)线程 A 需要更新数据,首先删除了 Redis 缓存 <br>2)线程 B 查询数据,发现缓存不存在,到数据库查询旧值,写入 Redis,返回 <br>3)线程 A 更新了数据库 这个时候,Redis 是旧的值,数据库是新的值,发生了数据不一致的情况。<br>
<font color="#f15a23">延时双删</font>的策略,在写入数据之后,再删除一次缓存
A 线程: <br>1)删除缓存<br> 2)更新数据库 <br>3)休眠 500ms(这个时间,依据读取数据的耗时而定)<br> 4)再次删除缓存<br>
一个字符串类型的内存最大容量<br>
<b><font color="#f15a23">512M</font></b>
常见性能问题和解决方案<br>
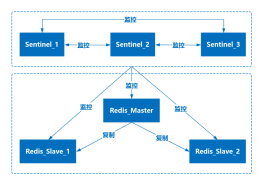
1. Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
2. 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次(<b>可配置为每执行一个命令就持久化一次</b>)。
3. 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
4. 尽量避免在压力较大的主库上增加从库
5. Master调用BG<b>REWRITE</b>AOF<u>重写AOF文件</u>,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
延时队列的实现<br>
使用时间戳做score, 消息内容作为key,调用zadd来生产消息,消费者使用zrangbyscore获取n秒之前的数据做轮询处理。<br>
使用过Redis做异步队列么,你是怎么用的?有什么缺点?<br>
使用过 Redis 做异步队列么,你是怎么用的?答:一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有 消息的时候,要适当 sleep 一会再重试。
如果对方追问可不可以不用 sleep 呢?list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。
如果对 方追问能不能生产一次消费多次呢?使用 pub/sub 主题订阅者模式,可以实现 1:N 的消息队列。
当发布者通过PUBLISH 命令向chinnel发布命令时,订阅该频道的客户端都会受到此消息。
如果对方追问 pub/sub 有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 RabbitMQ等。
如果对方追问 redis 如何实现延时队列?我估计现在你很想把面试官一棒打死如果你手上有一根棒球棍的话,怎么问的这 么详细。但是你很克制,然后神态自若的回答道:使用 sortedset,拿时间戳作为 score,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令 获取 N 秒之前的数据轮询进行处理。到这里,面试官暗地里已经对你竖起了大拇 指。但是他不知道的是此刻你却竖起了中指,在椅子背后。
什么是redis<br>
Remote Dictionary Server 远程字典服务<br>
是一个开源的基于C语言编写的nosql<br>